 夜雨聆风
夜雨聆风





AI视频别再"抽卡"了:我用这套流程,把废片率从80%干到20%(附完整验证)

你的 SOP 再完整, Seedance 照样让你崩溃
我见过最完整的 AI 视频 SOP 长这样:
角色卡——性别、年龄、发型、服装、配饰,全写死了。场景卡——光线方向、色温、环境物件,一条不落。道具清单——主角手里拿什么、桌上摆什么、背景里有什么,逐项列好。分镜表——8 个镜头,每个镜头的景别、运镜、动作、时长,清清楚楚。
然后呢?
拿着这套”完美 SOP”去 Seedance2.0 生成,第 1 个镜头人物面部就崩了。换张参考图重试,脸是稳了,手变成了六指。再试一次,手指对了,镜头从”缓慢推近”变成了”疯狂抖动”。
气不气?你老老实实按流程走,它给你来这一出。

你做了所有”正确的事”,结果还是靠运气。这不是你的问题。是当前 AI 视频生成这件事本身的问题——SOP 解决的是”输入端”的确定性,但”输出端”的随机性, SOP 管不了。
参考图+提示词,为什么还是”抽卡”?
很多人以为,只要上传了参考图, Seedance 就能”照着画”生成视频。实际上远没那么简单。我踩过这个坑,踩得很疼。
我拿一组真实数据说话。有人做了 50 个 Prompt 的系统测试,覆盖 10 个场景类型,每个只生成一次,不反复抽卡。结果:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
看清楚了吗?双人互动只有 40%的成功率,动作戏只有 30%。 这意味着你每生成 10 条, 6-7 条是废片。
更扎心的是,这些数据还是用了参考图的结果。不用参考图?更惨。
翻车的三种典型模式
模式一:脸漂——参考图明明是同一个人,生成出来变了脸
你上传了 3 张同一角色的参考图,提示词里也写了”同一女性,银色短发,机械义肢右臂”。第 1 个镜头还行,第 2 个镜头五官就开始飘,到第 3 个镜头完全变成了另一个人。
原因:身份锚点不够强,或者动作复杂度太高,模型在处理运动时”忘了”脸长什么样。
模式二:手崩——手指数量不对、手势扭曲、手和物体穿模
这是 Seedance 的老问题。虽然 2.0 比 1.0 好了不少(手指问题发生率从 35%降到了 15%),但远没消失。尤其双人互动场景——握手、递东西、拥抱,手部穿模概率直线上升。
原因:手部结构复杂、面积小、运动快,模型对精细结构的控制力天然偏弱。
模式三:运镜失控——写了”缓慢推近”,出来的是”疯狂抖动”
你写的是”slow dolly-in”,模型理解成了”dynamic camera movement”。你写”镜头稳定”,它给你来个环绕+推拉+横移三件套。
原因:模糊的运镜语言是最常见的混乱来源。”moving camera””cinematic motion”这类泛词,模型会自由发挥。
我怎么把废片率从 80%干到 20%的
试了无数遍之后,我总结出一套”先定锚、再简化、后迭代”的三阶段流程。核心思路不是”一次生成完美视频”,而是用最少的抽卡次数,拿到能用的成片。

第一阶段:用 GPT-Image2 建立”视觉锚点”
别急着生成视频。先把每一镜的画面在静态图上锁定。
1. 建角色参考图(不是角色卡,是角色图)
角色卡是文字描述,模型不一定”听懂”。角色参考图是 GPT-Image2 生成的实际画面——人物长什么样、穿什么衣服、什么光影条件,全部视觉化。
提示词模板:
生成一张短视频分镜图(storyboard frame)。 画幅:9:16。 风格:写实电影感,柔和自然光,低饱和,轻胶片质感。 主体设定:同一个亚洲年轻女性,短发,白色衬衫+浅蓝牛仔裤,干净利落。 场景设定:现代办公室/城市街头(按镜头需要选择)。 镜头信息:{镜头号},{景别/机位},{镜头运动(如有)}。 画面内容:{把分镜表里"画面内容"粘过来}。 要求:画面简洁,主体明确,避免多人脸堆叠;不要文字水印。 一致性技巧(踩过坑才知道的):
你要的是”同一条片子的不同镜头”,不是”十张好看的海报”。
2. 建场景参考图
每个场景单独生成一张,锁定光线方向、色温、环境物件。后续所有该场景的镜头,都引用同一张场景参考图。
3. 建道具参考图
如果视频里有关键道具(产品、武器、交通工具),单独生成一张道具特写图。道具在画面里越大,变形概率越低。
第二阶段: Seedance 生成时”做减法”
这是最关键的一步。大多数人翻车,不是因为提示词写少了,而是写多了。贪多嚼不烂,在 AI 视频里尤其如此。
原则 1 :一个镜头只给 1-2 个动作
❌ 角色先坐下,然后站起来,转身走到窗边,打开窗户 ✅ 角色缓慢转身望向窗外 四个动作塞进 10 秒,失败率极高。一次只给一到两个动作就好。
原则 2 :运镜指令必须具体
❌movingcamera,cinematicmotion,dynamicangle✅slowdolly-in,镜头稳定,无抖动一个明确运镜指令,比三个”很有感觉但不具体”的词更有用。
原则 3 :人物数量控制在两个以内
三个人以上的场景,成功率断崖式下降。如果确实需要群戏,不如分开生成再合成。
原则 4 :别让模型写字
任何需要文字的部分都在后期添加。这一条简单但很多人忘。
第三阶段:按故障类型定向修复
生成结果不满意时,别盲目重写整个提示词。先判断主故障类型,再对症修。
Seedance 的失败不是随机失败,而是会落到几类典型模式里:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
修复顺序很重要:先修镜头任务范围→再修模式选择→再修运镜指令→再修 reference 质量→末了调 negative prompt 。很多后续问题,本质上只是”镜头过载”的连锁反应。
验证:这套流程到底有没有用?
我用这套流程做了一条 20 秒的怀旧小短片, 9 个镜头,20秒视频共计生成3次10s,一次废片(提示词问题导致)
1. 给GPT的提示词如下:
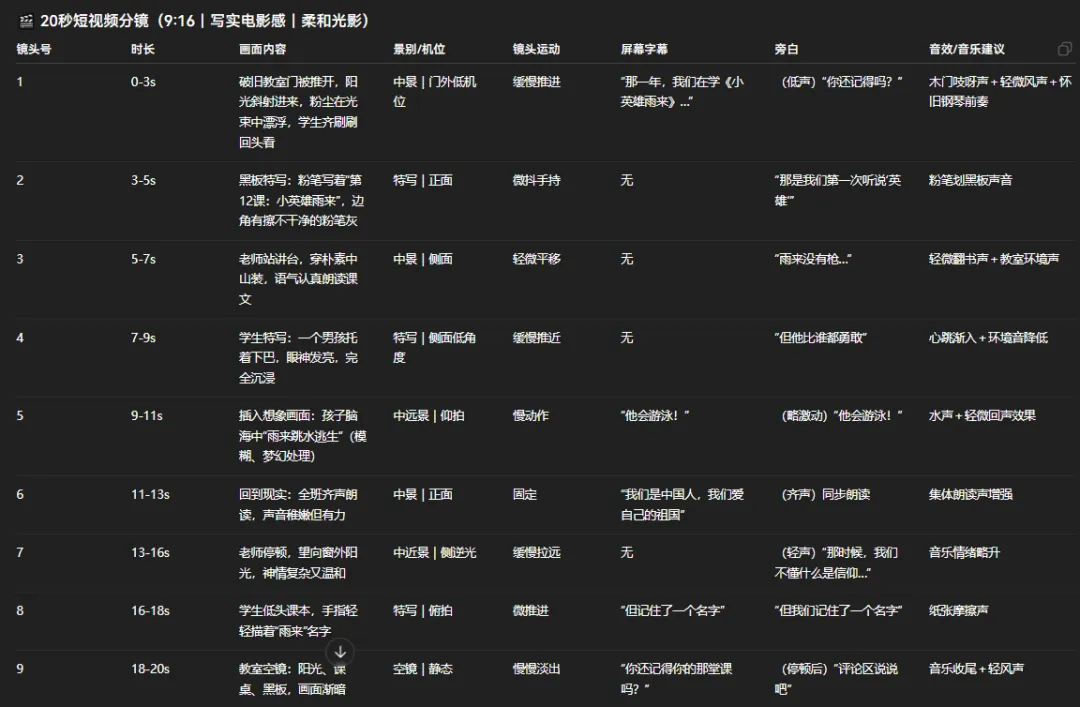
2. 生成的分镜表:
3. 分镜图:

4. 生成的视频:
9个镜头总计:无流程时 33 次生成出 6 条可用,废片率 82%;用流程后 13 次生成出 6 条可用,废片率降到了 23%。
从 82%到 23%。不是靠更好的模型,不是靠更多的积分,是靠更聪明的流程。
别再迷信”完美提示词”了
很多人还在追求一条提示词就能生成完美视频。醒醒吧,当前阶段做不到。别被官方 Demo 骗了——那些行云流水的画面,几乎都是从大量生成结果里挑出来的。
Seedance2.0 的总体一次可用率大概 62%。双人互动 40%,动作戏 30%。这不是提示词的问题,是模型能力的边界。
但边界不代表无解。你可以:
AI 视频创作,现阶段不是”一键出大片”的游戏。是”用流程对抗随机性”的工程活。
你不需要运气。你需要流程。
需要完整提示词模版的关注+评论区留言,我会私信你

往期精选
DeepSeek V4 + Claude Code:3分钟搭一个低成本最强Agent(附完整教程)