在上一文章中,我们已经简单介绍了TTS和STT技术的基本概念,也推荐了部分国内外常用的云语音服务平台。有兴趣的朋友应该都已经登录到相关的平台去体验语音处理相关的业务了 。你是否也发现:各大语音服务平台一般不光只有STT和TTS服务,还有很多其他新鲜的玩法,比如:语音播客、音色设计、同声传译、实时语言交互、声音复刻、语音合成等等
。你是否也发现:各大语音服务平台一般不光只有STT和TTS服务,还有很多其他新鲜的玩法,比如:语音播客、音色设计、同声传译、实时语言交互、声音复刻、语音合成等等 。
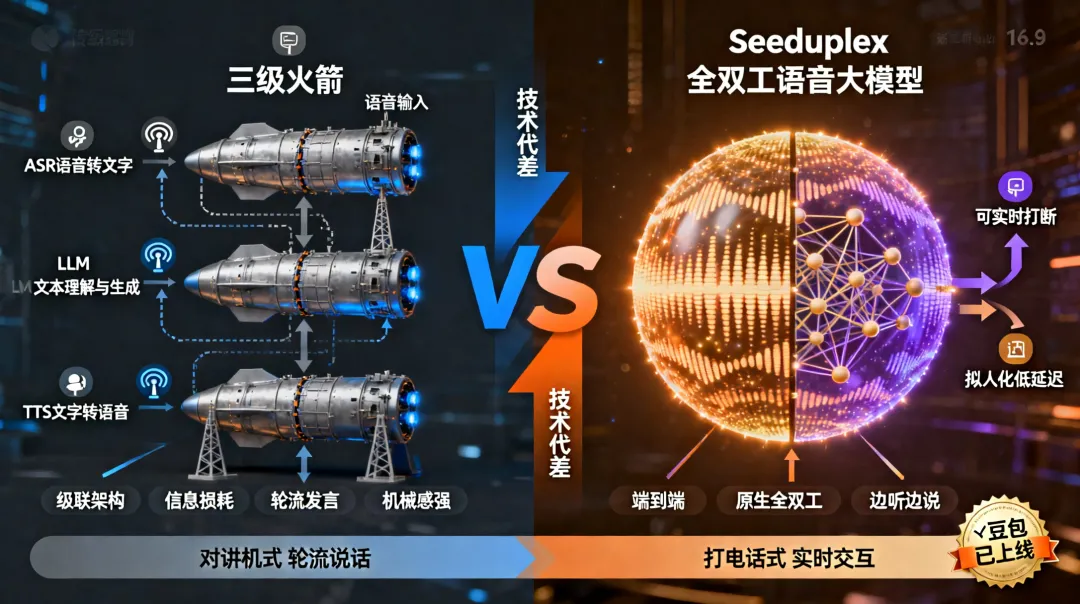
特别是火山引擎的豆包实时语音交互功能,它是基于Doubao实时语音大模型的端到端真人级语音对话模型,语音极具表现力。当然,它已经不只是一个简单的TTS和STT模型了,因为它有Doubao大模型作为后台支撑,你无需再依赖其他大模型就能轻松实现AI对话,等同于传统的大语言模型 + STT/TTS的综合模型:
当然,今天的重点不是讲豆包的实时语音交互,而是STT和TTS的基础应用。所以,还是继续选择任意的大模型(LLM) + STT/TTS的方式来进行开发。在此之前,因为要用到语音的录入和播放功能,需在Windows平台上先编写基础的录音和播放接口(使用pyaudio和wave库):
。
特别是火山引擎的豆包实时语音交互功能,它是基于Doubao实时语音大模型的端到端真人级语音对话模型,语音极具表现力。当然,它已经不只是一个简单的TTS和STT模型了,因为它有Doubao大模型作为后台支撑,你无需再依赖其他大模型就能轻松实现AI对话,等同于传统的大语言模型 + STT/TTS的综合模型:
当然,今天的重点不是讲豆包的实时语音交互,而是STT和TTS的基础应用。所以,还是继续选择任意的大模型(LLM) + STT/TTS的方式来进行开发。在此之前,因为要用到语音的录入和播放功能,需在Windows平台上先编写基础的录音和播放接口(使用pyaudio和wave库):
第一步,先写一个可以从麦克风录音,并记录为 .wav 格式音频文件的 audio.py 代码:
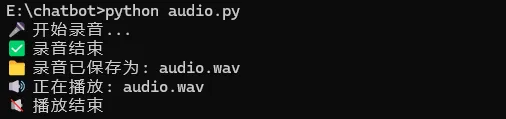
#import waveimport pyaudio# 录音参数设置FORMAT = pyaudio.paInt16 # 采样位深CHANNELS = 1 # 单声道RATE = 44100 # 采样率 44.1kHzCHUNK = 1024 # 每次读取的数据块大小# 默认录音时长RECORD_SECONDS = 5def audio_record(filename, duration=RECORD_SECONDS): """ 从麦克风录音并保存为 .wav 文件 """ p = pyaudio.PyAudio() # 打开音频流 stream = p.open(format=FORMAT, channels=CHANNELS, rate=RATE, input=True, frames_per_buffer=CHUNK) print("🎤 开始录音...") frames = [] for _ in range(0, int(RATE / CHUNK * duration)): data = stream.read(CHUNK) frames.append(data) print("✅ 录音结束") # 停止和关闭流 stream.stop_stream() stream.close() p.terminate() # 保存为 WAV 文件 wf = wave.open(filename, 'wb') wf.setnchannels(CHANNELS) wf.setsampwidth(p.get_sample_size(FORMAT)) wf.setframerate(RATE) wf.writeframes(b''.join(frames)) wf.close() print(f"📁 录音已保存为: {filename}")if __name__ == "__main__": # 录音5秒钟 audio_record("audio.wav", 5)
执行上面代码,终端调试输出如下,并在当前目录下生成一个名为 audio.wav 的文件,该文件可以直接用任意音频播放器打开播放:
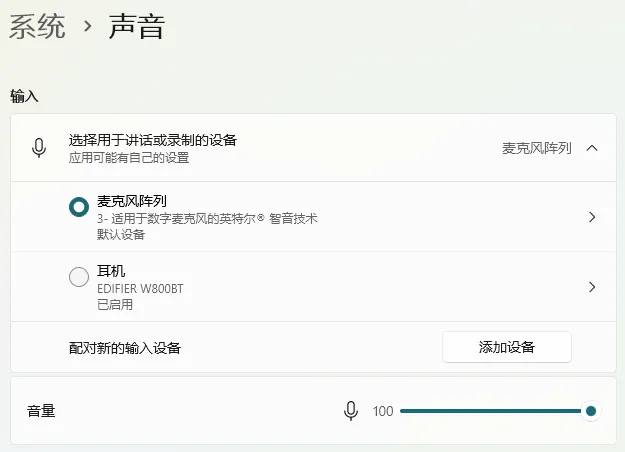
注意:该代码依赖并使用到电脑的默认音频输入接口。也就是说你的电脑必须要有音频输入设备,不管是笔记本电脑自带的麦克风阵列,还是你外接的耳麦。当然,如果你的电脑有多个音频输入设备,比如自带麦克风阵列的笔记本,同时又外接了耳麦 ,这种情况下,代码会自动使用你电脑设置的默认音频输入设备,例如:
上面截图中,电脑默认使用笔记本自带的麦克风阵列作为声音输入设备,可以通过修改系统默认输入设备来切换录音来源。当然,也可以忽略系统默认设置,直接修改代码来指定选择从哪一个输入设备录音。只需改一行代码就行:
,这种情况下,代码会自动使用你电脑设置的默认音频输入设备,例如:
上面截图中,电脑默认使用笔记本自带的麦克风阵列作为声音输入设备,可以通过修改系统默认输入设备来切换录音来源。当然,也可以忽略系统默认设置,直接修改代码来指定选择从哪一个输入设备录音。只需改一行代码就行:
# 打开音频流stream = p.open(format=FORMAT, channels=CHANNELS, rate=RATE, input=True, input_device_index=1, frames_per_buffer=CHUNK)
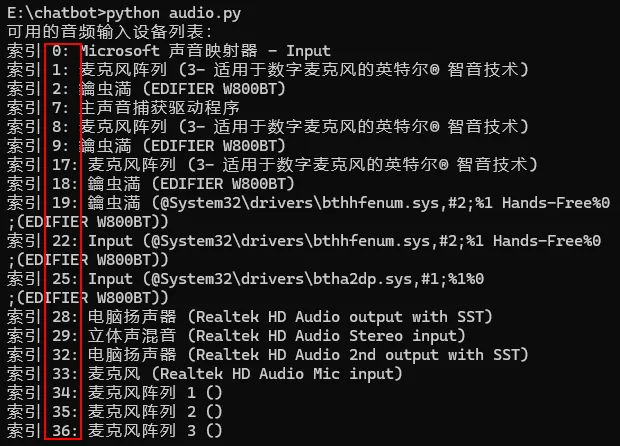
如上,只需在打开音频流的代码里加入一个input_device_index=xx的参数即可。xx是你的音频设备的索引号,如果不知道索引号是如何分布的,可以先通过如下代码来获取详细信息:
#import pyaudiodef audio_list_dev(): """ 罗列可用音频设备列表 """ p = pyaudio.PyAudio() print("可用的音频输入设备列表:") for i in range(p.get_device_count()): dev_info = p.get_device_info_by_index(i) # 只显示有输入通道的设备(即麦克风) if dev_info.get('maxInputChannels') > 0: print(f"索引 {i}: {dev_info.get('name')}") p.terminate()if __name__ == "__main__": audio_list_dev()
执行上述代码,将会罗列出你当前电脑上所有的音频输入输出设备,其中的索引号就是你要赋值给input_device_index的值,例如0、1、2…18等,有兴趣的朋友可以试一下切换其他MIC输入,没兴趣直接跳过,没啥影响!
除非你的应用有特殊的要求(需动态切换输入设备),否则若只是简单测试,强烈建议使用第一种方法,即直接使用或修改系统默认输入设备即可,安心省事!此外,上面代码实现的audio_record接口是指定了固定录音时间的,即从启动录音到结束录音的间隔是固定的,你必须在这个固定的时间间隔里把话说完 。
如果你想做到灵活地控制开始录音和结束录音(类似微信上发语音信息的过程:按住语音键开始说话,放开结束),需要稍微修改一下代码。比如,把录音功能写成后台线程运行的方式,然后通过指令去控制启动和结束。具体实现可以参考作者在Gitee上的完整代码:
。
如果你想做到灵活地控制开始录音和结束录音(类似微信上发语音信息的过程:按住语音键开始说话,放开结束),需要稍微修改一下代码。比如,把录音功能写成后台线程运行的方式,然后通过指令去控制启动和结束。具体实现可以参考作者在Gitee上的完整代码:
https://gitee.com/sml-ai/chatbot.git
第二步,我们来实现音频播放的功能,也就是将 .wav 格式的音频通过喇叭播放出来。在上面已有录音代码的基础上,添加如下代码:
#import osimport time# 原有代码....def audio_play(filename): """ 播放 .wav 音频文件 """ if not os.path.exists(filename): print(f"❌ 文件不存在: {filename}") return wf = wave.open(filename, 'rb') p = pyaudio.PyAudio() stream = p.open(format=p.get_format_from_width(wf.getsampwidth()), channels=wf.getnchannels(), rate=wf.getframerate(), output=True) print(f"🔊 正在播放: {filename}") data = wf.readframes(CHUNK) while data: stream.write(data) data = wf.readframes(CHUNK) stream.stop_stream() stream.close() p.terminate() wf.close() print("🔇 播放结束")if __name__ == "__main__": # 录音5秒钟 audio_record("audio.wav", 5) time.sleep(2) # 播放录音文件 audio_play("audio.wav")
上面已经实现了最简单的本地录音和播放功能,接下来就要通过API的方式来使用云平台的TTS和STT功能了。上一篇文章我们说过:当下支持API调用的云语音平台有很多,如果只是简单的学习和测试,建议选用提供免费试用的云平台即可。例如字节跳动的火山引擎,其豆包语音模型非常不错,它提供了非常富足的免费使用额度,可以放心大胆使用!而且,即使后续你想切换到收费模式,其性价比也是业界TOP1的存在(特此声明:没有任何广告意图,纯属个人建议,其他平台也很不错,你不一定非得选豆包)。
第一步,先到火山引擎官网上去注册账号。注意:需要完成手机号验证和实名认证等操作。关于如何使用,官网上有完整的入门教程。从账号注册到业务开通,到模型使用再到API和SDK调用等都有极详细的介绍,官网地址如下:
https://www.volcengine.com/
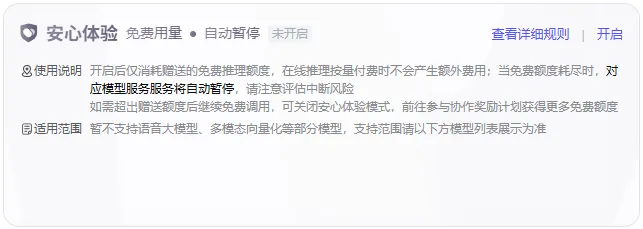
可考虑开启安心体验模式,该模式下可以保障免费体验模型的推理服务,又不产生费用,你调用推理API时,仅消耗平台赠送的50W token的免费额度,接近免费额度后服务暂停,避免产生额外费用。该模式需要自己手动开启哦!
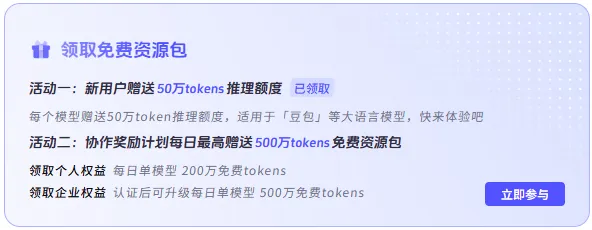
此外,新用户还可以参与领取免费资源包活动,但是参与该活动需要关闭安心体验模式,且一旦关闭安心体验模式,将不可再次开启,超出免费使用额度后将按实际消耗的token计费,请读者谨慎操作,自行判断选择哪种方式:
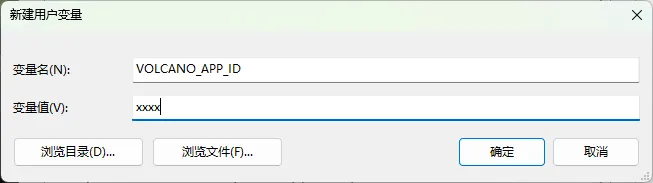
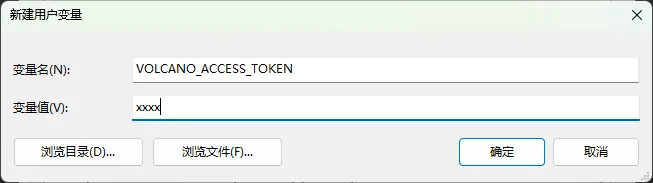
模型开通后,需在详情页面获取APP ID和Access Token(访问令牌),妥善保管,后续代码中需要用到。首次开通默认为试用版,享有免费的使用额度。若后续继续开通正式版,试用版赠送的免费额度将自动清空,请谨慎操作。
为了避免APP ID和Access Token泄露,建议不要将它们写死在代码里,而是写到你的系统环境变量中,代码里通过环境变量获取即可:
注意:Windows设置环境变量后,需要先关闭已经打开的命令行终端,然后重新打开才能生效,否则你获取回来的环境变量值将是空的。使用Python获取Windows环境变量方法如下:
# 从环境变量获取API KEY 和 Accecss TokenVOLCANO_APP_ID = os.environ.get("VOLCANO_APP_ID")VOLCANO_ACCESS_TOKEN = os.environ.get("VOLCANO_ACCESS_TOKEN")
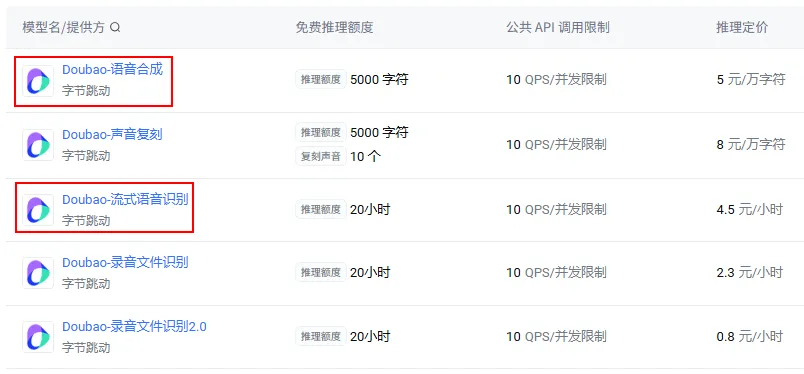
对于火山引擎的TTS和STT的详细使用方法,其官方有详细的指导文档和参考代码,这里就不复述官网已经详细介绍过的内容了:
https://www.volcengine.com/docs/6561/163043?lang=zh
我们在官网提供的参考代码基础上,为了契合我们的测试,进行了二次封装,代码已经放到我们的Gitee库上:https://gitee.com/sml-ai/chatbot.git可直接下载使用。我们将本地语音的录入和播放功能统一封装成一个AudioProcessor类;把火山引擎的TTS和STT功能也分别封装成了VolcanoTTS类和VolcanoSTT类。然后再整合到我们前面实现好的聊天AI主代码框架中,进而实现了让AI用语音的方式来和我们进行聊天(同步显示文字)。
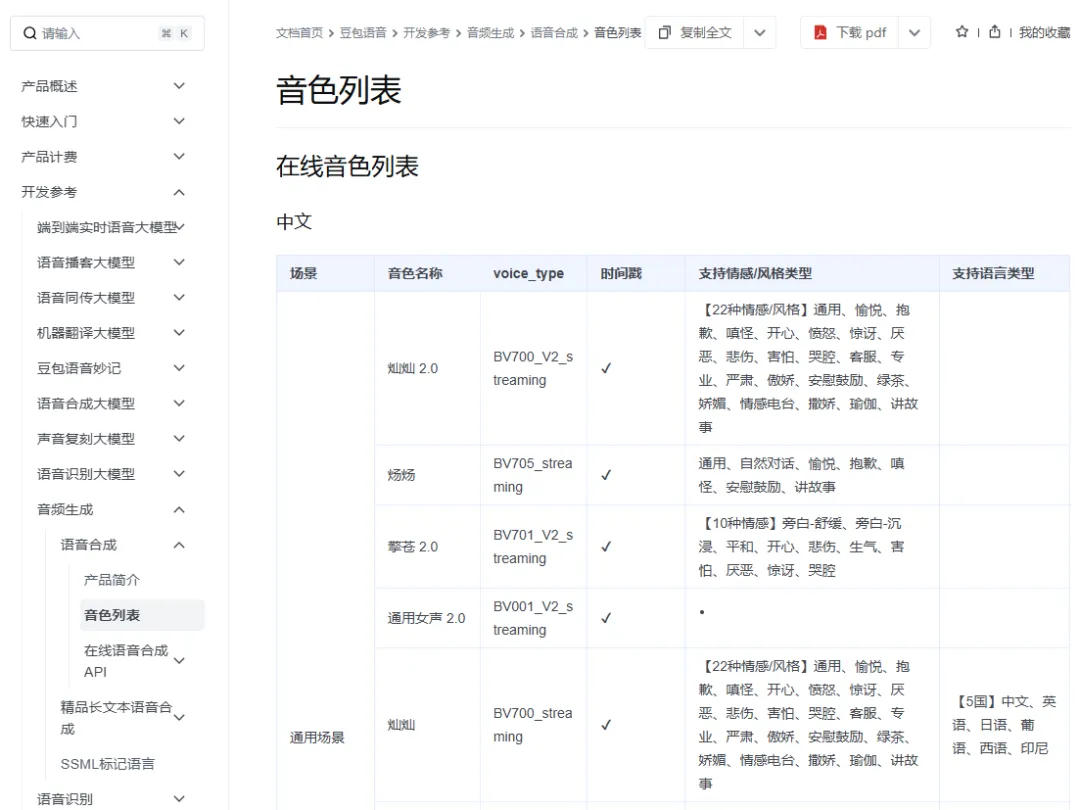
值得说明的是:对于TTS模型,火山引擎官方提供了大量的音色类型(包括不同的性别、年龄、场景、方言等),火山引擎官网上有详细的音色列表及对应的音色代号,我们提供的代码也对部分音色进行了二次封装(通过TTSVoice类)。用户可通过voice_type参数来设置音色。默认是通用女声“BV001_streaming”,可以在类实例化时设置为任意其他支持的音色:
class VolcanoTTS: """ 火山引擎文字转语音(TTS)封装类 """ def __init__(self, app_id: str, access_token: str, voice_type: str = TTSVoice.BV001): """ 初始化 TTS 客户端 Args: app_id: 火山引擎应用 ID access_token: 火山引擎访问令牌 voice_type: 音色类型(使用 TTSVoice 常量,默认女声) """
读过前面文章的都知道,我们前面实现的AI聊天机器人是通过命令行终端的方式来进行交互的,该方式下要实现灵活的语音输入有点困难,所以下面的例子中我们都只用到了TTS功能,没有用到STT。等我们后面把聊天AI做成GUI或者移动APP方式时实现起来就简单多了。
# 初始化 TTStts_cli = VolcanoTTS(VOLCANO_APP_ID, VOLCANO_ACCESS_TOKEN, TTSVoice.BV025)
# 初始化 TTStts_cli = VolcanoTTS(VOLCANO_APP_ID, VOLCANO_ACCESS_TOKEN, TTSVoice.BV213)
如果对其他音色感兴趣,请读者自行尝试,还是挺好玩的。此外,如果直接使用豆包语音大模型(非单纯的TTS和STT),它还支持角色性格设定和情感预测等更高级的使用方法,这个目前在情感陪伴类AI玩具行业应用已经非常广泛。后续有机会我们做一个对应的使用案例。
事实上,你完全可以直接在火山引擎官网上体验它的各种音色,不必通过我们封装的代码来体验。当然了,我们用API调用的方式来封装一遍也并非多此一举。一方面是为了更好的了解技术原理,另一方面也是为了融入后续的嵌入式服务平台而准备的。有兴趣的可继续关注后续。
本文由智源科普原创,转载请注明来源;文中部分图片源于网络,如有侵权可联系我们删除;本文内容仅代表个人观点,无任何政治立场、无任何商业目的,且个人见识有限,不当之处请各位看官权当笑话,不喜勿喷。
 夜雨聆风
夜雨聆风