 夜雨聆风
夜雨聆风





书太多读不完?分享一个 OpenClaw 伯衡君自制深度阅读技能:先读薄,再读厚
开篇寄语
事情是这样的。前两天有个朋友问伯衡君,有没有什么办法能快速搞懂一本书的核心内容。我当时就想,这不就是「把书读薄」吗?然后他又说,光读薄不行,还得能看出作者没说出来的东西,最好还能跟其他书对比一下。我又想,这不就是「把书读厚」吗?说实话,这两个需求听起来简单,真要做到,没个几小时下不来。但伯衡君最近潜心编纂,编写了个 OpenClaw 技能,能同时把这两件事干了。而且,是让 4 个 AI 角色同时帮你干。这个技能,就叫「四维深度阅读」。
前情提要
其实这个技能的灵感,来自伯衡君之前写过的一篇文章——《时间无限而人生有涯,故如何在5分钟阅读完一本书以扩展人生》,当时那篇文章里,伯衡君提到了一个核心思路,提取关键信息,和之前的知识做对比。后来伯衡君就想,能不能把这个思路用到读书上?于是就有了这个技能。
体验地址
技能已经发布到 ClawHub,可以直接安装使用。
直接对你的小龙虾说,给我安装 four-dimensional deep reading 技能
安装命令,一行搞定。
npx clawhub@latest install four-dimensional-deep-reading项目地址
ClawHub 页面,可以查看完整文档。
-
https://clawhub.ai/zhangboheng/four-dimensional-deep-reading
这个技能到底能干嘛
简单说,就是当你给出一本书的名字或文件,它会召唤 4 个虚拟角色,同时从 4 个不同角度帮你读这本书。
第一个角色:第一性原理师
这个角色干的事,就是把作者说的话拆成原子命题。
什么叫原子命题?
就是那些「不可再分」的基础观点。
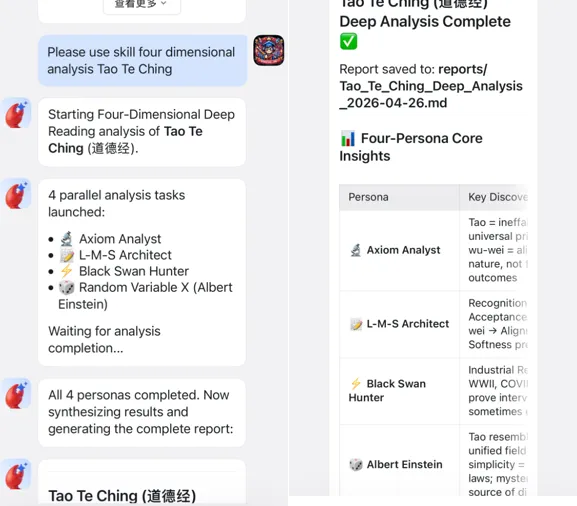
比如伯衡君之前用它分析过《道德经》。
第一性原理师给出的结论是这样的。
核心前提:道是不可言说的宇宙本源,无为是顺应自然的行动准则。
底层假设:
-
A1:宇宙存在一个统一的根本规律(道) -
A2:人为干预越少,系统越接近最优状态 -
A3:柔弱胜刚强是普遍规律
你看,原本五千多字的《道德经》,被压缩成了三句话。
这就是「把书读薄」。
第二个角色:结构化笔记官
这个角色负责把书里的内容变成可复用的知识卡片。
它用的是 L-M-S 结构。
-
L(Logic):逻辑链条,观点是怎么推导出来的 -
M(Method):方法论,能直接拿来用的工具 -
S(Summary):摘要,50 字以内的核心要点
还是《道德经》的例子。
Logic:认知道 → 接受无为 → 顺应自然 → 以柔克刚
Method:
-
无为而治:减少不必要干预 -
以柔克刚:避免正面冲突 -
知足常乐:降低欲望阈值
Summary:顺应自然规律,减少人为干预,以柔弱姿态应对刚强。
你看,这就不只是读薄了,而是把书里的东西变成了你以后能用的工具。
第三个角色:黑天鹅猎手
这个角色最有意思。
它专门找茬。
它的任务就是找出这本书的结论在什么情况下会失效。
伯衡君之前用它分析过一篇论文,叫《基于机器学习的 A 股基本面量化投资策略研究》。

论文里说,用 PCA 降维 + 多元线性回归,年化收益能达到 28%。
听起来很美好对吧?
但黑天鹅猎手直接泼了一盆冷水。
黑天鹅事件:
-
2020 年疫情期间,基本面数据和实际市场情绪严重脱钩,模型预测几乎失效 -
2021 年新能源补贴政策突变,模型没有覆盖政策敏感度维度,产生显著回撤
边界条件:
-
当市场流动性骤降时,PCA 特征向量失去解释力 -
当行业结构快速重组时,原有回归系数失效
你看,这就是「把书读厚」。
作者没说的,黑天鹅猎手帮你找出来了。
第四个角色:随机变量 X
这个角色最骚。
它每次都会随机选择一个历史名人或虚构角色,然后从那个角色的视角来解读这本书。
伯衡君分析《道德经》的时候,它随机到了爱因斯坦。
爱因斯坦的视角是这样的。
「道」这个概念,很像我在追求的「统一场论」——一个能解释所有物理现象的单一理论框架。但不同的是,物理学追求的是可验证的数学表达,而「道」追求的是不可言说的直觉体验。
你看,这个视角,是不是比单纯看书有意思多了?
而且每次分析,随机角色都不一样。
可能是乔布斯,可能是巴菲特,可能是福尔摩斯,也可能是孙悟空。
81 个角色池,每次都有新鲜感。
实战案例:PDF 论文分析
光说不练假把式。
伯衡君前两天收到一个 PDF 文件,是一篇关于机器学习量化投资的学术论文。
本来想自己慢慢读的,但一看 15 年的回测数据、一堆因子、各种图表,头就大了。
于是直接丢给四维深度阅读。
几分钟后,报告出来了。
第一性原理师告诉我,这篇论文的核心假设是「PCA 降维后的因子能保留足够的价值信息」。
结构化笔记官帮我把 15 个因子整理成了表格,还总结了择时逻辑。
黑天鹅猎手直接指出了策略在疫情和政策突变时会失效。
随机变量 X 这次抽到的是詹姆斯·西蒙斯——文艺复兴科技的创始人,量化投资传奇。
西蒙斯的视角是这样的。
基本面因子是否真的提供了额外的、可重复的预测信号,还是仅在特定时间段出现了偶然的相关性?PCA 降维后,模型是否仍保留了对收益率最敏感的特征子空间?
你看,这些问题,论文作者自己都没提。
但 AI 帮你问出来了。
支持哪些格式
这个技能支持的格式还挺全的。
- 书名:直接给书名,它会自动去豆瓣、维基百科抓取信息
- TXT 文件:直接解析,支持 UTF-8 和 GBK 编码
- Markdown 文件:直接解析,章节结构保留
- PDF 文件:需要先安装 poppler-utils(一行命令的事)
- EPUB 文件:需要安装 ebooklib
- MOBI 文件:需要安装 calibre(这个比较大,不常用可以不装)
伯衡君测试下来,TXT 和 PDF 最常用,Markdown 适合分析自己的笔记。
多语言支持
这个技能还支持 10 种语言的输出。
英语、简体中文、繁体中文、日语、韩语、法语、德语、西班牙语、葡萄牙语、俄语。
它会自动检测你用什么语言提问,就用什么语言输出。
比如你用中文问「分析《原子习惯》」,它就用中文输出。
你用英文问「Analyze Atomic Habits」,它就用英文输出。
当然,你也可以强制指定输出语言。
比如「分析《三体》–lang en」,就是中文书,英文输出。
怎么安装
安装很简单,一行命令。
clawhub install four-dimensional-deep-reading装完之后,如果你想支持 PDF 解析,再装一个依赖。
apt-get install poppler-utilsEPUB 的话。
pip install ebooklib beautifulsoup4就这么简单。
怎么用
用法更简单。
直接跟 AI 说就行。
-
「用深度阅读分析《原子习惯》」 -
「Deep read this file: /path/to/book.pdf」 -
「分析这个链接:https://example.com/book.pdf」
它会自动识别你给的是书名、文件还是链接。
然后召唤 4 个角色,开始干活。
分析完之后,报告会自动保存到 workspace/reports/ 目录下。
文件名格式是「书名_深度分析_日期.md」。
适合什么人用
坦率的讲,这个技能适合所有需要「深度阅读」的人。
- 学生:快速搞懂教材或论文的核心观点
- 研究者:发现论文的边界条件和潜在问题
- 投资者:分析投资类书籍或研报的逻辑漏洞
- 写作者:从经典作品中提取可复用的方法论
- 好奇的人:用不同角色的视角看世界
反正伯衡君自己用下来,感觉效率提升了不少。以前读一本书要一下午,现在 10 分钟就能拿到核心洞察。剩下的时间,可以用来验证、思考、或者摸鱼。
篇后寄语
好了,今天的安利就到这里。
这个技能,伯衡君已经替你们试过了——
好用不好用,你们自己试试就知道。
万一打开了新世界的大门呢。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~
谢谢你看我的文章,我们,下次再见。