 夜雨聆风
夜雨聆风





57、57、57!OpenAI、Google、Anthropic 史上首次在同一张榜单打平, 军备竞赛彻底变天了
【导读】Artificial Analysis 最新榜单给出了一个前所未有的画面:Claude Opus 4.7、GPT-5.4、Gemini 3.1 Pro 三大模型同时拿到 57 分,三巨头并列第一。精确分数只差 0.5 分,被置信区间直接吞掉。模型竞赛进入了一个新阶段,比较重点也覆盖到成本、幻觉率和 agent 稳定性。
三根一样高的柱子,震动了整个 AI 圈
4 月 19 日,科技博主 Theo 发了一条推文,只有一句话:
“For the first time ever, all three major labs are tied on Artificial Analysis”
「史上第一次,三大实验室在 Artificial Analysis 上打平了。」
配图更炸——Intelligence Index 的柱状图上,前三根柱子的高度完全一样,都写着 57。
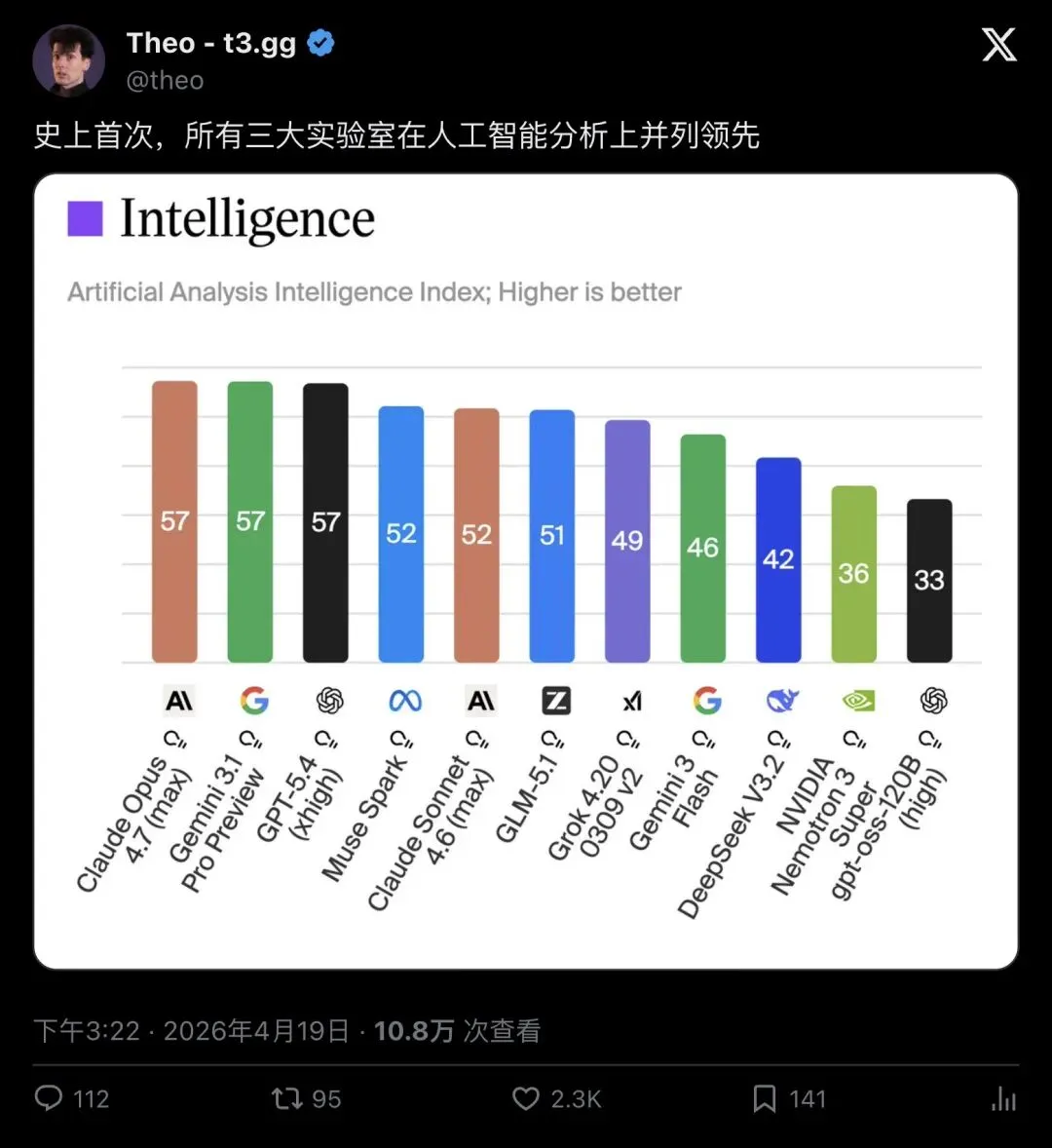
▲ Theo 的推文在 24 小时内收获 2300+ 点赞、10.8 万次浏览,成为当天 AI 圈传播最广的一条帖子
Claude Opus 4.7(Anthropic)、Gemini 3.1 Pro Preview(Google)、GPT-5.4 xhigh(OpenAI)——三家花了数十亿美元训练出的旗舰模型,在这张全球最被关注的独立 AI 评测榜上,第一次站到了同一个台阶上。
Theo 的厉害之处在于:他没有做任何原创发现,他做的事情只有一件——把一个埋在评测报告里的结构性变化,压缩成了一个社交媒体上谁都看得懂的判断句。
三大实验室。首次。打平。
这九个字,就够了。
Anthropic 的”追分大戏”:从落后 4 分到齐头并进
这次的新闻爆点,很多人以为是”第一次有人拿到 57 分”。
不对。
回看 3 月底的榜单,Google 的 Gemini 3.1 Pro Preview 和 OpenAI 的 GPT-5.4 早就已经拿到 57 了。当时 Anthropic 的 Claude Opus 4.6 只有53 分,落后整整 4 分。
也就是说,真正的故事线是:Anthropic 用一个版本的更新,把 4 分的差距一口气抹平了。
4 月 16 日,Anthropic 发布 Claude Opus 4.7。官方强调了三个核心升级:更强的软件工程能力、更好的视觉理解、在复杂多步骤工作流里更可靠。价格?不变,仍然是每百万 token 输入 $5、输出 $25。
同一天,Artificial Analysis 先放了一个信号弹——

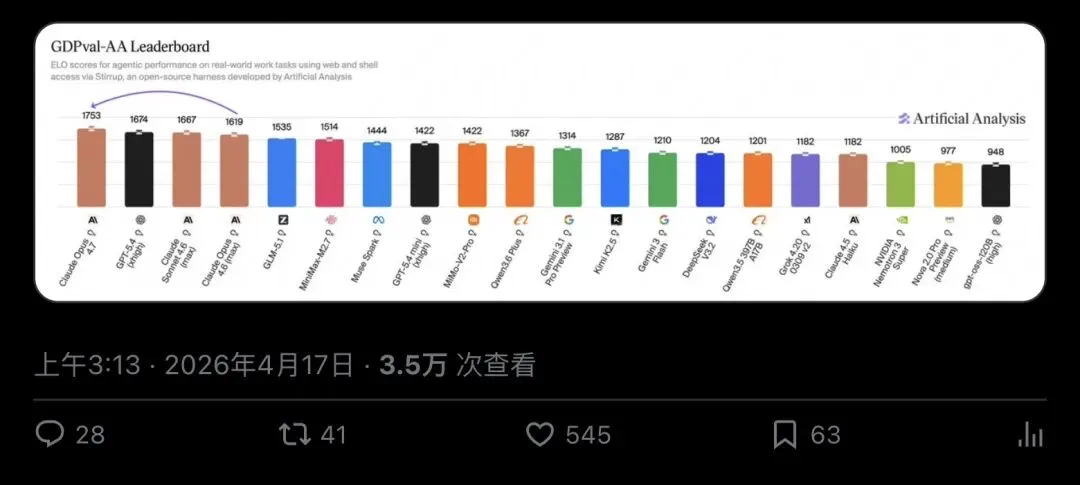
▲ Artificial Analysis 宣布 Opus 4.7 在 GDPval-AA(agentic 真实工作任务评测)上以 1753 Elo 登顶第一,超过 GPT-5.4 xhigh
这条推文传递的信号很明确:Anthropic 已经追到第一梯队,并在真实世界 agent 任务上拿到了领先位置。
“Artificial Analysis 历史上最大的一次并列”
4 月 18 日,靴子落地。
Artificial Analysis 官方发布长文,标题直白得不能再直白:《Opus 4.7: Everything you need to know》。
文章给出了整件事最关键的定性:
“This leads to the greatest tie in Artificial Analysis history: we now have the top three frontier labs in an equal first-place finish.”
「这带来了 Artificial Analysis 历史上最大的一次并列:三家前沿实验室并列第一。」




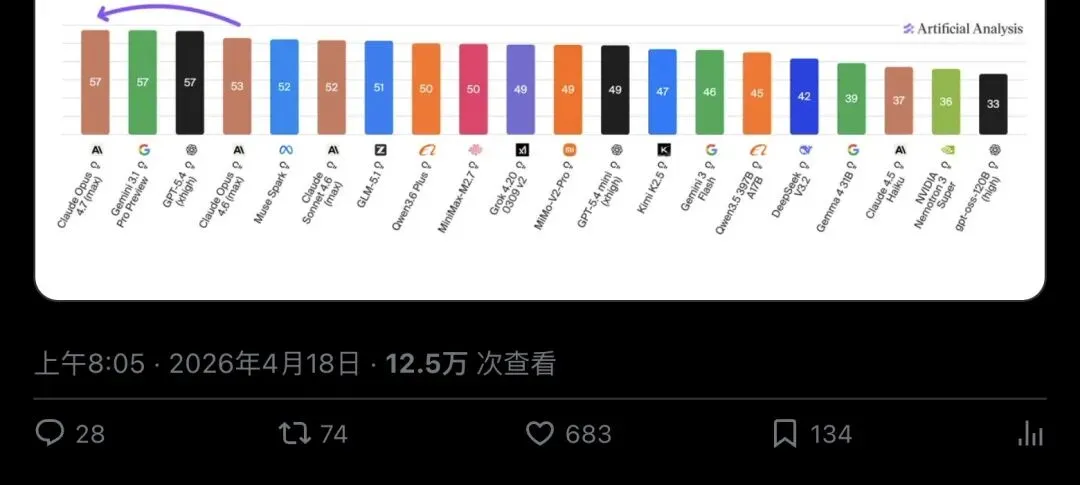
▲ Artificial Analysis 官方长推:详细列出了三家的精确分数、各自领先的子能力、以及 Opus 4.7 的效率提升
但紧接着,他们又补了一段极其重要的限定:
95% 置信区间为 ±1 分,榜单按整数展示。
精确分数其实是这样的:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
差距只有0.5 分,完全落在置信区间之内。
换句话说,榜单层面确实是并列第一,精确分数层面仍有极窄差异,这个差异已经小到没有明显统计意义。
这也让整件事变得更有意思,技术上还有小数点后面的较量,传播上则已经很难再靠一个总分明显拉开对手。
总分打平的背后:三家各自为王
如果只看”57 对 57 对 57″,你会以为三家模型已经没什么区别了。
大错特错。
Artificial Analysis 同时给出了一张更值得研究的分工地图:
Anthropic 领先真实世界 agent 任务。在 GDPval-AA(模拟 44 个职业、9 个行业的真实工作)上,Opus 4.7 以 1753 Elo 排名第一。
Google 领先知识与科学推理。在 HLE(Humanity’s Last Exam)、GPQA Diamond(博士级科学题)、SciCode(科学编程)、AA-Omniscience(事实知识 + 抗幻觉)等多项测试上,Gemini 3.1 Pro 占据优势。
OpenAI 领先长程编程与部分科学推理。在 TerminalBench Hard(终端工程任务)、CritPt(研究级物理推理)、AA-LCR(长上下文推理)上,GPT-5.4 表现最强。
可以看到,总分相同的同时,子能力分布更加分化。前沿模型的比较重点,也落到了不同真实场景里的表现。
更少 token、更少幻觉、更低成本——新阶段的胜负手
Opus 4.7 身上还藏着一组被低估的数字。
与前代 Opus 4.6 相比,Opus 4.7 的输出 token 使用量减少了约35%,Intelligence Index 仍然高了 4 分。跑完整套评测的成本约 $4,406,比 Opus 4.6 的 $4,970 低了大约11%。
更值得关注的是幻觉率的变化:从 Opus 4.6 的61%降到了36%。
降幻觉的方式也很有意思——Opus 4.7 变得更会说”我不确定”,而非硬编一个看似合理的答案。
用更少的 token,干更准的活,犯更少的错。
这组数字指向一个清晰的趋势:下一轮模型竞赛的关键指标,会同时包括总分、成本、稳定性和幻觉控制。
“最便宜的 Gemini 打平了最贵的 Claude”
开发者社区的反应最为直接。
一位名叫 Sahil 的独立开发者在 Theo 的推文下留言:
“Gemini 3.1 pro preview being the cheapest and still a tie with most expensive claude”
「Gemini 3.1 Pro Preview 明明最便宜,却还能和最贵的 Claude 打平。」
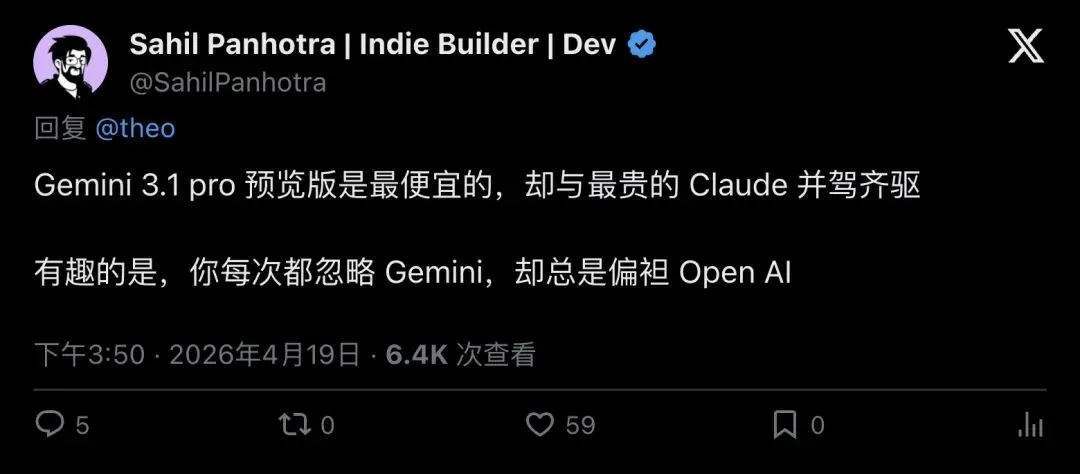
▲ 开发者 Sahil 的评论直击痛点:总分一样的情况下,谁更便宜谁就赢了
这条评论戳中了很多人的想法。看一组成本数据就明白了:
-
跑完整套 Artificial Analysis 评测,Gemini 3.1 Pro 花了约 $892 -
GPT-5.4 花了约$2,851 -
Claude Opus 4.7 花了约$4,406
同样的 57 分,成本差了将近5 倍。
当然,这里有个细节:Opus 4.7 的评测 token 消耗量最大(约 1.02 亿 token),因为它在推理模式下会生成大量思考 token。而 Gemini 只用了 5700 万 token。所以成本差异很大一部分来自架构和推理策略的不同。
对于真金白银付 API 账单的开发者来说,结论也很直接:在总分接近的情况下,成本就是一个核心变量。
当差距只剩小数点,评测本身也开始被审视
还有一个值得关注的声音。
沃顿商学院教授 Ethan Mollick——AI 领域最有影响力的学者型传播者之一——转发了这条新闻,但附上了一段尖锐的评论:
“I think Artificial Analysis does a good job overall and provides transparency in benchmarking, but GDPval-AA is not a good benchmark and needs to stop being reported.”
「我认为 Artificial Analysis 整体做得不错,也足够透明。但 GDPval-AA 不是一个好的 benchmark,不该继续这样被报道。」
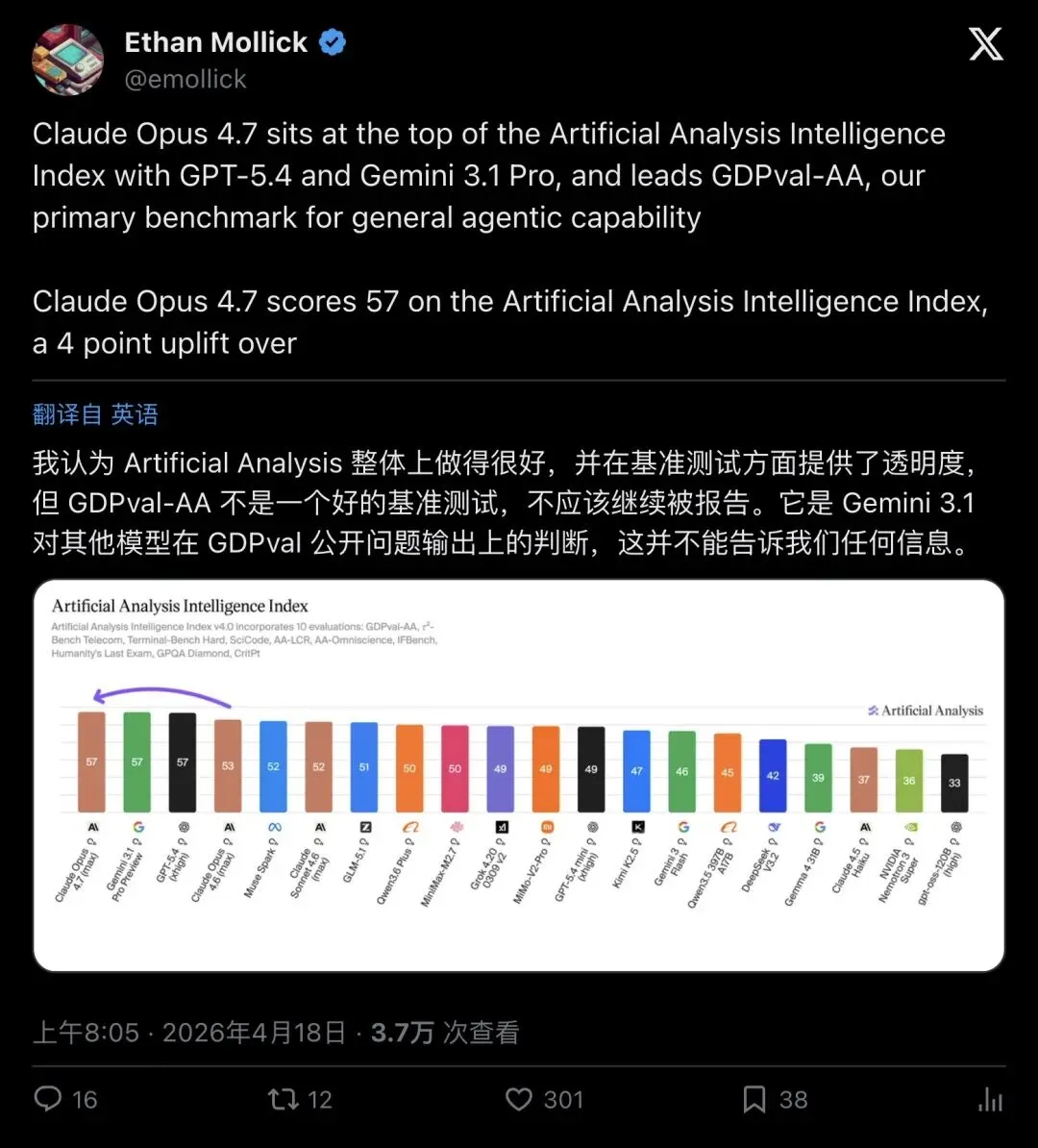
▲ Ethan Mollick 直言:GDPval-AA 用 Gemini 3.1 作为裁判模型来评判其他模型的输出,这个设计存在问题
他的核心质疑是:GDPval-AA 用 Gemini 3.1 来给其他模型打分,这相当于让一个参赛选手同时当裁判。
这个质疑本身不意味着 Artificial Analysis 的榜单就不可信,同时也提醒大家:当三家差距只剩下小数点和评测设计时,评测方法本身也会成为讨论焦点。
Hacker News 上 Anthropic 发布页下的讨论也印证了这个方向。社区讨论的焦点已经从“谁多了 0.3 分”挪开了,大家更关心安全限制是否会削弱真实使用场景、frontier 模型在工程工作流里的可靠性有没有真正跃迁、agent 和工具调用到底到了什么程度。
今天最核心的问题,已经落在“谁更适合真实工作”上。
模型竞赛仍在继续,关注点已经换到新赛道
让我们把视野拉远一点。
为什么三大实验室会在 2026 年进入”拉不开差距”的阶段?
第一,训练范式趋同。头部实验室都在拼更强的预训练、后训练、推理模式和 agent loop,大家用的技术路线越来越像。
第二,综合榜单已经高位拥挤。3 月的顶部分布是 57/57/53,4 月变成了 57/57/57。分数走势明显在收敛,没有继续分化。
第三,用户的关注点已经迁移。开发者开始同时问“哪个模型最聪明”“哪个模型做 agent 最稳”“哪个幻觉最少”“哪个性价比最高”。
Artificial Analysis 的这张榜单,恰好成了这个转折点的历史截面。
57、57、57——这三个数字真正说明的,是顶层智力越来越接近之后,决定差距的会更多落在 agent 能力、成本效率、幻觉控制和真实工作流体验上。
模型竞赛远没有结束。
从今天开始,跑道已经不同了。
— END —