 夜雨聆风
夜雨聆风





AI 产业链全景图谱:从芯片到应用,钱流向了哪里
▎全文约 10,000 字(含数据图表),阅读约需 20-25 分钟。
一、写在最前面
2026 年,全球 AI 支出预计达到 2.5 万亿美元,同比增长 44%(Gartner)。这个数字听起来很惊人,但如果拆开来看,你会看到一个极不均衡的价值分配结构。
OpenAI 刚刚完成了历史上最大规模的私募融资——1220 亿美元,估值 8520 亿。但与此同时,这家公司 2026 年预计亏损 140 亿美元,每赚 1 美元要花掉 1.35 美元。
NVIDIA (英伟达) 在 2026 财年数据中心收入 1937 亿美元(截至 2026 年 1 月),营业利润率超过 55%。
SK Hynix (海力士) 在 2026 年 Q1 收入同比暴增近 200%,HBM(高带宽内存)产能到 2027 年全部售罄。
台积电 2026 年资本开支 560 亿美元,先进封装产能(CoWoS)以 80% CAGR 扩张——但仍然供不应求。
AI 不是不赚钱,而是被”卖铲子的”赚走了。 越往上游、越靠近物理世界,赚钱确定性越高。
本文把 AI 产业链梳理为 7 个层次,从最底层的芯片制造开始,逐层往上走到应用层,试图将整个产业清晰的放在读者面前。
二、七层结构的全景图谱

一个或许不成立的规则:离沙子(硅)越近,赚钱确定性越高;离用户越近,竞争越激烈。
这不是巧合。芯片制造涉及的是物理世界的极限——纳米级的刻蚀精度、全球最复杂的供应链、十年以上的经验积累。这些东西不是写个更好的代码、训练个更好的模型就能替代的。
接下来的七个部分,我们从下往上,逐层深入。
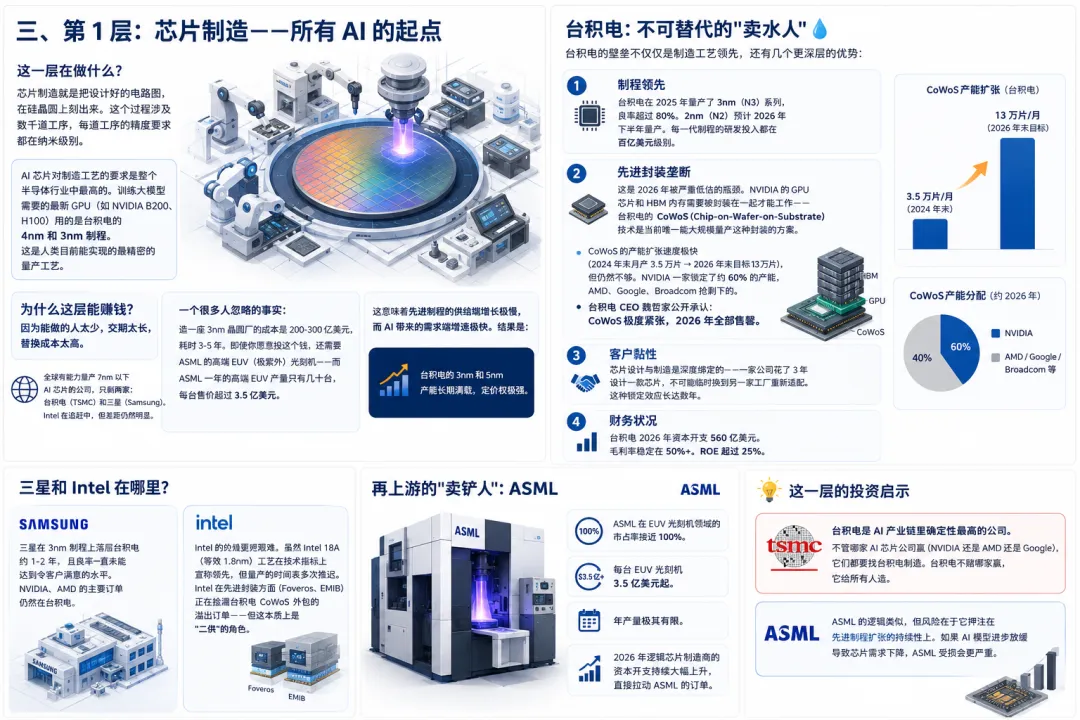
三、第 1 层:芯片制造——所有 AI 的起点
这一层在做什么?
芯片制造就是把设计好的电路图,在硅晶圆上刻出来。这个过程涉及数千道工序,每道工序的精度要求都在纳米级别。
AI 芯片对制造工艺的要求是整个半导体行业中最高的。训练大模型需要的最新 GPU(如 NVIDIA B200、H100)用的是台积电的 4nm 和 3nm 制程。这是人类目前能实现的最精密的量产工艺。
为什么这层能赚钱?
因为 能做的人太少,交期太长,替换成本太高。
全球有能力量产 7nm 以下 AI 芯片的公司,只剩两家:台积电(TSMC)和三星(Samsung)。Intel 在追赶中,但差距仍然明显。
一个很多人忽略的事实:造一座 3nm 晶圆厂的成本是 200-300 亿美元,耗时 3-5 年。即使你愿意投这个钱,还需要 ASML 的高端 EUV(极紫外)光刻机——而 ASML 一年的高端 EUV 产量只有几十台,每台售价超过 3.5 亿美元。
这意味着先进制程的供给端增长极慢,而 AI 带来的需求端增速极快。结果是:台积电的 3nm 和 5nm 产能长期满载,定价权极强。
台积电:不可替代的代工者
台积电的壁垒不仅仅是制造工艺领先,还有几个更深层的优势:
1. 制程领先
台积电在 2025 年量产了 3nm(N3)系列,良率超过 80%。2nm(N2)预计 2026 年下半年量产。每一代制程的研发投入都在百亿美元级别。
2. 先进封装垄断
这是 2026 年被严重低估的瓶颈。NVIDIA 的 GPU 芯片和 HBM 内存需要被封装在一起才能工作——台积电的 CoWoS(Chip-on-Wafer-on-Substrate) 技术是当前唯一能大规模量产这种封装的方案。
CoWoS 的产能扩张速度极快(2024 年末月产 3.5 万片→2026 年末目标 13 万片),但仍然不够。NVIDIA 一家锁定了约 60% 的产能,AMD、Google、Broadcom 抢剩下的。
台积电 CEO 魏哲家公开承认:CoWoS 极度紧张,2026 年全部售罄。
3. 客户黏性
芯片设计与制造是深度绑定的——一家公司花了 3 年设计一款芯片,不可能临时换到另一家工厂重新适配。这种锁定效应长达数年。
4. 财务状况
台积电 2026 年资本开支 560 亿美元。毛利率稳定在 50%+。ROE 超过 25%。
三星和 Intel 在哪里?
三星在 3nm 制程上落后台积电约 1-2 年,且良率一直未能达到令客户满意的水平。NVIDIA、AMD 的主要订单仍然在台积电。
Intel 的处境更艰难。虽然 Intel 18A(等效 1.8nm)工艺在技术指标上宣称领先,但量产的时间表多次推迟。Intel 在先进封装方面(Foveros、EMIB)正在捡漏台积电 CoWoS 外包的溢出订单——但这本质上是”二供”的角色。
再上游的”卖铲人”:ASML
台积电要造先进芯片,必须买 ASML 的光刻机。ASML 在 EUV 光刻机领域的市占率接近 100%。每台 EUV 光刻机 3.5 亿美元起,年产量极其有限。2026 年逻辑芯片制造商的资本开支大幅上升,直接拉动 ASML 的订单。
这一层的投资启示
台积电是 AI 产业链里确定性最高的公司。不管哪家 AI 芯片公司赢(NVIDIA 还是 AMD 还是 Google),它们都要找台积电制造。台积电不赌哪家赢,它给所有人造。
ASML 的逻辑类似,但风险在于它押注在先进制程扩张的持续性上。如果 AI 模型进步放缓导致芯片需求下降,ASML 受损会更严重。
四、第 2 层:AI 芯片设计——NVIDIA 不是唯一的答案
这一层在做什么?
芯片设计公司负责把 AI 算法的计算需求转化为芯片电路设计。它们不自己生产芯片(交给台积电/三星),专注于设计本身。
AI 芯片的核心是一种叫”矩阵乘法”的数学运算——大模型本质上是一个巨大的矩阵计算问题。谁把这个计算做得最快、最省电、最便宜,谁就赢了。
NVIDIA(NVDA):当前的绝对霸主
NVIDIA 在 2026 财年数据中心收入 1937 亿美元,营业利润率 >55%。这个利润率放在整个科技行业里也是顶级水平。
NVIDIA 的护城河不止是硬件。
NVIDIA 的核心竞争力是 CUDA 生态。一个简单的数字对比:AMD 和 Intel 也有 AI 加速卡,硬件指标差距不大,但全球做 AI 的工程师从第一天起就用 CUDA。训练框架(PyTorch、TensorFlow、JAX)的底层优化都是针对 NVIDIA GPU。几乎所有 AI 推理框架也优先支持 CUDA。
这意味着切换 NVIDIA 的成本不只是”换一块卡”——而是整个软件栈的迁移。对于一家部署了数千张 GPU 的企业,这个成本极其高昂。
但这不代表 NVIDIA 没有弱点。
训练垄断 vs 推理竞争。 在训练市场,NVIDIA 市占率仍然在 90% 以上。但在推理市场(目前占总 AI 计算支出的三分之二),格局完全不同:
-
Google 的 TPU 已经在处理 Gemini 90%+ 的推理 -
Amazon 的 Trainium 正在被 Anthropic 和 OpenAI 用于推理 -
微软的 Maia 200 专为 Azure 推理优化 -
AMD 的 MI400 正在将 HBM 容量提升到 432 GB
NVIDIA 面临的是”竞争从四面八方来”的局面。每一家超大规模云厂商都有自己的定制芯片计划——不是为了完全取代 NVIDIA,而是 不依赖单一供应商。
Blackwell 和 Rubin:守住王座的方法。
NVIDIA 的策略是不断拉高天花板。Blackwell B200 是当前旗舰,192 GB HBM3e 内存,单芯片功耗 1000W。2026 年下半年推出的 Vera Rubin 平台将进一步扩大领先优势。
Google TPU:最成熟的自研芯片
Google 从 2013 年开始造 TPU,到 2026 年已经是第七代。最新一代 Ironwood(TPU v7) 专门为推理设计:
-
4,614 TFLOPS(FP8)每芯片 -
192 GB HBM,7.37 TB/s 带宽 -
单个集群可扩展到 9,216 个芯片,总算力 42.5 ExaFLOPS
最大的新闻是:Anthropic 与 Google 签署了价值 400 亿美元的 TPU 使用协议,覆盖 3.5-5 GW 的计算容量。这意味着除了 NVIDIA GPU,Anthropic 的训练和推理正在大规模使用 TPU。Meta 也在 2026 年 2 月签署了数十亿美元的 Google Cloud TPU 合同,用于 Llama 4 的训练和推理。
这个信号非常明确:连 AI 模型公司自己都在主动寻求多元化。 它们不希望被 NVIDIA 锁死。
定制 ASIC 的崛起
这是 2026 年最重要的结构性变化之一。定制 ASIC(专用集成电路)市场增速 44.6%,远超 GPU 的 16.1%。
- Broadcom
定制 ASIC 设计龙头,Google TPU 和 Meta MTIA 的核心设计伙伴。2025 财年 AI ASIC 收入超 40 亿美元。 - Marvell
Amazon Trainium 的设计伙伴。 - Microsoft Maia 200
140 亿晶体管,216GB HBM3e,3nm,专门优化 Azure 推理成本(比上一代便宜 30%)。 - Amazon Trainium 3
正在被 Anthropic 和 OpenAI 使用。 - Meta MTIA
计划在 2 年内发布 4 代芯片,采用 RISC-V 架构。
搞清楚分工:定制的 ASIC 主要打推理市场,因为推理的工作负载高度固定,可以极致优化。但训练市场仍然被通用 GPU 主导,因为训练是一个快速变化的过程,通用软件栈更加灵活。2026 年推理芯片市场的 ASIC 占比预计为 40%,而 2024 年只有 15%。
AMD:追赶者
AMD 的 MI300X 和 MI400X 在纯算力指标上与 NVIDIA 接近,但面临三个挑战:
- 软件生态严重落后
——ROCm 比起 CUDA 还有数年差距 - 企业信任不足
——大客户偏向 NVIDIA 的成熟方案 - InfiniBand 网络锁死
——NVIDIA 收购 Mellanox 后,InfiniBand + GPU 的捆绑策略大大降低了切换意愿
这一层的投资启示
NVIDIA 未来 2-3 年仍然是最强的 AI 芯片公司。但需要警惕的是:推理市场正在被定制 ASIC 和网络效应相对薄弱的竞争者蚕食。 NVIDIA 的 CUDA 护城河在训练端固若金汤,但在推理端——这个正在变成最大市场的环节——护城河要浅得多。
Broadcom 是隐藏的赢家。它不直接卖芯片给终端用户,而是为 Google、Meta 等超大规模厂商做定制 ASIC 设计。这是”卖铲子给卖铲子的人”——不直接参与 GPU 大战,但每多一家公司自研芯片,Broadcom 就多一份生意。

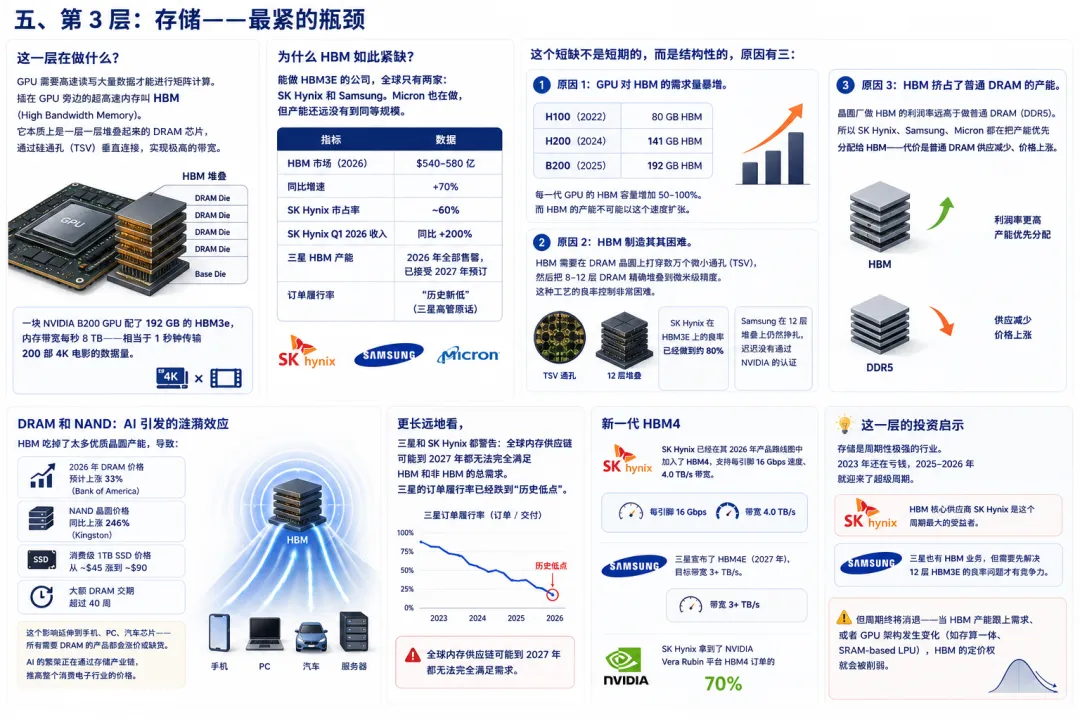
五、第 3 层:存储——最紧的瓶颈
这一层在做什么?
GPU 需要高速读写大量数据才能进行矩阵计算。插在 GPU 旁边的超高速内存叫 HBM(High Bandwidth Memory)。它本质上是一层一层堆叠起来的 DRAM 芯片,通过硅通孔(TSV)垂直连接,实现极高的带宽。
一块 NVIDIA B200 GPU 配了 192 GB 的 HBM3e,内存带宽每秒 8 TB——相当于 1 秒钟传输 200 部 4K 电影的数据量。
为什么 HBM 如此紧缺?
能做 HBM3E 的公司,全球只有两家:SK Hynix 和 Samsung。 Micron 也在做,但产能还远没有到同等规模。
|
|
|
|---|---|
|
|
$540-580 亿 |
|
|
+70% |
|
|
|
|
|
同比 +200% |
|
|
|
|
|
|
这个短缺不是短期的,而是结构性的,原因有三:
原因 1:GPU 对 HBM 的需求量暴增。
-
H100(2022):80 GB HBM -
H200(2024):141 GB HBM -
B200(2025):192 GB HBM
每一代 GPU 的 HBM 容量增加 50-100%。而 HBM 的产能不可能以这个速度扩张。
原因 2:HBM 制造极其困难。
HBM 需要在 DRAM 晶圆上打穿数万个微小通孔(TSV),然后把 8-12 层 DRAM 精确堆叠到微米级精度。这种工艺的良率控制非常困难。SK Hynix 在 HBM3E 上的良率已经做到约 80%,但 Samsung 在 12 层堆叠上仍然挣扎,迟迟没有通过 NVIDIA 的认证。
原因 3:HBM 挤占了普通 DRAM 的产能。
晶圆厂做 HBM 的利润率远高于做普通 DRAM(DDR5)。所以 SK Hynix、Samsung、Micron 都在把产能优先分配给 HBM——代价是普通 DRAM 供应减少、价格上涨。
DRAM 和 NAND:AI 引发的涟漪效应
HBM 吃掉了太多优质晶圆产能,导致:
- 2026 年 DRAM 价格预计上涨 33%
(Bank of America) - NAND 晶圆价格同比上涨 246%
(Kingston) -
消费级 1TB SSD 价格从 ~$45 涨到 ~$90 -
大额 DRAM 交期超过 40 周
这个影响延伸到手机、PC、汽车芯片——所有需要 DRAM 的产品都会涨价或缺货。AI 的繁荣正在通过存储产业链,推高整个消费电子行业的价格。
更长远地看,三星和 SK Hynix 都警告:全球内存供应链可能到 2027 年 都无法完全满足 HBM 和非 HBM 的总需求。三星的订单履行率已经跌到”历史低点”。
新一代 HBM4
SK Hynix 已经在其 2026 年产品路线图中加入了 HBM4,支持每引脚 16 Gbps 速度、4.0 TB/s 带宽。三星宣布了 HBM4E(2027 年),目标带宽 3+ TB/s。SK Hynix 拿到了 NVIDIA Vera Rubin 平台 HBM4 订单的 70%。
这一层的投资启示
存储是周期性极强的行业。2023 年还在亏钱,2025-2026 年就迎来了超级周期。HBM 核心供应商 SK Hynix 是这个周期最大的受益者,三星也有 HBM 业务,但需要先解决 12 层 HBM3E 的良率问题才有竞争力。
但周期终将消退——当 HBM 产能跟上需求、或者 GPU 架构发生变化(如存算一体、SRAM-based LPU),HBM 的定价权就会被削弱。
六、第 4 层:封装与互联——看不见的瓶颈
CoWoS:GPU 和 HBM 之间的”胶水”
CoWoS 做的事情,用一句话概括就是:把 GPU 计算芯片和 HBM 内存堆叠在同一个封装里,让它们之间的通信带宽最大化。
如果不做 CoWoS 封装,GPU 和 HBM 之间只能通过 PCB 走线连接,带宽要比封装内互联低 10-100 倍,功耗也高得多。对于训练大模型需要的海量数据传输来说,这是不可接受的。
2026 年 CoWoS 的供需情况:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
持续到 2027 年以后 |
|
|
|
|
|
|
|
|
|
台积电甚至开始外包部分 CoWoS 工序给 Amkor 和 ASE(日月光)——不是因为想做,而是实在做不完。2026 年台积电外包的 CoWoS 晶圆预计达 24-27 万片。
CoWoS 比 HBM 更紧缺。 HBM 至少有两个供应商,而 CoWoS 只有台积电一家能做大规摸量产。这也是为什么一些分析师说:CoWoS,而不是 HBM,才是 AI 硬件最真实的瓶颈。
光模块:AI 集群的血管
AI 集群不只是几千张 GPU 放在一起——它们需要高速联网互相通信。这个通信通道需要光纤连接,光纤两端的转换器叫 光模块。
光模块市场 2026 年预计达到 260 亿美元(TrendForce),同比增长 57%。2025 年出货了超过 4,200 万个高速模块(400G 和 800G)。
技术路线在加速演进:
400G(2022-2023)→ 800G(2024-2025)→ 1.6T(2026-2027)
800G 的出货量还在增长,1.6T 已经起步。LightCounting 甚至预测到 2030 年,AI 集群光学市场规模可能达到 1000 亿美元。这意味着我们看到的 260 亿可能只是长周期增长的起点。
关键供应商:中际旭创(中国,800G 市占第一)、Coherent、Eoptolink(新易盛)、Lumentum。上游激光器芯片(EML,CW-Laser)严重缺货,是当前产能的最大瓶颈。
硅光技术正在成熟:把光学元件直接集成在硅芯片上,可以大幅降低功耗和成本。NVIDIA 在 GTC 2026 发布的 Spectrum-X Photonics 交换机,就是硅光技术的里程碑产品。
网络交换机芯片:GPU 之间的交通指挥
如果光模块是高速公路,交换机芯片就是路口和指挥中心。交换机芯片的两个关键玩家:
Broadcom Tomahawk 6(2026 年 3 月量产):
-
102.4 Tbps 总带宽 -
最多 512 个 200G 端口 -
两层网络拓扑可以连接 128,000 个 XPU
NVIDIA Spectrum-X Photonics(2026 年下半年出货):
-
硅光集成,功耗降低 3.5x -
支持百万 GPU 级别集群 -
配合 InfiniBand,更完整但更封闭
这里有一个关键的战略矛盾:NVIDIA 希望用 InfiniBand 锁定 AI 网络,但行业正在朝开放的 Ethernet 标准迁移。 Broadcom 推的是后者——如果 Ethernet 生态赢了,NVIDIA 在网络上锁死客户的能力就弱了。
ABF 载板
一个容易被忽略的关键部件。GPU 封装需要高级有机载板(ABF substrate)。全球能做高品质 ABF 载板的只有日本 Ibiden、台湾 Unimicron(欣兴电子)、AT&S 等少数厂商。交期已经拉长到 26-40 周。
ABF 载板 + CoWoS 封装 + 光模块 + 交换机芯片——这四个环节共同构成了 AI 集群的互联基础设施。它们通常不被关注,但决定了”GPU 造出来后能不能真正跑起来”。

七、第 5 层:算力基础设施——电力是真正的天花板
液冷:从可选变成必需
NVIDIA Blackwell B200 单芯片功耗接近 1000W,机架级功率达到 40-140 kW。而在传统数据中心,一个机架的典型功耗只有 5-15 kW。
空气冷却到了这个级别已经物理上不可行。液冷不再是”为了更高效”的选择——它是为了让 GPU 能工作。
|
|
|
|---|---|
|
|
$37 亿 |
|
|
$181 亿
|
|
|
57-75%
|
|
|
|
液冷又分为两个技术路线:直接到芯片(Direct-to-Chip) 和 浸没式(Immersion)。前者通过冷板直接贴在芯片上带走热量,后者把整台服务器泡在绝缘液体里。直接到芯片占当前市场的约 45%,浸没式增长更快(CAGR 26-34%),适合 200 kW/rack 以上的极致密度场景。
关键供应商包括 Vertiv、Schneider Electric、CoolIT(刚被 Ecolab 以 47.5 亿美元收购)。冷量分配单元(CDU)是当前液冷部署的供应瓶颈。
电力:AI 增长的真实天花板
2026 年出现了几个令人警醒的数据:
-
国际能源署(IEA)预测:数据中心用电 2026 年达到 1,000 TWh——相当于整个日本的年用电量 -
美国超大规模云厂商 2026 年资本开支合计 7,250 亿美元 -
变压器交期从正常的 30 周拉长到 120 周以上 -
部分数据中心集群的规模正逼近 1 GW——相当于一个核反应堆的发电量
云厂商的应对策略非常激进:
- Microsoft
签署了核电站购电协议,探索 SMR(小型模块堆)供电 - Google
与 Kairos Power 签署协议,购买多个 SMR 的电力 - Amazon
投资数据中心邻近的天然气和可再生能源项目
Bloom Energy 的 2026 年数据中心电力报告显示:73% 的受访者正在评估或选择现场发电方案。这意味着越来越多的数据中心将脱离电网独立运作。
如果 AI 模型持续进化、Agent 用量爆炸式增长,电力约束可能在 2027-2028 年变成一个”硬天花板”——不是芯片不够,而是电不够。

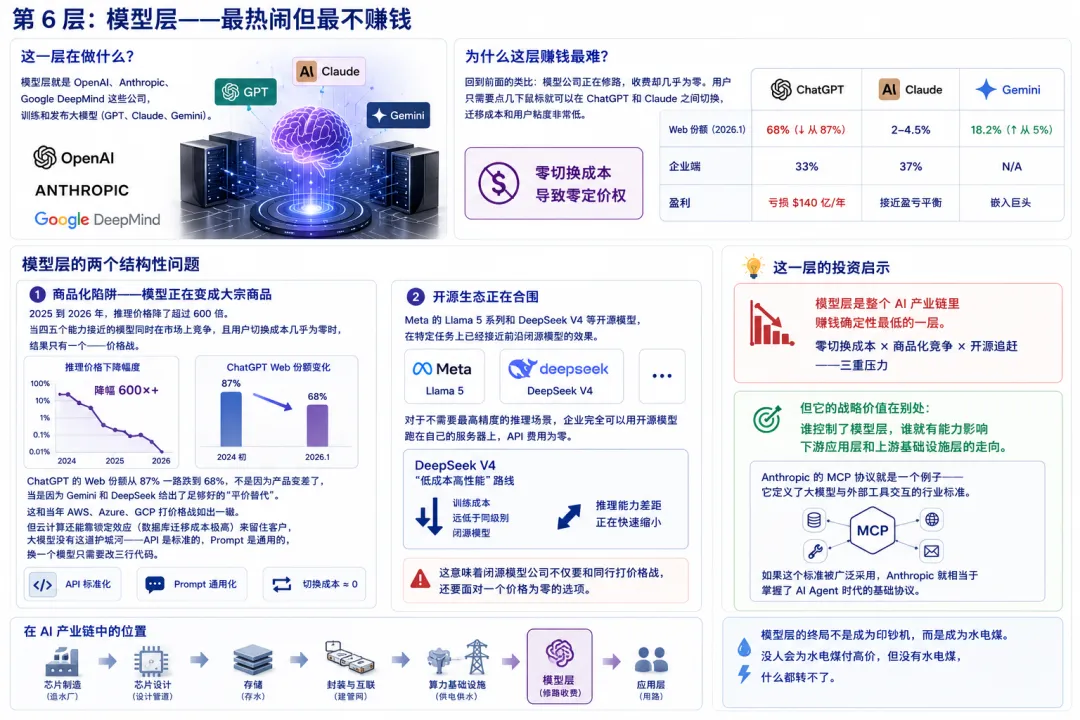
第 6 层:模型层——最热闹但最不赚钱
这一层在做什么?
模型层就是 OpenAI、Anthropic、Google 这些公司,训练和发布大模型(GPT、Claude、Gemini)。
为什么这层赚钱最难?
回到前面的类比:模型公司正在修路,收费却几乎为零。 用户只需要点几下鼠标就可以在 ChatGPT 和 Claude 之间切换,迁移成本和用户粘度非常低。
零切换成本导致零定价权。
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
37% |
|
|
|
|
|
|
模型层的两个结构性问题:
1. 商品化陷阱——模型正在变成大宗商品
2025 到 2026 年,推理价格降了超过 600 倍。当四五个能力接近的模型同时在市场上竞争,且用户切换成本几乎为零时,结果只有一个——价格战。ChatGPT 的 Web 份额从 87% 一路跌到 68%,不是因为产品变差了,而是因为 DeepSeek 给出了足够好的”平价替代”。
这和当年 AWS、Azure、GCP 打价格战如出一辙。但云计算还能靠锁定效应(数据库迁移成本极高)来留住客户,大模型没有这道护城河——API 是标准的,Prompt 是通用的,换一个模型只需要改三行代码。
2. 开源生态正在合围
DeepSeek V4 等开源模型,在特定任务上已经接近前沿闭源模型的效果。对于不需要最高精度的推理场景,企业完全可以用开源模型跑在自己的服务器上,API 费用为零。DeepSeek V4 的”低成本高性能”路线尤其值得关注——训练成本远低于同级别的闭源模型,且推理能力上的差距正在快速缩小。
这意味着闭源模型公司不仅要和同行打价格战,还要面对一个价格为零的选项。
这一层的投资启示
模型层是整个 AI 产业链里赚钱确定性最低的一层。 零切换成本 × 商品化竞争 × 开源追赶——三重压力。
但它的战略价值在别处:谁控制了模型层,谁就有能力影响下游应用层和上游基础设施层的走向。 Anthropic 的 MCP 协议就是一个例子——它定义了大模型与外部工具交互的行业标准。如果这个标准被广泛采用,Anthropic 就相当于掌握了 AI Agent 时代的基础协议。
模型层的终局不是成为印钞机,而是成为水电煤。没人会为水电煤付高价,但没有水电煤,什么都转不了。
九、第 7 层:应用层——赚慢钱的赢家
这一层在做什么?
在基础模型之上,把 AI 能力嵌入到具体的产品和服务中,让终端用户直接使用。
微软:隐藏的赢家
a16z 的 CIO 调查揭示了关键数据:
|
|
|
|
|---|---|---|
|
|
90%+ |
|
|
|
~74% |
|
|
|
|
|
为什么微软能赢?因为 65% 的企业倾向于从已有供应商购买 AI。微软是大多数企业的已有供应商。Copilot 的增量成本远低于单独购买 AI 服务的成本。微软的策略:不做最酷的模型,但让所有企业用户都在自己的日常工作里用上 AI。
Salesforce Agentforce 和其他垂直玩家
Salesforce 的 Agentforce 在 2025 年做到了 5 亿美元+ ARR,增速 330%。ServiceNow 的 AI Agent 产品也在快速渗透。这些公司的共同特点是:它们本来就有客户关系和业务流程,AI 只是增加了一个功能模块。
AI 原生公司的挑战
ChatGPT(个人版)虽然增长极快,但遇到了两个问题:免费用户的货币化率很低,海量的免费推理需求变成了巨额成本;企业采购跳过 chat 直接找 API——Microsoft 的 Copilot 和 Salesforce 的 Agentforce 才是企业真正买单的地方。
AI 原生应用在消费者端面临”同质化竞争 → 零切换成本 → 利润极薄”的困局。
这一层的投资启示
应用层的赢家,不是”把 AI 做成新产品的公司”,而是”把 AI 嵌入已有产品的公司”。 微软是企业端最大的受益者。Salesforce、ServiceNow 等 SaaS 巨头会陆续从 AI 功能中获得实质性收入增长。

十、一张图总结
AI 产业链价值分布(2026)芯片制造(台积电) 利润率高 ~50% 护城河极深 ★★★★★★AI 芯片(NVIDIA) 利润率极高 >55% 护城河深 ★★★★★存储 HBM(SK Hynix) 利润率极高(周期高点) 护城河中 ★★★★封装/互联(CoWoS/光模块) 利润中高 护城河中 ★★★★★基础设施(液冷/电力) 利润中 护城河浅→中 ★★★★★模型层(OpenAI/Anthropic) 利润负→低 护城河极浅 ★★★应用层(微软/Copilot) 利润中 护城河中→深 ★★★★
核心判断:
- 台积电是确定性最高的
不管哪家芯片赢,都找它造 - NVIDIA CUDA 护城河极深,但推理市场正在被蚕食
- SK Hynix 处于周期顶峰
周期性风险不可忽视 - CoWoS 和光模块是不被关注的隐藏瓶颈
- 模型层热闹但不赚钱
蒸馏和零切换成本是结构性问题 - 应用层微软最有可能成为最终赢家
▎如果觉得有收获,欢迎关注我,我会持续分享对投资和AI的想法。
写作时间:2026 年 5 月 6 日
主要数据来源:Gartner、IDC、TrendForce、ABI Research、a16z CIO Survey、Ramp AI Index、LightCounting、Cignal AI、Bloom Energy、Market Decipher、DigitalOcean、PwC 等机构报告。