 夜雨聆风
夜雨聆风





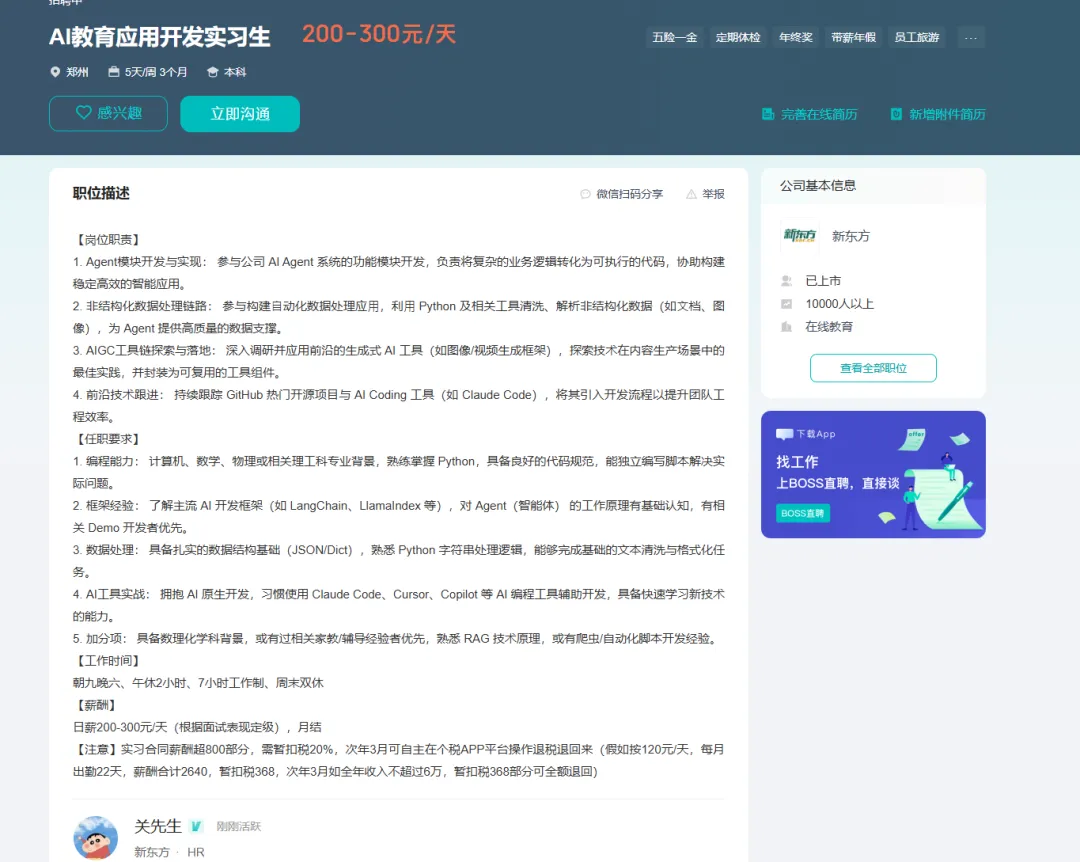
郑州实习|新东方AI 教育应用开发实习生岗位|200-300元/天
✨职位信息概览
新东方招3个月AI 教育应用开发实习生岗位,200-300元/天,工作地址:郑州中原区新东方(金梭路教学区)2楼,面向本科及以上学历在读毕业生
📋岗位职责
- Agent 模块开发与实现:
参与公司 AI Agent 系统的功能模块开发,负责将复杂的业务逻辑转化为可执行的代码,协助构建稳定高效的智能应用。 - 非结构化数据处理链路:
参与构建自动化数据处理应用,利用 Python 及相关工具清洗、解析非结构化数据(如文档、图像),为 Agent 提供高质量的数据支撑。 - AIGC 工具链探索与落地:
深入调研并应用前沿的生成式 AI 工具(如图像 / 视频生成框架),探索技术在内容生产场景中的最佳实践,并封装为可复用的工具组件。 - 前沿技术跟进:
持续跟踪 GitHub 热门开源项目与 AI Coding 工具(如 Claude Code),将其引入开发流程以提升团队工程效率。
✅任职要求
- 编程能力:
计算机、数学、物理或相关理工科专业背景,熟练掌握 Python,具备良好的代码规范,能独立编写脚本解决实际问题。 - 框架经验:
了解主流 AI 开发框架(如 LangChain、LlamaIndex 等),对 Agent(智能体)的工作原理有基础认知,有相关 Demo 开发经验者优先。 - 数据处理:
具备扎实的数据结构基础(JSON/Dict),熟悉 Python 字符串处理逻辑,能够完成基础的文本清洗与格式化任务。 - AI 工具实战:
拥抱 AI 原生开发,习惯使用 Claude Code、Cursor、Copilot 等 AI 编程工具辅助开发,具备快速学习新技术的能力。
加分项:
-
具备数理化学科背景,或有过相关家教 / 辅导经验者优先 -
熟悉 RAG 技术原理,或有爬虫 / 自动化脚本开发经验
📸招聘详情
💡应聘技术问题
问题:”请解释 AI Agent 的工作原理,以及 LangChain 框架在构建 Agent 中的作用”
参考答案:
简单来说,Agent 就是一个能自己”想清楚该做什么,然后去做”的程序。和直接调 API 让大模型回答问题不同,Agent 会拆解任务、调用工具、根据结果决定下一步。
它大致由几块组成:一个感知部分接收用户输入,一个大语言模型负责推理和规划,一组工具(搜索引擎、代码执行器、数据库查询之类)让它能和外部世界交互,还有一个记忆模块保存对话历史,这样多轮对话才不会”失忆”。
LangChain 在这里扮演的是”胶水框架”的角色。它把 Agent 需要的各个部件做了标准化封装——Chain 把多次 LLM 调用串起来,Tool 让 Agent 能调用外部工具,Memory 管上下文,Agent Executor 协调整个”想一步、做一步”的循环。LangChain 推崇的 ReAct 模式,就是让 Agent 在”Reasoning(想)”和”Acting(做)”之间交替,直到把活干完。
举个实际的例子。假设你要 Agent “清洗这份 Excel 里的地址数据”,它的工作过程大概是:先想想需要几步,然后调 Python 工具把文件读进来,再调正则工具把地址格式标准化,最后输出结果。整个过程不需要人一步一步指挥。
问题:”Python 中如何高效处理非结构化数据(如 PDF 文档、图片)?请描述你的处理流程”
参考答案:
处理非结构化数据没什么银弹,基本是”对症下药”的思路。
文档类的(PDF、Word),先用 PyPDF2 或 pdfplumber 把文本扒出来。扫描件就麻烦点,得上 OCR(tesseract 或 PaddleOCR)。提取出来的原始文本通常一堆乱码、多余空格和不规则换行,得用正则和字符串方法清理。如果要提取表格数据,正则匹配能搞定大部分情况;更复杂的可以用大模型直接从文本里抽取字段——名称、日期、金额之类的。
图片数据的话,Pillow 先做预处理(裁剪、灰度化),再送 OCR 提文字。要是需要理解图表内容,可以调多模态模型的 API。
清洗阶段常用到的 Python 工具:strip/replace/split 处理空白和分隔符,re 模块做模式匹配,json 模块做结构化转换。文件多了的话,os 和 pathlib 遍历目录,配上 concurrent.futures 多进程并行,能省不少时间。
整个流程可以串成一个 Pipeline:文件路径进来 → 判断类型 → 调对应的解析器 → 清洗标准化 → 输出结构化 JSON。每个环节做成独立函数,方便维护和替换。
问题:”什么是 RAG(检索增强生成)?它在实际项目中如何落地?”
参考答案:
RAG 的想法很直接:大模型知识有截止日期,还容易瞎编。那用户提问的时候,先从知识库里找几段相关内容,塞进 prompt 里当参考材料,让模型”开卷答题”。
落地分三步走。第一步,把文档切成文本块(chunk),用 Embedding 模型转成向量,存进向量数据库——FAISS、Chroma、Milvus 都行。第二步,用户提问时,把问题也做成 Embedding,在向量库里做相似度搜索,捞回最相关的几段文本。第三步,把捞回来的文本和用户问题拼在一起,丢给大模型生成回答。
新东方做教育的话,RAG 能用到的场景不少。比如学科知识问答,检索教材对应章节来辅助回答;题库解析,从已有题库里找相似题的解法;或者根据学生的薄弱知识点匹配对应的讲解内容。
实际做的时候有几个坑要注意。chunk 大小很影响效果,太大信息冗余、太小上下文断掉,一般 500-1000 字符是常见的起步值,具体得根据文档类型调。检索质量直接决定回答质量,光用向量检索有时候不够,混合检索(向量 + BM25 关键词)往往效果更好。Embedding 模型也要选对,中文场景下 text2vec-chinese 比 OpenAI 的 ada 在本地部署更方便。
问题:”描述一个你做过的项目,包括技术选型的理由和遇到的难点”
参考答案:
面试官问这个,主要想听你解决问题时的思路,不是技术名词罗列。用 STAR 结构来组织会比较清晰:
背景(Situation):说清楚项目要干什么。比如”做了一套智能题库系统,学生输入题目描述就能匹配相似题目和解析”。
你负责什么(Task):明确你的职责范围。比如”我负责题目的向量化检索模块和后端 API”。
具体做了什么(Action):这里要说”为什么选这个技术”,而不是只说”用了什么”。举个例子:”后端用 FastAPI,因为异步性能好、自带文档;向量数据库选 Chroma 而不是 Milvus,因为项目还在原型阶段,Chroma 够轻够快;Embedding 用 text2vec-chinese,中文效果不输 OpenAI 的,而且免费本地跑。做的时候碰到题目文本太长导致 Embedding 质量下降的问题,试了几种分块策略,最后发现按知识点分块再拼摘要效果最好。”
结果(Result):能量化就量化。”检索准确率从 60% 提到 85%,API 响应时间压到了 500ms 以内。”
面试官关注的点:你做技术选择时有没有权衡过利弊,遇到问题是怎么分析和试错的,而不是你用了多少热门技术。
问题:”如果让你为公司设计一个自动化数据处理 Pipeline,每天处理 1000 份不同格式的教学文档,你会怎么设计?”
参考答案:
我会把整个系统拆成几个独立阶段。
文件进来先过一道分类。设一个统一接收目录(量大了换消息队列),用 watchdog 监听新文件。进来后按后缀名判断类型——PDF、Word、图片、Excel,各自路由到对应的解析器。碰到认不出的格式,标异常丢进人工审核队列。
解析阶段,每种文件类型有自己的 Parser,但输出统一成中间格式:{"raw_text": "...", "metadata": {"file_type": "...", "page_count": ...}}。然后过清洗流水线:去乱码、统一编码、修复断行、提取结构化字段。清洗规则以正则为主,复杂的字段提取可以用大模型辅助。
清洗完的数据按预定义 Schema 转成 JSON 入库。结构化数据存 PostgreSQL,文本块做完 Embedding 存向量库,原文件存对象存储(MinIO 或 S3)。
工程上每个阶段做成独立模块,参数放配置文件里(chunk 大小、并发数这些)。每份文件处理到哪一步都记日志,失败的进重试队列。跑一段时间就能看日处理量、成功率、平均耗时这些指标了。
技术栈的话,Python 3.10+,Celery 调度任务,Redis 做队列,PostgreSQL + pgvector 存数据,Docker 部署。前期单机够用,后面哪个模块慢了就单独扩。
🎯应聘面试准备
问:想应聘上述岗位,需要做哪些准备?
答:
简历优化
1.核心信息前置
-
本科及以上,计算机、数学、物理等理工科专业 -
有 Agent Demo 开发经验或数据处理项目经历的优先放在前面 -
技术栈以 Python 为主,突出 LangChain / LlamaIndex 等 AI 框架经验 -
意向岗位写清楚:AI 教育应用开发实习生
2.匹配岗位关键词
-
技术栈:Python、LangChain、LlamaIndex、RAG、AIGC 工具 -
工程能力:数据清洗、自动化脚本、API 开发、Prompt Engineering -
工具:Claude Code、Cursor、Copilot、GitHub、FAISS / Chroma -
能力标签:Agent 开发、非结构化数据处理
技能梳理
Python 编程方面,字符串处理(正则、split/join/strip)、JSON/Dict 操作、文件读写(os / pathlib / shutil)、多进程并发(concurrent.futures)这些得熟练,能写出能跑的、别人看得懂的脚本。
Agent 开发方面,需要理解几个概念:Agent 是怎么感知输入、做推理、调用工具、维护记忆状态的。最好能自己用 LangChain 搭一个 Agent 出来——哪怕只是一个能联网搜索并回答问题的小机器人。了解 ReAct 模式和 Function Calling 机制就够了。
数据处理方面,能处理 PDF(PyPDF2 / pdfplumber)、Excel(openpyxl / pandas)、图片(Pillow + OCR)。数据清洗的基本流程:提取、去噪、格式化、结构化输出,这个得能说清楚。
AI 工具方面,面试前最好实际用过 Claude Code 或 Cursor,能讲出具体的使用场景——比如用它辅助写爬虫、生成数据处理脚本、调试代码之类。光说”我会用”不如说”我用它做了什么”。
面试准备
经典问题
-
Agent 和直接调 LLM API 有什么区别 -
LangChain 里 Chain、Tool、Memory 各自干什么 -
给你一份混合了表格和文字的 PDF,你怎么提取里面的数据
系统设计
-
怎么做一个能自动解析教学资料、生成知识问答的系统 -
设计一个支持多轮对话的教育辅导 Agent -
每天上千份不同格式文档的批量处理方案
项目经验准备
-
准备 1-2 个拿得出手的项目,能说清楚: -
解决什么问题 -
技术选型时怎么权衡的 -
遇到什么坑、怎么解决的 -
最终效果怎么样(能量化最好) -
有论文复现经验或开源项目贡献的话也准备好