当 OpenClaw 开始主动“少记一点”:长期记忆真正进入了工程化阶段
很多人理解 Agent 的长期记忆时,第一反应是:记得越多越好。
聊天记录要存下来,工具结果要存下来,模型推理过程最好也能存下来。插件能力也是一样,最好一次性把所有工具、所有接口、所有入口都暴露给模型。这样看起来系统更聪明,能力更强,也更像一个“全能助手”。
但真正把 Agent 用到日常工作流里,就会发现这条路并不稳。
记得太多,会把噪音、临时状态、模型产物和敏感上下文一起写进长期系统。暴露太多,会让模型看到过宽的工具面、过多的调用入口和过大的提示预算。短期看是能力丰富,长期看是边界模糊。
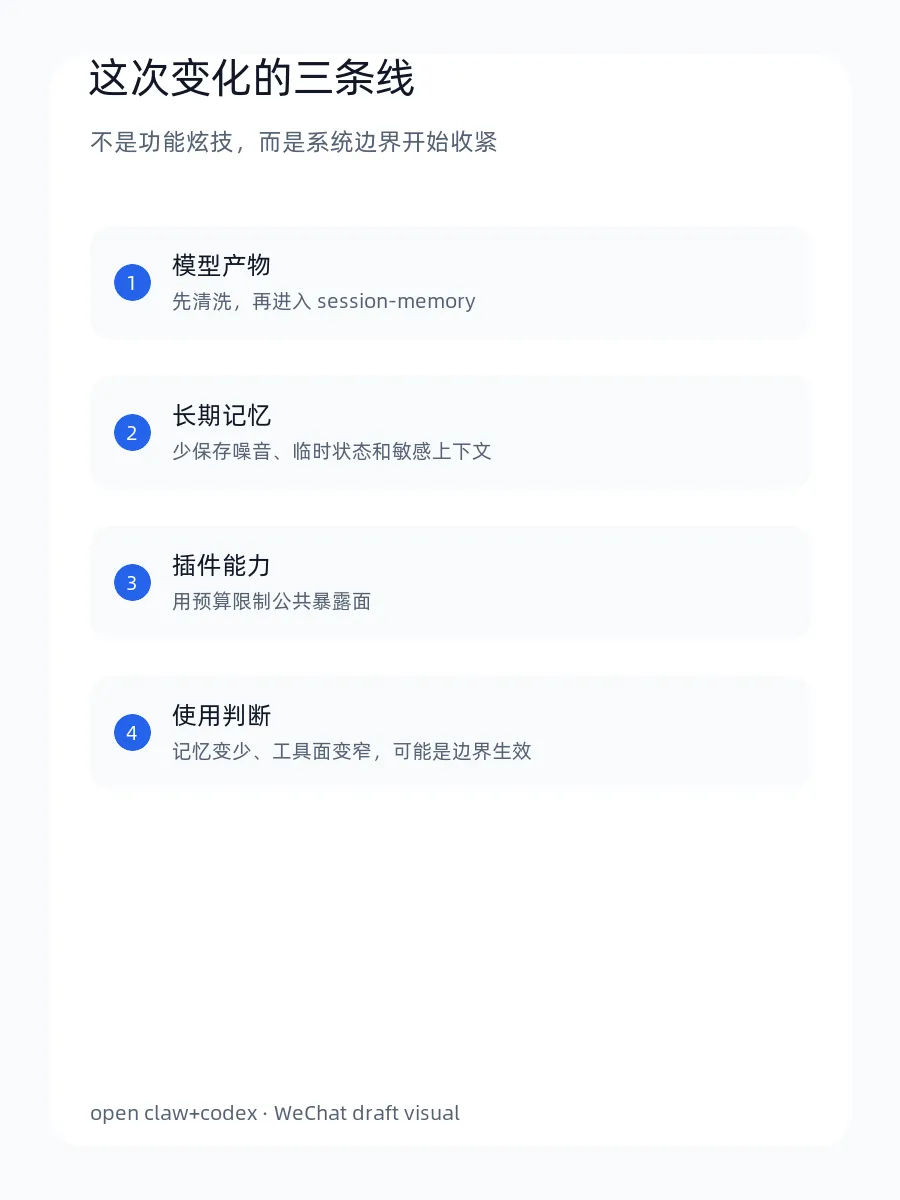
OpenClaw 主干最近合入了一个很小但值得注意的更新:`session-memory` 在保存模型产物前做清洗,同时 SDK plugin surface budgets 也有调整。
它更像一个方向信号:OpenClaw 正在从“把记忆和插件能力接起来”,进入“主动裁剪记忆和能力暴露面”的阶段。
▲ 这次变化的关键词:保存前清洗、暴露面预算、边界收紧。
01 一、长期记忆最大的问题,不是记不住,而是记错东西
一次任务结束后,把会话摘要写进 memory;一次工具调用结束后,把结果挂到 session;一次模型输出后,把产物留给下次调用。这样做当然有用,否则每次重启都像失忆。
但长期记忆的真正风险,往往不是“不够多”,而是“不够干净”。
单次回答错了,用户可以纠正;长期记忆写错了,后面每一次召回都会带着旧错误。它会让 Agent 看起来越来越“了解你”,但其实是在用一套污染过的上下文理解你。
所以 `session-memory` 保存前清洗这件事,表面上是安全处理,深层是记忆工程的质量门槛。
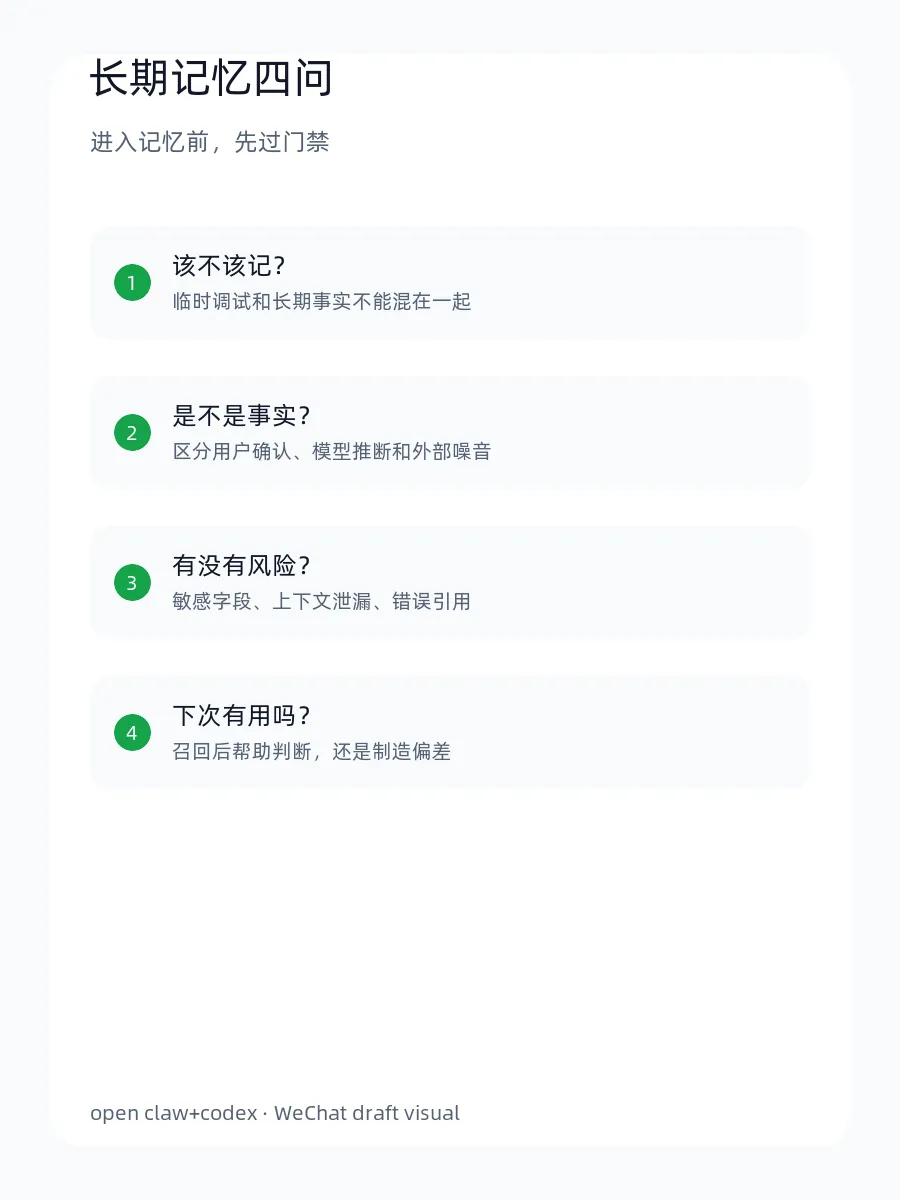
一个成熟的 Agent 记忆系统,不能只问“能不能写进去”,还要问:
另一个变化是 SDK plugin surface budgets。
这类更新听起来很工程化:surface、budget、export、baseline,像是只有维护者才关心的测试项。
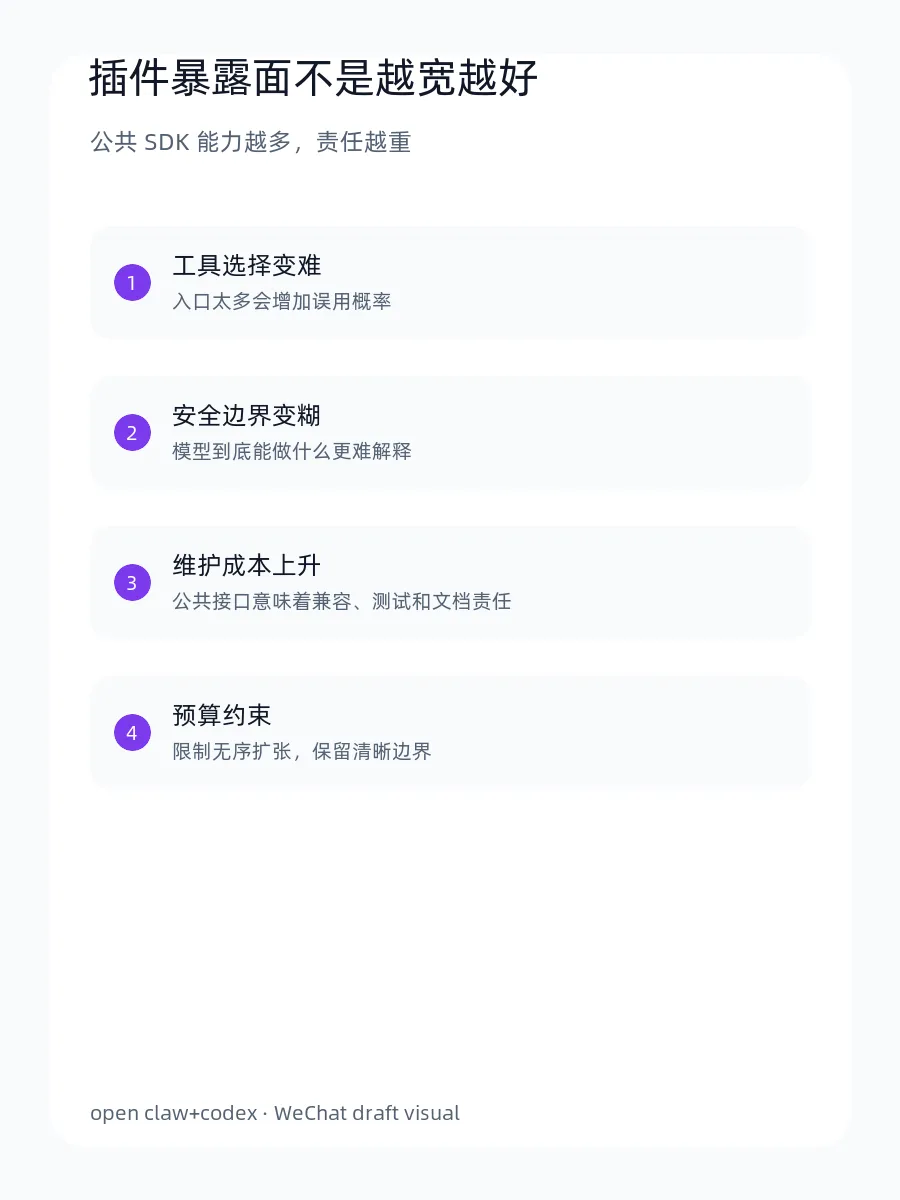
所谓 plugin surface,可以理解为插件向外暴露的能力边界。哪些函数能被调用,哪些类型成为公共 API,哪些入口会进入模型可见的工具面,都会影响系统的复杂度。
工具越多,不代表越会用。很多时候,模型会在多个相似入口之间摇摆,或者误用一个本不该公开的底层能力。
一个插件如果把太多内部能力暴露成公共接口,就很难说清楚“模型到底能做什么、不能做什么”。这对涉及文件、浏览器、账号、消息、执行节点的系统尤其危险。
一旦某个能力变成公共 surface,就意味着它要承担兼容性、文档、测试和安全责任。随手暴露的接口,最后都会变成长期债务。
所以 surface budget 的意义,不是限制能力,而是阻止能力无序扩张。
对开发者来说,这意味着 OpenClaw 正在更认真地区分:
▲ 插件暴露面越宽,越需要预算、审计和公共 API 边界。
如果你只是普通用户,这次更新可能不会带来一个明显按钮。
没有新的炫酷界面,也没有一个“点击开启长期记忆 2.0”的开关。
以后如果你发现 OpenClaw 或 Codex 的某些长期记忆“没以前那么多”,不一定是坏事。可能是保存前清洗开始生效,系统主动丢掉了一些不该长期保存的模型产物。
以后如果你发现某些插件能力报告变短、工具面变窄,也不一定是能力退化。可能是 SDK surface budget 在限制公共暴露面,把内部实现重新收回边界内。
过去我们常把 Agent 系统的问题理解成“能力不够”。
因为 Agent 的成熟,不是永远加工具、加记忆、加上下文,而是在该记的时候记、该忘的时候忘、该暴露的时候暴露、该收起来的时候收起来。
它会接触本地文件、微信消息、浏览器、插件、技能、项目仓库、长期记忆和多 Agent 协作。它越贴近日常工作,越不能只靠“模型聪明”来维持秩序。
• 它还要避免把隐私、噪音、错误推断和临时状态写成事实。
记忆治理解决的是:什么值得留下,什么必须清洗,什么应该过期,什么只能作为当前会话上下文。
插件治理解决的是:什么能力能被调用,什么能力只属于内部,什么能力需要人工确认,什么能力必须有审计和预算限制。
这次 `session-memory` 和 plugin surface budget 的更新,正好落在这两个位置。
它说明 OpenClaw 的工程重心,不只是把 Agent 做得“更会干活”,也在把 Agent 做得“更知道边界”。
05 五、一个成熟 Agent 系统,最终比拼的是边界感
真正拉开差距的,是系统能不能在真实环境里稳定运行:
• 用户是否知道系统为什么记住、为什么忘掉、为什么看不到某个工具。
它不是一个“大功能发布”,而是一个成熟系统开始收紧边界的信号。
很多 Agent 产品还停留在展示能力:我能接多少插件,我能记多少历史,我能调用多少工具。
你凭什么保证这些内容不会在未来变成错误召回、权限误用或上下文泄漏?
OpenClaw 这次的小更新,回答的正是这个方向。
长期记忆和插件生态走到这一步,才算真正进入工程化阶段。
 夜雨聆风
夜雨聆风