 夜雨聆风
夜雨聆风





汽车软件生成代码(MBD)硬核实战——值得收藏
引言| 各位汽车电子、域控、底层软件工程师,你是否还在为“只会拖模型不懂代码生成原理”而焦虑?量产项目中,AUTOSAR与非标底层集成、数据字典混乱、代码配置玄学——任何一个卡点都足以让你连续加班。

第一章|筑基 · 代码生成地基与数据对象圣经
很多工程师误以为生成嵌入式代码只是点一下“Generate”,但在量产级别的汽车软件中(VCU、BMS、ADAS),代码的可读性、内存布局、标定/观测量接口直接决定项目成败。本章我们从最基础但最关键的“数据对象”和基础配置讲起,没有这些根基,后期集成必出大问题。
1.1 绝不能绕过的配置三板斧:求解器/TLC/硬件实现
在Simulink中生成可落地的C代码,第一步是设置求解器为固定步长(Fixed-Step),通常用于实时嵌入式系统;第二步必须明确系统目标文件(System Target File),如ert.tlc(Embedded Coder),它决定了代码风格、效率以及与硬件的适配程度。第三步是硬件实现(Hardware Implementation):根据你的量产芯片(Infineon Tricore、NXP S32K、STM32等)配置字长、字节对齐等参数,这会直接影响编译器行为。
✅ 必须背诵掌握:
• 固定步长求解器 + ert.tlc 是量产代码的黄金起点。
• 硬件实现中的“设备供应商”与“芯片型号”必须与实际硬件匹配,否则会出现对齐异常或性能下降。
• “代码生成”标签页中,“Generate code only”仅用于测试,量产建议打包“Create code generation report”便于审查。
不要小看这些配置,很多初级工程师不懂TLC的作用,随便用一个grt.tlc,生成一大堆冗余代码,最终导致RAM/ROM溢出。高级工程师则会根据目标编译器手动优化代码生成选项(如开启“优先执行速度”或“优先代码紧凑”)。
1.2 数据对象——连接模型与底层接口的灵魂
实际控制器开发中,标定量(Calibration Parameter)、观测量(Measurement Signal)需要在底层和标定工具(CANape/INCA)中交互。如果你直接在模型中写死常数或用普通的Simulink信号线,生成代码后无法映射到A2L文件,也无法在线标定。Simulink数据对象就是解决这个痛点的标准方案。
Simulink.Parameter
—— 定义标定量(可被校准)。在代码中通常表现为 const或放置在特定段中。Simulink.Signal
—— 定义观测量/中间信号,可映射为全局变量或带读写保护。 Simulink.Bus
—— 复杂信号结构体,用于CAN报文或复杂接口。
🔥 核心工程原则:无论是初级还是高级工程师,都必须掌握数据对象的创建、属性配置(StorageClass、MemorySection)以及在模型中的绑定。千万不要为了省事而使用“Data Store Memory”(不规范的全局存储),它会导致仿真数据竞态和代码可读性灾难,量产流程中强烈不推荐。
举个实际例子:一个整车控制器中的最大扭矩限制,你需要在后台标定工具里动态修改。做法是在工作空间创建Para_MaxTrq = Simulink.Parameter(300),并设置StorageClass为ExportedGlobal 或 Calibration,然后在模型Gain模块参数框里直接输入Para_MaxTrq。生成代码后,这个参数就是一个全局常量,地址可被标定工具识别。重点:对象名、存储类、数据字典一致性是三个命门。
1.3 信号与参数绑定——代码接口的视觉契约
许多汽车软件团队采用“端口+信号对象绑定”来固化接口。例如在模型根级别的Inport/Outport模块上,右键选择“Signal Properties”,然后将信号名绑定到工作区的Simulink.Signal对象。这样生成的代码中,函数原型就会自动产生符合AUTOSAR规范的名词。对于PID控制器、滤波器等核心算法模块,必须做好每路信号的绑定,否则后续集成时找不到接口变量。
📖 记忆重点:信号对象存储类常用ExportedGlobal(全局可读)或ImportedExtern(外部定义);参数对象存储类常用Calibration(标定量)或Const(只读常量)。在代码生成报告中验证映射结果。

第二章|进阶 · 模型架构 + 数据管理工厂化
当你掌握数据对象基础后,下一个核心痛点在于:模型规模膨胀、数据成百上千个,如何高效管理?如何让模型结构生成可读性高的模块化代码?本章讲解从模型分层、原子子系统,到M脚本/Excel/数据字典三种数据管理实战,助你脱离“手搓对象”的低效状态。
2.1 模型结构与代码定制:原子子系统与函数边界
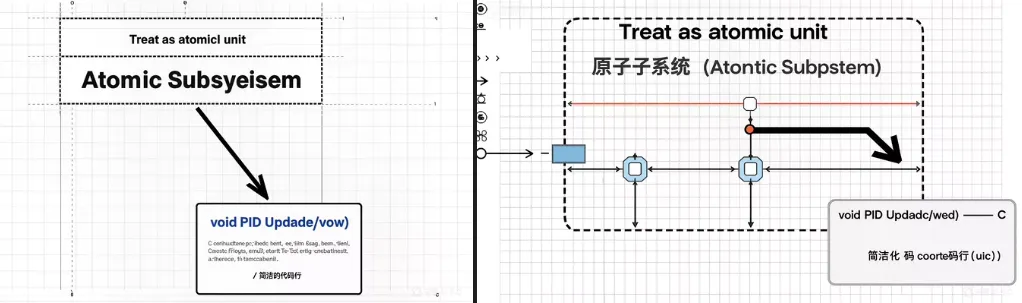
默认情况下,Simulink会为每个子系统生成独立函数,但需要主动配置。为了生成可调试、可复用的函数接口,必须掌握原子子系统(Atomic Subsystem)与函数原型定制。右键子系统选择“Treat as atomic unit”,并在Code Generation标签页中设置函数名(如void PID_Update(void))和文件划分。这样一来,生成的C代码将是你预期的模块化API,而不是一个大的杂烩函数。
针对变步长或条件执行场景,可以借助可变子系统(Variant Subsystem)或Exported Function Model(导出函数模型),这类方法在AUTOSAR架构中尤其常见。例如一个BMS模型中有多个电池算法变体,通过导出函数模型生成独立的周期函数,底层任务即可灵活调度。高级工程师需重点掌握 可变子系统和code mapping,但初阶工程师至少能读懂和修改。
⚡ 实践建议:团队协同开发时,用原子子系统 + 显式函数名生成代码,然后手写RTE调用这些函数。避免使用Code Mappings编辑器(晦涩且不易追溯),优先采用数据对象直接绑定方式,更直观且利于模型审查。
2.2 数据管理的三重境界:M脚本、Excel驱动、SLDD字典
在任何量产公司,数据管理决定项目能否规模化。第一阶段:手工在工作空间一个个创建参数/信号对象——仅适合原型。第二阶段:M脚本批量管理,通过.m文件用命令定义数百个数据对象,例如:Param_BattCurr = Simulink.Parameter(0); Param_BattCurr.CoderInfo.StorageClass = 'Calibration';。这属于最基本但最透明的数据管理方式,建议每个工程师必须掌握其原理,因为Excel工具最终也是调用这些底层命令。
🧠 背诵重点:M脚本管理数据的核心API —— Simulink.Parameter、Simulink.Signal创建对象;set_param关联模型工作空间;save保存为mat文件。理解了这个,再复杂的Excel框架都能拆解。
第三阶段:基于Excel的数据管理。很多成熟供应链开发了“Excel->生成数据对象脚本”的工具链。本文原作者从零实现了导入脚本,涉及xlsread、遍历结构体、动态设置对象属性等。这种方法的好处是非开发人员也能维护标定列表,但缺点是一旦工具链出bug,不懂底层M脚本原理的工程师会束手无策。所以建议:先掌握M脚本,再使用Excel封装工具,做到知其所以然。
最后,MathWorks官方推荐的数据字典(SLDD,Simulink Data Dictionary)用于大型团队协同。它相当于数据库式的数据管理,支持版本控制和变更追踪。SLDD使用Simulink.data.dictionary创建,将数据对象和模型分离。但国内多数公司由于历史原因尚未普及,因此高级工程师酌情掌握,初级了解即可,如果公司要求使用则需快速入手。
2.3 实战演练:PID算法从公式到生成代码的全过程
理论结合实战才深刻。书中以PID控制器为例,先写出离散PID公式,然后搭建误差、比例、积分、微分路径,定义PID_Kp、PID_Ki、PID_Kd三个参数对象(存储类Calibration),定义PID_Out信号对象(ExportedGlobal)。通过M脚本批量创建并加载到工作区,模型直接引用。最后生成代码,观察C文件中的PID计算函数和全局变量结构。这个流程你走一遍后,就能打通“需求->数据定义->建模->代码生成”完整链路。所有汽车电子工程师都应至少独立完成一次这个闭环。
第三章|高手 · 量产集成、优化定制与内存布局
前面的内容让你能高效生成模块化代码,但距离真正的量产还差最后几步:与底层MCAL集成、代码替换库优化数学运算、自定义存储段(Memory Section)以及公司级Package定制。这是资深专家与普通工程师的分水岭。

3.1 与底层集成:SWC与BSW的联姻
应用层模型生成的C代码(例如step()函数)需要被底层任务(如1ms、10ms周期)调用,并且需要访问底层驱动(ADC、PWM、CAN)。推荐的量产模式:应用层代码只负责算法和逻辑,通过RTE或手工编写的调度接口读写底层变量。底层包含main.c、中断、定时器回调,在回调中调用模型生成的void Model_step(void),并将底层AD值赋给模型的输入端口结构体。关键点:不要依赖特定硬件支持包生成MCAL代码(大多成熟公司不用),而是手动集成,这样芯片移植性最强。
🚀 记忆重点:集成三步法——① 生成代码后提取.h/.c文件加入工程;② 在主循环或RTOS任务中周期性调用step函数;③ 实现应用层接口变量与硬件寄存器/驱动变量的映射。不要使用一键生成整个工程,量产必须控制底层细节。
并且集成工程师必须理解生成代码的初始化函数Model_initialize需要先于step调用,某些编译器还需调整堆栈大小。若出现“未定义引用”,排查数据对象的存储类是否与底层链接脚本匹配。
3.2 代码替换库(CRL)与极致性能优化
电机控制、三角运算、查表等数学函数,如果用标准sin()、cos()会调用通用库效率低。而大部分芯片厂商提供优化的数学库(如ARM CMSIS-DSP、Infineon的专用数学函数)。通过代码替换库(Code Replacement Library),可以自动将模型生成的sin替换为arm_sin_f32,不需要手工改代码。这种做法在使用Embedded Coder时非常强大,但需要预先配置CRL表格。初级工程师只要知道这种机制,高级工程师应该能创建或修改CRL,在性能瓶颈时快速解决。
💡 行业现状:大众、博世等Tier1内部会维护自定义的CRL,将sin/cos/矩阵运算映射到硬件加速函数。学会配置CRL,你的代码性能直接上一个台阶。
3.3 Memory Section与自定义Package:终极掌控力
在AUTOSAR中,每个变量都会被分配到特定内存段(如 .calib_ram, .code_flash)。Simulink通过存储器段(Memory Section)和存储类(Storage Class)配合实现。你可以创建自己的package(派生自Simulink.Data),定义公司专属的存储类,例如MyCompany_Calibration_Flash,设定段名映射到链接脚本。这种自定义能力是架构师层面的必备技能。
🧩 重点归纳:记忆Memory Section三段式——① 在模型配置中定义内存段名称和属性(如volatile、对齐);② 为数据对象选择对应的存储器段;③ 在链接脚本中声明相同段名。只有三者匹配,代码才能正确放置变量位置,避免RAM溢出或Flash访问错误。
对于大多数初级和中级工程师,直接使用公司已经打包好的Package即可;但如果你的公司正在从零搭建MBD流程,本文的内容会帮你从原生Simulink.Parameter过渡到自主可控的存储体系,对标定量的memory位置、初始值进行精细控制。
3.4 非量产利器与避坑指南
有时我们需要快速集成遗留C代码,可以使用Simulink S-Function或者Simulation Target,但这通常不适合量产。对于Legacy Code Tool,非常不建议用在安全关键系统中,因为代码可追溯性差。另外CPU link code更是一种过时且不推荐的方式,直接忽略。量产项目要坚持“模型本身可读、代码生成规则清晰、数据字典一致”的三条铁律。
学习后指南 & 高频避坑
即便是完整学完上述模块,实际工作中仍会出现各种奇怪问题:模型复用数据对象冲突、代码生成报告找不到变量定义、标定工具无法识别Memory Section等。
📌 最终箴言:从“能生成代码”到“量产级代码生成”之间,差的不仅仅是工具操作,更是对数据生命周期、编译链接过程、底层硬件特性的深度理解。掌握本文90%的知识点,你已经超越80%的MBD工程师。

面试
资料
学习
路线
学习
指导
多名10年+大厂经验
工程师在线指导
学习
交流
众多开发者一起交流
助力你提升技能