当前时间: 2026-04-21 09:25:12
更新时间: 2026-04-21
分类:软件教程
评论(0)
AI漫剧
最近特别喜欢看AI漫剧,脑子一丢,就是看 今天来跟大家聊一聊AI漫剧。它的画风像动漫,节奏像短剧,一集一两分钟,讲的是修仙逆袭、末世求生或者战神归来的爽快故事。过去一年里最野蛮生长的新内容形态。2026年1月,国内单月上线的AI漫剧数量达到了14634部,相当于每天有470多部新剧问世。市场规模在2025年已经突破200亿元,预计2026年将冲到220亿。一个几乎”无中生有”的赛道,用十二个月时间走完了传统内容行业十年的路。
它到底是什么?怎么做出来的?为什么现在才出现?又有哪些解决不了的”硬伤”?这篇文章会带你拆解清楚。
今天来跟大家聊一聊AI漫剧。它的画风像动漫,节奏像短剧,一集一两分钟,讲的是修仙逆袭、末世求生或者战神归来的爽快故事。过去一年里最野蛮生长的新内容形态。2026年1月,国内单月上线的AI漫剧数量达到了14634部,相当于每天有470多部新剧问世。市场规模在2025年已经突破200亿元,预计2026年将冲到220亿。一个几乎”无中生有”的赛道,用十二个月时间走完了传统内容行业十年的路。
它到底是什么?怎么做出来的?为什么现在才出现?又有哪些解决不了的”硬伤”?这篇文章会带你拆解清楚。
一、AI漫剧到底是什么
简单说,AI漫剧就是用人工智能把网文、漫画或原创故事变成动态视频。每集时长1到5分钟,节奏快、情节密度高,适合碎片化观看。
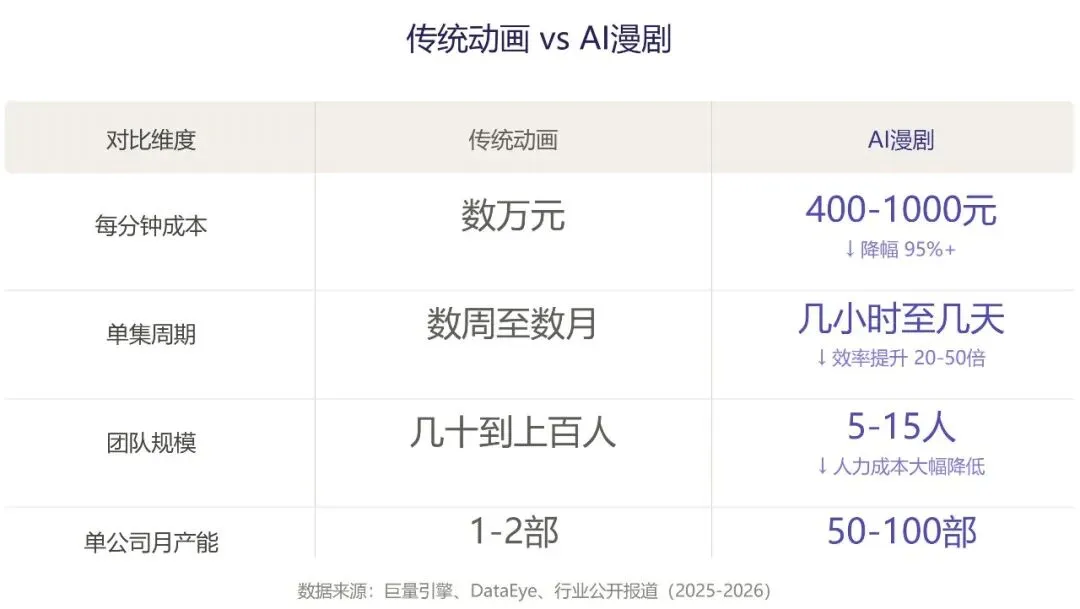
它和传统动画最大的区别是:传统动画是一帧一帧画出来的,AI漫剧是一张一张生成出来的。一部《你的名字》需要上百个动画师花几年时间绘制几万张原画,一部AI漫剧只需要十几个人用20天做50集——成本从传统动画的每分钟数万元,降到现在的每分钟几百元。
它也不同于我们熟悉的真人短剧。真人短剧要演员、要场地、要服化道,哪怕再省也省不掉这些。AI漫剧全程在电脑里完成,连”拍摄”这个动作都不存在。快手的数据显示,AI漫剧的付费用户中有六成是短剧触达不到的新增用户——二者其实不是替代关系,而是在吸引不同的受众。
AI漫剧的主流题材高度集中:修仙逆袭、末世求生、战神归来、穿越架空、复仇打脸……你会发现它们和网文的热门品类几乎完全重合。这不是偶然——AI漫剧最核心的商业逻辑,就是把海量存量网文IP用最低成本视觉化。一个网文作者写了十年的书,可能从没被改编过;但做成一部AI漫剧,只需要15万元预算和二十多天时间。
二、一部AI漫剧是怎么做出来的
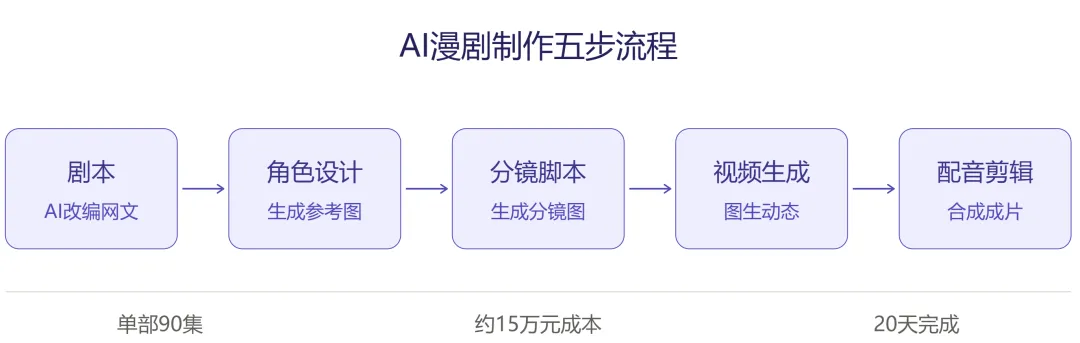
AI漫剧的制作流程已经相当工业化,基本可以拆成五个阶段。我们跟着一部假想的《战神归来》走一遍。
第一步:剧本。制作方拿到一本网文的IP授权后,先用大模型(比如DeepSeek、豆包)把几十万字的小说压缩、改编成90集的分集剧本,每集大约1000字。AI在这里主要干两件事:提炼爽点、切分集数、写对白。现在市场上一个好剧本能卖到10万元以上——人类编剧依然稀缺,但”复述和压缩”这种体力活AI干得飞快。
第二步:角色设计。这是整条流程最关键的一步。制作方先用AI生图工具(即梦、Midjourney、Nano Banana等)生成主角的3-5张参考图,包括正面、侧面、不同表情。这些参考图要在后续所有镜头里反复被调用,确保主角”不会变脸”。这听起来简单,但恰恰是AI漫剧最常翻车的地方——我们后面会讲。
第三步:分镜脚本。把每集剧本拆成15-25个镜头,每个镜头标注景别(远景/近景/特写)、人物动作、情绪状态和场景。然后根据这些文字描述,批量生成静态的分镜图片。这个阶段输出的其实是一本”可视化小人书”——所有画面都已经定好了,只差让它们动起来。
第四步:视频生成。这是技术含量最高的一步。把分镜图片喂给视频生成大模型(可灵、海螺、Seedance、Sora等),让AI根据静态图生成3-10秒的动态视频片段。比如一张”主角拔剑”的静态图,AI会自动补出拔剑的完整动作过程。这一步吃算力、费钱,也最容易出”AI味”。
第五步:配音剪辑。AI自动识别每句台词的说话人、情绪,匹配合适的声线配音。然后在剪辑软件里把所有片段拼起来,加背景音乐、音效、字幕,最后导出成片。
这五个阶段现在正在被进一步”打包”。一些平台(360纳米、Seko、幻舟AI等)已经把五步合成一个”智能体”,用户只需要提供一个故事方向,AI自动从剧本写到成片输出。业内管这个叫”一键成片”,单集制作时间从几天压缩到了30到60分钟。
三、技术原理:AI究竟是怎么”画”出一部片子的
要理解AI漫剧为什么是这几年才可能出现的,得先理解背后的两项关键技术:扩散模型和视频大模型。
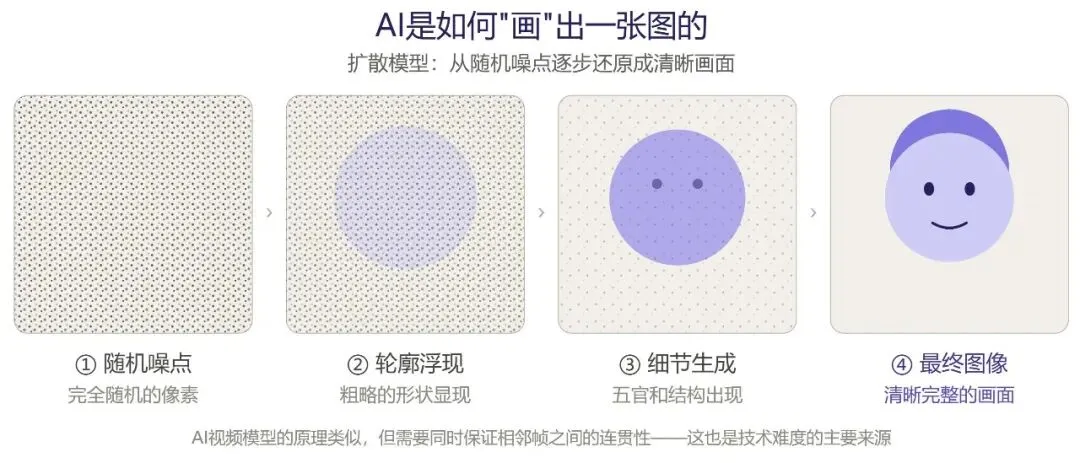
现在主流的AI生图(和生视频)用的是一种叫”扩散模型”的技术。打个比方:你有一张清晰的照片,把它泡在水里搅一搅,像素开始模糊;再搅,完全变成一团噪点。扩散模型做的事情是反过来——给它一团随机噪点,它一步步”去噪”,最后还原出一张清晰的图片。训练的时候,模型看过几十亿张图片和对应的文字描述,学到了”当你给我’少女在樱花树下’这样的描述时,应该从噪点里收敛到什么样的画面”。
视频生成是这个逻辑的延伸,但难度陡增。图片只需要考虑空间信息(每个像素点之间的关系),视频还要考虑时间信息——相邻帧之间必须连贯,一个人在第一帧抬手,第二帧就不能凭空跑到画面另一边。这就是为什么文生视频的技术成熟比文生图晚了差不多两年。
2025年下半年是一个关键节点。字节的Seedance、快手的可灵、谷歌的Veo、OpenAI的Sora 2等一批视频模型集中突破了5-10秒的稳定生成,画面连贯性大幅提升。更关键的是,这些模型开始支持”参考图输入”——你给它一张角色设计图,它能在生成视频时尽量保持这个角色的脸和衣服不变。没有这项能力,AI漫剧根本不成立:主角每集换一张脸,观众根本看不下去。
还有一项同样关键的技术:首尾帧生视频。给模型两张图片——一张是片段的起始画面,一张是结束画面,模型负责生成中间的过渡。这个能力让AI漫剧的”剪辑”变得可能:制作者可以精确控制每个镜头怎么开始、怎么结束,不再完全依赖AI的”即兴发挥”。
所以AI漫剧不是某一天突然冒出来的,它是多项底层技术同时跨过某条门槛之后的必然产物——就像短视频需要4G普及才能兴起一样。
四、为什么AI漫剧总有股”AI味”
看过几部AI漫剧的人都会有种说不清的感觉:画面好像是精美的,但就是”不太对”。这种”AI味”的来源,恰恰暴露了当前技术的边界。
人脸会悄悄漂移。同一个角色在不同镜头里,眼距、鼻梁、下巴的弧度会有微妙变化。原因在于,AI并不像人类一样”记住”这个角色长什么样——它每次生成都是基于参考图重新推理,中间的不确定性累积起来,就会出现”上一秒丹凤眼,下一秒铜铃眼”。从业者管这叫”崩脸”。
手部是重灾区。AI画手出名地差——六根手指、融合的手掌、反向弯折的指关节,都是常见现象。这是因为手的拓扑结构复杂,训练数据里手的姿态极其多样,模型很难稳定渲染。漫剧里你会发现主角很少特写手部,或者手部出现时都是静止的——这其实是制作者在规避模型的弱点。
物理逻辑经常出错。一杯茶放在桌上,镜头一切,杯子变了形状;人物的影子在不同镜头朝不同方向;雨水打在身上但衣服是干的。AI并不真正理解”物体存在”和”物理规律”,它只是在渲染”看起来像”的画面。这种现象在学术上叫”缺乏物体恒常性”——这是AI相对于人类认知的一个根本差距。
画面里的文字全是乱码。任何书本、路牌、招牌、聊天界面,那些”汉字”仔细看根本不成字。这是因为AI学会的是”汉字的视觉模式”,不是真正会写字。制作者通常用后期手动贴字来解决。
动作断档、表情僵硬。AI视频模型目前稳定生成的时长只有5-10秒,所以漫剧里几乎没有长镜头——一个挥剑动作会被拆成”举剑→眼神特写→刀光→敌人倒地”四个独立片段,每段3秒以内,靠快速切镜头和音效掩盖断档。人物表情则普遍缺乏微表情——真人说话时眼皮的频率、嘴角的小抽动、身体的重心微调,这些都是AI很难模拟的。所以你会觉得角色像”能动的手办”,而不是活人。
同质化严重。不同漫剧的主角长得惊人地相似,画风、光效、配色也大同小异。根源是大家用的是同一批模型、同一套提示词模板。中国传媒大学教授赵晖分析过:模型的训练数据集中在少数热门审美,创作者又倾向于”打安全牌”——偏离爆款数据就意味着放弃流量。最终形成了一个同质化的循环。
这些问题的本质是一样的:AI不”理解”画面里的东西,它只是用统计规律拼凑像素。要让一个角色在100个镜头里完全一致,需要模型具备类似”工作记忆”的能力,而这已经超出了当前主流视频模型的设计框架。
五、下一步会怎样
AI漫剧是一个典型的技术驱动型产业。它的上限,几乎完全取决于底层视频大模型的进化速度。
短期内(1-2年),我们大概率会看到三件事:稳定生成时长从10秒延长到1分钟以上;角色一致性接近完美,”崩脸”问题基本解决;口型同步和情绪表达更自然。这些都是各大模型厂商正在攻关的方向。
中期(3-5年),AI漫剧可能会和传统动画的界限模糊。当AI能生成画质不输手绘、动作流畅自然的动画时,”AI漫剧”这个品类本身可能消失——它会变成动画产业的一个新生产范式,而不是一个独立的内容类型。届时受冲击最大的,可能是成本在中游的2D动画公司。
长期来看,这场变革真正的意义或许是创作权力的下移。过去做动画需要团队、资金、技术壁垒,是少数人的专利。当工具门槛降到一个人一台电脑能做一部片子,内容产业会涌入大量此前被拦在门外的创作者——他们中的绝大多数会做出平庸作品,但也会有极少数人做出真正独特的东西。短视频平台已经证明了这个规律:降低工具门槛总会释放出一批意想不到的才华。
当然,这条路上有真实的争议。AI生成的形象和真人撞脸引发的肖像权纠纷、训练数据中未授权IP引发的版权问题、大量同质化内容挤压真人短剧和传统动画的生存空间——这些问题还没有成熟的答案。2026年4月起,中国广电总局已明确将动漫微短剧纳入”先审后播”的管理范畴,监管正在收紧。
无论如何,AI漫剧已经证明了一件事:内容生产的成本结构可以被AI从根本上改写。它今天看起来粗糙、雷同、漏洞百出,但这恰恰是一个新物种的早期形态。回头看,我们现在正在经历的,可能就是动画史上某个重要章节的开头。
 夜雨聆风
夜雨聆风