 夜雨聆风
夜雨聆风





扒开源码才发现:为什么你的 Claude Code token 烧得比别人快 10 倍?
致读者: 本篇文章 4600+ 字,预计阅读时间 14min。频繁 /clear 不省 token,反而更烧——这是我跑了一年 Claude Code 之后最贵的一条反共识。如果你正在用 CC 写代码 / 跑 skill / 做 agent,建议读完。每一条都有数字和官方背书。
01. 一个让我盯着账单看的下午
去年 11 月某天下午,我打开 Claude Code 的用量后台。
那天我没干什么大事——就是日常写代码、改 bug、写文。我估算总对话量 3-4 小时。
后台数字给我看傻了:
当日 input tokens 累计 480 万
按 Claude Pro 配额 5 小时一档算,这一天我已经把一周的额度烧掉一半。
我没在跑 batch,没在做 RAG,没让 AI 跑长任务。就是普通对话。为什么这么猛?
我把当天的会话回放了一遍——发现一件事——
那天我开了 17 次新会话 + 12 次 /clear。
平均每 7 分钟一次”重启”。每次重启的理由都很合理——”任务变了”、”上下文乱了”、”想清空一下”。
那时候我有一个根深蒂固的认知——
对话越长越烧 token,所以应该频繁 /clear。
后来我深挖了 Claude Code 的源码、官方 issue、Boris 的回复——才发现这个认知是完全错的。
不仅没省 token,反而让我多烧了 10 倍。
这篇文章讲的就是这一年我踩过的 5 个反共识。每一条都有数字、有官方背书、有我自己的实测。

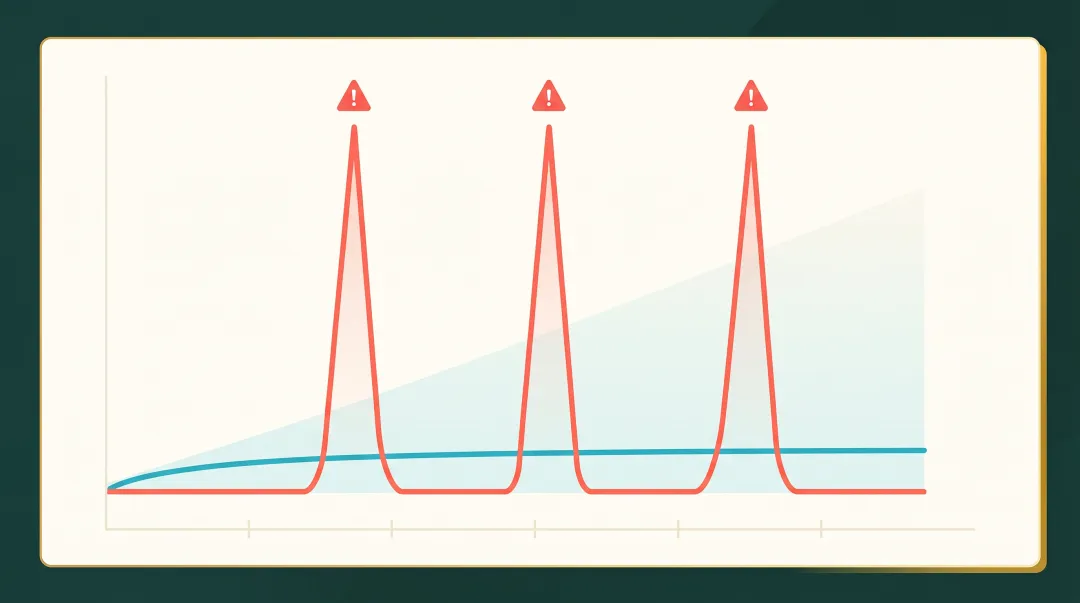
02. 反共识 1 · /clear 不省 token,反而更烧 10 倍
先讲机制,再讲数字。
Claude Code 用的是 提示缓存(prompt caching)——
每次对话开始,模型会把”系统指令 + CLAUDE.md + Skills 描述 + MCP 工具定义”这堆前缀内容算一次”指纹”,存起来。下一轮对话来的时候——
-
如果前缀没变 → 直接命中缓存,只花 1/10 的钱 -
前缀变了(比如修改了 CLAUDE.md、加了新 skill)→ 缓存失效,全量重建
关键的反共识来了——
/clear会清空整个对话上下文——但不只是对话,它把缓存也清掉了。
下一条消息来的时候—— – 系统指令要重新算 – CLAUDE.md 要重新算 – 全部 skills 要重新算 – MCP 工具要重新算
这个”前缀重建”,本身就要 5 万 token。
而你 /clear 之前那段历史对话,重读它的成本只有 1/10 价——比如 5 万 token 的历史,重读只算 5 千。
数学一下——
|
|
|
|---|---|
|
|
|
/clear
|
|
差了 10 倍。
我那天频繁 /clear 12 次——相当于每次都把”刚交完房租的房子”再重新装修一次。
这是 Anthropic 团队 Boris(Claude Code 项目负责人)在 GitHub issue #45756 里官方确认过的——他用了一句话——
“a surprisingly large number of users” 都踩了这个坑(频繁清空 + 大量 skills + 后台 agent 是配额异常的 top 2 元凶)。
正确的姿势是——
✅ 任务没变 + 上下文还在用 → 继续聊,缓存全热 ✅ 任务真的换了 / 闲置 > 1 小时 / 上下文被无关内容塞满 → 才开新会话
不要每隔 10 分钟就手痒按一下 /clear。
那个”我感觉对话变长了,应该清一下”的念头——那是错觉。
03. 反共识 2 · Skills 是隐形 token 黑洞,不是 MCP
这条更猛。
我以前以为 token 大头是—— 1. CLAUDE.md(每轮加载) 2. MCP 工具定义(每个 MCP 服务器一份) 3. 对话历史
错。
真正的大头是 Skills。
机制:你 ~/.claude/skills/ 里每个 skill 的 SKILL.md 全文,都会在每一轮对话注入到系统提示词里。AI 要靠读 SKILL.md 来判断什么时候触发哪个 skill。
我去年装了 25 个 skill——为了”用得方便”。包括飞书全套(lark-base / lark-mail / lark-doc / lark-im / lark-calendar / lark-task)、PPT 生成、图标搜索、各种内容工具。
每个 skill 平均 5-10KB,大的(lark-base 26.8KB / frontend-slides 20.8KB)。
我做了一次实测——
| 项目 | 数量 | 预估 token |
| ----------- | ------ | ---------- |
| 系统基础 | — | 2,500 |
| CLAUDE.md | 943B | 300 |
| MEMORY.md | 11.6KB | 3,900 |
| Skills(25个)| 173KB | 43,375 | ← 这里
| 插件 | 1个 | 500 |
| MCP | 0个 | 0 |
| 单轮固定开销 | — | ~50,500 |
Skills 一项,43375 token / 轮——占了固定开销的 86%。
CLAUDE.md 才 300 token。MEMORY.md 才 3900 token。Skills 是它们的 10-100 倍。
按半小时 20 轮对话算——仅 skill 描述就烧 87 万 input tokens。一周下来烧掉配额的 7%——而我那天根本没用上几个 skill。
它们是沉默地、每一轮、注入到提示词最前面的隐形开销。
我做的事是——
-
列出最近一个月真正用过的 skill(只有 6 个:飞书 IM/Doc/Calendar/Task/Shared + better-icons) -
把另外 19 个全部 mv 到 ~/.claude/skills-disabled/(不真删,随时恢复) -
重测——Skills 从 43K 降到 9.2K,单轮固定开销从 50K 降到 16K
每轮省 34K token,半小时 20 轮 ≈ 省 68 万 input tokens / 轮,约一周配额的 7%。
这是我做过的最高 ROI 的一次优化——花了 10 分钟,省了一周配额的 7%。

恢复也简单:
mv ~/.claude/skills-disabled/lark-base ~/.claude/skills/
如果某个 skill 一个月没用过——它就不该在全局。
04. 反共识 3 · 续聊比开新会话省 6-10 倍
这条跟反共识 1 是一对。
很多教程会教你”长对话效果会下降,建议频繁开新会话”。
这是没考虑缓存的错误结论。
实际机制——
活跃会话(< 1 小时无闲置): – 历史部分永远命中缓存 → 只付 1/10 价 – 新消息追加在末尾 → 按全价算(这部分本来就要付) – 总成本 = 1/10 历史 + 全价新消息
新会话: – 系统指令 + CLAUDE.md + Skills + MCP 全部重新算 → 5 万 token 前缀全价 – 第一条消息按全价 – 总成本 = 5 万前缀 + 全价新消息
差距:续聊每轮 5K 历史成本 vs 新会话每轮 50K 重建成本——10 倍。
我以前的错误习惯——
写完一段代码,觉得”任务结束了”,就
/clear开新会话准备下一个。
实际上 如果下一个任务还在同一个项目里、同一个上下文里——继续聊更省。
正确的转生信号(必开新会话)——
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
没有这些信号——继续聊。
我现在的硬规矩是——手指要按 /clear 之前先停 2 秒——问自己:
这次 /clear 是因为”任务真的换了”,还是只是”我感觉对话太长了”?
80% 的情况是后者——而后者就是个错觉。
05. 反共识 4 · 会话中途切模型反而更贵
这条是 2026 年新踩的坑。
我以前以为——
“用 Opus 写代码烧得快,那中途切 Sonnet 不就省了吗?”
错。
机制:缓存按模型隔离。Opus 和 Sonnet 各自维护自己的缓存。
会话中途切模型——
-
Opus 这边的缓存 → 作废(你用不到了) -
Sonnet 这边的缓存 → 从零开始重建(5 万 token 前缀)
结果:你不仅没省钱,反而把已经付过缓存费的 Opus 上下文全部浪费,还多付了一次 Sonnet 重建成本。
正确的做法——
不同任务用不同会话——每个会话锁定一个模型,从头到尾不切。
需要轻量任务时—— – 开子代理(隔离上下文)让它用 Sonnet/Haiku – 或者单独开一个 Sonnet 会话专做轻量活 – 或者用 /fast 模式(同一会话内不断缓存)
永远不要中途切模型。
补一条额外细节——Opus 的 token 消耗是 Sonnet 的 2 倍。不只是单价贵 1.7 倍——输出 token 也多(推理深度大,自然写得多)。
我现在的硬规矩——
-
日常编码:默认 Sonnet -
架构决策 / 多步推理 / 复杂方法论:用 Opus -
简单数据整理 / 前端样式微调:用 Haiku(或 /fast)
专人专岗,模型不要中途切。
06. 反共识 5 · 1M 上下文是配额杀手
最后一条最隐蔽,也最危险。
2026-03 起,Max/Team/Enterprise 用户默认启用 Opus 4.6 的 1M 上下文窗口(不再收 2x 溢价)。
很多人开心——”终于不用频繁压缩了”。
但 Boris 在 issue #45756 直接说——1M 上下文 + 缓存过期是当前配额异常的头号原因。
机制——
你用 1M 上下文跑了一段长会话——比如积累了 80 万 token 的上下文。 然后离开电脑去吃饭、开会,1 小时之后回来。 1 小时 = 缓存 TTL 过期。 你随手打一句”那个函数怎么样了”——
这一条消息触发了 80 万 token 的全量重建。
单次成本是日常对话的 5-10 倍。
我自己踩过这个坑一次。下午接了通电话,2 小时后回来发问,结果当晚配额直接见底。
正确的做法——
方案 A · 直接禁用 1M(保守)
在 ~/.claude/settings.json 里加:
{
"env": {
"CLAUDE_CODE_DISABLE_1M_CONTEXT": "1"
}
}
方案 B · 保留 1M 但设压缩阈值(推荐)
{
"env": {
"CLAUDE_CODE_AUTO_COMPACT_WINDOW": "200000"
}
}
接近 20 万 token 时自动压缩摘要,保留连续性又防止 1M 触发缓存重建。
何时真的需要 1M—— – 一次性加载大型代码库做全局重构 – 长时间多轮对话且不能被压缩打断
日常写代码 / 改 bug 完全用不上——多数会话 80-120K 就触发压缩了。
社区实测——上下文 > 200K 后模型表现明显下降,> 350K 基本靠运气。
1M 不是好东西,是陷阱。

07. 我的诊断流程 · 4 步定位流量大头
讲完 5 个反共识,给一份可执行的体检流程。
我每周一会跑一次。10 分钟搞定。
Step 1 · 量配置
# Skills 数量和总大小(最关键)
total=0
for d in ~/.claude/skills/*/; do
f="$d/SKILL.md"; [ ! -f "$f" ] && f="$d/skill.md"
if [ -f "$f" ]; then
size=$(wc -c < "$f")
total=$((total + size))
printf " %-35s %6d bytes (~%d tokens)\n" "$(basename $d)" "$size" "$((size/4))"
fi
done
echo "Skills总: $total bytes (~$((total/4)) tokens)"
输出长这样——
better-icons 2856 bytes (~714 tokens)
lark-im 9682 bytes (~2420 tokens)
lark-doc 7345 bytes (~1836 tokens)
...
Skills总: 173KB (~43375 tokens)
第一眼看 Skills 总数——如果 > 30K = 红灯,必砍。
Step 2 · 量 MEMORY.md / CLAUDE.md
wc -c ~/.claude/CLAUDE.md
wc -c ~/.claude/projects/*/memory/MEMORY.md
-
CLAUDE.md > 5KB = 偏胖,可压缩 -
MEMORY.md > 200 行 = 会被截断,必精简
Step 3 · 量 MCP
python3 -c "
import json
d=json.load(open('$HOME/.claude/settings.json'))
servers=d.get('mcpServers',{})
print(f'MCP 服务器: {len(servers)}个')
for k in servers: print(f' - {k}')
"
每个 MCP 服务器约 200-500 token / 轮——不大,但累积起来也烧。超过一周没用的关掉。
Step 4 · 算单轮总开销
单轮固定开销 ≈ 基础(2.5K) + CLAUDE.md + MEMORY.md + Skills(Σ) + MCP(N×300) + 插件
输出一个数字—— – < 8K = 🟢 健康 – 8-15K = 🟡 中等 – > 15K = 🔴 必须优化
我现在稳定在 16K 左右——主要是 6 个高频 skill + 70 行 MEMORY.md + claude-hud 插件。
08. 我的优化清单 · 按优先级排序
诊断完之后,按以下顺序优化——
🔥 优先级 1(立即可做,不影响功能)
- 移除不活跃的 Skills
——最大杠杆,每个大 skill 省 2-7K / 轮 - 关闭超过 1 周没用的 MCP
——每个省 200-500 / 轮 - MEMORY.md 索引精简到 80 行以内
——超 200 行会被截断 - 关闭功能重叠的插件
⚙️ 优先级 2(按需调整)
- Skills 分层
——高频留全局,低频移项目级 - CLAUDE.md 压缩到 < 200 行
——删可从代码推导的信息 - CLAUDE.md 里用 HTML 注释
<!-- -->写不想给 AI 看的备注
——注释会被剥掉,不花 token
🧠 优先级 3(使用习惯,最高杠杆)
- 搜索用 Glob/Grep,不 spawn Explore agent
——单次省 35-70K - 不要频繁 /clear
——保持缓存热(参见反共识 1) - 不要中途切模型
——参见反共识 4 - 死循环 80% 概率出现就立即打断
——AI 反复读同一文件 = 100% 浪费 - 复杂任务一次做对
——开扩展思考(thinking)一次搞定,比来回改 3 轮省
🔧 优先级 4(高级技巧)
permissions.deny限制 AI 阅读范围
—— ~/.claude/settings.json加:
{
"permissions": {
"deny": [
"Read(./.env*)",
"Read(./node_modules/**)",
"Read(./.venv/**)",
"Read(./build)"
]
}
}
防止 AI 误读 5 分钟无关文件。
- 命令行优先,MCP 其次
——能用 ghCLI 解决就别装 GitHub MCP(MCP 双向都要花 token) - Plan Mode 先规划再执行
——避免盲跑写一堆又推翻 - 缓存保活
——临时不输入时发条简短消息(”再等等”)续缓存
这套体系做下来,单轮固定开销从 50K 降到 16K,配额烧速降一半。
09. 收个尾 · 优化是认知问题,不是技术问题
回到开头——
我以前每天 /clear 十几次。
这个习惯背后是一个错的认知模型——”对话越长越烧,所以要频繁清”。
实际上——
Claude Code 的 token 经济不是”对话长度的线性函数”。
它是——
-
缓存命中 → 1/10 价 -
缓存失效 → 全价重建(重建本身就是 5 万 token)
如果你的认知模型还停在”长对话 = 浪费”——你会做出全是反向的优化决策——
-
频繁 /clear → 反复重建前缀 -
短对话切来切去 → 永远不在缓存里 -
装满 30 个 skill 觉得”工具多很 cool” → 每轮都在花 4 万
真正的优化不是”用得少”——是”用得对”。
具体到 5 条反共识——
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
每一条都跟”直觉”反着来——所以才容易踩。
最后——
如果你看完这篇文章只能记住一句话——
不要频繁 /clear。
90% 的 CC token 浪费,从手指按 /clear 那一秒开始。
下次手痒之前——看看上一条消息距现在多久。没超过 1 小时 → 别按。