 夜雨聆风
夜雨聆风





AI开源工具清单:从语音克隆到自动剪辑,这些项目值得收藏
今天在整理文件夹的时候,我突然意识到一个问题。
我这一年下来,光是找到好用的AI工具、验证能不能跑通、研究怎么配置环境,花的时间可能比真正用起来的时间还多。
这种感觉太熟悉了。就跟当年学编程一样,光是配环境就配了一周,真正写代码反而只用了两天。
AI工具也是这样。前期调研的时间成本,有时候比工具本身的价值还高。
所以今天,我把最近折腾过的几个开源项目整理了一下。不整虚的,每个都带完整GitHub链接,保证你能直接clone下来跑通。
一、语音克隆工具:5秒音频就能克隆你的声音
先说一个最近让我特别兴奋的方向——语音克隆。
说实话,我以前觉得这东西是专业人士才能玩的。需要录音棚、需要高质量音频、需要大量算力。普通人根本沾不上边。
但现在不一样了。
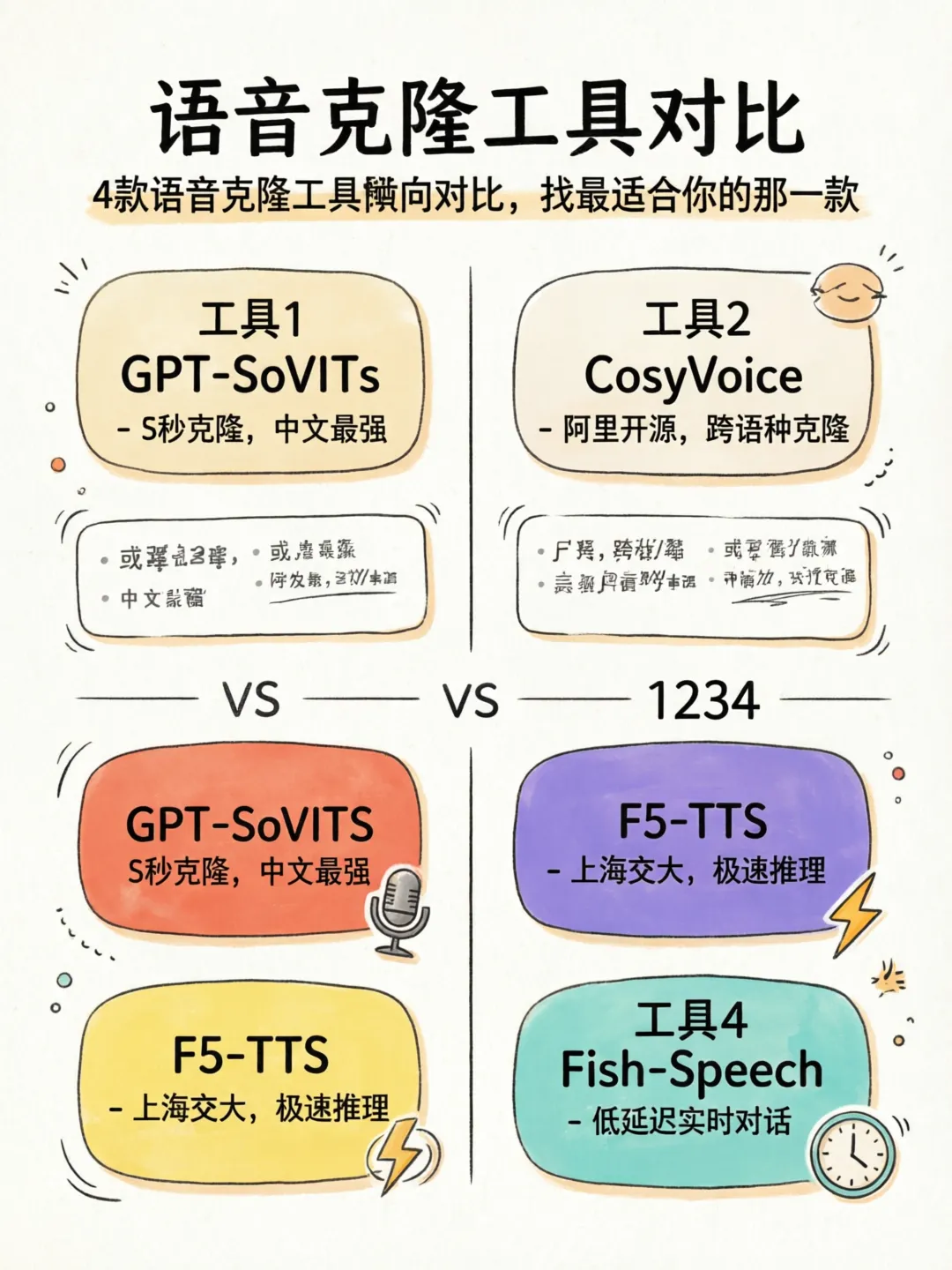
GPT-SoVITS
GitHub: https://github.com/RVC-Boss/GPT-SoVITS
这个项目最大的特点是门槛低到什么程度呢?
你给它5秒的音频,它就能复刻出你的声音。
5秒。就录一句话的功夫。
我用它测试了一下,录了自己读的一段话,然后让它用我的声音读了一段完全不同的内容。效果怎么说呢,有七八分像了。
对于普通用户来说,最友好的地方在于它有Windows集成包。下载下来,双击一下,直接就能跑。不用折腾什么conda、Python环境这些。
它的核心功能包括:
- Zero-shot TTS:5秒音频即时克隆
- Few-shot TTS:1分钟训练数据微调,音色更逼真
- 跨语言支持:中文、英文、日文、韩文、粤语都能跑
推理速度也不错。用RTX 4060Ti的话,1400字大概需要4分钟。如果是RTX 4090,那更快。
想体验的话,它有Hugging Face的在线Demo可以直接试:https://lj1995-gpt-sovits-proplus.hf.space/
CosyVoice
GitHub: https://github.com/FunAudioLLM/CosyVoice
这个是阿里出的开源项目。
相比GPT-SoVITS,它有一个很骚的功能——跨语种克隆。你给它一段中文音频,它可以用这个声音说英文。
坦率的讲,这对做跨境内容的朋友来说,应该挺有用的。
最低只需要3秒音频就能开始克隆,零样本复刻能力很强。多语言场景下用它会比较顺手。
F5-TTS
GitHub: https://github.com/SWivid/F5-TTS
上海交大开源的项目。
我是真的觉得,这个项目的强项是速度。极速推理,支持超长文本,而且可以做流式输出。
如果你是做批量生成的,比如需要快速生成大量语音内容,这个会非常合适。
我测试了一下,15秒的音频样本就能开始工作,生成出来的内容很流畅。
Fish-Speech
GitHub: https://github.com/fishaudio/fish-speech
这个项目的特点是什么?低延迟。
如果你做实时对话、数字人、语音助手这类场景,需要延迟越低越好。Fish-Speech就是为这个设计的。
它也支持多语言,中文效果不错。
二、自动剪辑视频:AI帮你剪掉口癖和废话
说完语音,再说说视频。
最近我花了点时间研究自动剪辑视频的工具。说真的,想看看AI能不能帮我把那些口播视频里的废话剪掉。
结果发现,这个领域已经有很多可以用的东西了。

video-use
GitHub: https://github.com/browser-use/video-use
这个是最近最火的一个。
它是一个Claude Code的Skill。简单来说,你把原始视频素材丢进一个文件夹,然后跟Claude Code对话,告诉它你想怎么剪辑,最后它会输出一个final.mp4。
核心功能包括:
- 自动剪掉口头禅(嗯、啊、false start)和镜头间的空白
- 自动对每个片段调色,支持暖色电影风、中性冲击感
- 每个剪切点加30ms音频淡入淡出,消除爆音
- 自动烧录字幕,默认两词一组全大写,可完全自定义
- 通过Manim、Remotion或PIL生成动画叠加层
- 每次渲染完成后在每个剪切点自动自评,通过后才呈现给你
- 用project.md持久化会话记忆,下次打开继续上次进度
这个东西最骚的地方在于,它不是那种「一键剪辑」的黑盒。你可以通过对话来精细控制剪辑逻辑。比如「把所有出现’呃’的地方剪掉,但保留语速正常的地方」,这种模糊需求它都能理解。
安装方式也很简单:
git clone https://github.com/browser-use/video-usecd video-useln -s "$(pwd)" ~/.claude/skills/video-usepip install -e .brew install ffmpeg需要Python 3.8以上,以及FFmpeg。
videocut-skills
GitHub: https://github.com/Ceeon/videocut-skills
这个是专门为口播视频设计的Claude Code Skill。
我测试了一下,19分钟的口播原片,丢进去,它自动识别了608处问题。其中静音114处,口误/重复494处。剪辑后视频72MB,全程AI辅助,人工只需要确认。
对比一下剪映,它有几个明显优势:
- 语义理解:AI逐句分析,识别重说、纠正、卡顿。剪映只能模式匹配
- 静音检测:超过0.3秒自动标记,可调节阈值。剪映是固定阈值
- 重复句检测:相邻句开头超过5字相同就删前保后。剪映没有这个功能
- 词典纠错:可以自定义专业术语词典。剪映没有
- 自更新:记住你的偏好,越用越准
对于做口播内容的朋友来说,这个工具应该挺有用的。
Pilipili-AutoVideo
GitHub: https://github.com/OpenDemon/Pilipili-AutoVideo
这个项目的定位是全自动AI视频代理。
特点是「一句话生成带字幕成片」。你给它一个主题描述,它直接给你输出一段完整的视频。
支持本地部署。2026年3月刚刚做了大更新,修复了竖屏比例、角色一致性、风格漂移、字幕清洗等8个问题。
如果你想要一个完全自动化的流程,不想在剪辑上花太多时间,这个可以试试。
Crayotter
GitHub: https://github.com/idwts/Crayotter
这个项目的核心理念很有意思。
它把视频生成拆成了三个阶段:规划、剪辑研究、工具执行。不是把所有过程塞进一个大模型,而是分工合作。
每个阶段专注做一件事,串联起来完成整个视频创作流程。
有在线演示可以体验:https://idwts.github.io/Crayotter
三、LLM应用模板库:100多个可以直接跑的Agent
说完具体的工具,再说一个让我眼前一亮的项目。
awesome-llm-apps
GitHub: https://github.com/Shubhamsaboo/awesome-llm-apps
这个项目收录了100多个LLM应用模板,全部可以clone下来直接跑。
许可证是Apache-2.0,可以商用,没有付费墙、没有注册、没有遥测。
它的定位是「LLM应用的Cookbook」。就像做菜有食谱,做LLM应用有这个模板库。
模板按功能分类:
- Starter AI Agents(12个):单文件Agent,只需API key即可运行
- Advanced AI Agents(21个):生产级Agent,含工具、记忆、多步推理
- Multi-agent Teams(13个):多Agent协作
- Voice AI Agents(4个):语音Agent
- MCP AI Agents(5个):MCP协议Agent
- RAG(19个):检索增强生成
- Agent Skills(19个):Agent技能系统
每个模板都是手写的原创代码,经过端到端测试才发布。3条命令就能运行,没有坏的requirements.txt。
支持的模型也很全面:Claude、Gemini、GPT、Llama、Qwen、xAI,一行配置就能切换。
快速开始:
git clone https://github.com/Shubhamsaboo/awesome-llm-apps.gitcd awesome-llm-apps/starter_ai_agents/ai_travel_agentpip install -r requirements.txtstreamlit run travel_agent.py每个模板都有免费的step-by-step教程,地址是 https://www.theunwindai.com
说在最后
如果你也在折腾这些工具,别嫌麻烦。多花点时间把环境配好、把流程跑通,后面会省很多事。
这种投资,值。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~
谢谢你看我的文章,我们,下次再见。
作者:剑飞,本文共3800字