 夜雨聆风
夜雨聆风





深势发布AI科学文档解析引擎Uni-Parser:超5000万文献数据验证,分子、公式、复杂表格秒变结构化数据


什么是
Uni-Parser
Uni-Parser 解析能力示例

工业级
解析效率

首创层级化
版面理解
-
图文绑定(figure-caption, table-title绑定)
-
分子 ID 与分子结构精准匹配 (molecule-identifier 绑定)
-
子图层级关系建模 (subfigure-figure 层级关系建模)
-
多层嵌套结构(subfigure/table-in-figure/molecule-in-table)统一建模
该能力显著区别于现有通用 OCR/MLLM-based 方法,这些方法普遍难以处理复杂的跨层级嵌套结构与一致性绑定问题。相比之下,Uni-Parser 在此类高复杂度科学文档中能够实现端到端的结构恢复,不仅提升了整体解析的完整性,也带来了更好的阅读顺序重建能力,并支持通过 figure 序号与分子 ID 进行高效检索与定位,具备更好的可解释性。
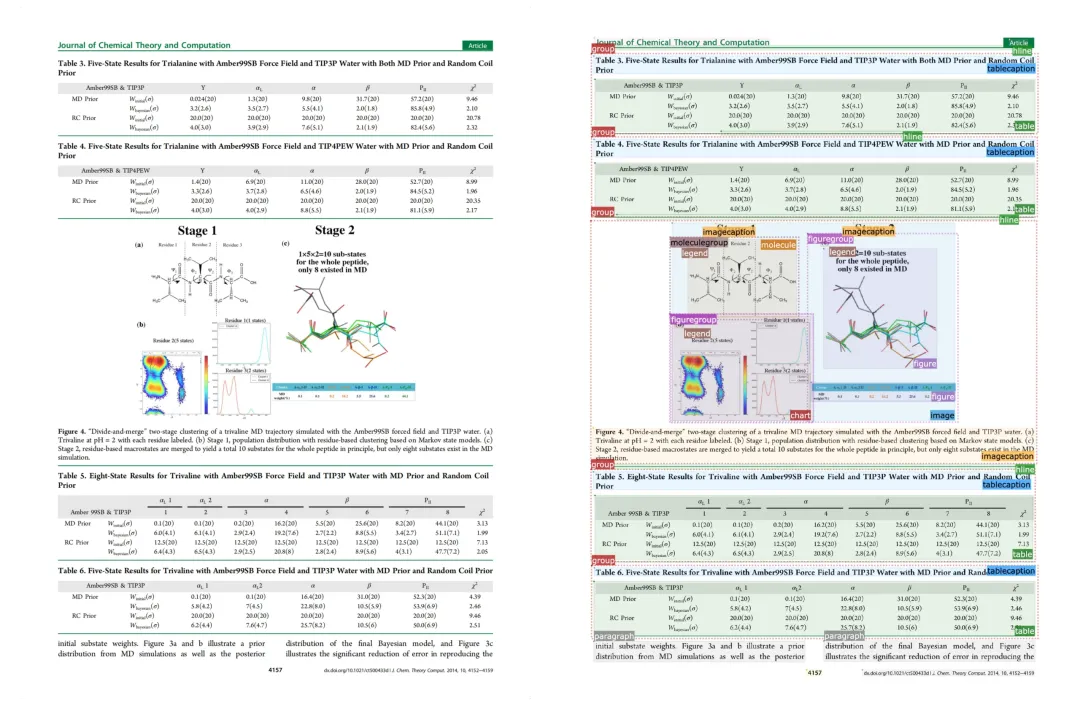
上图:带有层级结构的复杂版面布局解析

上图:科学论文中的复杂阅读顺序重建

高精度
化学结构识别
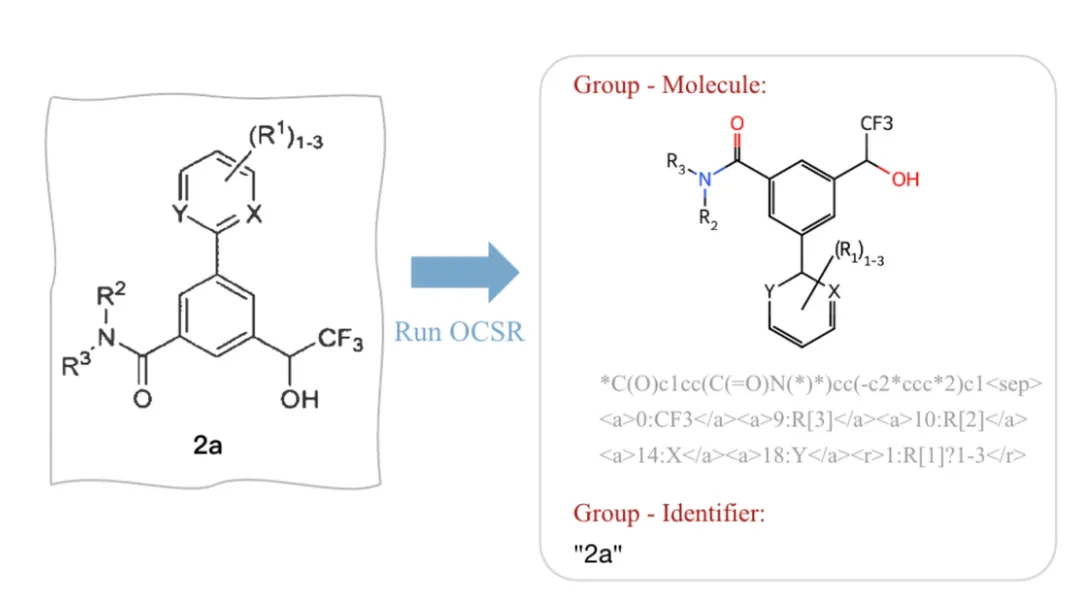
上图:分子-ID 精准解析与匹配
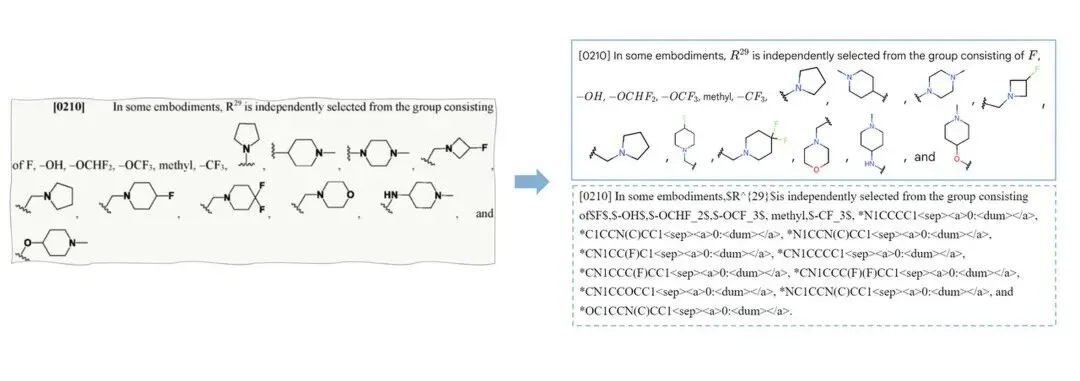
上图:包含分子结构的段落精准解析
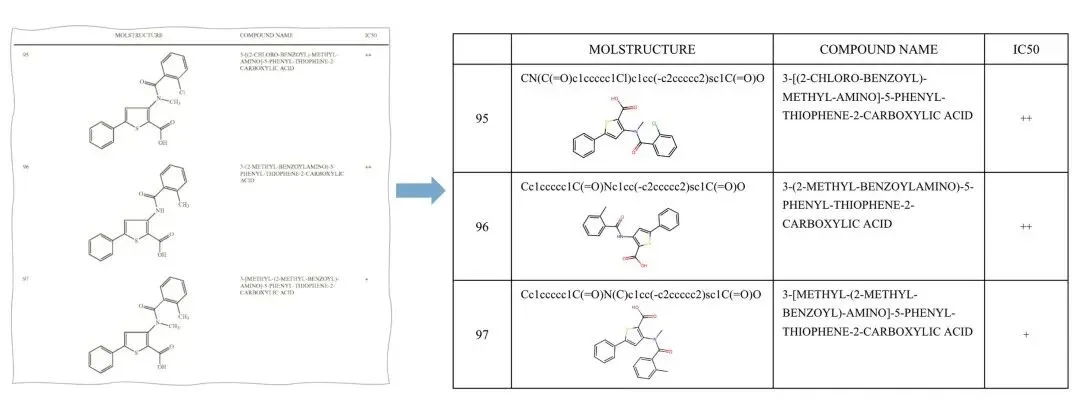
上图:包含分子结构的表格精准解析
针对化学结构解析任务,我们设计并集成了面向大规模化学场景解析的端到端 OCSR 子模块 MolParser,用于实现高精度、可规模化的分子结构解析。仅在单卡部署条件下,该模块即可达到约 3700 万分子/天的解析吞吐量,具备工业级的处理效率。此外,MolParser 不仅支持标准分子结构式识别,还能够处理复杂 Markush 结构与部分高分子结构解析任务,并支持超过 13,000 种缩写基团的自动替换与结构还原,从而显著提升对真实专利与文献场景中复杂化学表达的覆盖能力。在真实文献与专利场景构建的 Uni-Parser benchmark 上,Uni-Parser 在分子定位任务中取得 99.4% mAP@50,在常规分子结构识别任务中达到 97.9% 的准确率。在第三方基准 BioVista 上,模型在 Markush 结构识别、手性分子识别等多个子任务中均达到 SOTA 水平。
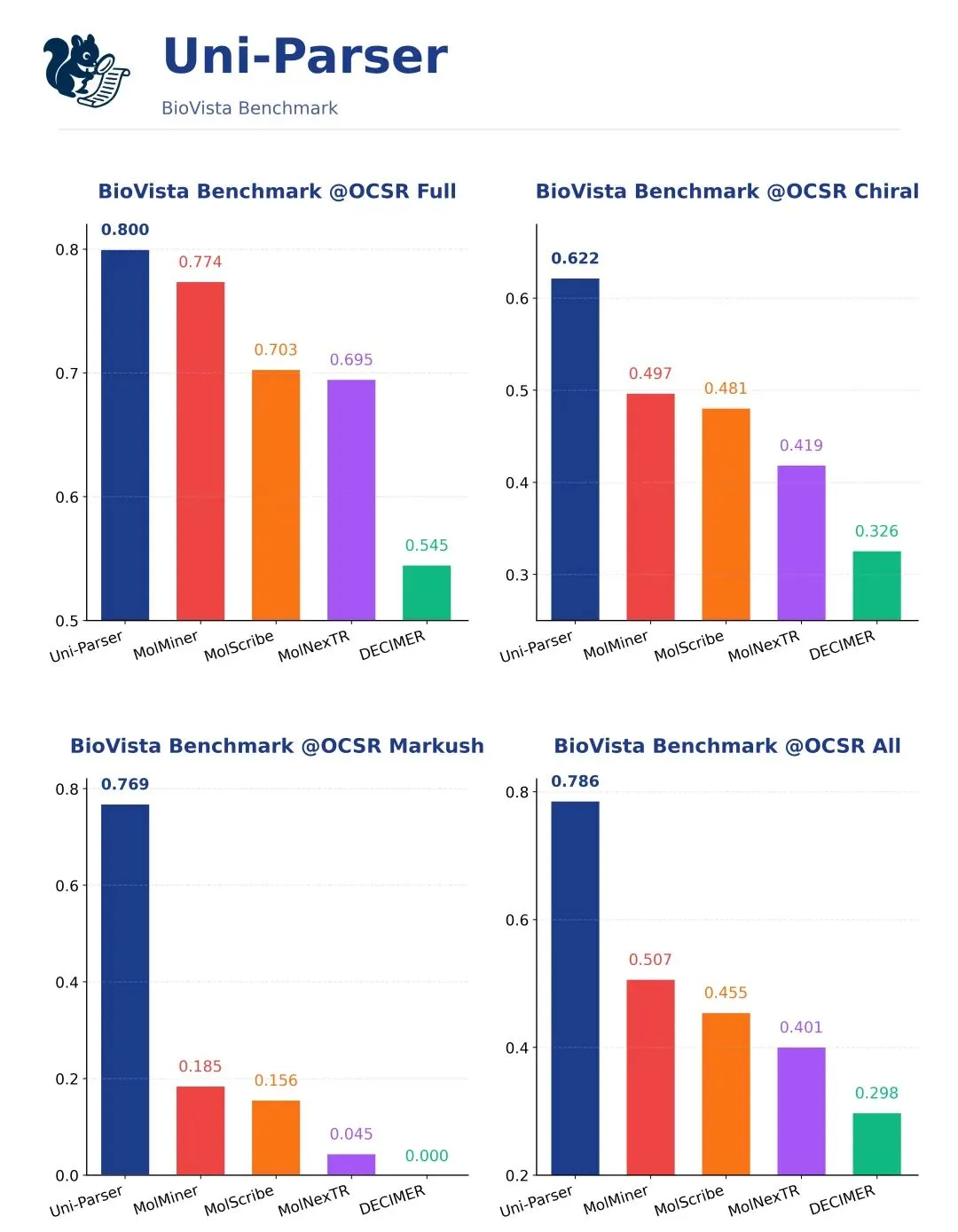
上图:BioVista 分子识别榜单

多模态解析
精度领先
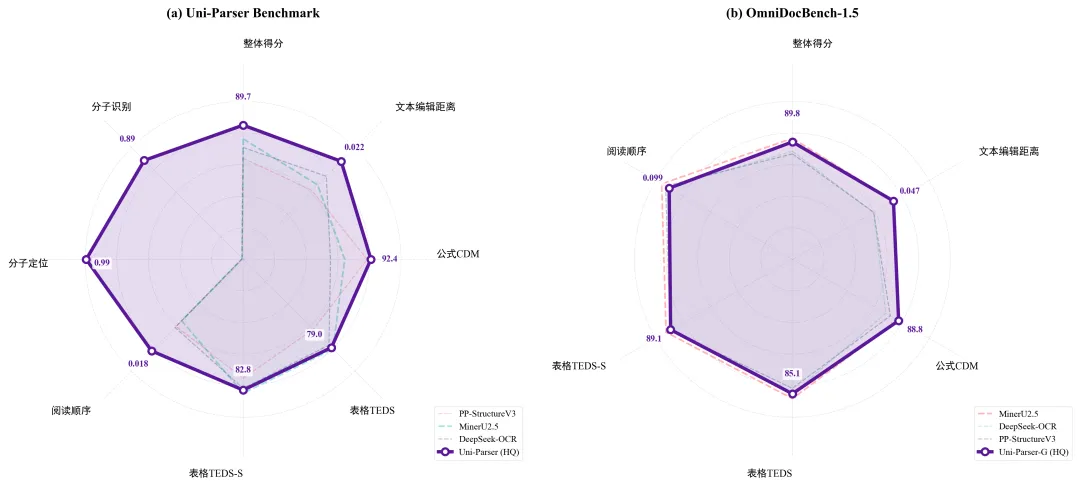
上图:Uni-Parser 多模态解析能力评测
在自建的科学文献与专利解析解析的基准测试(Uni-Parser Benchmark)中,Uni-Parser 相较于主流文档解析方法取得了显著领先的整体性能优势。尤其在科学文本、数学公式、分子定位和识别,以及复杂科学版面的阅读顺序上,有明显的优势。
同时,在包含 PPT、金融报告及报纸等多类型通用 PDF 文档解析任务上,通用模式 Uni-Parser-G 表现出与第一梯队的文档解析方法相当的竞争力。

零部署成本,
一键快速接入

多场景
下游应用赋能
此外,基于 Uni-Parser,我们构建并开源了科学多模态数据集 OmniScience,并在 Hugging Face 上发布,上线数日即登上热度榜并实现万级下载。从商业角度看,OmniScience 构建了数据与系统协同驱动的核心壁垒:依托对海量科学文献与专利的深度解析能力,持续从非结构化 PDF 中自动化生成高信息密度的结构化多模态数据,并与模型训练形成闭环迭代。这一能力不仅决定了模型性能的上限,也构成了难以复制的数据生产体系,使我们在科研、制药与材料等高价值场景中具备长期竞争优势与规模化扩展潜力。
https://huggingface.co/datasets/UniParser/OmniScience
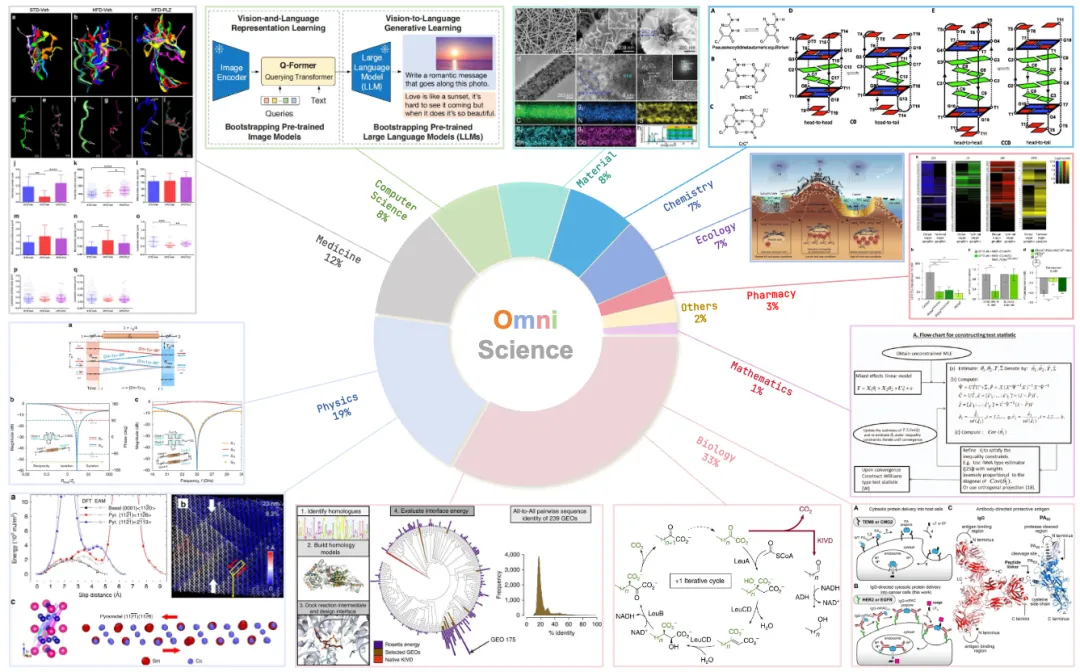
上图:OmniScience 数据集
NMRExp:高质量核磁数据基础设施
基于 Uni-Parser,我们还参与构建了大规模核磁谱数据库 NMRExp,从海量文献 Supporting Information 中自动解析实验谱图与结构信息,涵盖 ¹H、¹³C、¹⁹F、³¹P、²⁹Si、¹¹B 六类核种,总计 330 万余条结构–谱图对应记录,实现高精度的谱图数据抽取与结构关联(>99% 元数据解析准确率,>98% 分子骨架提取准确率)。该数据库为分子结构验证、反应分析及 AI for Chemistry 提供了关键数据基础设施。
https://www.nature.com/articles/s41597-025-06245-5
DocVQA: 迈向通用文档理解
在最新发布的文档理解评测基准 DocVQA2026中,基于 Uni-Parser 的方法取得了显著领先的性能表现,整体成绩大幅超越当前主流大模型基线(如 Gemini-3.1-Pro-preview 与 GPT-5.4)。尤其在科学论文的 VQA 任务上,Uni-Parser 达到了 85.0 的高分,展现出在复杂科研文档解析与推理方面的卓越能力。
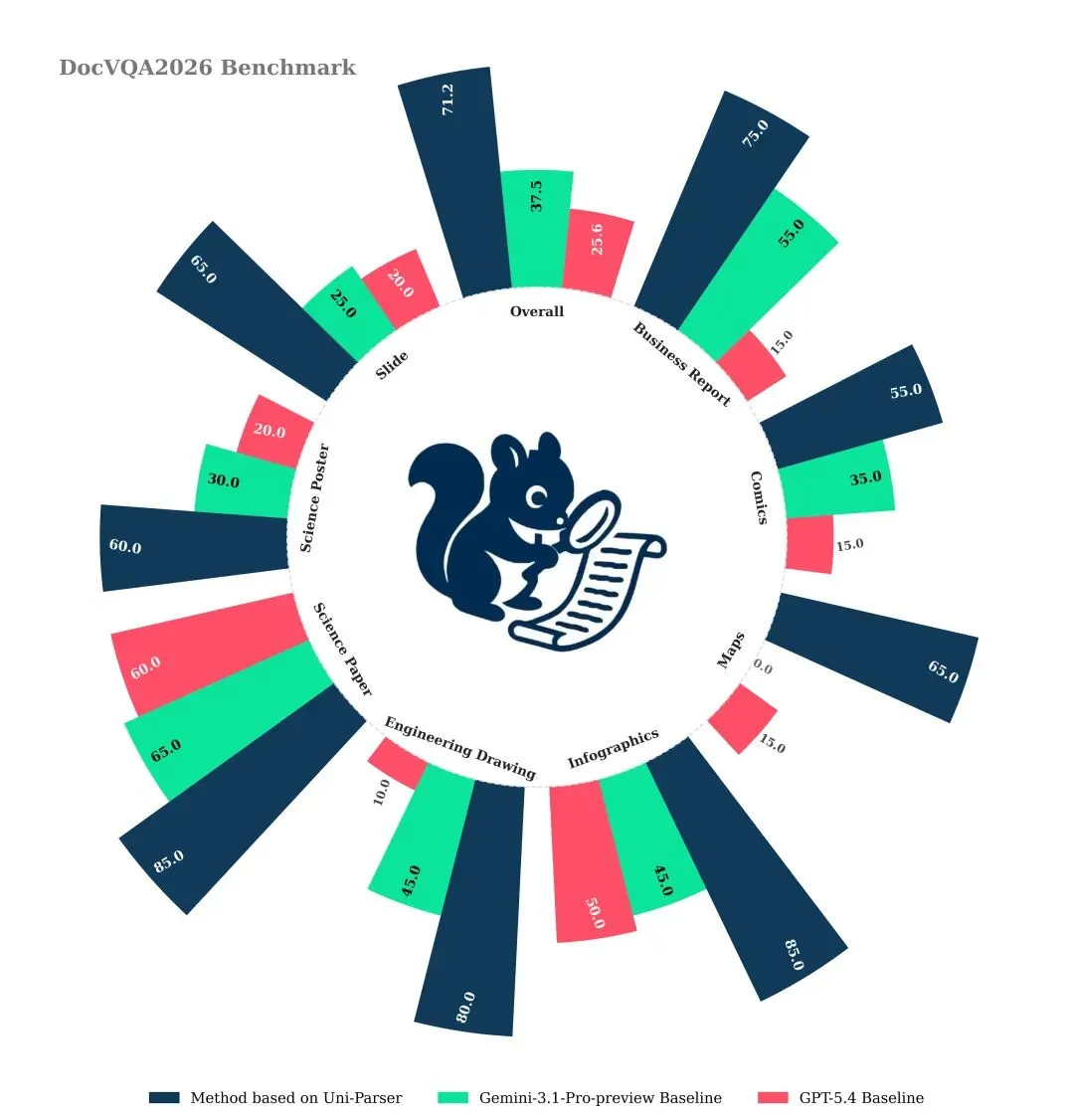
上图:DocVQA2026 Benchmark 指标对比
检索系统:玻尔·科学导航(化学版)
基于 Uni-Parser 的结构化解析能力,构建面向科研场景的语义检索与知识导航系统——玻尔·科学导航(化学版),实现对文献、分子结构、反应信息与实验数据的统一索引与跨模态检索能力,使用户能够以自然语言或结构化条件快速定位科学知识,实现从“文献检索”到“知识导航”的升级。
https://www.bohrium.com/chem-sn
整体上,我们构建的是一个从科学文档理解 → 数据生产 → 模型训练 → 行业应用的闭环系统,并以 Uni-Parser 为核心引擎,形成持续演进的数据与能力壁垒。
商业需求咨询
Uni-Parser 现已支持私有化部署与 SaaS API 调用,欢迎垂询:bd@dp.tech
加入我们
实习:
https://dptechnology.jobs.feishu.cn/index/position/7551731660225808676/detail
FTE:
https://dptechnology.jobs.feishu.cn/index/position/7486012032446138635/detail
关于深势科技
