 夜雨聆风
夜雨聆风





你的Agent会做梦了,OpenClaw和Anthropic给出的两种解法
你跟AI Agent聊了两个月,每天都在用,它记住了你喜欢什么风格、哪些项目在跑、踩过什么坑。然后有一天你突然发现,它说的有些东西好像是错的。或者更准确地说,有些东西曾经是对的,但现在不是了。
你去找它对质,它一脸无辜:是你让我记住的啊?
这种「记了,但记乱了」的感觉,我相信用过长期Agent的人都有体会。
2026年的春天,两个团队都发现了这个问题。他们都决定让Agent学会「睡觉」,在不使用的时候整理自己的记忆。
一个团队4月5日发布了方案,叫OpenClaw Dream。
另一个团队5月6日发布了方案,叫Anthropic Dreaming。
名字都带「Dream」,发布日期差了整整一个月。
但做出来的东西,完全不一样。
下面来分别说道说道这两个方案。
你可能会想,上下文窗口不是越来越大了嘛,128K、1M都有了,记不住就塞更多进去不就完了?
没那么简单。
第一,成本扛不住。 每次对话都加载全部历史,token消耗是选择性记忆的十几倍。你用得起,但你的钱包不一定同意。
第二,信息多了反而找不到重点。 128K窗口里可能只有3条有用信息,模型要在海量噪音里捞针。越大的窗口,「中间遗忘」效应越严重,真正重要的内容反而被淹没了。
第三,检索也会退化。 信息越多,向量检索越不准。语义相似但内容无关的噪音增多,你搜「项目架构」,它给你返回三条过时的技术方案。
所以问题从来不是「能存多少」,而是「该存什么」。
但问题不只是存什么。就算你知道该存什么,Agent用久了,记忆还是会腐败。
我的60天真实体验
我同时部署了5个Agent,每个有独立的workspace。
用OpenClaw的Memory系统跑了大概60天。一开始感觉挺好。Agent记住了我喜欢什么风格、哪些项目在跑、踩过什么坑。跨会话的时候不用每次都重新解释背景信息,省了很多力气。
但用着用着,问题就来了。
MEMORY文件越来越大。有些信息明明已经过时了还占着位置,有些重复的偏好被写了好几遍,而真正重要的新知识反而被噪音淹没。
personal agent帮我记录作息习惯时,第一周写的是「Boss习惯晚睡晚起」,但我已经改了作息,这一条还挂着没更新。content agent帮我记录写作风格偏好,今天写的是「段落要短、开头用『其实』」,明天再补充又写了「文章控制在800字以内、不要太长」,几次下来描述不统一,agent自己也搞不清我到底想要什么。
就像你有个特别能干的助理,但他的办公桌越来越乱。文件堆成山,找个东西要翻半天,好不容易找到一个,上面标注的信息还是三个月前的。
Agent不是记不住,是记住了太多、记住了太乱、记住了太多过时的东西。
这就是记忆腐败。

我的应对策略:每周定时任务
说了这么多问题,该说说我现在的应对策略了。
我在Dreaming出来之前就发现了记忆腐败,所以一个月前启动了每周定时任务来解决这个问题。
这个任务干三件事:
第一,从每日笔记里提取最重要的部分到MEMORY。 有些重要信息可能只是我没来得及检索,需要手动补位。
第二,自动合并MEMORY里相同的内容。 比如我的写作风格偏好可能分好几次写进去,定时任务会把它们合并成一条。
第三,删除它认为不重要的信息,但删除前会先备份。 这是最关键的一步。系统化的「记忆体检」,定期清理明显过时或从未被使用的条目。
目前跑得还行,没有遇到太多问题。
踩过的坑告诉我:虽然理论上有各种自动化方案能控制膨胀,但如果你真的把记忆系统用起来,用得杂、用得深,单纯的自动整合是不够的,还是需要一些人工介入来弥补。
OpenClaw在4月5日发布了Dream功能。它解决的是「信息太多、需要筛选」这个问题。
怎么理解它的方案呢?
你可以把Agent的大脑想象成人脑。白天你接收了大量信息,但不是所有信息都会变成长期记忆。很多信息在睡眠时被大脑整理、筛选、归档,只有一小部分真正重要的会被强化进入长期记忆。
OpenClaw Dream就是在模拟这个过程。
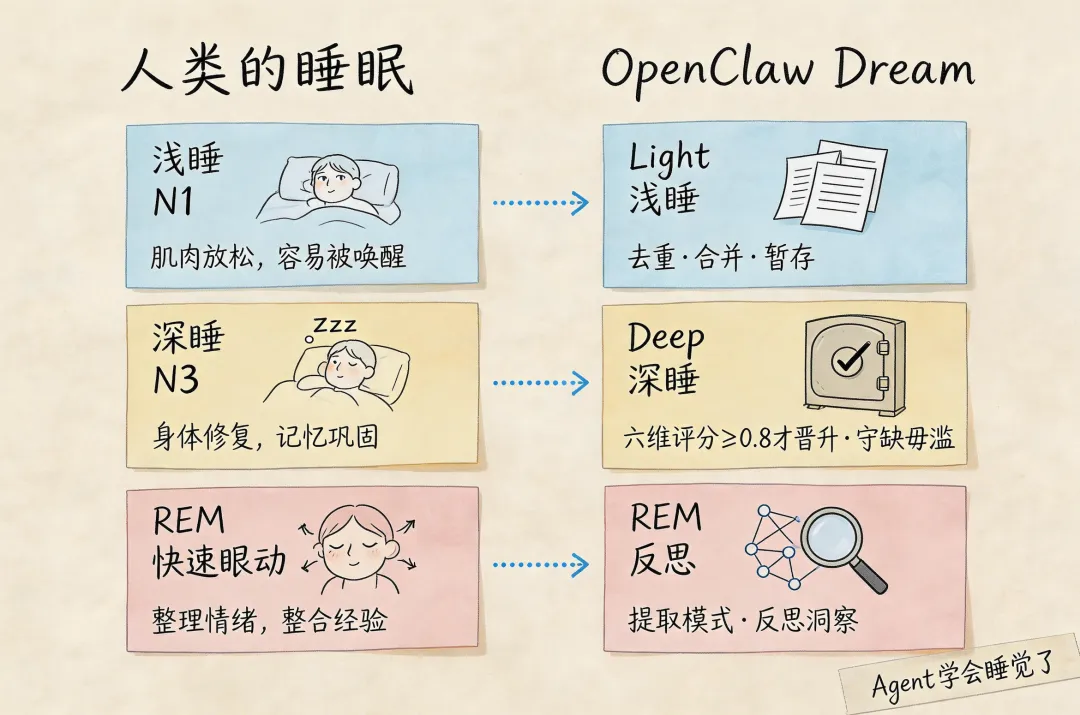
它把记忆整合分成三个阶段:
Light阶段(浅睡):处理最近一天或几天的短期记忆。干的事情比较简单,去重,把明显重复的内容合并一下,输出到临时区域,不直接写入长期记忆。就像你睡前把桌上的文件随便归归类,重要的放一边,不重要的先堆着。
REM阶段(快速眼动):开始做反思。看看最近哪些主题反复出现,哪些坑踩了两次以上。输出是主题摘要和反思记录。这个阶段是大脑开始真正「整理」的阶段,不只是分类,还要理解这些信息之间的关系。
Deep阶段(深度睡眠):这是关键。需要六维评分达到门槛,才会真正把内容提升到MEMORY.md。评不出来的不提升,宁缺毋滥。就像大脑在决定「这些信息真的值得进入长期记忆吗」?
三阶段的逻辑是:信息不是直接写入长期记忆的,需要经过层层筛选。
OpenClaw三阶段流程图
六维评分系统
OpenClaw的评分系统是它的核心技术亮点。
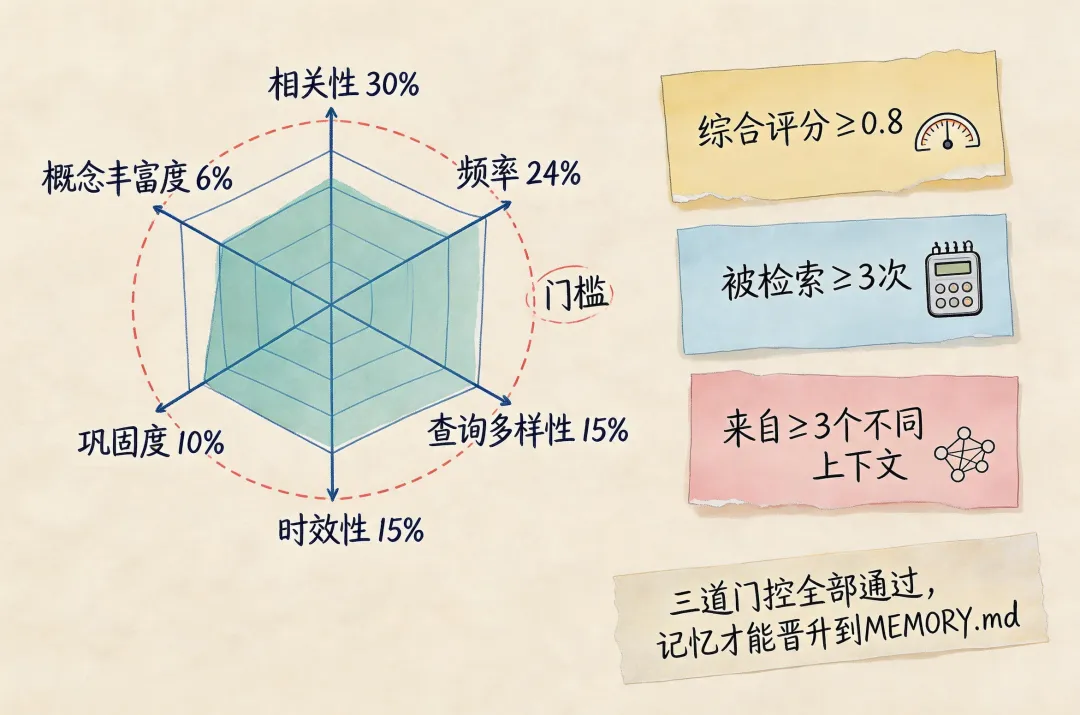
六个维度的权重是公开的:
-
相关性(0.30):被检索的次数越多越重要。你用得越多,系统认为它越重要。
-
频率(0.24):出现频率越高越重要。反复出现的信息通常更有价值。
-
查询多样性(0.15):被不同场景引用越多越重要。如果你从多个角度都用到了这条信息,那它很可能是核心知识。
-
时效性(0.15):越新鲜的内容权重越高。旧信息可能已经过时了。
-
巩固度(0.10):跨天重复出现的强度。今天用了明天还用,说明这条信息是持续有效的。
-
概念丰富度(0.06):信息密度高不高。信息量大但简洁的内容更有价值。
三道门控是:综合评分≥0.8、被检索≥3次、来自≥3个不同上下文。
这意味着一个条目即使出现频率很高,如果只出现在一个上下文中,也不会被提升。这防止了「局部噪音」被误判为「全局知识」。
六维评分雷达图+门控
Recall Signal陷阱
这是OpenClaw Dream方案使用中一个非常需要注意的部分,必须单独拿出来说。
OpenClaw的评分系统依赖一个叫recallCount的指标,字面意思是「被回忆的次数」。它的逻辑是:一条记忆如果被反复检索,说明它重要,应该提升到长期记忆。
问题在于:只有调用memory_search才会增加recallCount。
如果你让Agent读一个文件发现了重要事实,或者执行命令得到了关键信息,这些都不会增加recallCount。结果就是:Agent可能通过各种方式获取了重要知识,但因为没有显式检索记忆,这些知识永远不会被Dreaming提升。
今年5月11日,我跟踪了4天我的Dream使用数据:
Light Phase候选数:1,763行
Deep Phase每天评估:6个
晋升到MEMORY.md:0条
4天下来,1763条候选等着被评估,Deep Phase每天只评估6条,然后0条晋升。一条都没有。
我当时也愣了。但冷静下来一看,问题出在哪?
所有候选的recallCount都是0,从未被后续对话召回。
confidence只有0.58,离0.8的门槛还远。
这两点叠加在一起,结果就是:候选积累了一大堆,但因为recallCount不够,评分永远达不到门槛。因为评分不够,Deep Phase永远不提升。
这是使用门槛的问题,不是系统缺陷的证据。 Dreaming不是装上就自动生效的,你需要理解它的机制然后配合使用。

Recall Signal数据图
Anthropic在5月6日发布了Dreaming。它解决的是「Agent每次新会话都像失忆」这个问题。
官方的描述很简洁。「定时调度的后台进程」,它的工作流程很清晰:会话结束后自动触发,回顾过去一段时间的会话历史和记忆存储,干三件事,合并重复的事实、替换过时的信息、挖掘反复出现的模式,然后更新记忆库。
最大的特点是不需要人工干预,Agent自己学会记住该记住的东西。
Harvey(法律AI公司)是Anthropic的官方客户案例。通过Dreaming,他们的Agent记住了在会话之间学到的内容,包括文件类型变通方法和工具特定模式。完成率提升了约6倍。
从官方数据看,8分钟的Agent任务能处理530万tokens的会话历史,生成98行自动化脚本。这种长周期任务整合能力,是它最核心的价值。
从Claude Code本地版看Anthropic的思路
虽然Anthropic没有公开详细机制,但技术社区对Claude Code本地版的Auto Dream做了逆向工程分析,对我们理解Anthropic的思路很有帮助。
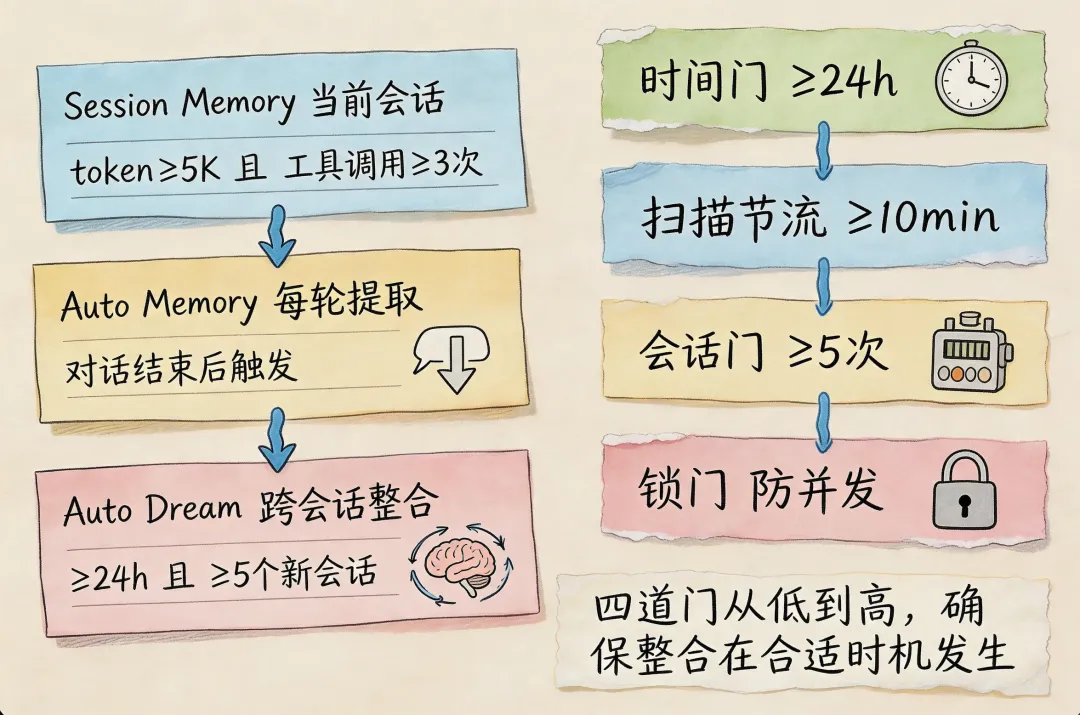
Claude Code本地版用的是三层记忆架构:
第一层:Session Memory(当前会话)。当token增长≥5K且工具调用≥3次时触发,后台forked agent维护结构化笔记。
第二层:Auto Memory Extraction(每轮对话结束)。当最终回答后触发,提取持久记忆到磁盘。
第三层:Auto Dream(跨会话整合)。当≥24h且≥5个新会话时触发,作用是合并重复、修正过时、修剪冗余。
三层架构的逻辑很清晰:当前会话的笔记 → 每轮结束提取到磁盘 → 跨会话整合归档。
更精妙的是它的四步门控机制:
① 时间门:距上次整合≥24小时。这是第一道关卡,先看时间够不够。
② 扫描节流:距上次扫描≥10分钟。这是性能优化,防止频繁扫描。
③ 会话门:≥5个新会话。这确保有足够的会话样本才做整合。
④ 锁门:防止多个进程同时consolidation。这是并发控制,避免重复处理。
四道门从低到高,层层把关,确保整合动作在合适的时机发生。
注意:这是Claude Code本地版的逆向分析,不是Managed Agents Dreaming的官方机制。 Managed Agents版本可能更复杂,也可能有不同的设计选择。但从中我们可以看出Anthropic在记忆系统上的设计思路,时间+会话数的双重门控,确保整合是有意义的。
Anthropic三层架构+四步门控图
同样的Dream,不同的场景
写到这里,你会发现两家的差异不是「理解不同」,而是面对的问题本来就不一样。
OpenClaw面对的场景是:Agent已经记住了很多东西,但记忆质量在下降,需要做减法提升质量。 六维评分、三道门控,都是为了筛选出真正重要的信息,宁缺毋滥。
Anthropic面对的场景是:Agent每次新会话都像失忆,跨会话的经验完全留不住,需要做加法把经验沉淀下来。 定时调度、三层架构,都是为了把丢失的东西捡回来,宁多勿漏。
都叫Dream,但解决的是两个完全不同的记忆问题。
OpenClaw适合:你已经用Agent很久了,它记住了一大堆东西,但越来越乱,越来越不准确。需要有人来「整理书架」。
Anthropic适合:你每次新建会话都要从头解释背景,Agent之间无法共享经验。需要有人来「记住你说过的」。
搞清楚自己面对的是哪个问题,才能选对方案。
说了这么多技术细节,最后聊点实在的,对我来说有哪些启示。
1. 记忆系统的价值不在于存了多少,而在于用了多少。OpenClaw的评分系统看recallCount,只有被显式检索的记忆才算「真正重要」。Anthropic的Dreaming挖掘跨会话的模式,只有反复出现的经验才值得沉淀。这两家不约而同地在说:记忆不是越多越好,被用到的记忆才是有价值的记忆。所以与其想着「怎么让Agent记住更多」,不如想着「怎么让Agent真正使用记忆」。一个被反复检索的记忆,比一百条写入后从未被调用过的记忆有价值得多。
2. 「被使用」比「被写入」更重要。我在第一条里已经说了核心观点,这里补充一个实操建议:定期审计你的MEMORY.md,看看哪些条目已经过时,从未被用过。这些条目要么删掉,要么想想为什么Agent从来没检索过它。OpenClaw的文档甚至建议每周问自己三个问题:这条规则上周用过吗?用了有效吗?环境变了它还成立吗?
3. 记忆系统不是装上就完事。很多人以为给Agent加个Memory系统就解决了记忆问题,实际上记忆系统需要配合使用。OpenClaw需要你理解Recall Signal的逻辑、知道什么时候该手动触发检索。Anthropic需要你设计好评估标准。完全放手的结果通常是:记忆膨胀但质量下降,或者记忆根本没被整合。建议:使用任何记忆系统之前,先读一遍它的核心文档,搞清楚「什么情况下记忆会被写入/更新/删除」。
4. 接受遗忘是必要的。两个方案都在强调「遗忘」的重要性。Anthropic会替换过时信息,OpenClaw会淘汰评分不足的内容。不要追求「记住一切」。 记忆系统的目标不是最大化存储,而是最大化有价值的检索命中率。每月定期清理一次MEMORY.md,删掉明显过时或从未被使用的条目。
5. 定期整理比完美系统更实际。我自己的每周定时任务就是证明,不完美的定期整理胜过完美的零干预。有时候一个看起来很土的办法,反而是最管用的。
6. 先把正在用的理解透,比追新更值。OpenClaw比Anthropic早了整整一个月发布,说明开源社区对需求的敏感度确实领先。但对我们这些实际用Agent的人来说,「记忆需要主动管理」这个理念是共通的,不管你用哪家的方案。与其追求最先进的记忆系统,不如先把正在用的这套理解透。
下篇见!避免错过更多干货,点击下方卡片关注
希望本文能对你有所启发,欢迎关注~
也感谢你的点赞与分享:)
📌 关于我
专注于 AI 产品落地的实践者,操盘过多个企业级 AI 应用从 0 到 1 的架构设计与迭代。擅长在模型能力不确定的前提下,通过系统组件的合理编排,构建稳定、可维护、可解释的 AI 系统。
目前主要提供:轻量级企业 AI 落地策略咨询、AI 架构与方向评审、企业 AI 应用培训与支持。
如果你正在思考 AI 如何真正为业务创造长期价值,欢迎交流。
👉 合作相关,请添加工作室微信:YHan_Studio