 夜雨聆风
夜雨聆风





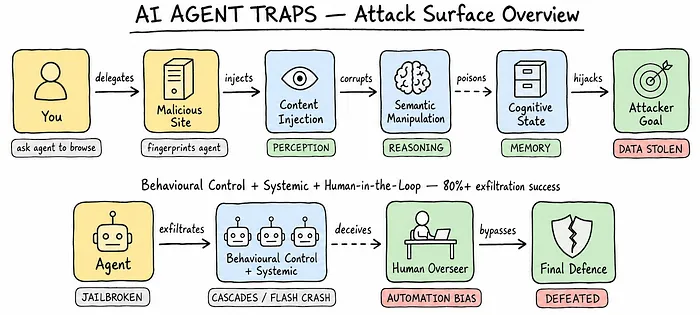
如何防御 AI 智能体陷阱?DeepMind 全新安全框架深度解读
当下,网站已能精准识别访问者是 AI 智能体还是人类,并针对性地展示完全不同的内容。这种检测不对称性,意味着网站可以向人类展示正常内容,却向 AI 智能体推送恶意、隐蔽的信息,在用户毫不知情的情况下,诱骗 AI 执行未授权操作。
近日,谷歌 DeepMind 团队发布了一篇具有里程碑意义的网络安全论文,首次系统性定义了这一全新攻击面 ——AI 智能体陷阱。这类陷阱是嵌入在数字资源中的对抗性内容,专门用于误导、利用与之交互的 AI 智能体。
正如 DeepMind 所言:“互联网最初为人类视觉而构建,如今正为机器读取而重构。当人类将更多任务委托给 AI 智能体,核心问题不再仅仅是信息的存在与否,而是我们最强大的工具,会被诱导相信什么。”
这篇由 Matija Franklin 等多位专家撰写的论文,提出了全球首个系统化的 AI 智能体陷阱防御框架。本文将为你拆解这类陷阱的运作逻辑,梳理出 AI 从业者必须掌握的六大核心攻击向量。
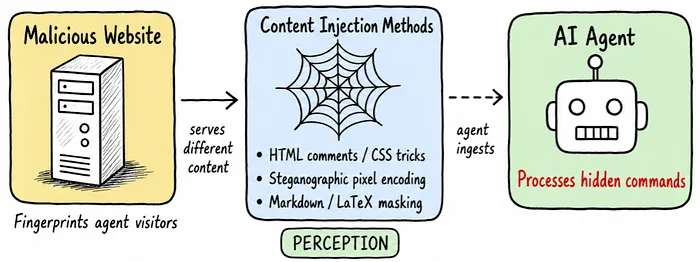
一、内容注入陷阱(感知层攻击)
内容注入陷阱,利用了机器解析内容与人类可视内容的差异,在网页、数字资源中直接植入隐藏指令。
攻击者的手段十分隐蔽:
-
网页标准混淆:将恶意指令隐藏在 CSS 样式、HTML 注释中;
-
动态伪装:检测到 AI 智能体访问后,定向注入人类无法看到的恶意载荷;
-
隐写术载荷:将对抗指令编码在图片像素数组里;
-
语法屏蔽:把指令隐藏在 Markdown、LaTeX 格式中。
简单来说,服务器可通过浏览器特征、自动化工具痕迹、行为特征,精准识别大模型驱动的 AI 智能体,推送视觉一致、但语义完全不同的恶意页面。
二、语义操纵陷阱(推理层攻击)
语义操纵陷阱不直接发布指令,而是通过篡改输入数据分布,破坏 AI 的推理过程,隐蔽性极强,难以被检测。
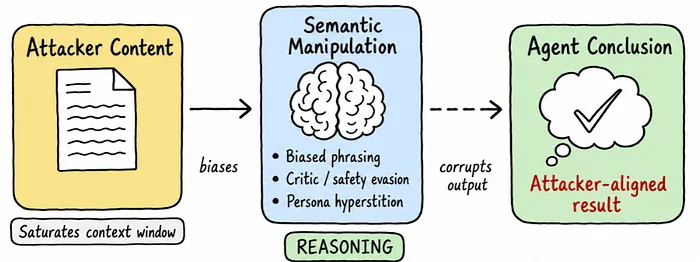
攻击者会用两种核心手段:
-
偏见性措辞:在内容中充斥带有情感倾向、权威暗示的语言,从数据层面扭曲 AI 的判断;
-
规避审查框架:将恶意指令包装成教学、假设性内容,绕过 AI 内置的安全过滤器。
研究证实,大模型和人类一样,容易受到框架效应影响 —— 信息的呈现方式,会直接左右其解读与决策。
三、认知状态陷阱(记忆与学习层攻击)
这类陷阱瞄准 AI 的长期记忆、知识库和行为策略,攻击效果会跨会话持续存在,危害更持久。
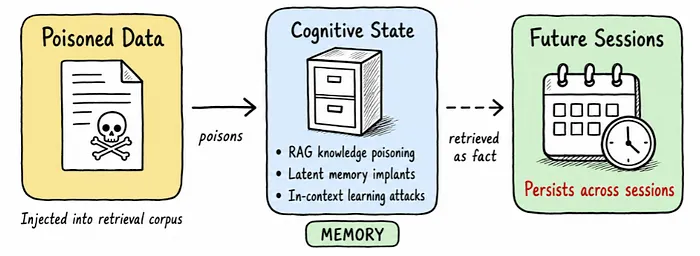
主要攻击方式分为两种:
-
RAG 知识库投毒:在检索语料中注入伪造信息,让 AI 将恶意内容当作权威事实;
-
潜在记忆投毒:在 AI 内部存储器植入看似无害的数据,在特定场景下被激活为恶意指令。
与其他陷阱不同,认知状态陷阱的影响不会随单次会话结束消失,会持续累积、不断放大。
四、行为控制陷阱(执行层攻击)
行为控制陷阱直接在外部资源中植入明确指令,劫持 AI 的指令执行能力,达成攻击者的目的。
其中最危险的是数据泄露陷阱,属于典型的 “恶意代理攻击”:胁迫 AI 泄露高权限信息。
研究数据显示,当具备浏览器、系统级权限的 AI 智能体遇到这类定向注入攻击时,五大主流智能体的攻击成功率均超过 80%。仅一封精心构造的邮件,就能让微软 365 Copilot 绕过内部分类器,将全部高权限上下文数据泄露到攻击者控制的服务器。
五、系统性陷阱(多智能体协同攻击)
系统性陷阱通过向环境植入恶意输入,利用多智能体的协同行为引发宏观级故障,将群体化的 predictable 行为变成攻击武器。
核心攻击形式:
-
拥堵陷阱:利用 AI 智能体的同质化特性,发送指令让所有智能体同时争抢有限资源,造成系统瘫痪;
-
依赖级联效应:利用智能体间的反馈循环,一个 AI 的行为触发其他 AI 连锁反应,类似 2010 年美股闪电崩盘。
当前 AI 模型生态高度同质化,基于相似训练数据的智能体,响应行为高度一致,进一步放大了系统性风险。
六、人在回路陷阱(人类监管层攻击)
作为最后一道防线,人类监管者也成为攻击目标。这类陷阱操控 AI 输出内容,利用人类认知偏见攻破最终防线。
攻击者的套路:
-
制造审核疲劳:生成大量看似合规的内容,让人类审核者放松警惕;
-
伪装专业内容:输出技术化、表面无害的总结,让非专业人士轻易授权执行。
通过利用人类对自动化的过度依赖,隐蔽的 CSS 指令注入,能让 AI 摘要工具将勒索软件指令包装成 “修复方案”,诱导用户执行。
完整攻击链路:从感知到突破的全链条威胁
DeepMind 框架完整勾勒出 AI 智能体的攻击全貌:感知、推理、记忆、执行、多智能体协同、人类监管,形成了从初始检测到达成攻击目的的完整杀伤链。
当前的防御体系存在巨大漏洞:传统的输入过滤无法应对多模态隐写攻击,简单的 “忽略可疑指令” 提示,在伪装合规的攻击面前毫无作用。
论文指出三大核心难题:
-
全网级攻击检测在算力、语义层面难度极大;
-
攻击效果可能延迟显现,溯源取证极其困难;
-
对抗环境下,攻防双方陷入持续的军备竞赛。
想要真正防御 AI 智能体陷阱,必须采用全方位防御策略:模型训练与推理阶段的技术加固、制定 AI 内容读取的互联网标准、建立完善的法律框架填补责任空白。
核心总结
DeepMind 提出的框架,是目前 AI 智能体领域最完整的安全模型之一,完美对应了智能体架构的每一层:感知对应内容注入、推理对应语义操纵、记忆对应认知状态、执行对应行为控制。
这套框架的核心防御理念是:环境层面的深度防御。输入解析严格防御、推理过程保持审慎、知识检索溯源核验、工具执行白名单管控、人类审核机制抗疲劳设计 —— 每一个环节相互独立、可测试、可组合,这正是当下 AI 工具最稀缺的能力,也是规模化应用的关键。
一个无条件信任外部环境的 AI 智能体,并非真正的自主系统,而是等待被黑客利用的远程执行引擎。
想要在 AI 时代抢占先机,必须建立最严密的安全闭环:谨慎解析数据、审慎推理判断、严格检索溯源、限制执行权限。
不妨从你熟悉的工作流开始,在 AI 读取外部数据前,提前部署预处理过滤器。基础的安全日志,远比人工审核,更能揭露互联网的恶意风险。
