 夜雨聆风
夜雨聆风





MyClaude源码分析:从零仿制ClaudeCode
MyClaude 是一个学习性项目,用约 500 行 Python 代码实现了 Claude Code 的核心交互循环——CLI 界面、XML 工具调用解析、LLM 对话管理、文件操作与 Bash 执行。本文逐模块拆解其源码架构,分析系统提示词的分层规则设计、工具调用解析器的正则匹配策略、带自动扩容的重试机制,以及配置驱动的模块化设计思想,适合想理解 AI Coding 助手底层原理的开发者阅读。
目录
-
概述 1.1 项目背景 1.2 技术栈 1.3 设计目标 -
核心架构 2.1 整体架构概览 2.2 模块职责划分 2.3 主循环流程 -
源码分析 3.1 入口与配置加载 3.2 系统提示词设计 3.3 消息管理 3.4 LLM 调用与重试 3.5 工具调用解析 3.6 工具执行 3.7 CLI 界面 -
功能详解 4.1 查询循环 4.2 工具调用流程 4.3 对话模式与编码模式切换 -
技术亮点 5.1 分层规则系统 5.2 正则解析器设计 5.3 智能重试机制 5.4 配置驱动的模块化 5.5 工具执行安全边界 -
实践指南 6.1 环境准备 6.2 配置说明 6.3 运行与调试 -
总结参考文献
1. 概述
1.1 项目背景
MyClaude 是一个用于学习和研究 Claude Code 工作原理的开源项目。它的目标分为两步:首先搭建一个功能精简的 0.01 版本,实现基本的编码对话循环;然后期望这个 0.01 版本能够在 AI 辅助下自我进化到 0.1 版本。项目的设计理念是”麻雀虽小,五脏俱全”——在极少的代码量中覆盖 AI 编程助手的核心机制。
1.2 技术栈
-
语言:Python 100%(约 500 行有效代码) -
LLM:MiniMax M2.7(通过 OpenAI 兼容接口调用) -
终端 UI:Rich 库(Markdown 渲染、语法高亮) -
配置:YAML(通过 PyYAML 解析为 SimpleNamespace) -
工具系统:XML 标签格式(view / create / str_replace / bash / done)
1.3 设计目标
-
极简实现:核心代码量控制在 500 行以内,每个模块职责单一 -
完整闭环:覆盖”用户输入 → LLM 调用 → 工具解析 → 工具执行 → 结果反馈”的完整链路 -
可进化:架构设计为 AI 自我修改留有空间,支持后续的自动进化
2. 核心架构
2.1 整体架构概览
项目采用分层架构,从下到上分为五个层次:
-
配置层(utility/config_loader.py):YAML 配置加载,全局单例模式 -
消息层(message/):系统提示词管理、API 消息构建 -
查询层(query/):LLM 调用、重试逻辑、会话日志 -
工具层(llm_tool/):XML 解析、工具执行、文件操作 -
表现层(cli/):CLI 交互、输出渲染、命令处理
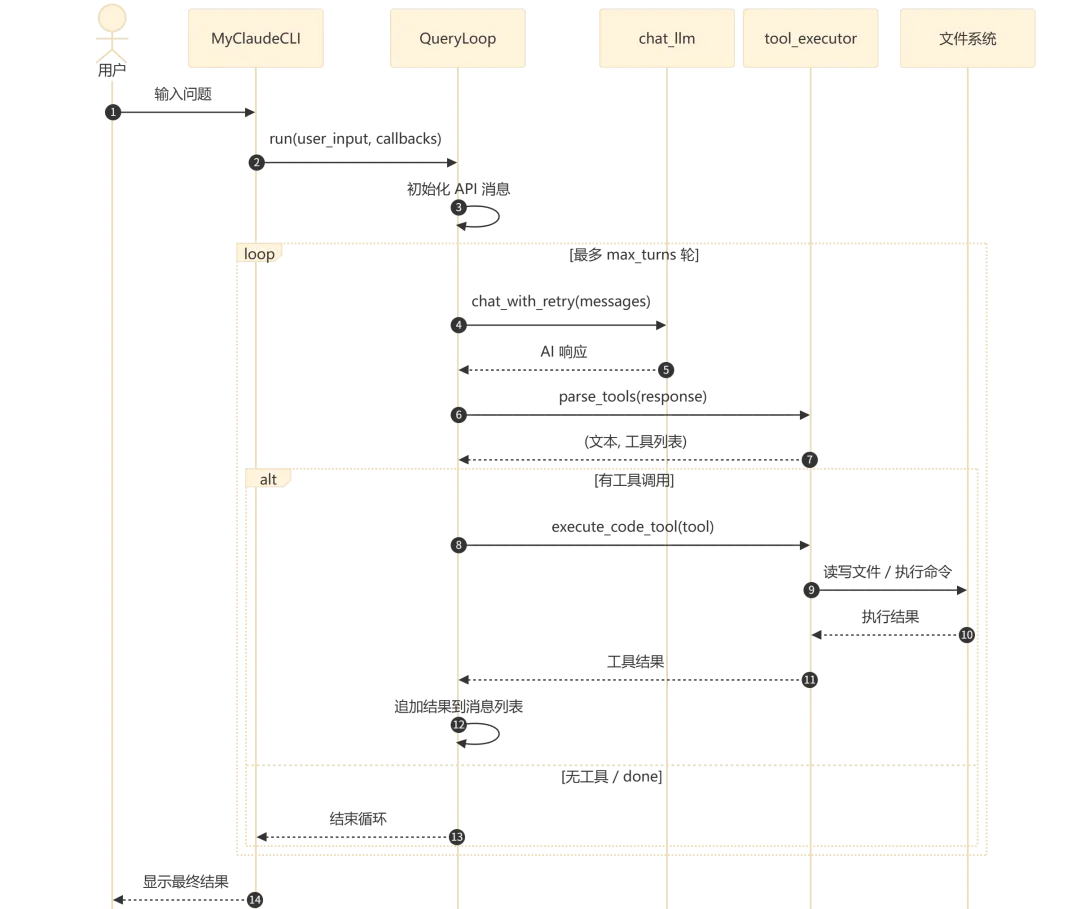
流程执行说明:
-
阶段一(步骤 1-2):CLI 接收用户输入,传递给 QueryLoop 启动查询循环 -
阶段二(步骤 3-5):QueryLoop 构建 API 消息,调用 LLM 并获取响应 -
阶段三(步骤 6-12):解析 LLM 响应中的工具调用,执行工具操作,将结果反馈给 LLM -
阶段四(步骤 13):LLM 返回 done 或无工具时,结束循环并展示结果
关键规则:
-
QueryLoop 不持有任何终端输出逻辑,所有输出通过回调函数注入 -
工具执行结果以 [tool_name] 工具执行结果:...格式追加到消息历史 -
done 工具是循环终止的唯一信号
2.2 模块职责划分
项目源码目录结构如下:
src/├── myclaude.py # 入口:参数解析、CLI 启动├── cli/│ ├──mycli.py # CLI 主循环:输入处理、命令路由│ └── cli_print.py # 终端输出:彩色打印、Markdown 渲染├── llm_tool/│ ├── tool_executor.py # 工具解析与执行调度│ └── cmd_bash.py # Bash 命令执行├── message/│ ├── llm_api_msg.py # API 消息管理│ └── sys_prompt.py # 系统提示词定义├── query/│ ├── query_loop.py # 核心查询循环│ ├── chat_llm.py # LLM API 调用(同步/流式/异步)│ └── session_log.py # 会话日志记录└── utility/├── config_loader.py # 配置加载与全局单例├── file_tool.py # 文件操作(view/create/str_replace)└── normal_utility.py # 通用工具(thinking 过滤等)
每个模块的职责:
-
myclaude.py:程序入口。处理命令行参数,创建 MyClaudeCLI 实例并启动 -
mycli.py:CLI 主循环。接收用户输入,路由斜杠命令(/quit、/clear、/help、/tokens),调用 QueryLoop 执行普通查询 -
cli_print.py:终端输出层。提供彩色打印、Markdown 渲染、打字机效果、工具调用格式化显示 -
tool_executor.py:工具系统。使用正则表达式从 LLM 响应中提取 XML 工具标签,调度执行具体工具 -
cmd_bash.py:Bash 执行器。通过 subprocess.run 执行 shell 命令,30 秒超时 -
llm_api_msg.py:消息管理器。维护发送给 LLM 的 messages 列表,提供系统提示词初始化、用户消息追加、助手回复追加、工具结果追加等方法 -
sys_prompt.py:系统提示词定义。约 80 行的分层规则系统,定义 LLM 的行为准则 -
query_loop.py:核心循环控制器。管理”发送消息 → 接收响应 → 解析工具 → 执行工具 → 继续下一轮”的循环 -
chat_llm.py:LLM 客户端。封装 OpenAI SDK,提供阻塞式、流式、异步流式三种调用方式,以及带自动扩容的重试逻辑 -
config_loader.py:配置管理器。加载 YAML 配置文件,转换为点号访问的 SimpleNamespace 对象,实现全局单例 -
file_tool.py:文件操作工具。实现 view(查看)、create(创建)、str_replace(替换)三种文件操作 -
normal_utility.py:通用工具函数。目前包含 thinking 内容过滤功能
2.3 主循环流程
主循环是整个系统的核心,由 QueryLoop.run() 方法驱动。其流程如下:
-
第一轮:初始化 API 消息列表(系统提示词 + 用户输入) -
循环体(最多 max_turns 轮): -
发送消息给 LLM,获取响应 -
从响应中解析工具调用列表 -
如果有工具调用,执行工具,将结果追加到消息列表,继续下一轮 -
如果无工具调用或收到 done 信号,退出循环 -
超轮次处理:达到最大轮次仍未结束,强制终止并提示用户
3. 源码分析
3.1 入口与配置加载
程序入口在 src/myclaude.py,核心逻辑非常简洁:
from cli.mycli import MyClaudeCLIdefmain():import argparseparser = argparse.ArgumentParser(description="MyClaude Code CLI")parser.add_argument('-m', '--model', type=str, default='MiniMax-M2.7',help='AI model to use')cli = MyClaudeCLI()cli.run()if __name__ == "__main__":main()
入口做了三件事:解析命令行参数、创建 CLI 实例、启动主循环。注意 argparse 解析了 model 参数但尚未使用——这是一个为后续多模型支持预留的扩展点。
配置加载(utility/config_loader.py)采用了一种巧妙的单例模式:
defload_config(filename="config.yaml"):start_dir = Path(__file__).resolve().parentbase_dir = find_project_root(start_dir, filename)config_path = base_dir / filenamewithopen(config_path, "r", encoding="utf-8") as f:raw = yaml.safe_load(f)return _dict_to_namespace(raw)# 模块级全局单例global_cfg = load_config()
关键设计点:
-
find_project_root 函数通过向上查找 config.yaml 文件来确定项目根目录,支持从任意子目录启动 -
_dict_to_namespace 递归将 YAML 字典转换为 SimpleNamespace,支持 global_cfg.model.api_key这样的点号访问 -
利用 Python 的模块缓存机制(sys.modules)实现全局单例:无论被 import 多少次,load_config() 只执行一次
3.2 系统提示词设计
系统提示词(message/sys_prompt.py)是整个项目最核心的资产,定义了 LLM 的行为准则。它采用六层分层规则结构:
Layer 1 – 强制编码信号:检测用户的”写”、”创建”、”修改”等请求,强制使用 XML 工具而非直接输出代码。
Layer 2 – 普通模式区分:区分编码任务(使用工具)和纯问答任务(直接回复)。
Layer 3 – 冲突仲裁:当用户请求同时包含问答和编码需求时,以 Layer 1 为准。
Layer 4 – 代码规范:要求生成的 Python 代码通过 PyCharm 格式化检查,包括文件末尾换行、PEP 8 空格、无重复代码片段、无非 ASCII 字符等。
Layer 5 – 任务终止规则:任务完成时必须使用 <done> 标签标记结束,禁止在 done 之后继续调用工具。
Layer 6 – 环境约束:声明当前环境为 Windows,要求使用 CMD 语法。
提示词还包含正向示例和反向示例,通过对比教会 LLM 正确的代码交付方式:代码必须放在 XML 标签内,禁止使用 Markdown 代码块。
3.3 消息管理
LLMAPIMessage 类(message/llm_api_msg.py)管理发送给 LLM 的消息历史:
classLLMAPIMessage:def__init__(self):self.api_messages = sys_prompt.system_prompt.copy()definit_api_msg(self, user_input):msg = {"role": "user", "content": user_input}self._append_info(msg)defappend_llm_response(self, llm_response):msg = {"role": "assistant", "content": llm_response}self._append_info(msg)defappend_tool_exec_result(self, result_msg):self._append_info(result_msg)
消息管理的设计原则:
-
系统提示词在初始化时被复制一份,避免修改原始模板 -
所有消息追加都通过 _append_info 方法,为后续的记忆压缩(memory compaction)预留扩展点 -
工具执行结果直接以 dict 形式追加,其 role 由 tool_executor 设定为 “user”(这是一种巧妙的设计:将工具结果伪装成用户消息,让 LLM 自然理解这是对之前操作的反馈) -
append_micro_info 方法名中的 “micro” 暗示这是轻量级追加,不触发记忆压缩
3.4 LLM 调用与重试
LLM 调用层(query/chat_llm.py)提供了三种调用方式和智能重试机制:
defchat_with_retry(api_messages):initial_max_tokens = global_cfg.model_chat.initial_max_tokensmax_retries = global_cfg.model_chat.max_retriesmax_tokens_limit = global_cfg.model_chat.max_tokens_limitmax_tokens = initial_max_tokensfor attempt inrange(max_retries + 1):ai_response, is_truncated = stream_chat(api_messages, max_tokens=max_tokens)ifnot is_truncated:return ai_responseif attempt >= max_retries:return ai_responsenext_tokens = max_tokens * 2if next_tokens > max_tokens_limit:return ai_responsemax_tokens = next_tokens
重试策略的设计思路:
-
初始 max_tokens 从配置读取(默认 9000) -
检测到截断(finish_reason == “length”)时,将 max_tokens 翻倍重试 -
翻倍上限由 max_tokens_limit(默认 64000)控制 -
最大重试次数由 max_retries(默认 3)控制 -
超过任一限制,返回带截断标记的结果而非无限重试
流式调用(stream_chat)处理了三种 finish_reason:
-
“length”:标记截断,触发重试逻辑 -
“stop”:正常结束 -
其他:记录原因并结束
3.5 工具调用解析
工具解析器(llm_tool/tool_executor.py)是整个工具系统的核心。它使用正则表达式从 LLM 的文本响应中提取 XML 格式的工具调用:
patterns = [("view", re.compile(r'<view\s+path="([^"]*)"\s*/>')),("create", re.compile(r'<create\s+path="([^"]*)">(.*?)</create>', re.DOTALL)),("bash", re.compile(r'<bash>(.*?)</bash>', re.DOTALL)),("str_replace", re.compile(r'<str_replace\s+path="([^"]*)">(.*?)<old>(.*?)</old>(.*?)<new>(.*?)</new>(.*?)</str_replace>',re.DOTALL)),("done", re.compile(r'<done>(.*?)(?:</done>|$)', re.DOTALL)),]
设计要点:
-
五个工具的正则按出现位置排序,保持原始顺序 -
done 标签允许不闭合( </done>|$),作为容错措施 -
str_replace 使用四段式结构(path + old + new),支持精确的代码替换 -
非工具文本(remaining)被保留并展示给用户,实现”对话 + 工具调用”混合输出 -
连续三个以上的换行被压缩为两个,保持输出整洁
返回结构为 (剩余文本, 工具列表),其中工具列表的每个元素为 {"llm_tool": "工具名", "params": {...}}。
3.6 工具执行
工具执行函数 execute_code_tool 根据工具名分发到具体实现:
-
view:调用 file_view,支持查看文件内容和目录列表 -
create:调用 file_create,自动创建父目录,检测已有文件并拒绝覆盖 -
str_replace:调用 file_str_replace,精确匹配替换,仅替换首次出现 -
bash:调用 tool_bash,subprocess.run 执行,30 秒超时
文件操作的安全边界:
-
所有相对路径拼接到 code_output_root 目录下,防止越权访问 -
create 检测文件已存在且非空时拒绝覆盖,要求使用 str_replace -
bash 通过 subprocess 的超时机制防止命令挂起 -
绝对路径直接放行(信任 LLM 的判断)
3.7 CLI 界面
CLI 界面(cli/mycli.py + cli/cli_print.py)实现了完整的交互体验:
-
主循环:接收输入 → 判断是否为斜杠命令 → 如果是命令则路由处理,否则进入查询循环 -
命令系统:/quit(退出)、/clear(清屏)、/help(帮助)、/tokens(显示 token 消耗) -
输出渲染:通过回调函数将 QueryLoop 的事件(状态显示、LLM 回复、工具调用、工具结果)映射为 Rich 终端的格式化输出 -
打字机效果:可配置的逐字符输出延迟,模拟实时打印
回调注入模式的设计非常优雅。QueryLoop 不直接依赖 CLI 模块,而是通过 run() 方法的参数接收五个回调函数:
defrun(self, user_input,on_context_mgr, # 状态上下文管理器(显示 thinking 动画)print_info, # 信息输出print_llm_rsp, # LLM 响应渲染print_tool_call, # 工具调用显示print_tool_result): # 工具结果显示
这种设计实现了查询逻辑与表现层的完全解耦——可以替换为 WebSocket 输出、GUI 界面或任何其他表现形式。
4. 功能详解
4.1 查询循环
QueryLoop.run() 是项目的核心编排方法。每次调用代表一个完整的用户查询会话:
turn = 0while turn < max_turns:turn += 11. 发送消息给 LLM(首轮初始化消息,后续轮追加工具结果)2. 接收 LLM 响应3. 解析响应中的工具调用4. 如果有 done 工具 → 结束循环5. 如果无工具调用且非对话模式 → 结束循环6. 否则执行工具,结果追加到消息列表,继续循环
对话模式的判断逻辑:
-
初始化时 is_chat_mode = True -
一旦发现 LLM 返回了工具调用,is_chat_mode = False -
在非对话模式下,如果 LLM 未返回任何工具(包括 done),系统直接结束循环并提示用户——不做额外补救 -
这个机制防止了 LLM 在工具使用中途”迷失方向”而无限挂起
最后一轮的特殊处理:在发起 LLM 请求前(_on_llm_req),如果当前已是最后一轮且处于编码模式,系统会提前追加指令 "请立刻完成当前任务,使用 <done> 标记结束",争取在超限前完成任务,这是一种温和的强制终止机制。
4.2 工具调用流程
一次完整的工具调用流程如下(以”写一个斐波那契函数”为例):
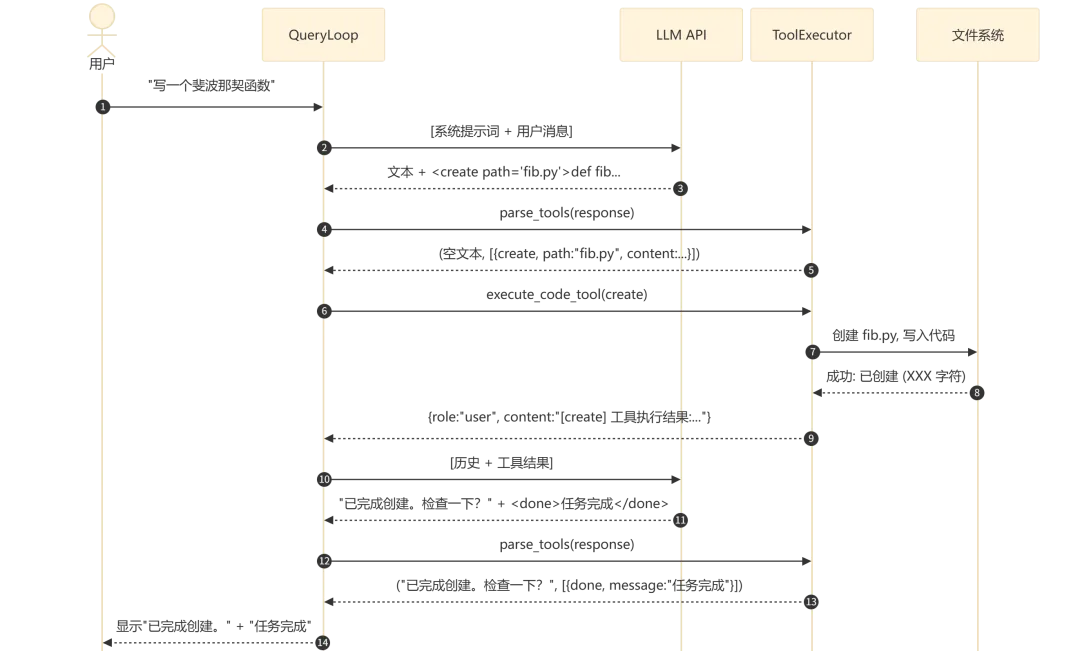
流程执行说明:
-
步骤 1-2:用户输入被封装为 API 消息并发送给 LLM -
步骤 3-4:LLM 返回的响应中同时包含说明文本和 XML 工具标签,解析器将其分离 -
步骤 5-8:create 工具执行,将代码写入文件系统,执行结果以 user 角色追加到消息列表 -
步骤 9-12:LLM 收到工具执行结果后判断任务完成,发出 done 信号 -
步骤 13:QueryLoop 检测到 done 工具,退出循环并展示最终结果
关键设计:
-
工具结果以 user 角色返回是一个巧妙的设计,让 LLM 将其视为”用户告诉你操作结果”,自然地理解并做出后续响应 -
多工具并行执行支持:同一轮响应中的多个工具会依次执行
4.3 对话模式与编码模式切换
QueryLoop 维护一个 is_chat_mode 标记来区分两种交互模式:
-
对话模式(is_chat_mode = True):LLM 直接回复文本,不产生工具调用。本轮结束后 QueryLoop 退出循环(QuitByNoneTool) -
编码模式(is_chat_mode = False):LLM 产生了至少一次工具调用。此后每次循环都期待 LLM 继续使用工具或发出 done 信号
模式切换逻辑:
# 如果 LLM response 里有工具,那就不是单纯的对话模式self.is_chat_mode = False# 如果无工具且为非对话模式:提醒用户ifnot self.is_chat_mode:self._print_info("LLM 未发出 done 工具,编码操作可能未完成,已自动结束")
这种设计的巧妙之处在于:单次交互中 LLM 的行为可能从”对话”切换为”编码”,但不会从”编码”切回”对话”。一旦 LLM 开始使用工具,就必须明确发出 done 信号才能结束,防止中途沉默。
5. 技术亮点
5.1 分层规则系统
系统提示词的六层结构是经过精心设计的:
-
优先级从高到低,高层规则覆盖低层规则 -
每层处理一类独立的决策问题,互不干扰 -
冲突仲裁层(Layer 3)明确处理模糊场景 -
环境约束层(Layer 6)将运行时环境信息注入提示词,让 LLM 产生平台正确的命令
这种分层设计比单一长提示词更易于维护和调优——可以独立修改某一层的规则而不影响其他层。
5.2 正则解析器设计
工具解析器使用正则表达式而非 XML 解析器,原因在于:
-
LLM 输出天然包含”不合法”的 XML(如不闭合的 done 标签、混合文本与标签) -
正则表达式对格式错误具有天然的容错性 -
解析失败时返回空工具列表,系统将其视为普通文本回复,不会崩溃
done 标签的正则 r'<done>(.*?)(?:</done>|$)' 尤其体现了容错设计——即使 LLM 忘记闭合标签,也能正确提取内容。
5.3 智能重试机制
chat_with_retry 实现了一种指数退避的变体——不是延长等待时间,而是扩大 token 配额。这个设计基于一个洞察:LLM 输出被截断最常见的原因是 max_tokens 设置不足,而非网络波动。因此:
-
检测到截断 → 翻倍 max_tokens → 重试 -
达到上限或最大重试次数 → 返回当前结果(即使截断) -
保证了重试不会无限进行
5.4 配置驱动的模块化
所有可调参数集中在 config.yaml 中,通过 SimpleNamespace 转换为点号访问。模块间依赖通过”导入 global_cfg 单例”的方式实现,避免了参数层层传递。
这种设计有一个隐含优势:AI 在自我进化时,可以通过修改 config.yaml 来调整行为,而不需要深入理解代码结构。
5.5 工具执行安全边界
-
文件操作默认限制在 code_output_root 目录内(通过 add_root_path 函数拼接路径前缀) -
create 操作检测已有文件并拒绝覆盖,防止 AI 误删代码 -
bash 执行有 30 秒超时保护 -
系统提示词中声明”环境为 Windows”,引导 LLM 生成正确的命令
6. 实践指南
6.1 环境准备
依赖项(requirements.txt):
-
openai >= 1.0.0:LLM API 客户端 -
rich >= 13.0.0:终端 UI 渲染 -
pyyaml >= 6.0:配置文件解析 -
numpy >= 1.24.0:数学计算(为 MemorySystem 预留)
pip install -r requirements.txt6.2 配置说明
config.yaml 分为五个配置组:
-
model:LLM API 连接参数(api_key、base_url、model_name、max_tokens、temperature) -
model_chat:重试策略参数(initial_max_tokens、max_retries、max_tokens_limit) -
memory:记忆系统配置(root_dir、max_inject_tokens、compact_threshold) -
code_project:项目路径配置(project_root、code_output_root、logs_root) -
cli:终端界面配置(theme、typewriter_delay、max_turns、show_thinking)
关键配置项:
-
model.api_key:LLM API 密钥 -
cli.max_turns:工具调用最大轮次(默认 10),防止 LLM 陷入无限循环 -
code_project.code_output_root:AI 生成代码的输出目录
6.3 运行与调试
cd MyClaudepython src/myclaude.py
启动后进入交互式 CLI 界面,支持的命令:
-
/help:显示帮助信息 -
/clear:清屏 -
/tokens:显示当前会话的 token 消耗 -
/quit 或 /exit:退出程序
直接输入自然语言即可与 AI 对话。当 AI 检测到编码意图时,会自动切换到工具模式,使用 XML 标签执行文件操作。
7. 总结
MyClaude 用约 500 行 Python 代码实现了一个完整的 AI 编程助手核心循环,展示了几个关键设计原则:
-
极简分层架构:每层职责单一,模块间通过回调注入解耦,没有任何循环依赖 -
分层提示词工程:六层规则系统比单一长提示词更可维护,正反示例对比提升 LLM 行为准确性 -
容错优先的解析器:正则表达式比 XML 解析器更适合解析 LLM 的非严格输出 -
配置驱动:所有可调参数集中管理,为 AI 自我进化提供简洁的”控制面板” -
安全的执行边界:文件操作限制在指定目录,bash 有超时保护,防止意外破坏
适合以下读者阅读:
-
想理解 AI Coding 助手底层原理的开发者 -
准备构建自己的 AI Agent 系统的工程师 -
对 LLM 提示词工程感兴趣的实践者 -
希望研究”最小可行 AI 编码助手”架构的学习者
该项目的下一步方向是让 0.01 版本在 AI 辅助下自我进化到 0.1 版本,这将涉及代码生成、测试验证、自动提交等自动化流程的引入。
参考文献
[1] MyClaude 项目仓库:https://github.com/1801573781/MyClaude
[2] MiniMax API 文档:https://platform.minimaxi.com
[3] OpenAI Python SDK:https://github.com/openai/openai-python
[4] Rich 终端库:https://github.com/Textualize/rich
[5] PyYAML 文档:https://pyyaml.org