 夜雨聆风
夜雨聆风





R软件:累计Meta分析实操指南,小白也能轻松上手

哈喽,做Meta分析的科研小伙伴们集合啦✨
是不是每次纳入十几篇、几十篇研究后,都会陷入这样的迷茫:
✅ 随着研究一篇篇新增,合并效应量到底在怎么变?
✅ 十几篇研究里,哪篇才是影响最终结果的“关键选手”?
✅ 早期研究和后期研究的结论一致吗?会不会出现结论反转?
其实不用慌!这些让人头疼的问题,「累计Meta分析」就能一次性解决~
很多小伙伴做Meta分析,只停留在“一次性合并所有研究”的传统操作上,却忽略了累计Meta分析的核心价值——它能动态展示“证据累积”的全过程,让你的Meta分析结论更稳定、更有说服力,投稿时也能更受审稿人青睐。
今天就手把手教大家,用R软件快速实现累计Meta分析,全程代码可直接复制粘贴,不用懂复杂编程,小白看完就能上手实操,赶紧码住!
先搞懂:什么是累计Meta分析?(2分钟入门,不踩坑)
在开始敲代码前,先花2分钟搞懂核心概念,避免盲目套代码做无用功,也能更好地解读后续结果。
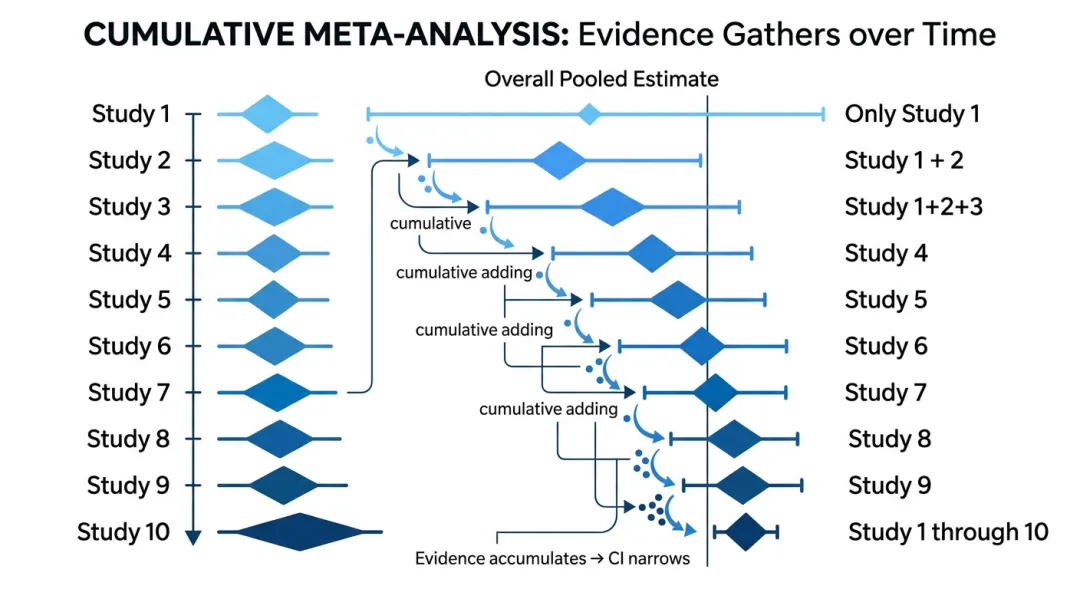
累计Meta分析(Cumulative Meta-Analysis),说通俗点就是「逐步纳入、逐步合并」的分析方法——按照一定顺序(最常用的是研究发表年份,也可以是样本量大小、研究质量高低),每次新增一篇研究,就重新做一次Meta分析,最终得到一系列动态的合并效应量及置信区间。
举个超直观的例子:
你纳入了10篇关于“某药物治疗高血压”的研究,按发表年份从早到晚排序,先合并第1篇的结果,再加入第2篇重新合并,接着加入第3篇……直到合并完所有10篇。
这样一步步操作下来,你就能清晰看到:随着研究证据的不断累积,药物的疗效结论(合并效应量)是逐渐稳定,还是出现了明显反转;也能快速发现,哪一篇研究加入后,结果发生了显著变化。
这里必须划重点,区分两个易混淆的概念👇
传统Meta分析:一次性合并所有研究,只给出一个最终的合并结果,无法体现证据的动态变化;
累计Meta分析:逐步合并、动态展示,和传统Meta分析方法本质一致,但能提供更多证据演变的信息,是传统Meta分析的重要补充,尤其适合纳入研究较多、时间跨度较大的课题,能有效提升结论的可信度。
而它的核心价值,总结起来就3点,记好啦:
① 判断结果稳定性:看新增研究是否会改变原有结论,避免单一研究的干扰;
② 识别关键研究:快速找到对合并结果贡献最大(或干扰最大)的研究,方便后续敏感性分析;
③ 增强结论说服力:动态展示证据累积过程,让审稿人清晰看到你的分析逻辑,减少质疑。
实操准备:R软件+必备包(一步到位,无需手动操作)
首先要确保你的电脑上已经安装了R软件(或RStudio,更推荐后者,操作更便捷),如果还没安装,直接去R语言官方网站(www.r-project.org/)下载,傻瓜式安装即可,全程下一步就好。
安装完成后,我们只需要准备2个核心包,就能完成累计Meta分析,无需额外安装其他冗余包。下面的代码直接复制粘贴到RStudio的控制台,按回车就能自动安装+加载,小白也能轻松操作👇
# 安装必备包(首次安装需运行,后续无需重复安装)install.packages(c("metafor", "meta"))# 加载必备包(每次打开R软件,都需要运行这行代码)library(metafor)library(meta)
⚠️ 小提醒:如果安装过程中出现“报错”,大概率是网络问题,建议切换网络后重新运行代码;如果提示“是否更新包”,直接按回车默认“否”即可,避免更新后出现版本不兼容的问题。
核心实操:3步完成累计Meta分析(代码可直接复制)
实操部分我们分3步走,全程围绕“数据准备→累计合并分析→结果解读”,每一步都配好可复制代码,还有详细说明,不用担心看不懂。
第一步:准备数据(关键!格式一定要对)
首先我们需要准备Meta分析的原始数据,这里给大家提供一个标准化的数据格式(以二分类数据为例,比如“有效/无效”“患病/未患病”),大家可以直接替换成自己的研究数据。
数据需要包含以下6列(缺一不可),建议用Excel整理好,再导入R软件:
① study:研究名称(比如“张三2020”“李四2022”,方便后续识别);
② year:研究发表年份(用于按年份排序,这是累计Meta分析最常用的排序方式);
③ n1:试验组样本量;
④ e1:试验组事件数(比如有效人数、患病人数);
⑤ n2:对照组样本量;
⑥ e2:对照组事件数。
下面给大家一个示例数据,大家可以直接复制代码运行,先熟悉流程,再替换成自己的数据👇
# 示例数据(直接复制运行,无需修改)data <- data.frame(study = c("Study1", "Study2", "Study3", "Study4", "Study5"),year = c(2018, 2019, 2020, 2021, 2022),n1 = c(50, 60, 70, 80, 90),e1 = c(40, 48, 56, 68, 76),n2 = c(50, 60, 70, 80, 90),e2 = c(25, 30, 35, 40, 45))# 查看数据(确认数据格式正确,无缺失值)View(data)
运行后会弹出数据查看窗口,大家可以检查一下数据是否完整,没有缺失值、没有格式错误,确认无误后,进入下一步。
第二步:按顺序排序(累计分析的核心前提)
累计Meta分析的关键,是“逐步纳入”,所以我们需要先将研究按指定顺序排序,最常用的就是按「发表年份」排序(从早到晚),代码如下,直接复制运行即可:
# 按发表年份从早到晚排序(核心代码)data_sort <- data[order(data$year), ]# 查看排序后的数据print(data_sort)
运行后,控制台会显示排序后的研究列表,从最早发表的研究到最新发表的研究,这样后续就能逐步纳入、逐步合并了。
⚠️ 补充说明:如果大家想按“样本量大小”“研究质量”排序,只需要将代码中的“year”替换成对应的列名即可(比如样本量列名是n,就替换成data$n)。
第三步:运行累计Meta分析,生成结果
这一步是核心,代码直接复制粘贴,无需修改(如果你的数据列名和示例一致),运行后就能得到累计Meta分析的结果和图表👇
# 第一步:计算效应量(二分类数据用OR值,连续数据可修改参数)res <- metabin(e1, n1, e2, n2, data = data_sort,studlab = study, sm = "OR", # sm="OR"表示效应量为OR值method = "MH", # 合并方法用Mantel-Haenszel法,最常用fixed = FALSE, random = TRUE) # 采用随机效应模型,更贴合实际研究# 第二步:运行累计Meta分析(按排序顺序逐步合并)cum_res <- cummeta(res, order = data_sort$year)# 第三步:查看累计分析结果print(cum_res)# 第四步:绘制累计Meta分析森林图(核心图表,直观展示动态变化)forest(cum_res,xlab = "OR值(95%CI)", # 横轴标签main = "累计Meta分析森林图", # 图表标题col = "black", # 线条颜色lwd = 1.2) # 线条粗细
运行完成后,会出现两个关键结果:一是控制台的文字结果,二是弹出的森林图,这两个部分我们下面重点解读。
关键解读:结果怎么看?小白也能看懂
很多小伙伴做完分析,看着一堆结果不知道怎么解读,其实重点看2个部分:文字结果+森林图,轻松get核心信息。
1. 文字结果解读(重点看3点)
控制台输出的文字结果中,重点关注以下3点,就能判断结果的稳定性和可靠性:
① 每一步的合并OR值及95%CI:随着研究逐步纳入,OR值是否逐渐稳定(比如从1.8逐渐波动到1.78,不再大幅变化);
② 异质性检验(I²值):如果I²<50%,说明研究间异质性较小,结果更稳定;如果I²≥50%,建议后续做敏感性分析(后面会补充);
③ P值:如果每一步的P值都<0.05,说明合并结果有统计学意义;如果某一步P值>0.05,说明该步纳入研究后,结论发生了反转,需要重点关注该研究。
2. 森林图解读(最直观,重点看趋势)
累计Meta分析的森林图,是动态展示证据累积的核心,解读起来很简单:
① 横轴为OR值(或其他效应量),竖线为OR=1的线(竖线左侧表示试验组优于对照组,右侧表示对照组优于试验组);
② 每一行代表一个研究,后面的横线是该研究的95%CI,如果横线不跨越竖线,说明该研究结果有统计学意义;
③ 最下方的“Cumulative”行,是每一步累计合并的结果,随着研究逐步纳入,这一行的横线会逐渐变窄(说明置信区间变窄,结果更稳定),如果横线始终不跨越竖线,说明结论稳定,没有反转。
小白避坑指南+实用技巧(投稿加分项)
结合很多小伙伴的实操经验,整理了3个高频坑和实用技巧,帮大家少走弯路,还能让分析结果更规范,投稿时更有优势👇
✅ 坑1:数据格式错误,导致分析失败
解决方法:严格按照前面的格式准备数据,列名不要乱改(比如不要把“n1”改成“试验组样本量”),避免缺失值,Excel整理后保存为CSV格式,再导入R软件更稳妥。
✅ 坑2:混淆固定效应模型和随机效应模型
解决方法:大多数Meta分析(包括累计Meta)都建议用随机效应模型(代码中fixed=FALSE, random=TRUE),因为它能考虑研究间的异质性,更贴合实际科研情况;只有当研究间异质性极低(I²<25%)时,才考虑用固定效应模型。
✅ 坑3:做完累计分析,没有做敏感性分析
解决方法:如果某篇研究纳入后,合并结果发生显著变化(比如P值从<0.05变成>0.05),需要将该研究剔除,重新做累计分析,对比前后结果,这就是敏感性分析,能提升结论的可靠性,投稿时审稿人很看重这一点。
💡 实用技巧:如果想让森林图更美观,适合插入论文或汇报,可以在forest()函数中添加更多参数(比如修改颜色、字体大小),后续可以留言,给大家补充美化代码。
最后总结
其实累计Meta分析并没有大家想象的那么复杂,核心就是“逐步纳入、动态展示”,用R软件操作,全程代码可复制,小白也能轻松上手。
它不仅能解决“结果稳定性”“关键研究识别”的问题,还能让你的Meta分析更有深度,投稿时更易通过审稿,尤其适合纳入研究较多、时间跨度较大的课题。