 夜雨聆风
夜雨聆风





AI不仅能抓出数据“内鬼”,还能写出“诊断报告”?一文读懂AXIS时序异常解释框架
一、导语(Lead)
这篇论文解决什么问题:本文致力于解决时间序列异常检测(TSAD)中长期存在的“黑盒”问题,旨在让模型不仅能检测出异常,还能用人类自然语言准确解释异常的形态特征与发生原因。
为什么这个问题重要:在医疗、工业、航空航天等高风险领域,工程师和领域专家无法盲目信任冰冷的“异常分数”,他们迫切需要语义级别的诊断说明来辅助关键决策。
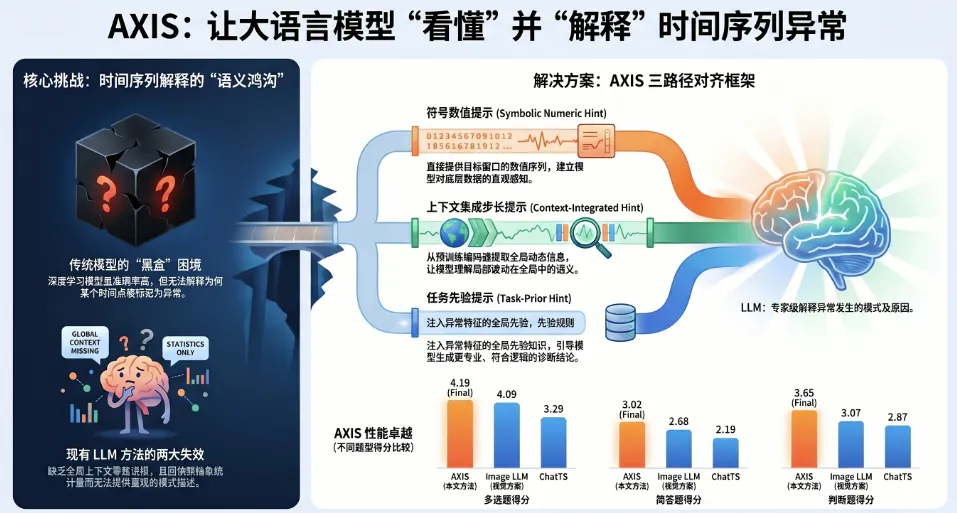
论文的核心创新是什么:作者提出了一种名为 AXIS 的开创性框架,它无需微调庞大的大语言模型(LLM),而是通过“数值型提示、步骤对齐上下文提示、任务先验提示”三大表征路径,成功跨越了连续时序信号与离散自然语言之间的语义鸿沟,并首创了专注于语义解释的时序异常基准测试数据集。
二、研究背景:为什么要解决这个问题?
在数字化和物联网技术飞速发展的今天,时间序列数据(Time Series Data)已经成为描述现实物理世界和复杂系统动态演变的最核心载体。从重症监护室里的连续心电图(ECG)、金融市场的秒级交易波动,到大型工业制造场景中旋转机械的振动信号、航空发动机的实时遥测数据,这些海量的时序数据中隐藏着系统健康状态的关键密码。时间序列异常检测(Time-Series Anomaly Detection, TSAD) 作为保障这些关键系统安全运行的“守门员”,其重要性不言而喻。
当前领域面临的核心问题
近年来,随着深度学习(Deep Learning)的普及,基于重构(如自编码器)、预测误差(如LSTM预测)以及注意力机制(如Transformer)的深度TSAD模型在检测准确率上取得了令人瞩目的成就。它们能够敏锐地捕捉到数据流中的微小异常波动。然而,这些深度学习模型在真实世界系统中的落地和广泛采用却面临着一个致命的瓶颈:它们本质上是一个彻头彻尾的“黑盒”(Black Box)。
想象一下,你是一名负责维护千万级别大型风力发电机的工程师。半夜两点,警报系统突然响起,AI模型输出了一串警告:“在时间步 450 到 500 之间,设备异常分数为 0.95,超过阈值。” 作为工程师,你面对这个数字会感到极其困惑和无力。你最想知道的、也是最务实的问题是:“为什么系统认为这里有异常?数据到底呈现了什么奇怪的形态?是突然的尖峰、长期的水平漂移,还是周期性规律被打破了?” 仅仅告诉你“有异常”,而不告诉你“为什么”,在关键任务场景下是毫无意义的。
现有方法的主要局限
为了打破这个黑盒,学术界和工业界曾尝试引入可解释性人工智能(Explainable AI, XAI)技术,最典型的代表是基于归因的方法,例如时间序列版本的 SHAP(SHapley Additive exPlanations)。这些事后解释(Post-hoc attribution)方法试图通过计算局部梯度或扰动输入,来告诉用户:“是哪些时间点的数据,或者哪些维度的特征导致了模型报警”。
然而,这种方法存在极其严重的局限性。它们提供的依然是底层的、缺乏语义的“统计关联”,而不是直观的“模式理解”。它们可能会输出一份报告说:“本次异常中,方差(Variance)的贡献度为 0.5,偏度(Skewness)的贡献度为 0.42,第 480 个时间点的特征重要性最高”。面对这样的解释,领域专家依然一头雾水:“方差和偏度只是抽象的统计学概念,数据当时的真实长相到底是什么样子的?” 现有的 XAI 技术只能揭示“是什么输入影响了模型”,却在解释“底层的异常事件到底是什么”这一问题上戛然而止。
为什么这个问题一直没有被很好解决
随着大语言模型(Large Language Models, LLMs)在自然语言处理领域的爆发,其强大的推理、上下文学习和语言生成能力让人们看到了曙光。人们开始尝试将时间序列输入给 LLM,期望它能像一个专家一样输出诊断报告。但这一尝试很快遭遇了滑铁卢,其根本原因在于两种模态之间存在巨大的“表征错位”与“语义鸿沟”。
LLM 天生是为处理离散的文本 Token 而设计的,而时间序列是长序列的、连续的浮点数值信号。如果采用最简单粗暴的“序列化(Serialization)”方法——也就是把时间序列的数字转换成字符串(比如 “1.23, 4.56, 7.89″)直接喂给 LLM,会遇到两个根本性失败:
-
1. 缺乏上下文基础(Contextual Grounding Challenge):受限于 LLM 的上下文窗口长度,我们通常只能把发生异常的那一小段局部数据(Snippet)切出来喂给模型。但这就像蒙着眼睛摸象。在时序数据中,判断一个局部出现的“V型波动”到底是不是异常,必须依赖于全局上下文。如果整个序列本身就是一个呈现 V 型震荡的周期函数,那么这个局部的 V 型就只是正常的周期波动(Benign fluctuation);如果不看全局,LLM 根本无法判断局部波动的真实含义。 -
2. 表征对齐失败(Representation Alignment Challenge):如果为了避免超出上下文窗口,我们不输入原始数据,而是输入预先计算好的统计摘要(比如“该段数据方差增大”),LLM 就会沦为一个毫无灵魂的“鹦鹉学舌”的翻译机。它的解释会退化为浅层的同义词替换(Circular explanations),根本无法提供领域专家所需的、基于波形几何形态(如“突发性尖峰”、“周期性缺失”)的深度模式洞察。
现实世界中的应用场景
解决时间序列语义解释问题的迫切性遍布各个行业。在医疗健康领域,心血管医生需要 AI 不仅挑出异常的心电图(ECG)波段,还要说明“此处出现了 ST 段抬高,疑似心肌梗死先兆”;在工业互联网(IIoT)中,机械故障诊断需要模型指出“振动信号在此时刻出现了连续的高频震荡,偏离了以往平稳运行的基线,可能预示轴承磨损”;在网络安全与 IT 运维中,运维人员需要系统自动出具报告:“从凌晨 2 点到 3 点,网络流量出现了异常的阶跃上升,突破了历史同期周期规律,疑似遭遇 DDoS 攻击”。
总而言之,我们需要一次范式的转变。未来的异常检测系统不能仅仅是一个冷酷的“报警器”,它必须成为一个精通时间序列语言的“诊断医师”。本论文所解决的核心痛点,正是如何优雅地搭建一座桥梁,让天生只懂人类语言的大语言模型,能够“看懂”连续波动的时序信号,并在全局上下文的支撑下,用流利、专业、准确的自然语言,将隐藏在数据深处的异常故事娓娓道来。
三、核心研究问题
问题
论文试图解决的核心问题是什么?
论文试图解决的核心问题是:如何将预训练的大语言模型(LLM)改造为能够对时间序列异常进行上下文感知、具有模式级别(Pattern-level)解释能力的诊断专家,同时克服连续信号与离散文本之间的模态鸿沟?
为了将这个宏大的目标具象化,作者在数学上对问题进行了重新表述,将其定义为**“语义时间序列异常解释(Semantic time series anomaly explanation)”**任务:
-
• 输入是什么:输入包含三个核心部分。第一部分是完整的单变量时间序列 ,它提供了全局上下文;第二部分是一个自然语言查询问题 (例如:“请问在这段数据中发现了什么异常?”);第三部分是一个明确的目标窗口区间 ,指出需要解释的具体时间范围。 -
• 输出是什么:输出是一段自然语言文本解释 。这段解释不仅要回答目标窗口 内是否存在异常,更重要的是,要用专家级别的语言详细描述该窗口内数据的形态特征,并解释为什么这种特征在全局背景下构成了异常。 -
• 为什么这个问题很难:
正如前文背景所述,时间序列的连续性、高维度与 LLM 的离散 Token 机制存在天然冲突。不仅如此,时序异常的判断极度依赖于跨时间尺度的长程依赖(Long-range dependencies)。要在不微调(冻结)LLM 的前提下,让它既能“看清”局部的细微波动,又能“记住”全局的周期规律,并在多维度的约束下生成不产生幻觉(Hallucination)的解释,是一个极具挑战性的多模态对齐难题。 -
• 当前研究中的痛点:现有的基于 LLM 的时序分析方法,要么强行把所有数据转成极其冗长的文本(导致 LLM 记忆衰退、上下文溢出且处理极慢),要么只输入局部窗口(彻底丢失全局判别标准),甚至仅仅让 LLM 去口语化翻译现成的 SHAP 特征值。这些手段都无法实现真正的“语义级”(Semantic-level)异常解释。
创新
作者提出了什么新的方法、模型或技术?
为了攻克上述挑战,作者提出了一套名为 AXIS (Explainable Time Series Anomaly Detection with Large Language Models) 的开创新框架。AXIS 的核心哲学是:不改变 LLM 本身的结构和权重,而是通过精心设计的“提示(Hints)”来引导和条件化(Conditioning)冻结的 LLM,使其具备理解时序动态的能力。
方法的整体思路:
AXIS 摒弃了传统的“直接序列化”或“硬提示(Hard Prompt)”策略。相反,它从时序信号中提取并构建了三种互补的“提示(Hints)”,将它们注入到 LLM 的输入空间中,从而在数值基础、细粒度动态和全局任务先验三个维度上为 LLM 提供了强有力的支撑。
核心创新点与关键模块结构:
AXIS 框架的杀手锏在于它的 Hint Tuner(提示调优器),它生成了三种协同工作的提示:
-
1. 符号化数值提示(Symbolic Numeric Hint):为了解决 LLM 缺乏精确数值锚定的问题(Numerical Grounding),AXIS 并没有把整条时序都文本化,而仅仅对目标窗口 范围内的数据进行文本化。为了适配 LLM 对整数更敏感的特性,数据首先在全局尺度下进行 Z-score 归一化,然后乘以一个放大因子 (默认 ),再四舍五入为整数,最后拼接成逗号分隔的字符串序列(如“123, 124, 127”)作为文本 Token 喂给 LLM。这种方法以极小的 Token 开销(仅与窗口长度线性相关),保留了局部的精确数值形状。 -
2. 融合上下文的步级对齐提示(Context-Integrated Step-aligned Hint):这是整个框架中最具技术深度的模块。仅仅有局部的数值是不够的,必须注入全局上下文。AXIS 首先使用一个在大规模时序数据上预训练过的 Transformer 编码器 对全局序列 进行特征提取,获得深层嵌入向量 。然后,截取与目标窗口对应的特征段 。
核心公式与机制解析:为了将这个时序特征映射到 LLM 能够理解的语义空间,作者创新性地构建了一个文本原型库(Text Prototypes Bank)。这个原型库是通过对 LLM 自身固有的词汇表嵌入矩阵(Vocabulary Word Embeddings) 进行可学习的线性投影得到的,即 。随后,时序特征 作为查询(Query),通过交叉注意力机制(Cross-Attention)去查阅这个文本原型库:
。
这个巧妙的设计被称为 Hint Tuner,它输出的 相当于一系列连续的“软提示(Soft Prompts)”,它们与具体的时序步骤严格对齐,并且融入了全局的时序关联信息,最重要的是,它们与 LLM 的语义空间天然对齐。 -
3. 任务先验提示(Task-Prior Hint):为了稳定 LLM 的解码过程,注入关于“异常检测”这一全局任务的先验知识,AXIS 还引入了一组少量的、可学习的固定查询向量 。同样地,通过与文本原型库进行交叉注意力计算 ,生成固定数量的软提示。这些提示独立于具体的样本,充当了引导 LLM 聚焦于诊断和推理任务的“定海神针”。
与传统方法的区别:
相比于仅将序列数值转成文本塞给 LLM 的传统方法,AXIS 首创了**“多模态软硬结合”的条件化机制。符号化数值提示充当“硬提示(Hard Prompts)”,保留底层刚性数据;步级对齐提示和任务先验充当“软提示(Soft Prompts)”,提供全局视角的语义抽象。此外,AXIS 是冻结(Frozen)** LLM 的,仅训练极小参数量的 Hint Tuner,大大降低了训练成本,且有效防止了灾难性遗忘(Catastrophic forgetting)。
额外创新:首个语义异常解释基准测试数据集
除了算法框架,本文的另一项巨大贡献是构建了领域内首个专门用于训练和评估“时序异常语义解释”的基准测试集(Benchmark)。现有的公开数据集要么只有数字标签,缺乏文字解释;要么完全依赖真实场景,解释过于领域特定(Domain-specific)而无法泛化。AXIS 采用了一种严谨的“程序化引擎(Procedural Engine)”,基于“异常级词汇表(Pattern-Level Anomaly Vocabulary)”在纯净的基线序列上合成各种典型的异常形状(如水平漂移、瞬态尖峰、周期断裂等),并保留对应的正常版本。通过双 LLM 代理(Multi-agent)交互,以配对对比(Comparative Windowing)的方式生成极其丰富、高质量的多格式问答数据(选择题、判断题、开放式问答),为时序 XAI 的发展奠定了坚实的数据基石。
比较
论文与哪些现有方法或 baseline 进行比较?
为了验证 AXIS 在生成高质量语义解释方面的统治力,论文选取了多个前沿领域的强大模型作为 baseline 进行了一系列极限测试。
-
• baseline 方法有哪些: -
1. 视觉-语言大模型(Timeseries VLM):以最新的 Image LLM (gpt-4o)为代表。 -
2. 专门针对时间序列的 LLM(Specialized TS-LLMs):包括 ChatTS、LLMAD、ChatTime,以及最先进的AnomLLM。其中,为了公平对比,作者测试了AnomLLM的两个版本:输入完整全局序列的AnomLLM(Full),以及仅输入目标窗口的AnomLLM(Window)。 -
• 这些方法各自特点: -
• Image LLM (gpt-4o):将时序异常检测视为一个计算机视觉推理问题。把时序数据画成折线图(并高亮目标窗口)喂给模型进行图像理解。 -
• ChatTS / ChatTime / AnomLLM:这些模型大多尝试通过不同的对齐投影头(Projection Head)或者直接将时间序列硬编码为文本向量来强行适配语言模型,通常将时间序列作为一种独立的模态输入,依赖模型内部去强行打通时序与文本的关联。 -
• 作者方法与它们的核心差异及优势:
与Image LLM相比,视觉图表会不可逆地丢失精确的数值信息,当面对细微的数值波动时,视觉模型往往会出现幻觉或判断失误;而 AXIS 通过“符号数值提示”牢牢锁定了数值的底线锚点。
与AnomLLM和ChatTS等专有时序大模型相比,这些模型在面临超长上下文时极易陷入记忆崩溃(仅看局部窗口则会因为缺乏全局基线而频繁误报);AXIS 则极其巧妙地利用外部轻量级的时序预训练编码器(Transformer)来捕获并浓缩全局视野,随后通过交叉注意力压缩成与目标窗口等长的“步级提示”,在不增加 LLM Token 负担的前提下,完美解决了“看局部不知全局”的 Contextual Grounding 难题。
核心理论假设
作者的核心理论假设或主要论点是什么?
-
• 为什么该方法能够解决问题:
作者的核心理论假设是:时间序列中的“动态演化模式”与自然语言中的“语义概念”是可以通过一个共享的潜在空间(Latent Space)进行映射与对齐的。而阻碍 LLM 理解时序的核心,并非 LLM 本身缺乏推理能力,而是缺乏对连续数值的“词汇量”以及对全局形态的“记忆锚定”。 -
• 作者给出的理论解释:
作者通过“解耦”的思想给出了理论解释。LLM 的长处在于“逻辑推理与文本生成”,而不擅长“提取高频、多尺度的底层数值特征”。因此,AXIS 并没有强迫 LLM 去学习如何做卷积或傅里叶变换,而是把“提特征”这个苦力活交给了专职的 Time-Series Encoder(在 Phase I 进行预训练,具备重构和异常判别能力)。然后,如何把这些抽象的密集特征告诉 LLM 呢?作者假设 LLM 固有的词向量矩阵(Vocabulary Embeddings)已经包含了人类描述世间万物形态的完备语义空间。因此,通过一个线性层投影提取出一个文本原型库,让时序特征去和这些文本原型进行注意力碰撞(Cross-attention),就能自动选出最符合当前时序形态的“语义软提示”组合。 -
• 直觉上的理解方式:
直观上理解,这就像是给一个顶尖的外科教授(冻结的 LLM)看病。如果你直接把显微镜下的原始细胞电信号(原始时序数据)扔给他,他会晕头转向;如果你只给他一张模糊的化验单截图(Image LLM),他可能看不清细节。
AXIS 的做法是给他配备了一个绝佳的医疗助手组合: -
1. 把关键病灶区(目标窗口)的精确数值用纸条写清楚递给他(符号化数值提示)。 -
2. 让一个精通病理的住院医(预训练时序 Encoder)先通读病人的毕生病历(全局上下文),然后针对病灶区,写出几条用医学术语(词汇原型库)总结好的病理分析备注(步级对齐提示)。 -
3. 提前告诉他今天我们要确诊的主要是哪几类罕见病(任务先验提示)。
有了这三样法宝,这位教授(LLM)自然能给出最精准、逻辑最严密的诊断报告。
四、研究方法(Methodology)
本章将结构化地详细拆解 AXIS 框架的内部运转机制与系统架构。
4.1 整体方法框架
AXIS 的工作流程由两阶段的训练管线(Two-phase training paradigm)和统一的推理过程构成。
-
1. 阶段一:时序特征专家培养(Phase I: Time-Series Encoder Pretraining)
系统首先需要一个能够精准感知时序波动的“眼睛”。作者采用了基于分块(Patchify)机制的非因果 Transformer 编码器。在这一阶段,将海量的时序数据送入编码器,联合优化两个目标:掩码重构(Masked Reconstruction)(遮住一部分波形,让模型去预测填补)和异常分类(Anomaly Classification)(区分正常与异常模式)。这一步强迫模型学习到时序数据的内在物理规律和异常特征。预训练完成后,该编码器的权重被完全冻结(Frozen)。 -
2. 阶段二:多模态提示调优器训练(Phase II: Hint Tuner Training)
这是最关键的对齐阶段。在这里,时序编码器和目标 LLM 均保持冻结,唯一的训练变量是横跨在两者中间的 Hint Tuner(提示调优器)。它负责将编码器提取的全局深层特征转换成 LLM 能听懂的“软提示(Soft Prompts)”。模型通过计算下一个 Token 预测的自回归语言建模损失(Negative log-likelihood loss)来反向传播更新 Hint Tuner 的参数。 -
3. 推理过程:统一的模板拼装(Inference)
在面对实际问题时,用户的查询(Query)、转化为文本形式的窗口数值(Symbolic numeric hint)、由 Hint Tuner 生成的步级软提示(Step-aligned hint)和任务软提示(Task-prior hint)会被拼装进一个精心设计的 Prompt 模板中。LLM 接收这个融合了多维信息的 Prompt 后,输出最终的自然语言诊断解释。
4.2 关键技术模块
深入 AXIS 的架构内部,我们必须详细解析它是如何构建这三大核心提示(Hints)路径的。
模块一:符号化数值提示(Symbolic Numeric Hint)—— 解决局部数据盲点
LLM 拥有强大的零样本数值推理能力,前提是你得把数字“喂”对。直接输入冗长的原始小数会导致灾难性的 Token 化破碎(Tokenization issues)。AXIS 的巧妙之处在于:只对目标分析窗口 范围内的数据进行文本化处理。为了避免处理浮点数的低效,它先用全局数据的统计量对序列进行 Z-score 标准化,然后乘以放大因子 100(避免丧失精度),接着四舍五入为整数,最后串联成如“123, 124, 127”的纯净文本字符串。这一路径成本极低,却让 LLM 牢牢抓住了波形的底层量化形态。
模块二:融合上下文的步级对齐提示(Context-Integrated Step-aligned Hint)—— 解决全局视野缺失
这是 AXIS 的“大脑中枢”。它需要解决一个矛盾:既要告诉 LLM 局部窗口每一时间步发生了什么,又要让这些局部信息包含对全局演化的深刻理解。
具体流程如下:
-
1. 全局序列 经过预训练好的时序 Transformer,输出包含全局感受野的密集嵌入矩阵 。 -
2. 从中切片提取出目标窗口的对应特征 。 -
3. 构建文本原型库(Text Prototypes Bank):提取冻结 LLM 的词汇嵌入矩阵 ,通过一个极小的可学习矩阵 进行线性变换,得到 。这个库代表了 LLM 语义空间的浓缩精华。 -
4. Perceiver 交叉注意力转换:将时序特征 映射为查询(Query),去 Attend(关注)文本原型库 的键和值。最终输出的 就是融合了全局上下文的、与目标窗口时间步严格对齐的“软提示”向量序列。它既带有宏观记忆,又被强行拉到了 LLM 的语义理解维度。
模块三:任务先验提示(Task-Prior Hint)—— 稳定生成逻辑
对于 LLM 而言,它可能一会儿扮演诗人,一会儿扮演程序员。为了让它立刻进入严谨的“异常分析师”角色,系统引入了一组(如 )固定的可学习向量 。这些向量同样与文本原型库进行交叉注意力交互,生成 。这些提示不依赖于具体的输入数据,而是编码了关于“什么是时间序列异常”的抽象全局先验知识,极大地规范了 LLM 的解码输出路径,防止偏题。
五、实验结果与分析
为了证明这套复杂机制的有效性,作者在他们首创的**“语义异常基准测试集”**上进行了严苛的评估。
解释论文的主要实验:
实验覆盖了三种真实应用中最常见的质询格式:多项选择题(Multiple Choice)(考察区分易混淆异常的能力)、判断题(True/False)(考察对特定模式存在与否的确证能力)、以及难度最高的开放式问答(Open-Ended)(考察自由组织语言、解释因果逻辑的综合能力)。
评估指标采用了最前沿的 LLM-as-a-judge(基于大模型的裁判,如 G-eval) 结合 双盲人类专家评估(Human evaluation) 两种方式,从正确性(Correctness)、推理质量(Reasoning Quality)、完整性(Completeness)等六个维度进行全方位打分。
分析实验结果与背后原因:
根据表 1 和图 11 的核心数据,AXIS 在所有题型、所有评测维度上,以压倒性优势击败了所有基线模型(Baselines),确立了全新的 State-of-the-Art(SOTA)。
-
• 完爆视觉大模型:在选择题综合得分上,AXIS(4.19分)超越了拥有千亿参数的最新视觉语言大模型 Image LLM(gpt-4o,4.09分)。为什么?视觉模型把波形当成了“图片”去识别,对于细微的数值振幅差异(如微弱的异常尖峰)缺乏数值层面的精确认知;而 AXIS 凭借模块一(符号化数值提示),在底层数字锚定上无懈可击。 -
• 碾压现有专有时序大模型:与 AnomLLM、ChatTS相比,AXIS 的优势更是断崖式的(AXIS 开放问答得分为 3.02,远远甩开 ChatTS 的 2.19 和 AnomLLM-Window 的 2.84)。
为什么会有这样的结果?原因在于 AXIS 完美解决了上下文感知(Contextual Grounding)的痛点。 论文中展示了一个极具代表性的案例(图 5a):在第 444 到 473 步的目标窗口内,数据呈现了剧烈的“V型”震荡。如果像AnomLLM那样只看局部窗口,模型会立刻报警说“这里有突发异常尖峰”;但 AXIS 凭借其阶段一预训练的全局 Transformer 所传递的“步级对齐软提示”,一眼识破这其实是整个时间序列固有的、正常的周期性震荡规律的一部分,从而极其精准地输出:“此处行为正常,属于典型时序动态,无异常”。 -
• 消融实验验证了设计的不可或缺性:消融实验(Ablation Studies)证明,如果去掉“步级对齐上下文提示(w/o-context-hint)”,模型在判断题上的准确率遭遇重创(从 3.65 暴跌至 2.44),说明缺乏全局视野,模型根本无法做出确凿的布尔逻辑判断。而如果砍掉“符号化数值提示(w/o-windows)”,模型在开放问答中的“准确度(Accuracy)”会惨跌至 2.00,因为没有了局部数字的支撑,LLM 就如同没有依据的空谈客,陷入严重的幻觉。这完美印证了三大表征路径的正交性与互补性。
六、对未来研究的启发
AXIS 的提出不仅仅是一个新模型的发布,它更像是一座灯塔,为时间序列分析与基础大语言模型的融合指明了未来的航向。
未来可能的研究方向:
-
1. 融入领域知识图谱(Domain-specific Knowledge Graphs):目前的框架教会了 LLM 理解时序数据的几何与物理形态。未来的研究可以探索如何将特定行业(如航空航天、医疗诊断)的实体关联知识图谱作为第四条 Hint 路径注入,使模型不仅能指出“这是由于方差突增导致的异常”,更能基于设备物理拓扑结构给出“这可能是 2 号轴承因高温引发的次生共振”,实现深度的因果推理(Causal Reasoning)。 -
2. 真·多模态对齐图文生成:未来的解释不应该局限于纯文本。更具颠覆性的方向是引导 LLM 在输出诊断报告的同时,自动调用代码库生成高亮了异构数据的可视化图表,实现“文本解释 + 可视化证据”的双重溯源。
哪些问题还没有解决与可能的改进思路:
目前的 AXIS 在阶段一(时序特征提取)仍依赖于大规模时序数据的无监督/半监督预训练。在面临一个采样率、维度和物理含义完全不同、且没有任何历史数据可供预训练的全新领域极端零样本(Zero-shot)场景时,其时序编码器提取的全局软提示质量可能会出现一定程度的衰减。
改进思路在于:探索更具普适性的“时序万能分词器(Universal Time-Series Tokenizer)”和跨域基础模型(Foundation Models),使得阶段一的编码器具有类似 CLIP 模型的泛化能力,真正做到“即插即用”,彻底解除对下游领域数据的依赖。
七、通俗版总结(200字)
这篇论文致力于打破人工智能在处理时间序列(比如心电图、工业设备震动波)时的“黑盒”问题。以往的 AI 只能冷冰冰地报警说“有异常”,却说不清楚“为什么”。
作者提出了一个极其巧妙的框架 AXIS。它不动大语言模型(LLM)的“脑子”,而是给它配备了三个“锦囊”:一个是精确记录局部波动的“数字账本”;一个是通读了全局数据后用 AI 语言写成的“上下文批注”;还有一个是提醒它专心做异常诊断的“任务小抄”。
通过这三个锦囊,原本只懂文字的 LLM 瞬间变成了一位能看懂复杂波动曲线的“诊断专家”。它不仅能精准地察觉出数据的异常尖峰或模式错乱,更能像真正的工程师一样,写出逻辑严密、通俗易懂的诊断报告,在准确率和解释质量上全面碾压了现有的顶尖方法,为未来工业和医疗 AI 系统的安全落地提供了强有力的解释保障。