 夜雨聆风
夜雨聆风





房间里的大象:了解AI常用术语与AI大厂
即使你不了解AI,也能看懂这篇文章。
最近有朋友问我:你知不知道什么是MCP、什么是Skills?这其实是一个比较进阶的词。后来我们讨论到说,实际上在我们的日常生活中,对于普罗大众来说,这些既熟悉又陌生的词是”房间里的大象“。
所谓的”房间里的大象“就是——大家可能都在日常生活中刷到、看到、听到某些词,比如说像LLM、Prompt、ChatGPT、Codex、Cursor,大家知道它的存在,但并不知道他们之间是什么关系,它到底是用来干什么的。但因为在对话的过程当中害怕尴尬,或者是问出来担心自己好像显得很不懂,所以就假装没有看见、没有听到,闭口不谈。
所以我今天打算,给大家讲一些基本的知识。「虽然我也是半吊子」
一、LLM(大语言模型)
一切AI能力的最底层,就是LLM。它是Large Language Model的缩写,大语言模型。它是今天所有AI应用的核心大脑。而支撑所有大模型运行的底层技术,叫做Transformer架构。这套架构最早是谷歌团队在2017年的论文《Attention is all you need》里提出的。但当时只是学术理论,并没有真正走进大众视野。真正把Transformer用透,把大模型做到可用,让全世界第一次感受到AI强大的,是OpenAI,从GPT-3.5开始。大模型突然变得能用、好吃、会思考,AI时代才真正到来。
那大模型到底是怎样工作的?原理可以用一句话来说明:下一个token预测、文字接龙。比如你问”今天天气如何”,模型经过思考后,先输出”很好”,然后再把”是”和”大”一起放回输入,继续预测下一个词是”晴天”。回答完毕,输出结束符停下,我们就拿到了它的回答:”很好,是大晴天”。这就是为什么AI永远是一个字一个字蹦出来的原因。
二、Prompt(提示词)
这里又引出了第二个概念:Prompt。它是给AI的精准指令。我们想让AI做什么,靠的是我们提出的问题,也就是Prompt提示词。分为两类:User Prompt和System Prompt。User Prompt就是用户直接提的需求,而System Prompt是后台设定的身份与规则,用户无法看到。
例如,我通过System Prompt设定一个AI的MBTI是”INTJ”。提出同样的问题”今天天气如何”,那么它只会回答”晴天”,更符合INTJ话少的设定。

三、Token(词元)
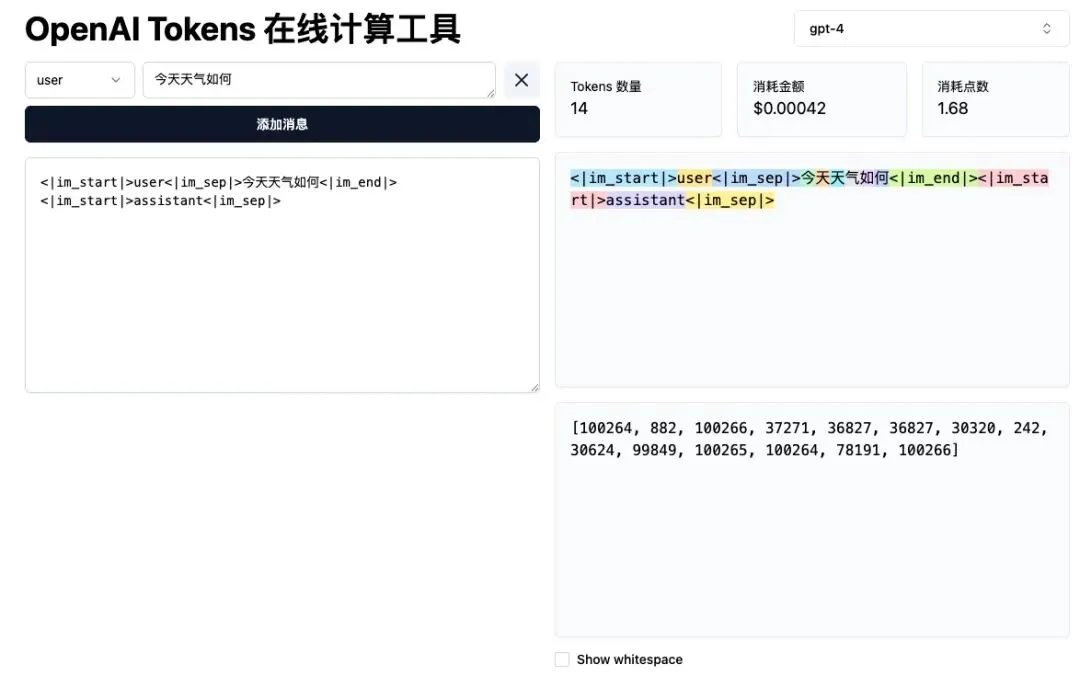
我们每次向AI输入的汉字或者单词,AI是怎样看懂的?AI不按汉字或者单词理解文字,它有自己的单位:Token。Token是模型把文字切成的最小片段,是AI处理文字的最小单元。比如刚才的提问”今天天气如何”,会被分成14个Token(实际上Token和汉字不是完全一一对应的,模型有一套自己的切分规则)。一般来说,一个Token大概是0.5个汉字,或者0.75个英文单词。
到这里,我们只是把输入做了切分。但其实切分后的Token,大模型还是不认识。因为大模型其实就是一堆数学函数,它的输入和输出都是数字。所以在刚才切分完成后,还要做进一步转换,把文字变成数字。于是刚才的Token就对应上Token ID,这才是大模型能看懂的语言。
四、Context(上下文)
刚才说到大模型的本质就是一堆数学函数,它没有长期记忆。但我们可能有一种感觉:AI好像能记住我们之前说过的话。这是因为我们每次提问,程序都会自动把之前的全部聊天记录和当前的问题打包在一起,发给模型。这一整包的所有信息合起来就是Context上下文。它就是AI当下能看到的全部信息,相当于AI的临时记忆。
而这个临时记忆不可能无限大。它最多能装下多少个Token,就是ContextWindow上下文窗口,也就是AI临时记忆的容量上限。窗口越大,AI能处理的内容就越长,记得越完整。
五、Tool(工具)
接下来我们讲下一个概念:Tool工具。它是AI连接现实世界的能力。大模型有一个缺陷:无法感知外部环境,它只有一个大脑。想让AI真正地动手做事,必须给它加工具。比如说天气查询、实时搜索、计算器、文件读取、地图定位。
工具的本质就是外部函数:输入参数,返回结果。这里有一个关键的点:大模型自己不能调用工具,真正去执行联网、查数据、调用接口的是平台。那平台是什么、是怎样工作的?我们举个例子。
比如刚我们提问:”今天天气如何?”
平台收到了我们的提问,首先判断到联网搜索开关是打开的。平台没有把问题直接给模型,先调用了内部的搜索引擎工具,去互联网上搜索实时天气数据。平台将抓取回来的数据整理成一份干净的参考资料,将整理好的网页内容和用户问题形成一份新的Prompt,发给大模型。大模型看到的是实时数据,根据这些实时数据生成答案,发给平台。
六、MCP(模型上下文协议)
接下来我们讲下一个概念:MCP,全称Model Context Protocol。不同的平台,工具接入规则是不一样的,开发者要重复开发适配多个平台的工具会很麻烦,于是出现了MCP。
Anthropic 是制定标准的人。他们发现让 AI 模型接入外部工具时,每个工具都需要写不同的适配代码,太碎片化了。于是他们设计了一个”标准插座”——MCP,让模型和工具之间通过统一协议通信,类似 USB-C 在硬件领域的角色。
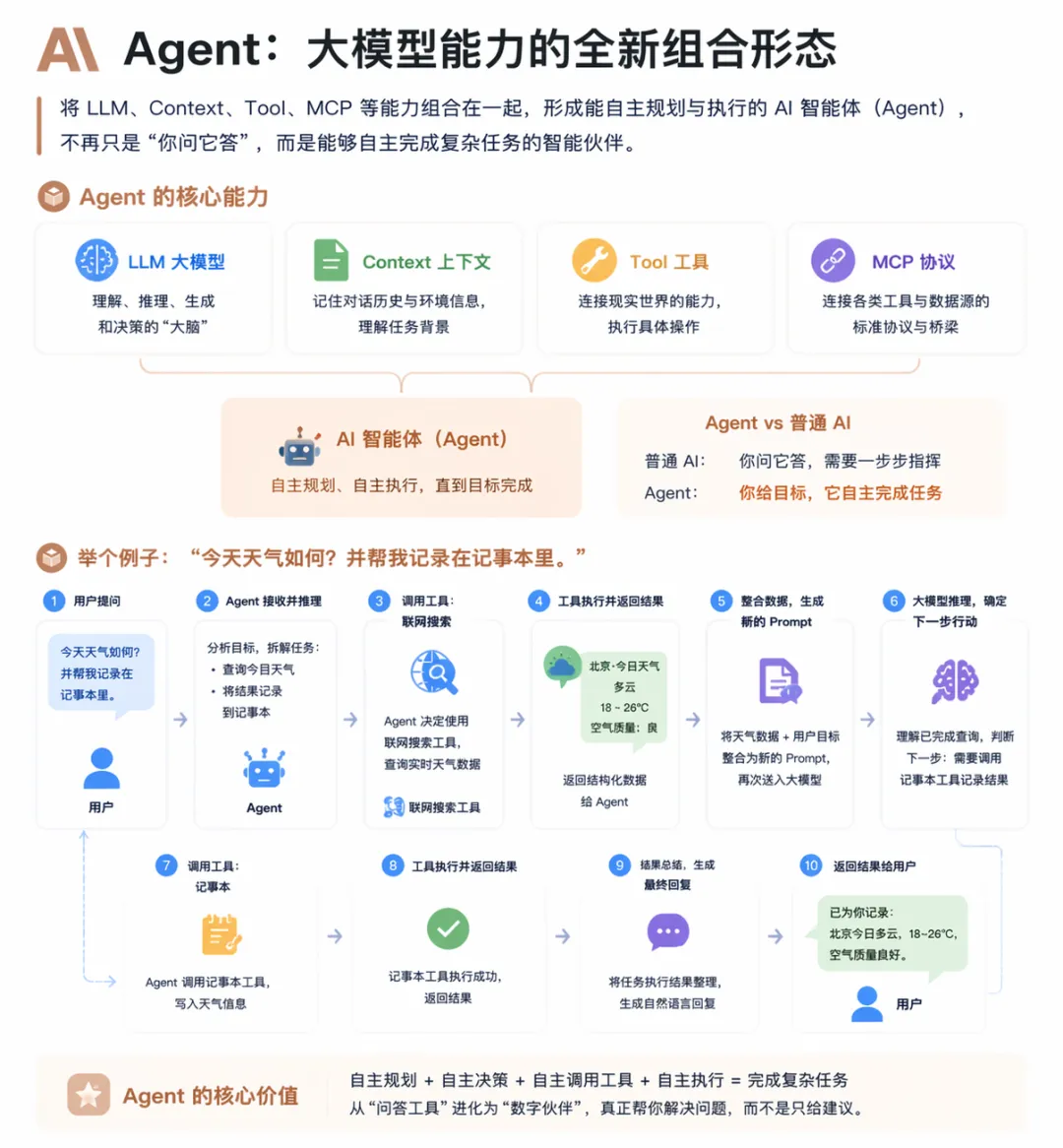
七、Agent(智能体or代理)
大模型把LLM、Context、Tool、MCP这些能力全部组合到一起,就形成了一个全新形态:AI智能体,也就是Agent(龙虾Openclaw/爱马仕Hermes等都是AI Agent)。它和我们平时用的同AI不是一个级别。普通AI智能做到你问它答,它还需要你一步一步指挥。但Agent的不一样:你只需要告诉它最终目标,它就能自己分析、自己拆解步骤、判断该用什么工具,一步步执行,直到把任务做完。
我们还是拿刚才的问题举例。比如我们提问:”今天天气如何?并帮我记录在记事本里。”
Agent经过推理后,自主决定需要调用联网搜索工具查询实时天气,工具执行完成后,返回的结构化数据被整合为新的Prompt,再次送入大模型,Agent知道之后做什么后,调用记事本工具执行记录操作,最后将结果返回给用户。
这就是Agent的核心价值:自主规划和自主执行的能力。
八、Agent Skill(智能体技能)
Skill是给Agent的专用技能包。虽然Agent能自主干活,但每次让它从零开始、重新拆解步骤,效率低还浪费Token。这时候Agent Skill就登场了。它是给Agent提前写好的一套固定流程,可以永久使用。
我们接着刚才的例子来说。提问”今天天气如何”。
没有Agent Skill的人,他会分析思考,下一步该做什么。
有Agent Skill的人,他会按照技能说明直接执行。其实就是告诉Agent:该做什么、怎么判断、怎么输出。
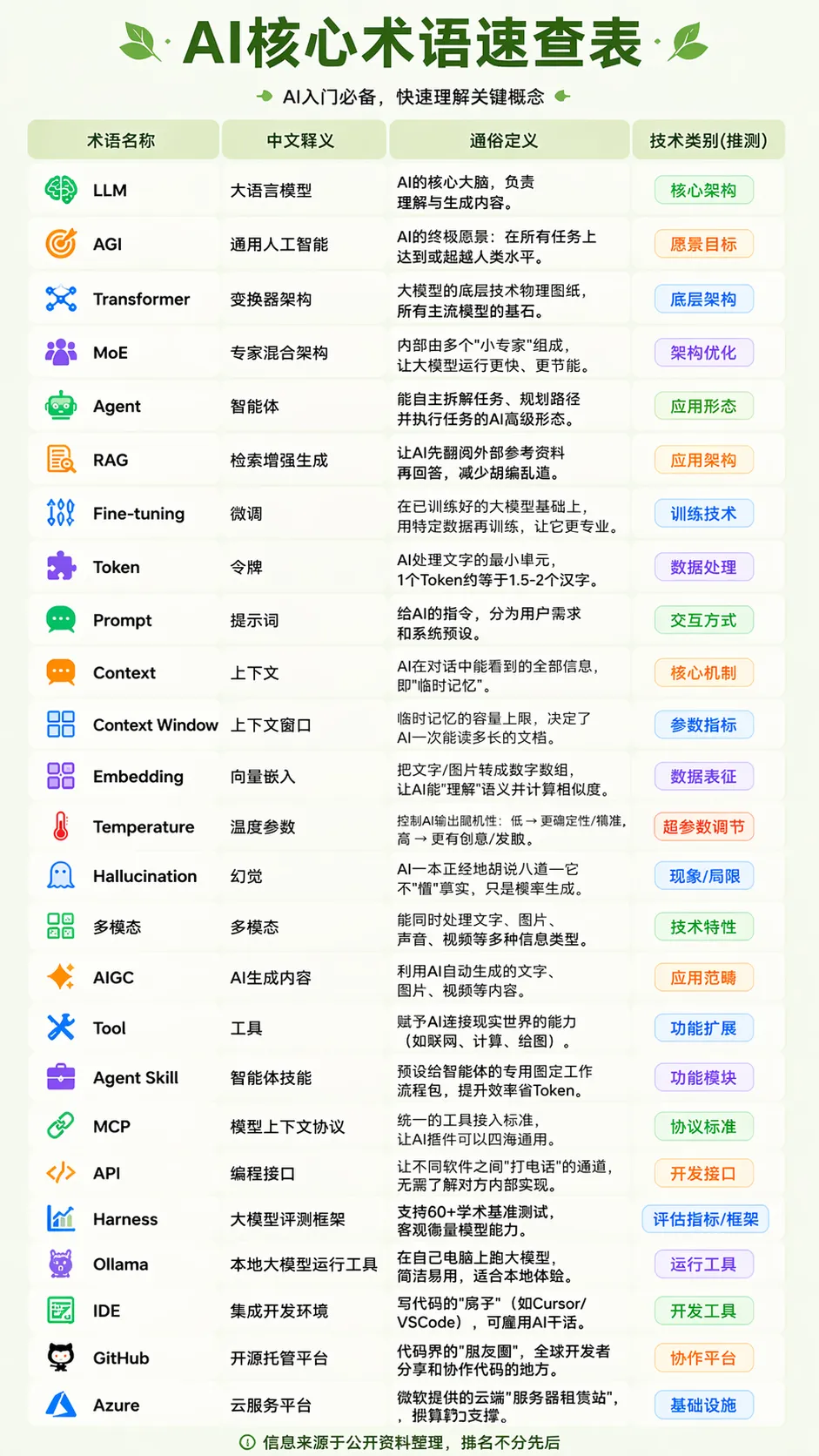
这里总结了以上所有AI名词,也包含了一些其他常见的AI术语:
九、那些AI大厂
厘清从LLM到Agent的逻辑关系,也就掌握了AI Agent的基本原理。在此基础上,不妨再看看全球AI大厂各自推出了哪些产品。
第一层是公司维度——OpenAI、Google、Microsoft、Anthropic、Meta等,这是产品背后的主体。再下一层才是它们各自推出的代表性模型、产品或Agent。
第一家是OpenAI,产品围绕ChatGpt展开,2022年的GPT3.5发布一炮而红,4月24日发布的模型GPT5.5以及生图模型Image2.0表现也很亮眼:

第二家是Google,虽然是AI启蒙大厂,但一度落后于OpenAI,直到它发布了Gemini,广受好评:
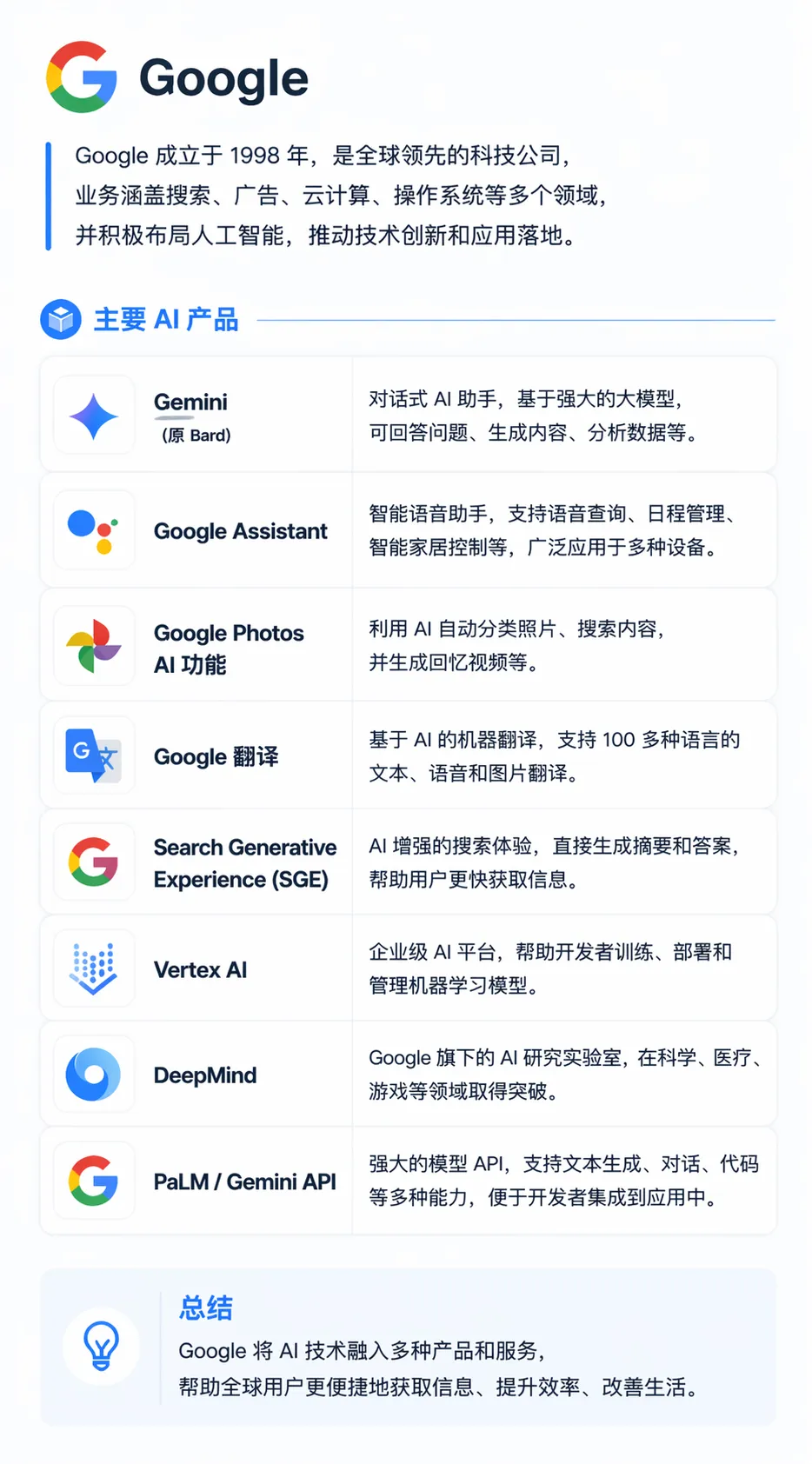
第三家是Anthropic,Claude是当前AI版本的神:
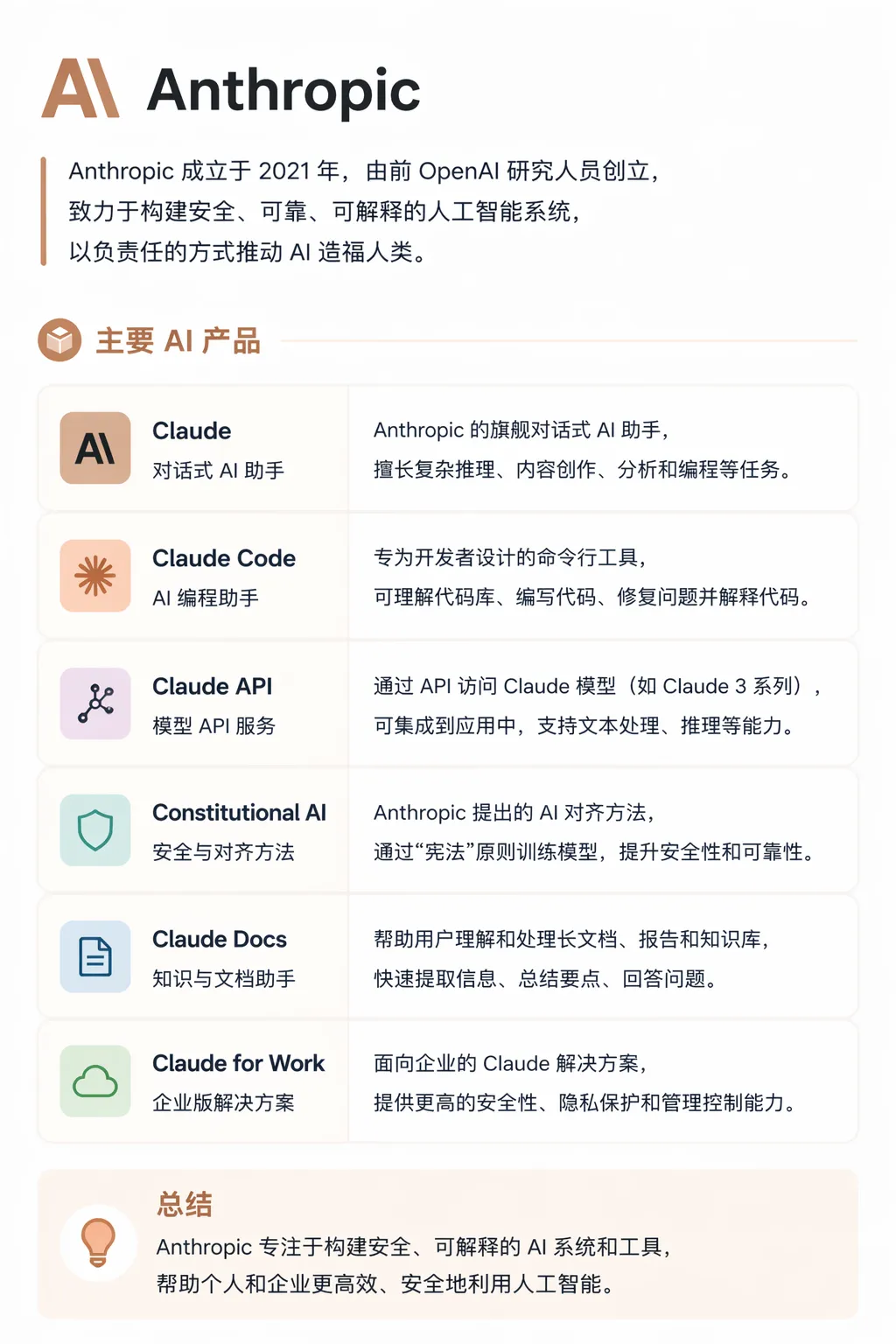
AI御三家看完了,再来了解下国内AI百花齐放的情况:
Deepseek4月24日发布了V4版本,作为开源模型性能已经比肩顶级闭源模型,跑在国产昇腾芯片上,「国产最强开源模型」的叙事也有所完整:算法是自己的,代码是开源的,芯片是国产的。
目前体验最智能的是智谱的大模型GLM5.1,很多国内的朋友都是Claude配GLM5.1,反馈很不错,唯一不足是智谱算力有限,导致API不是很稳定,经常报429连接超限。
国内也有走极致性价比路线的Minimax,最近的2.7版本API响应速度很快,虽然模型使用的参数少,没那么聪明,但胜在量大管饱。

这里总结了中外主流AI大厂的AI产品矩阵全貌:

归根结底,工具的目的始终是更好地解决人类的问题,辅助人更高效地生活。面对层出不穷的新名词,不必将其视为负担——去了解它,问AI一句”这到底是什么”,成本远比你想象的低。
申明:文中图片均由ChatGPT Images 2.0生成
牛油果进化论
一个现代趣味博物小馆
你也许会好奇
