 夜雨聆风
夜雨聆风





微软官方文档:设计一套安全的多租户RAG推理解决方案
原文可参考:https://learn.microsoft.com/en-us/azure/architecture/ai-ml/guide/secure-multitenant-rag

检索增强生成(RAG)是一种构建应用程序的模式,该模式利用基础模型对专有信息或互联网上未公开的其他数据进行推理。通常,客户端应用程序会调用编排层,由该层从向量数据库等数据存储中获取相关信息。随后,编排层将这些数据作为上下文的一部分,以基础数据的形式传递给基础模型。
多租户解决方案可供多个客户使用。每个客户(即租户)均由来自同一机构、企业或团体的多名用户组成。在多租户场景中,你需要确保各租户,或租户内的个人用户,仅能使用其获授权访问的基础数据。
除了确保用户仅能访问其获授权的信息之外,多租户架构还存在其他方面的考量。不过,本文将聚焦于多租户架构的这一核心层面:确保用户仅能访问其获授权的信。本文首先概述单租户检索增强生成(RAG)架构,探讨在基于检索增强生成的多租户架构中可能遇到的挑战以及一些常用的应对方案,同时梳理多租户架构的相关注意事项,并给出提升安全性的相关建议。
本文介绍了多项仅适用于Azure OpenAI在Foundry Models中的专属功能,例如Azure OpenAI On Your Data功能。不过,本文所述的大部分原则,同样适用于任意平台上的基础人工智能模型。
配备编排器的单租户检索增强生成架构
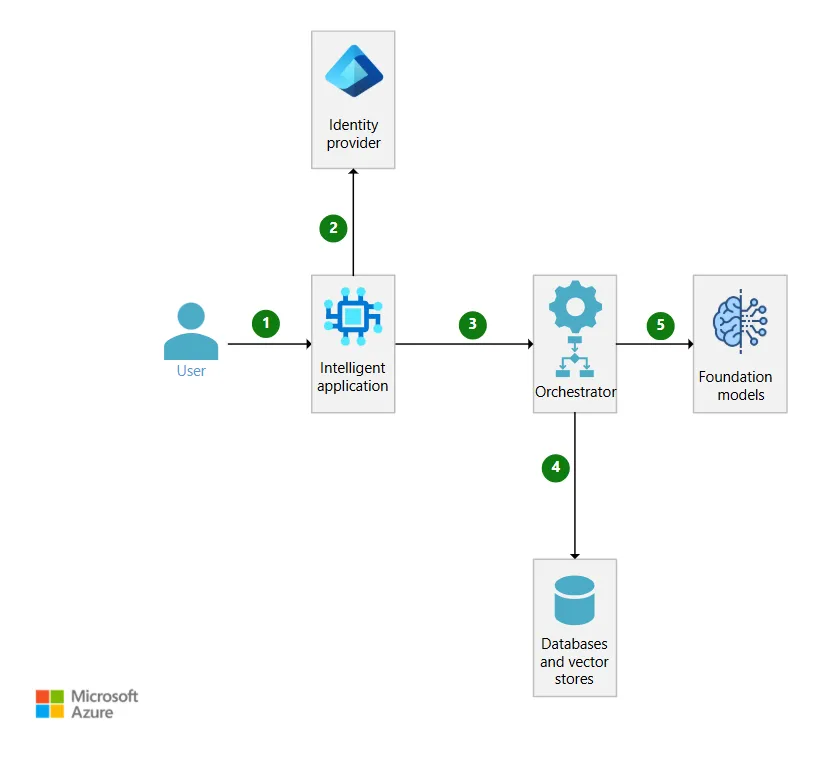
工作流
在这种单租户RAG架构中,协调器从数据存储中获取相关的专有租户数据,并将其作为基础数据提供给大语言基座模型。以下步骤描述了一个高层工作流程。
-
用户向智能 Web 应用程序发起请求。 -
身份提供商(identity provider)对请求方进行身份认证。 -
智能应用程序携带用户查询内容及用户授权令牌,调用编排器 API。 -
编排逻辑从请求中提取用户查询,并调用相应的数据存储,为该查询获取相关的参考依据数据(grounding data)。在下一步中,这些参考依据数据会被添加到发送给基础大模型的提示词(prompt)中,例如在 Azure OpenAI 中对外提供的模型。 -
编排逻辑连接至基础大模型的推理 API,并发送包含已获取参考依据数据的提示词。推理结果返回给智能应用程序。
具备直接数据访问能力的单租户检索增强生成架构
这种单租户RAG架构变体利用Azure OpenAI的On Your Data功能,直接与Azure AI Search等数据存储集成。
在这种架构中,你要么没有自己的编排器,要么编排器承担的职责更少。Azure OpenAI API会调用数据存储以获取基础数据,并将该数据传递给语言模型。这种方式会让你对要获取的基础数据以及数据的相关性拥有更少的控制权。
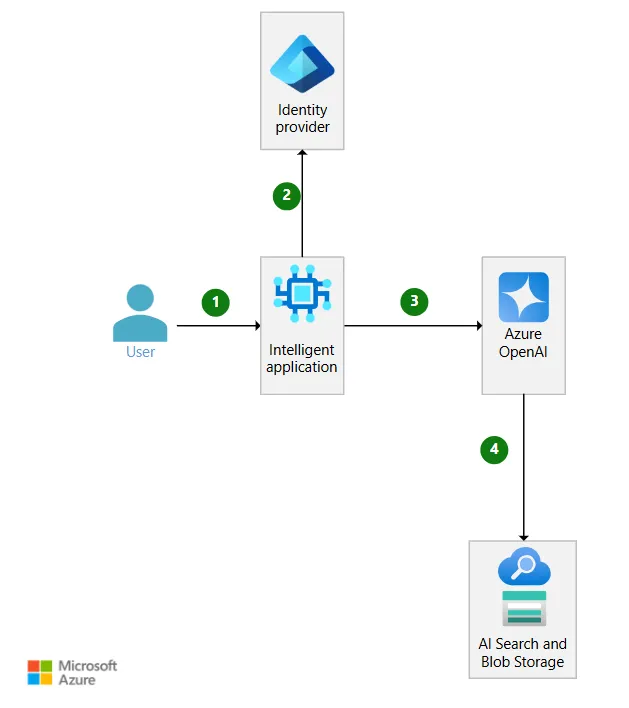
工作流
在该检索增强生成(RAG)架构中,提供基础模型的服务会从数据存储中获取对应的专属租户数据,并将该数据作为基础模型的基准参考数据。以下步骤描述了工作流程。
-
用户向智能 Web 应用程序发起请求。 -
身份提供商对请求方进行身份验证。 -
智能应用程序携带用户查询调用 Azure OpenAI。 -
Azure OpenAI 连接至受支持的数据存储(如 AI Search和 Azure Blob Storage),以获取参考依据数据。该数据将作为 Azure OpenAI 调用 OpenAI 大语言模型时上下文信息的一部分,处理结果返回至智能应用程序。
若要在多租户解决方案中使用此架构,那么直接访问参考依据数据的服务(如 Azure OpenAI)必须支持解决方案所需的多租户相关逻辑。
RAG架构中的多租户架构
在多租户解决方案中,租户数据既可存储于专属租户的存储库中,也可与其他租户数据共存于多租户存储库内。数据还可能存放在跨租户共享的存储库中。仅应将用户被授权访问的数据用作基础数据(grounding data)。用户应仅能查看通用数据、全租户数据,或其所属租户中经过筛选的数据,以此确保用户仅能查看自身获授权访问的数据。
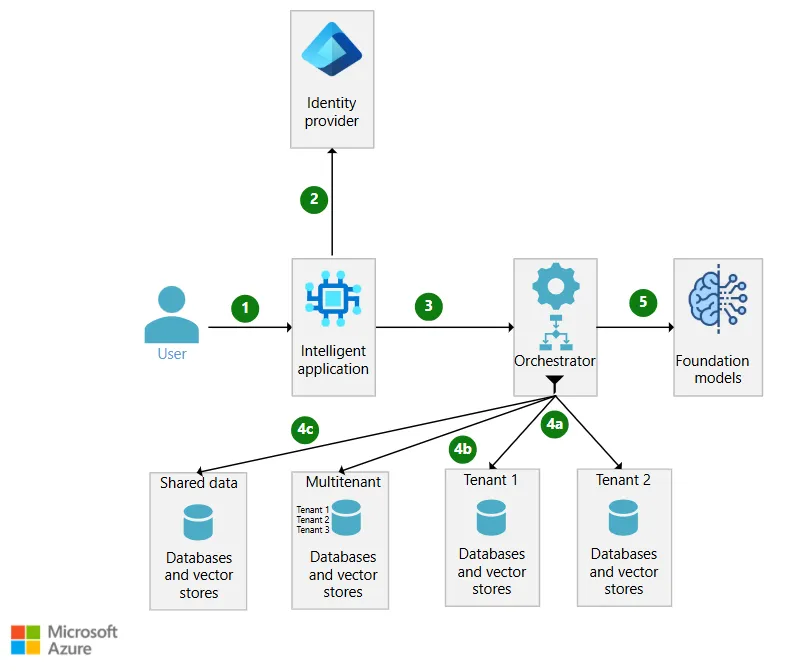
工作流程
-
用户向智能Web应用程序发起请求。 -
身份提供商对请求方进行身份验证。 -
智能应用程序携带用户查询及用户授权令牌,调用编排器API。 -
编排逻辑从请求中提取用户查询,并调用相应的数据存储,获取该查询对应的、经租户授权的相关基础数据。基础数据将被添加至提示词中,并在下一步发送至Azure OpenAI。该过程可包含以下部分或全部步骤:
-
4a. 编排逻辑从对应租户专属的数据存储实例中获取基础数据,并可应用安全过滤规则,仅返回用户有权访问的数据。
-
4b. 编排逻辑从多租户数据存储中获取对应租户的基础数据,并可应用安全过滤规则,仅返回用户有权访问的数据。
-
4c. 编排逻辑从租户间共享的数据存储中获取数据。
-
编排逻辑连接至基础模型的推理API,发送包含已获取基础数据的提示词,处理结果返回至智能应用程序。
检索增强生成(RAG)中多租户数据的设计考量
在设计多租户RAG推理解决方案时,请考虑以下选项。
选择一种存储隔离模型
在多租户场景中,针对存储与数据的两种主要架构方案为单租户专属存储(Store-per-tenant)和多租户共享存储(multitenant stores)。上述方案是对包含跨租户共享数据的存储方式的补充。你的多租户解决方案可结合使用这些方案。
按租户独立存储
在按租户独立存储的模式下,每个租户拥有专属的存储单元。该方案的优势在于可实现数据隔离与性能隔离。各租户的数据被封装在独立的存储单元中,在多数数据服务场景下,独立存储可有效避免其他租户带来的“邻居干扰”问题。同时,该方案能简化成本分摊流程,因为单个存储部署的全部成本可直接归属于对应租户。
该方案也存在一定挑战,例如管理与运维开销增加、成本更高。在面向大量小型租户的场景(如面向消费者的业务场景)中,不建议采用此方案,同时该方案还可能触及或超出服务上限。
在本人工智能场景中,按租户独立存储指的是,为上下文提供相关性所需的基础数据(grounding data),均来自仅包含该租户基础数据的现有或新建数据存储。在此拓扑结构中,数据库实例是区分不同租户的标识。
多租户存储
在多租户存储模式下,多个租户的数据共存于同一存储系统中。该方案的优势在于能够实现成本优化,相比单租户专属存储模式可承载更多租户,同时由于存储实例数量更少,管理开销也更低。
采用共享存储面临的挑战包括:需要实现数据隔离与管理、可能出现“邻区干扰”反模式,以及面向租户的成本分配更为复杂。其中,数据隔离是采用该方案时最核心的问题,必须部署安全机制以确保各租户仅能访问自身数据。若不同租户的数据生命周期存在差异,例如需要按不同时间计划创建索引等操作,数据管理也会变得更为棘手。
部分平台提供了可用于在共享存储中实现租户数据隔离的功能。例如,Azure Cosmos DB 原生支持数据分区与分片(data partitioning and sharding),通常会将租户标识符(tenant identifier)作为分区键,以此实现租户间的一定程度隔离;Azure SQL 与 Azure Database for PostgreSQL – Flexible Server则支持行级安全策略(row-level security)。不过,这些功能一般不会直接应用于多租户解决方案,因为若要在多租户存储中使用这类特性,需要围绕其对整体方案进行专门设计。
在该人工智能应用场景下,所有租户的基础数据会共存于同一数据存储中。因此,对该数据存储发起查询时,必须携带租户区分标识,以确保返回结果仅包含对应租户相关的有效数据。
共享存储
多租户解决方案通常会在不同租户之间共享数据。以医疗领域的多租户解决方案为例,数据库可存储通用医疗信息,或非特定于某一租户的信息。
在该人工智能场景下,基础数据存储库通常可被全局访问,无需依据特定租户进行数据筛选,因为这些数据对系统内所有租户均具备相关性且已获得授权。
Identity 身份
身份是多租户解决方案的核心要素,其中也包括多租户检索增强生成(RAG)解决方案。智能应用应与身份提供商集成,以完成用户身份的认证。多租户检索增强生成(RAG)解决方案需要一个身份目录,用于存储权威身份信息或身份引用。该身份信息需贯穿整个请求链路,使编排器、数据存储等下游服务能够识别用户身份。
定义你的租户与权限需求
在构建多租户检索增强生成(RAG)解决方案时,你必须为该方案明确租户的定义。可供选择的两种常见模式为企业对企业模式与企业对消费者模式。你所选择的模式,有助于确定在构建解决方案时还需考虑哪些其他因素。了解租户数量对于选择数据存储模式至关重要。若租户数量庞大,可能需要采用每个存储单元对应多个租户的模式;若租户数量较少,则可采用单租户专属存储单元的模式。各租户的数据量同样是关键因素。由于数据存储存在容量限制,若单个租户的数据量过大,可能会导致你无法使用多租户存储模式。
如果你打算扩展现有工作负载以支持该人工智能场景,或许你已经做出了这一决策。一般而言,若现有数据存储能够提供足够的相关性,并满足其他非功能性需求,便可将其用于存储基础数据(grounding data)。但如果你计划引入新组件,例如将专用向量检索库作为专门的基础数据存储,那么仍需做出相应决策。需考虑的因素包括当前的部署架构策略、对应用控制平面的影响,以及各租户间数据生命周期的差异,如按性能付费的场景等。
在为你的解决方案定义好租户的概念后,你需要明确数据的授权要求。租户仅能访问其自身所属的数据,但你的授权要求可能需要更精细的粒度。例如,在医疗解决方案中,你可能会制定如下规则:
-
患者仅能访问自身的患者数据。 -
医护人员可访问其所负责患者的数据。 -
财务用户仅能访问与财务相关的数据。 -
临床审核员可查看所有患者的数据。 -
所有用户均可在共享数据存储中获取基础医学知识。
在基于文档的检索增强生成(RAG)应用中,你可能希望依据标签体系或为文档设定的敏感等级,来限制用户对文档的访问。
在明确租户的定义并充分理解授权规则后,将这些信息作为数据存储解决方案的需求依据。
数据筛选
仅向用户开放其有权访问的数据,这一机制被称为筛选( filtering)或安全修剪( security trimming)。在多租户检索增强生成(RAG)场景中,用户可能会被关联至对应租户的专属存储库,但这并不意味着该用户能够访问此存储库中的所有数据。定义租户与授权需求(Define your tenant and authorization requirements )一文阐述了为数据设定授权规则的重要性,你应当以这些授权规则作为数据筛选的依据。
你可以借助行级安全等数据平台功能来实现数据筛选,也可通过自定义逻辑、数据或元数据完成筛选。这类平台功能通常不适用于多租户解决方案,因为系统设计需要围绕这些功能展开。
封装多租户数据逻辑
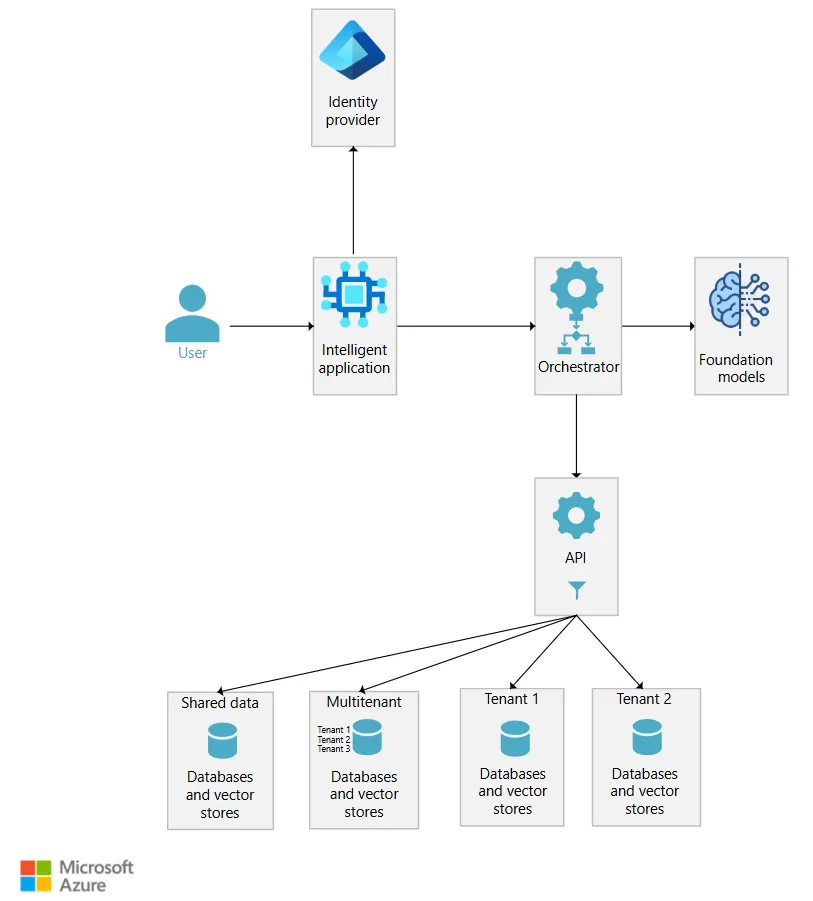
我们建议你在所用的存储机制前端部署一个应用程序编程接口(API)。该API如同守门人,能够确保用户仅能获取其经授权可访问的信息。
可通过以下方式限制用户对数据的访问权限:
-
用户所属租户。 -
平台功能。 -
自定义安全筛选或裁剪规则。
应用程序接口层应实现以下功能:
-
在单租户存储模型下,将查询路由至对应租户专属的存储节点。 -
在多租户存储模式中,仅筛选并返回当前用户所属租户的数据。 -
使用用户对应的合法身份信息,以支撑平台内置的授权验证逻辑。 -
执行自定义的安全过滤与权限裁剪逻辑。 -
存储基础信息的访问日志,用于审计追溯。
需要访问租户数据的代码不应直接查询后端存储。所有数据请求都应流经API层。该API层在租户数据之上提供了单一的治理或安全入口。此做法避免了租户和用户数据访问授权逻辑渗透到应用程序的其他区域。该逻辑被封装在API层中。这种封装让解决方案更易于验证和测试。
摘要
在设计多租户RAG推理解决方案时,必须考虑如何为租户构建基础数据解决方案的架构。需明确租户数量以及为每个租户存储的数据量,这些信息有助于设计数据多租户解决方案。我们建议实现一个API层,对数据访问逻辑进行封装,其中包含多租户逻辑与筛选逻辑。