 夜雨聆风
夜雨聆风





AIOps落地:基于OpenClaw打造企业级智能巡检系统
在企业运维体系里,“巡检”一直是一个绕不开的话题。
它看起来不新鲜:看 CPU、看内存、看磁盘、看日志、看 Pod、看数据库、看业务指标。但真正落到生产环境里,巡检从来不是简单地“查一遍指标”。
企业真正需要的是:
异常能不能提前发现?多源数据能不能关联起来?历史故障经验能不能复用?巡检动作能不能自动执行?最终结论能不能直接指导处理?
过去,我们常见的链路大概是:
监控系统发现异常↓告警平台推送消息↓运维人员打开 Grafana / 日志 / K8S 控制台↓人工判断问题原因↓手动执行处理动作↓事后补充文档或复盘
这套模式能用,但问题也很明显:
告警多,真正有价值的信息少;指标散,日志、事件、业务数据之间缺少关联;规则死,巡检逻辑长期依赖阈值;经验碎,处理方法往往存在个人脑子里;响应慢,越复杂的问题越依赖资深工程师。
进入 AI Agent 时代后,巡检系统的设计思路可以换一换了。
本文尝试聊聊:如何基于 OpenClaw 构建一套企业级智能巡检系统,让巡检从“定时检查”升级为“智能分析 + 自动沉淀 + 协同处置”。
01|为什么选择 OpenClaw 做智能巡检入口?
传统巡检系统更像一个“报表生成器”。
它能告诉你:
CPU 超过 90%磁盘快满了Pod 重启了接口错误率升高了
但它很难进一步回答:
这些异常是不是同一个问题导致的?是否和历史某次故障相似?应该先看哪个系统?是否需要升级为故障事件?有没有可以直接执行的处理预案?
OpenClaw 的价值,不在于替代 Prometheus、Grafana、Loki、Elasticsearch 或 Kubernetes,而在于把这些工具连接起来,成为一个统一的智能运维入口。
可以把它理解成一个“会调工具、会读上下文、会复用经验、会按计划执行任务”的运维 Agent。
1)用多工具调用打通巡检数据源
企业巡检不是单点数据分析,而是多系统协同判断。
一次业务接口超时,背后可能同时涉及:
应用日志异常;K8S Pod 频繁重启;数据库慢 SQL 增多;Redis 连接数打满;某台宿主机 CPU 被打高;上游服务接口响应变慢。
如果每次都靠人手动打开不同平台排查,效率一定很低。
基于 OpenClaw,可以将 Prometheus、Kubernetes、Loki、Elasticsearch、MySQL、Redis、Kafka、CMDB、工单系统等通过 MCP 或自定义工具接入进来,让 Agent 具备跨系统读取和分析能力。
这样,巡检不再是“单工具查询”,而是“多源信息编排”。
2)用 Skills 固化企业运维经验
企业巡检最难的不是第一次写出检查逻辑,而是让它持续复用。
比如某次 Kafka 消费延迟问题,资深工程师可能会这样排查:
先看 consumer lag;再看 broker 状态;再看 ISR 是否异常;再看最近是否有扩容、发布或网络抖动;最后结合日志判断是消费端变慢还是消息堆积。
这类经验如果只停留在人身上,就很难规模化。
OpenClaw 的 Skills 机制可以把这些成熟排查步骤沉淀为可复用能力,例如:
kafka_lag_diagnosismysql_slow_sql_reviewk8s_crashloop_analysisredis_memory_risk_checkbusiness_health_review
之后只要触发巡检,Agent 就可以按照既定 Skill 依次执行,而不是每次从零开始写提示词。
这对企业来说非常关键:巡检系统不只是自动化工具,更是运维知识库的执行载体。
3)用 Cron 实现周期性巡检
巡检必须是持续发生的。
每日早间巡检、每小时业务健康检查、每 10 分钟核心链路巡检、发布后的专项巡检,这些都是企业常见场景。
基于 OpenClaw 的定时任务能力,可以把巡检流程固定下来:
每 10 分钟检查核心业务链路;每 30 分钟检查中间件状态;每小时生成一次基础设施健康报告;每天早上汇总过去 24 小时风险趋势;每次发布后自动执行变更后巡检。
这样,巡检就从“有人想起来才看”变成“系统自动完成”。
4)用多渠道入口融入团队协作
企业巡检的结果不能只停留在控制台里。
真正有效的巡检报告,应该能够进入运维团队日常协作场景,例如:
飞书群;企业微信群;Slack;邮件;工单系统;值班系统;故障管理平台。
OpenClaw 可以作为统一入口接收指令,也可以把巡检结论推送到团队常用渠道中。
例如:
“检查一下订单系统最近 30 分钟有没有异常。”“生成今天早上的生产环境巡检报告。”“分析 payment-service 过去 1 小时错误率升高的原因。”“把 P1 风险整理成故障升级建议。”
这类交互方式,会让巡检系统更接近一个“在线 SRE 助手”,而不是冷冰冰的监控后台。
02|总体架构设计
一套基于 OpenClaw 的企业级智能巡检系统,可以拆成五个核心层次:
数据采集层工具接入层Agent 编排层智能分析层结果闭环层
整体链路可以这样理解:
监控指标 / 日志 / K8S 事件 / 中间件状态 / 业务数据↓Prometheus MCP / K8S MCP / Loki MCP / ES MCP / DB MCP / API MCP↓OpenClaw Agent↓巡检 Skills 编排↓LLM 关联分析与风险判断↓结构化巡检报告↓飞书、企微、邮件、工单、故障平台
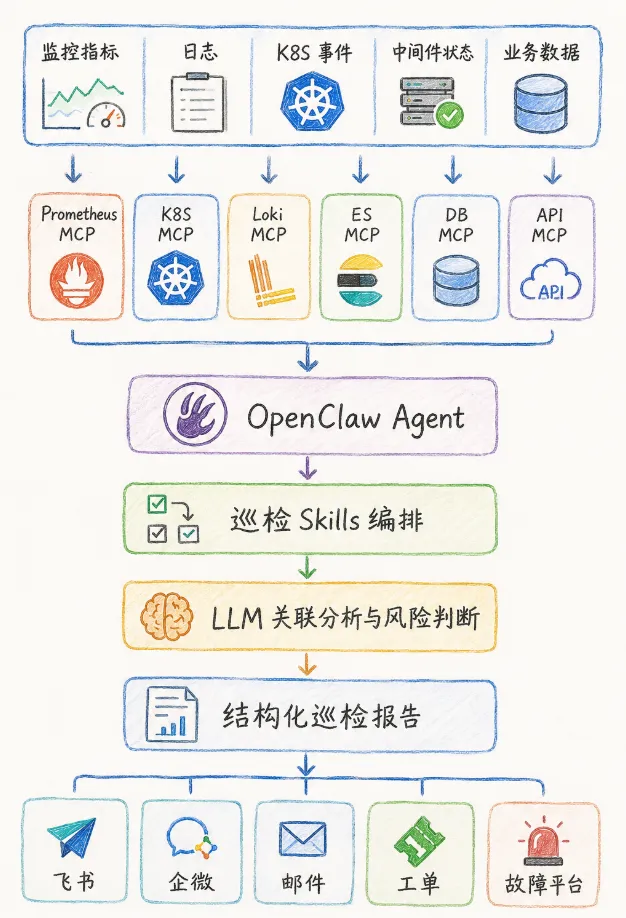
在这个架构里,OpenClaw 不直接替代已有监控平台,而是站在上层做三件事:
第一,调度工具。
它负责按照巡检任务调用不同数据源,比如 Prometheus 查指标、K8S 查 Pod 状态、Loki 查日志、数据库查业务数据。
第二,组织分析。
它不只是把数据贴出来,而是结合时间线、依赖关系、历史案例和异常模式进行综合判断。
第三,输出结论。
它需要生成运维能直接使用的结果,包括风险等级、影响范围、可能原因、建议动作、是否升级故障、是否需要人工介入。
一个成熟的巡检报告不应该只有:“CPU 使用率 92%。”
而应该是:“payment-service 所在节点 CPU 在 10:20 后持续升高,期间该服务 P99 响应时间从 800ms 升至 3.2s,同时日志中数据库连接超时增加,K8S Event 未发现重调度异常。初步判断瓶颈更可能位于数据库连接池或慢 SQL,建议优先检查最近发布 SQL 变更,并临时扩容连接池观察。”
这才是智能巡检的价值。
最后介绍下我的AIOps课:我的运维大模型课上线了,目前还在预售期,有很大优惠。AI越来越成熟了,大模型技术需求量也越来越多了,至少我觉得这个方向要比传统的后端开发、前端开发、测试、运维等方向的机会更大,而且一点都不卷!