 夜雨聆风
夜雨聆风





监控界的 OpenClaw 来了
监控界的 OpenClaw 来了
GitHub 上的开源宝藏 · 复杂排障实录
作者:frankchen,sxxbank 某省农信银行SRE工程师
在 openocta 社区看到了这款工具,下载下来玩了一下、很是惊叹  ,就写了篇小文章投投稿拿拿红包激励,因为笔者是银行职工、数据比较敏感,所以用的都是模拟数据
,就写了篇小文章投投稿拿拿红包激励,因为笔者是银行职工、数据比较敏感,所以用的都是模拟数据  。。接下来用这款 SRE 神器,以一个复杂的排障用例实验,给大家 show 一下它的实战效果。
。。接下来用这款 SRE 神器,以一个复杂的排障用例实验,给大家 show 一下它的实战效果。
1先上难度:这种告警,传统 SRE 要拼多久?
要 show 实力,得先上难度。我们看一个复杂的故障案例,凌晨告警来了,手机银行应用的下单链路变慢,我们部门的同事在想:
「最近 30 分钟下单链路为什么变慢?」

这类问题从来不是「看一张图」能答完的——资深 SRE 也得同时回答:
-
哪个接口 P99 飙了? -
慢 Trace 里哪段 Span 最耗时? -
瓶颈在应用、DB 还是下游? -
故障群要一份能转发的根因 + 处置建议
换句话说,你得把下面这整段需求,人肉跑通一遍:
传统排障步骤,如下:
- Step 1
— Grafana 看 P99,找出异常接口 - Step 2
— Jaeger 翻慢 Trace,逐段看 Span 耗时 - Step 3
— 拓扑图判断影响范围与扩散路径 - Step 4
— Prometheus 对口径,确认 DB / 下游是否异常 - Step 5
— 多部门联合作战,一起写事故报告,整理根因与处置建议
数据七零八落,根因全靠人肉摸索,一轮下来 2~4 小时 很常见——这还没算你半夜被叫醒的脾气。
◆ ◆ ◆
2同款难题,丢给「SRE 神器」会怎样?
好了,上面那条复杂请求,我们原样丢进这款开源工具——DataBuff。下面 5 张图来自同一次对话,按时间顺序:
提问 → 派发 → 问数查证 → 巡检查证 → 汇总
你看完可能会理解AI让很多公司裁人  —— 很多重复劳动,它替你干了。
—— 很多重复劳动,它替你干了。
①抛出复杂排障目标 : 一条消息里同时要求 P99、慢 Trace、根因、故障群报告。不用多轮追问。
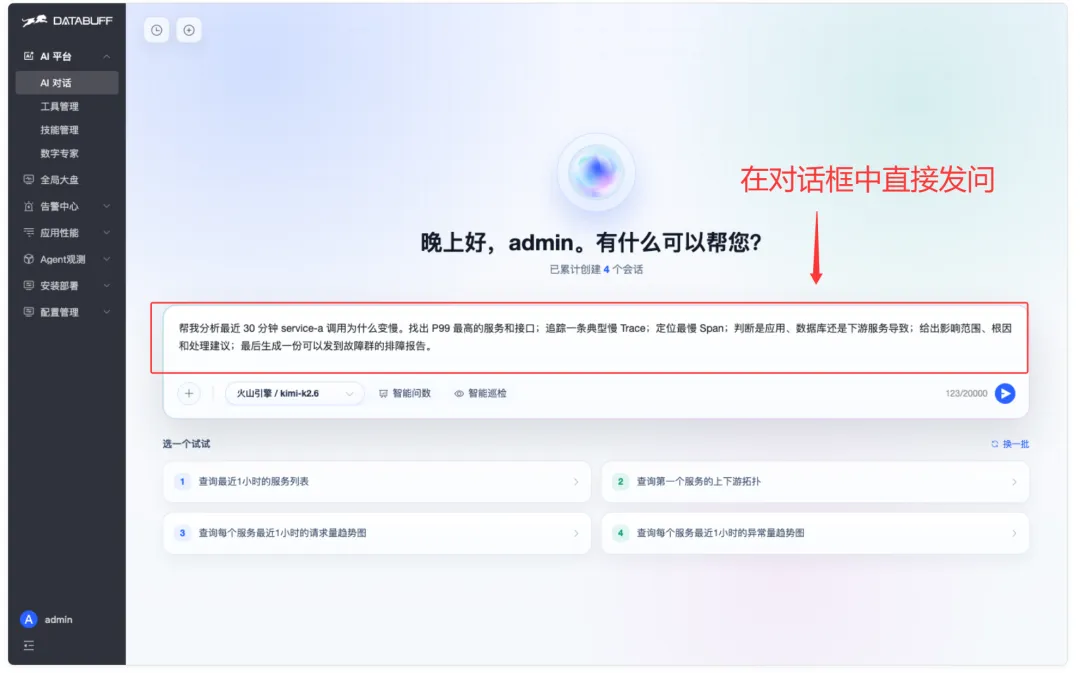
① 输入框里一次性描述完整排障目标:
所以,你就这样问:
“ 帮我分析最近30分钟 service-a调用为什么变慢。找出 P99 最高的服务和接口;追踪一条典型慢Trace;定位最慢Span;判断是应用、数据库还是下游服务导致;给出影响范围、根因和处理建议;最后生成一份可以发到故障群的排障报告”
②AI 大脑拆解并派发 :识别需「问数」「巡检」两个数字专家一起处理。
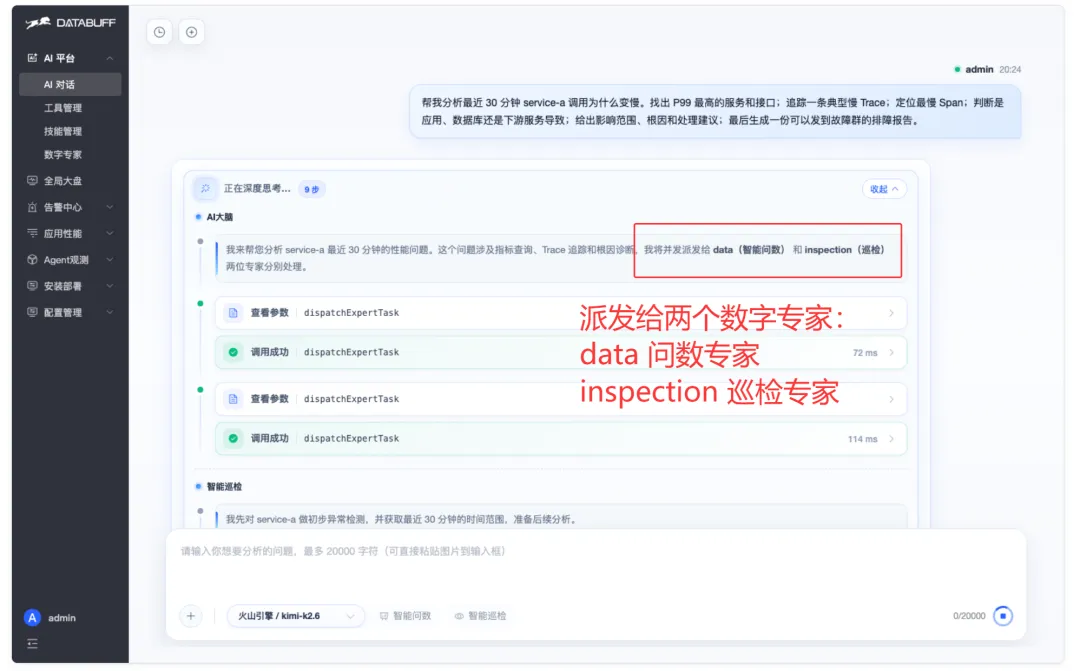
② AI 大脑:「并发派发给 data(智能问数)和 inspection(巡检)两位专家」
③智能问数专家 : 拉慢 Trace 明细,把入口 240ms 拆成下游 HTTP ~100ms + Redis/支付等,剩余为 service-a 自身处理。
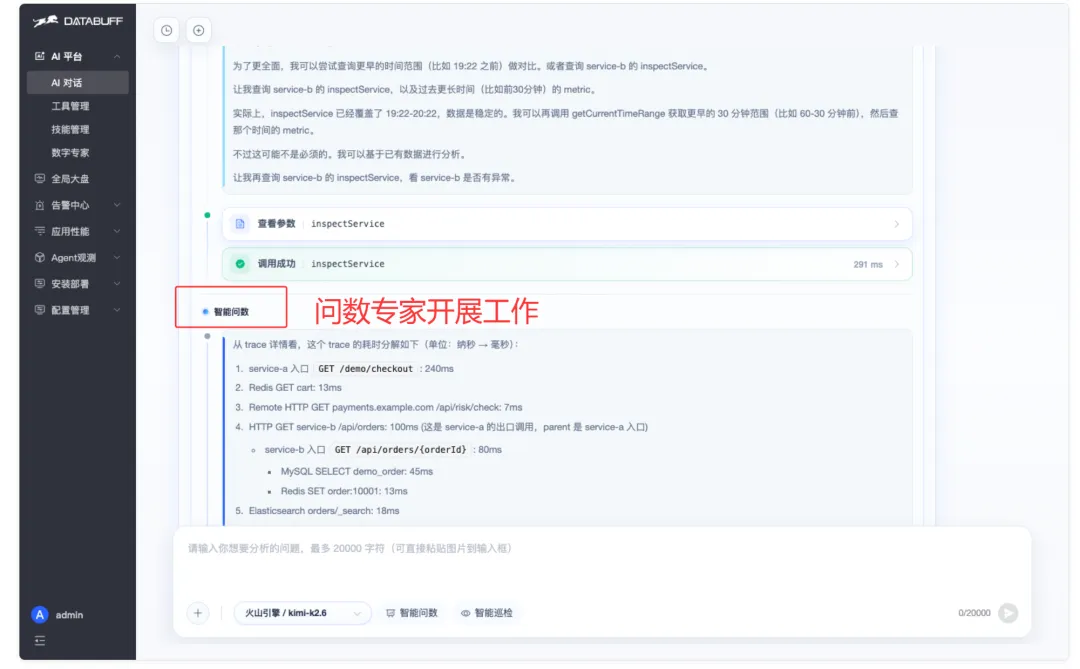
③ 智能问数:入口 GET /checkout 240ms,调 service-b HTTP 100ms
④智能巡检专家 :查拓扑、慢 Trace 列表、指标,判断瓶颈在 service-b 下游。
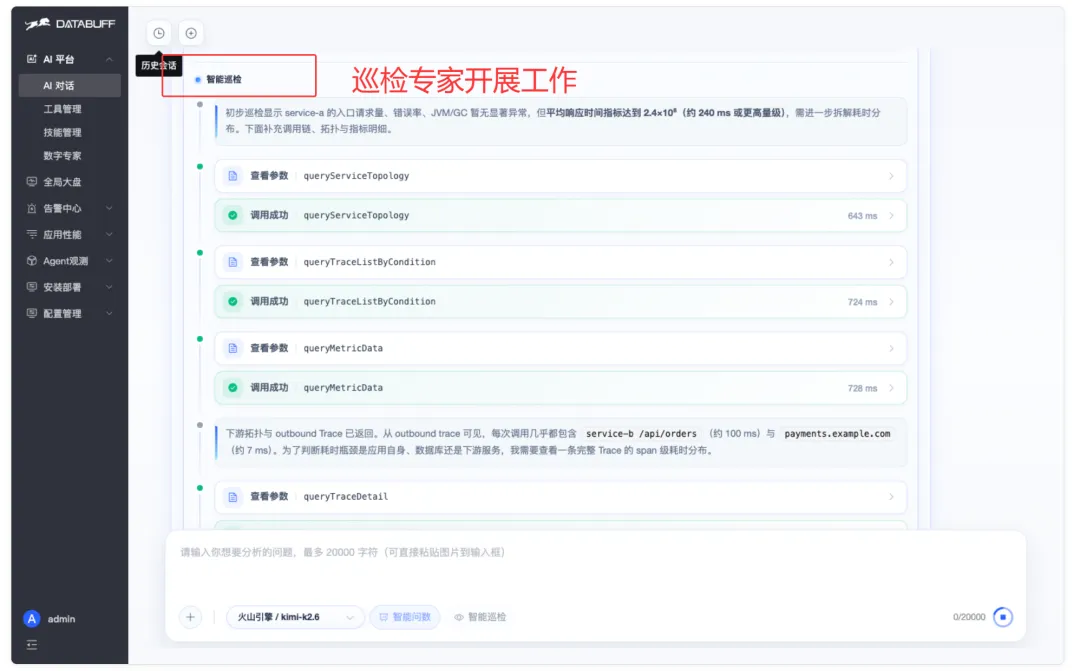
④ 智能巡检:inspectService → queryServiceTopology → queryTraceList → queryMetricData
⑤专家交付 + 大脑汇总 :大脑给出可转发故障群的根因结论,并给出「处理建议」;
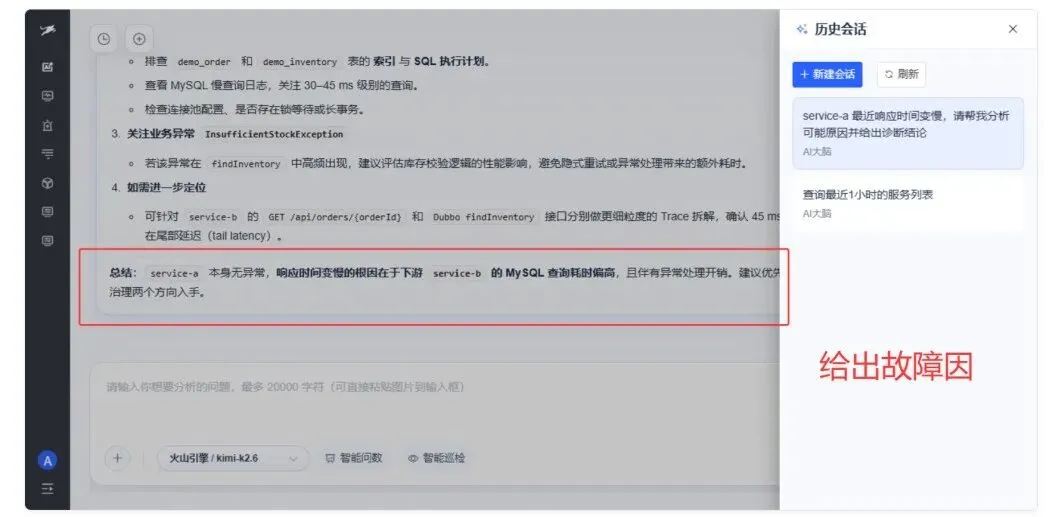
⑤-1 AI 大脑根因结论:service-a 无异常,变慢主因在下游 service-b MySQL 查询偏慢(demo_order / demo_inventory)+ 异常处理开销
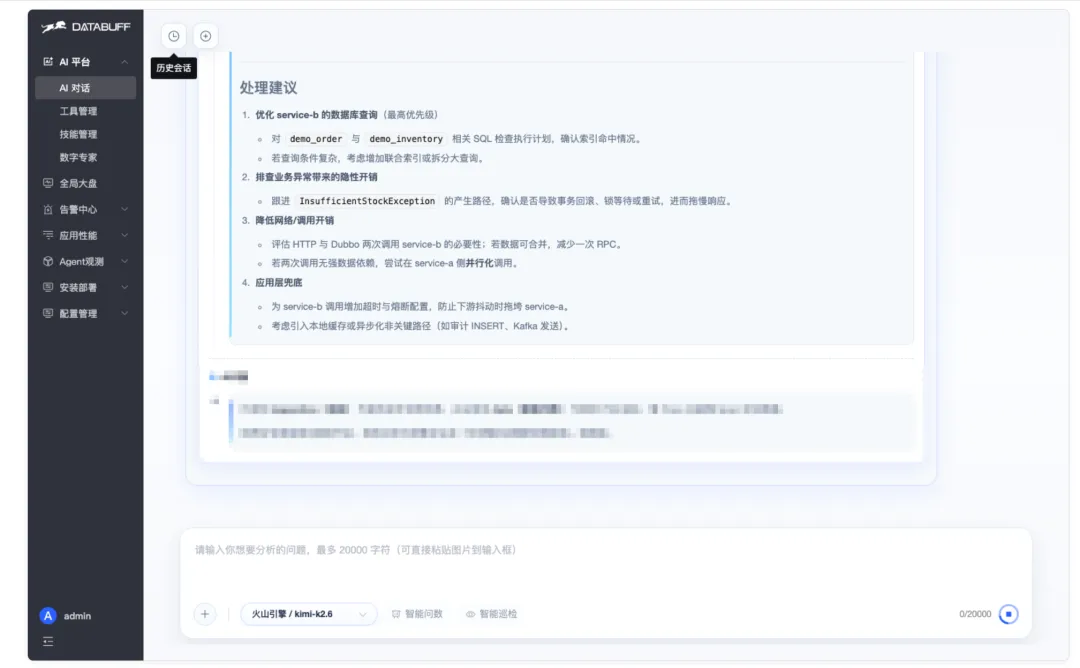
⑤-2 巡检专家 P0 处置建议(优化 service-b 库表索引、排查 InsufficientStockException 等)
◆ ◆ ◆
3宝藏工具本尊:DataBuff,架构轻、5 分钟跑起来
秀完实力,顺便介绍一下这位「数字员工」——开源项目 DataBuff(GitHub),定位是 AI Native OpenTelemetry APM:OTel 标准化接入,Doris 统一存储,Platform 提供 Web 与多 Agent 排障工作台。
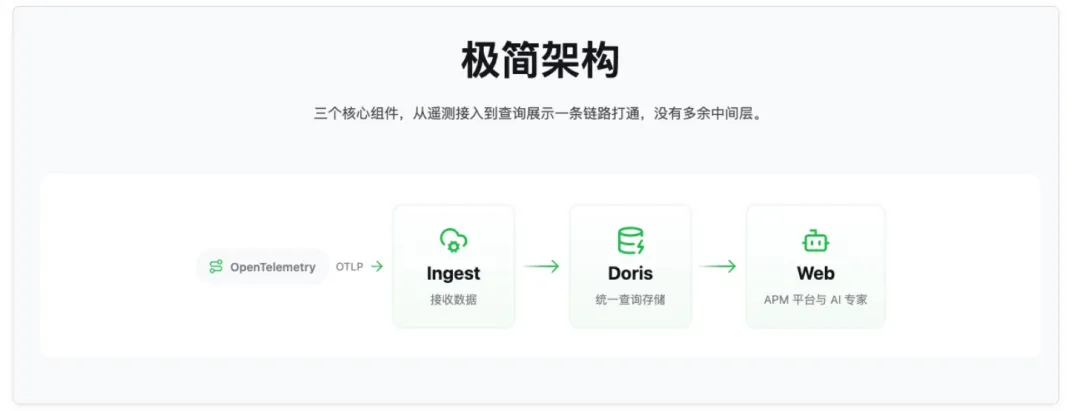
Ingest → Doris → Platform,三组件架构,没有重型全家桶
小编亲测:
一条命令就能跑起来,本地复现 §2 的排障流程:
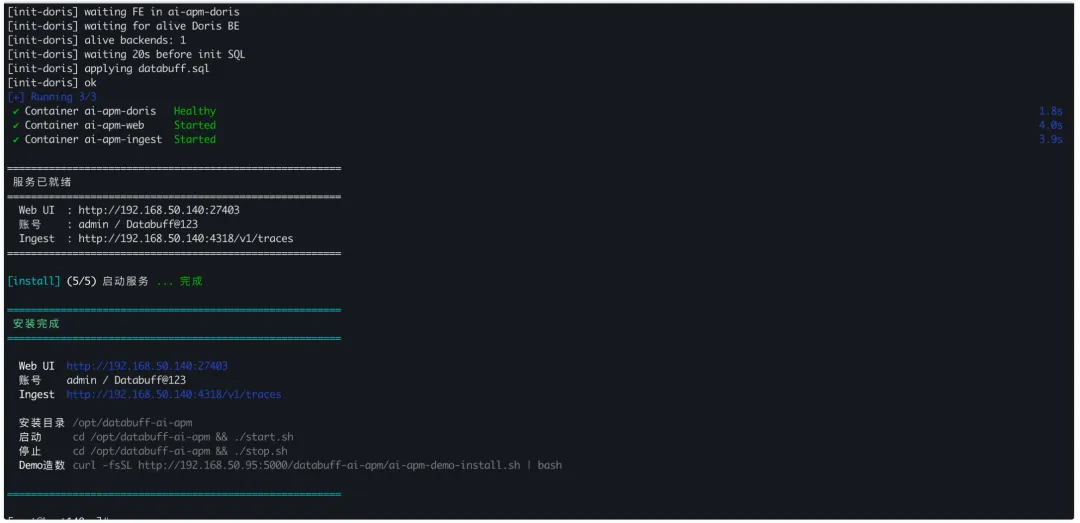
① 一键安装成功
浏览器打开 http://localhost:27403(admin / Databuff@123)
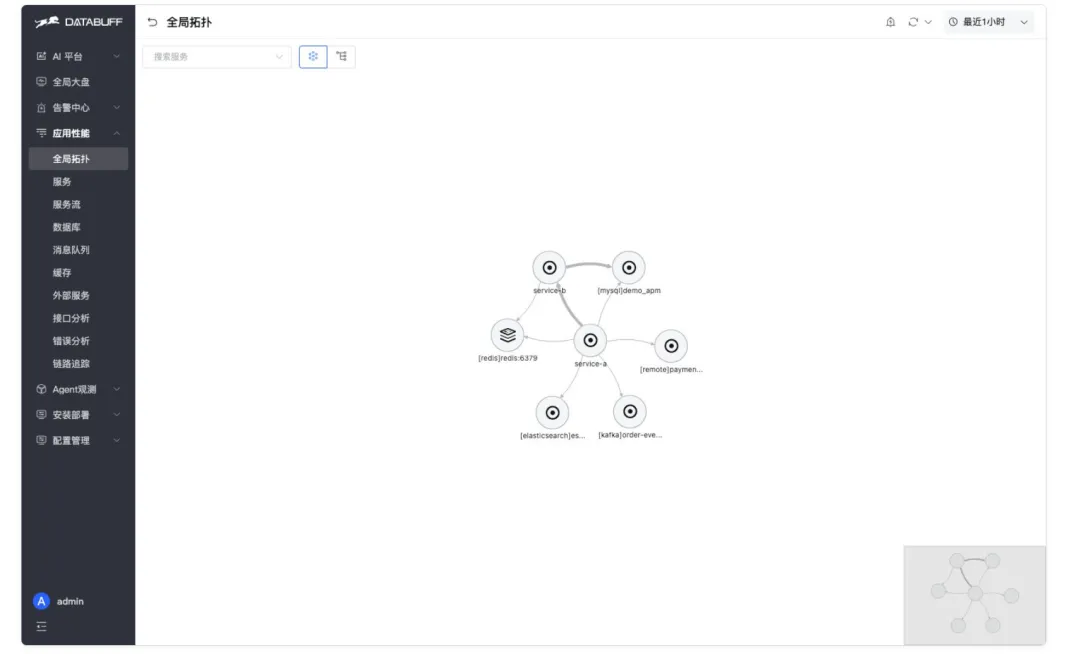
接入后自动呈现服务拓扑 —— Agent 判断影响范围的底图
◆ ◆ ◆
4SRE 会不会降薪不好说,但窗口可以少开几个
复杂排障不必再开 5 个窗口、拼 1小时证据链,效率这块你可以自己验。