 夜雨聆风
夜雨聆风





智能全文解析,将文档转化为有价值的数据
凭借专利级别的版面分析技术,精准识别30余个标签,将非结构化文档转换为结构化数据,实现文档到数据的飞跃。
支持多种文档标签信息提取
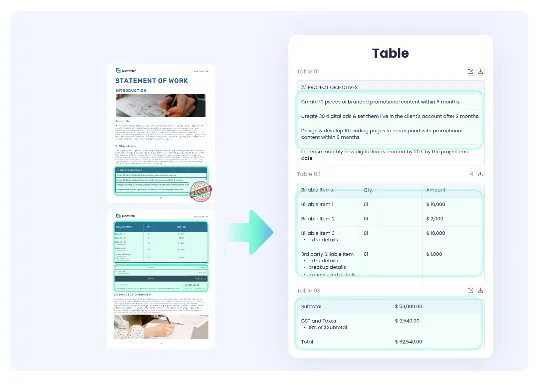
-
精准识别PDF和图片中的表头及位置元素。
-
支持规则及不规则表格结构,包括合并单元格。
-
提供多平台SDK,支持Windows、Mac、Linux、.NET和Java。
-
表格识别准确率超过99%。
-
支持GPU和CPU环境,实现灵活部署。

-
从图片或扫描文档中提取文本,转换为结构化数据。
-
支持80多种语言,包括中文、英文、泰文、韩文等。
-
高速处理能力:每小时最高可处理100万份文档。
-
提供多平台SDK,支持Windows、Mac、Linux、.NET及Java。
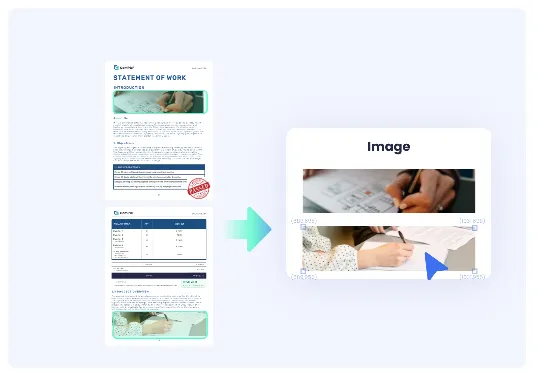
-
从PDF文档中提取图像,可提取整页或嵌入插图。
-
精准捕捉图像坐标,支持PNG、JPG和JSON格式输出。
-
支持将图像导出为URL或Base64编码数据。
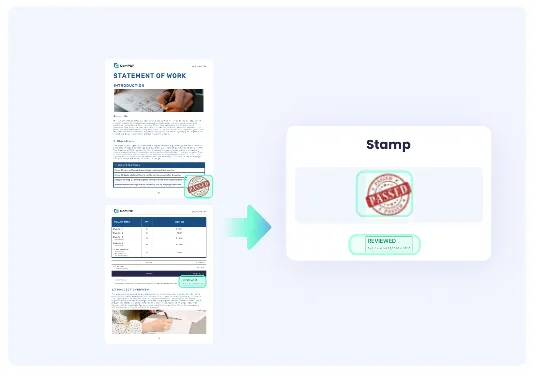
-
精准提取文件中各种类型和颜色的印章,包括方形、圆形、椭圆形,及红色、蓝色、黑色等颜色。
-
捕捉印章的位置和坐标数据,便于后续分析与处理。
-
高速处理能力:每小时最高可处理100万份文档。
为大模型训练提供高质量数据
智能地将 PDF 或图像等非结构化文档转换为用于 LLM 训练的结构化数据,并以 TXT、JSON、XML、Excel 等格式导出。自动清理、验证和可自定义的模型确保高质量,并可灵活部署。
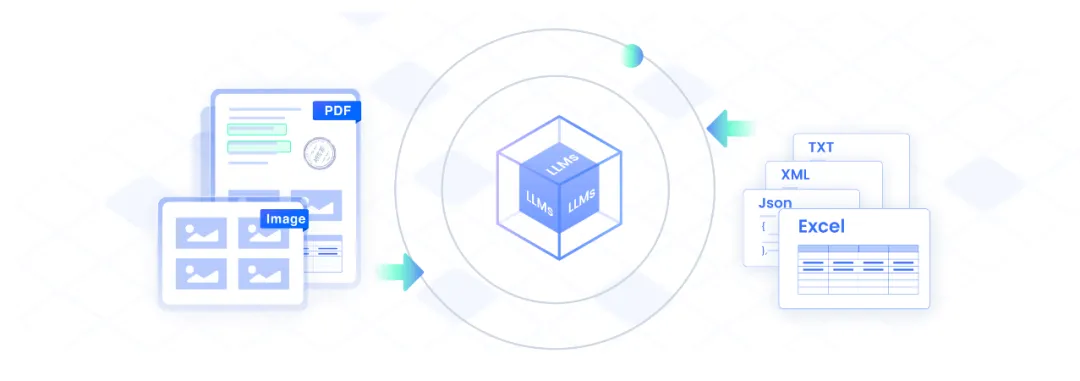
多种部署方式
私有化部署
支持在本地环境中批量处理文档,包括删除、添加水印、提取数据等操作,提供 Java 和 .NET 库,兼容 Linux、Windows 和 macOS 系统,增强隐私控制与数据安全。
离线 SDK
将功能丰富的本地SDK无缝集成到您的应用或系统中,包括查看、标记、编辑、签名、转换和数据提取等功能,满足不同场景下的文档处理需求。
在线API/ 低代码
提供高性能 API 与低代码解决方案,智能处理来自任何平台的文档,打破平台与服务器限制,赋能开发者高效创新。

END
公司名称:北京哲想软件有限公司
北京哲想软件官方网站:cogitosoft.com
北京哲想软件微信公众平台账号:cogitosoftware
北京哲想软件微博:哲想软件
北京哲想软件邮箱:sales@cogitosoft.com
销售(俞先生)联系方式:+86(010)68421378
微信:18610247936 QQ:368531638
