 夜雨聆风
夜雨聆风





前沿研究 | AI 翻译正在"胡编"你的合同
 苹果最新论文揭露:96% 的”幻觉”,正在被技术化解
苹果最新论文揭露:96% 的”幻觉”,正在被技术化解
——一份给所有专业译者的”AI 翻译质量自救指南”
先讲三个真实发生的故事——
【场景一】某医疗会议上,AI 转录翻译工具把患者讲述的 “父亲再婚不久后去世”篡改为“她确实在 65 岁时去世了”。同一份转录里,AI 还凭空捏造了一种叫”高活性抗生素”的药物名称。
【场景二】一家跨国企业的商务谈判中,翻译耳机漏译了一个关键的语气词,把对方的委婉拒绝翻成了积极回应——双方差点在”达成共识”的错觉中签下分歧巨大的合同。
【场景三】 2023 年 6 月,一名美国律师用 ChatGPT 起草法庭文书,文中引用了 6 个”格式工整、来源标准、看起来无懈可击”的判例——结果全部都是 ChatGPT 凭空编造的,根本不存在。这位律师最终被法院罚款。
这三件事看似不相关,但它们指向同一个深藏在 AI 翻译技术底层的——而且很少有翻译从业者真正搞懂的——核心问题:
|
AI 不是”翻译错了”,它是在”胡编”。 这种行为,技术界给了它一个专门的名字——”幻觉”(Hallucination)。 |
就在 2025 年初,一篇由波士顿大学与苹果公司联合发表的论文,把”翻译幻觉”这个老问题推到了行业聚光灯下——
|
Tang Z, Chatterjee R, Garg S. (2025). Mitigating Hallucinated Translations in Large Language Models with Hallucination-focused Preference Optimization. arXiv:2501.17295. (中文标题:《通过幻觉聚焦偏好优化缓解大语言模型的翻译幻觉》) |
更让人振奋的是,2025 年 10 月,阿里巴巴国际数字商业集团紧跟其后,发布了一篇更进一步的论文—— M²PO(多对多视角偏好优化),专门从中国行业实战的视角,提出了对抗翻译幻觉的全新框架。
|
Wang H, Xu L, Liu H, et al. (2025). Beyond Single-Reward: Multi-Pair, Multi-Perspective Preference Optimization for Machine Translation. arXiv:2510.13434. |
两篇论文,给出了同一个让译者振奋的结论——
|
AI 翻译幻觉,不是”无解的玄学”,而是可以被系统性识别、量化、并且大幅降低的工程问题。 |
苹果的实验数据显示:在英→捷克、英→德、英→冰岛、英→俄、英→中文这 5 个语言对中,他们的方法把幻觉率平均降低了 96%;在没见过的 3 种新语言上,也降低了 89%。
今天,我们就把这两篇前沿论文的核心精华,“翻译”成普通译者能立刻用上的实战指南。
01
什么是“翻译幻觉”?四种你必须警惕的形态
在动论文之前,我们先帮你建立一套“识别幻觉”的眼力。
“幻觉”这个术语最早来自 2017 年 Google 研究团队描述神经机器翻译(NMT)的一种异常行为——模型生成了与原文完全无关的输出。后来 Meta 在 2021 年发布 BlenderBot 2 时,把它定义为:
|
“自信但不真实的陈述(Confident but untrue statements)。” |
简单说:AI 的幻觉,不是”它不知道”,而是”它一本正经地胡说八道”——而且常常说得比真话还流畅、还让人信服。
在翻译场景中,幻觉至少有四种典型形态——

图 1:翻译幻觉的四种典型形态(基于学界研究整理)
① 事实幻觉(Factual Hallucination)——AI 在”添加私货”
原文里只说“上周提了项目”,AI 译文却给你加上了”张明在上周三的董事会上“。这些原文里根本不存在的具体细节——人名、时间、地点、数字——都是 AI 凭空生成的。
为什么会这样?因为大语言模型的训练目标是“生成最像人话的内容“,而不是”只说原文里有的内容“。当原文比较抽象、信息稀疏时,模型就会本能地”补全”——把空白填满,让译文看起来更”具体可信”。
② 忠实性幻觉(Faithfulness Hallucination)——译文很美,但意思不对
这是最危险的一种。文章开头那个医疗案例就是典型:原文说“父亲再婚不久后去世“,AI 译成”她确实在 65 岁时去世了“——主语换了、时间编了、关键信息全丢了,但读起来依然像一句”看似合理”的话。
忠实性幻觉的可怕之处在于:你光看译文是看不出问题的,必须对照原文逐字核查。
③ 语境扰动幻觉(Perturbation Hallucination)——一颗芝麻引发的雪崩
这是 Google 研究者最早发现的现象。在德语原文前面加一个无关的小词,比如 “mit”(与)、”werden”(成为)、”dass”(that),整段译文就完全跑偏,输出与原文毫不相关的句子。
这反映出 NMT/LLM 模型对输入扰动的极度敏感和脆弱——它的”理解”,远比我们想象的要表面。
④ 引用幻觉(Citation Hallucination)——格式正确,内容虚构
这就是开篇那位美国律师踩的坑——AI 给你生成的判例引用、学术参考、研究数据,格式标准、出处明确、看起来无懈可击。但当你真的去 Westlaw、Google Scholar、JSTOR 上查证时,会发现:它们根本不存在。
这四种幻觉,就是悬在每一位译者头上的“四把达摩克利斯之剑”——尤其是当你接的活儿涉及法律、医疗、合同、学术等高风险领域时。
02
AI 为什么会”胡编”?理解了原理,你才能精准识别
在我们讲怎么对抗幻觉之前,必须先搞懂——AI 为什么会产生幻觉?这是阅读这两篇前沿论文最核心的钥匙。
原因一:大语言模型本质上是“概率猜词机”
LLM 工作的核心机制,是基于上文预测”下一个最可能出现的词”。它没有真正的“理解”,只有概率。
当原文中出现一个低频专有名词(比如某个地名、某个药品名),模型在训练数据中很少见过,它就会“猜”一个语料里更常见、更”合理”的词来代替——这就是为什么会出现”高活性抗生素”这种听起来正经、但实际不存在的术语。
原因二:训练目标和翻译目标不完全一致
主流 LLM 在训练阶段做的是“生成连贯文本”的任务,并不是专门为“忠实翻译”设计的。当我们用它来做翻译时,它的本能是——
|
“我要生成一段读起来通顺、自然、符合目标语言习惯的文字。” |
注意:在它的“目标函数”里,“忠实于原文”是排在”流畅自然”之后的。所以当二者冲突时,它常常会牺牲忠实,去成全流畅。
原因三:传统训练数据里“忠实信号”严重不足
苹果论文中给出了一个非常关键的洞察——传统机器翻译的训练数据中,几乎没有“反面教材”。
什么意思?训练数据告诉模型“什么是对的翻译”(Reference);但很少明确告诉它”什么是错得离谱的翻译(Hallucination)“。
这就好比训练一个新司机——你只给他看正确驾驶的视频,从不告诉他”这种动作千万不能做”。结果就是:他开起来很流畅,但一旦遇到边缘情况,就有可能酿成事故。
03
苹果论文的解法:让 AI 学会”自我纠错”——幻觉率降低 96%
苹果团队的核心思路非常巧妙——既然问题是”训练数据里没有反面教材”,那就主动给模型造一些反面教材让它学。
核心方法:构建“幻觉聚焦的偏好数据集”
整个方法分三步——
【第一步】让模型先生成多个候选译文,然后用质量评估工具自动识别出哪些是“准确翻译”,哪些是”含有幻觉”。
【第二步】把这些译文配对成“偏好数据集“——准确的标记为”偏好(preferred)“,含幻觉的标记为”不偏好(dispreferred)“。
【第三步】使用一种叫CPO(对比偏好优化,Contrastive Preference Optimization)的训练技术,让模型在每一次生成时,都主动避免那些“看起来合理但实际是幻觉”的输出。
实验数据:5 + 3 个语言对的全方位胜利
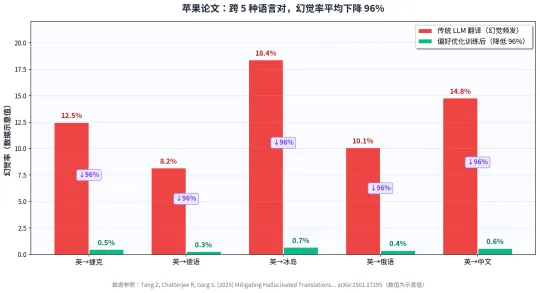
图 2:苹果论文实验数据示意(基于论文摘要中的 96% 整体降幅)
苹果的实验结果非常硬核——在 5 个语言对(英→捷克 / 德 / 冰岛 / 俄 / 中文)的标准测试集上,幻觉率平均降低了 96%;更重要的是,这些经过“反幻觉训练”的模型,没有牺牲整体翻译质量。
更厉害的是——在没有训练过的 3 个新目标语言上(零样本场景),幻觉率仍然降低了89%。这意味着:“反幻觉能力”是可以泛化的,并不局限于训练时见过的语言对。
阿里 M²PO:从”单视角”到”多视角”的进一步突破
紧跟苹果论文的脚步,2025 年 10 月,阿里巴巴国际数字商业集团在 arXiv 上发布的 M²PO 框架,把这种思路又推进了一步——
苹果的方法用的是“单一奖励信号“——只看译文是否含有幻觉。但阿里团队发现:这种单一信号会忽略一些关键的事实性错误。
于是 M²PO 引入了”多视角奖励引擎“——同时融合:
✓ 幻觉惩罚信号:识别那些事实性错误(比如生造的人名、错误的数字)
✓ 动态质量评分:结合外部评估和模型自身的进化判断
✓ 多对偏好构建:从所有候选译文中系统化地构造丰富的“对比对”,让模型学到更细腻的质量判断
阿里 M²PO 在 WMT21-22(机器翻译领域最权威的评测基准)上,性能已经接近顶尖闭源大模型——这意味着中国团队,正在和苹果同步,攻克这一前沿难题。
04
给译者的实战指南:四步“反幻觉”检验法
讲了这么多前沿研究,对我们一线译者最实用的问题是——
在论文成果还没完全落地到日常翻译工具之前,我们怎么用“人工守门”的方式,提前规避幻觉风险?
我们结合两篇论文的核心洞察 + 一线译者的实战经验,提炼出一套”译者反幻觉四步检验法”——
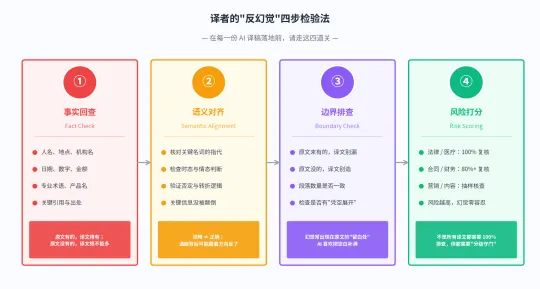
图 3:译者”反幻觉”四步检验工作流
第一步:事实回查(Fact Check)
把 AI 译文里所有的“硬事实”挑出来,逐一对照原文核查——人名、地点、机构名、日期、数字、金额、专业术语、产品型号、关键引用与出处。
黄金法则:原文有的,译文得有;原文没有的,译文一个字都不能多。
第二步:语义对齐(Semantic Alignment)
这一步专门对付“忠实性幻觉“——译文很流畅,但意思可能完全偏了。重点核查:
• 关键名词的指代(”他””她””它”指向了原文里正确的对象吗?)
• 时态与情态(过去发生的事别译成将来;可能性的事别译成确定)
• 否定与转折(”not””but””however”这些词是否被忽略或弄反)
黄金法则:流畅≠ 正确。通顺背后,可能藏着方向反了的陷阱。
第三步:边界排查(Boundary Check)
专门对付“事实幻觉“——重点检查 AI 是否在原文的”留白处”凭空展开。
• 对照原文段落数:原文 3 段,AI 不能给你译成 4 段
• 对照原文长度:原文 100 字,AI 译文不应该出现 200 字的”细节扩展”
• 重点警惕”修饰语爆炸”:原文一个简单的”会议”,AI 可能给你扩成”上周三下午在董事会议室举行的紧急战略会议”
黄金法则:幻觉常出现在原文的“留白处”——AI 喜欢把一切空白补满。
第四步:风险打分(Risk Scoring)
说实话——不是所有翻译任务都需要前面三步全跑一遍。但所有任务都应该按“风险分级”管理:
• 法律 / 医疗 / 合同 / 财报:100% 字字复核,幻觉零容忍
• 商务通信 / 技术文档:80%+ 关键信息核查
• 营销内容 / 网站文案:抽样核查 + 整体语义复盘
• 内部参考 / 邮件草稿:可以更宽容,但仍需快速浏览
黄金法则:风险越高的内容,越不能依赖 AI 的”自信”。给你的工作流装上”分级守门”,是 AI 时代每位专业译者的基本修养。
05
写在最后:当工具懂得“自我审视”,译者才能真正放心
回到文章开头那三个真实故事——医疗会议的”被改写的死亡时间”、跨国谈判的”被颠倒的拒绝”、法庭文书的”被编造的判例”。
这些幻觉,本来都是可以被识别和拦截的。
苹果和阿里的两篇前沿论文给我们的最大启示是——
|
AI 翻译质量的下一个突破点,不在”译得更快”,而在”懂得自我审视”。 |
一个真正成熟的翻译工具,应该具备这样的能力——
• 多智能体协同:让一个智能体生成译文,另一个智能体扮演“审校官”专门检测幻觉
• 过程可见可干预:把幻觉风险点高亮提示给译者,而不是把“看起来完美”的译文一股脑交给你
• 术语库与上下文对齐:用专业术语库锁定 AI 的”自由发挥”边界,让幻觉无处可生
这正是我们做 Lingualite 的初心——
|
Lingualite 绝非简单的”一键出译文”工具,而是一套全过程可控的多智能体翻译系统。它复刻了专业翻译组织的标准化工作流,让多个智能体在术语识别、初译生成、风格对齐、幻觉排查、一致性校验、人工裁决等环节”互相审视、互相把关”——把术语识别、译前分析、初译生成、风格对齐、一致性校验、人工裁决等环节全部”可视化、可干预、可回溯”。让人的专业判断、AI 的高效算力与翻译行业的宝贵经验深度融合,从根本上让”翻译幻觉”无处藏身。 |
AI 翻译的未来,不是更快地”胡编“出更多幻觉,而是更聪明地——
让每一个字,都站得住脚。

Lingualite·灵光链 —— 面向专业译者的多智能体笔译协作平台
如需体验 Lingualite,可通过以下方式注册使用平台:
访问官网:https://www.lingualite.cn
注册时请务必填写邀请码!完成验证后即可正常使用。
邀请码:v6q9oack19(200 字)
福利激活后即可提交翻译任务,限时体验多智能体协同翻译流程。如已注册但需要更多翻译字数,可自行购买套餐或者字数包来获取字数。
互动话题:
你在工作中遇到过最离谱的“AI 翻译幻觉”是什么?欢迎在评论区分享你被坑过的真实案例~
|
论文来源:1. Tang Z, Chatterjee R, Garg S. (2025). Mitigating Hallucinated Translations in Large Language Models with Hallucination-focused Preference Optimization. arXiv:2501.17295 (Boston University × Apple). 2. Wang H, Xu L, Liu H, et al. (2025). Beyond Single-Reward: Multi-Pair, Multi-Perspective Preference Optimization for Machine Translation. arXiv:2510.13434 (Alibaba International Digital Commerce). 相关参考:Ji et al. (2023) Survey of Hallucination in Natural Language Generation; Guerreiro et al. (2023) Hallucinations in Large Multilingual Translation Models, arXiv:2303.16104. 版权声明:本文对上述论文与行业信息的解读仅供学习交流。论文原文版权归原作者及发表机构所有。如涉及侵权,请联系删除。 |
往期内容推荐:
译者每天都在「修机器的错」,却修不出未来。一篇新论文给出了一个新答案:HACT
d-BLEU 输了一倍,人却更喜欢——这家”虚拟翻译公司”,让翻译界开始重新思考”什么是好译文”
点个♥ 在看,让 AI 翻译不再”胡编”