 夜雨聆风
夜雨聆风





考试接近满分的“AI医疗助手”,为何一到真实对话就掉链子?
真实使用效果与模型理论能力的落差:问题往往不在“会不会”,而在“怎么一起用”
同一批大语言模型,在“单独做题”时能给出很强的医学判断;但当公众通过聊天方式求助时, 最终做出的健康决策并未变好,某些关键任务反而更差。差距来自互动链条中的信息传递、误解与取舍,而不只是模型知识量。
一、为何要做“公众医疗助手”的随机对照?
过去两年,大语言模型在医学考试与知识问答上屡屡拿到高分,“像医生一样说话”的能力也越来越强。 因此,一个看似顺理成章的设想出现:让模型成为“公众医疗助手”,在家里帮助判断病情轻重、给出下一步行动建议。
但医疗判断并不只是背知识点。真实世界里,求助者往往用碎片化语言描述症状,表达不完整;模型会追问,也会给出多种可能; 最终还要由人类把信息拼起来,选出最合适的行动。真正的风险,可能藏在“对话链条”而不是“知识库”。
这正是《自然·医学》这项研究要回答的问题:把公众随机分组,让一部分人使用大语言模型聊天求助, 另一部分人按日常习惯自行查资料(搜索引擎、常用网站或经验),看最后的决策质量是否真的提升。
图1|试验设计一眼看懂
|
10 个医疗情景 (明确“最佳处置”) |
|
1,298 人 (人口学分层随机) |
|
三组用模型 一组自由查资料 |
|
|
|
|
||
|
(从 10 个中随机抽) |
|
① 处置选择(五级) ② 列出可能病因 |
|
(医生共识答案) |
试验为随机、预注册;模型组包含 GPT-4o、Llama 3、Command R+;对照组按日常习惯查资料。
二、任务是什么:比“猜病名”更关键的是“下一步怎么做”
试验把“在家自测”拆成两类输出: 一类是列出可能相关的健康问题(可理解为“哪些疾病可能在背后”); 另一类是选择下一步处置(可理解为“要不要立刻就医、去哪里就医、能否先观察”)。 这两类输出的难点不同:病名是知识与推理,处置则更像安全与风险管理。

研究使用“五级处置”作为标准答案标尺:从“自我照护”到“呼叫救护车”。
三、最关键的对比:模型单独做题很强,公众+模型并不更强
研究团队先确认:这些模型“单独做题”确实能完成任务。论文摘要给出两个代表性数字: 在模型直接获得完整情景并独立作答时, “相关病因识别”正确率可达 94.9%; “处置选择”平均正确率约 56.3%。
但当公众通过聊天方式向模型求助后,最终交卷结果却明显下降: 公众在“相关病因识别”方面 低于 34.5%, 在“处置选择”方面 低于 44.2%, 且整体上并不优于自由查资料的对照组;在“识别相关病因”这项任务上,对照组甚至显著更好。
图3|“理论能力”到“真实使用”的落差(示意)
以论文摘要与正文中的关键比例为参照:同一模型在不同环节的表现差异很大。
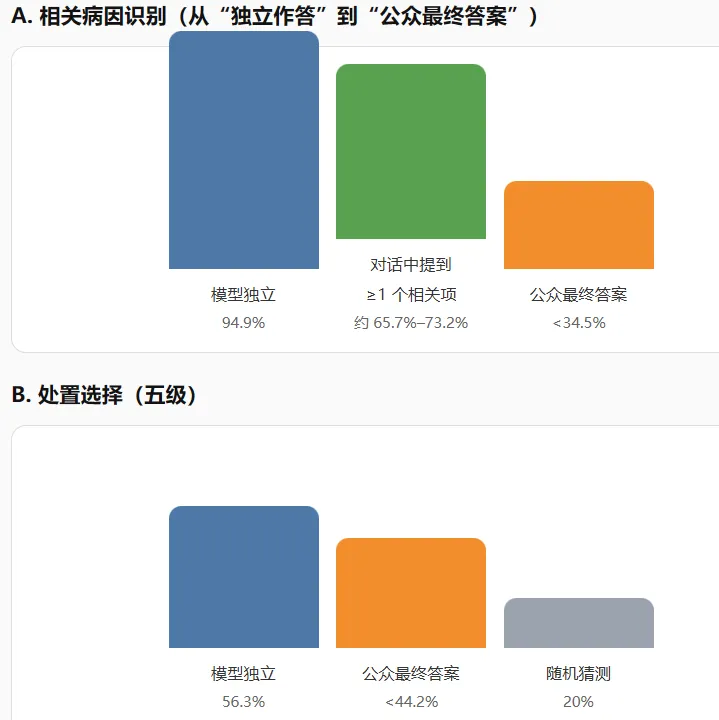
说明:A 中“对话中提到相关项”的区间来自正文(不同模型在对话中提到相关病因的比例)。B 中“随机猜测”来自五选一基线。
四、落差不是玄学:三段“信息传递”都可能断
直觉上,模型医学知识越多,公众得到的帮助应该越大。但研究显示:知识不等于效果,关键在于“信息如何流动”。 可以把一次求助想象成三段接力: (1)情景信息进入模型 → (2)模型给出候选解释 → (3)人类从候选中选出行动。 三段任意一段出问题,结果就会偏离“模型理论能力”。
(一)第一段:输入不完整,模型等于“只看了一半病历”
论文在对话记录中观察到:求助者提供的信息常常不全,或描述含糊, 使模型无法获得“完整情景”。正文也指出,既有“信息没说全”的情况,也有“模型误解提问”的情况。 一旦关键细节缺失,模型即使知识很强,也只能基于不完整线索推断。
一个常见的“缺信息”模式(示意)
描述:“肚子疼”。
缺失但关键:疼痛位置、持续时间、是否发热、是否呕吐/腹泻、是否黑便、是否怀孕、是否有基础病、是否出现昏厥等。
后果:模型只能给出覆盖面很广的可能性,候选越多,后面“选对行动”的难度越高。
(二)第二段:模型给了很多选项,但正确项混在其中
研究用“条件提取”方法统计对话里模型提到的病因:平均每次互动,模型会给出 2.21 个可能性(95% 置信区间 2.12–2.32), 但其中只有 34.0% 是正确的(95% 置信区间 32.3–35.9)。也就是说,模型常常能提到对的方向,但往往不止一个方向;并且错误项并不少。
这会引出一个现实问题:当候选里既有正确、也有错误时,如何让非专业人士可靠地把正确项挑出来? 如果挑选能力不足,模型输出越多,反而越可能带来“选择困难”或“被错误项带偏”。
(三)第三段:即使对话里出现了正确提示,最终也未必写进答案
更关键的是:对话中出现正确提示,并不等于最终决策采纳正确提示。 论文明确指出:即便正确建议出现在对话里,公众也并不稳定地把它写进最终回答。 数据上看,公众最终列出的病因平均为 1.33 个(95% 置信区间 1.28–1.38), 最终答案的“精确率”仅 38.7%(95% 置信区间 36.3–41.4)。
图4|从“模型输出”到“人类采纳”的漏斗

直观理解:模型并非“完全不懂”,而是“正确线索被稀释、被误读、被漏掉”。
五、用最少的统计,把“更好/更差”讲清楚
医学研究常用“比例”和“置信区间”表达结果。本文不铺开术语,只抓住三件事: (1)正确率有多高, (2)差异是否稳定, (3)差异有没有实际意义。
一个常用的小公式:赔率比(Odds Ratio, OR)
OR = [ p / (1 − p) ]对照 ÷ [ p / (1 − p) ]模型组
含义:对照组“做对”的优势是模型组的多少倍(以赔率表示)。 论文报告:在“识别相关病因”上,对照组识别出相关病因的优势约为 1.76 倍(95% 置信区间 1.45–2.13)。
另一个重要点是“统计显著”和“实际意义”要分开看。论文显示: 在“处置选择”上,模型组与对照组差异并不显著;但这不等于“已经足够好”,因为总体正确率仍然不高, 且各组都存在“低估病情严重程度”的倾向。
六、考试题与“模拟病人”为何预测不了真实互动?
很多医疗大模型在上线前会经历两类“看起来合理”的安全评测: 一类是医学考试题(例如执照考试风格的选择题、问答题); 另一类是“模拟病人”,即让模型扮演病人、另一个模型扮演医生来对话。 研究团队直接检验了这两类方法对真实结果的预测力,结论并不乐观:它们难以提前暴露“人类—模型互动失败”。
论文还做了一个“用模型代替人类参与者”的模拟实验:让一个模型扮演提问者、另一个模型提供帮助, 重复对话并作答。模拟参与者平均“处置选择”正确率约 57.3%, “相关病因识别”约 60.7%,明显高于真实公众;但这种模拟成绩与真实公众成绩的关联很弱, 回归系数只有大约 0.20–0.33(不同模型不同),甚至在“相关病因识别”上几乎无相关。
一句话解释“为何预测不了”
考试与模拟对话的共同点:信息更完整、表达更规范、目标更明确。 真实求助的共同点:信息碎、表达跳跃、担忧与偏好会改变提问方式,最终还要做取舍。 差异不在知识本身,而在互动链条的复杂性。
七、把“会答题”变成“能帮忙”:关键不只模型,更是系统
研究把问题指向“人类—模型互动”。这意味着:改进方向不只是“换更大模型”, 还包括界面、流程、表达方式、风险提示、以及如何帮助求助者把关键信息说清楚。 下面用更贴近日常的语言,拆成四个可操作的抓手。
(一)让模型少给“选项清单”,多给“结构化判断”
论文指出,对话中模型常给出多个候选(平均 2.21 个),而公众并不擅长从中挑出最关键的。因此,面向公众的医疗助手更需要“结构化输出”,例如: 优先级排序(先说最危险、最需要排除的), 给出理由(哪些症状支持、哪些反对), 明确下一步(需要补问哪些关键信息)。
(二)把“追问”变成固定流程:缺什么就问什么
真实对话里最大的问题之一,是关键事实缺失。 如果追问完全依赖自由聊天,很容易遗漏。 更稳健的做法是把追问做成“清单式流程”,例如围绕: 症状部位、 起病时间、 严重程度变化、 伴随症状、 基础病与用药、 危险信号(胸痛、呼吸困难、意识改变、持续高热、黑便/呕血等)。 先把信息补齐,再谈推断,能显著降低“只看半张病历”的概率。
(三)把“安全偏好”写进规则:不确定时宁可更谨慎
论文显示各组都存在低估严重程度的倾向。这提示:医疗助手不仅要“聪明”,还要“稳健”。 在公共健康场景里,系统往往应当把“漏掉严重情况”的代价放得更大, 在不确定时偏向建议专业评估,而不是给出过度安慰式的低风险结论。
(四)把“可信度”做成可见:区分事实、推断与不确定性
同一句回答,如果不区分“确定事实”与“推断”,容易让求助者把推断当成结论。 面向公众的输出更适合分层表达: 已知事实(由输入直接给出)、 可能解释(列出 1–2 个最高优先级)、 需要排除的危险信号、 下一步行动(到哪里、多久内、需要带什么信息)。 这样能减少“看上去很像确定结论”的误导。
八、一个更稳的使用流程模板(适用于聊天式自测)
流程模板(示意,可用于任何症状)
- 先给“时间线”
:何时开始、是否突然、是否加重或缓解。 - 再给“位置与性质”
:哪里不适、刺痛/闷痛/灼热/胀痛等。 - 补齐“伴随症状”
:发热、咳嗽、气促、呕吐、皮疹、尿频尿痛、头晕等。 - 说明“基础背景”
:年龄段、慢性病、妊娠相关、长期用药、过敏史。 - 单独确认“危险信号”
:胸痛/呼吸困难/意识异常/持续高热/明显出血/严重脱水等是否存在。 - 要求输出按层次
:最需要排除的危险情况 → 最可能解释 → 需要补问的关键问题 → 建议处置等级与理由。 - 交叉核对
:与权威健康机构的简明指引核对,尤其核对危险信号与就医时限。
这套模板的目标,是减少“信息缺失”和“输出难取舍”两类互动失败点。
九、这项研究的意义与边界:能说明什么,不能说明什么
(一)最重要的意义:上线前必须做“真人互动测试”
论文的主张非常明确:标准基准测试不足以预测真实互动失败, 在公共医疗建议这种高风险场景里,应当在部署前进行系统化的人类用户测试。 换句话说,“模型单独得分高”并不能替代“真实用户使用后更安全、更有效”的证据。
(二)边界:情景试验不等于真实就诊,但足以暴露互动问题
这类随机对照使用的是医生编写的标准化情景,并非真实病人就诊过程, 因此不能直接等同于临床结局(例如住院率、死亡率)。 但其价值在于:在可控条件下,把“对话链条”放到显微镜下, 能精准观察信息缺失、误读与取舍困难如何拉低最终质量。
(三)延伸思考:更强模型不一定自动更好,系统设计才决定落地
研究选择了多种可用模型做对照,结果一致指向互动瓶颈。因此,真正的改进路线往往是“模型能力 + 交互工程 + 安全策略 + 用户教育 + 上线后持续评估”。 医疗场景尤其如此:错误的代价高、责任边界严、需求又极其真实。
结尾一句话
大语言模型可以“像医生一样回答”,并不自动意味着它能“像医生一样帮助决策”; 让能力变成真实世界的效果,关键在于把互动链条做对,并用真人随机试验反复验证。
说明:本文仅讨论研究方法与结果,不构成医疗建议。出现胸痛、呼吸困难、意识障碍、明显出血等急症,应立即拨打当地急救电话或就近就医。