 夜雨聆风
夜雨聆风





X 上那些刷屏的 AI 短视频,原来是这么做出来的
最近一段时间如果你在 X 上逛,时不时的就能看到以下这类视频。
一个末世废土里的女主角独立对抗世界,电影感镜头切换。
或者两个卡通角色在厨房里互相斗气,3D 动画效果流畅得出奇。
还有科幻漫画感的城市追逐场景,人物在高楼间穿梭。
这些视频的共同特点是:不超过 15 秒,质量出奇的高,而且发帖者也都不是什么专业电影人。
从他们的推文当中会发现,这批视频几乎都提到了同样的两个工具:
GPT Image 2 和 Seedance 2.0
这不是巧合,而是一套正在 AI 创作圈里快速扩散的工作流组合。
要搞清楚这套组合为什么最近这么火,就要先了解一个在 AI 视频圈长期存在的老大难问题:
角色一致性
AI 生成视频最让人抓狂的地方,不是画质差,而是同一个人物在不同镜头里「脸不一样」。这就导致任何想讲故事、有连续角色的视频,基本不可能用 AI 直接完成,因为镜头一切换角色就变形了。
这个问题困扰了所有 AI 视频工具好几年。
而 GPT Image 2 加上 Seedance 2.0 的组合,是目前已知能把这个问题解决得最彻底的方案之一。
GPT Image 2 是 OpenAI 在 2026 年 4 月 21 日发布的新一代图像生成模型,官方名称是 ChatGPT Images 2.0,API 代号是 gpt-image-2。
这个模型发布 12 小时内就登上了 Image Arena 排行榜第一名,领先第二名足足 242 分,是该排行榜有史以来最大的领先幅度,直到现在也依然保持着头名。
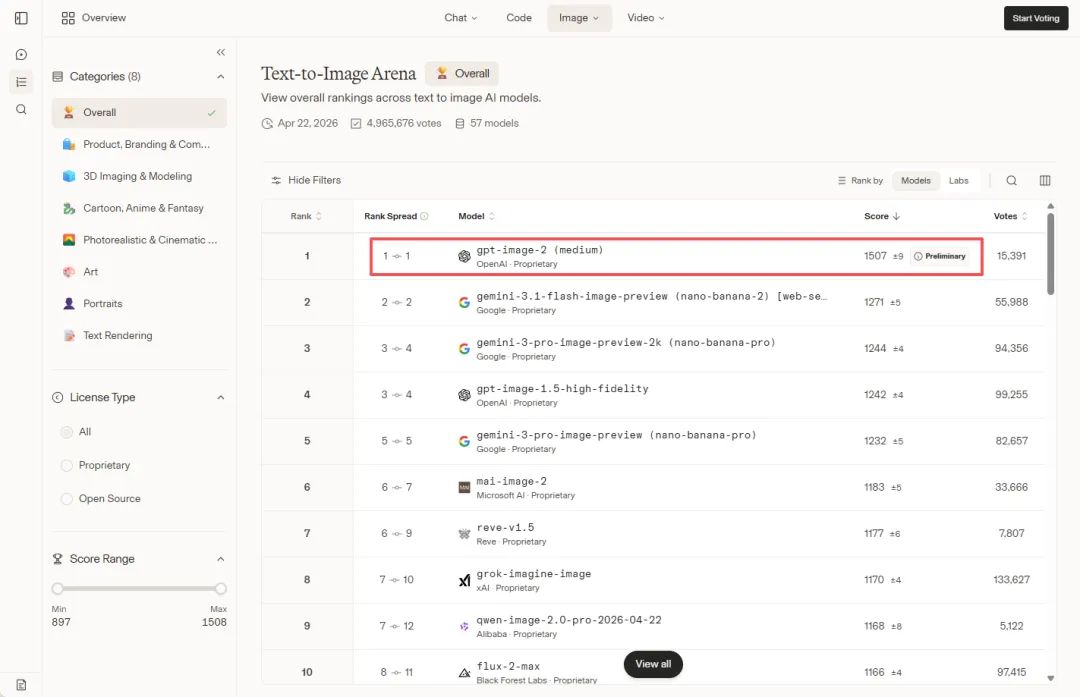
它相比上一代(GPT Image 1.5)最核心的两个突破:
第一,文字渲染接近完美,不再出现 AI 图像里那种字母错位、字体扭曲的现象,中文、日文、韩文、阿拉伯文等非拉丁字符也能准确处理。
第二,加入了「思考模式」,模型在生图前会先推理构图逻辑,类似 o1 的思维链机制。
对于这套工作流来说,更关键的能力是:
它可以在一次请求中生成最多 8 张角色一致的图像,同一个人物在不同角度、不同场景下保持高度稳定的外貌。
比如下面这张「一致性」的图像组,就成为了后续视频制作的视觉基础。

而 Seedance 2.0 是字节跳动旗下 AI 研究团队 Seed 开发的视频生成模型,2026 年 2 月正式发布。
字节跳动在国内的产品叫即梦(Jimeng),国际版叫 Dreamina,Seedance 2.0 是两者底层共用的视频模型。
这个模型一经发布迅速在全球社交媒体上走红,以对电影中真实演员的高度还原度而著称,甚至当时还引发了好莱坞制片公司的版权抗议,迪士尼和派拉蒙均向字节跳动发出过警告。
后来字节跳动表示会加强安全过滤,对真实人物生成进行了严格限制。
但对于创作者来说,这个模型真正的亮点是:
它接受图像、视频、音频同时作为参考输入,最多可以上传 9 张图片、3 段视频、3 段音频,一次性生成一段有角色、有镜头运动、有环境音效的连贯视频,单次生成时长最长 15 秒,分辨率可达到 1080p 乃至 2K。
这两个工具现在搭在一起,工作流的逻辑变成了:先用 GPT Image 2 做「角色设定」与「分镜稿」;再把生成好的图像交给 Seedance 2.0 让其「动起来」。
如果再拆细点儿说:
第一步,是在 ChatGPT 里描述你想要的故事场景和角色,让 GPT Image 2 一次性生成一组角色图。比如同一个主角儿的正面、侧面、不同动作姿势。
因为这些图是在同一次会话里生成的,模型会保持该角色外貌的稳定性。在 X 上流传的截图中,可以看到创作者用的就是这种「分镜网格图」的技巧。他们让 GPT Image 2 生成类似电影分镜板的多格画面,把多个镜头场景排列在同一张图里,这样角色在所有格子里都来自同一次生成,一致性更有保障。
第二步,就是把已生成好的图上传给 Seedance 2.0,配合文字描述来告诉模型「这个角色要做什么动作、镜头怎么移动」。比如从仰拍缓慢推进到特写,角色回头望向镜头。Seedance 2.0 会把静态的角色图变成一段儿有真实运动感的视频片段,包括镜头运动、物理动效,有时还会附带同步的环境声效。
在 X 上,用这套流程已经产生了各种风格视频的输出。除了文章开头你看的那些视频以外,比如像下面这种汉唐宫廷舞,就是通过刚刚上面那个 16 宫格的参考图生成的,角色一致性完成的非常好。
和直接使用文字生成视频相比,这套工作流的核心优势就是「可控性」。
我们就以上面这个汉唐宫廷舞的视频为模版,看看作者按照这套工作流,分成两步的话,他的提示词是如何撰写的。
Step 1 —— 先生成 16 宫格编舞分镜图
请创作一张高完成度、高清晰度的「汉唐宫廷舞 / 霓裳羽衣舞 · 16宫格分镜图」。【整体定位】这不是普通古风写真,也不是单纯舞蹈教学图,而是一张融合「汉唐宫廷舞」「霓裳羽衣舞」「真实宫苑空间」「电影分镜感」「16步动作编排」的高完成度分镜海报。整体要像一段盛唐宫廷舞的完整编舞被拆解成16个关键画面,每一格既清晰独立,又有连续流动感,方便后续用于视频生成。【场景设定】不要舞台,不要空黑背景,不要现代摄影棚。场景必须是一个真实、立体、优美、符合汉唐时代气质的盛唐宫苑空间:- 傍晚金蓝时刻,宫灯初上- 朱红宫柱- 金色宫灯- 宫廷回廊 / 大殿外庭院- 石阶、栏杆、轻纱帷幔- 远处可见层叠殿宇与宫苑深景- 空间有明确前景、中景、后景,具有真实纵深感- 整体氛围华美、通透、盛世感强,不要乌漆麻黑,不要浑浊,不要色斑【人物设定】主角是一位年轻中国女舞者,带有盛唐宫廷舞者气质,端庄、华美、优雅、克制。她在16格中必须保持同一张脸、同一人物身份、同一气质、同一套服装体系,不要每格都像换了一个人。【服装与妆造】服装为汉唐宫廷舞服 / 霓裳羽衣风格:- 高腰长裙- 大袖- 轻纱披帛- 精致发髻- 金色发饰、步摇- 少量花钿或唐风妆感- 裙摆、披帛、大袖都要有真实动态推荐配色:- 胭脂粉- 象牙白- 香槟金- 淡石青整体华丽但不俗艳。【版式要求】- 画面采用 4×4 的16宫格分镜排版- 每格都有明显编号 1-16- 每格都有中文动作标题- 每格可有简洁中文说明或短句提示- 每格都要像一个独立镜头画面- 适当加入动作方向箭头或轨迹线,增强分镜感- 整体清晰、工整、信息完整,但不要过度拥挤- 分辨率要非常高清,线条清楚,人物和背景都清晰,不要糊,不要脏,不要有色斑【动作分镜顺序】1. 宫苑亮相舞者站在宫苑中央,微侧身,长裙曳地,一手轻提大袖,一手自然垂落,建立盛唐气场。2. 起袖迎风双臂缓缓抬起,大袖与披帛轻轻被带起,像乐声初起。3. 拈花侧行舞者缓步前行,一手做拈花或兰花指,一手大袖舒展在身后,动作优雅。4. 开袖成云双袖向两侧大幅展开,形成对称而华丽的大开构图,像云气铺开。5. 回眸转廊舞者经过宫柱或回廊边缘,身体转向侧背,再缓缓回眸。6. 环步绕帛脚下走环步,披帛绕身形成流动轨迹,双臂一前一后,动作圆润。7. 旋裙开宴原地或小范围旋转,长裙与披帛打开,形成华丽旋舞。8. 折腰扬袖身体轻折,一袖高扬,一袖下垂,形成斜向张力构图。9. 低身献礼半蹲或单膝低位,双手托袖向前,动作像宫廷献礼,具有礼乐仪式感。10. 仰身拂云从低位起身,上半身轻微后仰,双袖向上扬起,披帛向后飞,动作华美但真人可完成。11. 飞步掠庭向侧前方做一个轻盈掠步,大袖和披帛向后带出,形成位移动线。12. 盛唐大旋最华丽的一次大旋转,长裙、披帛、大袖同时打开,是整套最强高潮之一。13. 回身收袖从大旋中自然回身,双袖由外向内慢慢收回,动作从大开转向收束。14. 托月举袖一手高举如托月,一手横于胸前,身体向上拉长,披帛在身侧形成弧线,仪式感强。15. 合袖礼成双袖缓缓合拢至胸前,形成“礼成”动作,神情宁静庄重。16. 霓裳定格最终大定格,一袖高扬,一袖低垂,身体优雅扭转,长裙铺开,端庄华美地完成收尾。【重点要求】- 必须突出真实空间感与时代感- 必须保持同一舞者一致性- 必须有完整的大袖、披帛、长裙动态- 必须适合后续作为视频分镜参考- 每一格动作都要明显不同,不能过于重复- 画面整体要华丽、优美、清晰、通透- 不要黑压压,不要脏,不要模糊,不要色斑,不要廉价古风感
Step 2 —— 把 16 宫格图丢给 Seedance 生成视频
请根据我提供的16宫格参考图,生成一段高完成度的「汉唐宫廷舞 / 霓裳羽衣舞」视频。【核心要求】严格按照画面1-画面16的顺序生成。这不是舞台表演,也不是仙侠特效,而是一位成年中国女舞者,在真实立体的盛唐宫苑空间里完成一段华美、端庄、流畅的宫廷舞。整体像电影里的宫廷舞段落,强调大袖、披帛、长裙的真实流动,以及盛唐礼乐气质。【人物设定】同一位成年中国女舞者,全程保持同一张脸、同一套造型。服装为汉唐宫廷舞服:高腰长裙、大袖、轻纱披帛、精致发髻与金色发饰,色调以胭脂粉、象牙白、香槟金、淡石青为主。【场景设定】真实盛唐宫苑 / 宫廷回廊 / 大殿外庭院。时间是傍晚金蓝时刻,宫灯初上。环境包含朱红宫柱、金色宫灯、层叠殿宇、栏杆、石阶、轻纱帷幔与远处宫殿深景。空间要有前景、中景、后景,真实、通透、优美,不要黑压压。【镜头要求】镜头稳定、优雅,有缓慢推进、横向跟拍、小幅环绕、低机位。不要乱晃,不要快切。大部分时候完整展示全身,让大袖、披帛、裙摆的流动清楚可见。画面12为全片高潮,镜头围绕舞者做完整360度环绕。必须严格遵守:场景要保持稳定性和一致性,不要出现割裂不符合物理世界的想象,人物动作自然连贯,不要出现字幕、符号等标识。BGM要大气。画面要连贯,一镜到底不允许剪辑。【分镜脚本】画面1:宫苑亮相,舞者立于宫苑中央,微侧身,长裙曳地,镜头缓慢推进。画面2:起袖迎风,双臂缓缓抬起,大袖与披帛轻轻被带起,镜头轻推近。画面3:拈花侧行,舞者缓步前行,一手拈花,一手大袖舒展,镜头横向跟拍。画面4:开袖成云,双袖向两侧大幅展开,形成对称构图,镜头半环绕。画面5:回眸转廊,舞者经过宫柱,转向侧背后回眸,镜头轻移。画面6:环步绕帛,脚下环步,披帛绕身,镜头小幅环绕。画面7:旋裙开宴,舞者旋转,长裙与披帛打开,镜头约180度环绕。画面8:折腰扬袖,身体轻折,一袖高扬,一袖下垂,镜头略低机位。画面9:低身献礼,舞者半蹲或单膝低位,双手托袖向前,镜头低机位慢推。画面10:仰身拂云,从低位起身,上身轻微后仰,双袖上扬,镜头随动作上抬。画面11:飞步掠庭,舞者做真实可完成的轻盈掠步,镜头横向跟拍。画面12:盛唐大旋,舞者完成最华丽的大旋转,长裙、披帛、大袖同时打开,镜头完整360度环绕。画面13:回身收袖,从大旋中自然回身,双袖由外向内收回,镜头轻跟随。画面14:托月举袖,一手高举如托月,一手横于胸前,镜头缓慢推进。画面15:合袖礼成,双袖缓缓合拢至胸前,动作庄重,镜头短暂停留。画面16:霓裳定格,最终大定格,一袖高扬,一袖低垂,长裙铺开,镜头轻微拉远收尾。【动作要求】所有动作必须是真人舞者真实可完成的动作,不要悬浮,不要飞天,不要不合理大腾空。重点表现宫廷舞的端庄、大袖展开、披帛流动、长裙旋转和礼乐之美。【负面要求】不要舞台背景,不要空黑背景,不要仙侠特效,不要魔法光效,不要人物悬浮,不要镜头乱晃,不要快切,不要画面浑浊,不要色斑,不要模糊。
你看完上面这些提示词后,可能心里会想,这提示词要写的这么复杂吗?我哪儿写的出来呀!
其实你真的以为上面这些提示词都是作者一个字一个字的敲出来的么!当然,我相信肯定有人能自己写出来,但一定是那些非常专业的人。
绝大部分的人都是非专业制作人员,在我看来,他们也都是先参考了 GPT Image 2 与 Seedance 2.0 的规则或规范,然后将这些规则或规范喂给 AI 大模型进行学习,再根据自己的想法或创意,与 AI 共同协作产出的。你要知道这些提示词肯定不是一次性生成的,也需要几轮的试错与打磨才能定稿。
因此,也不要觉得自己不行,上面的提示词其实就是模版,你也可以把它喂给大模型让它学习,然后再按照你自己构思的想法,与 AI 协作创作出来一个新的视频创意。
再回到正题~
最开始的时候,我们都是用文字转视频的方式,但纯文字转视频的模式等于把所有创作决策都交给了模型,让它进行猜测,每次结果都是抽卡且随机的,同一个提示词跑十次可能得到十个不同长相的角色。
这是文字转视频的最大问题!
而先用 GPT Image 2 把角色「锁定」,再让 Seedance 2.0 仅负责「动起来」,相当于把创作过程拆成了「设计」和「执行」两个阶段。
前者由人来主导,后者由模型来完成,出错率就能大幅降低。
我曾在 Atlas Cloud 上看过一篇技术分析,它指出:相比纯文字转视频,这套两段式流程的可用片段成功率可以降低到原来的五分之一到八分之一的成本,因为减少了大量废稿。
如果你也对这套图像转视频的新工作流方式感兴趣,也想试试看看,下面简单说一下怎么入手和费用情况,两个工具分开说。
GPT Image 2 方面
目前是所有 ChatGPT 用户(包括免费用户)都可以使用基础的「即时模式」,不需要额外付费,但有使用频次限制,用于偶尔测试完全够用。访问以下网址即可使用:
https://chatgpt.com/images
如果要解锁「思考模式」,也就是多图一致性生成、布局推理等更强功能,那就需要订阅 ChatGPT Plus,月费 $20,或者 Pro 档($100/月)。
上面这套工作流里用到的多图一致性生成,就属于 Thinking Mode 的功能,所以要想使用的话 Plus 是门槛。API 方面,是按 token 计费的,比如生成一张 1024×1024 的标准图像,低质量约 $0.006,中等质量约 $0.053,高质量约 $0.211。
Seedance 2.0 方面
国际用户的主要入口是 Dreamina 平台 dreamina.capcut.com,也可以通过 CapCut 的 AI 工具模块访问。Dreamina 有免费额度,新注册用户可以先试用。访问以下网址即可体验:
https://dreamina.capcut.com/zh-tw/tools/seedance-2-0
付费套餐的起步价约 $18/月,有更多生成次数,高档套餐约 $84/月。如果你能使用中文版的即梦平台,起步价是 69 元/月,折合约 $9.6,同等额度下更划算。另外,也有很多第三方平台(如 Lovart 等)也接入了 Seedance 2.0,各有不同的试用政策。
写在最后
总结一下这套组合的适用人群。
如果是想制作有连续角色的 AI 短视频、对视频质感有要求但没有专业制作背景的内容创作者,或者是想探索 AI 影视化创作可能性的独立创作者。
你要知道现在每段视频最长 15 秒,想要拼接成更长的成片仍需要手动剪辑,并且 Seedance 2.0 对真实人物面孔的生成是有内容过滤的(当然授权是必须的),GPT Image 2 的思考模式生成速度比较慢,复杂场景下可能需要最长 5-10 分钟。
不过对于大多数短视频内容来讲,GPT Image 2 + Seedance 2.0 的能力已经远超过去所有 AI 视频工具的组合效果。
值得你试一试!
既然看到这儿了,如果觉得还不错,帮忙随手点个「赞」、「在看」、「转发」三连;如果想第一时间收到推送,也可给我加个星标★,非常感谢!