 夜雨聆风
夜雨聆风





64K星!Claude Code最强插件Claude-Mem升级了,这架构设计有点东西!
大家好,前两天在逛GitHub Trending的时候,被一个项目刷屏了——Claude-Mem,一个Claude Code的持久化记忆插件,短短一周狂揽14.5k星,直接冲上总榜前三。
说实话一开始我是拒绝的。现在市面上”AI记忆”相关的项目多如牛毛,吹得天花乱坠,用起来一言难尽。但这次仔细看了下它的技术实现,有点被惊艳到了——特别是那个三层渐进式检索架构,不得不说这帮开发者是真的在认真思考怎么解决问题。
今天就跟大家聊聊这个项目,看看它到底有什么不一样的地方。

先说说Claude Code是个啥
可能有些朋友对Claude Code还不太熟悉。简单讲,这是Anthropic官方出品的命令行AI编程助手,可以理解为:一个能直接在终端里帮你写代码、调试、甚至做项目管理的AI。
跟那些IDE插件型的Copilot不一样,Claude Code是真正的Agent级工具——它能理解整个代码库、自主规划多步任务、跨文件修改代码、调用系统命令。说白了,它不是来给你补全代码的,是来帮你干活的。
这玩意儿现在在开发者圈子里火得不行。它有200K的超长上下文,能一次性”阅读”整个项目。而且原生支持VS Code、JetBrains等主流IDE,命令行操作起来特别流畅。配合插件系统,生态发展得贼快。

三层渐进式检索:这才是正经做工程的态度
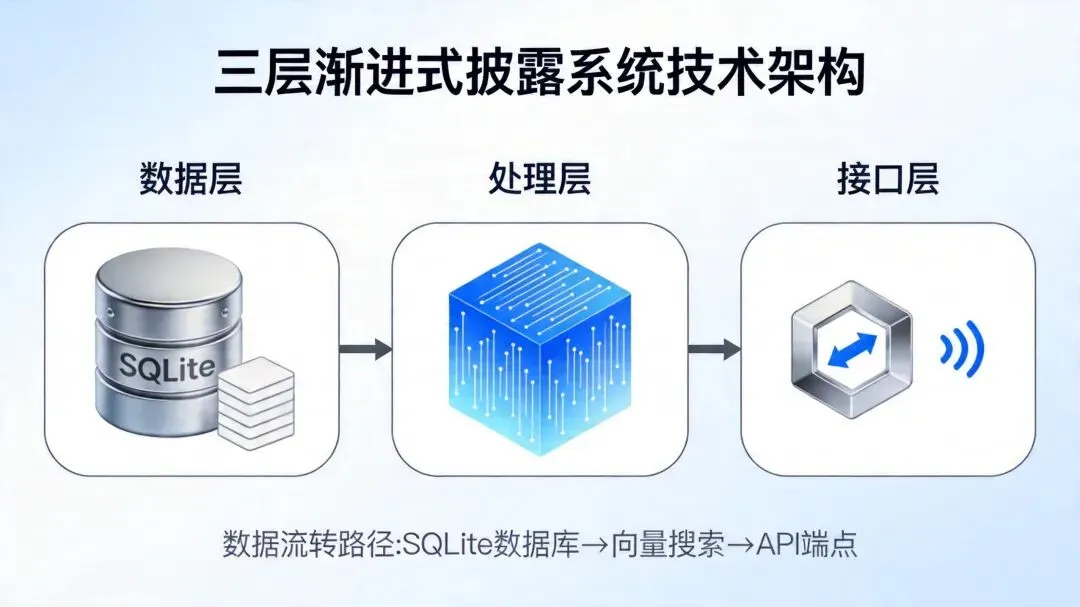
好了,重点来了。Claude-Mem最让我佩服的,是它的三层渐进式检索架构(Progressive Disclosure)。市面上大多数记忆系统的问题在于:要么一股脑把所有历史记录塞给AI,导致上下文爆炸;要么检索太粗暴,返回的结果跟你的需求八竿子打不着。
Claude-Mem怎么解决的呢?它把检索拆成了三步:
第一层:Search(索引)——先用关键词或自然语言搜一圈,返回给你一个紧凑的结果列表。这列表里只有ID、标题、时间、类型这些元信息,每条只占50-100个token。
第二层:Timeline(时间线)——从索引里挑几个看起来相关的点,围绕它们拉出一条时间线,看看这个观察点前后都发生了什么。这个步骤能帮你判断”这个结果到底跟我要搞的东西有没有关系”。
第三层:Get Observations(详情)——最后才去拿完整内容,而且只拿前面两步筛选出来的那些。每条大概500-1000个token。
整个流程下来,token消耗直接降了10倍。不是那种玄学优化,是实打实的工程设计。
我觉得这种设计思路特别值得学习——不是堆参数、不是靠更大的模型硬算,而是在架构层面就把问题想清楚了。这种渐进式的设计,既保证了信息完整性,又避免了上下文污染。
说到这里,可能有朋友会问:这种设计是怎么跟Claude Code集成的?
答案是MCP(Model Context Protocol)工具。Claude-Mem暴露了4个MCP工具:search、timeline、get_observations,还有一个__IMPORTANT__常驻提示,引导Claude按三层流程走。这种”用工具设计强制最佳实践”的做法,思路很巧妙。
SQLite + ChromaDB:轻量级方案的逆袭
说到技术选型,Claude-Mem用了SQLite + ChromaDB的组合,这让我挺意外的。
现在好多项目动不动就上PG、Milvus、Weaviate,搞得运维复杂度飙升。Claude-Mem反其道而行之:
**SQLite(FTS5)**负责全文搜索和结构化存储
ChromaDB负责向量嵌入和语义搜索
本地就能跑,不用部署什么分布式集群。数据全部存在~/.claude-mem/目录下,透明可控。

我特意去翻了下文档,作者还搞了个claude-mem-lite的精简版,连Chroma都去掉了,只依赖SQLite的FTS5做搜索。这个版本更适合轻量级场景,源码只有50KB,对比原版的2.3MB bundles,体积差了40多倍。
有个对比数据很有意思:LLM调用次数从原来的”每次工具调用都触发”降到了”每个episode只调用5-8次”;Token消耗从10万-25万降到了1千-4千,差了50-100倍。成本直接降了600多倍。
对于个人开发者或者小团队来说,这种”零运维”的方案真的很友好。装上就能用,不用折腾什么数据库集群。

观察类型分类:让记忆变得可搜索
Claude-Mem还有一个我很喜欢的功能:自动分类。
每次会话结束,它会通过Claude Agent SDK对观察进行总结和分类,标记为:
-
decision – 关键决策,比如”我们决定用PostgreSQL而不是MySQL”
-
bugfix – 修复记录,”这个bug的根因是空指针”
-
feature – 功能实现,”实现了JWT鉴权”
-
refactor – 重构,”把订单模块拆成了独立服务”
-
discovery – 新发现,”原来这个API有rate limiting”
每个观察还会被打上重要性等级(routine / notable / critical),方便后续筛选。
我之前用过一些类似的工具,回溯历史的时候全靠”模糊搜索”,运气不好搜半天也找不到想要的内容。Claude-Mem这种分类体系让记忆变成了真正可索引、可检索的资产,而不是一堆乱七八糟的日志。

Sidecar架构:优雅的非侵入式设计
讲技术架构的时候,一定要提一下Sidecar模式。
Claude-Mem没有直接修改Claude Code的源码,而是利用它的插件Hook机制,挂了一个独立的Worker Service在旁边。这种设计有几个好处:
-
不破坏原生体验——Claude Code怎么用还是怎么用,Claude-Mem只是”悄悄”在后台工作
-
隔离性——记忆处理完全异步,不会阻塞主对话流程
-
可维护性——升级、降级、禁用都很方便,不会影响主程序
Worker Service跑在37777端口,用Express.js处理HTTP请求,用Server-Sent Events做实时推送。整体架构清晰,组件之间职责分明。

Web Viewer:你的记忆控制台
Claude-Mem自带了一个Web界面(http://localhost:37777),可以实时查看记忆流。
Claude-Mem Web Viewer这个界面能干啥呢?
-
实时查看当前会话的观察记录
-
搜索和过滤历史记忆
-
管理项目和上下文配置
-
切换Beta功能(比如Endless Mode)
对于喜欢可视化操作的朋友来说,这个控制台挺实用的。不用命令行也能了解记忆系统的运行状态。

隐私控制:敏感内容你说了算
这是个很现实的问题——Claude Code天天跟你的代码打交道,里面难免有些不想被记住的东西。
Claude-Mem的处理方式是打标签:直接在代码里用<private>标签包裹的内容,不会进入存储层。这个过滤发生在hook层(边缘处理),数据根本到不了worker和数据库。
<private>数据库密码: Admin@123API密钥: sk-xxxxxx</private>
这部分内容完全不会被记录。对于商业项目来说,这个功能还是挺重要的。毕竟不是所有代码都适合当训练素材。
开源 vs 商业:开源核心很良心
最后说说License的问题。
Claude-Mem的核心功能是完全开源的(AGPL-3.0),所有API端点都保持开放。你可以直接访问localhost:37777上的所有接口,不存在什么”付费墙”。
作者也说了,Pro功能会以”额外能力”的形式提供,但不会去改核心接口。也就是说:不花钱也能用全部功能。
我觉得这种模式挺健康的——开源保证生态,增值服务保证开发者的可持续投入。对比某些”核心功能全锁付费版”的方案,诚意明显更足。
有意思的是,作者Alex Newman(@thedotmack)还搞了个$CMEM的Solana代币,作为社区激励。虽然这玩意儿见仁见智,但至少说明项目在认真考虑长期运营的问题。

写在最后
说实话,Claude-Mem让我对”AI编程记忆”这个赛道重新燃起了信心。
之前用过不少类似的产品,大多数停留在”把对话存下来”这个层面,缺乏真正的工程思考。Claude-Mem不一样——它的三层检索架构、轻量化技术选型、细致的分类体系,每一处都透着”认真做产品”的态度。
64K星不是白拿的!
如果你也是Claude Code的重度用户,真心建议试试这个插件。相信我,用过之后你会有”之前那些会话都白干了”的感觉。
好了,这期就聊到这里。各位观众老爷如果有什么问题,欢迎评论区交流!
项目链接:https://github.com/thedotmack/claude-mem
官方文档:https://docs.claude-mem.ai/
往期精选
你的下一批”员工”,可能不是人……17K Star开源项目Multica,让OPC触手可及!
3B参数打赢27B!阿里Qwen3.6-35B-A3B开源引爆Agent编程!
英伟达的”量子野心”:用AI给量子计算机装上大脑!全球首个量子AI开源模型——NVIDIA Ising发布!
把K线图变成”语言”,清华团队用LLM思路做出了股票预测开源模型Kronos!
MiniMax M2.7重磅开源,模型直接参与自身迭代优化!华为昇腾、摩尔线程等芯片0Day适配!
追踪AI前沿,深挖GitHub宝藏。
用优质内容陪你成长,
点击关注,携手启航。