 夜雨聆风
夜雨聆风





当 75% 的代码是 AI 写的,软件工程剩下什么
2026 年 4 月 22 日,Sundar Pichai 在 Google Cloud Next 的博文里写了一句话:Google 所有新代码中,75% 现在由 AI 生成,并由工程师审查批准。”相比去年秋天的 50%”——用了不到半年,比例涨了 25 个百分点。
Google 不是在做比喻。75% 是真实的内部比例,有工程师审查的生产代码,不是实验性输出。Anthropic 的数字是 70-90%。这两家最懂 AI 的公司的工程团队,已经有超过四分之三的新代码来自 AI。问题不再是”AI 会不会写代码”,而是:当多数代码都是 AI 写的,工程师做什么、软件质量意味着什么、出错的责任归谁——这些问题的答案都在变
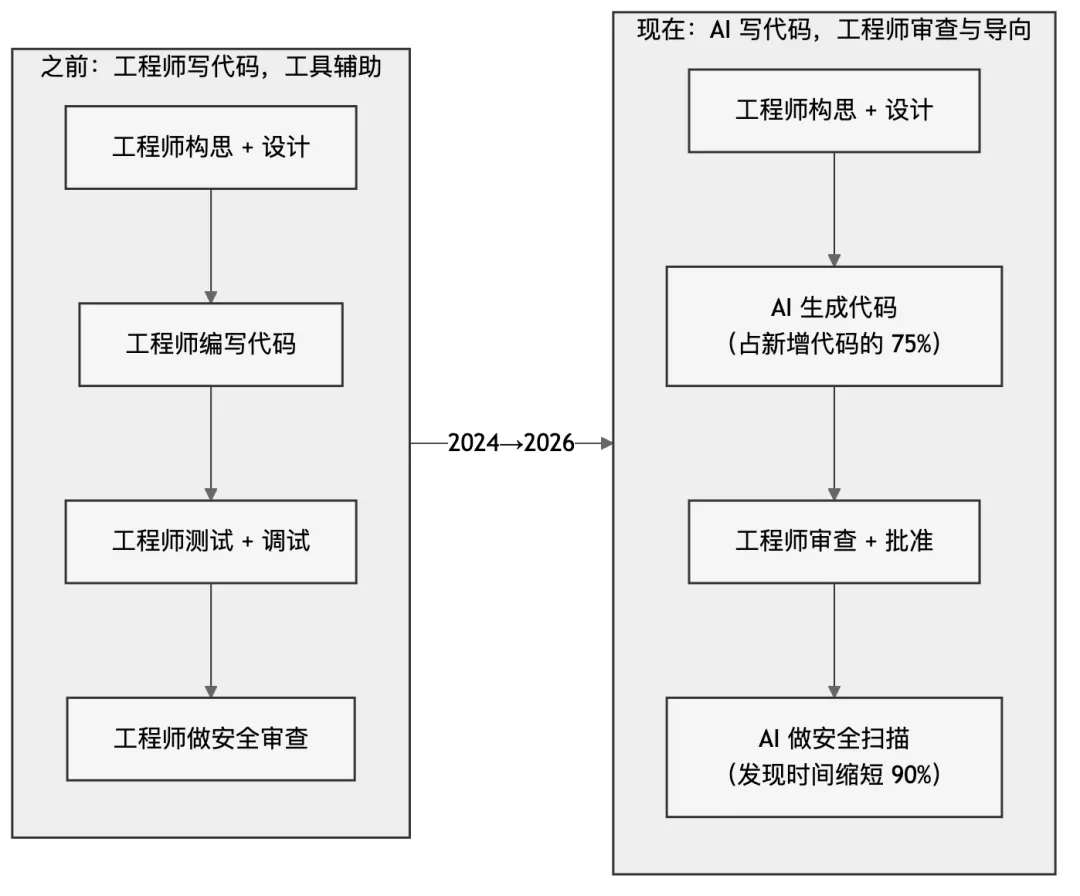
工程师不再主要”写”代码,而是主要”审”代码和”导向”AI。代码的量变大了,但工程师的精力不是被省出来的——它被重新分配到了更上游(设计决策、需求拆解)和更下游(安全审查、架构守护、边界案例的判断)。
75% 这个数字从哪来的
Google Cloud Next 博文是一手来源,Pichai 亲笔。时间节点:2026 年 4 月 22 日。数字附带了时间序列:50%(2025 年秋)→ 75%(2026 年 4 月),半年增长 25 个百分点。
这个比例指的是”新增生产代码”,不是所有存量代码。新增代码是流量,存量代码是库存——在一个有二十年历史的大型工程系统里,75% 的新增代码 AI 生成,不意味着 75% 的现有代码库是 AI 写的。但从流量角度看,工程团队的生产输出已经高度 AI 化。
Anthropic 的比例更高:70-90%。这个数字来自 2026 年 2 月,Anthropic 内部用 Claude Code 写自己的代码,占比区间在 70% 到 90% 之间。一个 AI 公司用自己的模型写了自家代码的七到九成,含义比技术声明更直接:他们愿意把这个工具的稳定性和代码质量押在自己的生产系统上,而不只是卖给别人用。
这些工具在做什么
光讲比例是不够的,配套的具体数字才说明规模。
CodeMender:Google 内部的 AI 安全工具,不只发现代码安全漏洞,还会主动生成修复 patch。传统流程是:安全扫描工具报告漏洞 → 开发团队排期修复 → 几周后才合入。CodeMender 在 CI 流水线里自动运行,发现问题后直接给出修复方案,工程师 review 的是修复,而不是先判断问题再自己想修法。这把”发现 → 修复”的周期从周级压缩到了 review 时间级。报告里描述的”关键安全缺陷”(critical security flaws),修复延迟越长,暴露窗口越大——CodeMender 的价值不只是找到了问题,而是几乎同步关闭了暴露窗口。
SOC 代理:Google 的安全运营中心(Security Operations Center)的典型告警响应路径是:告警触发 → 分析师看日志 → 判断是否真实威胁 → 评估影响范围 → 制定响应方案 → 执行。一个真实威胁的确认和缓解,有时需要 2-4 小时。AI 代理介入的是中间层:告警触发后,代理自动拉取相关日志、关联历史事件、过滤误报、生成响应建议,分析师直接看摘要和建议做最终决策。”90% 以上”意味着两小时的流程现在是十分钟内的决策。这在安全里有实际意义:攻击者从初始访问到横向移动通常需要数分钟到数十分钟,响应从小时级压缩到分钟级,直接改变了防御侧能打的仗。
大型代码迁移:代码迁移的典型场景——把使用内部旧版 API 的大型服务切换到新版、把 Python 2 代码库升级到 Python 3、把跨语言遗留模块批量重写——模式高度机械,但规模大,风险不低(一个边界行为的语义差异就是 bug)。代理处理模式化的批量替换,工程师处理需要业务判断的边界案例。6 倍提速的主要来源是规模效应:代理不疲劳,同等准确度下能以远高于人手的速度处理批量工作量,而工程师的精力集中在少数需要理解上下文的决策点上。
新产品开发:Pichai 描述 Gemini macOS 应用的构建——”从想法到 native Swift 原型,只需几天”。注意是 native Swift 原型,不是 web demo,意味着 Swift 语言上手、macOS 平台 API 调用、基本界面实现都在这几天里完成了。以前这个起步需要一个熟悉 Swift 和 macOS 开发的工程师;现在这个前置条件可以被跳过,原型门槛降低的结果是:更多想法能进入验证阶段,而不是在”还没人来做这个”里等待。
“AI 审查批准”是真正的关键词
Pichai 的原话是”AI-generated and approved by engineers”——这个”approved”是被刻意强调的。AI 写,工程师批。这是今天最普遍的使用模式,不是自动提交。
这个模式的含义:工程师审查的工作量没有减少,反而可能增加。AI 生成的代码量更大,但不一定每一段都需要同等深度的 review——有些改动是机械的、低风险的,有些是架构级的、高风险的。工程师需要判断哪些值得深看、哪些可以快速过。这个判断本身就是一项越来越重要的技能。
更重要的:当你审查一段不是你写的代码,你对它的理解深度天然低于你自己写的代码。AI 生成的代码在局部看可能没问题,但它的架构影响、它和其他模块的隐含依赖关系、它在边界条件下的行为——这些需要更主动地去验证,而不是假设 AI 已经考虑到了。这是 AI 代理在 monorepo 里的结构性问题 在宏观数字上的具体体现:每一个”AI 写、人批”的循环里,都有可能在架构层上积累细小的偏差。
质量的问题
2026 年 3 月到 4 月,Claude Code 出现了三个静默工程问题:推理努力度被降级、推理历史丢失、工具调用被截断。六周内没有任何官方通知,用户先发现的。Veracode 在这个窗口期内测出安全漏洞率达到 52%(此前约 51%),TrustedSec 记录代码质量下滑约 47%。
这件事的启示不只是”AI 工具会退化”,而是:当 75% 的代码来自 AI,质量监控的责任结构也在改变。以前质量主要由写代码的人负责,现在质量由生成代码的模型和审查代码的工程师共同决定——但两者的质量退化机制完全不同。人会疲劳、会马虎,但退化是渐进且有因可查的;模型会被静默降级、会因服务器变更而行为漂移,退化可以是突然的、无告知的。
如果你的质量体系是建立在”工程师写的代码,出了问题是人的问题”这个假设上的,它需要更新了。
软件工程剩下什么
这个问题有一个平滑的答案,也有一个诚实的答案。
平滑的答案是:工程师的价值从”写代码”上移到了”架构决策、需求拆解、质量把关”。工具链升级,人的价值层级跟着升级,皆大欢喜。这个答案不是错的,只是不完整。
诚实的答案是:写代码在工程师工作里占的比例确实在下降,而且这个下降不均匀。能最快被 AI 替代的,是那些模式化的、语境局限的、语法规则明确的编码工作——初级工程师做的那类任务。这不是说初级工程师没有价值,而是说他们学习”如何写代码”的传统路径,正在被改变。以前是写 → 犯错 → 改 → 积累经验;现在有一种可能是:让 AI 写 → 审查 → 提出修改 → 但少了很多”自己写出来才会犯的错”。这类错误其实是工程直觉的来源。
与此同时,工程师对系统整体的把握能力——理解为什么要这样设计、预见三个月后的问题、在 AI 给出的五种方案里知道哪种更合理——这类能力的溢价在上升。但这不是自然涌现的,它需要足够多的亲手写代码作为基础。
75% 是今天的数字,半年前是 50%。这个斜率如果持续,80% 和 90% 不需要技术突破,只需要当前趋势再走几个季度。在那个比例下,审查 AI 代码会成为工程师最主要的日常工作,而不是辅助工作。”能看出这段代码哪里不对”——在今天还是附加技能,正在变成核心技能。
延伸阅读
-
Google Cloud Next ’26:Sundar Pichai 博文 — 75% 数字和 CodeMender、SOC 代理的第一手来源 -
AI 编程代理正在悄悄破坏你的 monorepo 架构 — 微观视角:AI 代码在大型项目里如何在结构层面积累问题 -
Anthropic 的算力危机与 Google $400 亿 — 三个静默工程 bug 的背景:算力压力如何影响模型质量决策