 夜雨聆风
夜雨聆风





AI推理的聪明分诊术:什么时候投票,什么时候重写?
让AI做数学题时,一个常见的策略是”多采样+投票”:让模型对同一道题生成多个解答,然后通过多数投票选出最终答案。这就是大名鼎鼎的自一致性(Self-Consistency, SC)方法。然而,这种方法有一个致命的盲区:当所有采样都给出错误答案时,投票只会”精准地”选出那个错误答案。
另一种思路是”重写问题”:如果模型答错了,就把问题换一种表述方式重新提问,希望新的表述能帮助模型找到正确思路。但问题同样存在:对于模型本来就能做对的简单题,重写反而可能引入干扰,把对的变成错的。
那么,一个自然的问题是:能不能让AI自己判断,什么时候该投票,什么时候该重写?来自学术界的研究团队在论文《When to Vote, When to Rewrite: Disagreement-Guided Strategy Routing for Test-Time Scaling》中,提出了一个优雅的解决方案:用模型输出之间的”分歧度”作为信号,自动路由到不同的推理策略。更令人惊叹的是,这个方法完全不需要训练,即插即用。
一、测试时扩展的”一刀切”困境
测试时计算扩展(Test-Time Compute Scaling)是当前LLM推理领域最热门的研究方向之一。其核心思想是:在推理阶段投入更多的计算资源,以换取更好的推理质量。这就像考试时允许学生花更多时间思考,或者反复检查答案。
目前主流的测试时扩展策略可以大致分为两类。基于采样的策略(如Self-Consistency、Best-of-N)通过多次采样生成多个候选答案,然后通过投票或评分选择最优答案。基于迭代的策略(如Rewrite-and-Rethink、Self-Refine)通过反复修改问题或答案来逐步提升质量。
然而,现有方法几乎都采用”一刀切”的策略:对所有问题使用相同的推理策略。但现实是,不同问题的难度差异巨大。一道简单的加法题,一次采样就能答对,完全不需要多次投票;而一道复杂的数学竞赛题,即使采样64次也可能全部答错,此时投票毫无意义,不如换一种思路重新理解问题。
简单题浪费算力:对简单题多次采样投票,浪费计算资源。
难题投票失效:当所有采样都答错时,投票只会选出错误答案。
重写可能有害:对简单题重写问题,可能引入干扰反而降低准确率。
二、核心发现:分歧度是问题难度的”晴雨表”
这项研究最深刻的洞察在于一个简单但强大的观察:模型多次采样输出之间的分歧度,是问题难度和预测正确性的强相关信号。
具体而言,当模型对同一道题的多次采样给出完全一致的答案时(零分歧),这道题很可能是简单的,模型的答案也很可能是正确的。当模型给出部分一致、部分不同的答案时(轻微分歧),这道题有一定难度,但通过投票仍有较大概率得到正确答案。当模型给出完全不同的答案时(严重分歧),这道题很可能超出了模型当前的能力范围,继续投票意义不大,需要换一种策略。
研究团队通过大规模实验验证了这一观察。在多个数学推理基准上,输出分歧度与问题难度之间呈现出高度一致的相关性。这一发现为”策略路由”提供了可靠的基础:根据分歧度自动选择最优的推理策略。
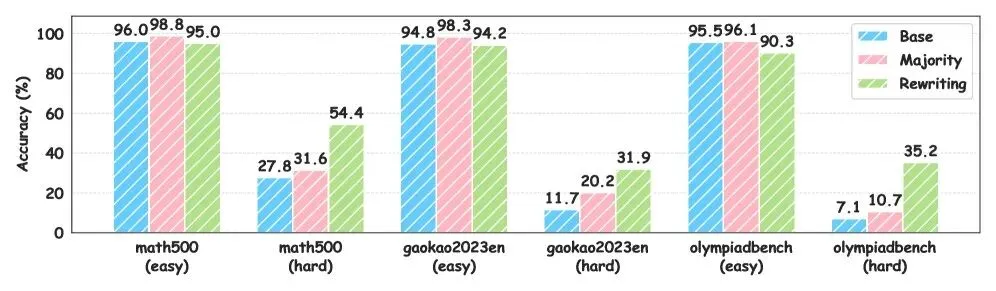
图1:输出分歧度与问题难度及预测正确性的关系。分歧度越高,问题越难,预测准确率越低
零分歧:答案高度一致,问题简单,答案大概率正确。
轻微分歧:部分一致,有一定难度,投票仍有效。
严重分歧:答案五花八门,问题困难,投票失效,需要重写。
三、框架设计:三阶段智能分诊
基于上述核心发现,研究团队设计了一个三阶段的智能分诊框架。整个框架的训练开销为零,完全不需要任何微调或额外训练,可以直接应用于任何LLM。
第一阶段:分歧度检测(Disagreement Filter)。系统首先对输入问题进行N次采样(通常N=4),收集所有输出。然后通过最小分歧度检测器(Minimal Disagreement Detector, MDD)计算输出之间的分歧度,将所有样本分为三类:无分歧样本(NDS)、轻微分歧样本(MDS)和严重分歧样本(SDS)。分类标准基于采样输出中不同答案的比例。
第二阶段:投票解决(Vote Resolve)。对于NDS和MDS样本,系统采用多数投票策略。NDS样本(所有输出一致)直接采用该答案,无需额外计算。MDS样本(部分输出一致)通过投票选出多数答案。研究团队发现,这两类样本占所有问题的绝大多数,且投票策略对它们非常有效。
第三阶段:重写与反思(Rewrite and Rethink)。对于SDS样本(输出严重分歧),系统认为继续投票无济于事,转而采用问题重写策略。系统使用LLM将原始问题改写为不同表述,然后基于改写后的问题重新生成解答。改写后的新表述可能帮助模型从不同角度理解问题,从而找到正确的解题思路。
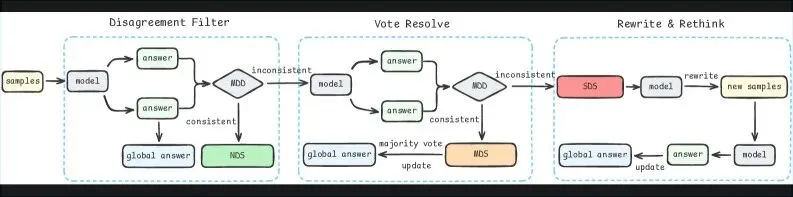
图2:DGRS框架整体流程。通过分歧度检测将样本分为三类,分别路由到投票或重写策略
阶段一:分歧度检测——4次采样,计算分歧度,分为NDS/MDS/SDS三类。
阶段二:投票解决——NDS直接采纳,MDS多数投票,高效处理简单和中等问题。
阶段三:重写与反思——SDS重写问题重新求解,专门攻克难题。
四、分歧度检测器:如何量化”意见不合”?
分歧度检测器是整个框架的核心组件,它的设计需要在准确性和效率之间取得平衡。研究团队设计了最小分歧度检测器(MDD),其核心思想是:在N次采样中,找到出现次数最多的答案,计算其占比。
具体而言,MDD首先从N次采样中提取最终答案(对于数学题,通常是最后一个数值结果)。然后统计每个不同答案的出现次数,找到最高频答案的频率。根据这个频率,将样本分为三类:NDS(最高频答案占比100%,即所有采样完全一致)、MDS(最高频答案占比超过50%但不足100%,即多数一致但存在少数不同意见)和SDS(最高频答案占比不超过50%,即没有明显多数,意见严重分裂)。
这种设计有几个巧妙之处。首先,它只需要提取和比较最终答案,计算开销极小。其次,分类阈值(100%和50%)具有直观的统计意义——全票通过意味着高度确信,过半数意味着有信心但不确定,不过半意味着缺乏共识。第三,这种基于频率的分类方式对采样次数N的变化具有鲁棒性。
NDS(无分歧):最高频答案占比 = 100%,所有采样完全一致。
MDS(轻微分歧):50% < 最高频答案占比 < 100%,多数一致。
SDS(严重分歧):最高频答案占比 <= 50%,意见严重分裂。
五、重写策略:给难题换一个”面孔”
对于被判定为”严重分歧”的难题,框架采用问题重写策略。研究团队探索了多种重写方式,包括改写问题的表述方式、分解复杂问题为子问题、从不同角度重新描述问题等。
重写的核心逻辑是:当模型在原始表述下反复犯错时,换一种表述可能激活模型的不同知识路径。这就像一个学生在某道题上卡住了,老师换一种方式讲解后,学生突然就理解了。LLM虽然不是人,但它对问题表述的敏感性是类似的——不同的表述可能触发不同的推理链。
研究团队还发现,重写策略的效果与重写的质量密切相关。简单的同义替换效果有限,而能够改变问题结构或视角的重写效果更好。例如,将一个应用题从”正向提问”改为”逆向提问”,或者将一个抽象的数学问题具象化为具体的场景描述。这种深层次的重写能够帮助模型跳出原有的错误推理路径。
此外,研究团队还设计了”反思”机制:在重写问题后,模型不仅生成新的解答,还被要求反思原始解答中的错误。这种”重写+反思”的组合策略,比单纯的重写或单纯的反思都更加有效。
改变表述:换一种方式描述问题,激活不同的知识路径。
结构变换:改变问题结构或视角,比简单同义替换更有效。
重写+反思:组合策略优于单一策略,帮助模型跳出错误路径。
六、实验结果:智能分诊碾压”一刀切”
研究团队在7个数学推理基准和3个主流模型(Qwen3-8B、Qwen3-4B、DS-Llama-8B)上进行了全面评估。实验结果令人印象深刻:DGRS框架在所有基准和所有模型上都显著优于现有的”一刀切”方法。
在准确率方面,DGRS相比纯Self-Consistency方法提升了3-7个百分点。更令人惊讶的是,这种提升是在使用更少采样次数的情况下实现的。传统的SC方法需要64次采样才能达到较好的效果,而DGRS只需要4次初始采样加上对少数难题的重写,就能达到更高的准确率。这意味着DGRS不仅更准确,而且更高效。
研究团队还发现,DGRS的增益主要来自对SDS样本(严重分歧样本)的处理。这些样本在纯SC方法下几乎全部答错,但通过重写策略,相当比例的样本被成功挽救。这证明了”分歧度引导的策略路由”的有效性——将有限的计算资源集中投入到最需要的地方。
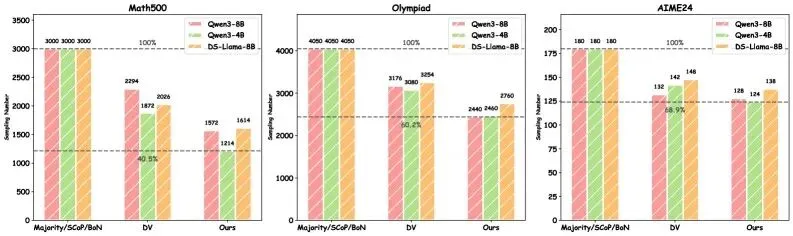
图3:DGRS与基线方法在多个数学推理基准上的准确率对比
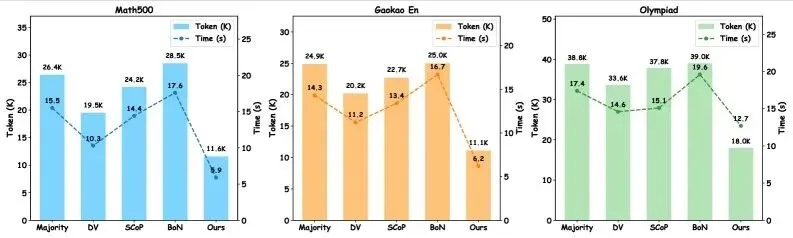
图4:DGRS在不同采样次数下的效率-准确率权衡对比
全面领先:在7个基准、3个模型上均显著优于基线方法。
3-7%提升:相比纯SC方法,准确率提升3-7个百分点。
更少采样:用更少的采样次数达到更高的准确率。
难题挽救:重写策略成功挽救大量SC方法无法解决的难题。
七、深度分析:为什么”分诊”比”一刀切”更聪明?
实验结果虽然亮眼,但更值得深入探讨的是:为什么基于分歧度的策略路由能够取得如此显著的提升?研究团队通过详细的消融实验和案例分析,揭示了几个关键机制。
第一,计算资源的精准分配。传统方法对所有问题平均分配计算资源,而DGRS将计算资源集中投入到最需要的地方——严重分歧的难题。这就像医疗系统中的”分诊”机制:将有限的医疗资源优先分配给最危重的病人。在计算资源有限的情况下,这种”精准投放”的策略远比”平均分配”更有效。
第二,避免重写的副作用。重写虽然对难题有效,但对简单题有害。DGRS通过分歧度检测,只对真正需要重写的难题使用重写策略,避免了对简单题的”过度治疗”。实验数据清楚地表明,如果对所有问题都使用重写策略,整体准确率反而会下降。
第三,分歧度的信息价值。分歧度不仅是一个分类信号,更蕴含了丰富的信息。高分歧度意味着模型对这道题”拿不准”,这本身就暗示了这道题可能需要不同的解决思路。低分歧度意味着模型”很确定”,此时应该信任模型的判断。DGRS巧妙地利用了这一信息。
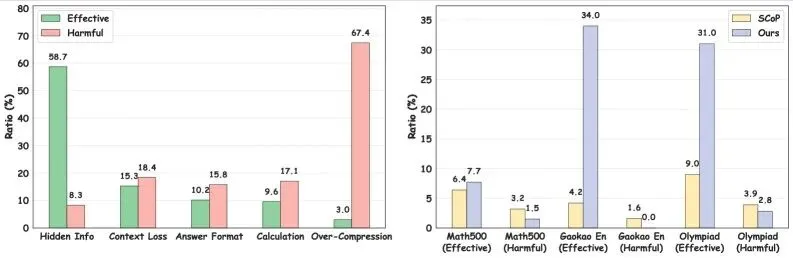
图5:消融实验结果,验证各组件的贡献和不同策略组合的效果
精准分配:将计算资源集中投入到最需要的难题上。
避免副作用:只对难题重写,避免对简单题的过度治疗。
信息利用:分歧度蕴含模型不确定性信息,指导策略选择。
八、跨任务泛化:从数学到代码
一个自然的问题是:DGRS的分歧度引导策略路由是否只适用于数学推理?研究团队通过在代码生成任务上的实验,验证了框架的通用性。
实验结果表明,DGRS在代码生成任务上同样有效。在多个代码基准上,DGRS相比纯SC方法都有显著提升。这证明了”分歧度作为难度信号”这一核心发现具有跨任务的普适性——不仅在数学推理中有效,在代码生成中同样有效。
研究团队还发现,代码生成任务中的分歧模式与数学推理有所不同。在代码生成中,轻微分歧(MDS)的比例更高,这可能是因为代码生成存在多种等价的正确实现方式。尽管如此,DGRS的策略路由机制仍然能够有效地识别出真正需要重写的难题,并为其分配重写策略。
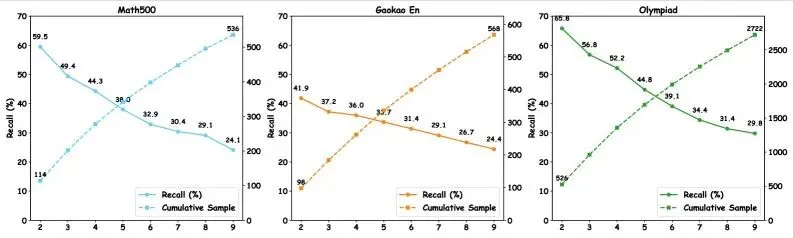
图6:DGRS在代码生成任务上的泛化实验结果
跨任务有效:在数学推理和代码生成任务上均表现优异。
分歧模式差异:不同任务中分歧的分布模式有所不同,但路由机制仍然有效。
通用范式:分歧度引导的策略路由可能成为测试时扩展的通用方法论。
九、与现有方法的对比:为什么DGRS更优?
DGRS与现有测试时扩展方法的核心区别在于其”自适应”特性。让我们将其与几类代表性方法进行对比。
与Self-Consistency(SC)相比,DGRS在SC的基础上增加了分歧度检测和重写策略。SC对所有问题一视同仁地使用投票,而DGRS能够识别出投票无效的难题并切换策略。实验表明,DGRS在SC的基础上额外提升了3-7%的准确率。
与Best-of-N相比,DGRS不需要额外的奖励模型来评分候选答案。Best-of-N需要训练一个判别器来选择最佳答案,而DGRS仅通过简单的分歧度计算就能实现策略路由,零训练开销。
与Rewrite-and-Rethink等纯重写方法相比,DGRS避免了重写对简单题的副作用。纯重写方法对所有问题都进行重写,而DGRS只对严重分歧的难题使用重写,在保持重写优势的同时避免了其劣势。
| 方法 | 策略 | 需要训练 | 自适应 | 计算效率 |
|---|---|---|---|---|
| Self-Consistency | 统一投票 | 否 | 否 | 中 |
| Best-of-N | 评分选择 | 是 | 否 | 低 |
| Rewrite-Rethink | 统一重写 | 否 | 否 | 低 |
| DGRS | 分歧路由 | 否 | 是 | 高 |
十、研究意义:从”更多计算”到”更聪明计算”
这项研究的意义远超方法本身。它代表了一种重要的范式转变:从”投入更多计算”到”更聪明地分配计算”。
当前的测试时扩展研究大多聚焦于如何设计更好的单一策略——更好的投票方法、更好的重写方法、更好的搜索方法。而DGRS提出了一个不同的问题:也许我们不需要一个”万能策略”,而是需要一个”聪明的调度器”,根据问题的特征自动选择最合适的策略。
这种”策略路由”的思路在计算机科学中并不新鲜——在处理器调度、网络路由、数据库查询优化等领域,”根据任务特征选择最优策略”是基本的设计原则。但在LLM推理领域,这种思路还是相对新颖的。DGRS的成功证明了这一思路在LLM推理中的巨大潜力。
更深层次地看,DGRS揭示了一个重要的事实:LLM的输出分歧度是一个被严重低估的信号。它不仅反映了模型的不确定性,还蕴含了关于问题难度、模型能力边界和最优推理策略的丰富信息。充分利用这一信号,可能是提升LLM推理能力的一条低成本、高收益的路径。
十一、未来展望:自适应推理的无限可能
这项研究为未来的工作打开了多个令人兴奋的方向。
第一个方向是更细粒度的策略路由。当前框架将样本分为三类,未来可以设计更细粒度的分类体系,并为每个类别设计更专门化的推理策略。例如,对于”计算密集型”难题使用更多采样的投票,对于”理解偏差型”难题使用重写策略,对于”多步推理型”难题使用分解策略。
第二个方向是动态多轮路由。当前框架只进行一轮策略路由,未来可以设计动态的多轮路由机制。在第一轮策略执行后,再次评估分歧度,决定是否需要切换策略或继续当前策略。这种”边做边看”的动态调整可能进一步提升效率。
第三个方向是跨模型协作路由。不同模型可能对不同类型的问题有不同的优势。未来可以设计跨模型的策略路由机制,根据问题特征选择最适合的模型来处理。这类似于人类团队中的”专业分工”——不同专家处理不同类型的问题。
第四个方向是与推理时搜索的结合。将分歧度引导的路由与搜索算法(如MCTS、Beam Search)结合,在搜索过程中动态调整搜索策略。例如,当搜索树中的节点分歧度很高时,增加搜索宽度;当分歧度很低时,提前剪枝以节省计算。
- 首次提出基于输出分歧度的策略路由框架,实现测试时扩展的自适应策略选择
- 发现输出分歧度是问题难度和预测正确性的强相关信号
- 设计三阶段框架:分歧度检测、投票解决、重写与反思
- 完全无需训练,即插即用,可应用于任何LLM
- 在7个数学基准上取得3-7%的准确率提升,同时使用更少采样
- 重写策略对难题有效但对简单题有害,精准路由是关键
- 框架在代码生成任务上同样有效,证明跨任务通用性
- 代表从”更多计算”到”更聪明计算”的范式转变
十二、写在最后
在医疗领域,”分诊”(Triage)是一个至关重要的概念。急诊室的医生不会对所有病人平均分配时间和资源,而是根据病情的严重程度进行快速分类,将最紧急的病人优先处理。这种”先分类、再分别处理”的思路,极大地提高了医疗系统的效率。
DGRS将这一智慧引入了AI推理领域。它告诉我们,不是所有问题都值得投入相同的计算资源。对于AI”十拿九稳”的简单题,一次采样就够了;对于AI”犹豫不决”的中等题,多投几次票就能解决;对于AI”完全迷茫”的难题,与其反复投票碰运气,不如换一种方式重新理解问题。
这种”因题施策”的思路看似简单,却蕴含着深刻的计算哲学:真正的智能不在于对所有问题使用最强的方法,而在于对每个问题使用最合适的方法。一个能识别自己”不确定”并据此调整策略的系统,比一个盲目使用统一策略的系统,更接近真正的智能。
从Self-Consistency到DGRS,测试时扩展的研究正在从”暴力美学”走向”精准智慧”。而这场关于”什么时候投票、什么时候重写”的探索,可能只是自适应推理时代的序幕。当AI学会像经验丰富的医生一样”分诊”时,它的推理能力将迈上一个全新的台阶。
When to Vote, When to Rewrite: Disagreement-Guided Strategy Routing for Test-Time Scaling. arXiv:2604.26644v1
『完』
关注我们:论文速读馆,每日深度解读一篇AI前沿论文,助你高效跟踪学术进展。
未来,加油!