










































































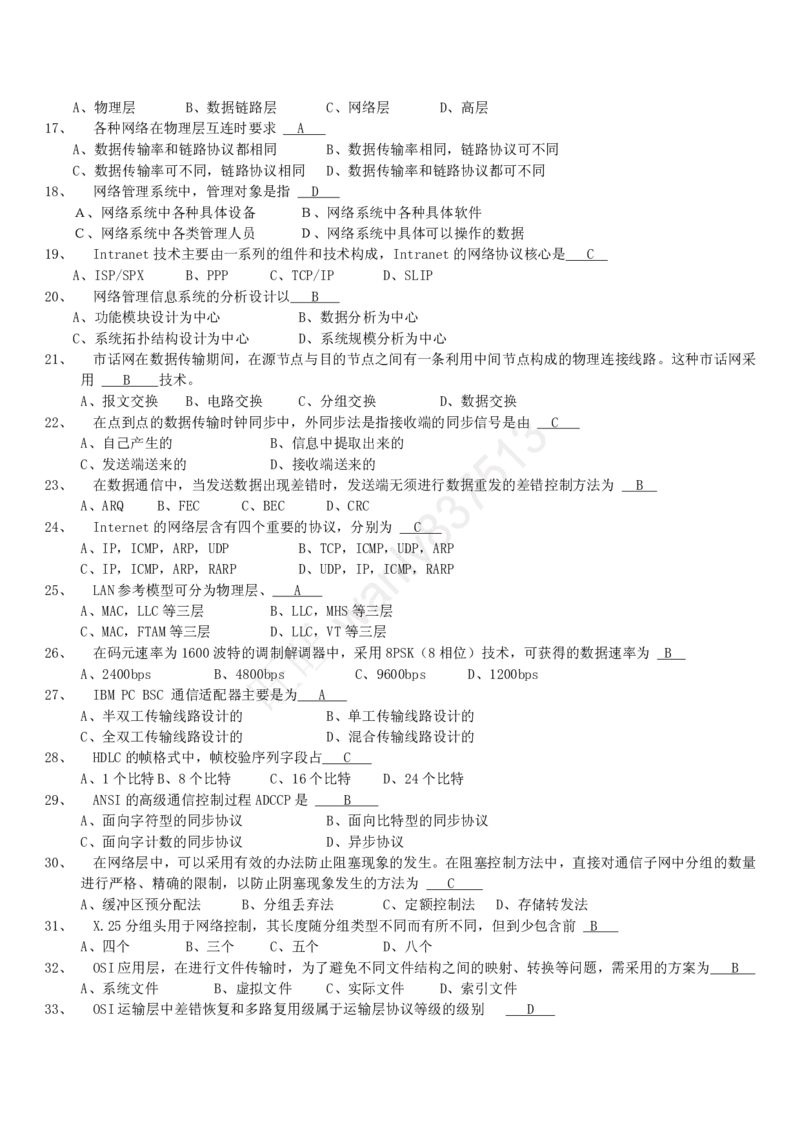

























































































































































文档内容
第 1111 章:数据库等基础知识习题...................................... 2
第 2222 章:计算机网络习题................................................ 75
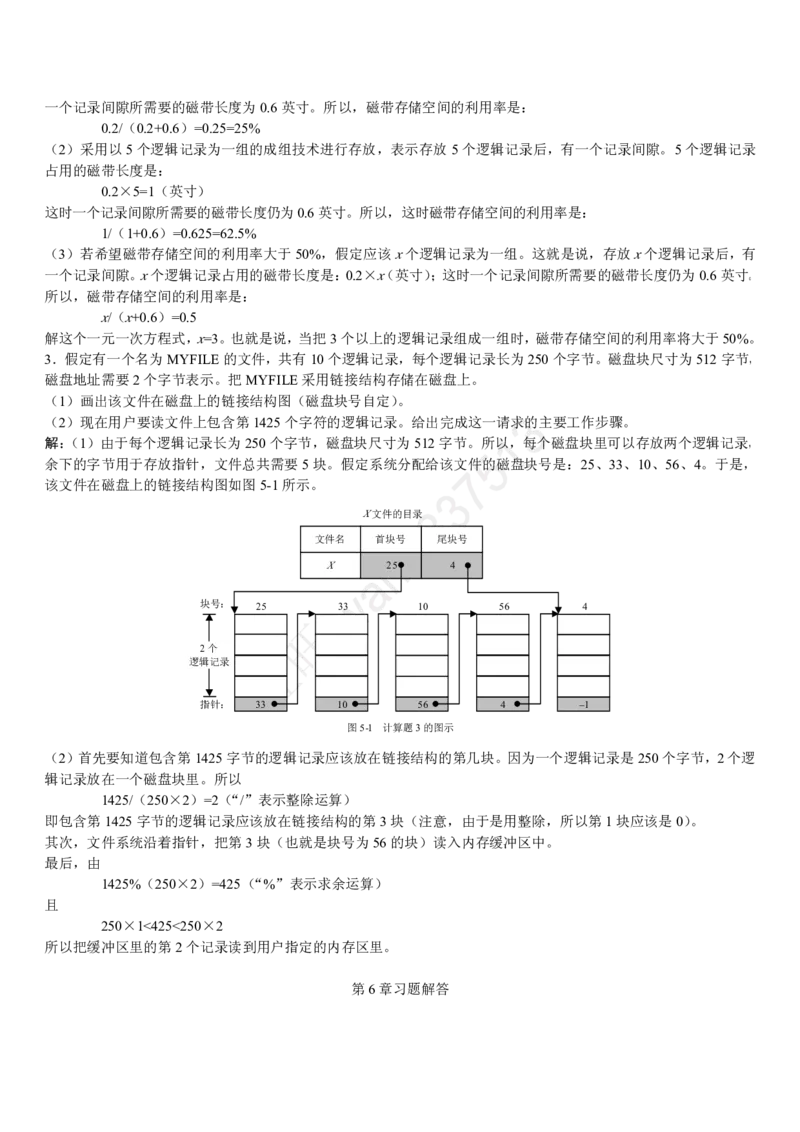
第 3333 章:操作系统习题.................................................... 96
第 4444 章:CCCC 语言练习题...................................................137
第 5555 章:信息系统分析与设计习题..............................193
○○○○○○○
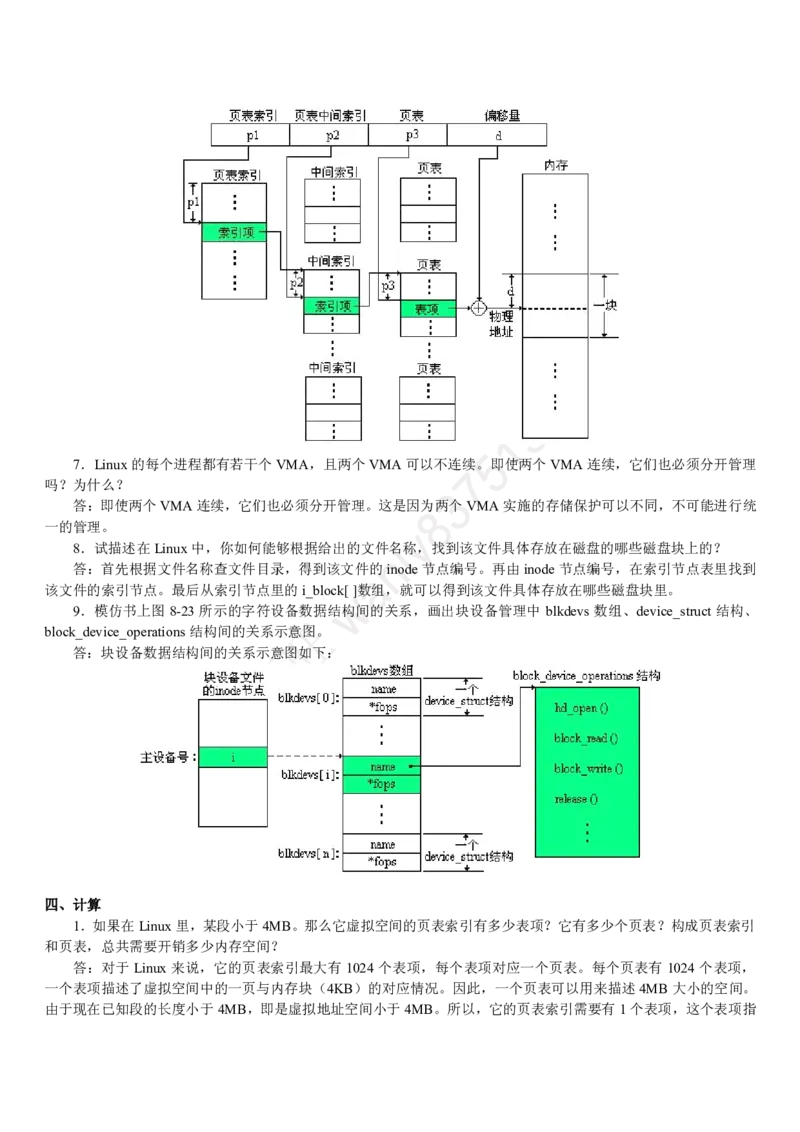
银 行 笔 试 小 当 家
祝祝祝祝大大大大家家家家笔笔笔笔试试试试顺顺顺顺利利利利,,,,马马马马到到到到成成成成功功功功
店店店店址址址址::::hhhhttttttttpppp::::////////wwwwaaaannnnllllyyyy888833337777555511113333....ttttaaaaoooobbbbaaaaoooo....ccccoooommmm第 1111 章:数据库等基础知识习题
第一章 数据结构
一、选择题
(1)下列数据结构中,能用二分法进行查找的是
A)顺序存储的有序线性表 B)线性链表
C)二叉链表 D)有序线性链表
【答案】A
【解析】二分查找只适用于顺序存储的有序表。在此所说的有序表是指线性表中的元素按值非递减排列(即从小到大.
但允许相邻元素值相等)的。选项A正确。
(2)下列关于栈的描述正确的是
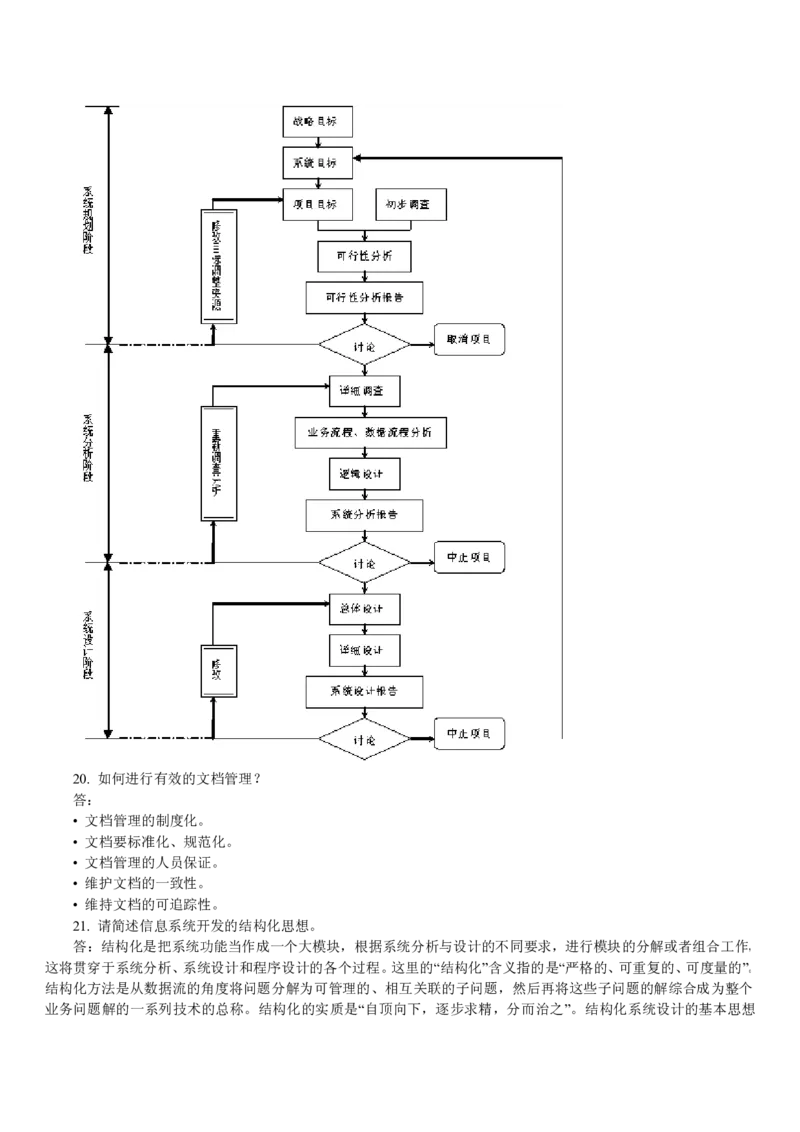
A)在栈中只能插入元素而不能删除元素
B)在栈中只能删除元素而不能插入元素
C)栈是特殊的线性表,只能在一端插入或删除元素
D)栈是特殊的线性表,只能在一端插入元素,而在另一端删除元素
【答案】C
【解析】栈是一种特殊的线性表,其插入与删除运算都只在线性表的一端进行。由此可见,选项A、选项B和选项D
错误,正确答案是选项C。
(3)下列叙述中正确的是
A)一个逻辑数据结构只能有一种存储结构
B)数据的逻辑结构属于线性结构,存储结构属于非线性结构
C)一个逻辑数据结构可以有多种存储结构,且各种存储结构不影响数据处理的效率
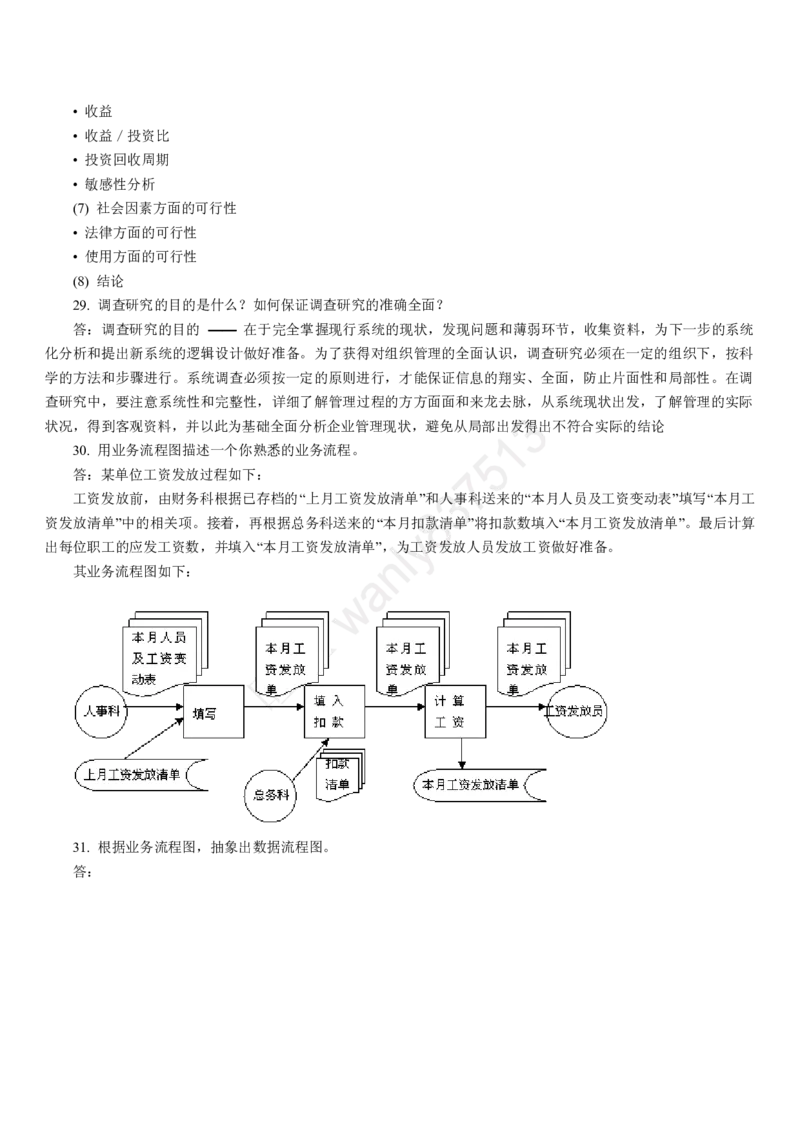
D)一个逻辑数据结构可以有多种存储结构,且各种存储结构影响数据处理的效率
【答案】D
【解析】一般来说,一种数据的逻辑结构根据需要可以表示成多种存储结构,常用的存储结构有顺序、链接、索引
等存储结构。而采用不同的存储结构,其数据处理的效率是不同的。由此可见,选项D的说法正确。
(4)算法执行过程中所需要的存储空间称为算法的
A)时间复杂度B)计算工作量C)空间复杂度D)工作空间
【答案】c
【解析】算法执行时所需要的存储空间,包括算法程序所占的空间、输入的初始数据 所占的存储空间以及算法
执行过程中所需要的额外空间,其中额外空间还包括算法程序执行过程的工作单元以及某种数据结构所需要的附加
存储空间。这些存储空间共称为算法的空间复杂度。
(5)下列关于队列的叙述中正确的是
A)在队列中只能插入数据B)在队列中只能删除数据
C)队列是先进先出的线性表D)队列是先进后出的线性表
【答案】c【解析】对队列可以进行插入和删除数据的操作,只是插入数据只能在队尾,删除数据只能在队头。所以队列是先
进先出的线性表。
(6)设有下列二叉树:
A
B C
D E F
对此二叉树后序遍历的结果为
A)ABCDEF B)BDAECF C)ABDCEF D)DBEFCA
【答案】D
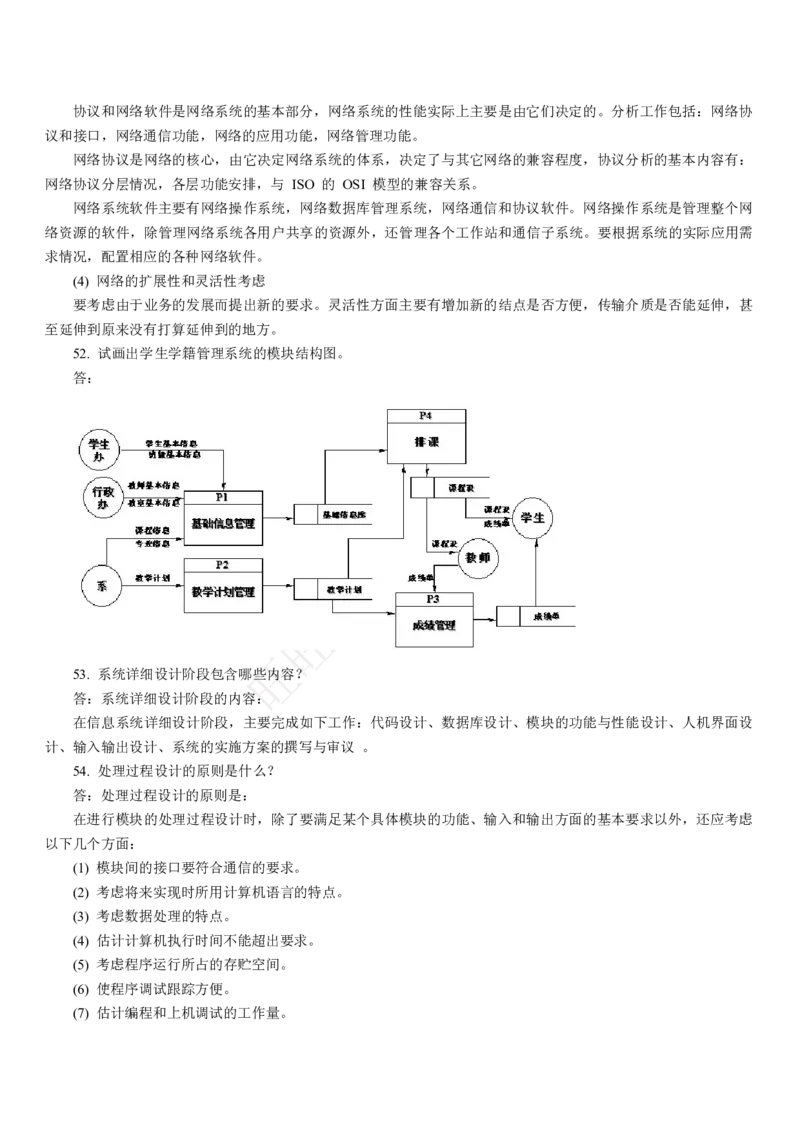
【解析】二叉树的遍历分为先序、中序、后序三种不同方式。本题要求后序遍历。其遍历顺序应该为:后序遍历左
子树一>后序遍历右子树一>访问根结点。按照定义,后序遍历序列是DBEFCA,故答案为D。
(7) 下列叙述中正确的是( )
A)程序执行的效率与数据的存储结构密切相关
B)程序执行的效率只取决于程序的控制结构
C)程序执行的效率只取决于所处理的数据量
D)以上三种说法都不对
【答案】A
【解析】本题考查程序效率。程序效率是指程序运行速度和程序占用的存储空间。影响程序效率的因素是多方面的,
包括程序的设计、使用的算法、数据的存储结构等。在确定数据逻辑结构的基础上,选择一种合适的存储结构,可
以使得数据操作所花费的时间少,占用的存储空间少,即提高程序的效率。因此,本题选项A的说法是正确的。
(8) 下列叙述中正确的是( )
A)数据的逻辑结构与存储结构必定是一一对应的
B)由于计算机存储空间是向量式的存储结构,因此,数据的存储结构一定是线性结构
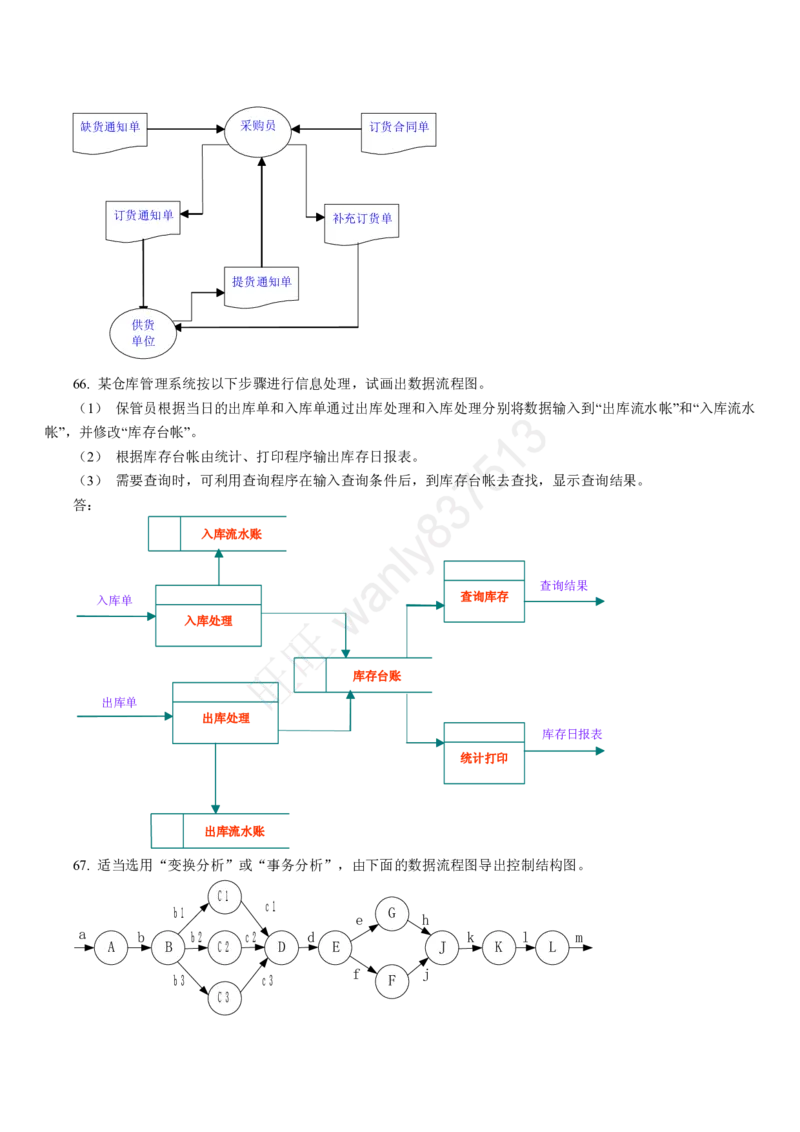
C)程序设计语言中的数组一般是顺序存储结构,因此,利用数组只能处理线线结构
D)以上三种说法都不对
【答案】D
【解析】本题考查数据结构的基本知识。
数据之间的相互关系称为逻辑结构。通常分为四类基本逻辑结构,即集合、线性结构、树型结构、图状结构或网状
结构。存储结构是逻辑结构在存储器中的映象,它包含数据元素的映象和关系的映象。存储结构在计算机中有两种,
即顺序存储结构和链式存储结构。顺序存储结构是把数据元素存储在一块连续地址空间的内存中;链式存储结构是
使用指针把相互直接关联的节点链接起来。因此,这两种存储结构都是线性的。可见,逻辑结构和存储结构不是一
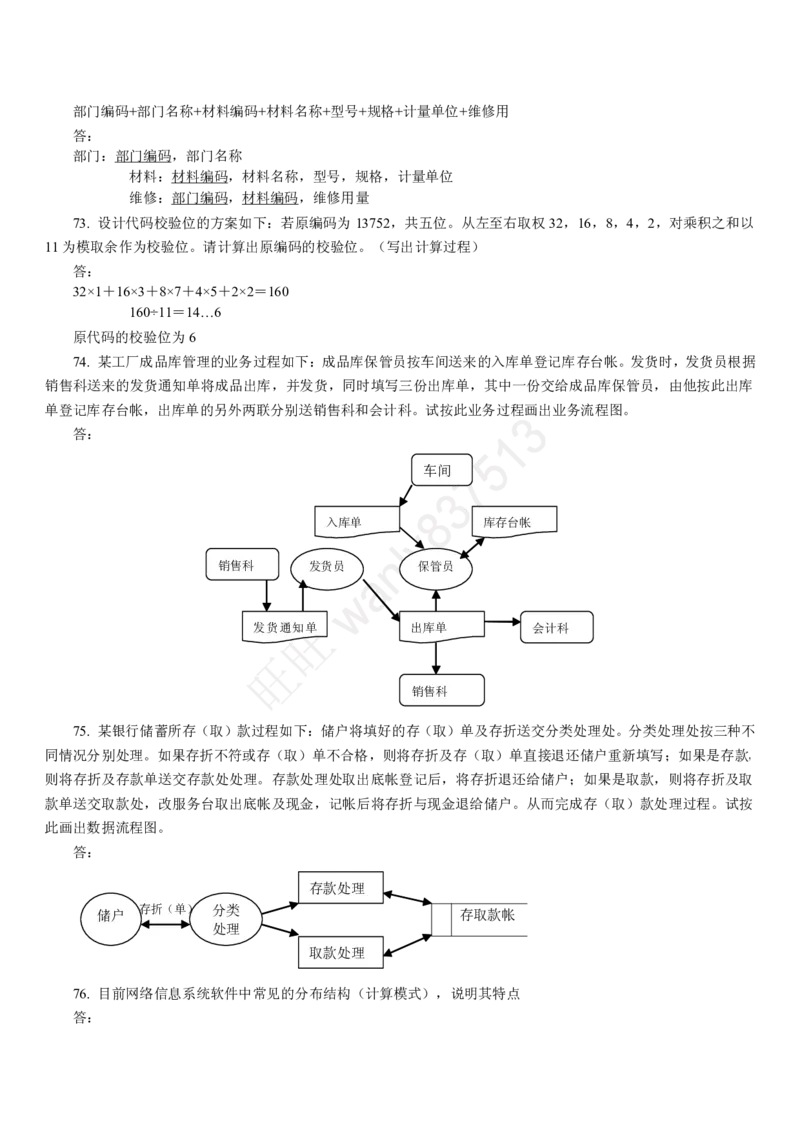
一对应的。因此,选项A和选项B的说法都是错误的。
无论数据的逻辑结构是线性的还是非线性的,只能选择顺序存储结构或链式存储结构来实现存储。程序设计语言中,数组是内存中一段连续的地址空间,可看作是顺序存储结构。可以用数组来实现树型逻辑结构的存储,比如二叉树。
因此,选项c的说法是错误的
(9) 冒泡排序在最坏情况下的比较次数是( )
A)n(n+1)/2 B)nlogn C)n(n-1)/2 D)n/2
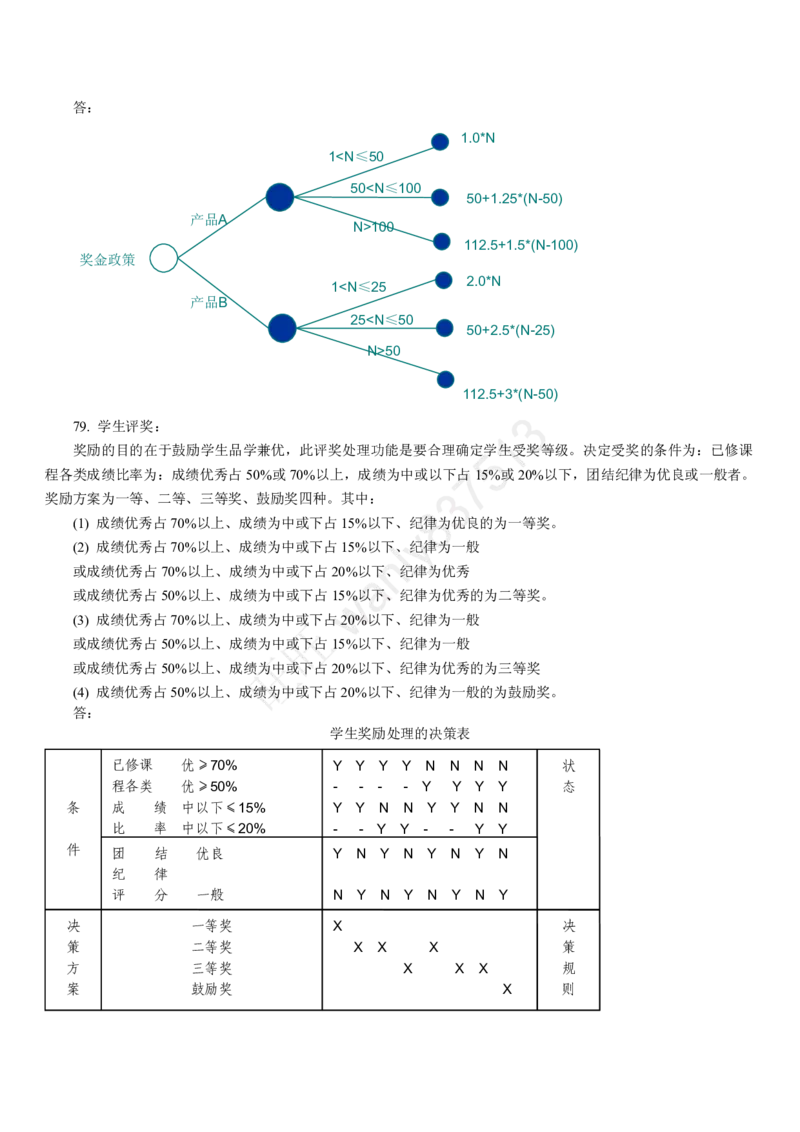
2
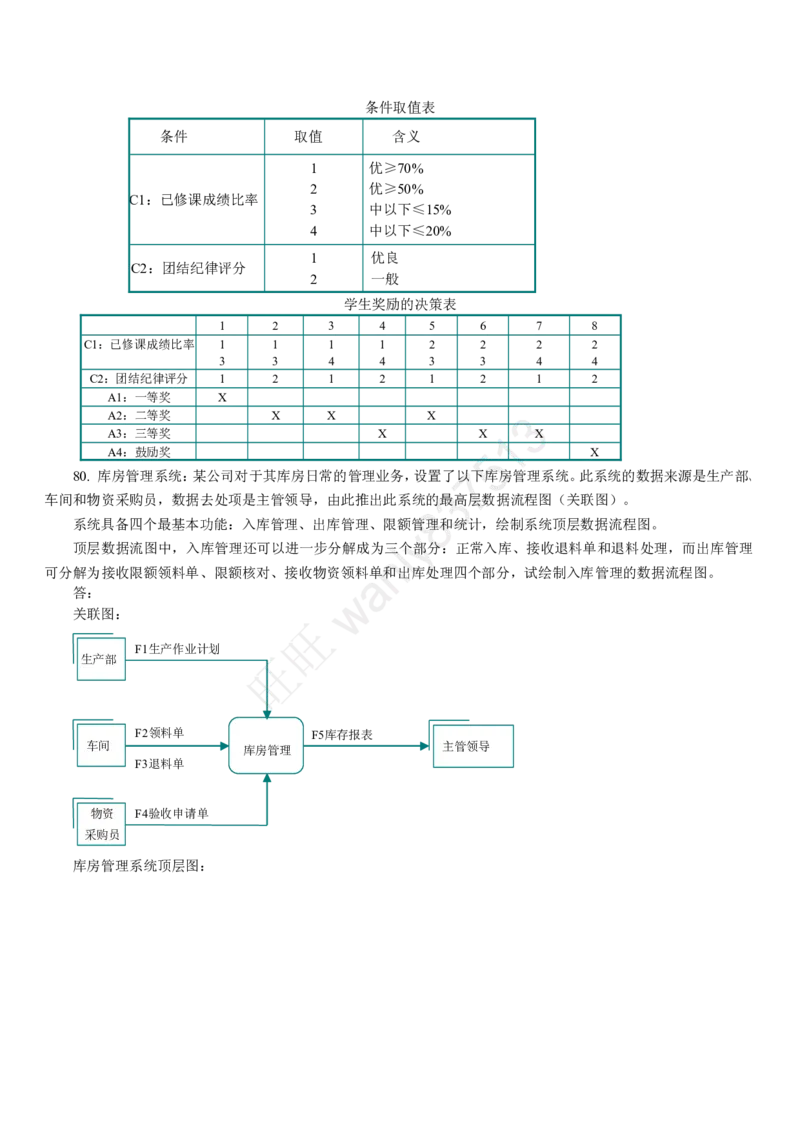
【答案】C
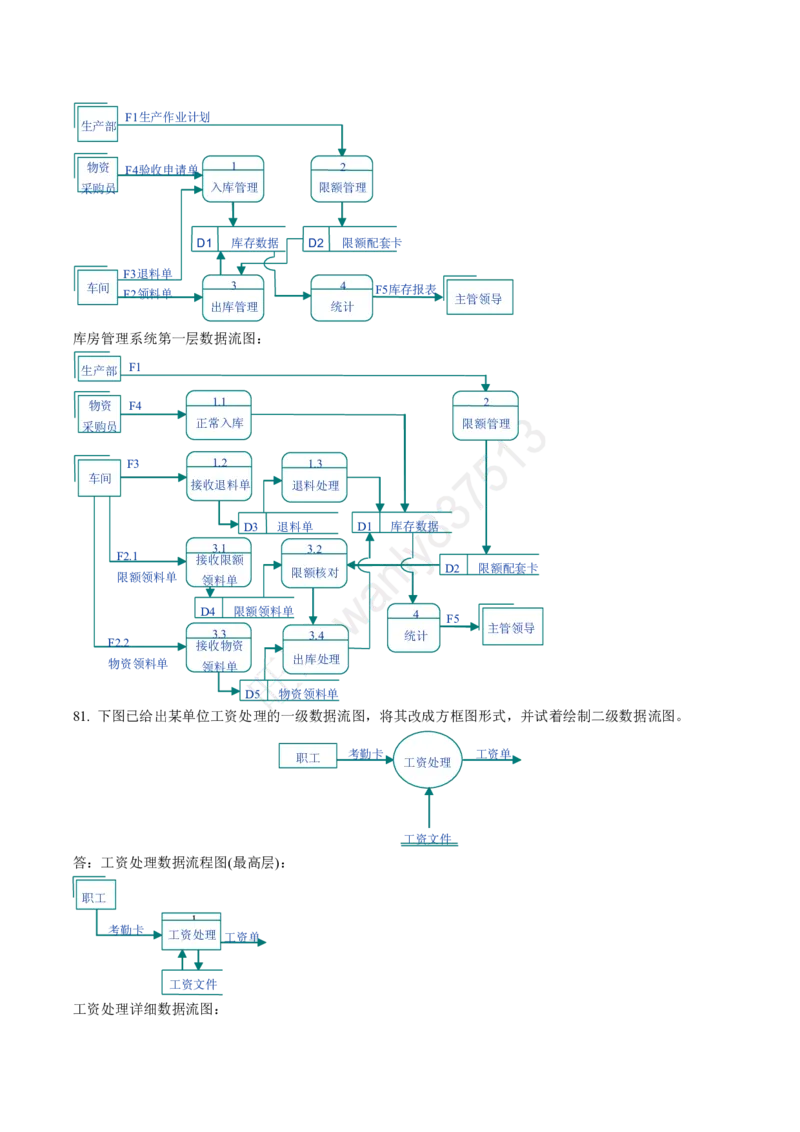
【解析】冒泡排序的基本思想是:将相邻的两个元素进行比较,如果反序,则交换;对于一个待排序的序列,经一
趟排序后,最大值的元素移动到最后的位置,其他值较大的元素也向最终位置移动,此过程称为一趟冒泡。对于有n
个数据的序列,共需 n-1趟排序,第 i趟对从l到n-i个数据进行比较、交换。冒泡排序的最坏情况是待排序序列
逆序,第l趟比较n-1次,第2趟比较n-2次。依此类推,最后趟比较 1次,一共进行n-l趟排序。因此,冒泡排
序在最坏情况下的比较次数是(n-1)+(n-2)+…+l,结果为n(n-1)/2。本题的正确答案是选项c。
(10) 一棵二叉树中共有70个叶子结点与80个度为1的结点,则该二叉树中的总结点数为( )
A)219 B)221 C)229 D)231
【答案】A
【解析】本题考查数据结构中二叉树的性质。二叉树满足如下一条性质,即:对任意一棵二叉树,若终端结点(即叶
n n n = n +l
子结点)数为 ,而其度数为2的结点数为 ,则 。
0 2 0 2
根据这条性质可知,若二叉树中有70个叶子结点,则其度为2的结点数为70-1,即69个。二叉树的总结点数是度
为2、度为1和叶子结点的总和,因此,题目中的二叉树总结点数为69+80+70,即219。因此,本题的正确答案是选
项A。
(11) 下列叙述中正确的是( )
A)算法的效率只与问题的规模有关,而与数据的存储结构无关
B)算法的时间复杂度是指执行算法所需要的计算工作量
C)数据的逻辑结构与存储结构是一一对应的
D)算法的时间复杂度与空间复杂度一定相关
【答案】B
【解析】本题考查数据结构中有关算法的基本知识和概念。数据的结构,直接影响算法的选择和效率。而数据结构
包括两方面,即数据的逻辑结构和数据的存储结构。因此,数据的逻辑结构和存储结构都影响算法的效率。选项 A
的说法是错误的。算法的时间复杂度是指算法在计算机内执行时所需时间的度量;与时间复杂度类似,空间复杂度
是指算法在计算机内执行时所需存储空间的度量。因此,选项B的说法是正确的。
数据之间的相互关系称为逻辑结构。通常分为四类基本逻辑结构,即集合、线性结构、树型结构、图状结构或网状
结构。存储结构是逻辑结构在存储器中的映象,它包含数据元素的映象和关系的映象。存储结构在计算机中有两种,
即顺序存储结构和链式存储结构。可见,逻辑结构和存储结构不是一一对应的。因此,选项c的说法是错误的。有
时人们为了提高算法的时间复杂度,而以牺牲空间复杂度为代价。但是,这两者之间没有必然的联系。因此,选项D
的说法是错误的。
(12)下列关于算法的时间复杂度陈述正确的是
A) 算法的时间复杂度是指执行算法程序所需要的时间
B) 算法的时间复杂度是指算法程序的长度C) 算法的时间复杂度是指算法执行过程中所需要的基本运算次数
D) 算法的时间复杂度是指算法程序中的指令条数
【答案】C
【解析】算法的时间复杂度是指执行算法所需要的计算工作量,也就是算法在执行过程中所执行的基本运算的次数,
而不是指程序运行需要的时间或是程序的长度。
(13)下列关于栈的叙述中正确的是
A)在栈中只能插入数据 B)在栈中只能删除数据
C)栈是先进先出的线性表 D)栈是先进后出的线性表
【答案】D
【解析】对栈可进行插入和删除数据的操作,但必须牢记插入和删除数据都只能是在栈顶,是一种特殊的线性表。
所以栈是先进后出的线性表。
(14)设有下列二叉树:
A
B C
FF
D E F
对此二叉树中序遍历的结果为
A)ABCDEF B)DAECF C)BDAECF D)DBEFCA
【答案】C
【解析】二叉树的遍历分为先序、中序、后序三种不同方式。本题要求中序遍历,其遍历顺序应该为:中序遍历左
子树->访问根结点->中序遍历右子树。按照定义,中序遍历序列是BDAECF,故答案为B。
(15)按照“后进先出”原则组织数据的数据结构是
A)队列 B)栈
C)双向链表 D)二叉树
【答案】B
【解析】“后进先出”表示最后被插入的元素最先能被删除。选项A中,队列是指允许在一端进行插入、而在另一端
进行删除的线性表,在队列这种数据结构中,最先插入的元素将最先能够被删除,反之,最后插入的元素将最后才
能被删除,队列又称为“先进先出”的线性表,它体现了“先来先服务”的原则:选项B中,栈顶元素总是最后被
插入的元素,从而也是最先能被删除的元素,栈底元素总是最先被插入的元素,从而也是最后才能被删除的元素。
队列和栈都属于线性表,它们具有顺序存储的特点,所以才有“先进先出”和“后进先出”的数据组织方式。
双向链表使用链式存储方式.二叉树也通常采用链式存储方式,它们的存储数据的空间可以是不连续的,各个数据
结点的存储顺序与数据元素之间的逻辑关系可以不一致。所以选项c和选项D错。
(16)下列叙述中正确的是
A)线性链表是线性表的链式存储结构
B)栈与队列是非线性结构C)双向链表是非线性结构
D)只有根结点的二叉树是线性结构
【答案】A
【解析】一个非空的数据结构如果满足下列两个条件:(1)有且只有一个根结点;(2)每一个结点最多有一个前件,也
最多有一个后件。则称为线性结构。线性链表是线性表的链式存储结构,选项 A的说法是正确的。栈与队列是特殊
的线性表,它们也是线性结构,选项B的说法是错误的;双向链表是线性表的链式存储结构,其对应的逻辑结构也
是线性结构,而不是非线性结构,选项 c的说法是错误的;二叉树是非线性结构,而不是线性结构,选项D的说法
是错误的。因此,本题的正确答案为A
(17)对如下二叉树
A
B C
D E F
进行后序遍历的结果为
A)ABCDEF B)DBEAFC
C)ABDECF D)DEBFCA
【答案】D
【解析】二叉树后序遍历的简单描述如下:若二叉树为空,则结束返回。否则(1)后序遍历左子树;(2)后序遍历右
子树;(3)访问根结点。也就是说,后序遍历是指在访问根结点、遍历左子树与遍历右子树这三者中,首先遍历左子
树,然后遍历右子树,最后访问根结点,并且,在遍历左、右子树时,仍然先遍历左子树,然后遍历右子树,最后
访问根结点。根据后序遍历的算法,后序遍历的结果为DEBFCA。
(18) 下列对队列的叙述正确的是( )
A)队列属于非线性表
B)队列按“先进后出”原则组织数据
C)队列在队尾删除数据
D)队列按“先进先出”原则组织数据
【答案】D
【解析】本题考查数据结构中队列的基本知识。队列是一种限定性的线性表,它只允许在表的一端插入元素,而在
另一端删除元素,所以队列具有先进先出的特性。在队列中,允许插入元素的一端叫做队尾,允许删除的一端则称
为队头。这与日常生活中的排队是一致的,最早进入队列的人最早离开,新来的人总是加入到队尾。因此,本题中
只有选项D的说法是正确的。
(19) 对下列二叉树进行前序遍历的结果为( )A) DYBEAFCZX B) YDEBFZXCA C) ABDYECFXZ D) ABCDEFXYZ
【答案】C
【解析】本题考查数据结构中二叉树的遍历。根据对二叉树根的访问先后顺序不同,分别称为前序遍历、中序遍历
和后序遍历。这三种遍历都是递归定义的,即在其子树中也按照同样的规律进行遍历。下面就是前序遍历方法的递
归定义。当二叉树的根不为空时,依次执行如下3个操作:
(1)访问根结点
(2)按先序遍历左子树
(3)按先序遍历右子树
根据如上前序遍历规则,来遍历本题中的二叉树。首先访问根结点,即 A,然后遍历A的左子树。遍历左子树同样
按照相同的规则首先访问根结点B,然后遍历B的左子树。遍历B的左子树,首先访问D,然后访问D的左子树,D
的左子树为空,接下来访问D的右子树,即Y。遍历完B的左子树后,再遍历B的右子树,即E。到此遍历完A的左
子树,接下来遍历A的右子树。按照同样的规则,首先访问C,然后遍历c的左子树。即F。c的左子树遍历完,接
着遍历c的右子树。首先访问右子树的根结点X,然后访问X的左子树,X的左子树,即Z,接下来访问X的右子树,
右子树为空。到此,把题目的二叉树进行了一次前序遍历。遍历的结果为ABDYECFXZ,故本题的正确答案为选项C。
(20) 某二叉树中有n个度为2的结点,则该二叉树中的叶子结点数为( )
A) n+1 B) n-1 C) 2n D) n/2
【答案】A
【解析】本题考查数据结构中二叉树的性质。 二叉树满足如下一条性质,即:对任意一棵二叉树,若终端结点(即
叶子结点)数为n,而其度数为2的结点数为n,则n=n+l。
o 2 0 2
根据这条性质可知,若二叉树中有n个度为2的结点,则该二叉树中的叶子结点数为n+l。因此,本题的正确答案是
选项A。
(22)下列叙述中正确的是
A)一个算法的空间复杂度大,则其时间复杂度也必定大
B)一个算法的空间复杂度大,则期时间复杂度必定小
C)一个算法的时间复杂度大,则其空间复杂度必定小
D)上述三种说法都不对
【答案】D
【解析】时间复杂度是指一个算法执行时间的相对度量;空间复杂度是指算法在运行过程中临时占用所需存储空间
大小的度量。人们都希望选择一个既省存储空间、又省执行时间的算法。然而,有时为了加快算法的运行速度,不
得不增加空间开销;有时为了能有效地存储算法和数据,又不得不牺牲运行时间。时间和空间的效率往往是一对矛
盾,很难做到两全。但是,这不适用于所有的情况,也就是说时间复杂度和空间复杂度之间虽然经常矛盾。但是二
者不存在必然的联系。因此,选项A、B、c的说法都是错误的。故本题的正确答案是D。
(23)在长度为64的有序线性表中进行顺序查找,最坏情况下需要比较的次数为A)63 B)64 C)6 D)7
【答案】B
【解析】在长度为 64的有序线性表中,其中的 64个数据元素是按照从大到小或从小到大的顺序排列有序的。在这
样的线性表中进行顺序查找,最坏的情况就是查找的数据元素不在线性表中或位于线性表的最后。按照线性表的顺
序查找算法,首先用被查找的数据和线性表的第一个数据元素进行比较。若相等,则查找成功,否则,继续进行比
较,即和线性表的第二个数据元素进行比较。同样,若相等,则查找成功,否则,继续进行比较。依次类推,直到
在线性表中查找到该数据或查找到线性表的最后一个元素,算法才结束。因此,在长度为64的有序线性表中进行顺
序查找,最坏的情况下需要比较64次。因此,本题的正确答案为B。
(24)对下列二叉树
进行中序遍历的结果是
A)ACBDFEG B)ACBDFGE
C)ABDCGEF D)FCADBEG
F
C E
A D G
B
【答案】A
【解析】二叉树的中序遍历递归算法为:如果根不空,则(1)按中序次序访问左子树;(2)访问根结点:(3)按中序次
序访问右子树。否则返回。本题中,根据中序遍历算法.应首先按照中序次序访问以 c为根结点的左子树,然后再
访问根结点F,最后才访问以E为根结点的右子树。遍历以c为根结点的左子树同样要遵循中序遍历算法,因此中序
遍历结果为ACBD;然后遍历根结点F;遍历以E为根结点的右子树,同样要遵循中序遍历算法,因此中序遍历结果
为EG。最后把这三部分的遍历结果按顺序连接起来,中序遍历结果为ACBDFEG。因此,本题的正确答案是A。
(25)数据的存储结构是指______。
A)存储在外存中的数据 B)数据所占的存储空间量
C)数据在计算机中的顺序存储方式 D)数据的逻辑结构在计算机中的表示
【答案】D
【解析】数据的逻辑结构在计算机存储空间中的存放形式称为数据的存储结构,也称数据的物理结构。所以选项D正
确。
(26)下列关于栈的描述中错误的是______。
A) 栈是先进后出的线性表
B) 栈只能顺序存储
C) 栈具有记忆作用
D) 对栈的插入与删除操作中,不需要改变栈底指针
【答案】B
【解析】本题考核栈的基本概念,我们可以通过排除法来确定本题的答案。栈是限定在一端进行插入与删除的线性
表,栈顶元素总是最后被插入的元素,从而也是最先能被删除的元素;栈底元素总是最先被插入的元素,从而也是最后才能被删除的元素,即栈是按照“先进后出”或“后进先出”的原则组织数据的,这便是栈的记忆作用,所以
选项A和选项C正确。对栈进行插入和删除操作时,栈顶位置是动态变化的,栈底指针不变,选项 D正确。由此可
见,选项B的描述错误。
(29)下列对于线性链表的描述中正确的是______。
A) 存储空间不一定是连续,且各元素的存储顺序是任意的
B) 存储空间不一定是连续,且前件元素一定存储在后件元素的前面
C) 存储空间必须连续,且前件元素一定存储在后件元素的前面
D) 存储空间必须连续,且各元素的存储顺序是任意的
【答案】A
【解析】在链式存储结构中,存储数据的存储空间可以不连续,各数据结点的存储顺序与数据元素之间的逻辑关系
可以不一致,数据元素之间的逻辑关系,是由指针域来确定的。由此可见,选项A的描述正确。
(1)线性表若采用链式存储结构时,要求内存中可用存储单元的地址
A)必须是连续的
B)部分地址必须是连续的
C)一定是不连续的
D)连续不连续都可以
解析: 在链式存储结构中,存储数据结构的存储空间可以是连续的,也可以是不连续的,各数据结点的存储顺序与
数据元素之间的逻辑关系可以不一致。故本题答案应该为选项D)
(2)在待排序的元素序列基本有序的前提下,效率最高的排序方法是
A)冒泡排序
B)选择排序
C)快速排序
D)归并排序
解析: 从平均时间性能而言,快速排序最佳,其所需时间最少,但快速排序在最坏情况下的时间性能不如堆排序和
归并排序。当序列中的记录基本有序或元素个数较少时,冒泡排序和简单选择排序为最佳排序方法,故本题答案应
该为选项A)。
(3)下列叙述中,错误的是
A)数据的存储结构与数据处理的效率密切相关
B)数据的存储结构与数据处理的效率无关
C)数据的存储结构在计算机中所占的空间不一定是连续的
D)一种数据的逻辑结构可以有多种存储结构
解析: 一般来说,一种数据结构根据需要可以表示成多种存储结构。常用的存储结构有顺序、链接、索引等,而采
用不同的存储结构,其数据处理的效率是不同的;一个数据结构中的各数据元素在计算机存储空间中的位置关系与
逻辑关系是有可能不同的。故本题答案应该为选项B)。
(4)希尔排序属于
A)交换排序B)归并排序
C)选择排序
D)插入排序
解析: 希尔排序的基本思想是把记录按下标的一定增量分组,对每组记录使用插入排序,随增量的逐渐减小,所分
成的组包含的记录越来越多,到增量的值减小到 1时,整个数据合成一组,构成一组有序记录,故其属于插入
排序方法。故本题答案应该为选项D)。
(1)栈和队列的共同特点是
A)都是先进先出
B)都是先进后出
C)只允许在端点处插入和删除元素
D)没有共同点
解析:栈和队列都是一种特殊的操作受限的线性表,只允许在端点处进行插入和删除。二者的区别是:栈只允许在
表的一端进行插入或删除操作,是一种“后进先出”的线性表;而队列只允许在表的一端进行插入操作,在另一端
进行删除操作,是一种“先进先出”的线性表。故本题答案应该为选项C)。
(2)已知二叉树后序遍历序列是dabec,中序遍历序列是debac,它的前序遍历序列是
A)acbed
B)decab
C)deabc
D)cedba
解析: 依据后序遍历序列可确定根结点为c;再依据中序遍历序列可知其左子树由deba构成,右子树为空;又由左
子树的后序遍历序列可知其根结点为 e,由中序遍历序列可知其左子树为 d,右子树由ba构成,如下图所示。求得
该二叉树的前序遍历序列为选项D)。
(3)链表不具有的特点是
A)不必事先估计存储空间
B)可随机访问任一元素
C)插入删除不需要移动元素
D)所需空间与线性表长度成正比
解析: 链表采用的是链式存储结构,它克服了顺序存储结构的缺点:它的结点空间可以动态申请和释放;它的数据
元素的逻辑次序靠结点的指针来指示,不需要移动数据元素。但是链式存储结构也有不足之处:① 每个结点中
的指针域需额外占用存储空间;② 链式存储结构是一种非随机存储结构。故本题答案应该为选项D)。
(6)算法的时间复杂度是指A)执行算法程序所需要的时间
B)算法程序的长度
C)算法执行过程中所需要的基本运算次数
D)算法程序中的指令条数
解析: 算法的复杂度主要包括算法的时间复杂度和算法的空间复杂度。所谓算法的时间复杂度是指执行算法所需要
的计算工作量;算法的空间复杂度一般是指执行这个算法所需要的内存空间。故本题答案应该为选项 A)。
(2)树是结点的集合,它的根结点数目是
A)有且只有1
B)1或多于1
C)0或1
D)至少2
解析: 树是一个或多个结点组成的有限集合,其中一个特定的结点称为根,其余结点分为若干个不相交的集合。每
个集合同时又是一棵树。树有且只有1个根结点。故本题答案应该为选项A)。
(3)如果进栈序列为e1,e2,e3,e4,则可能的出栈序列是
A)e3,e1,e4,e2
B)e2,e4,e3,e1
C)e3,e4,e1,e2
D)任意顺序
解析: 由栈"后进先出"的特点可知:A)中e1不可能比e2先出,C)中e3不可能比e4先出,且e1不可能比e2先
出,D)中栈是先进后出的,所以不可能是任意顺序。B)中出栈过程如图所示:
故本题答案应该为选项B)。
(4)在设计程序时,应采纳的原则之一是
A)不限制goto语句的使用
B)减少或取消注解行
C)程序越短越好
D)程序结构应有助于读者理解
解析:滥用goto 语句将使程序流程无规律,可读性差,因此A)不选;注解行有利于对程序的理解,不应减少或取
消,B)也不选;程序的长短要依照实际情况而论,而不是越短越好,C)也不选。故本题答案应该为选项D)。
(5)程序设计语言的基本成分是数据成分、运算成分、控制成分和
A)对象成分
B)变量成分
C)语句成分D)传输成分
解析: 程序设计语言是用于书写计算机程序的语言,其基本成分有以下4种,数据成分:用来描述程序中的数据。
运算成分:描述程序中所需的运算。控制成分:用来构造程序的逻辑控制结构。传输成分:定义数据传输成分,
如输入输出语言。故本题答案应该为选项 D)。
(1)循环链表的主要优点是
A)不再需要头指针了
B)从表中任一结点出发都能访问到整个链表
C)在进行插入、删除运算时,能更好的保证链表不断开
D)已知某个结点的位置后,能够容易的找到它的直接前件
解析: 循环链表就是将单向链表中最后一个结点的指针指向头结点,使整个链表构成一个环形,这样的结构使得从
表中的任一结点出发都能访问到整个链表。故本题答案应该为选项B)。
(3)对长度为N的线性表进行顺序查找,在最坏情况下所需要的比较次数为______。
A) N+1
B) N
C) (N+1)/2
D) N/2
解析:[答案]B,很简单,我们的二级程序设计语言书中都有此算法,另外还要掌握二分法查找,这也是我们二级中
常考的。那么二分法最坏的情况为多少次呢?log2 n的最小整数值。比如n为4,最坏的情况要比较3次;n为
18,最坏的情况要比较5次。
(1)下列叙述中正确的是
A)线性表是线性结构
B)栈与队列是非线性结构
C)线性链表是非线性结构
D)二叉树是线性结构
解析: 线性表是一种线性结构,数据元素在线性表中的位置只取决于它们自己的序号,即数据元素之间的相对位置
是线性的;栈、队列、线性链表实际上也是线性表,故也是线性结构;树是一种简单的非线性结构。故本题答案应
该为选项A)。
(3)已知数据表A中每个元素距其最终位置不远,为节省时间,应采用的算法是
A)堆排序
B)直接插入排序
C)快速排序
D)直接选择排序
解析: 当数据表A中每个元素距其最终位置不远,说明数据表A按关键字值基本有序,在待排序序列基本有序的情
况下,采用插入排序所用时间最少,故答案为选项B)。
(2)算法分析的目的是
A)找出数据结构的合理性
B)找出算法中输入和输出之间的关系C)分析算法的易懂性和可靠性
D)分析算法的效率以求改进
解析: 算法分析是指对一个算法的运行时间和占用空间做定量的分析,一般计算出相应的数量级,常用时间复杂度
和空间复杂度表示。分析算法的目的就是要降低算法的时间复杂度和空间复杂度,提高算法的执行效率。故本题答
案应该为选项D)。
(1)算法的空间复杂度是指
A)算法程序的长度
B)算法程序中的指令条数
C)算法程序所占的存储空间
D)执行过程中所需要的存储空间
解析: 算法的复杂度主要包括算法的时间复杂度和算法的空间复杂度。所谓算法的时间复杂度是指执行算法所需要
的计算工作量;算法的空间复杂度一般是指执行这个算法所需要的内存空间。故本题答案应该为选项 D)。
(3)数据结构中,与所使用的计算机无关的是数据的
A)存储结构
B)物理结构
C)逻辑结构
D)物理和存储结构
解析: 数据结构概念一般包括3个方面的内容,数据的逻辑结构、存储结构及数据上的运算集合。数据的逻辑结构
只抽象的反映数据元素之间的逻辑关系,而不管它在计算机中的存储表示形式。故本题答案应该为选项 C)。
(2)设有两个串p和q,求q在p中首次出现位置的运算称作
A)连接
B)模式匹配
C)求子串
D)求串长
解析: 子串的定位操作通常称作串的模式匹配,是各种串处理系统中最重要的操作之一,算法的基本思想是:从主
串的开始字符起和模式的第一个字符比较,若相等则继续比较后续字符,否则从主串的下一个字符起再重新和模式
的字符比较,依次类推,直至模式中的每一个字符依次和主串中的一个连续的字符序列相等,称匹配成功,否则称
匹配不成功。
(3)下列关于队列的叙述中正确的是______。
A. 在队列中只能插入数据
B. 在队列中只能删除数据
C. 队列是先进先出的线性表
D. 队列是先进后出的线性表
解析:C
队列是先进先出的,栈是先进后出的,2者的区别一定要搞清楚。
(1)算法的空间复杂度是指
A)算法程序的长度B)算法程序中的指令条数
C)执行算法程序所占的存储空间
D)算法执行过程中所需要的存储空间
【答案】D
【解析】算法的空间复杂度一般是指这个算法执行时所需要的内存空间,其中包括算法程序所占的空间、输入的初
始数据所占的存储空间以及算法执行过程中所需要的额外空间,其中额外空间还包括算法程序执行过程的工作单元
以及某种数据结构所需要的附加存储空间。
(2)线性表的链式存储结构是一种
A)随机结构
B)顺序结构
C)索引结构
D)散列结构
【答案】B
【解析】线性表的链式存储结构中的每一个存储结点不仅含有一个数据元素,还包括指针,每一个指针指向一个与
本结点有逻辑关系的结点。此类存储方式属于顺序存储。
(3)设有下列二叉树:对此二叉树先序遍历的结果是
A)ABCDEF
B)DBEAFC
C)ABDECF
D)DEBFCA
【答案】C
【解析】二叉树的遍历分为先序、中序、后序三种不同方式。本题要求先序遍历;遍历顺序应该为:访问根结点->
先序遍历左子树->先序遍历右子树。按照定义,先序遍历序列是ABDECF。
(3)已知数据表A中每个元素距其最终位置不远,为节省时间,应采用的算法是______。
A)堆排序 B)直接插入排序
C)快速排序 D)直接选择排序
答案:B
评析:当数据表A中每个元素距其最终位置不远,说明数据表 A按关键字值基本有序,在待排序序列基本有序的情
况下,采用插入排序所用时间最少,故答案为选项B。
(4)用链表表示线性表的优点是______。
A)便于插入和删除操作 B)数据元素的物理顺序与逻辑顺序相同
C)花费的存储空间较顺序存储少 D)便于随机存取
答案:A
评析:链式存储结构克服了顺序存储结构的缺点:它的结点空间可以动态申请和释放;它的数据元素的逻辑次序靠
结点的指针来指示,不需要移动数据元素。故链式存储结构下的线性表便于插入和删除操作。
5. 下列关于栈的叙述中正确的是______。
A、在栈中只能插入数据B、在栈中只能删除数据
C、栈是先进先出的线性表
D、栈是先进后出的线性表
解析:栈是限定在一端进行插入与删除的线性表。
栈是按照"先进后出"的或后进先出的原则组织数据的,因此,栈也被称为"先进后出"表或"后进先出"表。
本题答案是D。
7. 对长度为N的线性表进行顺序查找,在最坏情况下所需要的比较次数为______。
A、N+1
B、N
C、(N+1)/2
D、N/2
解析:在进行顺序查找过程中,如果线性表中被查的元素是线性表中的最后一个,或者被查元素根本不在线性表中,
则为了查找这个元素需要与线性表中所有元素进行比较,这是顺序查找最坏的情况。
本题答案为B。
1. 在一棵二叉树上第5层的结点数最多是______。
A、8
B、16
C、32
D、15
解析:根据二叉树的性质:二叉树第i(i≥1)层上至多有2i-1个结点。得到第5层的结点数最多是16。
本题答案为B。
7. 在下列选项中,哪个不是一个算法一般应该具有的基本特征______。
A、确定性
B、可行性
C、无穷性
D、拥有足够的情报
解析:作为一个算法,一般应具有以下几个基本特征。
1)可行性
2)确定性
3)有穷性
4)拥有足够的情报
本题答案为C。
5. 在计算机中,算法是指______。
A、查询方法
B、加工方法
C、解题方案的准确而完整的描述
D、排序方法
解析:计算机算法是指解题方案的准确而完整的描述,它有以下几个基本特征:可行性、确定性、有穷性和拥有足够
的情报。
本题答案为C。
7. 在单链表中,增加头结点的目的是______。
A、方便运算的实现B、使单链表至少有一个结点
C、标识表结点中首结点的位置
D、说明单链表是线性表的链式存储实现
解析:头结点不仅标识了表中首结点的位置,而且根据单链表(包含头结点)的结构,只要掌握了表头,就能够访问
整个链表,因此增加头结点目的是为了便于运算的实现。
本题答案为A。
1. 数据的存储结构是指______。
A、存储在外存中的数据
B、数据所占的存储空间量
C、数据在计算机中的顺序存储方式
D、数据的逻辑结构在计算机中的表示
解析:本题考查的是数据结构的基本概念。
数据的逻辑结构在计算机存储空间中的存放形式形式称为数据的存储结构(也称数据的物理结构)。
故本题答案为D。
2. 下列关于栈的描述中错误的是______。
A、栈是先进后出的线性表
B、栈只能顺序存储
C、栈具有记忆作用
D、对栈的插入与删除操作中,不需要改变栈底指针
解析:本题考查的是栈和队列。
栈是一种特殊的线性表,这种线性表只能在固定的一端进行插入和删除操作,允许插入和删除的一端称为栈顶,
另一端称为栈底。一个新元素只能从栈顶一端进入,删除时,只能删除栈顶的元素,即刚刚被插入的元素。所以栈
又称先进后出表(FILO-First In Last Out)。线性表可以顺序存储,也可以链式存储,而栈是一种线性表,也可
以采用链式存储结构。
故本题答案为B。
3. 对于长度为n的线性表,在最坏情况下,下列各排序法所对应的比较次数中正确的是______。
A、冒泡排序为n/2
B、冒泡排序为n
C、快速排序为n
D、快速排序为n(n-1)/2
解析:本题考查的是基本排序算法。
假设线性表的长度为n,则在最坏情况下,冒泡排序需要经过n/2遍的从前往后扫描和n/2遍的从后往前扫描,
需要比较次数为n(n-1)/2。快速排序法的最坏情况比较次数也是n(n-1)/2。
故本题答案为D。
4. 对长度为n的线性表进行顺序查找,在最坏情况下所需要的比较次数为______。
A、log2n
B、n/2
C、n
D、n+1
解析:本题考查的是顺序查找。
在进行顺序查找过程中,如果线性表中的第一个元素就是被查找元素,则只需做一次比较就查找成功,查找效率最高;但如果被查找的元素是线性表中的最后一个元素,或者被查找的元素根本就不在线性表中,则为了查找这
个元素需要与线性表中所有的元素进行比较,这是顺序查找的最坏情况。所以对长度为 n的线性表进行顺序查找,
在最坏情况下需要比较n次。
故本题答案为C。
5. 下列对于线性链表的描述中正确的是______。
A、存储空间不一定是连续,且各元素的存储顺序是任意的
B、存储空间不一定是连续,且前件元素一定存储在后件元素的前面
C、存储空间必须连续,且前件元素一定存储在后件元素的前面
D、存储空间必须连续,且各元素的存储顺序是任意的
解析:本题考查的是线性单链表、双向链表与循环链表的结构及其基本运算。
在链式存储结构中,存储数据结构的存储空间可以不连续,各数据结点的存储顺序与数据元素之间的逻辑关系
可以不一致,而数据元素之间的逻辑关系是由指针域来确定的。
故本题答案为A。
2. 下列叙述中正确的是______。
A、线性表是线性结构
B、栈与队列是非线性结构
C、线性链表是非线性结构
D、二叉树是线性结构
解析:根据数据结构中各数据元素之间前后间关系的复杂程度,一般将数据结构分为两大类型:线性结构与非线性结
构。
如果一个非空的数据结构满足下列两个条件:(1)有且只有一个根结点;(2)每一个结点最多有一个前件,
也最多有一个后件。则称该数据结构为线性结构,又称线性表。
所以线性表、栈与队列、线性链表都是线性结构,而二叉树是非线性结构。
本题答案是A。
3. 设一棵完全二叉树共有699个结点,则在该二叉树中的叶子结点数为______。
A、349
B、350
C、255
D、351
解析:所谓完全二叉树是指除最后一层外,每一层上的结点数均达到最大值;在最后一层上只缺少右边的若干结点。
具有n个结点的完全二叉树,其父结点数为int(n/2),而叶子结点数等于总结点数减去父结点数。本题n=699,
故父结点数等于int(699/2)=349,叶子结点数等于699-349=350。
本题答案是B。
2. 下列关于栈的叙述中正确的是______。
A、在栈中只能插入数据
B、在栈中只能删除数据
C、栈是先进先出的线性表
D、栈是先进后出的线性表
解析:栈是限定在一端进行插入与删除的线性表。
栈是按照"先进后出"的或后进先出的原则组织数据的,因此,栈也被称为"先进后出"表或"后进先出"表。
本题答案是D。3. 在深度为5的满二叉树中,叶子结点的个数为______。
A、32
B、31
C、16
D、15
解析:所谓满二叉树是指这样的一种二叉树:除最后一层外,每层上的所有结点都有两个子结点。这就是说,在满二
叉树中,每一层上的结点数都达到最大值,即在满二叉树的第K层上有2K-1个结点,且深度为m的满二叉树有2m个结
点。
在满二叉树中,最后一层的结点个数就是叶子结点的个数,本题中深度为 5,故叶子结点数为25-1=24=16。
本题答案是C。
2. 数据的存储结构是指______。
A、数据所占的存储空间量
B、数据的逻辑结构在计算机中的表示
C、数据在计算机中的顺序存储方式
D、存储在外存中的数据
解析:数据的逻辑结构在计算机存储空间中的存放形式称为数据的存储结构。
本题答案为B。
3. 设有下列二叉树:
A
B C
D E F
对此二叉树中序遍历的结果为______。
A、ABCDEF
B、DBEAFC
C、ABDECF
D、DEBFCA
解析:所谓中序遍历是指在访问根结点、遍历左子树与遍历右子树这三者中,首先遍历左子树,然后访问根结点,最
后遍历右子树;并且在遍历左、右子树时,仍然先遍历左子树,然后访问根结点,最后遍历右子树。
本题答案为B。
1. 在计算机中,算法是指______。
A、查询方法
B、加工方法
C、解题方案的准确而完整的描述
D、排序方法
解析:计算机算法是指解题方案的准确而完整的描述,它有以下几个基本特征:可行性、确定性、有穷性和拥有足够
的情报。
本题答案为C。2. 栈和队列的共同点是______。
A、都是先进后出
B、都是先进先出
C、只允许在端点处插入和删除元素
D、没有共同点
解析:栈和队列都是一种特殊的操作受限的线性表,只允许在端点处进行插入和删除。二者的区别是:栈只允许在表
的一端进行插入或删除操作,是一种"后进先出"的线性表;而队列只允许在表的一端进行插入操作,在另一端进行
删除操作,是一种"先进先出"的线性表。
本题答案为C。
3. 已知二叉树后序遍历序列是dabec,中序遍历序列是debac,它的前序遍历序列是______。
A、cedba
B、acbed
C、decab
D、deabc
解析:依据后序遍历序列可确定根结点为c;再依据中序遍历序列可知其左子树由deba构成,右子树为空;又由左子
树的后序遍历序列可知其根结点为e,由中序遍历序列可知其左子树为d,右子树由ba构成。求得该二叉树的前序
遍历序列为选项A。
本题答案为A。
1. 数据结构中,与所使用的计算机无关的是数据的______。
A、存储结构
B、物理结构
C、逻辑结构
D、物理和存储结构
解析:数据结构概念一般包括3个方面的内容,数据的逻辑结构、存储结构及数据上的运算集合。数据的逻辑结构只
抽象的反映数据元素之间的逻辑关系,而不管它在计算机中的存储表示形式。
本题答案为C。
2. 栈底至栈顶依次存放元素A、B、C、D,在第五个元素E入栈前,栈中元素可以出栈,则出栈序列可能是______。
A、ABCED
B、DBCEA
C、CDABE
D、DCBEA
解析: 栈操作原则是"后进先出",栈底至栈顶依次存放元素A、B、C、D,则表明这4个元素中 D是最后进栈,B、C
处于中间,A最早进栈。所以出栈时一定是先出D,再出C,最后出 A。
本题答案为D。
1. 下面叙述正确的是______。
A、算法的执行效率与数据的存储结构无关
B、算法的空间复杂度是指算法程序中指令(或语句)的条数
C、算法的有穷性是指算法必须能在执行有限个步骤之后终止
D、以上三种描述都不对
解析:算法的设计可以避开具体的计算机程序设计语言,但算法的实现必须借助程序设计语言中提供的数据类型及其算法。数据结构和算法是计算机科学的两个重要支柱。它们是一个不可分割的整体。算法在运行过程中需辅助存储
空间的大小称为算法的空间复杂度。算法的有穷性是指一个算法必须在执行有限的步骤以后结束。
本题答案为C。
2. 设一棵完全二叉树共有699个结点,则在该二叉树中的叶子结点数为______。
A、349
B、350
C、255
D、351
解析:所谓完全二叉树是指除最后一层外,每一层上的结点数均达到最大值;在最后一层上只缺少右边的若干结点。
具有n个结点的完全二叉树,其父结点数为int(n/2),而叶子结点数等于总结点数减去父结点数。本题n=699,
故父结点数等于int(699/2)=349,叶子结点数等于699-349=350。
本题答案是B。
9. 已知数据表A中每个元素距其最终位置不远,为节省时间,应采用的算法是______。
A、堆排序
B、直接插入排序
C、快速排序
D、直接选择排序
解析:当数据表A中每个元素距其最终位置不远,说明数据表A按关键字值基本有序,在待排序序列基本有序的情况
下,采用插入排序所用时间最少。
本题答案为B。
二、填空题
(1)问题处理方案的正确而完整的描述称为 _____ 。
【答案】算法或程序或流程图
【解析】算法是问题处理方案正确而完整的描述
(2)对长度为10的线性表进行冒泡排序,最坏情况下需要比较的次数为 ____ 。
【答案】45
【解析】在冒泡排序中,最坏情况下,需要比较的次数为n(n-1/2),也就是:10*(lO-1)/2=45
(3)算法复杂度主要包括时间复杂度和 ____ 复杂度。
【答案】空间
【解析】算法的复杂度主要包括时间复杂度和空间复杂度。所谓算法的时间复杂度,是指执行算法所需要的计算工
作量。一个算法的空间复杂度,一般是指执行这个算法所需要的内存空间。
(4)一棵二叉树第六层(根结点为第一层)的结点数最多为 _______个。
【答案】32
【解析】二叉树的一个性质是,在二叉树的第k层上,最多有2k-1(k≥1)个结点。此,26-1等于32。所以答案为32。
(5)数据结构分为逻辑结构和存储结构,循环队列属于______ 结构。
【答案】存储或物理或存储结构或物理结构
【解析】数据的逻辑结构在计算机存储空间中的存放形式称为数据的存储结构(也称数据的物理结构)。所谓循环队
列,就是将队列存储空间的最后一个位置绕到第一个位置,形成逻辑上的环状空间,供队列循环使用。可知,循环队列应当是物理结构。
(6)下列软件系统结构图的宽度为 ____ 。
A
B C D
E F
【答案】 3
【解析】题目中的图形是倒置的树状结构,这是用层次图表示的软件结构。结构图中同一层模块的最大模块个数称
为结构的宽度,它表示控制的总分布。根据上述结构图宽度的定义,从图中可以看出,第二层的模块个数最多,即
为3。因此,这个系统结构图的宽度就为3。
(7)按“先进后出”原则组织数据的数据结构是 ____ 。
【答案】栈或 Stack
【解析】栈和队列是两种特殊的线性表,其特殊性在于对它们的操作只能在表的端点进行。栈中的数据按照后进先
出的原则进行组织,而队列中的数据是按照先进先出的原则进行组织。因此,本题的正确答案是栈(Stack)。
(8)数据结构分为线性结构和非线性结构,带链的队列属于线性结构___ 。
【答案】
【解析】数据结构分为线性结构和非线性结构,其中队列是属于线性结构。队列有两种存储结构,一种是顺序存储
结构,称为顺序队列;另一种是链式存储结构,称为链队列。题目中所说的带链的队列就是指链队列。无论队列采
取哪种存储结构,其本质还是队列,还属于一种线性结构。因此,本题的正确答案是线性结构。
(9) 在深度为7的满二叉树中,度为2的结点个数为_______。
【答案】63或26-1
【解析】本题考查数据结构中满二叉树的性质。在满二叉树中,每层结点都是满的,即每层结点都具有最大结点数。
深度为k的满二叉树,一共有2k-1个结点,其中包括度为2的结点。因此,深度为7的满二叉树,一共有27-1个结
点,即127个结点。
根据二叉树的另一条性质,对任意一棵二叉树,若终端结点(即叶子结点)数为n,而其度数为2的结点数为n 则
0 2
n=n+1。设尝试为7的满二叉树中,度为2的结点个数为x,则改树中中子结点的个数为x+1。则应满足x+(x+1)=127,
0 2
解该方程得到,x的值为63。
结果上述分析可知,在深度为7的满二叉树中,度为2的结点个数为63。
(10) 线性表的存储结构主要分为顺序存储结构和链式存储结构。队列是一种特殊的线性表,循环队列是队列的_____
存储结构。
【答案】顺序
【解析】本题考查数据结构的队列。队列是一种特殊的线性表,即限定在表的一端进行删除,在表的另一端进行插
入操作的线性表。允许删除的一端叫做队头,允许插入的一端叫做队尾。线性表的存储结构主要分为顺序存储结构
和链式存储结构。当队列用链式存储结构实现时,就称为链队列;当队列用顺序存储结构实现时,就称为循环表。
因此,本题划线处应填入“顺序”。
(11) 对下列二叉树进行中序遍历的结果为 ____ 。【答案】ACBDFEHGP
【解析】本题考查数据结构中二叉树的遍历。根据对二叉树根的访问先后顺序不同,分别称为前序遍历、中序遍历
和后序遍历。这三种遍历都是递归定义的,即在其子树中也按照同样的规律进行遍历。下面就是中序遍历方法的递
归定义。
当二叉树的根不为空时,依次执行如下3个操作:
(1)按中序遍历左子树。
(2)访问根结点。
(3)按中序遍历右子树。
根据如上前序遍历规则,来遍历本题中的二叉树。首先遍历F的左子树,同样按中序遍历。先遍历C的左子树,即
结点A,然后访问c,接着访问c的右子树,同样按中序遍历c的右子树,先访问结点B,然后访问结点D,因为结
点D没有右子树,因此遍历完C的右子树,以上就遍历完根结点F的左子树。然后访问根结点F,接下来遍历F的右
子树.同样按中序遍历。首先访问E的左子树,E的左子树为空,则访问结点E,然后访问结点E的右子树,同样按
中序遍历。首先访问G的左子树,即H,然后访问结点G,最后访问G的右子树P。以上就把整个二叉树遍历一遍,
中序遍历的结果为ACBDFEHGP。因此.划线处应填入“ACBDFEHGP”。
(11)用链表表示线性表的突出优点是 。
答案:插入和删除操作方便,不必移动数据元素,执行效率高
解析: 为了克服顺序表中插入和删除时需要移动大量数据元素的缺点,引入了链式存储结构。链表表示线性表的突
出优点是插入和删除操作方便,不必移动数据元素,执行效率高。
(11)算法的基本特征是可行性、确定性、 和拥有足够的情报。
答案:有穷性
解析: 算法是指解题方案的准确而完整的描述。它有4个基本特征,分别是可行性、确定性、有穷性和拥有足够的
情报。
(12)在长度为n的有序线性表中进行二分查找。最坏的情况下,需要的比较次数为 。
答案:log2n
解析: 对于长度为n的有序线性表,在最坏情况下,二分查找只需要比较log2n次,而顺序查找需要比较n次。
(11)数据结构分为逻辑结构与存储结构,线性链表属于 存储结构 。
答案:
解析: 数据的逻辑结构是指反映数据元素之间逻辑关系的数据结构;数据的存储结构是指数据的逻辑结构在计算机
存储空间中的存放形式。在数据的存储结构中,不仅要存放各数据元素的信息,还需要存放各数据元素之间的前后
件关系的信息。
(11)冒泡排序算法在最好的情况下的元素交换次数为 0 。答案:0
解析: 根据冒泡排序算法思想可知,若待排序的初始序列为“正序”序列,则只需进行一趟排序,在排序过程中进
行n-1次关键字间的比较,且不移动和交换记录,这种情况是冒泡排序的最好情况,故冒泡排序算法在最好的情况
下的元素交换次数为0。
(12)在最坏情况下,堆排序需要比较的次数为 。
答案:O(nlog2n)
(13)若串s="MathTypes",则其子串的数目是 。
答案:46
解析: 串s中共有9个字符,由于串中字符各不相同,则其子串中有0个字符的1个(空串),1个字符的9个,2
个字符的8个,3个字符的7个,4个字符的6个,5个字符的5个,6个字符的4个,7个字符的3个,8个字符的
2个,9个字符的1个,共有1+2+3+4+5+6+7+8+9+1=46。
(11)在算法正确的前提下,评价一个算法的两个标准是 。
答案:时间复杂度和空间复杂度
(12)将代数式 转换成程序设计中的表达式为 。
答案:(x+y*y)/(a+b)
(11)数据的逻辑结构有线性结构和 两大类。
答案:非线性结构
解析: 数据的逻辑结构有线性结构和非线性结构两大类。
(11)当线性表采用顺序存储结构实现存储时,其主要特点是 。
答案:逻辑结构中相邻的结点在存储结构中仍相邻
解析: 顺序存储结构的主要特点是数据元素按线性表的逻辑次序,依次存放在一组地址连续的存储单元中。在存储
单元中各元素的物理位置和逻辑结构中各结点间的相邻关系是一致的。
52. 设一棵完全二叉树共有500个结点,则在该二叉树中有______个叶子结点。
解析:所谓完全二叉树是指除最后一层外,每一层上的结点数均达到最大值;在最后一层上只缺少右边的若干结点。
具有n个结点的完全二叉树,其父结点数为int(n/2),而叶子结点数等于总结点数减去父结点数。本题n=500,
故父结点数等于int(500/2)=250,叶子结点数等于500-250=250。
标准答案为:250
51. 算法的基本特征是可行性、确定性、______和拥有足够的情报。
解析:算法是指解题方案的准确而完整的描述。它有4个基本特征,分别是可行性、确定性、有穷性和拥有足够的情
报。
标准答案为:有穷性
52. 顺序存储方法是把逻辑上相邻的结点存储在物理位置______的存储单元中。
解析:常用的存储表示方法有4种,顺序存储、链式存储、索引存储、散列存储。其中,顺序存储方法是把逻辑上相
邻的结点存储在物理位置也相邻的存储单元中。
标准答案为:相邻(1)算法的复杂度主要包括空间复杂度和【时间1】复杂度。
【答案】时间
【解析】算法的复杂度主要指时间复杂度和空间复杂度。
(2)在线性结构中,队列的操作顺序是先进先出,而栈的操作顺序是【2】 。
【答案】先进后出
【解析】队列和栈都是线性结构,但是不同之处在于队列的操作顺序是先进先出,而栈的操作顺序是先进后出。
(2)在最坏情况下,堆排序需要比较的次数为 【2】 。
答案:O(nlogn)
2
评析:在最坏情况下,冒泡排序所需要的比较次数为n(n-1)/2;简单插入排序所需要的比较次数为n(n-1)/2;希尔
排序所需要的比较次数为O(n1.5);堆排序所需要的比较次数为O(nlogn)。
2
(3)若串s="Program",则其子串的数目是 【3】 。
答案:29
评析:串 s中共有7个字符,由于串中字符各不相同,则其子串中有 0个字符的 1个(空串),1 个字符的7个,2
个字符的 6 个,3 个字符的 5 个,4 个字符的 4 个,5 个字符的 3 个,6 个字符的 2 个,7 个字符的 1 个,共有
1+2+3+4+5+6+7+1=29。
51. 实现算法所需的存储单元多少和算法的工作量大小分别称为算法的 ______。
解析:算法的复杂性是指对一个在有限步骤内终止算法和所需存储空间大小的估计。算法所需存储空间大小是算法的
空间复杂性,算法的计算量是算法的时间复杂性。
标准答案为:空间复杂度和时间复杂度
52. 数据结构包括数据的逻辑结构、数据的 ______以及对数据的操作运算。
解析:数据结构包括3个方面,即数据的逻辑结构、数据的存储结构及对数据的操作运算。
标准答案为:存储结构
53在最坏情况下,冒泡排序的时间复杂度为______。
解析:冒泡排序法是一种最简单的交换类排序方法,它是通过相邻数据元素的交换逐步将线性表变成有序。
假设线性表的长度为n,则在最坏的情况下,冒泡排序需要经过n/2遍的从前往后的扫描和n/2遍的从后往前的
扫描,需要的比较次数为n(n-1)/2。
标准答案为:n(n-1)/2 或 n*(n-1)/2 或 O(n(n-1)/2) 或 O(n*(n-1)/2)
54. 顺序存储方法是把逻辑上相邻的结点存储在物理位置______的存储单元中。
解析:常用的存储表示方法有4种,顺序存储、链式存储、索引存储、散列存储。其中,顺序存储方法是把逻辑上相
邻的结点存储在物理位置也相邻的存储单元中。
标准答案为:相邻
52. 在先左后右的原则下,根据访问根结点的次序,二叉树的遍历可以分为三种:前序遍历、______遍历和后序遍
历。
标准答案为:中序
解析: 在先左后右的原则下,根据访问根结点的次序,二叉树的遍历可以分为三种:前序遍历、中序遍历和后序遍
历。
前序遍历是指在访问根结点、遍历左子树与遍历右子树这三者中,首先访问根结点,然后遍历左子树,最后遍
历右子树;并且遍历左、右子树时,仍然先访问根结点,然后遍历左子树,最后遍历右子树。中序遍历指在访问根结点、遍历左子树与遍历右子树这三者中,首先遍历左子树,然后访问根结点,最后遍历
右子树;并且遍历左、右子树时,仍然先遍历左子树,然后访问根结点,最后遍历右子树。
后序遍历指在访问根结点、遍历左子树与遍历右子树这三者中,首先遍历右子树,然后访问根结点,最后遍历左
子树;并且遍历左、右子树时,仍然先遍历右子树,然后访问根结点,最后遍历左子树。
55. 数据结构包括数据的逻辑结构、数据的 ______以及对数据的操作运算。
标准答案为:存储结构
解析: 数据结构包括3个方面,即数据的逻辑结构、数据的存储结构及对数据的操作运算。
51. 某二叉树中度为2的结点有18个,则该二叉树中有 个叶子结点。
标准答案为:19
解析:本题考查的是二叉树的定义及其存储结构。
二叉树的性质3:在任意一棵二叉树中,度为0的结点(即叶子结点)总是比度为2的结点多一个。本题中度为2的
结点数为18,故叶子结点数为18+1=19个。
55. 问题处理方案的正确而完整的描述称为 。
标准答案为:算法 本题考查的是算法的基本概念。
解析:所谓算法是指解题方案的准确而完整的描述。
51. 在先左后右的原则下,根据访问根结点的次序,二叉树的遍历可以分为三种:前序遍历、______遍历和后序遍
历。
标准答案为:中序
解析:在先左后右的原则下,根据访问根结点的次序,二叉树的遍历可以分为三种:前序遍历、中序遍历和后序遍历。
前序遍历是指在访问根结点、遍历左子树与遍历右子树这三者中,首先访问根结点,然后遍历左子树,最后遍
历右子树;并且遍历左、右子树时,仍然先访问根结点,然后遍历左子树,最后遍历右子树。
中序遍历指在访问根结点、遍历左子树与遍历右子树这三者中,首先遍历左子树,然后访问根结点,最后遍历
右子树;并且遍历左、右子树时,仍然先遍历左子树,然后访问根结点,最后遍历右子树。
后序遍历指在访问根结点、遍历左子树与遍历右子树这三者中,首先遍历右子树,然后访问根结点,最后遍历左
子树;并且遍历左、右子树时,仍然先遍历右子树,然后访问根结点,最后遍历左子树。
51. 设一棵完全二叉树共有500个结点,则在该二叉树中有______个叶子结点。
标准答案为:250
解析:所谓完全二叉树是指除最后一层外,每一层上的结点数均达到最大值;在最后一层上只缺少右边的若干结点。
具有n个结点的完全二叉树,其父结点数为int(n/2),而叶子结点数等于总结点数减去父结点数。本题n=500,
故父结点数等于int(500/2)=250,叶子结点数等于500-250=250。
52. 在最坏情况下,冒泡排序的时间复杂度为______。
标准答案为:n(n-1)/2 或 n*(n-1)/2 或 O(n(n-1)/2) 或 O(n*(n-1)/2)
解析:冒泡排序法是一种最简单的交换类排序方法,它是通过相邻数据元素的交换逐步将线性表变成有序。
假设线性表的长度为n,则在最坏的情况下,冒泡排序需要经过n/2遍的从前往后的扫描和n/2遍的从后往前的
扫描,需要的比较次数为n(n-1)/2。
第二章 程序设计基础
一、选择题
(1)下列叙述中正确的是A)程序设计就是编制程序 B)程序的测试必须由程序员自己去完成
C)程序经调试改错后还应进行再测试 D)程序经调试改错后不必进行再测试
【答案】C
【解析】软件测试仍然是保证软件可靠性的主要手段,测试的目的是要尽量发现程序中的错误,调试主要是推断错
误的原因,从而进一步改正错误。测试和调试是软件测试阶段的两个密切相关的过程,通常是交替进行的。选
项C正确。
(2)下面描述中,不符合结构化程序设计风格的是
A)使用顺序、选择和重复(循环)三种基本控制结构表示程序的控制逻辑
B)注重提高程序的可读性
D)使用goto语句
【答案】 D
【解析】在结构化程序设计中,应严格控制使用GOTO语句,必要时才可以使用,故答案为D。
(3)在面向对象设计中,对象有很多基本特点,其中“从外面看只能看到对象的外部特性,而对象的内部对外是不可
见的”这一性质指的是对象的
A)分类性B)标识惟一性C)多态性D)封装性
【答案】D
【解析】从外面看只能看到对象的外部特性,而对象的内部,即处理能力的实行和内部状态,指的是对象的封装性。
(4)结构化程序设计的一种基本方法是
A)筛选法B)递归法C)归纳法D)逐步求精法
【答案】D
【解析】在结构化程序设计中通常采取自上而下、逐步求精的方法,其总的思想是先全局后局部、先整体后细节、
先抽象后具体。而筛选法、递归法和归纳法指的都是程序的某种具体算法。
(5)函数重载是指
A)两个或两个以上的函数取相同的函数名,但形参的个数或类型不同
B)两个以上的函数取相同的名字和具有相同的参数个数,但形参的类型可以不同
C)两个以上的函数名字不同,但形参的个数或类型相同
D)两个以上的函数取相同的函数名,并且函数的返回类型相同
【答案】A
【解析】函数重载指的是两个或两个以上的函数具有相同的函数名,但形参的个数或类型不同。程序中通过判断主
调函数传过来的参数的个数和类型,来决定选择调用哪个具体的函数。
(6)下列选项中不符合良好程序设计风格的是
A)源程序要文档化
B)数据说明的次序要规范化
C)避免滥用goto 语
D)模块设计要保证高耦合、高内聚
【答案】D
【解析】编程风格是在不影响性能的前提下,有效地编排和组织程序,以提高可读性和可维护性。更直接的说,风格就是意味着要按照规则进行编程。这些规则包括:程序文档化。就是程序文档包含恰当的标识符.适当的注解和
程序的视觉组织等。(2)数据说明。出于阅读理解和维护的需要,最好使模块前的说明语句次序规范化。此外,为
方便查找,在每个说明语句的说明符后,数据名应按照字典顺序排列。(3)功能模块化。即把源程序代码按照功能划
分为低耦合、高内聚的模块。(4)注意goto语句的使用。合理使用goto语句可以提高代码的运行效率.但goto语
句的使用会破坏程序的结构特性。因此,除非确实需要,否则最好不使用 goto语,因此,本题的正确答案是D。
(7) 在结构化程序设计中,模块划分的原则是( )
A)各模块应包括尽量多的功能
B)各模块的规模应尽量大
C)各模块之间的联系应尽量紧密
D)模块内具有高内聚度、模块间具有低耦合度
【答案】D
【解析】本题考查软件工程中软件设计的概念和原理。人们在开发计算机软件的长期实践中积累了丰富的经验,总
结这些经验得到如下的启发式规则:
1.改进软件结构,提高模块独立性。通过模块的分解或合并,力求降低耦合提高内聚。低耦合也就是降低不同模块
间相互依赖的紧密程度,高内聚是提高一个模块内各元素彼此结合的紧密程度。
2.模块的规模应适中。一个模块的规模不应过大,过大的模块往往是由于分解不够充分;过小的模块开销大于有益
操作,而且模块过多将使系统接口复杂。因此过小的模块有时不值得单独存在。
3.模块的功能应该可以预测,但也要防止模块功能过分局限。如果模块包含的功能太多,则不能体现模块化设计的
特点;如果模块的功能过分的局限,使用范围就过分狭窄。
经过上述分析,本题的正确答案是选项D。
(8) 下面选项中不属于面向对象程序设计特征的是( )
A)继承性 B)多态性 C)类比性 D)封装性
【答案】C
【解析】通常认为,面向对象方法具有封装性、继承性、多态性几大特点。就是这几大特点,为软件开发提供了一
种新的方法学。
封装性:所谓封装就是将相关的信息、操作与处理融合在一个内含的部件中(对象中)。简单地说,封装就是隐藏信
息。这是面向对象方法的中心,是面向对象程序设计的基础。
继承性:子类具有派生它的类的全部属性(数据)和方法,而根据某一类建立的对象也都具有该类的全部,这就是继
承性。继承件自动在类与子类间共享功能与数据,当某个类作了某项修改,其子类会自动改变,子类会继承其父类
所有特性与行为模式,继承有利于提高软件开发效率,容易达到一致性。
多态性:多态性就是多种形式。不同的对象在接收到相同的消息时,采用不同的动作。例如,一个应用程序包括许
多对象,这些对象也许具有同一类型的工作,但是却以不同的做法来实现。不必为每个对象的过程取一过程名,造
成复杂化,可以使过程名复用。同一类型的工作有相同的过程名,这种技术称为多态性。
经过上述分析可知,选项C的说法是错误的。
(9) 在面向对象方法中,实现信息隐蔽是依靠( )
A)对象的继承 B)对象的多态
C)对象的封装 D)对象的分类【答案】c
【解析】通常认为,面向对象方法具有封装性、继承性、多态性几大特点。就是这几大特点,为软件开发提供了一
种新的方法学。
封装性:所谓封装就是将相关的信息、操作与处理融合在一个内含的部件中(对象中)。简单地说,封装就是隐藏
信息。这是面向对象方法的中心,也是面向对象程序设计的基础。
继承性:子类具有派生它的类的全部属性(数据)和方法,而根据某一类建立的对象也都具有该类的全部,这就是继
承性。继承性自动在类与子类间共享功能与数据,当某个类作了某项修改,其子类会自动改变,子类会继承其父类
所有特性与行为模式。继承有利于提高软件开发效率,容易达到一致性。
多态性;多态性就是多种形式。不同的对象在接收到相同的消息时,采用不同的动作。例如,一个应用程序包括许
多对象,这些对象也许具有同一类型的工作.但是却以不同的做法来实现。不必为每个对象的过程取一过程名,造
成复杂化,可以使过程名复用。同一类型的工作有相同的过程名,这种技术称为多态性。
经过上述分析可知,在面向对象方法中,实现信息隐蔽是依靠对象的封装。正确答案是选项c。
(10) 下列叙述中,不符合良好程序设计风格的是( )
A)程序的效率第一,清晰第二 B)程序的可读性好
C)程序中有必要的注释 D)输入数据前要有提示信息
【答案】A
【解析】本题考查软件工程的程序设计风格。软件在编码阶段,力求程序语句简单、直接,不能只为了追求效率而
使语句复杂化。除非对效率有特殊的要求,程序编写要做到清晰第一、效率第二。
人们在软件生存期要经常阅读程序,特别是在软件测试和维护阶段,编写程序的人和参与测试、维护的人都要阅读
程序,因此要求程序的可读性要好。
正确的注释能够帮助读者理解程序,可为后续阶段进行测试和维护提供明确的指导。所以注释不是可有可无的,而
是必须的,它对于理解程序具有重要的作用。
I/O信息是与用户的使用直接相关的,因此它的格式应当尽可能方便用户的使用。在以交互式进行输入/输出时,
要在屏幕上使用提示符明确提示输入的请求,指明可使用选项的种类和取值范围。
经过上述分析可知,选项A是不符合良好程序设计风格要求的。
(11)结构化程序设计的3种结构是
A)顺序结构、选择结构、转移结构
B)分支结构、等价结构、循环结构
C)多分支结构、赋值结构、等价结构
D)顺序结构、选择结构、循环结构
解析: 顺序结构、选择结构和循环结构(或重复结构)是结构化程序设计的3种基本结构。故本题答案应该为选项
D)。
(12)在结构化程序设计思想提出之前,在程序设计中曾强调程序的效率,现在,与程序的效率相比,人们更重视
程序的
A)安全性
B)一致性
C)可理解性D)合理性
答案:C
(13)对建立良好的程序设计风格,下面描述正确的是
A)程序应简单、清晰、可读性好
B)符号名的命名只要符合语法
C)充分考虑程序的执行效率
D)程序的注释可有可无
解析: 程序设计应该简单易懂,语句构造应该简单直接,不应该为提高效率而把语句复杂化。故本题答案应该为选
项A)。
(14)结构化程序设计主要强调的是
A)程序的规模
B)程序的效率
C)程序设计语言的先进性
D)程序易读性
解析: 结构化程序设计方法的主要原则可以概括为自顶向下、逐步求精、模块化及限制使用 goto语句,总的来说
可使程序结构良好、易读、易理解、易维护。故本题答案应该为选项D)。
(15)对象实现了数据和操作的结合,是指对数据和数据的操作进行
A)结合
B)隐藏
C)封装
D)抽象
解析: 对象是由数据及可以对这些数据施加的操作组成的统一体。对象的内部,即处理能力的实行和内部状态,对
外是看不见的,这一特性称做对象的封装。故本题答案应该为选项C)。
(4)编制一个好的程序,首先要保证它的正确性和可靠性,还应强调良好的编程风格,在书写功能性注释时应考虑
A)仅为整个程序作注释
B)仅为每个模块作注释
C)为程序段作注释
D)为每个语句作注释
【答案】C
【解析】功能性注释是嵌在源程序体中的,用以描述其后的语句或程序段是在做什么工作,或者执行了下面的语句
会怎么样。所以它描述的是一段程序,是为程序段做注释,而不是每条语句。
(5)下列哪个是面向对象程序设计不同于其他语言的主要特点?
A)继承性
B)消息传递
C)多态性
D)静态联编
【答案】A【解析】继承是一个子类直接使用父类的所有属性和方法。它可以减少相似的类的重复说明,从而体现出一般性与
特殊性的原则,这使得面向对象程序设计语言有了良好的重用性,也是其不同于其他语言的主要特点。
3. 结构化程序设计主要强调的是______。
A、程序的规模
B、程序的易读性
C、程序的执行效率
D、程序的可移植性
解析:结构化程序设计主要强调的是结构化程序清晰易读,可理解性好,程序员能够进行逐步求精、程序证明和测试,
以保证程序的正确性。
本题答案为B。
2. 下面概念中,不属于面向对象方法的是______。
A、对象
B、继承
C、类
D、过程调用
解析:面向对象方法是一种运用对象、类、封装、继承、多态和消息等概念来构造、测试、重构软件的方法。面向对
象方法从对象出发,发展出对象,类,消息,继承等概念。
本题答案为D。
3. 面向对象的设计方法与传统的的面向过程的方法有本质不同,它的基本原理是______。
A、模拟现实世界中不同事物之间的联系
B、强调模拟现实世界中的算法而不强调概念
C、使用现实世界的概念抽象地思考问题从而自然地解决问题
D、鼓励开发者在软件开发的绝大部分中都用实际领域的概念去思考
解析:面向对象的设计方法与传统的的面向过程的方法有本质不同,它的基本原理是,使用现实世界的概念抽象地思
考问题从而自然地解决问题。它强调模拟现实世界中的概念而不强调算法,它鼓励开发者在软件开发的绝大部分中
都用应用领域的概念去思考。
本题答案为C。
4. 对建立良好的程序设计风格,下面描述正确的是______。
A、程序应简单、清晰、可读性好
B、符号名的命名要符合语法
C、充分考虑程序的执行效率
D、程序的注释可有可无
解析:要形成良好的程序设计风格,主要应注重和考虑下述一些因素:符号名的命名应具有一定的实际含义,以便于
对程序功能的理解;正确的注释能够帮助读者理解程序;程序编写应优先考虑清晰性,除非对效率有特殊要求,程
序编写要做到清晰第一,效率第二。
本题答案为A。
5. 下面对对象概念描述错误的是______。
A、任何对象都必须有继承性
B、对象是属性和方法的封装体
C、对象间的通讯靠消息传递
D、操作是对象的动态性属性解析:对象是由数据和容许的操作组成的封装体,与客观实体有直接的对应关系。对象之间通过传递消息互相联系,
以模拟现实世界中不同事物彼此之间的联系。
本题答案为A。
4. 在面向对象方法中,一个对象请求另一对象为其服务的方式是通过发送______。
A、调用语句
B、命令
C、口令
D、消息
解析:面向对象的世界是通过对象与对象间彼此的相互合作来推动的,对象间的这种相互合作需要一个机制协助进
行,这样的机制称为消息。消息是一个实例与另一个实例之间传递的信息,它请求对象执行某一处理或回答某一要
求的信息,它统一了数据流和控制流。
本题答案为D。
5. 在设计程序时,应采纳的原则之一是______。
A、程序结构应有助于读者理解
B、不限制goto语句的使用
C、减少或取消注解行
D、程序越短越好
解析:滥用goto语句将使程序流程无规律,可读性差;添加的注解行有利于对程序的理解,不应减少或取消;程序
的长短要依照实际需要而定,并不是越短越好。
本题答案为A。
3. 对建立良好的程序设计风格,下面描述正确的是______。
A、程序应简单、清晰、可读性好
B、符号名的命名要符合语法
C、充分考虑程序的执行效率
D、程序的注释可有可无
解析:要形成良好的程序设计风格,主要应注重和考虑下述一些因素:符号名的命名应具有一定的实际含义,以便于
对程序功能的理解;正确的注释能够帮助读者理解程序;程序编写应优先考虑清晰性,除非对效率有特殊要求,程
序编写要做到清晰第一,效率第二。
本题答案为A。
二、填空题
(1)在面向对象方法中, ______描述的是具有相似属性与操作的一组对象。
【答案】类
【解析】在面向对象方法中,类描述的是具有相似属性与操作的一组对象。
(2)在面向对象方法中,类的实例称为 ______。
【答案】对象
【解析】类描述的是具有相似性质的一组对象。例如,每本具体的书是一个对象,而这些具体的书都有共同的性质,
它们都属于更一般的概念“书”这一类对象。一个具体对象称为类的实例。
(3)子程序通常分为两类: 和函数,前者是命令的抽象,后者是为了求值。
答案:过程
解析: 当程序之间发生调用关系时,调用命令所在的代码段被称为主程序,被调用的代码段被称为子程序。子程序是对功能的抽象,可分为过程和函数两类,两者的区别是函数是通过函数名来返回值的,而过程只能通过形式参数
或对全局变量进行修改以返回值。
(4)在面向对象的程序设计中,类描述的是具有相似性质的一组 。
答案:对象
解析: 将属性、操作相似的对象归为类,也就是说,类是具有共同属性、共同方法的对象的集合。
(5)在面向对象方法中,类之间共享属性和操作的机制称为 。
答案:继承
解析: 类是面向对象语言中必备的程序语言结构,用来实现抽象数据类型。类与类之间的继承关系实现了类之间的
共享属性和操作,一个类可以在另一个已定义的类的基础上定义,这样使该类型继承了其超类的属性和方法,当然,
也可以定义自己的属性和方法。
(6)在面向对象的设计中,用来请求对象执行某一处理或回答某些信息的要求称为 。
答案:消息
解析:在面向对象技术中,主要用到对象(object)、类(class)、方法(method)、消息(message)、继承(inheritance)、
封装(encapsulation)等基本概念。其中消息是用来请求对象执行某一处理或回答某些信息的要求。
(7)一个类可以从直接或间接的祖先中继承所有属性和方法。采用这个方法提高了软件的 。
答案:可重用性
解析:本题考查了继承的优点:相似的对象可以共享程序代码和数据结构,从而大大减少了程序中的冗余,提高软
件的可重用性。
53. 一个类可以从直接或间接的祖先中继承所有属性和方法。采用这个方法提高了软件的______。
解析:继承的优点:相似的对象可以共享程序代码和数据结构,从而大大减少了程序中的冗余,提高软件的可重用性。
标准答案为:可重用性 或 重用性 或 复用性 或 可复用性
54. 面向对象的模型中,最基本的概念是对象和 ______。
解析:面向对象模型中,最基本的概念是对象和类。对象是现实世界中实体的模型化;将属性集和方法集相同的所有
对象组合在一起,可以构成一个类。
标准答案为:类
54. 在面向对象方法中,信息隐蔽是通过对象的______性来实现的。
解析:软件工程的基本原则包括抽象、信息隐蔽、模块化、局部化、确定性、一致性、完备性和可验证性。
信息隐蔽是指采用封装技术,将程序模块的实现细节隐藏起来,使模块接口尽量简单。
标准答案为:封装
51. 面向对象的程序设计方法中涉及的对象是系统中用来描述客观事物的一个______。
解析:面向对象的程序设计方法中涉及的对象是系统中用来描述客观事物的一个实体,是构成系统的一个基本单位,
它由一组表示其静态特征的属性和它可执行的一组操作组成。
标准答案为:实体
52. 在面向对象方法中,类的实例称为 。
标准答案为:对象
解析:本题考查的是面向对象方法的基本概念。
将属性、操作相似的对象归为类,也就是说,类是具有共同属性、共同方法的对象的集合。所以,类是对象的
抽象,它描述了属于该对象类型的所有对象的性质,而一个对象则是其对应类的一个实例。52. 结构化程序设计方法的主要原则可以概括为自顶向下、逐步求精、______和限制使用goto语句。
标准答案为:模块化
解析:结构化程序设计方法的主要原则可以概括为自顶向下、逐步求精、模块化和限制使用goto语句。
自顶向下:程序设计时,应先考虑总体,后考虑细节;先考虑全局目标,后考虑局部目标。不要一开始就过多
追求众多的细节,先从最上层总目标开始设计,逐步使问题具体化。
逐步求精:对复杂问题,应设计一些子目标作过度,逐步细化。
模块化:一个复杂问题,肯定是由若干稍简单的问题构成。模块化是把程序要解决的总目标分解为分目标,再
进一步分解为具体的小目标,把每个小目标称为一个模块。
限制使用goto语句。
53. 面向对象的程序设计方法中涉及的对象是系统中用来描述客观事物的一个______。
标准答案为:实体
解析:面向对象的程序设计方法中涉及的对象是系统中用来描述客观事物的一个实体,是构成系统的一个基本单位,
它由一组表示其静态特征的属性和它可执行的一组操作组成。
第三章 软件工程基础
一、选择题
(1) 下列叙述中正确的是( )
A)软件测试的主要目的是发现程序中的错误
B)软件测试的主要目的是确定程序中错误的位置
C)为了提高软件测试的效率,最好由程序编制者自己来完成软件测试的工作
D)软件测试是证明软件没有错误
【答案】A
【解析】本题考查软件工程中测试的目的和方法。仅就软件测试而言,,它的目的是发现软件中的错误,但是,发
现错误并不是最终目的,最终目的是通过测试发现错误之后还必须诊断并改正错误,这就是调试的目的。由于测试
的目标是暴露程序中的错误.从心理学角度看,由程序的编写者自己进行测试是不恰当的。因此,在软件测试阶段
通常由其他人员组成测试小组来完成测试工作。因此,经过上述分析可知选项A的说法是正确的,而选项B、c、D
的说法是错误的。
(2)下列描述中正确的是
A)软件工程只是解决软件项目的管理问题
B)软件工程主要解决软件产品的生产率问题
C)软件工程的主要思想是强调在软件开发过程中需要应用工程化原则
D)软件工程只是解决软件开发中的技术问题
【答案】C
【解析】软件工程学是研究软件开发和维护的普遍原理与技术的一门工程学科。所谓软件工程是指,采用工程的概
念、原理、技术和方法指导软件的开发与维护。软件工程学的主要研究对象包括软件开发与维护的技术、方法、
工具和管理等方面。由此可见,选项A、B和D的说法均不正确.选项C正确。(3)在软件设计中,不属于过程设计工具的是
A)PDL(过程设计语言) B)PAD图 C)N-S图 D)DFD图
【答案】D
【解析】数据流图DFD,是结构化分析方法最主要的一种图形工具,不属于过程设计具。
(4)下列叙述中正确的是
A)软件交付使用后还需要进行维护
B)软件一旦交付使用就不需要再进行维护
C)软件交付使用后其生命周期就结束
D)软件维护是指修复程序中被破坏的指令
【答案】A
【解析】本题考核软件维护的概念。维护是软件生命周期的最后一个阶段,也是持续时间最长、付出代价最大的阶
段,在软件交付使用后,还需要进行维护。软件维护通常有以下四:为纠正使用中出现的错误而进行的改正性维护;
为适应环境变化而进行的适应性维护;为改进原有软件而进行的完善性维护;为将来的可维护和可靠而进行的预防
性维护。软件维护不仅包括程序代码的维护,还包括文档的维护。综上所述,本题的正确答案是A,其余选项的说法
错误。
(5)用黑盒技术测试用例的方法之一为
A)因果图B)逻辑覆盖C)循环覆盖D)基本路径测试
【答案】A
【解析】黑盒测试主要方法有等价值划分法、边界值分析法、错误推测法、因果图法等。白盒测试的主要方法有逻
辑覆盖、基本路径测试循环覆盖等。只有A属于黑盒测试。
(6)软件需求分析阶段的工作可以分为4个方面:需求获取、需求分析、编写需求分析说明书和
A)阶段性报告B)需求评审C)总结D)都不正确
【答案】B
【解析】需求分析的四个方面是:需求获取、需求分析、编写需求分析说明书和需求评审。
(7)在数据库的两级映射中,从概念模式到内模式的映射一般由______实现。
A)数据库系统B)数据库管理系统C)数据库管理员D)数据库操作系统
【答案】B
【解析】从概念模式到内模式的映射一般数据库管理系统(DBMS)实现。
(8)下面不属于软件设计原则的是
A)抽象B)模块化C)自底向上D)信息隐藏
【答案】C
【解析】软件设计的原则包括:抽象、模块化、信息隐蔽和模块独立性。所以自底向上不是软件设计原则。答案为C。
(9) 软件是指( )
A)程序 B)程序和文档
C)算法加数据结构 D)程序、数据和相关文档的集合
【答案】D
【解析】本题考查软件的定义。软件是计算机系统中与硬件相互依存得另一部分,它包括程序、相关数据及其说明文档得总和。因此,本题得正确答案是选项D。
(11)下列选项中不属于结构化程序设计方法的是
A)自顶向下 B)逐步求精
C)模块化 D)可复用
【答案】D
【解析】结构化程序设计方法的主要原则有 4点:自顶向下(先从最上层总目标开始设计,逐步使问题具体化)、逐
步求精(对于复杂问题,设计一些子目标作为过渡,逐步细化)、模块化(将程序要解决的总目标分解为分目标,再进
一步分解为具体的小目标,每个小目标作为一个模块)、限制使用GOTO语句。没有可复用原则,所以选项D为答案。
(13)下列叙述中正确的是
A)软件测试应该由程序开发者来完成
B)程序经调试后一般不需要再测试
C)软件维护只包括对程序代码的维护
D)以上三种说法都不对
【答案】D
【解析】本题考核软件测试、软件调试和软件维护的概念。软件测试的目标是在精心控制的环境下执行程序,以发
现程序中的错误,给出程序可靠性的鉴定。软件测试具有挑剔性,测试不是为了证明程序是正确的,而是在设想程
序有错误的前提下进行的,其目的是设法暴露程序中的错误和缺陷,就是说,测试是程序执行的过程,目的在于发
现错误;一个好的测试在于能发现至今未发现的错误;一个成功的测试是发现了至今未发现的错误。由于测试的这
一特征,一般应当避免由开发者测试自己的程序。所以,选项A的说法错误。
调试也称排错,目的是发现错误的位置,并改正错误。经测试发现错误后,可以立即进行调试并改正错误;经
过调试后的程序还需进行回归测试,以检查调试的效果,同时也可防止在调试过程中引进新的错误。所以,选项 B
的说法错误。
软件维护通常有4 类:为纠正使用中出现的错误而进行的改正性维护;为适应环境变化而进行的适应性维护;
为改进原有软件而进行的完善性维护;为将来的可维护和可靠而进行的预防性维护。软件维护不仅包括程序代码的
维护.还包括文档的维护。文档可以分为用户文档和系统文档两类。但无论是哪类文档,都必须与程序代码同时维
护。只有与程序代码完全一致的文档才有意义和价值。所以,选项c的说法错误。
综上所述,选项A、B、c的说法都错误,所以,选项D为正确答案。
(15)下列选项中不属于软件生命周期开发阶段任务的是
A)软件测试 B)概要设计
C)软件维护 D)详细设计
【答案】c
【解析】软件生命周期由软件定义、软件开发和软件维护三个时期组成,每个时期又进一步划分为若干个阶段。软
件定义时期的基本任务是确定软件系统的工程需求。软件定义可分为软件系统的可行性研究和需求分析两个阶段。
软件开发时期是具体设计和实现在前一时期定义的软件,它通常由下面五个阶段组成:概要设计、详细设计、编写
代码、组装测试和确认测试。软件维护时期的主要任务是使软件持久的满足用户的需要。即当软件在使用过程中发
现错误时应加以改正:当环境改变时应该修改软件,以适应新的环境;当用户有新要求时应该及时改进软件,以满
足用户的新要求。根据上述对软件生命周期的介绍,可知选项 c中的软件维护不是软件生命周期开发阶段的任务。因此,本题的正确答案是c。
(16)下列对于软件测试的描述中正确的是______。
A) 软件测试的目的是证明程序是否正确
B) 软件测试的目的是使程序运行结果正确
C) 软件测试的目的是尽可能多地发现程序中的错误
D) 软件测试的目的是使程序符合结构化原则
【答案】C
【解析】软件测试的目标是在精心控制的环境下执行程序,以发现程序中的错误,给出程序可靠性的鉴定。测试不
是为了证明程序是正确的,而是在设想程序有错误的前提下进行的,其目的是设法暴露程序中的错误和缺陷。可见
选项C的说法正确。
(18)下列描述中正确的是______。
A)程序就是软件
B)软件开发不受计算机系统的限制
C)软件既是逻辑实体,又是物理实体
D)软件是程序、数据与相关文档的集合
【答案】D
【解析】计算机软件是计算机系统中与硬件相互依存的另一部分,包括程序、数据与相关文档的完整集合。选项 D
的描述正确。
(20)详细设计的结果基本决定了最终程序的
A)代码的规模
B)运行速度
C)质量
D)可维护性
解析: 详细设计阶段的根本目标是确定应该怎样具体的实现所要求的系统,但详细设计阶段的任务还不是具体的编
写程序,而是要设计出程序的“蓝图”,以后程序员将根据这个蓝图写出实际的程序代码,因此,详细设计阶段的结
果基本上就决定了最终的程序代码的质量。故本题答案应该为选项C)。
(22)公司中有多个部门和多名职员,每个职员只能属于一个部门,一个部门可以有多名职员,从职员到部门的联
系类型是
A)多对多
B)一对一
C)多对一
D)一对多
解析: 现实世界中事物之间的联系在信息世界中反映为实体集之间的联系,实体集间的联系个数不仅可以是单个的
也可以是多个的,这种关系可以有下面几种对应:一对一、一对多(多对一)多对多。两个实体集间的联系可以用
下图表示:故本题答案应该为选项C)。
(24)软件生命周期中所花费用最多的阶段是
A)详细设计
B)软件编码
C)软件测试
D)软件维护
解析: 软件生命周期分为软件定义、软件开发及软件运行维护3个阶段。本题中,详细设计、软件编码和软件测试
都属于软件开发阶段;维护是软件生命周期的最后一个阶段,也是持续时间最长,花费代价最大的一个阶段,软件
工程学的一个目的就是提高软件的可维护性,降低维护的代价。故本题答案应该为选项 D)。
(25)下列叙述中,不属于软件需求规格说明书的作用的是
A)便于用户、开发人员进行理解和交流
B)反映出用户问题的结构,可以作为软件开发工作的基础和依据
C)作为确认测试和验收的依据
D)便于开发人员进行需求分析
解析: 软件需求规格说明书(SRS,Software Requirement Specification)是需求分析阶段的最后成果,是软件
开发中的重要文档之一。它有以下几个方面的作用:① 便于用户、开发人员进行理解和交流;② 反映出用户问题
的结构,可以作为软件开发工作的基础和依据;③ 作为确认测试和验收的依据。
(26)下列不属于软件工程的3个要素的是
A)工具
B)过程
C)方法
D)环境
解析: 软件工程包括3个要素,即方法、工具和过程。方法是完成软件工程项目的技术手段;工具支持软件的开发、
管理、文档生成;过程支持软件开发的各个环节的控制、管理。故本题答案应该为选项 D)。
(27)模块独立性是软件模块化所提出的要求,衡量模块独立性的度量标准则是模块的
A)抽象和信息隐蔽
B)局部化和封装化
C)内聚性和耦合性
D)激活机制和控制方法
解析: 模块的独立程序是评价设计好坏的重要度量标准。衡量软件的模块独立性使用耦合性和内聚性两个定性的度
量标准。故本题答案应该为选项C)。
(28)软件开发的结构化生命周期方法将软件生命周期划分成
A)定义、开发、运行维护B)设计阶段、编程阶段、测试阶段
C)总体设计、详细设计、编程调试
D)需求分析、功能定义、系统设计
解析: 通常,将软件产品从提出、实现、使用维护到停止使用退役的过程称为软件生命周期。它可以分为软件定义、
软件开发及软件运行维护3个阶段。
(30)下列不属于结构化分析的常用工具的是
A)数据流图
B)数据字典
C)判定树
D)PAD图
解析: 结构化分析的常用工具有数据流图、数据字典、判定树和判定表。而PAD图是常见的过程设计工具中的图形
设计。故本题答案应该为选项D)。
(31)在软件生产过程中,需求信息的给出是
A)程序员
B)项目管理者
C)软件分析设计人员
D)软件用户
解析: 软件需求是指用户对目标软件系统在功能、行为、性能、设计约束等方面的期望。故本题答案应该为选项D)。
(32)下列工具中为需求分析常用工具的是
A)PAD
B)PFD
C)N-S
D)DFD
解析: 需求分析中的常用工具有 PAD、PFD及N-S等,而DFD(数据流图)为结构化分析工具。故本题答案应该为选
项D)。
(33)NULL是指
A)0
B)空格
C)未知的值或无任何值
D)空字符串
解析: 此题属于记忆性的题目,NULL是指未知的值或无任何值。故本题答案应该为选项C)。
(34)软件工程的出现是由于
A)程序设计方法学的影响
B)软件产业化的需要
C)软件危机的出现
D)计算机的发展
解析: 软件工程概念的出现源自于软件危机。为了消除软件危机,通过认真研究解决软件危机的方法,认识到软件工程是使计算机软件走向工程科学的途径,逐步形成了软件工程的概念。故本题答案应该为选项C)。
(35)软件开发离不开系统环境资源的支持,其中必要的测试数据属于
A)硬件资源
B)通信资源
C)支持软件
D)辅助资源
答案:D
(36)在数据流图(DFD)中,带有名字的箭头表示
A)模块之间的调用关系
B)程序的组成成分
C)控制程序的执行顺序
D)数据的流向
解析: 数据流相当于一条管道,并有一级数据(信息)流经它。在数据流图中,用标有名字的箭头表示数据流。数
据流可以从加工流向加工,也可以从加工流向文件或从文件流向加工,并且可以从外部实体流向系统或从系统流向
外部实体。故本题答案应该为选项D)。
(37)软件设计包括软件的结构、数据接口和过程设计,其中软件的过程设计是指
A)模块间的关系
B)系统结构部件转换成软件的过程描述
C)软件层次结构
D)软件开发过程
解析: 软件设计包括软件结构设计、数据设计、接口设计和过程设计。其中结构设计是定义软件系统各主要部件之
间的关系;数据设计是将分析时创建的模型转化为数据结构的定义;接口设计是描述软件内部、软件和操作系统之
间及软件与人之间如何通信;过程设计则是把系统结构部件转换成软件的过程性描述。故本题答案应该为选项B)。
(38)检查软件产品是否符合需求定义的过程称为
A)确认测试
B)集成测试
C)验证测试
D)验收测试
解析: 确认测试的任务是验证软件的功能和性能,以及其他特性是否满足需求规格说明定的各种需求;集成测试的
主要目的是发现与接口有关的错误。故本题答案应该为选项A)。
(39)数据流图用于抽象描述一个软件的逻辑模型,数据流图由一些特定的图符构成。下列图符名标识的图符不属
于数据流图合法图符的是
A)控制流
B)加工
C)数据存储
D)源和潭
解析: 数据流图包括4个方面,即加工(转换)(输入数据经加工变换产生输出)、数据流(沿箭头方向传送数据的通道,一般在旁边标注数据流名)、存储文件(数据源)(表示处理过程中存放各种数据的文件)、源和潭(表示系统
和环境的接口,属系统之外的实体)。不包括选项中的控制流。故本题答案应该为选项A)。
(40)下列叙述中,正确的是
A)软件就是程序清单
B)软件就是存放在计算机中的文件
C)软件应包括程序清单及运行结果
D)软件包括程序和文档
解析: 软件(software)是计算机系统中与硬件相互依存的另一部分,是包括程序、数据及相关文档的完整集合。
故本题答案应该为选项D)。
(41)软件设计中,有利于提高模块独立性的一个准则是
A)低内聚低耦合
B)低内聚高耦合
C)高内聚低耦合
D)高内聚高耦合
解析: 模块的独立程度是评价设计好坏的重要度量标准。衡量软件的模块独立性使用耦合性和内聚性两个定性的度
量标准。一般优秀的软件设计,应尽量做到高内聚,低耦合,即减弱模块之间的耦合性和提高模块内的内聚性,有
利于提高模块的独立性。故本题答案应该为选项C)。
(42)软件生命周期中花费时间最多的阶段是
A)详细设计
B)软件编码
C)软件测试
D)软件维护
解析: 软件生命周期分为软件定义、软件开发及软件运行维护3个阶段。本题中,详细设计、软件编码和软件测试
都属于软件开发阶段;维护是软件生命周期的最后一个阶段,也是持续时间最长,花费代价最大的一个阶段,软件
工程学的一个目的就是提高软件的可维护性,降低维护的代价。故本题答案应该为选项 D)。
(6)需求分析最终结果是产生
A)项目开发计划
B)需求规格说明书
C)设计说明书
D)可行性分析报告
【答案】B
【解析】需求分析应交付的主要文档就是需求规格说明书。
(7)在进行单元测试时,常用的方法是
A)采用白盒测试,辅之以黑盒测试
B)采用黑盒测试,辅之以白盒测试
C)只使用白盒测试
D)只使用黑盒测试【答案】A
【解析】白盒测试是测试程序内部逻辑结构,黑盒测试只依据程序的需求规格说明书,检查程序的功能是否符合它
的功能说明。从程序内部的逻辑结构对系统进行测试才是测试的根本,更容易发现和解决程序中的问题,因此单元
测试时应该以白盒测试为主,而黑盒测试为辅。
(5)下列不属于结构化分析的常用工具的是______。
A)数据流图 B)数据字典 C)判定树 D)PAD图
答案:D
评析:结构化分析的常用工具有数据流图、数据字典、判定树和判定表。而 PAD图是常见的过程设计工具中的图形
设计。
(6)软件设计的基本原理中,______是评价设计好坏的重要度量标准。
A)信息隐蔽性 B)模块独立性
C)耦合性 D)内聚性
答案:B
评析:信息隐蔽是指,在一个模块内包含的信息(过程或数据),对于不需要这些信息的其他模块来说是不能访问的。
模块的独立性是指每个模块只完成系统要求的独立的子功能,并且与其他模块的联系最少且接口简单。模块独立性
是评价设计好坏的重要度量标准,而衡量软件的模块独立性使用的是耦合性和内聚性两个度量标准:内聚性是指一
个模块内部各个元素间彼此结合的紧密程度的度量。一个模块的内聚性越强,则该模块的模块独立性越强;耦合性
是模块间互相连接的紧密程度的度量。耦合性取决于各个模块之间接口的复杂度、调用方式以及哪些信息通过接口。
(7)在软件工程中,白箱测试法可用于测试程序的内部结构。此方法将程序看做是______。
A)循环的集合 B)地址的集合
C)路径的集合 D)目标的集合
答案:C
评析:软件的白盒测试方法是把测试对象看作一个打开的盒子,它允许测试人员利用程序内部的逻辑结构及有关信
息,设计或选择测试用例,对程序所有逻辑路径进行测试。
2. 结构化方法中,用数据流程图(DFD)作为描述工具的软件开发阶段是______。
A、可行性分析
B、需求分析
C、详细设计
D、程序编码
解析:软件开发阶段包括需求分析、总体设计、详细设计、编码和测试五个阶段。其中需求分析阶段常用的工具是数
据流图和数据字典。
本题答案为B。
4. 在软件生命周期中,能准确地确定软件系统必须做什么和必须具备哪些功能的阶段是______。
A、概要设计
B、详细设计
C、可行性分析
D、需求分析
解析:通常,将软件产品从提出、实现、使用维护到停止使用退役的过程称为软件生命周期。也就是说,软件产品从
考虑其概念开始,到该软件产品不能使用为止的整个时期都属于软件生命周期。软件生命周期的主要活动阶段为:
(1)可行性研究和计划制定。确定待开发软件系统的开发目标和总的要求,给出它的功能、性能、可靠性以及
接口等方面的可能方案,制定完成开发任务的实施计划。
(2)需求分析。对待开发软件提出的需求进行分析并给出详细定义,即准确地确定软件系统的功能。编写软件
规格说明书及初步的用户手册,提交评审。
(3)软件设计。系统设计人员和程序设计人员应该在反复理解软件需求的基础上,给出软件的结构、模块的划
分、功能的分配以及处理流程。
(4)软件实现。把软件设计转换成计算机可以接受的程序代码。即完成源程序的编码,编写用户手册、操作手
册等面向用户的文档,编写单元测试计划。
(5)软件测试。在设计测试用例的基础上,检验软件的各个组成部分。编写测试分析报告。
(6)运行和维护。将已交付的软件投入运行,并在运行使用中不断地维护,根据新提出的需求进行必要而且可
能的扩充和删改。
本题答案是D。
6. 下面不属于软件设计原则的是______。
A、抽象
B、模块化
C、自底向上
D、信息隐蔽
解析:在软件设计过程中,必须遵循软件工程的基本原则:这些原则包括抽象、信息隐蔽、模块化、局部化、确定性、
一致性、完备性和可靠性。
本题答案为C。
4. 程序流程图(PFD)中的箭头代表的是______。
A、数据流
B、控制流
C、调用关系
D、组成关系
解析:程序流程图(PFD)是一种传统的、应用广泛的软件过程设计表示工具,通常也称为程序框图,其箭头代表的
是控制流。
本题答案为B。
8. 在结构化方法中,软件功能分解属于下列软件开发中的______阶段。
A、详细设计
B、需求分析
C、总体设计
D、编程调试
解析:总体设计过程通常由两个主要阶段组成:系统设计,确定系统的具体实现方案;结构设计,确定软件结构。为
确定软件结构,首先需要从实现角度把复杂的功能进一步分解。分析员结合算法描述仔细分析数据流图中的每个处
理,如果一个处理的功能过分复杂,必须把它的功能适当地分解成一系列比较简单的功能。
本题答案为C。
9. 软件调试的目的是______。
A、发现错误
B、改正错误C、改善软件的性能
D、挖掘软件的潜能
解析:由程序调试的概念可知:程序调试活动由两部分组成,其一是根据错误的迹象确定程序中错误的确切性质、原
因和位置。其二,对程序进行修改,排除这个错误。所以程序调试的目的就是诊断和改正程序中的错误。
本题答案为B。
6. 下列叙述中,不属于软件需求规格说明书的作用的是______。
A、便于用户、开发人员进行理解和交流
B、反映出用户问题的结构,可以作为软件开发工作的基础和依据
C、作为确认测试和验收的依据
D、便于开发人员进行需求分析
解析:软件需求规格说明书(SRS,Software Requirement Specification)是需求分析阶段的最后成果,是软件开
发中的重要文档之一。它有以下几个方面的作用:① 便于用户、开发人员进行理解和交流;② 反映出用户问题的
结构,可以作为软件开发工作的基础和依据;③ 作为确认测试和验收的依据。
本题答案为D。
9. 软件开发的结构化生命周期方法将软件生命周期划分成______。
A、定义、开发、运行维护
B、设计阶段、编程阶段、测试阶段
C、总体设计、详细设计、编程调试
D、需求分析、功能定义、系统设计
解析:通常,将软件产品从提出、实现、使用维护到停止使用退役的过程称为软件生命周期。它可以分为软件定义、
软件开发及软件运行维护三个阶段。
本题答案为A。
10. 在软件工程中,白箱测试法可用于测试程序的内部结构。此方法将程序看做是______。
A、循环的集合
B、地址的集合
C、路径的集合
D、目标的集合
解析:软件的白盒测试方法是把测试对象看做一个打开的盒子,它允许测试人员利用程序内部的逻辑结构及有关信
息,设计或选择测试用例,对程序所有逻辑路径进行测试。
本题答案为C。
6. 下列对于软件测试的描述中正确的是______。
A、软件测试的目的是证明程序是否正确
B、软件测试的目的是使程序运行结果正确
C、软件测试的目的是尽可能多地发现程序中的错误
D、软件测试的目的是使程序符合结构化原则
解析:本题考查的是软件测试的目的。
关于软件测试的目的,Grenford J.Myers再《The Art of Software Testing》一书中给出了深刻的阐述:软件
测试是为了发现错误而执行程序的过程;一个好的测试用例是指很可能找到迄今为止尚未发现的错误的用例;一个
成功的测试是发现了至今尚未发现的错误的测试。整体来说,软件测试的目的就是尽可能多地发现程序中的错误。
故本题答案为C。
7. 为了使模块尽可能独立,要求______。
A、模块的内聚程度要尽量高,且各模块间的耦合程度要尽量强B、模块的内聚程度要尽量高,且各模块间的耦合程度要尽量弱
C、模块的内聚程度要尽量低,且各模块间的耦合程度要尽量弱
D、模块的内聚程度要尽量低,且各模块间的耦合程度要尽量强
解析:本题考查的是软件工程基本概念。
模块独立性是指每个模块只完成系统要求的独立的子功能,并且与其他模块的联系最少且接口简单。耦合性与
内聚性是模块独立性的两个定性标准,耦合与内聚是相互关联的。在程序结构中,各模块的内聚性越强,则耦合性
越弱。一般较优秀的软件设计,应尽量做到高内聚,低耦合,即减弱模块之间的耦合性和提高模块内的内聚性,有
利于提高模块的独立性。
故本题答案为B。
8. 下列描述中正确的是______。
A、程序就是软件
B、软件开发不受计算机系统的限制
C、软件既是逻辑实体,又是物理实体
D、软件是程序、数据与相关文档的集合
解析:本题考查的是软件工程基本概念。
计算机软件是计算机系统中与硬件相互依存的另一部分,是包括程序、数据及相关文档的完整集合。软件具有
以下特点:①软件是一种逻辑实体,而不是物理实体,具有抽象性;②软件的生产过程与硬件不同,它没有明显的
制作过程;③软件在运行、使用期间不存在磨损、老化问题;④软件的开发、运行对计算机系统具有依赖性,受计
算机系统的限制,这导致软件移植的问题;⑤软件复杂性高,成本昂贵;⑥软件开发涉及诸多的社会因素。
故本题答案为D。
5. 在软件生命周期中,能准确地确定软件系统必须做什么和必须具备哪些功能的阶段是______。
A、概要设计
B、详细设计
C、可行性分析
D、需求分析
解析:通常,将软件产品从提出、实现、使用维护到停止使用退役的过程称为软件生命周期。也就是说,软件产品
从考虑其概念开始,到该软件产品不能使用为止的整个时期都属于软件生命周期。
软件生命周期的主要活动阶段为:
(1)可行性研究和计划制定。确定待开发软件系统的开发目标和总的要求,给出它的功能、性能、可靠性以及
接口等方面的可能方案,制定完成开发任务的实施计划。
(2)需求分析。对待开发软件提出的需求进行分析并给出详细定义,即准确地确定软件系统的功能。编写软件
规格说明书及初步的用户手册,提交评审。
(3)软件设计。系统设计人员和程序设计人员应该在反复理解软件需求的基础上,给出软件的结构、模块的划
分、功能的分配以及处理流程。
(4)软件实现。把软件设计转换成计算机可以接受的程序代码。即完成源程序的编码,编写用户手册、操作手
册等面向用户的文档,编写单元测试计划。
(5)软件测试。在设计测试用例的基础上,检验软件的各个组成部分。编写测试分析报告。
(6)运行和维护。将已交付的软件投入运行,并在运行使用中不断地维护,根据新提出的需求进行必要而且可
能的扩充和删改。
本题答案是D。
6. 数据流图用于抽象描述一个软件的逻辑模型,数据流图由一些特定的图符构成。下列图符名标识的图符不属于数据流图合法图符的是______。
A、控制流
B、加工
C、数据存储
D、源和潭
解析:本题答案为A。
7. 软件需求分析阶段的工作,可以分为四个方面:需求获取、需求分析、编写需求规格说明书以及______。
A、阶段性报告
B、需求评审
C、总结
D、都不正确
解析:软件的需求分析阶段的工作,可以概括为四个方面:需求获取、需求分析、编写需求规格说明书和需求评审。
需求获取的目的是确定对目标系统的各方面需求。涉及到的主要任务是建立获取用户需求的方法框架,并支持
和监控需求获取的过程。
需求分析是对获取的需求进行分析和综合,最终给出系统的解决方案和目标系统的逻辑模型。
编写需求规格说明书作为需求分析的阶段成果,可以为用户、分析人员和设计人员之间的交流提供方便,可以
直接支持目标软件系统的确认,又可以作为控制软件开发进程的依据。
需求评审是对需求分析阶段的工作进行复审,验证需求文档的一致性、可行性、完整性和有效性。
本题答案是B。
6. 下面不属于软件工程的3个要素的是______。
A、工具
B、过程
C、方法
D、环境
解析:软件工程包括3个要素,即方法、工具和过程。
本题答案为D。
7. 程序流程图(PFD)中的箭头代表的是______。
A、数据流
B、控制流
C、调用关系
D、组成关系
解析:程序流程图(PFD)是一种传统的、应用广泛的软件过程设计表示工具,通常也称为程序框图,其箭头代表的
是控制流。
本题答案为B。
5. 检查软件产品是否符合需求定义的过程称为______。
A、确认测试
B、集成测试
C、验证测试
D、验收测试
解析:确认测试的任务是验证软件的功能和性能及其他特性是否满足了需求规格说明中的确定的各种需求,以及软件
配置是否完全、正确。本题答案为A。
6. 下列工具中不属于需求分析常用工具的是______。
A、PAD
B、PFD
C、N-S
D、DFD
解析:常见的需求分析方法有:结构化分析方法和面向对象的分析方法。结构化分析的常用工具有:数据流图(DFD)、
数据字典(DD)、判定树和判定表等。
本题答案为D。
7. 下面不属于软件设计原则的是______。
A、抽象
B、模块化
C、自底向上
D、信息隐蔽
解析:在软件设计过程中,必须遵循软件工程的基本原则:这些原则包括抽象、信息隐蔽、模块化、局部化、确定性、
一致性、完备性和可靠性。
本题答案为C。
6. 下列不属于软件调试技术的是______。
A、强行排错法
B、集成测试法
C、回溯法
D、原因排除法
解析:调试的关键在于推断程序内部的错误位置及原因。主要的调试方法有强行排错法、回溯法和原因排除法。
本题答案为B。
7. 下列叙述中,不属于软件需求规格说明书的作用的是______。
A、便于用户、开发人员进行理解和交流
B、反映出用户问题的结构,可以作为软件开发工作的基础和依据
C、作为确认测试和验收的依据
D、便于开发人员进行需求分析
解析:软件需求规格说明书(SRS,Software Requirement Specification)是需求分析阶段的最后成果,是软件开
发中的重要文档之一。它有以下几个方面的作用:① 便于用户、开发人员进行理解和交流;② 反映出用户问题的
结构,可以作为软件开发工作的基础和依据;③ 作为确认测试和验收的依据。
本题答案为D。
8. 在数据流图(DFD)中,带有名字的箭头表示______。
A、控制程序的执行顺序
B、模块之间的调用关系
C、数据的流向
D、程序的组成成分
解析:数据流相当于一条管道,并有一级数据(信息)流经它。在数据流图中,用标有名字的箭头表示数据流。数据流可以从加工流向加工,也可以从加工流向文件或从文件流向加工,并且可以从外部实体流向系统或从系统流向外
部实体。
本题答案为C。
5. 软件设计包括软件的结构、数据接口和过程设计,其中软件的过程设计是指______。
A、模块间的关系
B、系统结构部件转换成软件的过程描述
C、软件层次结构
D、软件开发过程
解析:软件设计包括软件结构设计、数据设计、接口设计和过程设计。其中结构设计是定义软件系统各主要部件之间
的关系;数据设计是将分析时创建的模型转化为数据结构的定义;接口设计是描述软件内部、软件和操作系统之间
及软件与人之间如何通信;过程设计则是把系统结构部件转换成软件的过程性描述。
本题答案为B。
6. 为了避免流程图在描述程序逻辑时的灵活性,提出了用方框图来代替传统的程序流程图,通常也把这种图称为
______。
A、PAD图
B、N-S图
C、结构图
D、数据流图
解析:常见的过程设计工具有:程序流程图、N-S图、PAD图和HIPO图。其中,为了避免流程图在描述程序逻辑时的
灵活性,提出了用方框图来代替传统的程序流程图,通常也把这种图称为 N-S图。
本题答案为B。
10. 需求分析阶段的任务是确定______。
A、软件开发方法
B、软件开发工具
C、软件开发费用
D、软件系统功能
解析:需求分析是软件定义时期的最后一个阶段,它的基本任务就是详细调查现实世界要处理的对象(组织、部门、
企业等),充分了解原系统的工作概况,明确用户的各种需求,然后在此基础上确定新系统的功能。选项A)软件开
发方法是在总体设计阶段完成的任务;选项B)软件开发工具是在实现阶段需完成的任务;选项C)软件开发费用是
在可行性研究阶段需完成的任务。
本题答案为D。
5. 检查软件产品是否符合需求定义的过程称为______。
A、确认测试
B、集成测试
C、验证测试
D、验收测试
解析:确认测试的任务是验证软件的功能和性能及其他特性是否满足了需求规格说明中的确定的各种需求,以及软件
配置是否完全、正确。
本题答案为A。
7. 在数据流图(DFD)中,带有名字的箭头表示______。
A、控制程序的执行顺序
B、模块之间的调用关系C、数据的流向
D、程序的组成成分
解析:数据流相当于一条管道,并有一级数据(信息)流经它。在数据流图中,用标有名字的箭头表示数据流。数据
流可以从加工流向加工,也可以从加工流向文件或从文件流向加工,并且可以从外部实体流向系统或从系统流向外
部实体。
本题答案为C。
8. 软件设计包括软件的结构、数据接口和过程设计,其中软件的过程设计是指______。
A、模块间的关系
B、系统结构部件转换成软件的过程描述
C、软件层次结构
D、软件开发过程
解析:软件设计包括软件结构设计、数据设计、接口设计和过程设计。其中结构设计是定义软件系统各主要部件之间
的关系;数据设计是将分析时创建的模型转化为数据结构的定义;接口设计是描述软件内部、软件和操作系统之间
及软件与人之间如何通信;过程设计则是把系统结构部件转换成软件的过程性描述。
本题答案为B。
二、填空题
(1)诊断和改正程序中错误的工作通常称为 ____ 。
【答案】调试或程序调试或软件调试或Debug(英文字母大小写均可)或调试程序或调试软件
【解析】调试也称排错,调试的目的是发现错误的位置,并改正错误。一般的调试过程分为错误侦查、错误诊断和
改正错误。
(2)在进行模块测试时,要为每个被测试的模块另外设计两类模块:驱动模块和承接模块(桩模块)。其中 _____ 的
作用是将测试数据传送给被测试的模块,并显示被测试模块所产生的结果。
【答案】驱动模块
【解析】由于模块不是一个独立的程序,不能单独运行,因此,在进行模块测试时,还应为每个被测试的模块另外
设计两类模块:驱动模块和承接模块。其中驱动模块的作用是将测试数据传送给被测试的模块,并显示被测试模块
所产生的结果;承接模块的作用是模拟被测试模块的下层模块。通常,承接模块有多个。
(3) ____ 的任务是诊断和改正程序中的错误。
【答案】调试(阶段)或程序调试(阶段)或软件调试(阶段)或Debug(阶段)
【解析】软件测试的目的是发现程序中的错误,而调试的目的是确定程序中错误的位置和引起错误的原因,并加以
改正。换句话说,测试的目的就是诊断和改正程序中的错误。调试不是测试,但是它总是发生在测试之后。因此,
本题的正确答案是调试(阶段)或程序调试(阶段或软件调试(阶段)或Debug(阶段)。
(4) 软件测试分为白箱(盒)测试和黑箱(盒)测试,等价类划分法属于______测试。
【答案】黑箱或黑盒或黑箱(盒)
【解析】本题考查软件工程的测试。对于软件测试而言,黑箱(盒)测试是把程序看成一个黑盒子,完全不考虑程序
的内部结构和处理过程,它只检查程序功能是否能按照规格说明书的规定正常使用,程序是否能适当的接收输入数
据产生正确的输出信息。与黑箱(盒)测试相反,白箱(盒)测试的前提是可以把程序看成装在一个透明的白盒子里,
也就是完全了解程序的结构和处理过程。它按照程序内部的逻辑测试程序,检验程序中的每条通路是否都能按照预定要求正确处理。
等价类划分是把所有可能的输入数据(有效的和无效的)划分成若干个等价类,则可以合理的做出下述假定:每类中
的一个典型值在测试中的作用与这一类中所有其他值的作用相同。显然,等价类划分完全不考虑程序的内部结构和
处理过程,因此它属于黑箱(盒)测试。
(5) 软件生命周期可分为多个阶段,一般分为定义阶段、开发阶段和维护阶段。编码和测试属于_______阶段。
【答案】开发或软件开发
【解析】本题考查软件工程的软件生命周期及其各阶段的基本任务。一般说来,软件生命周期由软件定义、软件开
发和软件维护三个时期组成。
软件定义时期的任务是确定软件开发工程必须完成的总目标;导出实现工程目标应该采用的的策略及系统必须完
成的功能;确定工程的可行性;估计完成该项工程需要的资源和成本,并且制定工程进度表。
软件开发时期的任务是设计程序结构,给出程序的详细规格说明;编写程序代码,并且仔细测试编写出的每一个程
序模块;最后进行综合测试,也就是通过各种类型的测试使软件达到预定的要求。
软件维护时期的任务是使软件持久的满足用户的需要。具体地说,就是诊断和改正在使用过程中发现的软件错误;
修改软件从而适应环境的变化;根据用户的要求改进或扩充软件使其更完善;修改软件为将来的维护活动预先做准
备。
显然,编码和测试属于软件开发阶段。划线处心填入“开发”或“软件开发”。
(6) 在结构化分析使用的数据流图(DFD)中,利用______对其中的图形元素进行确切解释。
【答案】数据字典或DD
【解析】本题考查数据流图和数据字典的概念。数据流图(Data Flow Diagram,DFD)是一种结构化分析描述模型,
用来对系统的功能需求进行建模,它可以用少数几种符号综合地反映出信息在系统中的流动、处理和存储情况。尽
管数据流图给出了系统数据流向和加工等情况,但其各个成分的具体含义仍然不清楚或不明确,因此,在实际中常
采用数据词典这一基本工具对其作进-步的详细说明。数据词典(Data Dictionary,简称DD)和数据流图密切配合,
能清楚地表达数据处理的要求。数据词典用于对数据流图中出现的所有成分给出定义,它使数据流图上的数据流名
字、加工名字和数据存贮名字具有确切的解释。每一条解释就是一条词条,按一定的顺序将所有词条排列起来,就
构成了数据词典,就象日常使用的英汉词典、新华词典一样。因此,划线处应填入“数据字典”或“DD”。
(7) 软件需求规格说明书应具有完整性、无歧义性、正确性、可验证性、可修改性等特性,其中最重要的 ____ 。
【答案】正确性
【解析】本题考查软件工程中需求规格说明书的评审。衡量需求规格说明书好坏的标准按重要性次序排列为:正确
性、无歧义性、完全性、可验证性、一致性、可理解性、可修改性和可追踪性。因此,划线处应填入“正确性”。
(8) 在两种基本测试方法中, ____测试的原则之一是保证所测模块中每一个独立路径至少要执行一次。
【答案】白盒或白箱或白盒子或WhiteBox
【解析】本题考查软件工程的测试。测试一般有两种方法:黑盒测试和白盒测试。黑盒测试不考虑程序的内部逻辑
结构和处理过程,只着眼于程序的外部特性。用黑盒测试来发现程序中的错误,必须用所有可能的输入数据来检查
程序能否都能产生正确的输出。白盒测试是在了解程序内部结构和处理过程的基础上,对程序的所有路径进行测试,
检查路径是否都能按预定要求正确工作。因此,划线处应填入“白盒(箱)”或“White Box”。
(9)程序测试分为静态分析和动态测试。其中 ___ 是指不执行程序,而只是对程序文本进行检查,通过阅读和讨
论,分析和发现程序中的错误。【答案】静态分析
【解析】程序测试分为静态分析和动态测试。其中,静态分析是指不执行程序,而只是对程序文本进行检查,通过
阅读和讨论,分析和发现程序中的错误。
(10)软件的 设计又称为总体结构设计,其主要任务是建立软件系统的总体结构。
答案:概要
(11)对软件是否能达到用户所期望的要求的测试称为 。
答案:有效性测试
(12)通常,将软件产品从提出、实现、使用维护到停止使用退役的过程称为 。
答案:软件生命周期
解析: 软件产品从考虑其概念开始,到该软件产品不能使用为止的整个时期都属于软件生命周期。一般包括可行性
研究与需求分析、设计、实现、测试、交付使用以及维护等活动。
(13)耦合和内聚是评价模块独立性的两个主要标准,其中 反映了模块内各成分之间的联系。
答案:内聚
解析: 内聚性是一个模块内部各个元素间彼此结合的紧密程度的度量,内聚是从功能角度来度量模块内的联系;耦
合性是模块间互相连接的紧密程度的度量。
(14)常用的黑箱测试有等价分类法、 、因果图法和错误推测法4种。
答案:边值分析法
解析: 黑箱测试方法完全不考虑程序的内部结构和内部特征,而只是根据程序功能导出测试用例。常用的黑箱测试
有等价分类法、边值分析法、因果图法和错误推测法4种。
(15)测试的目的是暴露错误,评价程序的可靠性;而 的目的是发现错误的位置并改正错误。
答案:调试
解析: 软件测试的目标是在精心控制的环境下执行程序,以发现程序中的错误,给出程序可靠性的鉴定;调试也称
排错,它是一个与测试有联系又有区别的概念。具体来说,测试的目的是暴露错误,评价程序的可靠性,而调试的
目的是发现错误的位置,并改正错误。
(16)软件维护活动包括以下几类:改正性维护、适应性维护、 维护和预防性维护。
答案:完善性维护
解析: 软件维护活动包括以下几类:改正性维护、适应性维护、完善性维护和预防性维护。改正性维护是指在软件
交付使用后,为了识别和纠正软件错误、改正软件性能上的缺陷、排除实施中的误使用,应当进行的诊断和改正错
误的过程;适应性维护是指为了使软件适应变化,而去修改软件的过程;完善性维护是指为了满足用户对软件提出
的新功能与性能要求,需要修改或再开发软件,以扩充软件功能、增强软件性能、改进加工效率、提高软件的可维
护性;预防性维护是为了提高软件的可维护性、可靠性等,为以后的进一步改进软件打下良好基础。
(17)软件开发环境是全面支持软件开发全过程的 集合。
答案:软件工具
(18)软件危机出现于60年代末,为了解决软件危机,人们提出了 的原理来设计软件,这就是软
件工程诞生的基础。
答案:软件工程学
(19)软件工程研究的内容主要包括: 技术和软件工程管理。答案:软件开发技术
解析: 基于软件工程的目标,软件工程的理论和技术性研究的内容主要包括:软件开发技术和软件工程管理。软件
开发技术包括:软件开发方法学、开发过程、开发工具和软件工程环境,其主体内容是软件开发方法学。软件工程
管理包括:软件管理学、软件工程经济学,以及软件心理学等内容。
(20)软件工程的出现是由于 。
答案:软件危机
解析: 从20世纪 60年代中期到 70年代中期,随着计算机应用的日益普及,软件数量急剧膨胀,在程序运行时发
现的错误必须设法改正,用户有了新的需求时必须相应的修改程序以适应新的环境。种种软件维护工作耗费惊人的
资源,更严重的是许多程序个体化使得程序最终无法维护,“软件危机”就这样出现了。为了更有效的开发与维护软
件,新兴了一门软件工程学即软件工程。
(21)单元测试又称模块测试,一般采用 测试。
答案:白盒法
解析: 软件测试过程一般按4个步骤进行,即单元测试、集成测试、验收测试和系统测试。单元测试的技术可以采
用静态分析和动态测试。对动态测试多采用白盒动态测试为主,辅之以黑盒测试。
(3)数据流图的类型有【3】和事务型。
【答案】变换型
【解析】典型的数据流图有两种,即变换型和事务型。
(1)测试的目的是暴露错误,评价程序的可靠性;而 【1】 的目的是发现错误的位置并改正错误。
答案:调试
评析:软件测试的目标是在精心控制的环境下执行程序,以发现程序中的错误,给出程序可靠性的鉴定;调试也称
排错,它是一个与测试有联系又有区别的概念。具体来说,测试的目的是暴露错误,评价程序的可靠性,而调试的
目的是发现错误的位置,并改正错误。
53. Jackson结构化程序设计方法是英国的M.Jackson提出的,它是一种面向______的设计方法。
解析:结构化分析方法主要包括:面向数据流的结构化分析方法(SA-Structuredanalysis),面向数据结构的Jackson
方法(JSD-Jacksonsystemdevelopmentmethod)和面向数据结构的结构化数据系统开发方法(DSSD-Datastructured
system development method)。
标准答案为:数据结构
55. 软件维护活动包括以下几类:改正性维护、适应性维护、______维护和预防性维护。
解析:软件维护活动包括以下几类:改正性维护、适应性维护、完善性维护和预防性维护。改正性维护是指在软件交
付使用后,为了识别和纠正软件错误、改正软件性能上的缺陷、排除实施中的误使用,应当进行的诊断和改正错误
的过程;适应性维护是指为了使软件适应变化,而去修改软件的过程;完善性维护是指为了满足用户对软件提出的
新功能与性能要求,需要修改或再开发软件,以扩充软件功能、增强软件性能、改进加工效率、提高软件的可维护
性;预防性维护是为了提高软件的可维护性、可靠性等,为以后的进一步改进软件打下良好基础。
标准答案为:完善性
51. 若按功能划分,软件测试的方法通常分为白盒测试方法和______测试方法。
解析:软件测试的方法有三种:动态测试、静态测试和正确性证明。设计测试实例的方法一般有两类:黑盒测试方法
和白盒测试方法。在使用黑盒法设计测试实例时,测试人员将程序看成一个"黑盒",也就是说,他不关心程序内部是如何实现的,而只是检查程序是否符合它的"功能说明",所以使用黑盒法设计的测试用例完全是根据程序的功能
说明来设计的;如用白盒法,则需要了解程序内部的结构,此时的测试用例是根据程序的内部逻辑来设计的,如果
想用白盒法发现程序中所有的错误,则至少必须使程序中每种可能的路径都执行一次。实际上这是不可能的,即使
测遍所有的路径,仍不一定能保证符合相应的功能要求。
标准答案为:黑盒
52. 与结构化需求分析方法相对应的是______方法。
解析:与结构化需求分析方法相对应的是结构化设计方法。结构化设计就是采用最佳的可能方法设计系统的各个组成
部分以及各个成分之间的内部联系的技术。也就是说,结构化设计是这样一个过程,它决定用哪些方法把哪些部分
联系起来,才能解决好某个具体且有清楚定义的问题。
标准答案为:结构化设计
53. 软件维护活动包括以下几类:改正性维护、适应性维护、______维护和预防性维护。
解析:软件维护活动包括以下几类:改正性维护、适应性维护、完善性维护和预防性维护。改正性维护是指在软件交
付使用后,为了识别和纠正软件错误、改正软件性能上的缺陷、排除实施中的误使用,应当进行的诊断和改正错误
的过程;适应性维护是指为了使软件适应变化,而去修改软件的过程;完善性维护是指为了满足用户对软件提出的
新功能与性能要求,需要修改或再开发软件,以扩充软件功能、增强软件性能、改进加工效率、提高软件的可维护
性;预防性维护是为了提高软件的可维护性、可靠性等,为以后的进一步改进软件打下良好基础。
标准答案为:完善性
52. 软件工程研究的内容主要包括:______技术和软件工程管理。
标准答案为:软件开发
解析:基于软件工程的目标,软件工程的理论和技术性研究的内容主要包括:软件开发技术和软件工程管理。
软件开发技术包括:软件开发方法学、开发过程、开发工具和软件工程环境,其主体内容是软开发方法学。
软件工程管理包括:软件管理学、软件工程经济学、软件心理学等内容。
53. 与结构化需求分析方法相对应的是______方法。
标准答案为:结构化设计
解析:与结构化需求分析方法相对应的是结构化设计方法。结构化设计就是采用最佳的可能方法设计系统的各个组成
部分以及各个成分之间的内部联系的技术。也就是说,结构化设计是这样一个过程,它决定用哪些方法把哪些部分
联系起来,才能解决好某个具体且有清楚定义的问题。
53. 数据字典是各类数据描述的集合,它通常包括5个部分,即数据项、数据结构、数据流、______和处理过程。
标准答案为:数据存储
解析: 数据字典是各类数据描述的集合,它通常包括 5 个部分,即数据项,是数据的最小单位;数据结构,是若干
数据项有意义的集合;数据流,可以是数据项,也可以是数据结构,表示某一处理过程的输入或输出;数据存储,
处理过程中存取的数据,常常是手工凭证、手工文档或计算机文件;处理过程。
54. 软件的需求分析阶段的工作,可以概括为四个方面:______、需求分析、编写需求规格说明书和需求评审。
标准答案为:需求获取
解析:软件的需求分析阶段的工作,可以概括为四个方面:需求获取、需求分析、编写需求规格说明书和需求评审。
需求获取的目的是确定对目标系统的各方面需求。涉及到的主要任务是建立获取用户需求的方法框架,并支持
和监控需求获取的过程。
需求分析是对获取的需求进行分析和综合,最终给出系统的解决方案和目标系统的逻辑模型。
编写需求规格说明书作为需求分析的阶段成果,可以为用户、分析人员和设计人员之间的交流提供方便,可以直接支持目标软件系统的确认,又可以作为控制软件开发进度的依据。
需求评审是对需求分析阶段的工作进行的复审,验证需求文档的一致性、可行性、完整性和有效性。
53. 诊断和改正程序中错误的工作通常称为 。
标准答案为:程序调试
解析:本题考查的是软件的调试。
程序调试的任务是诊断和改正程序中的错误。它与软件测试不同,软件测试是尽可能多地发现软件中的错误。先
要发现软件的错误,然后借助于一定的调试工具去找出软件错误的具体位置。软件测试贯穿整个软件生命期,调试
主要再开发阶段。
53. 软件的调试方法主要有:强行排错法、______和原因排除法。
标准答案为:回溯法
解析:调式的关键在于推断程序内部的错误位置及原因。其主要的调试方法有:强行排错法、回溯法和原因排除法。
强行排错法:是传统的调试方法,其过程可概括为:设置断点、程序暂停、观察程序状态、继续运行程序。这
是目前使用较多、效率较低的调试方法。
回溯法:该方法适合于小规模程序的排错。即一旦发现了错误,先分析错误征兆,确定最先发现"症状"的位置。
然后,从发现"症状"的地方开始,沿程序的控制流程,逆向跟踪源程序代码,直到找到错误根源或确定错误产生的
原因。
原因排除法:是通过演绎和归纳,以及二分法来实现的。
55. 数据字典是各类数据描述的集合,它通常包括5个部分,即数据项、数据结构、数据流、______和处理过程。
标准答案为:数据存储
解析:数据字典是各类数据描述的集合,它通常包括5个部分,即数据项,是数据的最小单位;数据结构,是若干数
据项有意义的集合;数据流,可以是数据项,也可以是数据结构,表示某一处理过程的输入或输出;数据存储,处
理过程中存取的数据,常常是手工凭证、手工文档或计算机文件;处理过程。
第四章 数据库基础
一、选择题
(1) 在下列关系运算中,不改变关系表中的属性个数但能减少元组个数的是( )
A)并 B)交 C)投影 D)笛卡儿乘积
【答案】B
【解析】本题考查数据库的关系运算。两个关系的并运算是指将第一个关系的元组加到第二个关系中,生成新的关
系。因此,并运算不改变关系表中的属性个数,也不能减少元组个数。两个关系的交运算是包含同时出现在第一和
第二个关系中的元组的新关系。因此,交运算不改变关系表中的属性个数,但能减少元组个数。投影是一元关系操
作。投影操作选取关系的某些属性,这个操作是对一个关系进行垂直分割,消去某些属性,并重新安排属性的顺序,
再删除重复的元组。因此,投影运算既可以减少关系表中的属性个数,也可以减少元组个数。两个关系的笛卡儿乘
积是指一个关系中的每个元组和第二个关系的每个元组连接。因此,笛卡儿乘积运算能够增加元组属性的个数。
经过上述分析可知,在上述四种运算中,交运算不改变关系表中的属性个数但能减少元组个数。因此,正确答
案是选项B。(2) 在E-R图中,用来表示实体之间联系的图形是( )
A)矩形 B)椭圆形 C)菱形 D)平行四边形
【答案】C
【解析】E-R模型中,有三个基本的抽象概念:实体、联系和属性。E-R图是E-R模型的图形表示法,在E-R图中,
用矩形框表示实体,菱形框表示联系,椭圆形框表示属性。因此,本题的正确答案是选项C。
(3) 下列叙述中错误的是( )
A)在数据库系统中,数据的物理结构必须与逻辑结构一致
B)数据库技术的根本目标是要解决数据的共享问题
C)数据库设计是指在已有数据库管理系统的基础上建立数据库
D)数据库系统需要操作系统的支持
【答案】A
【解析】本题考查数据库系统的基本概念和知识。数据的逻辑结构,是数据间关系的描述,它只抽象地反映数据元
素之间的逻辑关系,而不管其在计算机中的存储方式。数据的存储结构,又叫物理结构,是逻辑结构在计算机存储
器里的实现。这两者之间没有必然的联系。因此,选项A的说法是错误的。
数据库可以看成是长期存储在计算机内的、大量的、有结构的和可共享的数据集合。因此,数据库具有为各种用
户所共享的特点。不同的用户可以使用同一个数据库,可以取出它们所需要的子集,而且容许子集任意重叠。数据
库的根本目标是要解决数据的共享问题。因此,选项B的说法是正确的。
数据库设计是在数据库管理系统的支持下,按照应用的要求,设计一个结构合理、使用方便、效率较高的数据
库及其应用系统。数据库设计包含两方面的内容:一是结构设计,也就是设计数据库框架或数据库结构:二是行为
设计,即设计基于数据库的各类应用程序、事务等。因此,选项C的说法是错误的。
数据库系统除了数据库管理软件之外,还必须有其他相关软件的支持。这些软件包括操作系统、编译系统、应用软
件开发工具等。对于大型的多用户数据库系统和网络数据库系统,还需要多用户系统软件和网络系统软件的支持。
因此,选项D的说法是正确的。
因此,本题的正确答案是选项A。
(4)数据库设计的根本目标是要解决
A)数据共享问题 B)数据安全问题
C)大量数据存储问题 D)简化数据维护
【答案】A
【解析】本题考核数据库技术的根本目标,很简单,记忆性题目。数据库技术的根本目标就是要解决数据的共享问
题,选项A正确。
(5)设有如下关系表:
R S T
A B C A B C A B C
1 1 2 3 1 3 1 1 2
2 2 3 2 2 3
3 1 3
则下列操作中正确的是A)T=R∩S B)T=R∪S C)T=R×S D)T=R/S
【答案】B
【解析】选项A、B、c分别进行交运算、并运算、笛卡尔积运算,选项D不是关系运算。T由属于关系R以及关系S
的元组组成,简单来说,就是S和R的元组之和,是并运算,选项B正确。
(6)数据库系统的核心是
A)数据模型 B)数据库管理系统 C)数据库 D)数据库管理员
【答案】B
【解析】数据库管理系统(DBMS)是整个数据库系统的核心,它对数据库中的数据进行管理,还在用户的个别应用与
整体数据库之间起接门作用。选项B正确。
(7)在数据库管理系统提供的数据语言中,负责数据的查询及增、删、改等操作的是
A)数据定义语言B)数据转换语言C)数据操纵语言D)数据控制语言
【答案】c
【解析】在数据库管理系统提供的数据语言中,数据操纵语言负责数据的查询及增、删、改等操作。
(8)关系数据库的数据及更新操作必须遵循_____等完整性规则。
A)实体完整性和参照完整性
B)参照完整性和用户定义的完整性
D)实体完整性、参照完整性和用户定义的完整性
【答案】D
【解析】关系模型中包括关系的数据结构、关系的操纵和关系中的数据约束。关系完整性约束即数据完整性,包括
实体完整性、参照完整性和用户自定义完整性。
(9)实体联系模型中实体与实体之间的联系不可能是
A)一对一B)多对多C)一对多D)一对零
【答案】D
【解析】实体联系模型中实体与实体之间的联系有一对一(1:1),一对多或多对一(1:m或m:1),多对多(m:n)其中
一对一是最常用的关系。
(10)支持数据库各种操作的软件系统叫做
A)数据库管理系统B)文件系统C)数据库系统D)操作系统
【答案】A
【解析】数据库管理系统是一种系统软件,负责数据库中的数据组织、数据操纵、数据维护维护、控制及保护和数
据服务等操作。所以答案为A。
(11)在关系数据库模型中,通常可以把______称为属性,其值称为属性值。
A)记录B)基本表C)模式D)字段
【答案】D
【解析】数据库表中字段转化为属性,把记录的类型转化为关系模式。
(12)用树形结构来表示实体之间联系的模型称为
A)关系模型B)层次模型C)网状模型D)数据模型
【答案】B【解析】关系模型以二维表表示实体之间的联系,网状模型以一个不加任何条件限制
的无向图表示实体之间的联系。层次模型的基本结构为树形结构。而 D选项数据模
型包括关系模型、网状模型和层次模型。
(13)“商品”与“顾客”两个实体集之间的联系一般是
A)一对一 B)一对多
C)多对一 D)多对多
【答案】D
【解析】本题考核实体集之间的联系。实体集之间的联系有 3 种:一对一、 一对多和多对多。因为一类商品可以
由多个顾客购买,而一个顾客可以购买多类商品.所以.“商品”与“顾客”两个实体集之间的联系一般是“多对多”,
选项D正确。
(14)在E—R图中,用来表示实体的图形是
A)矩形 B)椭圆形 C)菱形 D)三角形
【答案】A
【解析】在E—R图中,用三种图框分别表示实体、属性和实体之间的联系,其规定如下:用矩形框表示实体,框内
标明实体名;用椭圆状框表示实体的属性,框内标明属性名;用菱形框表示实体间的联系,框内标明联系名。所以,
选项A正确。
(15)数据库DB、数据库系统DBS、数据库管理系统DBMS之间的关系是
A)DB包含DBS和DBMS
B)DBMS包含DB和DBS
C)DBS包含DB和DBMS
D)没有任何关系
【答案】C
【解析】数据库管理系统DBMS是数据库系统中实现各种数据管理功能的核心软件。它负责数据库中所有数据的存储、
检索、修改以及安全保护等,数据库内的所有活动都是在其控制下进行的。所以,DBMS包含数据库DB、操作系统、
数据库管理系统与应用程序在一定的硬件支持下就构成了数据库系统。所以,DBS包含DBMS,也就包含DB。综上所
述.选项C正确。
(16) 下列叙述中正确的是( )
A)数据库系统是一个独立的系统,不需要操作系统的支持
B)数据库技术的根本目标是要解决数据的共享问题
C)数据库管理系统就是数据库系统
D)以上三种说法都不对
【答案】B
【解析】本题考查数据库系统的基本概念和知识。
数据库系统除了数据库管理软件之外,还必须有其他相关软件的支持。这些软件包括操作系统、编译系统、应用软
件开发工具等。对于大型的多用户数据库系统和网络数据库系统,还需要多用户系统软件和网络系统软件的支持。
因此,选项A的说法是错误的。
数据库可以看成是长期存储在计算机内的、大量的、有结构的和可共享的数据集合。因此,数据库具有为各种用户所共享的特点。不同的用户可以使用同一个数据库,可以取出它们所需要的子集,而且允许子集任意重叠。数据库
的根本目标是要解决数据的共享问题。因此,选项B的说法是正确的。
通常将引入数据库技术的计算机系统称为数据库系统。一个数据库系统通常由五个部分组成,包括相关计算机的硬
件、数据库集合、数据库管理系统、相关软件和人员。
因此,选项C的说法是错误的。本题的正确答案是选项B。
(17) 下列叙述中正确的是( )
A)为了建立一个关系,首先要构造数据的逻辑关系
B)表示关系的二维表中各元组的每一个分量还可以分成若干数据项
C)一个关系的属性名表称为关系模式
D)一个关系可以包括多个二维表
【答案】C
【解析】本题考查数据库的关系模型。关系模型的数据结构是一个“二维表”,每个二维表可称为一个关系,每个关
系有一个关系名。表中的一行称为一个元组;表中的列称为属性,每一列有一个属性名。表中的每一个元组是属性
值的集合,属性是关系二维表中最小的单位,它不能再被划分。关系模式是指一个关系的属性名表,即二维表的表
框架。因此,选项c的说法是正确的。
(18)在数据库系统中,用户所见的数据模式为
A)概念模式 B)外模式
C)内模式 D)物理模式
【答案】B
【解析】数据库管理系统的三级模式结构由外模式、模式和内模式组成。外模式也称子模式或用户模式,是指数据
库用户所看到的数据结构,是用户看到的数据视图。模式也称逻辑模式,是数据库中对全体数据的逻辑结构和特性
的描述。是所有用户所见到的数据视图的总和。内模式也称存储模式或物理模式,是指数据在数据库系统内的存储
介质上的表示,即对数据的物理结构和存取方法的描述。根据上述介绍可知,数据库系统中用户所见到的数据模式
为外模式。因此,本题的正确答案是B。
(19)数据库设计的四个阶段是:需求分析、概念设计、逻辑设计和
A)编码设计 B)测试阶段
C)运行阶段 D)物理设计
【答案】D
【解析】数据库的生命周期可以分为两个阶段: 一是数据库设计阶段;二是数据库实现阶段。数据库的设计阶段
又分为如下四个子阶段:即需求分析、概念设计、逻辑设计和物理设计。因此,本题的正确答案是D。
(20)设有如下三个关系表
R S T
A B C A B C
m 1 3 m 1 3
n n 1 3
下列操作中正确的是A)T=R∩S B)T=R∪S C)T=R×S D)T=R/S
【答案】c
【解析】本题考查数据库的关系代数运算。R 表中只有一个域名A,有两个记录(也叫元组),分别是m和n;s表中
有两个域名,分别是 B和c,其所对应的记录分别为l和3。注意观察表T,它是由R的第一个记录依次与 s的所有
记录组合,然后再由 R的第二个记录与s的所有记录组合,形成的一个新表。上述运算恰恰符合关系代数的笛卡尔
积运算规则。关系代数中,笛卡尔积运算用“×”来表示。因此,上述运算可以表示为 T=R×s。因此,本题的正确
答案为c。
(21)数据库核技术的根本目标是要解决数据的
A)存储问题 B)共享问题
C)安全问题 D)保护问题
【答案】B
【解析】数据库产生的背景就是计算机的应用范围越来越广泛,数据量急剧增加,对数据共享的要求越来越高。共
享的含义是多个用户、多种语言、多个应用程序相互覆盖的使用一些公用的数据集合。在这样的背景下,为了满足
多用户、多应用共享数据的要求,就出现了数据库技术,以便对数据库进行管理。因此,数据库技术的根本目标就
是解决数据的共享问题。故选项B正确。
(22)数据独立性是数据库技术的重要特点之一,所谓数据独立性是指______。
A)数据与程序独立存放
B)不同的数据被存放在不同的文件中
C)不同的数据只能被对应的应用程序所使用
D)以上三种说法都不对
【答案】D
【解析】数据具有两方面的独立性:一是物理独立性。即由于数据的存储结构与逻辑结须有构之间由系统提供映象,
使得当数据的存储结构改变时,其逻辑结构可以不变,因此,基于逻辑结构的应用程序不必修改。二是逻辑独立性。
即由于数据的局部逻辑结构(它是总体逻辑结构的一个子集,由具体的应用程序所确定,并且根据具体的需要可以作
一定的修改)与总体逻辑结构之间也由系统提供映象,使得当总体逻辑结构改变时,其局部逻辑结构可以不变,从而
根据局部逻辑结构编写的应用程序也可以不必修改。综上所述,本题的正确答案是D。
(23)用树形结构表示实体之间联系的模型是______。
A)关系模型 B)网状模型 C)层次模型 D)以上三个都是
【答案】C
【解析】在数据库系统中,由于采用的数据模型不同,相应的数据库管理系统(DBMS)也不同。目前常用的数据模
型有三种:层次模型、网状模型和关系模型。在层次模型中,实体之间的联系是用树结构来表示的,其中实体集(记
录型)是树中的结点,而树中各结点之间的连线表示它们之间的关系。因此,本题的正确答案是 C。
(24)下列关系运算的叙述中,正确的是
A)投影、选择、连接是从二维表行的方向进行的运算
B)并、交、差是从二维表的列的方向来进行运算
C)投影、选择、连接是从二维表列的方向进行的运算D)以上3种说法都不对
解析: 在关系模型的数据语言中,一般除了运用常规的集合运算(并、交、差、笛卡尔积等),还定义了一些专门
的关系运算,如投影、选择、连接等。前者是将关系(即二维表)看成是元组的集合,这些运算主要是从二维表的
行的方向来进行的。后者是从二维表的列的方向来进行运算的。故本题答案应该为选项 C)。
(25)关系数据库管理系统应能实现的专门的关系运算包括
A)排序、索引、统计
B)选择、投影、连接
C)关联、更新、排序
D)显示、打印、制表
解析: 关系数据库建立在关系数据模型基础上,具有严格的数学理论基础。关系数据库对数据的操作除了包括集合
代数的并、差等运算之外,更定义了一组专门的关系运算:连接、选择和投影。关系运算的特点是运算的对象都是
表。故本题答案应该为选项B)。
(26)数据库管理系统DBMS中用来定义模式、内模式和外模式的语言为
A)C
B)Basic
C)DDL
D)DML
解析: 选项A)、B)显然不合题意。数据定义语言(Data Definition Language,简称DDL)负责数据的模式定义
与数据的物理存取构建;数据操纵语言(DataManipulationLanguage,简称DML)负责数据的操纵,包括查询及增、
删、改等操作。故本题答案应该为选项C)。
(27)下列有关数据库的描述,正确的是
A)数据库是一个DBF文件
B)数据库是一个关系
C)数据库是一个结构化的数据集合
D)数据库是一组文件
解析: 数据库(Database,简称DB)是数据的集合,它具有统一的结构形式并存放于统一的存储介质内,是多种应
用数据的集成,并可被各个应用程序所共享。数据库中的数据具有“集成”、“共享”之特点。故本题答案应该为选
项C)。
(28)下列有关数据库的描述,正确的是
A)数据处理是将信息转化为数据的过程
B)数据的物理独立性是指当数据的逻辑结构改变时,数据的存储结构不变
C)关系中的每一列称为元组,一个元组就是一个字段
D)如果一个关系中的属性或属性组并非该关系的关键字,但它是另一个关系的关键字,则称其为本关系的外关键字
解析: 数据处理是指将数据转换成信息的过程,故选项 A)叙述错误;数据的物理独立性是指数据的物理结构的改
变,不会影响数据库的逻辑结构,故选项B)叙述错误;关系中的行称为元组,对应存储文件中的记录,关系中的列
称为属性,对应存储文件中的字段,故选项C)叙述错误。故本题答案应该为选项D)。(29)单个用户使用的数据视图的描述称为
A)外模式
B)概念模式
C)内模式
D)存储模式
解析: 选项A)正确,外模式是用户的数据视图,也就是用户所见到的数据模式;选项 B)不正确,全局数据视图
的描述称为概念模式,即数据库中全部数据的整体逻辑结构的描述;选项C)不正确,物理存储数据视图的描述称为
内模式,即数据库在物理存储方面的描述;选项D)不正确,存储模式即为内模式。
(30)将E-R图转换到关系模式时,实体与联系都可以表示成
A)属性
B)关系
C)键
D)域
解析: 数据库逻辑设计的主要工作是将E-R图转换成指定RDBMS中的关系模式。首先,从E-R图到关系模式的转换
是比较直接的,实体与联系都可以表示成关系,E-R图中属性也可以转换成关系的属性。实体集也可以转换成关系。
故本题答案应该为选项B)。
(31)SQL语言又称为
A)结构化定义语言
B)结构化控制语言
C)结构化查询语言
D)结构化操纵语言
解析: 结构化查询语言(Structured Query Language,简称SQL)是集数据定义、数据操纵和数据控制功能于一体
的数据库语言。故本题答案应该为选项C)。
(32)在数据管理技术发展过程中,文件系统与数据库系统的主要区别是数据库系统具有
A)特定的数据模型
B)数据无冗余
C)数据可共享
D)专门的数据管理软件
解析: 在文件系统中,相互独立的记录其内部结构的最简单形式是等长同格式记录的集合,易造成存储空间大量浪
费,不方便使用。而在数据库系统中,数据是结构化的,这种结构化要求在描述数据时不仅描述数据本身,还要描
述数据间的关系,这正是通过采用特定的数据模型来实现的。故本题答案应该为选项A)。
(33)数据库设计包括两个方面的设计内容,它们是
A)概念设计和逻辑设计
B)模式设计和内模式设计
C)内模式设计和物理设计
D)结构特性设计和行为特性设计答案:A
(34)实体是信息世界中广泛使用的一个术语,它用于表示
A)有生命的事物
B)无生命的事物
C)实际存在的事物
D)一切事物
解析: 实体是客观存在且可以相互区别的事物。实体可以是具体的对象,如一个学生,也可以是一个抽象的事件,
如一次出门旅游等。因此,实体既可以是有生命的事物,也可以是无生命的事物,但它必须是客观存在的,而且可
以相互区别。故本题答案应该为选项C)。
(35)数据库的故障恢复一般是由
A)数据流图完成的
B)数据字典完成的
C)DBA完成的
D)PAD图完成的
解析: 一旦数据库中的数据遭受破坏,需要及时进行恢复,RDBMS一般都提供此种功能,并由DBA负责执行故障恢
复功能。故本题答案应该为选项C)。
(36)下列说法中,不属于数据模型所描述的内容的是
A)数据结构
B)数据操作
C)数据查询
D)数据约束
解析: 数据模型所描述的内容有 3个部分,它们是数据结构、数据操作和数据约束。其中,数据模型中的数据结构
主要描述数据的类型、内容、性质,以及数据库的联系等;数据操作主要是描述在相应数据结构上的操作类型与操
作方式。故本题答案应该为选项C)。
(37)分布式数据库系统不具有的特点是
A)数据分布性和逻辑整体性
B)位置透明性和复制透明性
C)分布性
D)数据冗余
解析: 分布式数据库系统具有数据分布性、逻辑整体性、位置透明性和复制透明性的特点,其数据也是分布的;但
分布式数据库系统中数据经常重复存储,数据也并非必须重复存储,主要视数据的分配模式而定。若分配模式是一
对多,即一个片段分配到多个场地存放,则是冗余的数据库,否则是非冗余的数据库。故本题答案应该为选项D)。
(38)关系表中的每一横行称为一个
A)元组
B)字段
C)属性
D)码解析: 关系表中,每一行称为一个元组,对应表中的一条记录;每一列称为表中的一个属性,对应表中的一个字段;
在二维表中凡能惟一标识元组的最小属性集称为该表的键或码。故本题答案应该为选项 A)。
(39)下列数据模型中,具有坚实理论基础的是
A)层次模型
B)网状模型
C)关系模型
D)以上3个都是
解析: 关系模型较之格式化模型(网状模型和层次模型)有以下方面的优点,即数据结构比较简单、具有很高的数
据独立性、可以直接处理多对多的联系,以及有坚实的理论基础。故本题答案应该为选项 C)。
(40)应用数据库的主要目的是
A)解决数据保密问题
B)解决数据完整性问题
C)解决数据共享问题
D)解决数据量大的问题
解析: 数据库中的数据具有"集成"与"共享"的特点,亦即是数据库集中了各种应用的数据,进行统一构造与存储,
而使它们可以被不同应用程序所使用,故选项C)正确。
(41)在数据库设计中,将E-R图转换成关系数据模型的过程属于
A)需求分析阶段
B)逻辑设计阶段
C)概念设计阶段
D)物理设计阶段
解析: E-R模型即实体-联系模型,是将现实世界的要求转化成实体、联系、属性等几个基本概念,以及它们之间的
两种联接关系。数据库逻辑设计阶段包括以下几个过程:从 E-R图向关系模式转换,逻辑模式规范化及调整、实现
规范化和RDBMS,以及关系视图设计。故本题答案应该为选项B)。
(42)在数据管理技术的发展过程中,经历了人工管理阶段、文件系统阶段和数据库系统阶段。其中数据独立性最
高的阶段是
A)数据库系统
B)文件系统
C)人工管理
D)数据项管理
解析: 人工管理阶段是在20世纪50年代中期以前出现的,数据不独立,完全依赖于程序;文件系统是数据库系统
发展的初级阶段,数据独立性差;数据库系统具有高度的物理独立性和一定的逻辑独立性。故本题答案应该为选项A)。
(43)下列4项中说法不正确的是
A)数据库减少了数据冗余
B)数据库中的数据可以共享
C)数据库避免了一切数据的重复
D)数据库具有较高的数据独立性解析: 数据库系统具有以下几个特点,一是数据的集成性、二是数据的高共享性与低冗余性、三是数据的独立性、
四是数据统一管理与控制。故本题答案应该为选项C)。
(44)下列4项中,必须进行查询优化的是
A)关系数据库
B)网状数据库
C)层次数据库
D)非关系模型
解析: 关系数据模型诞生之后迅速发展,深受用户喜爱,但关系数据模型也有缺点,其最主要的缺点是由于存取路
径对用户透明,查询效率往往不如非关系数据模型,因此为了提高性能,必须对用户的查询请求进行优化。故本题
答案应该为选项A)。
(45) 最常用的一种基本数据模型是关系数据模型,它的表示应采用
A)树
B)网络
C)图
D)二维表
解析: 关系数据模型用统一的二维表结构表示实体及实体之间的联系(即关系)。故本题答案应该为选项D)。
(8)数据库是()的集合,它具有统一的结构格式并存放于统一的存储介质,可被各个应用程序所共享。
A)视图
B)消息
C)数据
D)关系
【答案】C
【解析】数据库是数据的集合,其中的数据是按数据所提供的数据模式存放的,它能构造复杂的数据结构,以建立
数据之间的内在联系与复杂的关系。
(9)下列叙述中,不正确的是
A)数据库技术的根本目标是要解决数据共享的问题
B)数据库系统中,数据的物理结构必须与逻辑结构一致
C)数据库设计是指设计一个能满足用户要求,性能良好的数据库
D)数据库系统是一个独立的系统,但是需要操作系统的支持
【答案】B
【解析】数据库应该具有物理独立性和逻辑独立性,改变其一而不影响另一个。
(10)规范化理论中,分解()是消除其中多余的数据相关性。
A)关系运算
B)内模式
C)外模式
D)视图
【答案】A【解析】数据库规范化的基本思想是逐步消除数据依赖中不合适的部分,根本思想是通过分解关系运算来消除多余
的数据相关性。
(8)在数据管理技术发展过程中,文件系统与数据库系统的主要区别是数据库系统具有______。
A)数据无冗余 B)数据可共享
C)专门的数据管理软件 D)特定的数据模型
答案:D
评析:在文件系统中,相互独立的记录其内部结构的最简单形式是等长同格式记录的集合,易造成存储空间大量浪
费,不方便使用。而在数据库系统中,数据是结构化的,这种结构化要求在描述数据时不仅描述数据本身,还要描
述数据间的关系,这正是通过采用特定的数据模型来实现的。
(9)分布式数据库系统不具有的特点是______。
A)分布式 B)数据冗余
C)数据分布性和逻辑整体性 D)位置透明性和复制透明性
答案:B
评析:分布式数据库系统具有数据分布性、逻辑整体性、位置透明性和复制透明性的特点,其数据也是分布的;但
分布式数据库系统中数据经常重复存储,数据也并非必须重复存储,主要视数据的分配模式而定。若分配模式是一
对多,即一个片段分配到多个场地存放,则是冗余的数据库,否则是非冗余的数据库。
(10)下列说法中,不属于数据模型所描述的内容的是______。
A)数据结构 B)数据操作
C)数据查询 D)数据约束
答案:C
评析:数据模型所描述的内容有 3个部分,它们是数据结构、数据操作和数据约束。其中,数据模型中的数据结构
主要描述数据的类型、内容、性质,以及数据库的联系等;数据操作主要是描述在相应数据结构上的操作类型与操
作方式。
9. 下列有关数据库的描述,正确的是______。
A、数据库是一个DBF文件
B、数据库是一个关系
C、数据库是一个结构化的数据集合
D、数据库是一组文件
解析:数据库(Database,简称DB)是数据的集合,它具有统一的结构形式并存放于统一的存储介质内,是多种应用
数据的集成,并可被各个应用程序所共享。数据库中的数据具有"集成"、"共享"之特点。
本题答案为C。
10. 下列说法中,不属于数据模型所描述的内容的是______。
A、数据结构
B、数据操作
C、数据查询
D、数据约束
解析:数据模型所描述的内容有3个部分,它们是数据结构、数据操作和数据约束。其中,数据模型中的数据结构主
要描述数据的类型、内容、性质,以及数据库的联系等;数据操作主要是描述在相应数据结构上的操作类型与操作
方式。本题答案为C。
8. 视图设计一般有3种设计次序,下列不属于视图设计的是______。
A、自顶向下
B、由外向内
C、由内向外
D、自底向上
解析:视图设计一般有3种设计次序,它们分别是自顶向下、自底向上和由内向外,它们又为视图设计提供了具体的
操作方法,设计者可根据实际情况灵活掌握,可以单独使用也可混合使用。
本题答案为B。
5. 在关系数据库中,用来表示实体之间联系的是______。
A、树结构
B、网结构
C、线性表
D、二维表
解析:在关系数据库中,用二维表来表示实体之间联系。
本题答案为D。
6. 将E-R图转换到关系模式时,实体与联系都可以表示成______。
A、属性
B、关系
C、键
D、域
解析:关系是由若干个不同的元组所组成,因此关系可视为元组的集合,将E-R图转换到关系模式时,实体与联系都
可以表示成关系。
本题答案为B。
10. 数据处理的最小单位是______。
A、数据
B、数据元素
C、数据项
D、数据结构
解析:数据处理的最小单位是数据项;由若干数据项组成数据元素;而数据是指能够被计算机识别、存储和加工处理
的信息载体;数据结构是指数据之间的相互关系和数据运算。
本题答案为C。
1. 用树形结构来表示实体之间联系的模型称为______。
A、关系模型
B、层次模型
C、网状模型
D、数据模型
解析:层次模型是最早发展出来的数据库模型。它的基本结构是树形结构,这种结构方式在现实世界中很普遍,如家
族结构、行政组织机构,它们自顶向下、层次分明。
本题答案为B。
4. 按条件f对关系R进行选择,其关系代数表达式为______。
A、B、
C、б(R)
f
D、∏(R)
f
解析:选择运算是一个一元运算,关系R通过选择运算(并由该运算给出所选择的逻辑条件)后仍为一个关系。这个
关系是由R中那些满足逻辑条件的元组所组成。如果关系的逻辑条件为 f,则R满足f的选择运算可以写成:б(R)。
f
本题答案为C。
8. 单个用户使用的数据视图的描述称为______。
A、外模式
B、概念模式
C、内模式
D、存储模式
解析: 外模式是用户的数据视图,也就是用户所见到的数据模式;全局数据视图的描述称为概念模式,即数据库中
全部数据的整体逻辑结构的描述;物理存储数据视图的描述称为内模式,即数据库在物理存储方面的描述;存储模
式即为内模式。
本题答案为A。
9. 数据独立性是数据库技术的重要特点之一,所谓数据独立性是指______。
A、数据与程序独立存放
B、不同的数据被存放在不同的文件中
C、不同的数据只能被对应的应用程序所使用
D、以上三种说法都不对
解析:本题考查的是数据库系统的基本特点。
数据独立性是数据与程序间的互不依赖性,即数据库中数据独立于应用程序而不依赖于应用程序。也就是说,
数据的逻辑结构、存储结构与存取方式的改变不会影响应用程序。选项A、B、C三种说法都是错误的。
故本题答案为D。
10. 用树形结构表示实体之间联系的模型是______。
A、关系模型
B、网状模型
C、层次模型
D、以上三个都是
解析:本题考查的是数据模型。
层次模型是最早发展起来的数据库模型,它的基本结构是树形结构。
故本题答案为C。
8. 下述关于数据库系统的叙述中正确的是______。
A、数据库系统减少了数据冗余
B、数据库系统避免了一切冗余
C、数据库系统中数据的一致性是指数据类型的一致
D、数据库系统比文件系统能管理更多的数据
解析:由于数据的集成性使得数据可为多个应用所共享,特别是在网络发达的今天,数据库与网络的结合扩大了数据
关系的应用范围。数据的共享自身又可极大地减少数据冗余性,不仅减少了不必要的存储空间,更为重要的是可以
避免数据的不一致性。所谓数据的一致性是指在系统中同一数据的不同出现应保持相同的值,而数据的不一致性指的是同一个数据在系统的不同拷贝处有不同的值。
本题答案是A。
9. 关系表中的每一横行称为一个______。
A、元组
B、字段
C、属性
D、码
解析:在关系数据库中,关系模型采用二维表来表示,简称"表"。二维表是由表框架及表元组组成。
在表框架中,按行可以存放数据,每行数据称为元组。
本题答案是A。
10. 数据库设计包括两个方面的设计内容,它们是______。
A、概念设计和逻辑设计
B、模式设计和内模式设计
C、内模式设计和物理设计
D、结构特性设计和行为特性设计
解析: 数据库设计可分为概念设计与逻辑设计。
数据库概念设计的目的是分析数据间内在语义关联,在此基础上建立一个数据的抽象模型。
数据库逻辑设计的主要工作是将ER图转换为指定的RDBMS中的关系模型。
本题答案是A。
8. 在数据管理技术的发展过程中,经历了人工管理阶段、文件系统阶段和数据库系统阶段。其中数据独立性最高的
阶段是______。
A、数据库系统
B、文件系统
C、人工管理
D、数据项管理
解析:在数据管理技术的发展过程中,经历了人工管理阶段、文件系统阶段和数据库系统阶段。其中数据独立性最高
的阶段是数据库系统。
本题答案为A。
9. 用树形结构来表示实体之间联系的模型称为______。
A、关系模型
B、层次模型
C、网状模型
D、数据模型
解析:层次模型是最早发展出来的数据库模型。它的基本结构是树形结构,这种结构方式在现实世界中很普遍,如家
族结构、行政组织机构,它们自顶向下、层次分明。
本题答案为B。
10. 关系数据库管理系统能实现的专门关系运算包括______。
A、排序、索引、统计B、选择、投影、连接
C、关联、更新、排序
D、显示、打印、制表
解析:关系数据库管理系统能实现的专门关系运算,包括选择运算、投影运算、连接运算。
本题答案为B。
8. 索引属于______。
A、模式
B、内模式
C、外模式
D、概念模式
解析: 内模式(Internal Schema)又称物理模式(Physical Schema),它给出了数据库物理存储结构与物理存
取方法,如数据存储的文件结构、索引、集簇及hash等存取方式与存取路径。
本题答案为B。
9. 在关系数据库中,用来表示实体之间联系的是______。
A、树结构
B、网结构
C、线性表
D、二维表
解析:在关系数据库中,用二维表来表示实体之间联系。
本题答案为D。
10. 将E-R图转换到关系模式时,实体与联系都可以表示成______。
A、属性
B、关系
C、键
D、域
解析:关系是由若干个不同的元组所组成,因此关系可视为元组的集合,将E-R图转换到关系模式时,实体与联系都
可以表示成关系。
本题答案为B。
9. SQL语言又称为______。
A、结构化定义语言
B、结构化控制语言
C、结构化查询语言
D、结构化操纵语言
解析:结构化查询语言(Structured Query Language,简称SQL)是集数据定义、数据操纵和数据控制功能于一体的
数据库语言。
本题答案为C。
10. 视图设计一般有3种设计次序,下列不属于视图设计的是______。
A、自顶向下
B、由外向内
C、由内向外
D、自底向上解析:视图设计一般有3种设计次序,它们分别是自顶向下、自底向上和由内向外,它们又为视图设计提供了具体的
操作方法,设计者可根据实际情况灵活掌握,可以单独使用也可混合使用。
本题答案为B。
7. 数据处理的最小单位是______。
A、数据
B、数据元素
C、数据项
D、数据结构
解析:数据处理的最小单位是数据项;由若干数据项组成数据元素;而数据是指能够被计算机识别、存储和加工处理
的信息载体;数据结构是指数据之间的相互关系和数据运算。
本题答案为C。
8. 下列有关数据库的描述,正确的是______。
A、数据库是一个DBF文件
B、数据库是一个关系
C、数据库是一个结构化的数据集合
D、数据库是一组文件
解析:数据库(Database,简称DB)是数据的集合,它具有统一的结构形式并存放于统一的存储介质内,是多种应用
数据的集成,并可被各个应用程序所共享。数据库中的数据具有"集成"、"共享"之特点。
本题答案为C。
9. 单个用户使用的数据视图的描述称为______。
A、外模式
B、概念模式
C、内模式
D、存储模式
解析: 外模式是用户的数据视图,也就是用户所见到的数据模式;全局数据视图的描述称为概念模式,即数据库
中全部数据的整体逻辑结构的描述;物理存储数据视图的描述称为内模式,即数据库在物理存储方面的描述;存储
模式即为内模式。
本题答案为A。
4. 关系数据库管理系统能实现的专门关系运算包括______。
A、排序、索引、统计
B、选择、投影、连接
C、关联、更新、排序
D、显示、打印、制表
解析:关系数据库管理系统能实现的专门关系运算,包括选择运算、投影运算、连接运算。
本题答案为B。
6. 数据库概念设计的过程中,视图设计一般有三种设计次序,以下各项中不对的是______。
A、自顶向下
B、由底向上
C、由内向外
D、由整体到局部
解析:数据库概念设计的过程中,视图设计一般有三种设计次序,它们是:
1)自顶向下。这种方法是先从抽象级别高且普遍性强的对象开始逐步细化、具体化与特殊化。2)由底向上。这种设计方法是先从具体的对象开始,逐步抽象,普遍化与一般化,最后形成一个完整的视图设
计。
3)由内向外。这种设计方法是先从最基本与最明显的对象着手逐步扩充至非基本、不明显的其它对象。
本题答案为D。
10. 在数据管理技术发展过程中,文件系统与数据库系统的主要区别是数据库系统具有______。
A、数据无冗余
B、数据可共享
C、专门的数据管理软件
D、特定的数据模型
解析:在文件系统中,相互独立的记录其内部结构的最简单形式是等长同格式记录的集合,易造成存储空间大量浪费,
不方便使用。而在数据库系统中,数据是结构化的,这种结构化要求在描述数据时不仅描述数据本身,还要描述数
据间的关系,这正是通过采用特定的数据模型来实现的。
本题答案为D。
二、填空题
(1)在关系数据库中,把数据表示成二维表,每一个二维表称为 __ 。
【答案】关系或关系表
【解析】在关系模型中,把数据看成一个二维表,每一个二维表称为一个关系。表中的每一列称为一个属性,相当
于记录中的一个数据项,对属性的命名称为属性名,表中的一行称为一个元组,相当于记录值。
(2)在关系模型中,把数据看成是二维表,每一个二维表称为一个 ____ 。
【答案】关系或关系表
【解析】在关系模型中,把数据看成一个二维表,每一个二维表称为一个关系。因此,本题的正确答案是关系。
(3)数据管理技术发展过程经过人工管理、文件系统和数据库系统三个阶段,其中数据独立性最高的阶段是______ 。
【答案】数据库系统或数据库系统阶段或数据库或数据库阶段或数据库管理技术阶段
【解析】在数据库系统管理阶段,数据是结构化的,是面向系统的,数据的冗余度小,从而节省了数据的存储空间,
也减少了对数据的存取时间,提高了访问效率.避免了数据的不一致性,同时提高了数据的可扩充性和数据应用
的灵活性;数据具有独立性,通过系统提供的映象功能,使数据具有两方面的独立性:一是物理独立性,二是逻
辑独立性;保证了数据的完整性、安全性和并发性。综上所述,数据独立性最高的阶段是数据库系统管理阶段。
(4)一个关系表的行称为 ___ 。
【答案】 记录 或 元组
【解析】关系是关系数据模型的核心。关系可以用一个表来直观的表示,表的每一列表示关系的一个属性,每一行
表示一个元组或记录。因此,本题的正确答案是元组或记录。
(5) 在数据库系统中,实现各种数据管理功能的核心软件称为 ____ 。
【答案】数据库管理系统或DBMS
【解析】数据库管理系统(Database Management System,DBMS)是一种操纵和管理数据库的大型软件,是用于建立、
使用和维护数据库,简称DBMS。它对数据库进行统一的管理和控制,以保证数据库的安全性和完整性。用户通过DBMS访问数据库中的数据,数据库管理员也通过DBMS进行数据库的维护工作。它提供多种功能,可使多个应用程序和用
户用不同的方法在同时或不同时刻去建立,修改和询问数据库。因此,数据库系统中,数据库管理系统是实现各种
数据管理功能的核心软件。本题的答案是数据库管理系统或DBMS。
(6) 在E-R图中,矩形表示______ 。
【答案】实体或实体集或Entity
【解析】本题考查数据库的E-R图。E-R模型中,有三个基本的抽象概念:实体、联系和属性。E-R 图是E-R模型的
图形表示法,在E-R图中,用矩形框表示实体,菱形框表示联系,椭圆形框表示属性。因此,划线处应填入“实体”
或“实体集”或“Entity”。
(7)数据独立性分为逻辑独立性与物理独立性。当数据的存储结构改变时,其逻辑结构可以不变,因此,基于逻辑结
构的应用程序不必修改,称为 ____ 。
【答案】物理独立性
【解析】数据独立性分为逻辑独立性与物理独立性。当数据的存储结构改变时,其逻辑结构可以不变,因此,基于
逻辑结构的应用程序不必修改,称为物理独立性。
(8)实体之间的联系可以归结为一对一联系、一对多(或多对多)的联系与多对多联系。如果一个学校有许多教师,
而一个教师只归属于一个学校,则实体集学校与实体集教师之间的联系属于 的联系。
答案:一对多
(9)数据库管理系统常见的数据模型有层次模型、网状模型和 3种。
答案:关系模型
解析: 数据库管理系统是位于用户与操作系统之间的一层系统管理软件,是一种系统软件,是用户与数据库之间的
一个标准接口。其总是基于某种数据模型,可以分为层次模型、网状模型和关系模型。
(10)一个项目具有一个项目主管,一个项目主管可管理多个项目,则实体“项目主管”与实体“项目”的联系属
于 的联系。
答案:一对多(1∶N)
解析: 两个实体集间的联系实际上是实体集间的函数关系,这种函数关系可以有 3种,即一对一(1∶1)的联系、
一对多(1∶N)或多对一(N∶1)的联系和多对多(N∶N)的联系。
(11)数据库设计分为以下6个设计阶段:需求分析阶段、 、逻辑设计阶段、物理设计阶段、实施
阶段、运行和维护阶段。
答案:概念设计阶段
解析:数据库设计分为以下 6个设计阶段:需求分析阶段、概念设计阶段、逻辑设计阶段、物理设计阶段、实施阶
段及数据库运行和维护阶段。
(12)关键字ASC和DESC分别表示 的含义。
答案:ASC表示升序排列,DESC表示降序排列
解析: ASC表示升序排列,DESC表示降序排列,多用在索引定义和SELECT语句中的ORDER子句中。
(13)关系数据库的关系演算语言是以 为基础的DML语言。
答案:谓词演算
解析: 关系数据库中的关系演算包括元组关系演算和域关系演算。二者都是由原子公式组成的公式。而这些关系演
算都是以数理逻辑中的谓词演算为基础的。(14) 是数据库设计的核心。
答案:数据模型
解析: 数据模型是对客观事物及联系的数据描述,它反映了实体内部及实体与实体之间的联系。因此,数据模型是
数据库设计的核心。
(15)在关系模型中,把数据看成一个二维表,每一个二维表称为一个 。
答案:关系
解析: 在关系模型中,把数据看成一个二维表,每一个二维表称为一个关系。表中的每一列称为一个属性,相当于
记录中的一个数据项,对属性的命名称为属性名;表中的一行称为一个元组,相当于记录值。
(16)关系操作的特点是 操作。
答案:集合操作
解析: 在关系操作中,所有操作对象与操作结果都是关系。而关系定义为元数相同的元组的集合。因此,关系操作
的特点是集合操作。
(17)数据库恢复是将数据库从 状态恢复到某一已知的正确状态。
答案:错误状态
解析: 数据库恢复是将数据库中的数据从错误状态中恢复到某种逻辑一致的状态。如果数据库中包含成功事务提交
的结果,则称数据库处于一致性状态。
(18)数据的基本单位是 。
解析:数据元素
(4)在数据库理论中,数据物理结构的改变,如存储设备的更换、物理存储的更换、存取方式等都不影响数据库的
逻辑结构,从而不引起应用程序的变化,称为【4】 。
【答案】物理独立性
【解析】数据的物理结构改变,不影响数据库的逻辑结构,从而不引起应用程序的变化,这种性质叫做物理独立性。
51. 数据的逻辑结构在计算机存储空间中的存放形式称为数据的______。
解析:模式也称逻辑模式或概念模式,是数据库中全体数据的逻辑结构和特征的描述,是所有用户的公共数据视图。
例如数据记录由哪些数据项构成,数据项的名字、类型、取值范围等。
外模式是模式的子集,所以也称子模式或用户模式,是数据库用户能够看见的和使用的、局部的逻辑结构和特
征的描述,是与某一应用有关的数据的逻辑表示。
内模式也称物理模式或存储模式。一个数据库只有一个内模式,它是数据物理结构和存储方式的描述,是数据库
内部的表示方法。例如,记录的存储方式是顺序存储、索引按照什么方式组织;数据是否压缩存储,是否加密等。
标准答案为:模式 或 逻辑模式 或 概念模式
54. 数据库设计分为以下 6个设计阶段:需求分析阶段、______、逻辑设计阶段、物理设计阶段、实施阶段、运行
和维护阶段。
解析:数据库设计分为以下6个设计阶段:需求分析阶段、概念设计阶段、逻辑设计阶段、物理设计阶段、实施阶段
及数据库运行和维护阶段。
标准答案为:概念设计阶段或 数据库概念设计阶段
55. 数据库保护分为:安全性控制 、______、并发性控制和数据的恢复。
解析:考查考生对数据库基本知识的了解。
安全性控制:防止未经授权的用户有意或无意存取数据库中的数据,以免数据被泄露、更改或破坏;完整性控制:保证数据库中数据及语义的正确性和有效性,防止任何对数据造成错误的操作;并发控制:正确处理好多用户、多
任务环境下的并发操作,防止错误发生;恢复:当数据库被破坏或数据不正确时,使数据库能恢复到正确的状态。
标准答案为:完整性控制
54. 关系模型的完整性规则是对关系的某种约束条件,包括实体完整性、______和自定义完整性。
标准答案为:参照完整性
解析:关系模型允许定义三类数据约束,它们是实体完整性、参照完整性以及用户定义的完整性约束,其中前两种完
整性约束由关系数据库系统自动支持。
实体完整性约束要求关系的主键中属性值不能为空,这是数据库完整性的最基本要求,因为主键是惟一决定元
组的,如为空则其惟一性就成为不可能的了。
参照完整性约束是关系之间相关联的基本约束,它不允许关系引用不存在的元组:即在关系中的外键要么是所
关联关系中实际存在的元组,要么是空值。
自定义完整性是针对具体数据环境与应用环境由用户具体设置的约束,它反映了具体应用中数据的语义要求。
55. 数据模型按不同的应用层次分为三种类型,它们是______数据模型、逻辑数据模型和物理数据模型。
标准答案为:概念
解析:数据模型按不同的应用层次分为三种类型,它们是概念数据模型、逻辑数据模型和物理数据模型。
概念数据模型简称概念模型,它是一种面向客观世界、面向用户的模型;它与具体的数据库管理系统无关。
逻辑数据模型又称数据模型,它是一种面向数据库系统的模型,该模型着重于在数据库系统一级的实现。
物理数据模型又称物理模型,它是一种面向计算机物理表示的模型,此模型给出了数据模型在计算机上物理结构的
表示。
(5)数据库管理系统是位于用户与【5】之间的软件系统。
【答案】操作系统
【解析】数据库管理系统是帮助用户创建和管理数据库的应用程序的集合。因此,数据库管理系统需要操作系统的
支持,为用户提供服务。
(4)一个项目具有一个项目主管,一个项目主管可管理多个项目,则实体“项目主管”与实体“项目”的联系属于
【4】 的联系。
答案:1对多 或 1:N
评析:两个实体集间的联系实际上是实体集间的函数关系,这种函数关系可以有 3种,即一对一(1∶1)的联系、
一对多(1∶N)或多对一(N∶1)的联系和多对多(N∶N)的联系。
(5)数据库管理系统常见的数据模型有层次模型、网状模型和 【5】 三种。
答案:关系模型
评析:数据库管理系统是位于用户与操作系统之间的一层系统管理软件,是一种系统软件,是用户与数据库之间的
一个标准接口,其总是基于某种数据模型,可以分为层次模型、网状模型和关系模型。
52. 数据库系统的三级模式分别为______模式、内部级模式与外部级模式。
解析:数据库系统在其内部具有三级模式及二级映射,三级模式分别是概念级模式、内部级模式和外部级模式。
概念模式是数据库系统中全局数据逻辑结构的描述,是全体用户(应用)公共数据视图。
内模式又称物理模式,它给出了数据库物理存储结构与物理存取方法,如数据存储的文件结构、索引、集簇及
hash等存取方式与存取路径,内模式的物理性主要体现在操作系统及文件级上,它还未深入到设备级上(如磁盘及
磁盘操作)。外模式也称子模式或用户模式,它是用户的数据视图,也就是用户所见到的数据模式,它由概念模式推导而出。
标准答案为:概念或 概念级
55. 关系模型的数据操纵即是建立在关系上的数据操纵,一般有______、增加、删除和修改四种操作。
解析: 关系模型的数据操纵即是建立在关系上的数据操纵,一般有查询、增加、删除和修改四种操作。
数据查询:用户可以查询关系数据库中的数据,它包括一个关系内的查询以及多个关系间的查询。
数据删除的基本单位是一个关系内的元组,它的功能是将指定关系内的指定元组删除。
数据插入仅对一个关系而言,在指定关系中插入一个或多个元组。
数据修改是在一个关系中修改指定的元组和属性。
标准答案为:查询
55. 一个项目具有一个项目主管,一个项目主管可管理多个项目,则实体"项目主管"与实体"项目"的联系属于______
的联系。
解析:两个实体集间的联系实际上是实体集间的函数关系,这种函数关系可以有 3种,即一对一(1∶1)的联系、一
对多(1∶N)或多对一(N∶1)的联系和多对多(N∶N)的联系。
标准答案为:一对多或 1对多 或 一对n 或 1:N 或 1:n 或 1:n 或 1:N 或 一对m 或 1:M 或 1:m 或 1:m 或
1:N
51. 如果一个工人可管理多个设施,而一个设施只被一个工人管理,则实体"工人"与实体"设备"之间存在______联
系。
标准答案为:一对多或 1对多 或 一对n 或 1:N 或 1:n 或 1:n 或 1:N 或 一对m 或 1:M 或 1:m 或 1:m 或
1:N
解析:实体之间的对应关系称为联系,它反映现实世界事物之间的相互关联。两个实体间的联系可以归结为三种类型:
一对一联系表现为某一实体与另一实体一一对应相关联;一对多联系表现为某一实体与相关多个实体相关联;多对
多联系表现为多个实体与相关多个实体相联系。
54. 在关系数据库中,把数据表示成二维表,每一个二维表称为 。
标准答案为:关系或 一个关系 本题考查的是关系数据模型。
解析:在关系数据库中,把数据表示成二维表,而一个二维表就是一个关系。
54. 数据库系统的三级模式分别为______模式、内部级模式与外部级模式。
标准答案为:概念或 概念级
解析:数据库系统在其内部具有三级模式及二级映射,三级模式分别是概念级模式、内部级模式和外部级模式。
概念模式是数据库系统中全局数据逻辑结构的描述,是全体用户(应用)公共数据视图。
内模式又称物理模式,它给出了数据库物理存储结构与物理存取方法,如数据存储的文件结构、索引、集簇及
hash等存取方式与存取路径,内模式的物理性主要体现在操作系统及文件级上,它还未深入到设备级上(如磁盘及
磁盘操作)。
外模式也称子模式或用户模式,它是用户的数据视图,也就是用户所见到的数据模式,它由概念模式推导而出。
54. 软件的需求分析阶段的工作,可以概括为四个方面:______、需求分析、编写需求规格说明书和需求评审。
标准答案为:需求获取
解析:软件的需求分析阶段的工作,可以概括为四个方面:需求获取、需求分析、编写需求规格说明书和需求评审。
需求获取的目的是确定对目标系统的各方面需求。涉及到的主要任务是建立获取用户需求的方法框架,并支持
和监控需求获取的过程。
需求分析是对获取的需求进行分析和综合,最终给出系统的解决方案和目标系统的逻辑模型。
编写需求规格说明书作为需求分析的阶段成果,可以为用户、分析人员和设计人员之间的交流提供方便,可以
直接支持目标软件系统的确认,又可以作为控制软件开发进度的依据。
需求评审是对需求分析阶段的工作进行的复审,验证需求文档的一致性、可行性、完整性和有效性。55. ______是数据库应用的核心。
标准答案为:数据库设计
解析:数据库设计是数据库应用的核心。在数据库应用系统中的一个核心问题就是设计一个能满足用户要求,性能良
好的数据库,这就是数据库设计。
第 2222 章:计算机网络习题
一、单项选择题
1、 一座大楼内的一个计算机网络系统,属于 B
A、 PAN B、LAN C、MAN D、 WAN
2、 计算机网络中可以共享的资源包括 A
A、硬件、软件、数据、通信信道 B、主机、外设、软件、通信信道
C、硬件、程序、数据、通信信道 D、主机、程序、数据、通信信道
3、 网络协议主要要素为 C
A、数据格式、编码、信号电平 B、数据格式、控制信息、速度匹配
C、语法、语义、同步 D、编码、控制信息、同步
4、 采用专用线路通信时,可以省去的通信阶段是 A
A、建立通信线路 B、建立数据传输链路
C、传送通信控制信号和数据 D、双方确认通信结束
5、 通信系统必须具备的三个基本要素是 C
A、终端、电缆、计算机 B、信号发生器、通信线路、信号接收设备
C、信源、通信媒体、信宿 D、终端、通信设施、接收设备
6、 宽带传输通常使用的速率为 C
A、0~10Mbit/s B. 1~2.5Mbit/s C. 5~10Mbit/s D. 0~400Mbit/s
7、 计算机网络通信系统是 D
A、电信号传输系统 B、文字通信系统 C、信号通信系统 D、数据通信系统
8、 网络接口卡的基本功能包括:数据转换、通信服务和 B
A、数据传输 B、数据缓存 C、数据服务 D、数据共享
9、 完成通信线路的设置与拆除的通信设备是 C
A、线路控制器 B、调制解调器 C、通信控制器 D、多路复用器
10、 在星型局域网结构中,连接文件服务器与工作站的设备是 D
A、调制解调器 B、交换器 C、路由器 D、集线器
11、 在OSI七层结构模型中,处于数据链路层与运输层之间的是(B)
A、物理层 B、网络层 C、会话层 D、表示层
12、 完成路径选择功能是在OSI模型的 C
A、物理层 B、数据链路层 C、网络层 D、运输层
13、 下列功能中,属于表示层提供的是 D
A、交互管理 B、透明传输 C、死锁处理 D、文本压缩
14、 TCP/IP协议簇的层次中,解决计算机之间通信问题是在 B
A、网络接口层 B、网际层 C、传输层 D、应用层
15、 对局域网来说,网络控制的核心是 C
A、工作站 B、网卡 C、网络服务器 D、网络互连设备
16、 在中继系统中,中继器处于 AA、物理层 B、数据链路层 C、网络层 D、高层
17、 各种网络在物理层互连时要求 A
A、数据传输率和链路协议都相同 B、数据传输率相同,链路协议可不同
C、数据传输率可不同,链路协议相同 D、数据传输率和链路协议都可不同
18、 网络管理系统中,管理对象是指 D
A、网络系统中各种具体设备 B、网络系统中各种具体软件
C、网络系统中各类管理人员 D、网络系统中具体可以操作的数据
19、 Intranet技术主要由一系列的组件和技术构成,Intranet的网络协议核心是 C
A、ISP/SPX B、PPP C、TCP/IP D、SLIP
20、 网络管理信息系统的分析设计以 B
A、功能模块设计为中心 B、数据分析为中心
C、系统拓扑结构设计为中心 D、系统规模分析为中心
21、 市话网在数据传输期间,在源节点与目的节点之间有一条利用中间节点构成的物理连接线路。这种市话网采
用 B 技术。
A、报文交换 B、电路交换 C、分组交换 D、数据交换
22、 在点到点的数据传输时钟同步中,外同步法是指接收端的同步信号是由 C
A、自己产生的 B、信息中提取出来的
C、发送端送来的 D、接收端送来的
23、 在数据通信中,当发送数据出现差错时,发送端无须进行数据重发的差错控制方法为 B
A、ARQ B、FEC C、BEC D、CRC
24、 Internet的网络层含有四个重要的协议,分别为 C
A、IP,ICMP,ARP,UDP B、TCP,ICMP,UDP,ARP
C、IP,ICMP,ARP,RARP D、UDP,IP,ICMP,RARP
25、 LAN参考模型可分为物理层、 A
A、MAC,LLC等三层 B、LLC,MHS等三层
C、MAC,FTAM等三层 D、LLC,VT等三层
26、 在码元速率为1600波特的调制解调器中,采用8PSK(8相位)技术,可获得的数据速率为 B
A、2400bps B、4800bps C、9600bps D、1200bps
27、 IBM PC BSC 通信适配器主要是为 A
A、半双工传输线路设计的 B、单工传输线路设计的
C、全双工传输线路设计的 D、混合传输线路设计的
28、 HDLC的帧格式中,帧校验序列字段占 C
A、1个比特B、8个比特 C、16个比特 D、24个比特
29、 ANSI的高级通信控制过程ADCCP是 B
A、面向字符型的同步协议 B、面向比特型的同步协议
C、面向字计数的同步协议 D、异步协议
30、 在网络层中,可以采用有效的办法防止阻塞现象的发生。在阻塞控制方法中,直接对通信子网中分组的数量
进行严格、精确的限制,以防止阴塞现象发生的方法为 C
A、缓冲区预分配法 B、分组丢弃法 C、定额控制法 D、存储转发法
31、 X.25分组头用于网络控制,其长度随分组类型不同而有所不同,但到少包含前 B
A、四个 B、三个 C、五个 D、八个
32、 OSI应用层,在进行文件传输时,为了避免不同文件结构之间的映射、转换等问题,需采用的方案为 B
A、系统文件 B、虚拟文件 C、实际文件 D、索引文件
33、 OSI运输层中差错恢复和多路复用级属于运输层协议等级的级别 DA、0 B、1 C、2 D、3
34、 Netware 386 网络系统中,安装只使用常规内存的DOS工作站,所使用的信息重定向文件是 A
A、NEXT.COM B、IPX.COM C、EMSNEXT.EXE D、XMSNEXT.EXE
35、 在局域网参考模型中,两个系统的同等实体按协议进行通信。在一个系统中,上下层之间则通过接口进行通
信,用 B 来定义接口。
A、服务原语 B、服务访问点 C、服务数据单元 D、协议数据单元
36、 ALOHA网是一个报文分组 C 网。
A、光纤 B、双绞线 C、无线 D、同轴电缆
37、 在DQDB双总线子网的访问控制中能够提供等时服务的媒体访问控制协议是 B
A、载波监听多路访问 B、预先仲裁访问
C、分布式排队访问 D、时分多址访问
38、 令牌总线的媒体访问控制方法是由 C 定义的。
A、IEEE 802.2 B、IEEE 802.3 C、IEEE 802.4 D、IEEE 802.5
39、 MAC层是__D__所特有的。
A.局域网和广域网 B.城域网和广域网
C.城域网和远程网 D.局域网和城域网
40、 CSMA的非坚持协议中,当站点侦听到总线媒体空闲时,它是__B_
A.以概率P传送 B.马上传送
C.以概率(1-P)传送 D.以概率P延迟一个时间单位后传送
41、 在CSMA的非坚持协议中,当媒体忙时,则__C___直到媒体空闲。
A.延迟一个固定的时间单位再侦听 B.继续侦听
C.延迟一个随机的时间单位再侦听 D.放弃侦听
42、 采用全双工通信方式,数据传输的方向性结构为 A
A. 可以在两个方向上同时传输 B.出只能在一个方向上传输
C.可以在两个方向上传输,但不能同时进位 D.以上均不对
43、 采用异步传输方式,设数据位为7位,1位校验位,1位停止位,则其通信效率为 B
A.30% B. 70% C.80% D.20%
44、 T1载波的数据传输率为 D
A.1Mbps B. 10Mbps C. 2.048Mbps D.1.544Mbps
45、 采用相位幅度调制PAM技术,可以提高数据传输速率,例如采用8种相位,每种相位取2种幅度值,可使一个码
元表示的二进制数的位数为 D
A.2位 B.8位 C.16位 D.4位
46、 若网络形状是由站点和连接站点的链路组成的一个闭合环,则称这种拓扑结构为 C
A.星形拓扑 B.总线拓扑 C.环形拓扑 D.树形拓扑
47、 RS-232C接口信号中,数据终端就绪 DTR 信号的连接方向为 A
A.DTE�DCE B. DCE�DTE C. DCE�DCE D. DTE�DTE
48、 RS-232C的机械特性规定使用的连接器类型为 B
A.DB-15连接器 B.DB-25连接器 C.DB-20连接器 RJ-45连接器
49、 RS-232C的电气特性规定逻辑”1”的电平范围分别为 B
A.+5V至+15V B.-5V至-15V
C. 0V至+5V D. 0V至-5V
50、 若BSC帧的数据段中出现字符串”A DLE STX”, 则字符填充后的输出为 C
A. A DLE STX STX B. A A DLE STX
C. A DLE DLE STX D. A DLE DLE DLE STX51、 若HDLC帧的数据段中出现比特串”01011111001”,则比特填充后的输出为 B
A.010011111001 B.010111110001 C. 010111101001 D. 010111110010
52、 以下各项中,不是数据报操作特点的是 C
A. 每个分组自身携带有足够的信息,它的传送是被单独处理的
B. 在整个传送过程中,不需建立虚电路
C. 使所有分组按顺序到达目的端系统
D. 网络节点要为每个分组做出路由选择
53、 TCP/IP体系结构中的TCP和IP所提供的服务分别为 D
A.链路层服务和网络层服务 B.网络层服务和运输层服务
C.运输层服务和应用层服务 D.运输层服务和网络层服务
54、 对于基带CSMA/CD而言,为了确保发送站点在传输时能检测到可能存在的冲突,数据帧的传输时延至少要等于
信号传播时延的 B
A. 1倍 B.2倍 C.4倍 D.2.5倍
55、 以下各项中,是令牌总线媒体访问控制方法的标准是 B
A. IEEE802.3 B.IEEE802.4 C.IEEE802.6 D.IEEE802.5
56、 采用曼彻斯特编码,100Mbps传输速率所需要的调制速率为 A
A.200Mbaud B. 400Mbaud C. 50Mbaud D. 100MBaud
57、 若信道的复用是以信息在一帧中的时间位置(时隙)来区分,不需要另外的信息头来标志信息的身分,则这种
复用方式为 C
A.异步时分复用 B.频分多路复用 C.同步时分复用 D.以上均不对
58、 由于帧中继可以使用链路层来实现复用和转接,所以帧中继网中间节点中只有 A .
A.物理层和链路层 B.链路层和网络层
C.物理层和网络层 D.网络层和运输层
59、 第二代计算机网络的主要特点是 A 。
A. 计算机-计算机网络 B. 以单机为中心的联机系统
C. 国际网络体系结构标准化 D. 各计算机制造厂商网络结构标准化
60、 在同一个信道上的同一时刻,能够进行双向数据传送的通信方式是 C 。
A. 单工 B. 半双工 C. 全双工 D. 上述三种均不是
61、 从通信协议的角度来看,路由器是在哪个层次上实现网络互联 C
A. 物理层 B. 链路层 C. 网络层 D. 传输层
62、 有关计算机的缩略语MPC,NPC和WWW分别意指 D
A. 多媒体计算机、网络计算机和电子邮件
B. 多媒体、计算机网络和环球网
C. 多媒体计算机、网络计算机和浏览器
D. 多媒体计算机、网络计算机和环球网
63、 下面协议中,用于WWW传输控制的是 C
A. URL B. SMTP C. HTTP D.HTML
64、 域名服务器上存放有internet主机的 C
A. 域名 B. IP地址 C. 域名和IP地址 D.E-mail地址
65、 计算机通信子网技术发展的顺序是 C
A. ATM->帧中继->电路交换->报文组交换 B.电路交换->报文组交换->ATM->帧中继
C.电路交换->报文分组交换->帧中继->ATM D.电路交换->帧中继->ATM->报文组交换
66、 使用同样网络操作系统的两个局域网络连接时,为使连接的网络从网络层到应用层都能一致,连接时必须使
用 DA.文件服务器 B. 适配器 C. 网卡 D.网桥
67、 在数字式数据通信中,影响最大的噪声是 D
A. 热噪声 B.内调制杂音 C.串扰 D.脉冲噪声
68、 比特串01111101000111110010在接收站经过删除“0”比特后的代码为: B
A. 01111101000111110010 B.011111100011111010
C. 0111111000111110010 D.011111010011111010
69、 国际电报电话委员会(CCITT)颁布的X.25与OSI的最低__C____层协议相对应。
A. 1 B. 2 C. 3 D. 4
70、 IEEE802.3标准是___B___。
A. 逻辑链路控制 B.CSMA/CD访问方法和物理层规范
C. 令牌总线访问方法和物理层规范 D.令牌环网访问方法和物理层规范
71、 局域网具有的几种典型的拓扑结构中,一般不含___D___。
A. 星型 B. 环型 C. 总线型 D.全连接网型
72、 为采用拨号方式联入Internet网络,___D__是不必要的。
A. 电话线 B.一个MODEM C.一个Internet账号 D. 一台打印机
73、 下面协议中,用于电子邮件 email 传输控制的是___B___。
A. SNMP B. SMTP C. HTTP D.HTML
74、 计算机网络中,分层和协议的集合称为计算机网络的 C 。目前应用最广泛的是 G
A. 组成结构; B参考模型; C.体系结构; D.基本功能。
E.SNA; F.MAP/TOP; G.TCP/IP; H.X.25; I.ISO/OSI;
75、 采用Go-back-N方法,接收窗口内的序号为4时接收到正确的5号帧应该 A
A.丢弃 B. 缓存 C. 递交高层 采用Go-back-N法,接收到有错误的 5号帧后接收到正确的 6号帧,此
时对6号帧应该 A
A.丢弃 B. 缓存 C. 递交高层采用选择重发法,序号采用3比特编码,接收窗口大小为3,窗口内最小序
号为6并且接收缓冲区全空时,接收到正确的6号帧后紧接着接收到正确的0号帧,此时对0号帧应该 B
A.丢弃 B. 缓存 C. 递交高层
78、 采用选择重发法,接收窗口内的序号为4、5,当接收到有错误的4号帧后接收到正确的5号帧,此时对5号
帧应该 B
A.丢弃 B. 缓存 C. 递交高层
79、 采用选择重发法,序号采用3比特编码,接收窗口大小为3,窗口内最小序号为6时接收到正确的0号帧,
此时对6号帧应该 C
A.丢弃 B. 缓存 C. 递交高层
80、 在计算机网络中,所有的计算机均连接到一条通信传输线路上,在线路两端连有防止信号反射的装置。 这
种连接结构被称为 A 。
A、总线结构 B、环型结构 C、星型结构 D、网状结构
81、 在OSI的七层参考模型中,工作在第三层以上的网间连接设备是 B 。
A、集线器 B、网关 C、网桥 D、中继器
82、 IP地址是一个32位的二进制,它通常采用点分 C 。
A、二进制数表示 B、八进制数表示 C、十进制数表示 D、十六进制数表示
83、 在TCP/IP协议簇中,UDP协议工作在 B 。
A、应用层 B、传输层 C、网络互联层 D、网络接口层
84、 在IP地址方案中,159.226.181.1是一个 B 。
A、A类地址 B、B类地址 C、 C类地址 D、 D类地址
85、 把网络202.112.78.0划分为多个子网(子网掩码是 255.255.255.192),则各子网中可用的主机地直总数是D 。
A、254 B、 252 C、 128 D、124
86、 在Internet域名体系中,域的下面可以划分子域,各级域名用圆点分开,按照 D 。
A、从左到右越来越小的方式分4层排列 B、从左到右越来越小的方式分多层排列
C、从右到左越来越小的方式分4层排列 D、从右到左越来越小的方式分多层排列
87、 计算机接入Internet时,可以通过公共电话网进行连接。以这种方式连接并在连接时分配到一个临时性 IP
地址的用户,通常作用的是 C 。
A、拨号连接仿真终端方式 B、经过局域网连接的方式
C、SLIP/PPP协议连接方式 D、经分组网连接的方式
88、 在调制解调器上,表示该设备已经准备好,可以接收相连的计算机所发送来的信息的指示灯是 A 。
A、CTS B、RD C、 DTR D、 DCD
89、 在10Base T的以太网中,使用双绞线作为传输介质,最大的网段长度是 D 。
A、2000m B、500m C、185m D. 100m
90、 在Internet上浏览时,浏览器和WWW服务器之间传输网页使用的协议是 B 。
A、IP B、HTTP C、FTP D、Telnet
91、 帧中继技术是在 B 用简化的方法传送和交换数据的一种技术。
A、物理层 B、数据链路层 C、网络层 D、传输层
92、 ISDN的B信道提供的带宽以 B 为单位。
A、16Kbps B\64Kbps C.56Kbps D.128Kbps
93、 帧中继网是一种 A 。
A、广域网 B、局域网 C、ATM网 D、 以太网
94、 电子邮件地址Wang@263.net中没有包含的信息是 C 。
A、发送邮件服务器 B、接收邮件服务器
C、邮件客户机 D、邮箱所有者
95、 下列文件中属于压缩文件的是 C 。
A、fit.ext B. trans.doc C. test.zip D. map.htm
96、 在Internet/Intranet中,不需要为用户设置帐号和口令的服务是 D 。
A、WWW B、FTP C、E-mail D、DNS
97、 数字签名是数据的接收者用来证实数据的发送者身份确实无误的一种方法,目前常采用的数字签名标准是
A 。
A、DSS标准 B、CRC标准 C、SNMP标准 D、DSA标准
98、 计算机系统安全“桔皮书”(OrangeBook)将计算机安全由低到高分为四类七级,其中的最高安全级为 A 。
A、A1级 B、B1级 C、C1级 D、 D1级
99、 .报文交换技术说法不正确的是 D
A服文交换采用的传送方式是“存储一转发”方式
B.报文交换方式中数据传输的数据块其长度不限且可变
C.报文交换可以把一个报文发送到多个目的地
D.报文交换方式适用于语言连接或交互式终端到计算机的连接
100、 若在一个语音数字化脉码调制系统中,在量化时采用了128个量化等级,则编码时相应的码长为 C 位。
A.8 B.12 8 C.7 D.256
101、 能从数据信号波形中提取同步信号的典型编码是 D
A.归零码 B.不归零码 C.定比码 D.曼彻斯特编码
102、 世界上很多国家都相继组建了自己国家的公用数据网,现有的公用数据网大多采用 AA.分组交换方式 B.报文交换方式 C.电路交换方式 D.空分交换方式
103、 智能大厦及计算机网络的信息基础设施是 C 。
A.集散系统 B.电子大学网络 C.结构化综合布线系统 D.计算机集成制造系统
104、 移动式电话归属于 A 领域。
A.广播分组交换 B.远程交换 C.信息高速公路 D.电子数据交换
105、 计算机网络通信采用同步和异步两种方式,但传送效率最高的是 A
A.同步方式 B.异步方式 C.同步与异步方式传送效率相同 D.无法比较
106、 有关光缆陈述正确的是 A
A.光缆的光纤通常是偶数,一进一出 B.光缆不安全
C.光缆传输慢 D.光缆较电缆传输距离近
107、 通过改变载波信号的相位值来表示数字信号1、0的方法叫做 C
A. ASK B. FSK C. PSK D. ATM
108、 在计算机网络中,一般局域网的数据传输速率要比广域网的数据传输速率 A
A.高 B.低 C.相同 D.不确定
109、 下列属于广域网拓扑结构的是 B 。
A、树形结构 B、集中式结构 C、 总线形结构 D、环形结构
110、 计算机网络由通信子网和资源子网组成。下列设备中属于资源子网的是 C 。
A、PSE B、PAD C、HOST D、NCC
111、 分布式计算机系统与计算机网络系统的重要区别是 D 。
A、硬件连接方式不同 B、系统拓扑结构不同
C、通信控制方式不同 D、计算机在不同的操作系统下,工作方式不同
112、 计算机网络是计算机技术和通信技术相结合的产物,这种结合开始于 A 。
A、20世纪50年代 B、20世纪60年代初期
C、20世纪60年代中期 D、20世纪70年代
113、 电路交换是实现数据交换的一种技术,其特点是 C 。
A、无呼损 B、不同速率的用户之间可以进行数据交换
C、信息延时短,且固定不变 D、可以把一个报文发送到多个目的节点中
114、 在计算机网络通信系统中,一般要求误码率低于 C 。
A、10-4 B、10-5 C、10-6 D、10-7
115、 下列陈述中,不正确的是 D 。
A、数字通信系统比模拟通信系统的抗干扰性更好
B、数字通信系统比模拟通信系统更便于集成化
C、数字通信系统比模拟通信系统更便于微形化
D、数字通信系统比模拟通信系统的信道利用率更高
116、 UTP与计算机连接,最常用的连接器为 A 。
A、RJ-45 B、AUI C、 BNC-T D、NNI
117、 在OSI模型中,NIC属于 B 。
A、物理层 B、数据链路层 C、网络层 D、 运输层
118、 同轴电缆与双绞线相比,同轴电缆的抗干扰能力 C 。
A、弱 B、一样 C、强 D、不能确定
119、 在OSI中,为网络用户间的通信提供专用程序的层次是 D 。
A、运输层 B、会话层 C、表示层 D、应用层
120、 在OSI中,完成整个网络系统内连接工作,为上一层提供整个网络范围内两个终端用户用户之间数据传输通
路工作的是 C 。A、物理层 B、数据链路层 C、网络层 D、运输层
121、 在OSI中,为实现有效、可靠数据传输,必须对传输操作进行严格的控制和管理,完成这项工作的层次是
B 。
A、物理层 B、数据链路层 C、网络层 D、运输层
122、 在OSI中,物理层存在四个特性。其中,通信媒体的参数和特性方面的内容属于 A 。
A、机械特性 B、电气特性 C、功能特性 D、规程特性
123、 智能大厦系统的典型技术组成包括结构化布线系统和 3A系统。3A系统是指楼宇自动化系统、通信自动化系
统和 A 。
A、办公自动化系统 B、消防自动化系统
C、信息管理自动化系统 D、安保自动化系统
124、 用于高层协议转换的网间连接器是 C 。
A、路由器 B、集线器 C、网关 D、网桥
125、 桥接器互连反映了数据链路层一级的转换,下列功能属于桥接器的是 B 。
A、根据实际情况可以变更帧的格式 B、可以对不同格式的帧进行重组
C、根据实际情况可以变更帧的内容 D、只能对相同格式的帧进行重组
126、 在OSI网络管理标准体系中,访问控制功能所处的功能域是 D 。
A、故障管理 B、配置管理 C、性能管理 D、安全管理
127、 在TCP/IP中,解决计算机到计算机之间通信问题的层次是 B 。
A、网络接口层 B、网际层 C、传输层 D、应用层
128、 信号传输率为1200Baud,每个码元可取8种离散状态,该信号的数据传输率是 B
A、1200bps B. 3600bps C. 9600bps D.150bps
129、 ATM采用的线路复用方式为 C 。
A、频分多路复用 B、同步时分多路复用
C、异步时分多路复用 D、独占信道
130、 Bell系统的T1载波标准采用的线路复用方式为 B 。
A、频分多路复用 B、同步时分多路复用
C、异步时分多路复用 D、独占信道
131、 一个8相的PSK调制解调器,其波特率为1600波特,可获得的数据传输率为 B
A、1600bps B. 4800bps C. 3200bps D. 12800bps
132、 就同步方式而言,异步通信属 C 。
A、自同步 B、外同步 C、群同步 D、内同步
133、 X.25数据交换网使用的是 A 。
A、分组交换技术 B、报文交换技术
C、帧交换技术 D、电路交换技术
134、 卫星通信的主要缺点是 B 。
A、经济代价大 B、传播延迟时间长 C、易受干扰,可靠性差 D、传输速率低。
135、 对语音信号进行脉码调制(PCM)时采样频率应 A 。
A、≥8000次/s B. ≥4000次/s
C. ≥8000次×logN,N为每个码元状态数 D.≤8000次/s
2
136、 若帧序号采用3位二进制码,对于GO-back- N的有序接收方式,发送窗口最大尺寸是 D .
A. 1 B.3 C. 8 D. 7
137、 在数字通信中广泛采用CRC循环冗余码的原因是CRC可以 C .
A.检测出一位差错 B.检测并纠正一位差错
C.检测出多位突发性差错 D.检测并纠正多位突发性差错138、 若信息位为8位,要构成能纠正一位错的海明码,冗余位至少 D
A.1位 B.2位 C.3位 D.4位
139、 因特网在通信子网内实现数据报操作方式对端系统 C .
A.只提供数据报服务 B.只提供虚电路服务
C.提供数据报和虚电路服务 D.不提供服务
140、 在网络层提供协议转换,在不同网络之间存贮转发分组的网络设备是 D
A.网桥 B.网关 C.集线器 D.路由器
141、 CSMA技术中,算法规则为1)如媒体空闲,则立即发送; 2)若媒体忙,等待一个随机重发延迟后再重复 1).该算
法规则称为 A .
A.非坚持性算法 B. 1-坚持性算法
C.P-坚持性算法 D.CSMA/CD算法
142、 某部门申请到一个C类IP地址,若要分成8个子网,其掩码应为 C .
A. 255.255.255.255 B.255.255.255.0
C.255.255.255.224 D.255.255.255.192
二、填充题
1、 通信系统中,称调制前的电信号为 基带 信号,调制后的电信号为 调制 信号。
2、 CCITT对DTE—DCE的接口标准中,通过公用数据网进行数据传输的建议是 X 系列。
3、 网络中各种被共享的资源按特性可以分为四类:硬件、软件、 数据 和 通信 。
4、 在OSI中,完成相邻节点间流量控制功能的层次是 数据链路层 。
5、 因特网提供服务所采用的模式是 客户/服务器 。
6、 信息网络与计算机网络的目的不同。信息网络的目的是进行 信息交流 ,而计算机网络的目的是实现 资
源共享 。
7、 计算机网络的体系结构是一种 分层 结构。
8、 通信协议具有层次性、 有效性 、可靠性 。
9、 在网络系统中,丢失、被监用、被非法授权人访问或修改后对组织造成损失的信息是 敏感信息 。
10、 ____1980____年,我国正式参加了ISO的标准工作.
11、 计算机网络系统由通信子网和 资源子网 组成
12、 计算机网络系统由负责信息传递的通信子网和负责信息处理的 资源 子网组成。
13、 计算机网络系统发展的第一阶段是联机系统,实质上是 联机多用户 系统。
14、 通信系统中,称调制前的电信号为 基带 信号,调制后的信号为调制信号。
15、 在采用电信号表达数据的系统中,数据有数字数据和 模拟 数据两种。
16、 信息高速公路的主干部分是由 光纤 及其附属设备组成。
17、 树型拓扑结构优点是: 易于扩展 、 故障隔离较容易 。
18、 串行数据通信的方法有三种: 单工、半双工和全双工 。
19、 模拟信号传输的基础是 载波 ,它是频率恒定的连续信号。
20、 保持转达发式集中器可提供字符级的 缓存(或缓冲) 能力。
21、 两种最常使用的多路复用技术是:频分多路复用和 时分多路复用 。
22、 为了防止发送方和接收方的计时漂移,它们的时钟必须设法 同步 。
23、 IPX/SPX协议提供了分组寻址和 路由选择 功能。
24、 IP地址是网际层中识别主机的 逻辑 地址。
25、 保持转发式集中器可提供字符级的 缓存(或缓冲) 能力。
26、 IPX/SPX协议提供了分组寻址和 选择路由 功能。
27、 抽象语法是对数据 结构 的描述。28、 局域网软件主要由网卡驱动程序和 网络操作系统 两个基本部分组成。
29、 网桥独立于 网络层 协议,网桥最高层为数据链路层。
30、 网络安全中,脆弱性是指网络系统中 安全防护 的弱点。
31、 ISP是掌握Internet 接口 的机构。
32、 微软公司提出的开放式数据库互连技术其简称为 ODBC 。
33、 中继器具有完全再生网络中传送的原有 物理 信号的能力。
34、 Token Bus的媒体访问控制方法与其相应的物理规范由 IEEE802.4 标准定义。
35、 当数据报在物理网络中进行传输时,IP地址被转换成 物理 地址。
36、 计算机网络的结构可以从 网络体系结构 、网络组织和网络配置三个方面来描述。
37、 通信线路连接有点对点和 分支式 两种连接方式。
38、 为抽象语法指定一种编码规则,便构成一种 传送 语法。
39、 数据传输有两种同步的方法:同步传输和异步传输。其中异步传输采用的是 群 同步技术。
40、 计算机网络的主要功能为 硬件资源 共享、 软件资源 共享、用户之间的信息交换。
41、 帧中继是以___分组交换______技术为基础的____高速分组交换_____技术。
42、 RS-449标准的电气特性有两个子标准,即__平衡 __方式的RS-422电气标准和 非平衡 _方式的RS-423电气
标准。
43、 调制解调器按其特性分类有人工___拨号____式和自动_ 呼叫(应答) 式两类。
44、 数据链路层的最基本功能是向该层用户提供_ 透明的 _和_ 可靠的 _的数据传输基本服务。
45、 在X.25中,两个DTE之间的虚电路分为_ 虚呼叫电路(或虚电路,交换虚电路)_和_永久虚电路__。
46、 对于路由选择算法而言,固定路由选择属于___静态路由选择____策略,分布路由选择属于__动态路由选择__
策略。
47、 OSI的会话层处于___运输(第4)___层提供的服务之上,给__表示(第6)_层提供服务。
48、 OSI环境中负责处理语义的是___应用(第7)___层,负责处理语法的是____表示(第6)_ 层,下面各层负责
信息从源到目的地的有序移动。
49、 计算机交换机CBX采用的拓扑结构为___星型拓扑__;光纤分布数据接口FDDI采用的拓扑结构为___环型拓扑
___。
50、 虚电路服务是OSI__网络(第3)___层向运输层提供的一种可靠的数据传送服务,它确保所有分组按发送___
顺序___到达目的地端系统。
51、 Internet采用的协议簇为___TCP/IP____;若将个人电脑通过市话网上 Internet需配置___调制解调器(MODEM)
__。
52、 国际互连网使用的X.121地址,划分为若干字段,规定头四位为网络识别标志,其后三位为__主机所在的区位
号__,再后五位是实际___网络地址___。
53、 在网络应用系统中,Client/Server体系结构是在网络基础之上,以___数据库管理__系统为后援,以___微机
__为工作站的一种系统结构。
54、 OSI模型有__物理层、数据链路层、网络层 、运输层、会话层、表示层和应用层七个层次。
55、 DTE和DCE是CCITT使用的术语,在目前 X.25 是广域分组网范畴中的一个十分流行的面向用户的接口标准。
56、 对数字数据的模拟信号进行调制的三种基本形式: 移幅键控法ASK、移频键控法FSK、移相键控法PSK 。
57、 信号传输中差错是同 噪声 所引起的。噪声有两大类,一类是信道所固有的,持续存在的随机热噪声;另
一类是由外界特定的短暂原因所造成的冲击噪声。热噪声引起的差错称为 随机错 。
58、 按照实际的数据传送技术,交换网络又可分为电路交换网、报文交换网 分组 交换网。
59、 差错控制的首要步骤是 差错控制编码 ,它也是最常用的差错检测方法。
60、 传输媒体是通信网络中发送方和接收方之间的物理通路。计算机网络中采用的传输媒体可分为有线和无线两大
类。双绞线、同轴电缆和光纤是常用的三种 有线 传输媒体。卫星通信、无线通信、红外通信、激光通信以及微
波通信的信息载体都属于 无线 传输媒体。61、 网络互连是目前网络技术研究的热点之一,并且在这领域取得了很大的进展。在诸多网络互连协议中,传输控
制协议/互连网协议是一个普遍使用的网络的互连的标准协议。 TCP/IP 协议被广泛应用,成为一个事实上的
工业标准,它使异构环境里不同节点能够彼此通信。
62、 在计算机网络和数据通信中用得最广泛的检错码是CRC码(循环冗余码)又称 多项式码。
63、 IEEE802.3 是载波监听多路访问/冲突检测访问方法和物理层协议,IEEE802.4是令牌总线访问方法和物理层
协议,IEEE802.5是令牌环访问方法和物理层协议。
64、 Internet 被认为是美国信息高速公路雏形。
65、 对于数字通信系统而言,它具有两个显著的优点: 抗干扰性强 、 保密性好 。
66、 用电路交换技术完成的数据传输要经历 电路建立 、 数据传输 、 电路拆除 过程。
67、 校园网广泛采用 客户/服务器 服务模式,其资源分布一般采用 层次 结构。
68、 ISO是一个自发的不缔约组织,由各技术委员会组成。
69、 T1系统的传输速率为 1.544Mbps ,E1系统的数据传输速率为 2.048Mbps 。
70、 模拟信号数字化的转换过程包括: 采样、量化和编码 三个步骤。
71、 曼彻斯特编码是一种同步方式为 自同步法 的编码方案。
72、 通过增加冗余位使得码字中“1”的上数恒为奇数或偶数的编码方法为 奇偶校验码 。
73、 使用 光纤 作为传播媒体是,需完成 电信号 和 光信号 之间的转换。
74、 在计算机的通信子网中,其操作方式有两种,它们是面向连接的 虚电路 和无连接的 数据报 。
75、 同步传输时,可以采用面向 字符 的方案,也可采用面向 位 的方案。
76、 为进行计算机网络中的数据交换而建立的 规则 、标准或 约定 的集合称为网络协议。
77、 当链路层使用窗口机制来描述Go-back-N方法时,其 接收 窗口等于1,而 发送窗口大于1。
78、 在数据报服务方式中,网络节点要为每个 分组/数据报 选择路由,在 虚电路 服务方式中,网络节点只
在连接建立时选择路由。
79、 HDLC中的异步响应方式是一种 非平衡 数据链路操作方式,它由 从/次 站来控制超时和重发。
80、 数据链路层中把站分为三类,其中用于控制目的的站常称为 主 站,其它受控的站被称为 从 站。
81、 完整的HDLC帧由标志字段、地址字段、 控制字段 、信息字段、和 帧校验字段 组成。
82、 X.25的数据分组中P(S)称为 分组发送顺序号 ,P(R)称为 分组接收顺序号 .
83、 X.25协议包括 物理层、数据链路层和分组 三个层次。
84、 X.25是为同一个网络上用户进行相互通信而设计的。然而,在两个单独的网络上工作的用户常常需要建立通信
来共享资源或交换数据, X.75 就是为满足这个需要而设计的,其目的就是进行网间互连。
85、 在X.25中,两个DTE之间的虚电路分为 虚呼叫电路 和 永久虚电路 。
86、 在HDLC规程中,监控帧主要用于 差错 控制和 流量 控制。
87、 运输层的运输服务有两大类: 面向连接 服务和 无连接 的服务。
88、 死锁是网络 阻塞/拥塞 的极端结果。最常见的死锁有 直接存储转发死锁、重装死锁和间接转发死锁。
89、 网桥提供 DCE/数据链路层 级的端到端的连接。
90、 常用路由器分为用于 面向连接 的路由器和用于 无连接 的路由器两种。
91、 在TCP/IP协议簇中,运输层的 传输控制(TCP)协议提供了一种可靠的数据流服务。
92、 服务在形式上使用一组 原语 来描述。
93、 TCP/IP的网络层最重要的协议是 IP互连网协议 ,它可将多个网络连成一个互连网。
94、 TCP在IP的基础上,提供端到端的 面向连接 的可靠传输。
95、 异步串行通信规程规定,传送的每个字符的最后是 停止位,其宽度为1位或1.5位或 2位,信号电平为 低
电平 。
96、 网卡是局域网连接的必备设备,网络接口卡的作用是在工作站与网络间提供 数据传输 的功能。其作用与调制
解调器/电话网络中的RS-232C异步通信适配器的作用相同。
97、 OSI/RM的数据链路层功能,在局域网参考模型中被分成 MAC媒体访问控制 和逻辑链路控制LLC两个子层。98、 LLC帧分为三类: 信息帧、监控帧和无编号帧。
99、 以太网采用 1-坚持 的CSMA算法进行载波监听,采用 二进制指数退避 算法决定冲突后的避让时间。
100、在局域网参考模型中, LLC 与媒体无关, MAC 则依赖于物理媒体和拓扑结构。
101、令牌丢失和 数据帧 无法撤消,是环网上最严重的两种差错。
102、从一个站点开始发送数据到另一站点开始接收数据,也即载波信号从一端传播到另一端所需要的时间,称为
信号传播时延 。
103、4B/5B编码技术是每次对4位数据进行编码,每4位数据编码成 5 位符号,用光信号的有无来代表 5 位符
号中每一位是1还是0。
104、令牌总线媒体访问差别控制是将物理总线上的站点构成一个 逻辑环 。
105、令牌环的媒体访问控制功能包括: 帧发送、令牌发送、帧接收和优先权操作。
106、本站地址、 前趋地址 、和 后继地址 可以唯一地表示令牌总线逻辑上的每个站点。
107、子网掩码的作用是 判断两台主机是否在同一子网中 。
108、用户标识符就是用户的 用户名 。
109、SNMP设计为一种基于 用户数据协议UDP 的应用层协议,它是TCP/IP协议簇的一部分。
110、域名系统DNS是一个 分布式数据库 系统。
111、Internet采用的工作模式为 客户机/服务器 。
112、100BASE-TX和100BASE-FX都使用 4B/5B NRZI 编码。
113、域名采取 层次 结构,其格式可表示为:机器名.网络名.机构名.最高域名。
114、Internet中的 A 类地址一般分配给具有大量主机的网络使用; B 类地址通常分配给规模中等的网络使
用; C 类地址分配给小型网络使用。
115、ISDN是由综合数字电话网(IDN)演变发展而来的一种网络,它提供 端到端 的数字连接以支持广泛的业务,
包括语音和非语音的业务。它为用户联网提供了一组少量标准的 多用途网络接口 。
116、ISDN通常利用单独一个通道传送 信令 ,以在线路交换机之间传送控制信息。
117、ISDN系统结构主要讨论用户和网络之间的接口,该接口也称为 数字位通道 。
118、Internet所提供的三项基本服务是E-mail、 Telnet 、FTP。
119、通常所谓某台主机在internet上,就是指该主机具有一个 IP地址 ,并运行TCP/IP协议,可以向Internet
上的所有其它主机发送 IP分组 。
120、TCP提供的是 端到端 之间的 可靠的 服务。
121、局域网与Internet主机的连接方法有两种,一种是通过 电话线 ,另一种是通过 路由器 与Internet主
机相连。
122、快速以太网的冲突检测时间等于网络最大传播时延的 两 倍。
123、千兆以太网对媒体的访问采取 全双工和半双工 两种方式。
124、100BASE-T4采用 8B/6T 编码方案。
125、100BASE-T的物理层包括三种媒体选项:100BASE-TX、 100BASE-FX、100BASE-T4 。
126、目前B-ISDN采用的传送方式主要有:高速分组交换、 光交换、异步传送方式ATM 和高速电路交换方式四
种。
127、帧中继技术本质上是分组交换技术,它与X.25协议的主要区别是 对X.25协议进行简化 。
128、100BASE-T和10BASE-T的区别主要表现在物理层标准和 网络设计 方面。
129、ATM是一种转换模式,在这一模式中信息被组成成 信元 ,并且不需要周期性地出现在信道上,从这个意义
上说,这种转换模式是 异步 的。
130、DQDB的时隙长53个字节,其中 1 个字节是接入控制字段, 52 字节是时隙字段。
131、ATM的虚连接方式有永久虚连接和 交换虚连接 。
132、ATM的信头有两种格式,分别对应 用户网络接口UNI 和 网络节点接口NNI 。
133、B-ISDN中的B表示宽带,指网络的 传输速率 非常高,能达几十或几百Mbps,甚至达到几十Gbps;ISDN表示综合业务,是指将话音传输、 图像 传输、数据传输等多种业务综合到一个网络中。
134、由窄带ISDN向宽带ISDN发展的第三个阶段的主要特征是引入了 智能管理网 。
135、网络的安全遭受攻击、侵害的类型有三种:第一种 数据篡改 ,第二种是 冒名搭载 ,第三种是利用 网络
软硬件功能 的缺陷所造成的“活动天窗”来访问网络。
136、NovellNetware是在 局域网基础 上建立的网络操作系统,它是一个围绕核心高度的 多用户共享资源的 操
作系统。
137、分布式队列双总线DQDB子网可以作为 协议 的一个组成部分。DQDB子网通过 服务访问点SAP 、路由器和
网关互连构成一个MAN。
138、计算机网络中常用的三种有线媒体是__同轴电缆、双绞线、光纤__。
139、令牌总线对最小的分组长度_____无_________要求。
140、计算机网络的发展和演变可概括为 面向终端的计算机网络 、 计算机—计算机网络 和开放式标准化
网络三个阶段。
141、串行数据通信的方向性结构有三种,即单工、 半双工 和 全双工 。
142、模拟信号传输的基础是载波,载波具有三个要素,即 幅度 、 频率 和 相位 。数字数据可以针对载波
的不同要素或它们的组合进行调制,有三种基本的数字调制形式,即 移幅键控法ASK 、移频键控法FSK 和 移
相键控法PSK 。
143、最常用的两种多路复用技术为 频分多路复用技术FDM 和 时分多路复用技术TDM ,其中,前者是同一时
间同时传送多路信号,而后者是将一条物理信道按时间分成若干个时间片轮流分配给多个信号使用。
144、HDLC有三种不同类型的帧,分别为 信息帧(I帧)、 监控帧(S帧) 和 无编号帧(U帧) 。
145、X.25协议的分组级相当于OSI参考模型中的 网络 层,其主要功能是向主机提供多信道的 虚电路 服务。
146、到达通信子网中某一部分的分组数量过多,使得该部分乃至整个网络性能下降的现象,称为 拥塞 现象。
严重时甚至导致网络通信业务陷入停顿,即出现 死锁 现象。
147、OSI的会话层处于 运输层 提供的服务之上,为 表示 层提供服务。
148、会话层定义了两类同步点,分别为 主同步点 和 次同步点 。其中后者用于在一个对话单元内部实现数
据结构化。
149、OSI表示层的主要功能为 语法转换 、 语法协商 和连接管理。
150、FTAM是一个用于传输、访问 和 管理 开放系统中文件的信息标准。它使用户即使不了解所使用的实际文
件系统的实现细节,也能对该文件系统进行操作。
151、在TCP/IP层次模型中与OSI参考模型第四层(运输层)相对应的主要协议有 TCP(传输控制协议) 和 UDP
(用户数据报协议) ,其中后者提供无连接的不可靠传输服务。
152、在TCP/IP层次模型的第三层(网络层)中包括的协议主要有IP、ICMP、 ARP 及 RARP 。
153、载波监听多路访问CSMA技术,需要一种退避算法来决定避让的时间,常用的退避算法有 非坚持 、 1-坚
持 和 P-坚持 三种。
154、ATM的信元具有固定的长度,即总是 53 字节,其中 5 字节是信头, 48 字节是信息段。
155、WWW上的每一个网页都有一个独立的地址,这些地址称为 统一资源定位器 。
156、TCP/IP模型由低到高分别为_网络接口__、__网际______、__传输__、__应用___层次。
157、组成数据通信网络的基本要素为 信源 、 信缩 和 传输系统 三项。
158、OSI规定了每一层均可使用的服务原语有四种类型:请求 、 指示 、 响应 、 证实 。
159、10BASE-T标准规定的网络拓扑结构是__星型 ,网络速率是_10Mbps__,网络所采用的网络介质是___双绞线
_____,信号是__基带___。
160、传统的加密方法可以分成两类: 替代密码 和 换位密码 。现代密码学采用的算法主要有: 秘密密钥算
法 和 公开密钥算法 _。
161、数据传输通常可分成五个阶段,其中第二阶段是 建立数据传输链路 ,第五阶段是 断开数据传输链
路 。162、在IEEE802局域网体系结构中,数据链路层被细化成 LLC逻辑链路子层 和 MAC介质访问控制子层 两层。
163、 广播式通信信道中,介质访问方法有多种。IEEE802规定中包括了局域网中最常用三种,包括:___CSMA/CD
总线___、__Token-ring_令牌__、__ TOKEN-BUS令牌总线 ___。
164、SDLC、HDLC和X.25均属于 面向比特 型的通信控制规程。
165、在WWW中,使用统一资源定位器URL来唯一地标识和定位因特网中的资源,它由三部分组成:__协议____、 主
机地址(域名) 、 文件路径名 。
166、在计算机网络中,双绞线、同轴电缆及光纤等用于传输信息的载体被称为 通信 介质。
167、网络工作站是连接网络上的,它保持原有功能为用户服务,同时又可以按照被授予的 权限 访问服务器。
168、Internet在 逻辑 上是统一的,在物理上则由不同的网络互连而成。
169、Intranet是基于Internet技术的具有防止外界侵入安全措施的企业 内部 网络。
170、通信协议包括了通信过程的说明,规定了应当发出哪些控制信息、完成哪些动作以及做出哪些应答,并对发布
请求、执行运作以及返回应答予以解释。这些说明构成了协议的 语义 。
171、当互连网络上的某台主机有一条以上的 物理连接 时,它需要多个IP地址。
172、在ICP/IP协议簇中,传送层负责向 应用层 提供服务。
173、在IP协议中,地址分类方式可以支持 5 种不同的网络类型。
174、调制解调器是实现计算机的 数字 信号和电话线模拟信号间相互转换的设备。
175、路由表分为静态路由表和动态路由表,使用路由选择信息协议RIP来维护的路由表是 动态 路由表。
176、网卡与主机的接口常使用的三种方法是共享存储器法、DMA法和 I /O端口 法。
177、支持在电子邮件中传输汉字信息的协议是 MIME 。
178、电子邮件系统由发送邮件服务器、接收邮件服务器、邮件中继、邮件网关和 邮件客户 组成。
179、FTP协议可以传输文本文件,也可以传输压缩文件、图形/图像文件、声音文件、电影文件等 二进制文件 。
180、传统电话采用电话交换网络来传送语音信息,而IP电话则采用 Internet 网络亚传送语音信息。
181、主域名服务器中除了包含有本辖区的数据文件外,还包含了一个 cache文件,该文件包含了Internet的 根
域名服务器 的名字与IP地址的映射信息,可以从Internet上获得。
182、大多数网络层防火墙的功能可以设置在内部网络与Internet相连的 路由器 上。
183、可采用回密与数字签名技术来保证邮件安全,目前最流行的方法是 PGP技术,它是基于 RSA 加密技术的邮
件加密系统。
184、光纤通信中,按使用的波长区之不同分为 单模 光纤通信方式和 多模 光纤通信方式。
185、无线传输媒体除通常的无线电波外,通过空间直线传输的还有三种技术: 微波、激光 、红外线等。
186、.网络拓扑的主要类型有:星形拓扑、 总线拓扑、环形拓扑 、树形拓扑、混合拓扑及网形拓扑。
187、.同轴电缆分为 基带同轴电缆 和 宽带同轴电缆 。
188、现有的公共数据网,如我国的CNPAC,关国的TELENET等,广泛采用的交换技术为分组交换技术
189、.在数字信号脉冲编码方案中,全宽码又称为不归零码,包括 单极性不归零码 和 双极性不归零码
两种。
190、.数据可分为 模拟数据 和 数字数据 两大类。
191、.数字信号实现模拟传输时,数字信号变换成音频信号的过程称为 调制 ;音频信号变换成数字信号的过
程称为 解调 。
192、.单位时间内传输的二进制信息位数是指 :数据传输 速率,而单位时间内传输的码元个数是指 码元
(调制或信号传输) 速率。
193、为了进行数据传输,在数据传输之前先要在发送站与接收站之间建立一条逻辑通路,这种交换方式称为 虚
电路交换方式 。
194、.用电路交换技术完成数据传输要经历 电路建立 、数据传输和 电路拆除 三个过程。
195、若在传输过程中,每个数据块的开始处有一个 帧头 ,结尾处有一个 帧尾 ,来判定数据块的开
始和结束,则这种传输方式称为同步传输。196、.能连续影响多位数据或一串码元的噪声为 冲击噪声 ;称这种差错为 突发错 。
197、.光纤传输电信号时,其光源可以采用 发光 二极管或 注入型激光 二极管。
198、编码解码器在信源端是把 模拟 信号转换成 数字 信号,在另一端是把 数字 信号反转换成 模拟
信号。
199、
三、名词解释
1、带宽:带宽通常指通过给定线路发送的数据量,从技术角度看,带宽是通信信道的宽度(或传输信道的最高频率
与最低频率之差),单位是赫兹。
2、智能终端:具有独立数据处理能力;能连接在多用户系统中的计算机。
3、半双工通信:通信信道的每一端可以是发送端,也可以是接收端;但在同一时刻里,信息只能有一个传输方向。
4、IP地址:用于区别Internet上主机(服务器),它由32位二进制数组成四段号码,是Internet中识别主机(服
务器)的唯一标识。
5、信道容量:信道的最大数据传输速率,是信道传输数据能力的极限,单位为位/秒
6、不归零制NRZ:在一个码元的全部时间内发出或不发出电流(单极性),以及发出正电流或负电流(双极性)。每
一位编码占用了全部码元的宽度。这种编码方式称为不归零码NRZ。
7、多路复用:在数据通信或计算机网络系统中,传输媒体的带宽或容量往往超过传输单一信号的需求,为了有效地
利用通信线路,可以利用一条信道传输多路信号,这种方法称为信道的多路利用,简称多路复用。
8、 奇偶校验码:是一种通过增加1位冗余位使得码字中“1”的个数恒为奇数或偶数的编码方法。这是一种检错
码。
9、 通信协议:是一套语义和语法规则,用来规定通信双方在通信过程必须遵循的控制信息交换的规则的集合。
10、 阻塞:在分组交换网络中,到达通信子网的报文量大于通信子网对报文的处理能力,导致性能大为下降的现象。
11、 防火墙:是在被保护网络与公共网络之间设置的隔离防护设施。
12、 DTE:数据终端设备,例如计算机。
13、 身份鉴别:验证通信双方是本次通信的合法用户的过程。
14、 帧:在链路层上传输的信息报文,由帧头、控制字段、数据字段、帧尾组成。
15、 包交换:把信息划分成多个小的信息包,然后在网络上进行传输。
16、 秘密密钥算法:不公开加密密钥的信息加密算法。
17、 主机IP地址:在Internet上的每台主机都必须有一个唯一的标识,即IP地址。它由32位4个字节二进制数
组成,为书写方便起见,常将每个字节为一段并以十进制数来表示,每段间用“. ”分隔。IP地址由网络标识
和主机标识两部分组成,常用的IP地址有A、B、C三类。
18、 网络的体系结构:计算机网络各层次及其协议的集合。其层次结构一般以垂直分层模型来表示。
19、 模拟信号:是随时间连续变化的电流、电压或电磁波,可以用某个参量(幅度、频率、相位等)或其编码来表
示数据。如通过无线电波传播的电视信号、通过电话线传播的语音信号等。
20、 流量控制:是对发送方数据流量的控制,使其发送效率不致超过接收方所能承受的能力。它并不是数据链路层
特有的功能,许多高层协议中也提供流量控制功能。
21、 数据传输速率:指每秒能传输的二进制信息的位数,单位记做bps或b/s。
22、 阻塞控制:指到达通信子网中某一部分的分组数量过多,使得使部分网络来不及处理,以致引起这部分乃至整
个网络性能下降的现象,严重时甚至会导致网络通信业务陷入停顿,即出现死锁现象。
23、 循环冗余码:又称CRC码,是一种漏检率很低,便于实现、应用广泛的检错码。此部分内部要求能根据生成多
项式G(x),为要发磅的数据串计算出冗余位;或能根据生成多项式G x ,校验收到的数据串是否有错。
24、 域名及域名系统DNS:域名采用层次结构的基于“域”的命令方案,每一层由一个子域名组成,子域名间用“.”
分隔,其格式为:机器名.网络名.机构名.最高域名.
Internet上的域名由域名系统DNS统一管理.DNS是一个分布式数据库系统,由域名空间、域名服务器和地址转换请求程序三部分组成,用来实现域名和IP地址之间的转换。
25、 PPP协议:是一种有效的点——点通信协议,它由串行通信线路上的组帧方式,用于建立、配制、测试和拆除
数据链路的链路控制协议LCP及一组用以支持不同网络控制协议NCPS三部分组成。
26、 子网掩码:是32位二进制数,它的子网主机标识部分为全“0”。利用子网掩码可以判断两台主机是否在同一
子网中。若两台主机的IP地址分别与它们的子网掩码相“与”后的结果相同,则说明这两台主机在同一子网中。
27、 计算机网络:在硬件方面,利用通信设备和线路将地理位置不同、功能独立的多个计算机系统互连起来,再运
行相应的网络软件(网络通信协议、信息交换技术和网络操作系统),以实现信息共享及信息传递的系统。
28、 TCP/IP协议:是美国国防部高级计划研究局 DARPA为实现ARPANET互连网而开发的。TCP/IP已成为一个事实
上的工业标准。TCP/IP是一组协议的代名词,它还包括许多别的协议,组成了 TCP/IP协议簇。TCP提供运输层
服务,而IP提供网络层服务。TCP/IP协议作为一个网络体系结构,它分为四个层次,自底向上依次为数据链路
层、网络层、运输层和应用层。
29、 防火墙:是在保护的 Intranet和Internet之间竖起的一道安全屏障,用于增强 Intranet的安全性。目前的
防火墙技术可以起到如下安全作用:
1) 集中的网络安全;
2) 安全警报
3) 重新部署网络地址转换
4) 监视Internet的使用
5) 向外发布信息。
典型的防火墙系统可以由一个或多个构件组成,其主要部分 是:包过滤路由器、应用层网关和电路层
网关。
30、 频分多路利用FDM:在物理信道的可用带宽超过单个原始信号所需带宽的情况下,可将该物理信道的总带宽分
割成若干个与传输单个信号带宽相同(或略宽)的子信道,每个子信道传输一种信号,这就是频分多路复用。
31、 地址转换协议ARP:在TCP/IP环境下,网络层有一组将 IP地址转换为相应物理网络地址的协议,这组协议即
为地址转换协议ARP。
32、 网络协议:就是为进行计算机网络中的数据交换而建立的规则、标准或约定的集合。协议总是指某一层的协议,
准确地说,它是对同等层实体之间的通信制定的有关通信规则和约定的集合。
四、简答题
1、简述调制解调器的主要功能
答:信号转换;确保信源和信宿两端同步;提高数据在传输过程中的抗干扰能力;实现信道的多路复用。
2、简述在数据传输中,防止阻塞产生的办法
答:通过对点对点的同步控制,使计算机之间的收发数据速率同步;控制网络的输入,避免突然大量数据报文提交;
接收工作站在接收数据报文之前,保留中够的缓冲空间
3、ATM网络具有哪些主要特点
答: 支持复杂的多媒体应用;相对传统 LAN拥有保证的服务质量; 良好的伸缩性; 提高生产率; 改进现有应用
的性能; 为用户网络提供带宽; 保护用户投资; 高频宽; 低延时; 节省费用。
4、简答分组交换的特点和不足
答:优点:
(1) 节点暂时存储的是一个个分组,而不是整个数据文件
(2) 分组暂时保存在节点的内存中,保证了较高的交换速率
(3) 动态分配信道,极大的提高了通信线路的利用率
缺点:
(1)分组在节点转发时因排队而造成一定的延时
(2)分组必须携带一些控制信息而产生额外开销,管理控制比较困难5、什么是模拟信号?什么是数字信号?数字信号如何在模拟传输系统上转输?
6、 绘出比特流0011001110001的基本曼彻斯特编码波形图和差分曼彻斯特编码波形图。
7、 在令牌总线中,如果一个站接收了令牌后马上崩溃,此时将发生何种情况?
8、网络层提供的数据报服务与虚电路服务台有什么特点?
9、 简述CSMA技术的P—坚持算法规则
答:P—坚持算法规则为:
1)监听总线,如果总线空闲,则以P的概率发送,而以(1-P)的概率延迟一个时间单位(最大传播时延的
2倍)
2)延迟了一个时间单位后,再重复步骤(1)
3)如果总线是忙的,继续监听直到总线空闲并重复步骤(1)。
10、 简述Novell NetWare对文件服务器的共享硬盘提供的5级可靠性措施
答:第一级:对硬盘目录和文件分配表的保护
第二级:对硬盘表面损坏时的数据保护
第三级:采用磁盘镜像的方法实现对磁盘驱动器损坏的保护
第四级:采用磁盘双工,对磁盘通道或磁盘驱动器损坏直到保护作用
第五级:采用事务跟踪系统TTS的附加容错功能。
11、 简述使用“拨号网络”连接Internet所需进行的准备工作。
答:1)选择合适的ISP,通过ISP获取Internet帐号;
2)准备一个调制解调器和一条能拨通ISP的电话线;
3)安装“拨号网络”
4)安装TCP/IP协议并将其绑定到“拨号网络适配器”
5)输入TCP/IP相关信息
6)用“拨号网络”建立与ISP的连接。
12、 找出不能分配给主机的IP地址,并说明原因。
A.131.107.256.80 B.231.222.0.11
C.126.1.0.0 D.198.121.254.255
E.202.117.34.32
答:A.第三个数256是非法值,每个数字都不能大于255
B.第一个数231是保留给组播的地址,不能用于主机地址
C.以全0结尾的IP地址是网络地址,不能用于主机地址
D.以全1结尾的IP地址是广播地址,不能用于主机地址
13、 简要说明ISO/OSI的网络协议体系结构?
答:OSI包括7层,它们分别是物理层、数据链路层、网络层、传输层、会话层、表示层和应用层。
物理层:实现透明的比特流传输。
数据链路层:在网络的相邻节点之间建立、维持和释放数据链路。
网络层:在两个端系统之间的通信子网上建立、维持和终止网络连接。
传输层:为会话层实体间的通信提供端到端的透明的数据传送。
会话层:组织、管理和同步两个实体之间的会话连接和它们之间的数据交换。
表示层:为应用层实体提供信息的公共表示方面的服务。
应用层:为应用进程提供访问OSI的手段。
14、 简述几种因特网的接入方式?
答:1.以终端方式入网:在本地 PC机上运行仿真终端软件,连接到ISP主机,成为该主机的一台终端,经由该主
机访问因特网。2.以拨号方式入网:例如普通电话拨号,ISDN等,采用PPP协议。
3.以专线方式入网:通过数字专线将本地局域网与因特网相连,不需要拨号。
15、 请比较一下数据报与虚电路的异同?
答:见下表。
虚电路 数据报
目标地址 建立连接时需要 每个分组都需要
初始化设置 需要 不需要
分组顺序 由通信子网负责 由主机负责
差错控制 由通信子网负责 由主机负责
流量控制 通信子网提供 网络层不提供
连接的建立和释放 需要 不需要
16、 某网络上连接的所有主机,都得到“Request time out”的显示输出,检查本地主机配置和 IP 地址:
202.117.34.35,子网掩码为255.255.0.0,默认网关为202.117.34.1,请问问题可能出在哪里?
答:子网掩码应为255.255.255.0。按原配置,本地主机会被网关认为不在同一子网中,这样网关将不会转发任何发
送给本地主机的信息。
五、计算题
1、在数字传输系统中,码元速率为600波特,数据速率为1200bps,则信号取几种不同的状态?若要使得码元速率
与数据速率相等,则信号取几种状态?(请给出公式与计算步骤)
解:C=Blog2L
C=1200bps,B=600波特,得L=4
信息取4位状态
当L=2时,码元速率与数据速率相等
2、用速率2400bps的调制解调器,无校验,一位停止位,一分钟内最多传输多少个EBCDIC字符?
解:1分钟传输位数2400bps×60=144000(位)
每个EDCDIC字符传输位数(8+1+1)=10(位)
1分钟传输的EBCDIC字符数
144000/10=14400(个)
3、当HDLC的控制帧中地址字段为“10110010”,控制字段为“10001001”,帧校验序列采用G(X)=x16+X12+X5+1
来产生,请写出此帧的完整形式。(注FCS用规定长度的X代替)
解:帧的完整格式为:
011111101011001010001001XXXXXXXXXXXXXXXX01111110
注:(1)给出前后标志字段
(2)给出地址字段,控制字段正确位置
(3)给出FCS为16个X
4、在X.25分组级(层)协议中,分组头逻辑信道标识字段用于标识逻辑信道,试问:逻辑信道共有几个组?理论
上允许多少条逻辑信道?
解:16组逻辑信道 4096条逻辑信道
5、在10km长的令牌环局域网上,有100个站点,每站引入1位延迟,数据速率为10Mbps,信号传播速度为200m/μs,
问该环的位长度为多少?该环网的实际有效位长度为多少?
解:环的位长度5×10×10+1×100=600位
1位延迟相当于多少米电缆
1/10Mbps×200m/μs=0.1μs/位×200m/μs=20m环网的实际等效长度为
10Km+20m/站×100站12km
6、假设一个主机的IP地址为192.168.5.121,而子网掩码为255.255.255.248,那么该IP地址的网络号为多少?
11000000 10101000 00000101 01110000
∧ 11111111 11111111 11111111 11111000
11000000 10101000 00000101 01110000 =192.168.5.112
7、某单位为管理方便,拟将网络195.3.1.0划分为5个子网,每个子网中的计算机数不超过15台,请规划该子网。
写出子网掩码和每个个子网的子网地址。
答:因为网络IP地址第一段为195判断是C类,
1 对C类地址,要从最后8位中分出几位作为子网地址:
∵22<5<23,∴选择3位作为子网地址,共可提供7个子网地址。
2 检查剩余的位数能否满足每个子网中主机台数的要求:
∵ 子网地址为3位,故还剩5位可以用作主机地址。而
25>15+2,所以可以满足每子网15台主机的要求。
3 子网掩码为255.255.255.228。
(11100000B = 228 )
4 子网地址可在32(001~)、64(010~)、96(011~)、128(100~)、160(101~)、192(110~)、228(111~)
共7个地址中任意选择5个
8、带宽为3KHz的信道。
a) 不考虑噪声的情况下,其最大数据传输速率为多少? S =2W=2*3=6000Baud
max
b) 若信号电平分为16级,重做a) S =2Wlog.L=2*3log.23=18Kbps
max 2 2
c) 若信噪比S/N为30dB,其最大数据传输速率为多少?
S =Wlog.(1+S/N) 10lgS/N=30 S/N=1000
max 2
S =3* log.(1+1000)<3* log.210=30Kbps
max 2 2
9、对于100BaseT标准,其传输速率为多少?采用了什么类型的传输介质?
传输速率为 100Mbps,传输媒体为3、4、5 类 UTP或光缆。
100BASE-T 的物理层包含三种媒体选项:100BASE-TX、100BASE-FX 和 100BASE-T4
10、 采用相—幅调制PAM技术在带宽为32KHz的无噪声信道上传输数字信号,每个相位处都有两种不同幅度的电
平。若要达到192Kbps的数据速度,至少要有多少种不同的相位?
解:
11、 速率为9600bps的MODEM,若采用无校验位,一位停止位的异步传输方式,试计算2分钟内最多能传输多少
个汉字(双字节)?
12、 长2km、数据传输率为10Mbps的基带总线LAN,信号传播速度为200m/us,试计算:
1)1000比特的帧从发送开始到接收结束的最大时间是多少;2)若两相距最远的站点在同一时刻发送数据,则经过多长时间两站发现冲突?
六、应用题
1、在数据传输过程中,若接收方收到发送方送来的信息为10110011010,生成多项式为G(x)=x4+x3+1,
接收方收到的数据是否正确?(请写出判断依据及推演过程)
解:接收正确
接收信息/G(X),余数为零,则正确,否则出错
推演过程:
余数为0,接收正确
2、某8比特数据经“位填充”后在信道上用曼彻斯特编码以送,信道上的波形如下图所示,试求原8比特的数据。
3、浏览器的主要访问功能,可以通过点击“工具栏”上的按钮来实现,点击 后退 可以返回前一页,点击 前进 可
以进入下一页,点击 停止 可以终止当前显示页的传输,点击 刷新 可以更新当前显示页,点击 主页 可以返
回浏览器预定的起始页。
4、请画出信息“001101”的不归零码、曼彻斯特编码、差分曼彻斯特编码波形图。解:
5、若BSC帧数据段中出现下列字符串,问字符填充后输出什么?
答:SYNSYNSTXHOWDOYOUDO?ETXBCC
写出3个控制字符
写出5个控制字符
6、安装TCP/IP协议的步骤如下:打开“控制面板”中的“网络”图标,进入“网络”对话框,在 配置 选项卡中
点击“添加”按钮,进入“请选择网络组件类型”对话框,选择 协议 ,点击“添加”按钮,再在“选择网
络协议”对话框中的 厂商 栏内选“Microsoft”,在”网络协议“中选择 TCP/IP 。
7、试根据发送滑动窗口变化过程,在下图所示各发送窗口下标出“发送帧序号”或“接收确认帧序号”说明。(参
照第一窗口说明)
发送四号帧 接收确认3号帧 发送5号帧 接收确认4号帧 接收确认5号帧
8、具有6个节点的分组交换网的拓扑结构如下图所示,若依次建立5条虚电路:ABCD、BCD、AEFD、BAE、 AECDFB
1)列出各节点的路由表及相关节点连接图示(用箭头线)
2)指出当报文分组沿虚电路H�A�E�C�D�F�B�H 传输地虚电路号的变更情况。
A B第 3333 章:操作系统习题
第1章习题解答
一、填空
1.计算机由 硬件 系统和 软件 系统两个部分组成,它们构成了一个完整的计算机系统。
2.按功能划分,软件可分为 系统 软件和 应用 软件两种。
3.操作系统是在 裸机 上加载的第一层软件,是对计算机硬件系统功能的 首次 扩充。
4.操作系统的基本功能是 处理机(包含作业) 管理、 存储 管理、 设备 管理和 文件 管理。
5.在分时和批处理系统结合的操作系统中引入“前台”和“后台”作业的概念,其目的是 改善系统功能,提高处
理能力 。
6.分时系统的主要特征为 多路性 、 交互性 、 独立性 和 及时性 。
7.实时系统与分时以及批处理系统的主要区别是 高及时性 和 高可靠性 。
8.若一个操作系统具有很强的交互性,可同时供多个用户使用,则是 分时 操作系统。
9.如果一个操作系统在用户提交作业后,不提供交互能力,只追求计算机资源的利用率、大吞吐量和作业流程的自
动化,则属于 批处理 操作系统。
10.采用多道程序设计技术,能充分发挥 CPU 和 外部设备 并行工作的能力。二、选择
1.操作系统是一种 B 。
A.通用软件 B.系统软件 C.应用软件 D.软件包
2.操作系统是对 C 进行管理的软件。
A系统软件 B.系统硬件 C.计算机资源 D.应用程序
3.操作系统中采用多道程序设计技术,以提高CPU和外部设备的 A 。
A.利用率 B.可靠性 C.稳定性 D.兼容性
4.计算机系统中配置操作系统的目的是提高计算机的 B 和方便用户使用。
A.速度 B.利用率 C.灵活性 D.兼容性
5. C 操作系统允许多个用户在其终端上同时交互地使用计算机。
A.批处理 B.实时 C.分时 D.多道批处理
6.如果分时系统的时间片一定,那么 D ,响应时间越长。
A.用户数越少 B.内存越少 C.内存越多 D.用户数越多
三、问答
1.什么是“多道程序设计”技术?它对操作系统的形成起到什么作用?
答:所谓“多道程序设计”技术,即是通过软件的手段,允许在计算机内存中同时存放几道相互独立的作业程序,
让它们对系统中的资源进行“共享”和“竞争”,以使系统中的各种资源尽可能地满负荷工作,从而提高整个计算机
系统的使用效率。基于这种考虑,计算机科学家开始把 CPU、存储器、外部设备以及各种软件都视为计算机系统的
“资源”,并逐步设计出一种软件来管理这些资源,不仅使它们能够得到合理地使用,而且还要高效地使用。具有这
种功能的软件就是“操作系统”。所以,“多道程序设计”的出现,加快了操作系统的诞生。
2.怎样理解“虚拟机”的概念?
答:拿操作系统来说,它是在裸机上加载的第一层软件,是对计算机硬件系统功能的首次扩充。从用户的角度看,
计算机配置了操作系统后,由于操作系统隐蔽了硬件的复杂细节,用户会感到机器使用起来更方便、容易了。这样,
通过操作系统的作用使展现在用户面前的是一台功能经过扩展了的机器。这台“机器”不是硬件搭建成的,现实生
活中并不存在具有这种功能的真实机器,它只是用户的一种感觉而已。所以,就把这样的机器称为“虚拟机”。
3.对于分时系统,怎样理解“从宏观上看,多个用户同时工作,共享系统的资源;从微观上看,各终端程序是轮流
运行一个时间片”?
答:在分时系统中,系统把CPU 时间划分成许多时间片,每个终端用户可以使用由一个时间片规定的 CPU 时间,
多个用户终端就轮流地使用CPU。这样的效果是每个终端都开始了自己的工作,得到了及时的响应。也就是说,“从
宏观上看,多个用户同时工作,共享系统的资源”。但实际上,CPU在每一时刻只为一个终端服务,即“从微观上看,
各终端程序是轮流运行一个时间片”。
第2章习题解答
一、填空
1.进程在执行过程中有3种基本状态,它们是 运行 态、 就绪 态和 阻塞 态。
2.系统中一个进程由 程序 、 数据集合 和 进程控制块(PCB) 三部分组成。
3.在多道程序设计系统中,进程是一个 动 态概念,程序是一个 静 态概念。4.在一个单CPU系统中,若有5个用户进程。假设当前系统为用户态,则处于就绪状态的用户进程最多有 4 个,
最少有 0 个。
注意,题目里给出的是假设当前系统为用户态,这表明现在有一个进程处于运行状态,因此最多有 4个进程处于就
绪态。也可能除一个在运行外,其他4个都处于阻塞。这时,处于就绪的进程一个也没有。
5.总的来说,进程调度有两种方式,即 不可剥夺 方式和 剥夺 方式。
6.进程调度程序具体负责 中央处理机(CPU)的分配。
7.为了使系统的各种资源得到均衡使用,进行作业调度时,应该注意 CPU忙碌 作业和 I/O忙碌 作业
的搭配。
8.所谓系统调用,就是用户程序要调用 操作系统 提供的一些子功能。
9.作业被系统接纳后到运行完毕,一般还需要经历 后备 、 运行 和 完成 三个阶段。
10.假定一个系统中的所有作业同时到达,那么使作业平均周转时间为最小的作业调度算法是 短作业优先 调度算
法。
11.在引入线程的操作系统中,所谓“线程”,是指进程中实施 处理机调度和分配 的基本单位。
12.有了线程概念后,原来的进程就属于是 单线程 的进程情形。
二、选择
1.在进程管理中,当 C 时,进程从阻塞状态变为就绪状态。
A.进程被调度程序选中 B.进程等待某一事件发生
C.等待的事件出现 D.时间片到
2.在分时系统中,一个进程用完给它的时间片后,其状态变为 A 。
A.就绪 B.等待 C.运行 D.由用户设定
3.下面对进程的描述中,错误的是 D 。
A.进程是动态的概念 B.进程的执行需要CPU
C.进程具有生命周期 D.进程是指令的集合
4.操作系统通过 B 对进程进行管理。
A.JCB B.PCB C.DCT D.FCB
5.一个进程被唤醒,意味着该进程 D 。
A.重新占有CPU B.优先级变为最大
C.移至等待队列之首 D.变为就绪状态
6.由各作业JCB形成的队列称为 C 。
A.就绪作业队列 B.阻塞作业队列
C.后备作业队列 D.运行作业队列
7.既考虑作业等待时间,又考虑作业执行时间的作业调度算法是 A 。
A.响应比高者优先 B.短作业优先
C.优先级调度 D.先来先服务
8.作业调度程序从处于 D 状态的队列中选取适当的作业投入运行。
A.就绪 B.提交 C.等待 D.后备
9. A 是指从作业提交系统到作业完成的时间间隔。
A.周转时间 B.响应时间
C.等待时间 D.运行时间
10.计算机系统在执行 C 时,会自动从目态变换到管态。
A.P操作 B.V操作 C.系统调用 D.I/O指令11.进程状态由就绪变为运行,是由于 C 引起的。
A.中断事件 B.进程状态变迁
C.进程调度 D.为作业创建进程
三、问答
1.在多道程序设计系统中,如何理解“内存中的多个程序的执行过程交织在一起,大家都在走走停停”这样一个现
象?
答:在多道程序设计系统中,内存中存放多个程序,它们以交替的方式使用 CPU。因此,从宏观上看,这些程序
都开始了自己的工作。但由于 CPU只有一个,在任何时刻CPU只能执行一个进程程序。所以这些进程程序的执行
过程是交织在一起的。也就是说,从微观上看,每一个进程一会儿在向前走,一会儿又停步不前,处于一种“走
走停停”的状态之中。
2.什么是“原语”、“特权指令”、“系统调用命令”和“访管指令”?它们之间有无一定的联系?
答:特权指令和访管指令都是CPU指令系统中的指令,只是前者是一些只能在管态下执行的指令,后者是一条只能
在目态下执行的指令。原语和系统调用命令都是操作系统中的功能程序,只是前者执行时不能被其他程序所打断,
后者没有这个要求。操作系统中有些系统调用命令是以原语的形式出现的,例如创建进程就是一条原语式的系统
调用命令。但并不是所有系统调用命令都是原语。因为如果那样的话,整个系统的并发性就不可能得到充分地发
挥。
3.操作系统是如何处理源程序中出现的系统调用命令的?
答:编译程序总是把源程序中的系统调用命令改写成为一条访管指令和相应的参数。这样在程序实际被执行时,
就通过访管指令进入操作系统,达到调用操作系统功能子程序的目的。
4.系统调用与一般的过程调用有什么区别?
答:系统调用是指在用户程序中调用操作系统提供的功能子程序;一般的过程调用是指在一个程序中调用另一个程
序。因此它们之间有如下三点区别。
(1)一般的过程调用,调用者与被调用者都运行在相同的CPU状态,即或都处于目态(用户程序调用用户程序),
或都处于管态(系统程序调用系统程序);但发生系统调用时,发出调用命令的调用者运行在目态,而被调用的对象
则运行在管态,即调用者与被调用者运行在不同的CPU状态。
(2)一般的过程调用,是直接通过转移指令转向被调用的程序;但发生系统调用时,只能通过访管指令提供的一个
统一的入口,由目态进入管态,经分析后,才转向相应的操作系统命令处理程序。
(3)一般的过程调用,在被调用者执行完后,就径直返回断点继续执行;但系统调用可能会导致进程状态的变化,
从而引起系统重新分配处理机。因此,系统调用处理结束后,不一定是返回调用者断点处继续执行。
5.试述创建进程原语的主要功能。
答:创建进程原语的主要功能有以下三项。
(1)为新建进程申请一个PCB。
(2)将创建者(即父进程)提供的新建进程的信息填入PCB中。
(3)将新建进程设置为就绪状态,并按照所采用的调度算法,把PCB排入就绪队列中。
6.处于阻塞状态的一个进程,它所等待的事件发生时,就把它的状态由阻塞改变为就绪,让它到就绪队列里排队,
为什么不直接将它投入运行呢?
答:只要是涉及管理,就应该有管理的规则,没有规则就不成方圆。如果处于阻塞状态的一个进程,在它所等待的
事件发生时就径直将它投入运行(也就是把CPU从当前运行进程的手中抢夺过来),那么系统就无法控制对CPU这
种资源的管理和使用,进而也就失去了设置操作系统的作用。所以,阻塞状态的进程在它所等待的事件发生时,必
须先进入就绪队列,然后再去考虑它使用CPU的问题。
7.作业调度与进程调度有什么区别?答:作业调度和进程调度(即 CPU调度)都涉及到CPU的分配。但作业调度只是选择参加CPU竞争的作业,它并
不具体分配CPU。而进程调度是在作业调度完成选择后的基础上,把CPU真正分配给某一个具体的进程使用。
8.系统中的各种进程队列都是由进程的 PCB 链接而成的。当一个进程的状态从阻塞变为就绪状态时,它的 PCB 从
哪个队列移到哪个队列?它所对应的程序也要跟着移来移去吗?为什么?
答:当一个进程的状态从阻塞变为就绪时,它的 PCB 就从原先在的阻塞队列移到就绪队列里。在把进程的 PCB
从这个队列移到另一个队列时,只是移动进程的 PCB,进程所对应的程序是不动的。这是因为在进程的 PCB 里,
总是记录有它的程序的断点信息。知道了断点的信息,就能够知道程序当前应该从哪里开始往下执行了。这正是
保护现场所起的作用。
9.为什么说响应比高者优先作业调度算法是对先来先服务以及短作业优先这两种调度算法的折中?
答: 先来先服务的作业调度算法,重点考虑的是作业在后备作业队列里的等待时间,因此对短作业不利;短作
业优先的作业调度算法,重点考虑的是作业所需的 CPU时间(当然,这个时间是用户自己估计的),因此对长作业
不利。“响应比高者优先”作业调度算法,总是在需要调度时,考虑作业已经等待的时间和所需运行时间之比,即:
该作业已等待时间 / 该作业所需CPU时间
不难看出,这个比值的分母是一个不变的量。随着时间的推移,一个作业的“已等待时间”会不断发生变化,也就
是分子在不断地变化。显然,短作业比较容易获得较高的响应比。这是因为它的分母较小,只要稍加等待,整个比
值就会很快上升。另一方面,长作业的分母虽然很大,但随着它等待时间的增加,比值也会逐渐上升,从而获得较
高的响应比。根据这种分析,可见“响应比高者优先”的作业调度算法,既照顾到了短作业的利益,也照顾到了长
作业的利益,是对先来先服务以及短作业优先这两种调度算法的一种折中。
10.短作业优先调度算法总能得到最小的平均周转时间吗?为什么?
答:短作业优先调度算法只有在所有作业同时到达后备作业队列时,才能得到最小的平均周转时间。如果各作业不
是同时到达,这个结论是不成立的。可以用反例说明,例如,教材上举有如下例子:考虑有 5个作业A到E,运行
时间分别是2、4、1、1、1;到达时间分别是0、0、3、3、3。按照短作业优先的原则,最初只有A和B可以参与
选择,因为其他3个还没有到达。于是,运行顺序应该是 A、B、C、D、E。它们每个的周转时间分别是2、6、4、
5、6,平均周转时间是4.6。但如果按照顺序B、C、D、E、A来调度,它们每一个的周转时间成为9、4、2、3、4,
平均周转时间是4.4。结果比短作业优先调度算法好。之所以会这样,就是因为这5个作业并没有同时到达。
四、计算
1.有三个作业:
作 业 到达时间 所需CPU时间
1 0.0 8
2 0.4 4
3 1.0 1
分别采用先来先服务和短作业优先作业调度算法。试问它们的平均周转时间各是什么?你是否还可以给出一种更好
的调度算法,使其平均周转时间优于这两种调度算法?
解:(1)采用先来先服务作业调度算法时的实施过程如下。
作 业 到达时间 所需CPU时间 开始时间 完成时间 周转时间
1 0.0 8 0.0 8.0 8.0
2 0.4 4 8.0 12.0 11.63 1.0 1 12.0 13.0 12.0
这时,作业的调度顺序是1→2→3。其平均周转时间为:
(8+11.6+12)/3=10.53
(2)采用短作业优先作业调度算法时的实施过程如下。
作 业 到达时间 所需CPU时间 开始时间 完成时间 周转时间
1 0.0 8 0.0 8.0 8.0
3 1.0 1 8.0 9.0 8.0
2 0.4 4 9.0 13.0 12.6
这里要注意,在作业 1运行完毕进行作业调度时,作业 2和3都已经到达。由于是实行短作业优先作业调度算法,
因此先调度作业3运行,最后调度作业2运行。所以,这时的作业调度顺序是1→3→2。其平均周转时间为:
(8+8+12.6)/3=9.53
(3)还可以有更好的作业调度算法,使其平均周转时间优于这两种调度算法。例如,如果知道在作业1后面会来两
个短作业,那么作业1到达后,先不投入运行。而是等所有作业到齐后,再按照短作业优先作业调度算法进行调度,
具体实施过程如下。
作 业 到达时间 所需CPU时间 开始时间 完成时间 周转时间
3 1.0 1 1.0 2.0 1.0
2 0.4 4 2.0 6.0 5.6
1 0.0 8 6.0 14.0 14.0
这时的作业调度顺序是3→2→1。其平均周转时间为:
(1+5.6+14)/3=6.87
2.设有一组作业,它们的到达时间和所需CPU时间如下所示。
作业号 到达时间 所需CPU时间
1 9:00 70分钟
2 9:40 30分钟
3 9:50 10分钟
4 10:10 5分钟
分别采用先来先服务和短作业优先作业调度算法。试问它们的调度顺序、作业周转时间以及平均周转时间各是什么?
解:(1)采用先来先服务作业调度算法时的实施过程如下。
作业号 到达时间 所需CPU时间 开始时间 完成时间 周转时间
1 9:00 70分钟 9:00 10:10 70分钟
2 9:40 30分钟 10:10 10:40 60分钟
3 9:50 10分钟 10:40 10:50 60分钟4 10:10 5分钟 10:50 10:55 45分钟
这时,作业的调度顺序是1→2→3→4。其平均周转时间为:
(70+60 +60 +45)/4=58.75
(2)采用短作业优先作业调度算法时的实施过程如下。
作业号 到达时间 所需CPU时间 开始时间 完成时间 周转时间
1 9:00 70分钟 9:00 10:10 70分钟
4 10:10 5分钟 10:10 10:15 5分钟
3 9:50 10分钟 10:15 10:25 35分钟
2 9:40 30分钟 10:25 10:55 75分钟
这时,作业的调度顺序是1→4→3→2。其平均周转时间为:
(70+5+35+75)/4=46.25
3.某系统有三个作业:
作业号 到达时间 所需CPU时间
1 8.8 1.5
2 9.0 0.4
3 9.5 1.0
系统确定在它们全部到达后,开始采用响应比高者优先调度算法,并忽略系统调度时间。试问对它们的调度顺序是
什么?各自的周转时间是多少?
解:三个作业是在9.5时全部到达的。这时它们各自的响应比如下:
作业1的响应比 =(9.5 –8.8)/1.5=0.46
作业2的响应比 =(9.5 –9.0)/0.4=1.25
作业3的响应比 =(9.5 –9.5)/1.0=0
因此,最先应该调度作业2运行,因为它的响应比最高。它运行了 0.4后完成,这时的时间是9.9。再计算作业1和
3此时的响应比:
作业1的响应比 =(9.9 –8.8)/1.5=0.73
作业3的响应比 =(9.9 –9.5)/1.0=0.40
因此,第二个应该调度作业1运行,因为它的响应比最高。它运行了1.5 后完成,这时的时间是11.4。第三个调度的
是作业3,它运行了1.0后完成,这时的时间是12.4。整个实施过程如下。
作业号 到达时间 所需CPU时间 开始时间 完成时间 周转时间
2 9.0 0.4 9.5 9.9 0.9
1 8.8 1.5 9.9 11.4 2.6
3 9.5 1.0 11.4 12.4 2.9
作业的调度顺序是2→1→3。各自的周转时间为:作业1为0.9;作业2为2.6;作业3为2.9。第3章(大本)习题解答
一、填空
1.将作业相对地址空间的相对地址转换成内存中的绝对地址的过程称为 地址重定位 。
2.使用覆盖与对换技术的主要目的是 提高内存的利用率 。
3.存储管理中,对存储空间的浪费是以 内部碎片 和 外部碎片 两种形式表现出来的。
4.地址重定位可分为 静态重定位 和 动态重定位 两种。
5.在可变分区存储管理中采用最佳适应算法时,最好按 尺寸 法来组织空闲分区链表。
6.在分页式存储管理的页表里,主要应该包含 页号 和 块号 两个信息。
7.静态重定位在程序 装入 时进行,动态重定位在程序 执行 时进行。
8.在分页式存储管理中,如果页面置换算法选择不当,则会使系统出现 抖动 现象。
9.在请求分页式存储管理中采用先进先出(FIFO)页面淘汰算法时,增加分配给作业的块数时, 缺页中断 的次数
有可能会增加。
10.在请求分页式存储管理中,页面淘汰是由于 缺页 引起的。
11.在段页式存储管理中,每个用户作业有一个 段 表,每段都有一个 页 表。
二、选择
1.虚拟存储器的最大容量是由 B 决定的。
A.内、外存容量之和 B.计算机系统的地址结构
C.作业的相对地址空间 D.作业的绝对地址空间
2.采用先进先出页面淘汰算法的系统中,一进程在内存占3块(开始为空),页面访问序列为1、2、3、4、1、2、5、
1、2、3、4、5、6。运行时会产生 D 次缺页中断。
A.7 B.8 C.9 D.10
从图3-1 中的“缺页计数”栏里可以看出应该选择D。
页面走向→ 1 2 3 4 1 2 5 1 2 3 4 5 6
1 2 3 4 1 2 5 5 5 3 4 4 6
3个内存块→ 1 2 3 4 1 2 2 2 5 3 3 4
1 2 3 4 1 1 1 2 5 5 3
缺缺页页计计数数→→ √ √ √ √ √ √ √ √ √ √
图3-1 选择题2配图
3.系统出现“抖动”现象的主要原因是由于 A 引起的。
A.置换算法选择不当 B.交换的信息量太大
C.内存容量不足 D.采用页式存储管理策略
4.实现虚拟存储器的目的是 D 。
A.进行存储保护 B.允许程序浮动
C.允许程序移动 D.扩充主存容量
5.作业在执行中发生了缺页中断,那么经中断处理后,应返回执行 B 指令。
A.被中断的前一条 B.被中断的那条
C.被中断的后一条 D.程序第一条
6.在实行分页式存储管理系统中,分页是由 D 完成的。A.程序员 B.用户 C.操作员 D.系统
7.下面的 A 页面淘汰算法有时会产生异常现象。
A.先进先出 B.最近最少使用 C.最不经常使用 D.最佳
8.在一个分页式存储管理系统中,页表的内容为:
若页的大小为4KB,则地址转换机构将相对地址0转 换成的物理地址是
页号 块号
A 。
0 2
A.8192 B.4096
C.2048 D.1024 1 1
注意,相对地址0肯定是第0页的第0个字节。查页表可知第0页存放在内存的第2块。现在块的尺寸是 4KB,因
此第2块的起始地址为8192。故相对地址0所对应的绝对地址(即物理地址)是 8192。
9.下面所列的存储管理方案中, A 实行的不是动态重定位。
A.固定分区 B.可变分区 C.分页式 D.请求分页式
10.在下面所列的诸因素中,不对缺页中断次数产生影响的是 C 。
A.内存分块的尺寸 B.程序编制的质量
C.作业等待的时间 D.分配给作业的内存块数
11.采用分段式存储管理的系统中,若地址用24位表示,其中8位表示段号,则允许每段的最大长度是 B 。
A.224 B.216 C.28 D.232
三、问答
1.什么是内部碎片?什么是外部碎片?各种存储管理中都可能产生何种碎片?
答:所谓“内部碎片”,是指系统已经分配给用户使用、用户自己没有用到的那部分存储空间;所谓“外部碎片”,
是指系统无法把它分配出去供用户使用的那部分存储空间。对于教材而言,单一连续区存储管理、固定分区存储管
理、分页式存储管理和请求页式存储管理都会出现内部碎片。只是前两种存储管理造成的内部碎片比较大,浪费较
为严重;后两种页式存储管理,平均来说每个作业都会出现半页的内部碎片。教材中,只有可变分区存储管理会产
生外部碎片。
2.叙述静态重定位与动态重定位的区别。
答:静态重定位是一种通过软件来完成的地址重定位技术。它在程序装入内存时,完成对程序指令中地址的调整。
因此,程序经过静态重定位以后,在内存中就不能移动了。如果要移动,就必须重新进行地址重定位。
动态重定位是一种通过硬件支持完成的地址重定位技术。作业程序被原封不动地装入内存。只有到执行某
条指令时,硬件地址转换机构才对它里面的地址进行转换。正因为如此,实行动态重定位的系统,作业
程序可以在内存里移动。也就是说,作业程序在内存中是可浮动的。
3.一个虚拟地址结构用24个二进制位表示。其中12 个二进制位表示页面尺寸。试问这种虚拟地址空间总共多少页?
每页的尺寸是多少?
答:如下图所示,由于虚拟地址中是用 12 个二进制位表示页面尺寸(即页内位移),所以虚拟地址空间中表示页号
的也是12个二进制位。这样,这种虚拟地址空间总共有:
212=4096(页)
每页的尺寸是:
212=4096 =4K(字节)
23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
页号 页内位移
虚拟地址4.什么叫虚拟存储器?怎样确定虚拟存储器的容量?
答:虚拟存储器实际是一种存储扩充技术。它把作业程序存放在辅助存储器里,运行时只装入程序的一部分。遇到
不在内存的程序时,再把所需要的部分装入。这样在内存和辅存之间调入、调出的做法,使用户的作业地址空间无
需顾及内存的大小。给用户造成的印象是,无论程序有多大,它在这个系统上都可以运行。这种以辅助存储器作为
后援的虚幻存储器,就称为虚拟存储器。虚拟存储器的大小是由系统的地址结构确定的。
5.为什么请求分页式存储管理能够向用户提供虚拟存储器?
答:请求分页式存储管理的基本思想是:操作系统按照存储块的尺寸,把用户作业地址空间划分成页,全部存放在
磁盘上。作业运行时,只先装入若干页。运行过程中遇到不在内存的页时,操作系统就把它从磁盘调入内存。这样
一来,用户的作业地址空间无需顾及内存的大小。这与虚拟存储器的思想是完全吻合的。所以,请求分页式存储管
理能够向用户提供虚拟存储器。
6.在请求分页式存储管理中,为什么既有页表,又有快表?
答:在分页式或请求页式存储管理中,通常是利用内存储器构成页表的。当CPU执行到某条指令、要对内存中的某
一地址访问时,因为这个地址是相对地址,所以先要根据这个地址所在的页号去查页表(访问一次内存),然后才能
由所形成的绝对地址去真正执行指令(第二次访问内存)。可见,由于页表在内存,降低了CPU的访问速度。
为了提高相对地址到绝对地址的变换速度,人们想到用一组快速寄存器来代替页表。这时查页表是以并行的方式进
行,立即就能输出与该页号匹配的块号,这样做无疑比内存式的页表要快得多。但是,快速寄存器的价格昂贵,由
它来组成整个页表是不可取的。考虑到程序运行时具有局部性,因此实际系统中总是一方面采用内存页表、另一方
面用极少几个快速寄存器组成快表来共同完成地址的变换工作。这时的地址变换过程,如教材中的图 3-22所示。
7.试述缺页中断与页面淘汰之间的关系。
答:在请求页式存储管理中,当根据虚拟地址查页表而发现所要访问的页不在内存时,就会产生缺页中断。系统响
应中断后,就由操作系统到辅存把所需要的页读入内存。这时,内存可能有空闲的块,也可能没有。只有当内存中
没有空闲块时,才会出现将内存现有页面淘汰出去的问题,即要进行页面淘汰。所以,缺页中断和页面淘汰之间的
关系是:页面淘汰一定是由缺页中断所引起;但缺页中断则不一定引起页面淘汰。
8.试述缺页中断与一般中断的区别。
答:在计算机系统中,由于某些事件的出现,打断了当前程序的运行,而使CPU去处理出现的事件,这称为“中断”。
通常,计算机的硬件结构都是在执行完一条指令后,去检查有无中断事件发生的。如果有,那么就暂停当前程序的
运行,而让CPU去执行操作系统的中断处理程序,这叫“中断响应”。CPU在处理完中断后,如果不需要对CPU重
新进行分配,那么就返回被中断进程的程序继续运行;如果需要进行CPU的重新分配,那么操作系统就会去调度新
进程。
由上面的讲述可以看出,缺页中断与一般中断的区别如下。
(1)两种中断产生的时刻不同:缺页中断是在执行一条指令中间时产生的中断,并立即转去处理;而一般中断则是
在一条指令执行完毕后,当硬件中断装置发现有中断请求时才去响应和处理。
(2)处理完毕后的归属不同:缺页中断处理完后,仍返回到原指令去重新执行,因为那条指令并未执行;而一般中
断则是或返回到被中断进程的下一条指令去执行,因为上一条指令已经执行完了,或重新调度,去执行别的进程程
序。
9.怎样理解把相对地址划分成数对:(页号,页内位移)的过程对于用户是“透明”的?
答:在操作系统中,所谓“透明”,即指用户不知道的意思。对于分页式存储管理来说,用户向系统提供的相对地址
空间,是一个一维的连续空间。系统接受了这个作业后,在内部把这个相对地址空间划分成若干页。由于这种划分
对于用户来说是根本不知道的,所以说把相对地址划分成数对:(页号,页内位移)的过程对于用户是“透明”的。
10.做一个综述,说明从单一连续区存储管理到 固定分区存储管理,到
可变分区存储管理,到分页式存储管理,再到请
单道
求分页式存储管理,每
单一连续分区存储管理
一种存储管理的出现,都是在原有基础上的发展 固定分区存储管理 和提高。
多道
答:教材共介绍了 5种存储管理策略,它们适用 于不同的场合,如图
3-2所示。图中,在单一连续分区存储管理与固定 连续 分区存储管理之间画
可变分区存储管理
分页式存储管理
不连续
全部
请求页式存储管理
部分
图3-2 各种存储管理策略的适用场合了一条线,那表明位于线以上的存储管理策略只适用于单道程序设计,以下的适用于多道程序设计;在可变分区存
储管理与分页式存储管理之间画了一条线,那表明位于线以上的存储管理策略都要求为进入内存的作业分配一个连
续的存储区,以下的存储管理策略打破了连续性的要求;在分页式存储管理与请求页式存储管理之间画了一条线,
那表明位于线以上的存储管理策略都要求使作业程序全部进入内存,而以下的存储管理策略打破了全部的要求,只
要部分装入内存就可以了。
由此可见,每一种存储管理的出现,都是在原有存储管理基础上的一次发展和提高。它们从简单到复杂,从不完善
到逐渐完善。
11.试述分页式系统与分段式系统的主要区别。
答:从形式上看,分页式系统与分段式系统有许多相似之处,比如两者都不要求作业在内存中连续存放。但在概念
上,两者却完全不同。主要表现在以下几个方面。
(1)把用户作业进行分页,是系统的一种行为,对用户是透明的。所以,页是信息的物理单位。分段是为了满足用
户的需要,每段在逻辑上都有完整的意义,因此是信息的逻辑单位。
(2)页的大小固定,且由系统决定。将逻辑地址划分成数对(页号,页内位移),是由机器硬件实现的。段的长度
不固定,取决于用户所编写的程序结构,通常由编译程序在对源程序进行编译时根据信息的性质来划分。
(3)分页时,作业的地址空间是一维的;分段时,作业的地址空间是二维的。
四、计算
1.在可变分区存储管理中,按地址法组织当前的空闲分区,其大小分别为:10KB,4KB,20KB,18KB,7KB,9KB,
12KB和15KB。现在依次有3 个存储请求为:12KB,10KB,9KB。试问使用最先适应算法时的分配情形如何?那
么最佳适应、最坏适应呢?
解:我们用表来说明实行各种分配算法时的情形。
(1)最先适应算法
请求队列 最先适应算法
初始 10K 4K 20K 18K 7K 9K 12K 15K
12K 10K 4K 8K 18K 7K 9K 12K 15K
10K 0000 4K 8K 18K 7K 9K 12K 15K
9K 0000 4K 8K 9K 7K 9K 12K 15K
(2)最佳适应算法
请求队列 最佳适应算法
初始 10K 4K 20K 18K 7K 9K 12K 15K
12K 10K 4K 20K 18K 7K 9K 0 15K
10K 0 4K 20K 18K 7K 9K 0 15K
9K 0 4K 20K 18K 7K 0 0 15K
(3)最坏适应算法
请求队列 最坏适应算法
初始 10K 4K 20K 18K 7K 9K 12K 15K12K 10K 4K 8K 18K 7K 9K 12K 15K
10K 10K 4K 8K 8K 7K 9K 12K 15K
9K 10K 4K 8K 8K 7K 9K 12K 6K
可见,分配算法不同,选择的分配对象也不一样。
2.系统内存被划分成8块,每块4KB。某作业的虚拟地址空间共划分成16 个页面。当前在内存的页与内存块的对
应关系如下表所示,未列出的页表示不在内存。
页 号 块 号 页 号 块 号
0 2 4 4
1 1 5 3
2 6 9 5
3 0 11 7
试指出对应于下列虚拟地址的绝对地址:
(a)20 (b)4100 (c)8300
解:(a)虚拟地址20对应的页号是0,页内位移是20。用0去查页表,知道第0页现在存放在内存的第2块。由于
每块的长度是4KB,所以第2块的起始地址为8192。因此,虚拟地址20所对应的绝对地址是:
8192+20=8212
(b)虚拟地址4100 对应的页号是:
4100/4096=1(“/”是整除运算符)
对应的页内位移是:
4100%4096=4(“%”是求余运算符)
用1去查页表,知道第1页现在存放在内存的第 1块。第1块的起始地址为4096。因此,虚拟地址4100 所对应的绝
对地址是:
4096+4=4100
(c)虚拟地址8300 对应的页号是:
8300/4096=2(“/”是整除运算符)
对应的页内位移是:
8300%4096=108(“%”是求余运算符)
用2去查页表,知道第2页现在存放在内存的第6块。第6块的起始地址为
6×4K=24576
因此,虚拟地址8300 所对应的绝对地址是
24576+108=24684
3.某请求分页式存储管理系统,接收一个共7页的作业。作业运行时的页面走向如下:
1,2,3,4,2,1,5,6,2,1,2,3,7,6,3,2,1,2,3,6
若采用最近最久未用(LRU)页面淘汰算法,作业在得到2块和 4块内存空间时,各会产生出多少次缺页中断?如
果采用先进先出(FIFO)页面淘汰算法时,结果又如何?
解:(1)采用最近最久未用(LRU)页面淘汰算法,作业在得到2块内存空间时所产生的缺页中断次数为18 次,如
图3-3(a)所示;在得到4块内存空间时所产生的缺页中断次数为10次,如图3-3(b)所示。页面走向→ 1 2 3 4 2 1 5 6 2 1 2 3 7 6 3 2 1 2 3 6
1 2 3 4 2 1 5 6 2 1 2 3 7 6 3 2 1 2 3 6
2个内存块→
1 2 3 4 2 1 5 6 2 1 2 3 7 6 3 2 1 2 3
缺缺页页计计数数→→ √ √ √ √ √ √ √ √ √ √ √ √ √ √ √ √ √ √
(a) 2块时的LRU
页面走向→ 1 2 3 4 2 1 5 6 2 1 2 3 7 6 3 2 1 2 3 6
1 2 3 4 2 1 5 6 2 1 2 3 7 6 3 2 1 2 3 6
1 2 3 4 2 1 5 6 2 1 2 3 7 6 3 2 1 2 3
4个内存块→
1 2 3 4 2 1 5 6 6 1 2 3 7 6 3 3 1 2
1 1 3 4 2 1 5 5 6 1 2 2 7 6 6 6 1
缺缺页页计计数数→→ √ √ √ √ √ √ √ √ √ √
(b) 4块时的LUR
图3-3 LRU时的情形
(2)采用先进先出(FIFO)页面淘汰算法,作业在得到 2块内存空间时所产生的缺页中断次数为 18 次,如图3-4
(a)所示;在得到4块内存空间时所产生的缺页中断次数为14次,如图3-4(b)所示。
页面走向→ 1 2 3 4 2 1 5 6 2 1 2 3 7 6 3 2 1 2 3 6
1 2 3 4 2 1 5 6 2 1 1 3 7 6 3 2 1 1 3 6
2个内存块→
1 2 3 4 2 1 5 6 2 2 1 3 7 6 3 2 2 1 3
缺缺页页计计数数→→ √ √ √ √ √ √ √ √ √ √ √ √ √ √ √ √ √ √
(a) 2块时的FIFO
页面走向→ 1 2 3 4 2 1 5 6 2 1 2 3 7 6 3 2 1 2 3 6
1 2 3 4 4 4 5 6 2 1 1 3 7 6 6 2 1 1 3 3
1 2 3 3 3 4 5 6 2 2 1 3 7 7 6 2 2 1 1
4个内存块→
1 2 2 2 3 4 5 6 6 2 1 3 3 7 6 6 2 2
1 1 1 2 3 4 5 5 6 2 1 1 3 7 7 6 6
缺缺页页计计数数→→ √ √ √ √ √ √ √ √ √ √ √ √ √
(b) 4块时的FIFO
图3-4 FIFO时的情形
关于先进先出(FIFO)页面淘汰算法,在给予作业更多的内存块时,缺页中断次数有可能上升,这是所谓的异常现
象。但要注意,并不是在任何情况下都会出现异常。是否出现异常,取决于页面的走向。本题所给的页面走向,在
FIFO页面淘汰算法下,并没有引起异常:2块时缺页中断次数为18次,4块时缺页中断次数为14 次。
4.在一个分段式存储管理中,有段表如下:
段号 段长 基址
0 210 500
1 2350 20
2 100 90
3 1350 590
4 1938 95
试求逻辑地址[0,430]、[1,10]、[2,500]、[3,400]、[4,112]、[5,32]所对应的物理地址。
解:(1)逻辑地址[0,430]的物理地址是210+430=640;
(2)逻辑地址[1,10]的物理地址是2350+10=2360;
(3)由于第2段的基址是100,段长是90,所以逻辑地址[2,500]为非法;
(4)逻辑地址[3,400]的物理地址是1350+400=1750;
(5)由于第4段的基址是1938,段长是95,所以逻辑地址[4,112]为非法;
(6)由于该作业不存在第5段,所以逻辑地址[5,32]为非法。第 4444章习题解答
一、填空
1.磁带、磁盘这样的存储设备都是以 块 为单位与内存进行信息交换的。
2.根据用户作业发出的磁盘I/O请求的柱面位置,来决定请求执行顺序的调度,被称为 移臂 调度。
3.DMA控制器在获得总线控制权的情况下能直接与 内存储器 进行数据交换,无需CPU介入。
4.在DMA方式下,设备与内存储器之间进行的是 成批 数据传输。
5.通道程序是由 通道 执行的。
6.通道是一个独立与CPU的、专门用来管理 输入/输出操作 的处理机。
7.缓冲的实现有两种方法:一种是采用专门硬件寄存器的硬件缓冲,一种是在内存储器里开辟一个区域,作为专用
的I/O缓冲区,称为 软件缓冲 。
8.设备管理中使用的数据结构有系统设备表(SDT)和 设备控制块(DCB) 。
9.基于设备的分配特性,可以把系统中的设备分为独享、共享和 虚拟 三种类型。
10.引起中断发生的事件称为 中断源 。
二、选择
1.在对磁盘进行读/写操作时,下面给出的参数中, C 是不正确的。
A. 柱面号 B.磁头号 C.盘面号 D.扇区号
2.在设备管理中,是由 B 完成真正的I/O操作的。
A.输入/输出管理程序 B.设备驱动程序
C.中断处理程序 D.设备启动程序
3.在下列磁盘调度算法中,只有 D 考虑I/O请求到达的先后次序。
A.最短查找时间优先调度算法 B.电梯调度算法
C.单向扫描调度算法 D.先来先服务调度算法
4.下面所列的内容里, C 不是DMA方式传输数据的特点。
A.直接与内存交换数据 B.成批交换数据
C.与CPU并行工作 D.快速传输数据
5.在CPU启动通道后,由 A 执行通道程序,完成CPU所交给的I/O任务。
A. 通道 B.CPU C.设备 D.设备控制器
6.利用SPOOL技术实现虚拟设备的目的是 A 。
A.把独享的设备变为可以共享 B.便于独享设备的分配
C.便于对独享设备的管理 D.便于独享设备与CPU并行工作
7.通常,缓冲池位于 C 中。
A.设备控制器 B.辅助存储器 C.主存储器 D.寄存器
8. B 是直接存取的存储设备。
A.磁带 B.磁盘 C.打印机 D.键盘显示终端
9.SPOOLING系统提高了 A 的利用率。
A.独享设备 B.辅助存储器 C.共享设备 D.主存储器
10.按照设备的 D 分类,可将系统中的设备分为字符设备和块设备两种。
A.从属关系 B.分配特性 C.操作方式 D.工作特性三、问答
1.基于设备的从属关系,可以把设备分为系统设备与用户设备两类。根据什么来区分一个设备是系统设备还是用户
设备呢?
答:所谓“系统设备”,是指在操作系统生成时就已被纳入系统管理范围的设备;所谓“用户设备”是指在完成应用
任务过程中,用户特殊需要的设备。因此,判定一个设备是系统设备还是用户设备,依据是它在系统生成时,是否
已经纳入了系统的管理范围。如果是,它就是系统设备;如果不是,它就是用户设备。
2.设备管理的主要功能是什么?
答:设备管理的主要功能是:(1)提供一组I/O命令,以便用户进程能够在程序中提出I/O请求,这是用户使用外部
设备的“界面”;(2)记住各种设备的使用情况,实现设备的分配与回收;(3)对缓冲区进行管理,解决设备与设备
之间、设备与CPU之间的速度匹配问题;(4)按照用户的具体请求,启动设备,通过不同的设备驱动程序,进行实
际的I/O操作;I/O操作完成之后,将结果通知用户进程,从而实现真正的I/O操作。
3.试分析最短查找时间优先调度算法的“不公平”之处。例如例4-1里,原来磁臂移到16柱面后,下一个被处理的
I/O请求是柱面1。假定在处理16柱面时,到达一个对柱面8的I/O新请求,那么下一个被处理的就不是柱面1而是
柱面8了。这有什么弊端存在?
答:最短查找时间优先调度算法,只考虑各I/O请求之间的柱面距离,不去过问这些请求到达的先后次序。这样一来,
可能会出现的弊端是磁头总是关照邻近的I/O请求,冷待了早就到达的、位于磁盘两头的I/O请求。这对于它们来说,
当然是“不公平”的。
4.总结设备和CPU在数据传输的4种方式中,各自在“启动、数据传输、I/O管理以及善后处理”各个环节所承担
的责任。
答:使用“程序循环测试”的方式来进行数据传输,不仅启动、I/O管理和善后处理等工作要由 CPU来承担,即使
在数据传输时,CPU也要做诸如从控制器的数据寄存器里取出设备的输入信息,送至内存;将输出的信息,从内存
送至控制器的数据寄存器,以供设备输出等工作。因此,在这种方式下,CPU 不仅要花费大量时间进行测试和等待,
并且只能与设备串行工作,整个计算机系统的效率发挥不出来。
使用“中断”的方式来进行数据传输,启动、I/O管理以及善后处理等工作仍然要由 CPU 来承担,但在设备进行数
据传输时,CPU和外部设备实行了并行工作。在这种方式下,CPU的利用率有了一定的提高。
使用“直接存储器存取(DMA)”的方式来进行数据传输,I/O的启动以及善后处理是CPU的事情,数据传输以及
I/O管理等事宜均由DMA负责实行。不过,DMA方式是通过“窃取”总线控制权的办法来工作的。在它工作时,
CPU被挂起,所以并非设备与CPU在并行工作。因此,在一定程度上影响了 CPU的效率。
使用“通道”方式来进行数据传输,在用户发出I/O请求后,CPU就把该请求全部交由通道去完成。通道在整个I/O
任务结束后,才发出中断信号,请求 CPU进行善后处理。这时 CPU对I/O请求只去做启动和善后处理工作,输入/
输出的管理以及数据传输等事宜,全部由通道独立完成,并且真正实现了 CPU与设备之间的并行操作。
5.用户程序中采用“设备类,相对号”的方式使用设备有什么优点?
答:在用户程序中采用“设备类,相对号”的方式使用设备的优点是:第一,用户不需要记住系统中每一台设备的
具体设备号,这是非常麻烦的事情;第二,在多道程序设计环境下,用户并不知道当前哪一台设备已经分配,哪一
台设备仍然空闲。通过“设备类,相对号”来提出对设备的使用请求,系统就可以根据当前的具体情况来分配,从
而提高设备的使用效率;第三,用户并不知道设备的好坏情况。如果是用“绝对号”指定具体的设备,而该设备正
好有故障时,这次I/O任务就不可能完成,程序也就无法运行下去。但通过“设备类,相对号”来提出对设备的使用
请求,系统就可以灵活处理这种情况,把好的设备分配出去。
6.启动磁盘执行一次输入/输出操作要花费哪几部分时间?哪个时间对磁盘的调度最有影响?
答:执行一次磁盘的输入/输出操作需要花费的时间包括三部分:(1)查找时间;(2)等待时间;(3)传输时间。在这
些时间中,传输时间是设备固有的特性,无法用改变软件的办法将它改进。因此,要提高磁盘的使用效率,只能在减
少查找时间和等待时间上想办法,它们都与I/O在磁盘上的分布位置有关。由于磁臂的移动是靠控制电路驱动步进电机来实现,它的运动速度相对于磁盘轴的旋转来讲较缓慢。因此,查找时间对磁盘调度的影响更为主要。
7.解释通道命令字、通道程序和通道地址字。
答:所谓“通道命令字”,是指通道指令系统中的指令。只是为了与CPU的指令相区别,才把通道的指令改称为“通
道命令字”。
若干条通道命令字汇集在一起,就构成了一个“通道程序”,它规定了设备应该执行的各种操作和顺序。
通常,通道程序存放在通道自己的存储部件里。当通道中没有存储部件时,就存放在内存储器里。这时,为了使通
道能取得通道程序去执行,必须把存放通道程序的内存起始地址告诉通道。存放这个起始地址的内存固定单元,被
称为“通道地址字”。
8.何为DMA?通道与DMA有何区别?
答:所谓“DMA”,是指“直接存储器存取”的数据传输方式,其最大特点是能使I/O设备直接和内存储器进行成批
数据的快速传输。适用于一些高速的I/O设备,如磁带、磁盘等。通道方式与DMA方式之间的区别如下。
(1)在DMA方式下,数据传输的方向、传输长度和地址等仍然需要由CPU来控制。但在通道方式下,所需的CPU
干预大大减少。
(2)在DMA方式下,每台设备要有一个DMA控制器。当设备增加时,多个DMA控制器的使用,显然不很经济;
但在通道方式下,一个通道可以控制多台设备,这不仅节省了费用,而且减轻了CPU在输入/输出中的负担。
(3)在DMA方式下传输数据时,是采用“窃取”总线控制权的办法来工作的。因此,CPU与设备之间并没有实现
真正的并行工作;在通道方式下,CPU把I/O任务交给通道后,它就与通道就真正并行工作。
9.解释记录的成组与分解。为什么要这样做?
答:往磁带、磁盘上存放信息时,经常是把若干个记录先在内存缓冲区里拼装成一块,然后再写到磁带或磁盘上。
存储设备与内存储器进行信息交换时,就以块为单位。这个把记录拼装成块的过程,被称为是“记录的成组”。
从磁带、磁盘上读取记录时,先是把含有那个记录的块读到内存的缓冲区中,在那里面挑选出所需要的记录,然后
把它送到内存存放的目的地。这个把记录从缓冲区里挑选出来的过程,被称为是“记录的分解”。
之所以这样做,一是为了提高存储设备的存储利用率;二是减少内、外存之间信息交换次数,提高系统的效率。
10.试述SPOOL系统中的3个组成软件模块各自的作用。
答:SPOOLING系统中的3个软件模块是预输入程序、缓输出程序和井管理程序。它们各自的作用如下。
(1)预输入程序预先把作业的全部信息输入到磁盘的输入井中存放,以便在需要作业信息以及作业运行过程中需要
数据时,可以直接从输入井里得到,而无需与输入机交往,避免了等待使用输入机的情况发生。
(2)缓输出程序总是查看“输出井”中是否有等待输出的作业信息。如果有,就启动输出设备(如打印机)进行输
出。因此,由于作业的输出是针对输出井进行的,所以不会出现作业因为等待输出而阻塞的现象。
(3)井管理程序分为“井管理读程序”和“井管理写程序”。当作业请求输入设备工作时,操作系统就调用井管理
读程序,把让输入设备工作的任务,转换成从输入井中读取所需要的信息;当作业请求打印输出时,操作系统就调
用井管理写程序,把让输出设备工作的任务,转换成为往输出井里输出。
四、计算
1.在例4-1 里,对电梯调度算法只给出了初始由外往里移动磁臂时的调度结果。试问如果初始时假定是由里往外移
动磁臂,则调度结果又是什么?
解:这时调度的顺序是11→9→1→12→16→34→36,总共划过的柱面数是:
2+8+11+4+18+2=45
2.磁盘请求以10、22、20、2、40、6、38 柱面的次序到达磁盘驱动器。移动臂移动一个柱面需要6ms,实行以下
磁盘调度算法时,各需要多少总的查找时间?假定磁臂起始时定位于柱面 20。
(a)先来先服务;
(b)最短查找时间优先;(c)电梯算法(初始由外向里移动)。
解:(a)先来先服务时,调度的顺序是20→10→22→20→2→40→6→38,总共划过的柱面数是:
10+12+2+18+38+34+32=146
因此,总的查找时间为:146×6=876ms。
(b)最短查找时间优先时,调度的顺序是 20→22→10→6→2→38→40(由于磁臂起始时定位于柱面20,所以可以
把后面第20 柱面的访问立即进行),总共划过的柱面数是:
2+12+4+4+36+2=60
因此,总的查找时间为:60×6=360ms。
(c)电梯算法(初始由外向里移动)时,调度的顺序是 20→22→38→40→10→6→2(由于磁臂起始时定位于柱面
20,所以可以把后面第20 柱面的访问立即进行),总共划过的柱面数是:
2+16+2+30+4+4=58
因此,总的查找时间为:58×6=348ms。
3.假定磁盘的移动臂现在处于第8 柱面。有如下表所示的6个I/O请求等待访问磁盘,试列出最省时间的I/O响应
次序。
序 号 柱 面 号 磁 头 号 扇 区 号
1 9 6 3
2 7 5 6
3 15 20 6
4 9 4 4
5 20 9 5
6 7 15 2
解:由于移动臂现在处于第8柱面,如果按照“先来先服务”调度算法,对这6个I/O的响应次序应该是8→9→7→
15→9→20→7;如果是按照“最短查找时间优先”调度算法,对这6个I/O的响应次序可以有两种,一是8→9→7→
15→20(到达9时完成1 和4的请求,到达7时完成2和6的请求),二是8→7→9→15→20(到达7时完成2和6
的请求,到达9 时完成1和4的请求);如果按照“电梯”调度算法,对这6个I/O的响应次序可以有两种,一是 8
→9→15→20→7(由里往外的方向,到达9时完成1和4的请求,到达7时完成2和6的请求),二是8→7→9→15
→20(由外往里的方向,到达7时完成2和6的请求,到达9时完成1和4的请求);如果按照“单向扫描”调度算
法,对这6个I/O的响应次序是8→9→15→20→0→7。对比后可以看出,实行8→7→9→15→20 的响应次序会得到
最省的时间,因为这时移动臂的移动柱面数是:
1+2+6+5=14
第5章习题解答
一、填空
1.一个文件的文件名是在 创建该文件 时给出的。
2.所谓“文件系统”,由与文件管理有关的 那部分软件 、被管理的文件以及管理所需要的数据结构三部分组成。
3. 块 是辅助存储器与内存之间进行信息传输的单位。
4.在用位示图管理磁盘存储空间时,位示图的尺寸由磁盘的 总块数 决定。
5.采用空闲区表法管理磁盘存储空间,类似于存储管理中采用 可变分区存储管理 方法管理内存储器。6.操作系统是通过 文件控制块(FCB)感知一个文件的存在的。
7.按用户对文件的存取权限将用户分成若干组,规定每一组用户对文件的访问权限。这样,所有用户组存取权限的
集合称为该文件的 存取控制表 。
8.根据在辅存上的不同存储方式,文件可以有顺序、 链接和索引三种不同的物理结构。
9.如果把文件视为有序的字符集合,在其内部不再对信息进行组织划分,那么这种文件的逻辑结构被称为“ 流式
文件 ”。
10.如果用户把文件信息划分成一个个记录,存取时以记录为单位进行,那么这种文件的逻辑结构称为“ 记录式文
件 ”。
二、选择
1.下面的 B 不是文件的存储结构。
A.索引文件 B.记录式文件
C.串联文件 D.连续文件
2.有一磁盘,共有10个柱面,每个柱面20 个磁道,每个盘面分成16 个扇区。采用位示图对其存储空间进行管理。
如果字长是16 个二进制位,那么位示图共需 A 字。
A.200 B.128 C.256 D.100
3.操作系统为每一个文件开辟一个存储区,在它的里面记录着该文件的有关信息。这就是所谓的 B 。
A.进程控制块 B.文件控制块
C.设备控制块 D.作业控制块
4.文件控制块的英文缩写符号是 C 。
A.PCB B.DCB C.FCB D.JCB
5.一个文件的绝对路径名总是以 C 打头。
A.磁盘名 B.字符串 C.分隔符 D.文件名
6.一个文件的绝对路径名是从 B 开始,逐步沿着每一级子目录向下,最后到达指定文件的整个通路上所有子目录
名组成的一个字符串。
A.当前目录 B.根目录
C.多级目录 D.二级目录
7.从用户的角度看,引入文件系统的主要目的是 D 。
A.实现虚拟存储 B.保存用户和系统文档
C.保存系统文档 D.实现对文件的按名存取
8.按文件的逻辑结构划分,文件主要有两类: A 。
A.流式文件和记录式文件 B.索引文件和随机文件
C.永久文件和临时文件 D.只读文件和读写文件
9.位示图用于 B 。
A.文件目录的查找 B.磁盘空间的管理
C.主存空间的共享 D.文件的保护和保密
10.用户可以通过调用 C 文件操作,来归还文件的使用权。
A.建立 B.打开 C.关闭 D.删除三、问答
1.试说出MS-DOS或Windows对文件名的命名规则。举几个例子,说明哪个文件名起得是对的,哪个文件名起得
是不符合命名规则的。
答:例如MS-DOS,它的文件名由两部分组成:文件名和扩展名。文件名由 1~8个字符组成;在文件名的后面,可
以跟随扩展名(可选)。扩展名总是以一个点开始,然后是1~3个字符。组成文件名和扩展名的字符可以如下。
英文字母:A~Z,a~z,共52个(不区分大小写)。
数字符号:0~9。
特殊符号:$、#、&、@等。
不能使用的字符有*、?等。
例如:
test.txt abc.obj
等都是正确的文件名;而:
abcdefhgijk.txty
是不正确的文件名。
对于Windows,文件名最多可以有256个字符,其他与MS-DOS类同。
2.试说出在MS-DOS里打印机的文件名。举一个包含有这个名字的MS-DOS命令,它的含义是什么?
答:在MS-DOS里,可以把打印机视为只写文件来处理,这时打印机的文件名是:PRN。例如命令:
COPY \USER\FILE1 PRN
表明是把文件“\USER\FILE1”拷贝到文件PRN,也就是把文件“\USER\FILE1”在打印机上打印出来。
3.为什么位示图法适用于分页式存储管理和对磁盘存储空间的管理?如果在存储管理中采用可变分区存储管理方
案,也能采用位示图法来管理空闲区吗?为什么?
答:无论是分页式存储管理还是磁盘存储空间的管理,它们面对的管理对象——存储块(内存块或磁盘块)的数量,
在系统的运行过程中是固定不变的。因此,可以很方便地用相同数量的二进制位来对应管理它们。但如果在存储管
理中采用可变分区存储管理方案,那么在系统运行时,分区的数目是变化的。因此,也就无法用位示图法来管理这
些分区的使用情况。
4.有些操作系统提供系统调用命令 RENAME给文件重新命名。同样,也可以通过把一个文件复制到一个新文件、
然后删除旧文件的方法达到给文件重新命名的目的。试问这两种做法有何不同?
答:使用RENAME命令给文件重新命名时,用户要提供两个参数:旧文件名,新文件名。RENAME命令将根据旧
文件名找到文件的目录项,把里面登记的旧文件名改为新文件名。所以,文件重新命名的功能就是修改该文件目录
里的文件名,其他特性不变。
后一种方法是先对文件进行复制,为其起一个新的名字,然后再删除旧的文件。这时,复制过程犹如创建一个文件,
新文件除了名字与以前不同外,文件的某些特性也改变了,例如存放的地址不同了。所以,采用这种方法虽然也能
够达到给文件重新命名的目的,但显得要比前一种方法复杂一些。
5.“文件目录”和“目录文件”有何不同?
答:“文件目录”是指一个文件的目录项,里面存放着文件的有关数据信息。“目录文件”则是指如果文件很多,那
么文件目录项的数量也就很多。为此,操作系统经常把这些目录项汇集在一起,作为一个文件来加以管理,这就是
所谓的“目录文件”。因此,“文件目录”和“目录文件”是两个不同的概念,不能混为一谈。
6.一个文件的绝对路径名和相对路径名有何不同?
答:在树型目录结构中,用户要访问一个文件,必须使用文件的路径名来标识文件。从根目录出发、一直到所要访
问的文件,将所经过的目录名字用分隔符连接起来,所形成的字符串,就是该文件的绝对路径名。如果是从当前目
录出发,一直到所要访问的文件,将所经过的目录名字用分隔符连接起来,所形成的字符串,就是该文件的相对路
径名。可以看出,绝对路径名是文件的全名,必须从根目录开始。所以,一个文件的绝对路径名是惟一的。相对路径名总是从当前目录往下,所以文件的相对路径名与当前位置有关,是不惟一的。
7.试述“创建文件”与“打开文件”两个系统调用在功能上的不同之处。
答:所谓“创建文件”,表示原先该文件并不存在。所以创建文件时,最主要的功能是在磁盘上为其开辟存储空间,
建立起该文件的FCB。文件创建后,有了它的FCB,系统才真正感知到它的存在;“打开文件”是这个文件已经存在,
只是它的有关信息不在内存。因此,打开文件最主要的功能是把该文件FCB中的信息复制到内存中,以便为随后对
文件的操作带来便利。
8.试述“删除文件”与“关闭文件”两个系统调用在功能上的不同之处。
答:“删除文件”最主要的功能是把该文件的FCB收回。文件没有了FCB,系统也就无法感知到它的存在了。所以,
在执行了删除文件的命令后,这个文件就在系统里消失了;而“关闭文件”最主要的功能是把复制到内存活动目录
表里的该文件的FCB 信息取消。这样一来,在内存活动目录表里没有了该文件的信息,就不能够对这个文件进行读、
写了。所以,关闭一个文件后,这个文件还存在,只是不能对它操作了。如果要操作,就必须再次将它打开(即把
FCB里的信息复制到内存的活动目录表),然后再进行操作。
9.为什么在使用文件之前,总是先将其打开后再用?
答:有关文件的信息都存放在该文件的 FCB里,只有找到文件的 FCB,才能获得它的一切信息。但 FCB 是在磁盘
里。因此,只要对文件进行操作,就要到磁盘里去找它的FCB。这种做法,无疑影响了文件操作的执行速度。正因
为如此,操作系统才考虑在对文件进行操作前,先将其打开,把文件的FCB内容复制到内存中来。这样,查找文件
的FCB,就不必每次都要去访问磁盘。
10.如果一个文件系统没有提供显式的打开命令(即没有OPEN命令),但又希望有打开的功能,以便在使用文件时
能减少与磁盘的交往次数。那么应该把这一功能安排在哪个系统调用里合适?如何安排?
答:文件系统中设置打开命令的根本目的,是减少文件操作时与磁盘的交往次数。如果系统没有提供显式的打开命
令,但又要能减少与磁盘的交往次数,那么只需把这一功能安排在读或写系统调用命令里。这时,在读、写命令功
能前面添加这样的处理:总是先到内存的活动目录表里查找该文件的 FCB。如果找到,则表明在此前文件已经被打
开,于是就可以立即进行所需要的读、写操作;如果没有找到,那么表明在此前文件还没有打开。于是应该先按照
文件名,到磁盘上去查找该文件的FCB,把它复制到内存的活动目录表里,然后再进行对它的操作。
四、计算
1.我们知道,可以用位示图法或成组链接法来管理磁盘空间。假定表示一个磁盘地址需要D个二进制位,一个磁盘
共有B块,其中有F块空闲。在什么条件下,成组链接法占用的存储空间少于位示图?
解:依题意,该磁盘共有B块,这意味采用位示图法来管理磁盘空间时,共需要 B个二进制位构成位示图的存储空
间;另一方面,现在共有F个空闲块,而表示一个磁盘地址(即一个空闲块)需要D个二进制位。所以在当前条件
下,用成组链接法来管理磁盘空间中的 F个空闲块时,要用F×D个二进制位的存储空间来管理它们。因此,只要
题中所给的D、B、F三者之间满足关系:
B>F×D
就可以保证使用成组链接法占用的存储空间少于位示图。
2.假定磁带的存储密度为每英寸800个字符,每个逻辑记录长为160个字符,记录间隙为0.6 英寸。现在有1000个
逻辑记录需要存储到磁带上。分别回答:
(1)不采用记录成组技术,这时磁带存储空间的利用率是多少?
(2)采用以5个逻辑记录为一组的成组技术进行存放,这时磁带存储空间的利用率是多少?
(3)若希望磁带存储空间的利用率大于50%,应该多少个逻辑记录为一组?
解:(1)如果不采用记录成组技术,存放一个逻辑记录,就要有一个记录间隙。因为磁带的存储密度为每英寸 800
个字符,每个逻辑记录长为160个字符。所以一个逻辑记录占用的磁带长度是:
160/800=0.2(英寸)一个记录间隙所需要的磁带长度为0.6 英寸。所以,磁带存储空间的利用率是:
0.2/(0.2+0.6)=0.25=25%
(2)采用以5个逻辑记录为一组的成组技术进行存放,表示存放 5个逻辑记录后,有一个记录间隙。5个逻辑记录
占用的磁带长度是:
0.2×5=1(英寸)
这时一个记录间隙所需要的磁带长度仍为0.6英寸。所以,这时磁带存储空间的利用率是:
1/(1+0.6)=0.625=62.5%
(3)若希望磁带存储空间的利用率大于50%,假定应该x个逻辑记录为一组。这就是说,存放x个逻辑记录后,有
一个记录间隙。x个逻辑记录占用的磁带长度是:0.2×x(英寸);这时一个记录间隙所需要的磁带长度仍为0.6 英寸。
所以,磁带存储空间的利用率是:
x/(x+0.6)=0.5
解这个一元一次方程式,x=3。也就是说,当把3个以上的逻辑记录组成一组时,磁带存储空间的利用率将大于50%。
3.假定有一个名为MYFILE的文件,共有10个逻辑记录,每个逻辑记录长为250 个字节。磁盘块尺寸为512 字节,
磁盘地址需要2个字节表示。把MYFILE采用链接结构存储在磁盘上。
(1)画出该文件在磁盘上的链接结构图(磁盘块号自定)。
(2)现在用户要读文件上包含第1425 个字符的逻辑记录。给出完成这一请求的主要工作步骤。
解:(1)由于每个逻辑记录长为250个字节,磁盘块尺寸为512 字节。所以,每个磁盘块里可以存放两个逻辑记录,
余下的字节用于存放指针,文件总共需要5块。假定系统分配给该文件的磁盘块号是:25、33、10、56、4。于是,
该文件在磁盘上的链接结构图如图5-1所示。
X文件的目录
文件名 首块号 尾块号
X 25 4
块号: 25 33 10 56 4
2个
逻辑记录
指针: 33 10 56 4 –1
图5-1 计算题3的图示
(2)首先要知道包含第1425 字节的逻辑记录应该放在链接结构的第几块。因为一个逻辑记录是250个字节,2个逻
辑记录放在一个磁盘块里。所以
1425/(250×2)=2(“/”表示整除运算)
即包含第1425 字节的逻辑记录应该放在链接结构的第3块(注意,由于是用整除,所以第1块应该是0)。
其次,文件系统沿着指针,把第3块(也就是块号为56 的块)读入内存缓冲区中。
最后,由
1425%(250×2)=425(“%”表示求余运算)
且
250×1<425<250×2
所以把缓冲区里的第2个记录读到用户指定的内存区里。
第6章习题解答一、填空
1.信号量的物理意义是当信号量值大于零时表示 可分配资源的个数 ;当信号量值小于零时,其绝对值为 等待使
用该资源的进程的个数 。
2.所谓临界区是指进程程序中 需要互斥执行的程序段 。
3.用P、V操作管理临界区时,一个进程在进入临界区前应对信号量执行 P 操作,退出临界区时应对信号量执行 V
操作。
4.有m个进程共享一个临界资源。若使用信号量机制实现对临界资源的互斥访问,则该信号量取值最大为 1 ,最
小为 −(m−1)。
注意,无论有多少个进程,只要它们需要互斥访问同一个临界资源,那么管理该临界资源的信号量初值就是 1。当有
一个进程进入临界区时,信号量的值就变为0。随后再想进入的进程只能等待。最多的情况是让一个进程进入后,其
余(m−1)个进程都在等待进入。于是这时信号量取到最小值:−(m−1)。
5.对信号量S的P操作原语中,使进程进入相应信号量队列等待的条件是 V<0 。
s
6.死锁是指系统中多个 进程 无休止地等待永远不会发生的事件出现。
7.产生死锁的4个必要条件是互斥、非剥夺、部分分配和 循环等待 。
8.在银行家算法中,如果一个进程对资源提出的请求将会导致系统从 安全 的状态进入到 不安全 的状态时,就暂
时拒绝这一请求。
9.信箱在逻辑上被分为 信箱头 和 信箱体 两部分。
10.在操作系统中进程间的通信可以分为 低级 通信与 高级 通信两种。
二、选择
1.P、V操作是 A 。
A.两条低级进程通信原语 B.两条高级进程通信原语
C.两条系统调用命令 D.两条特权指令
2.进程的并发执行是指若干个进程 B 。
A.共享系统资源 B.在执行的时间上是重叠的
C.顺序执行 D.相互制约
3.若信号量S初值为2,当前值为−1,则表示有 B 个进程在与S相关的队列上等待。
A.0 B.1 C.2 D.3
4.用P、V操作管理相关进程的临界区时,信号量的初值应定义为 C 。
A.−1 B.0 C.1 D.随意
5.用V操作唤醒一个等待进程时,被唤醒进程的状态变为 B 。
A.等待 B.就绪 C.运行 D.完成
6.若两个并发进程相关临界区的互斥信号量MUTEX现在取值为0,则正确的描述应该是 B 。
A.没有进程进入临界区
B.有一个进程进入临界区
C.有一个进程进入临界区,另一个在等待进入临界区
D.不定
7.在系统中采用按序分配资源的策略,将破坏产生死锁的 D 条件。
A.互斥 B.占有并等待 C.不可抢夺 D.循环等待
8.某系统中有3个并发进程,都需要4个同类资源。试问该系统不会产生死锁的最少资源总数应该是 B 。A.9 B.10 C.11 D.12
9.银行家算法是一种 A 算法。
A.死锁避免 B.死锁防止 C.死锁检测 D.死锁解除
10.信箱通信是进程间的一种 B 通信方式。
A.直接 B.间接 C.低级 D.信号量
三、问答
1.试说出图6-1(即教材中第2章的图2-2)所给出的监视程序 A和计数程序B之间体现出一种什么关系,是“互
斥”还是“同步”?为什么?
程序A: 程序B:
while(1) while(1)
{ {
A1: 收到监视器的信号; B1: 延迟半小时;
A2: COUNT=COUNT+1; B2: 打印COUNT的值;
} B3:COUNT=0;
}
图6-1 对两个程序的描述
答:图6-1(即教材中第2章的图2-2)所给出的监视程序A和计数程序B之间体现出的是一种互斥关系,因为在监
视程序A里,要对共享变量COUNT进行操作:
COUNT=COUNT+1;
在计数程序B里要对共享变量COUNT进行操作:
打印COUNT的值;
COUNT=0;
这两段程序是不能交叉进行的,不然就会出现与时间有关的错误。
2.模仿教材中的图6-4,画出COPY和PUT之间的直接依赖关系。然后把两个图汇集在一起,体会它们三者之间正
确的同步关系。再模仿教材中的图6-8,能用信号量及P、V操作来正确处理GET、COPY 和PUT三者之间的协同工
作关系吗?
答:图6-2 给出了GET、COPY和PUT三者间正确的同步关系:GET在向COPY 发“可以拷贝”的消息后,要等待
COPY发来“拷贝结束”的消息。因为这个消息意味着输入缓冲区R已经被COPY腾空,GET可以再次向里面存放
从文件F里取出的记录了;COPY 在等到GET发来的“可以拷贝”的消息后,才能够把输入缓冲区R里的记录拷贝
到输出缓冲区T中。完成这个动作后,表示输入缓冲区 R已经被COPY腾空,因此应该立即向GET发消息,告诉
它输入缓冲区R又可以使用了。随后,向PUT发送“可以打印”的消息,等待PUT发来“打印结束”的消息;PUT
在等到COPY发来“可以打印”的消息后,才能够从输出缓冲区T里取出记录打印。打印完毕后,向COPY发送“打
印完毕”的消息。这个消息意味着输出缓冲区T已经被PUT腾空,COPY又可以再次去等待GET发送的“可以拷贝”
的消息,从输入缓冲区R里取出记录存入输出缓冲区T了。GET COPY
1. 1.
从文件F取出一个记 等待GET发送“可以
录送至输入缓冲区R 拷贝”的消息
2. 2.
PUT
向COPY发送“可以 将缓冲区R里的记录
拷贝”的消息 拷贝到缓冲区T里 1.
等待COPY发送“可
3. 3. 以打印”的消息
等待COPY发来“拷 向GET发送“拷贝结
贝结束”的消息 束”的消息 2.
将缓冲区T里的数据
4. 打印输出
向PUT发送“可以打
印”的消息 3.
向COPY发送“打印
5. 完毕”的消息
等待PUT发送“打印
完毕”的消息
图6-2 GET、COPY和PUT三者间的工作关系
于是,GET、COPY和PUT三者间有 4个同步问题:在GET的标号为3的地方是一个同步点;在COPY的标号为1
和5的地方是两个同步点;在PUT的标号为1的地方是一个同步点。因此,共要设置4个同步信号量:
S1——控制COPY与GET取得同步,初值=0;
S2——控制GET与COPY取得同步,初值=0;
S3——控制PUT与COPY取得同步,初值=0;
S4——控制COPY与PUT取得同步,初值=0。
图6-3 表述了用信号量及P、V操作来正确处理GET、COPY和PUT三者之间的协同工作关系。
GET COPY
1. 1.
从文件F取出一个记 P(S1)
录送至输入缓冲区R
2. PUT
2. 将缓冲区R里的记录
1.
V(S1) 拷贝到缓冲区T里
P(S3)
3. 3.
P(S2) V(S2) 2.
将缓冲区T里的数据
4. 打印输出
V(S3)
3.
5. V(S4)
P(S4)
图6-3 用P、V操作保证GET、COPY和PUT三者的正确协作
3.在图6-4(a)(即教材中图6-8)GET里,是先安放V(S1),再安放P(S2)的。能把它们两个的安放顺序颠倒过来
变成图6-4(b)吗?为什么?GET COPY GET COPY
1. 1. 1. 1.
从文件F取出一个记 P(S1) 从文件F取出一个记 P(S1)
录送至输入缓冲区R 录送至输入缓冲区R
2. 2.
2. 将缓冲区R里的记录 2. 将缓冲区R里的记录
V(S1) 拷贝到缓冲区T里 P(S2) 拷贝到缓冲区T里
3. 3. 3. 3.
P(S2) V(S2) V(S1) V(S2)
(a) (b)
图6-4 安放V(S1)和P(S2)的两种方法
答:图6-4(b)里是先安放P(S2), 再安放V(S1)。这种安放顺序是不行的。因为安放P(S2),表示要在此等待COPY
发来的消息(即希望COPY 执行V(S2)操作),在接到了COPY 的消息后,才执行 V(S1)(即向COPY 发消息)。但
是,根据COPY的安排,不接到GET发来的消息(即执行P(S1)操作),是不会向COPY发消息的(即执行V(S2)操
作)。于是,GET和COPY就陷入了循环等待:GET等待COPY发消息,COPY 等待GET发消息。产生两个死锁了。
4.进程A和B共享一个变量,因此在各自的程序里都有自己的临界区。现在进程 A在临界区里。试问进程A的执
行能够被别的进程打断吗?能够被进程B打断吗(这里,“打断”的含义是调度新进程运行,使进程A暂停执行)?
答:当进程A在自己的临界区里执行时,能够被别的进程打断,没有任何的限制。当进程A在自己的临界区里执行
时,也能够被进程B打断,不过这种打断是有限制的。即当进程B执行到要求进入自己的临界区时,就会被阻塞。
这是因为在它打断进程A时,A正在临界区里还没有出来,既然A在临界区,B当然就无法进入自己的临界区。
5.信号量上的P、V操作只是对信号量的值进行加1或减1操作吗?在信号量上还能够执行除 P、V操作外的其他
操作吗?
答:根据信号量的定义可知,P、V操作并非只是对信号量进行减1或加1操作,更重要的是在减1或加1后,还要
判断运算的结果。对于 P操作,判定后调用进程自己有可能继续运行,也可能阻塞等待。对于 V操作,判定后调用
进程自己最后总是继续运行,但之前可能会唤醒在信号量队列上等待的进程。
在信号量上除了能执行P、V操作外,不能执行其他任何操作。
6.系统有输入机和打印机各一台,均采用P-V操作来实现分配和释放。现在有两个进程都要使用它们。这会发生死
锁吗?试说明理由。
答:采用信号量上的P、V操作,只能正确地完成对设备的申请与释放,但不能控制进程对设备的申请、释放顺序。
因此,当进程申请和释放设备的顺序不当时,仍会发生死锁。例如,进程 A使用输入机和打印机的顺序是:
请求打印机(Ar1)→请求输入机(Ar2)→释放打印机(Ar3)→释放输入机(Ar4)
进程B使用输入机和打印机的顺序是:
请求输入机(Br1)→请求打印机(Br2)→释放输入机(Br3)→释放打印机(Br4)
其中圆括号里标注的字母,表示某进程对设备的某种使用。例如,Ar1表示进程A请求打印机。由于A和B都是进
程,它们的执行可以交叉进行。执行顺序:
Ar1→Ar2→Ar3→Ar4→Br1→Br2→Br3→Br4
或
Ar1→Ar2→Br1→Ar3→Ar4→Br2→Br3→Br4
都是合理的交叉。但是,以Ar1→Br1开始的执行就无法再往下进行了。因为进程A执行了Ar1,表明它占用了打印
机。接着进程B执行了Br1,表明它占用了输入机。这样一来,不管后面是执行 Ar2(进程A申请输入机)还是执
行Br2(进程B申请打印机),都不可能得到满足,两个进程先后被阻塞:进程A占据着打印机而等待输入机,进程
B占据着输入机而等待打印机。这就产生了死锁。
7.现有4个进程A、B、C、D,共享10个单位的某种资源。基本数据如图6-5(即教材中的图6-28)所示。试问如
果进程D再多请求一个资源单位,所导致的是安全状态还是不安全状态?如果是进程C提出同样的请求,情况又会是怎样呢?
答:若进程D多请求一个资源,资源的使用情况如图 6-6(a)所示。这时,系统剩余 1个资源,4个进程各自还需
要的资源数是5、4、2、2,资源剩余数无法保证任何一个进程运行结束。所以D多请求一个资源单位,会导致不安
全状态。若是进程C提出同样的请求,那么系统资源的使用情况如图6-6(b)所示。这时,整个系统虽然也只剩余
1个资源,但却能够保证4个进程都完成。所以,C再多请求一个资源单位,系统将处于安全状态。
进程 最大需求 已有量 进程 最大需求 已有量
A 6 0 A 6 1
B 5 0 B 5 1
C 4 0 C 4 2
D 7 0 D 7 4
系统剩余数:10 系统剩余数:2
(a) (b)
图6-5 第7题的基本数据
进程 最大需求 已有量 还需量 进程 最大需求 已有量 还需量
A 6 1 4 A 6 1 5
B 5 1 5 B 5 1 4
C 4 2 2 C 4 3 1
D 7 5 2 D 7 4 3
系统剩余数:1 系统剩余数:1
(a) (b)
图6-6 不安全与安全状态示意图
8.假定图6-7(即教材中的图6-21)里的进程A申请最后一台磁带机,会引起死锁吗?
进程 磁带机 绘图仪 打印机 CD-ROM 进程 磁带机 绘图仪 打印机 CD-ROM
A 3 0 1 1 A 1 1 0 0
EEEE [ 6 3 4 2 ]
B 0 1 0 0 B 0 1 1 2 (资源总数)
C 1 1 1 0 C 3 1 0 0
PPPP [ 5 3 2 2 ]
(已分配数)
D 1 1 0 1 D 0 0 1 0
AAAA [ 1 0 2 0 ]
E 0 0 0 0 E 2 1 1 0 (剩余数)
(a) (b) (c)
图6-7 多种资源的银行家算法
答:进程A申请了最后一台磁带机后,系统资源的使用情况由图6-7变为图6-8。按照多种资源的银行家算法,这时
系统资源的剩余数可以满足进程D的要求,于是系统资源剩余数矩阵AAAA变为AAAA[1 12 1];这样的剩余数,可以满足
进程A的要求,于是系统资源剩余数矩阵AAAA变为AAAA[5 132];这样的剩余数,可以满足进程B、C、E三个进程中任
何一个的需要,例如给E。在E完成后,系统资源剩余数矩阵AAAA仍为AAAA[5132];再给C,C完成后系统资源剩余数
矩阵AAAA变为AAAA[6 242];再给B,B完成后系统资源剩余数矩阵AAAA变为AAAA[6 342],系统收回了所有资源。由此可知,
进程A申请最后一台磁带机,不会引起死锁。
9.一个计算机有6台磁带机,有n个进程竞争使用,每个进程最多需要两台。那么n为多少时,系统才不存在死锁
的危险?
答:由于每个进程最多需要两台磁带机,考虑极端情况:每个进程已经都申请了一台。那么只要还有一台空闲,就
可以保证所有进程都可以完成。也就是说当有条件:n+1=6(即n=5)时,系统就不存在死锁的危险。进程 磁带机 绘图仪 打印机 CD-ROM 进程 磁带机 绘图仪 打印机 CD-ROM
A 4 0 1 1 A 0 1 0 0
EEEE [ 6 3 4 2 ]
B 0 1 0 0 B 0 1 1 2 (资源总数)
C 1 1 1 0 C 3 1 0 0
PPPP [ 6 3 2 2 ]
(已分配数)
D 1 1 0 1 D 0 0 1 0
AAAA [ 0 0 2 0 ]
E 0 0 0 0 E 2 1 1 0 (剩余数)
(a) (b) (c)
图6-8 进程A申请了最后一台磁带机后
10.考虑教材中的图6-16(d)。如果进程C需要的是资源S,而不是资源R,这会引起死锁吗?如果是既要求资源R
又要求资源S,情况会怎样?
答:这时的资源使用序列为:(1)A申请R,C申请T,A申请S,C申请S,A释放R,A释放S;(2)A申请R,
C申请T,A申请S,C申请S,C申请R,A释放R,A释放S。分别画出它们的资源分配图,可知,它们都不会引
起死锁。
四、计算
1.在公共汽车上,司机和售票员的工作流程如图6-9(即教材上的图6-29)所示。为了确保行车安全,试用信号量
及其P、V操作来协调司机和售票员的工作。
解:从日常生活知识知道,司机和售票员之间的工作有如下的制 约关系存在。
司机: 售票员:
(1)司机必须在得到售票员的“关门完毕”的信号后,才能启 动汽车。这是一个司
机要与售票员取得同步的问题。
启动车辆 关车门
(2)售票员必须在得到司机的“已经停车”的信号后,才能打 开车门。这是一个售
票员要与司机取得同步的问题。 运行 售票
因此,为了确保行车安全,需要设置两个同步信号量:
S1——初值为0,控制司机与售票员取得同步; 到站停车 开车门
S2——初值为0,控制售票员与司机取得同步。
于是,在加入了信号量上的P、V操作后,图6-9应该变为图6-10。 图6-9 司机与售票员
2.有一个阅览室共100 个座位。用一张表来管理它,每个表目记录座号以及读者姓名。读者进入时要先在表上登记,
退出时要注销登记。试用信号量及其P、V操作来描述各个读者“进入”和“注销”工作之间的同步关系。
解:分析题意,知道在管理读者“进入”和“注销” 阅览室的工作中,存在这样一些制约关系:
(1)100个座位是读者共同使用的资源,因此要用一个资源分配信号量来管理它;
(2)读者“进入”阅览室时,要申请座位。只有申请到座位才能进入,否则应该等待到座位的释放;
(3)没有读者时,不能做“注销”工作,必须等到有了读者才能做。
因此,可以设置两个信号量:
S1——初值为100,管理座位的分配;
S2——初值为0,控制“注销”与“进入”间取得同步。司机: 售票员:
P(S1) 关车门
(等待售票员发“关门
完毕”的消息)
V(S1)
(向司机发“关门
启动车辆 完毕”的消息)
运行 售票
到站停车
P(S2)
(等待司机发“已经
V(S2) 停车”的消息)
(向售票员发“已经
停车”的消息)
开车门
图6-10 加入P、V操作后的司机与售票员
“进入”与“注销”两个进程的流程如图6-11所示。
“进入”进程 信号量: “注销”进程
S1的初值=100
S2的初值=0
P(S1) P(S2)
(申请一个座位) (等待“进入”进程消息)
办理阅读手续 办理注销手续
V(S2) V(S1)
(向“注销”进程发消息) (向“进入”进程发消息)
图6-11 “进入”与“注销”两个进程
在读者进入时,调用“进入”进程,通过P(S1)来申请座位。如果申请到,就可以办理阅览手续。如果100个座位都
申请完毕,那么第101 个读者就只有在关于S1的队列上等待,等到有人调用“注销”进程执行V(S1)。在有读者离
去时,就调用“注销”进程。
3.今有3个并发进程R、S、T,它们共享一个缓冲区B。进程R负责从输入设备读入信息,每读出一个记录后就把
它存入缓冲区B中;进程S利用缓冲区B加工进程R存入的记录;进程T把加工完毕的记录打印输出。缓冲区B一
次只能存放一个记录。只有在进程 T把缓冲区里的记录输出后,才能再往里存放新的记录。试用信号量及其 P、V
操作控制这3个进程间的的正确工作关系。
解:3个并发进程R、S、T之间有如下的制约关系:
(1)R必须先做,在往缓冲区B里面存入数据后,应该向 S发消息,然后等待T打印输出后释放缓冲区B;
(2)S应该与R取得同步,在等到R发来的消息(表明B里面有数据)后,取出加工、回存,然后向T发消息;
(3)T应该与S取得同步,在等到S发来的消息(表明B里的数据已经加工完毕)后,才取出打印,然后向R发消
息,表示缓冲区B又可以使用了。
从这些关系可以看出,这里是3个同步问题:R要与T取得同步;S要与R取得同步;T要与S取得同步。所以,
设置3个同步信号量:
S1——控制S要与R取得同步;
S2——控制T要与S取得同步;
S3——控制R要与T取得同步。图6-12 给出了它们的工作流程示意。
进程R 信号量: 进程S 进程T
S1=0
S2=0
从设备读入数据 S3=0 P(S1) P(S2)
(等待R的消息) (等待S的消息)
将数据存入B
对B中数据
数据打印
V(S1) 加工、回存
(向S发消息)
P(S3) V(S2) V(S3)
(等待P的消息) (向T发消息) (向R发消息)
图6-12 R、S、T之间的相互制约关系
4.假定有3个进程R、W1、W2 共享一个缓冲区B,B中每次只能存放一个数。进程R从输入设备读入一个数,把
它存放到缓冲区B里。如果存入的是奇数,则由进程 W1 取出打印;如果存入的是偶数,则由进程 W2取出打印。
规定进程R只有在缓冲区B为空或内容已经被打印后才能进行存放;进程 W1 和W2 不能从空缓冲区里取数,也不
能重复打印。试用信号量及其P、V操作管理这3个进程,让它们能够协调地正确工作。
解:这实际上也是最简单“生产者—消费者”问题的 变种:进程R是产生
奇数 进程W1
者,进程W1、W2 是两个消费者。只是 W1只消费 奇数,W2 只消费偶
进程R 缓冲区B
数。图6-13 所示的是3个进程的工作示意。
偶数 进程W2
分析一下题目,知道3个进程间有如下的制约关系存 在:
图6-13 奇数、偶数问题
(1)进程R申请使用缓冲区B,释放缓冲区B的权 利是由进程 W1 或
W2掌握的;
(2)进程W1要等待R往缓冲区B里放入奇数后,才能工作(要与R取得同步),然后释放缓冲区;
(3)进程W2要等待R往缓冲区B里放入偶数后,才能工作(要与R取得同步),然后释放缓冲区。
因此,应该设置3个信号量:
S——初值为1,控制缓冲区B的分配;
SO——初值为0,控制W1与R取得同步;
SE——初值为0,控制W2与R取得同步。
3个进程的工作流程如图6-14 所示。
进程R
进程W1 进程W2
得到一个数
P(SO) P(SE)
P(S) (等待R发消息) (等待R发消息)
(申请缓冲区B)
将数存入缓冲区B 从B中取出奇数 从B中取出偶数
Y N V(S) V(S)
B里是奇数?
(释放缓冲区B) (释放缓冲区B)
V(SO) V(SE)
(向W1发消息) (向W2发消息)图6-14 W、R1、R2的相互制约关系
这里有3个问题需要解释。
(1)在进程R中,把数存入B之后,应该根据数的奇、偶性,来决定是向进程W1发消息,还是向进程W2发消息。
这样,才能给予W1 或W2 从B里取数的机会。
(2)由于在进程R里已经对数的奇、偶性做了判断,所以进程W1 或W2 到缓冲区B里取数时,不必对它再行判断,
取出的内容肯定是所需要的,不会弄错。
(3)假定在进程R没有执行之前,进程W1和W2都先于它执行了。那么这时由于信号量 SO和SE的值都是0,所
以它们都无法执行下去,分别在SO和SE的有关队列上等待。当进程R被调度到、判定放入B的数是奇数还是偶数,
并向W1或W2 发消息后,它们两个中的一个才会被唤醒,才会到B里去取数。
还可以从别的角度出发,去理解本题目中R、W1、W2之间的制约关系,从而得到它的另一种解决办法。图6-15给
出了流程图,只需设置两个信号量:
S——初值为1;
G——初值为0。
这里有3个问题需要解释。
(1)信号量S用于资源分配。进程R通过P(S)申请使用缓冲区B。申请到后,才向里面存放数,然后就在信号量G
上执行一个V操作,笼统地告诉进程W1或W2:缓冲区B里有数可取了。由于并不知道这个数的奇、偶性,所以,
它们两个谁去取都是可以的。
(2)这时判断缓冲区B里数的奇、偶性,是在进程W1或W2里进行的。运行W1时,如果判定B里的是奇数,那
么进程W1就可以将其取出,然后释放缓冲区B(通过V(S)实现)。如果判定 B里的是偶数,那么进程W2 就可以将
其取出,然后释放缓冲区B(通过V(S)实现)。
进程R 进程W1 进程W2
得到一个数 P(G) P(G)
(等待R发消息) (等待R发消息)
P(S)
(申请缓冲区B) N B里是 Y N B里是 Y
奇数? 奇数?
将数存入缓冲区B V(G) 从B中取出奇数 从B中取出偶数 V(G)
(恢复原样) (恢复原样)
V(G) V(G) V(S)
(向W1或W2发消息) (释放缓冲区B) (释放缓冲区B)
图6-15 W、R1、R2的另一种相互制约关系(3)要注意的是,如果在进程W1 里判定B中的数不是奇数,那么它就不应该取出此数。同样地,如果在进程 W2
里判定B中的数不是偶数,那么它就不应该取出此数。既然它没有取,表明数还在缓冲区B里。所以要通过V(G),
使信号量G恢复原来的取值(含义是告诉要去取数的进程:B里有数要取),以便给另一个进程去取的机会。如果不
做这一步,那么信号量G的当前值是0,无论进程W1 还是W2 在它的上面再执行P(G)时,就都无法通过,两个进
程就会全被阻塞,进入死锁。所以,进程W1 和W2 里的V(G)是非常重要的。
5.在飞机订票系统中,假定公共数据区的单元 Ai(i=1,2,3…)里存
第j售票处要订
放着某月某日第i次航班现有票数。在第j个售票 第i航班的飞机票 处,利用变量 Rj暂存
Ai里的内容。现在为第j个售票处编写代码如图 6-16(即教材中的图
6-30)所示。试问它的安排对吗?如果正确,试 按旅客要求找到Ai 说明理由;如果不对,
指出错误,并做出修改。
P(S)
解:从图 6-16 可以知道,公共数据区的单元Ai (i=1,2,3…)里存放
(进入公共数据监界区)
的某月某日第i次航班的现有票数,是j(j=1,2, 3…)个售票处共享的
数据。因此,这些售票处对公共数据区的单元Ai Rj=Ai; (i=1,2,3…)的操作
(取出该航班现有票数)
不能同时进行。正因为如此,图中把对Ai的这些 操作,用名为S的信号
量上的P、V操作,保证它们互斥进行。这样处 N 理都是正确的。
Rj≥1?
关键是当判定没有第i次航班的机票时,图6-28 (还有这个班次的飞机票?) 里仅安排了打印“票已
售完!”的动作。这样,第j售票处只有进入临界 Y 打印“票已售完!” 区的P(S),而没有执行
Rj=Rj–1; Ai=Rj;
退出临界区的V(S)。它没有退出临界区,别的售 票窗口也就无法再进
(进行数据修改)
入这个临界区。所以,这种安排是不对的。应该 把图 6-16 改成为图
6-17,这样就完全正确了。 V(S)
(退出公共数据监界区)
第j售票处要订
第i航班的飞机票 售出一张飞机票
按旅客要求找到Ai
图6-16 第j售票处的售票程序
P(S)
(进入公共数据监界区)
Rj=Ai;
(取出该航班现有票数)
N
Rj≥1?
(还有这个班次的飞机票?)
Y 打印“票已售完!”
Rj=Rj–1; Ai=Rj;
(进行数据修改)
V(S)
(退出公共数据监界区)
V(S)
(退出公共数据监界区)
售出一张飞机票
图6-17 正确的第j售票处的售票程序
第七章习题解答
一、填空1.一个操作系统的可扩展性,是指该系统 能够跟上先进计算技术发展 的能力。
2.在引入线程的操作系统中,线程是进程的一个实体,是 进程 中实施调度和处理机分派的基本单位。
3.一个线程除了有所属进程的基本优先级外,还有运行时的 当前 优先级。
4.在Windows2000 中,具有1~15 优先级的线程称为 可变型 线程。它的优先级随着时间配额的用完,会被强
制降低。
5.Windows2000 在创建一个进程时,在内存里分配给它一定数量的页帧,用于存放运行时所需要的页面。这些
页面被称为是该进程的“ 工作集 ”。
6.Windows2000 采用的是请求调页法和 集群 法相结合的取页策略,把页面装入到内存的页帧里的。
7.分区是磁盘的基本组成部分,是一个能够 被格式化和单独使用 的逻辑单元。
8. MFT是一个数组,是一个以数组元素为 记录 构成的文件。
9.只要是存于NTFS卷上的文件,在MFT里都会有一个 元素 与之对应。
10.在Windows2000 的设备管理中,整个I/O处理过程都是通过 I/O请求包(IRP)来驱动的。
二、选择
1.在引入线程概念之后,一个进程至少要拥有 D 个线程。
A.4 B.3 C.2 D.1
2.在Windows2000 中,只有 A 状态的线程才能成为被切换成运行状态,占用处理器执行。
A.备用 B.就绪 C.等待 D.转换
3.Windows2000 是采用 C 来实现对线程的调度管理的。
A.线程调度器就绪队列表
B. 线程调度器就绪队列表、就绪位图
C. 线程调度器就绪队列表、就绪位图、空闲位图
D.线程调度器就绪队列表、空闲位图
4.在Windows2000 里,一个线程的优先级,会在 A 时被系统降低。
A.时间配额用完 B.请求I/O C.等待消息 D.线程切换
5.在单处理机系统,当要在进程工作集里替换一页时,Windows2000实施的是 B 页面淘汰策略。
A.FIFO(先进先出) B.LRU(最近最久未用)
C.LFU(最近最少用) D.OPT(最优)
6.在页帧数据库里,处于下面所列 A 状态下的页帧才可以变为有效状态。
A.初始化 B.备用 C.空闲 D.修改
7.当属性值能够直接存放在MFT的元素里时,称其为 B 。
A.非常驻属性 B.常驻属性 C.控制属性 D.扩展属性
8.在NTFS文件系统中,文件在磁盘上存储时的物理结构是采用 C 的。
A.连续式 B.链接式 C.索引式 D.组合式
9.在Windows2000 的设备管理中,I/O请求包(IRP)是由 D 建立的。
A.用户应用程序 B.文件系统驱动程序
C.设备驱动程序 D.I/O管理器
10.Windows2000处理机调度的对象是 B 。
A.进程 B.线程 C.程序 D.进程和线程
三、问答
1.何谓操作系统的‘微内核’设计模式?
答:所谓操作系统的‘微内核’设计模式,其中心思想是将操作系统划分成两个部分:系统的非基本部分和系
统的核心部分。系统的非基本部分以单一功能的进程形式,在用户态下运行;把最为关键的进程管理、内存管理、以及进程通信等功能,留存下来组成系统的内核,在核心态下运行。
2.用微内核模式构造的操作系统,为什么具有可扩展性、可移植性、以及更好的安全性和可靠性?
答:用微内核模式构造操作系统,要增加新的服务时,是增加到用户空间中,而不是修改内核。当内核确实需
要变动时,因为内核本身很小,因此所要做的修改也会很小。所以说,这样的操作系统能够跟上先进计算技术的发
展,具有可扩展性;由于很小,因此稍加改动,就能够从一种硬件平台移到另一种硬件平台,从而具有可移植性;
再有,绝大多数服务都运行在用户态,不以内核进程的面目出现,即使一种服务失败,也不会导致整个系统的崩溃
或瘫痪,因此使内核具有更好的安全性和可靠性。
3.什么是对称多处理器系统(SMP)?
答:一个计算机系统是所谓的“对称多处理器系统(SMP)”,即该系统具有多个处理器,每个处理器都运行同
一个操作系统的拷贝,这些拷贝根据需要可以互相通信。
4.何谓“处理机饥饿”线程?为何要极大地提升它的优先级?
答:所谓“处理机饥饿”,是指在就绪队列里长期等待而一直没有得到运行机会的那种线程。由于它长时间的等
待,得不到CPU,这显然是不公平的。为了平衡线程间的这种关系,Windows2000 就专门有一个系统线程,定时检
查是否存在这样的线程(比如,它们在就绪队列里已经超过了300个时钟中断间隔,相当3~4 秒钟)。如果有,就把
该线程的优先级一下提升到15,分配给它长度为正常值两倍的时间配额。在它用完这个时间配额后,其优先级立即
衰减到它原来的基本优先级。
5.何为“置页策略”?Windows2000 具体是怎么做的?
答:当缺页中断时,系统必须确定把虚拟页面放入到物理内存的什么地方。这就是所谓的“置页策略”。
在Windows2000,内存中可分配的页帧对象,只能从页帧号数据库的初始化帧链表、空闲帧链表、后备帧链表
和修改帧链表里得到。具体的做法是:
(1)在要求存储分配时,如果需要的是一个零初始化的页帧,那么系统首先试图从初始化帧链表中得到一个可
分配的页帧;如果这个链表为空,则从空闲帧链表中选取一帧并将其初始化;如果空闲帧链表也为空,那么就改为
从后备帧链表中选取一帧并将其初始化;如此等等。
(2)如果所需要的并不是一个零初始化页帧,那么首先去查看空闲帧链表;如果空,则去查看后备帧链表。在
决定要把后备帧链表里记录的一帧分配出去之前,必须从该元素回溯,找到进程页表里相关的表项,清除其里面的
“页帧号”,断绝这个页表项与该页帧的联系。这样,才能保证分配的安全。
(3)如果必须要把一个处于修改状态的页帧分配出去,那么首先要将该页帧的内容写入磁盘,然后将它链到后
备帧链表里去,以便使用。
6.为什么要把一个磁盘划分为若干个分区:
答:把磁盘格式化为若干个分区,主要的目的有三个:第一,使磁盘初始化,以便将其格式化后用于存储数据;
第二,通过一个个分区,可以将不同的操作系统分开,以保证多个操作系统可以在同一个磁盘上得到正常的运行;
第三,便于更好地对磁盘进行管理,达到充分利用磁盘空间的目的。
7.什么是NTFS文件系统中的VCN和LCN?
答:在NTFS文件系统中,簇是文件存储的分配单位。系统按照簇的尺寸来划分文件的虚拟空间,这样形成的
顺序号,称为虚拟簇号,即VCN;把整个卷中所有的簇从头到尾进行顺序编号,称为逻辑簇号,即LCN。
8.在NTFS中是如何实现其可恢复性的?
答:为了实现可恢复性,NTFS在主控文件表(MFT)里设置了一个日志文件。在系统运行过程中,随时向日志
文件里存储更新记录,定时地向日志文件里存储检查点记录、事务表记录以及脏页表记录。为系统的恢复积累所需
要的信息。
在系统崩溃而重新启动时,NTFS将对日志文件进行分析扫描、重做扫描和撤消扫描,完成重做和撤消,使系统
恢复到发生崩溃之前。
9.Windows2000 为什么采用两级中断处理方式?
答:Windows 2000采用的是中断服务程序(ISR)和延迟过程调用程序(DPC)两级处理中断。之所以这样,是
为了提高系统的并行工作能力,防止因中断服务程序占用较长的处理机时间,引起不必要的阻塞。因此,中断服务程序(ISR)部分执行尽可能少的关键性操作,并运行在高中断请求级上;余下的中断处理部分称为延迟过程调用程
序(DPC),运行在低中断请求级上。
四、计算
1.FAT16 文件系统的簇号应该用多少个二进制位标识?如果一簇的尺寸最大为 16KB,那么这种卷的尺寸最多
为多少?
答:由FAT16表明,这种文件系统的簇号应该用16个二进制位来标识。也就是说,这种卷最多可以含21(6 =65536)
个簇。题目中给出一个簇的最大尺寸为16KB,因此这种卷的最大尺寸为216*16KB=1GB。
第8章习题解答
一、填空
1.Linux中,可以同时并行工作的进程个数,由符号常量 NR_TASKS 所限定。通常,它被定义为512。
2.在Linux 中,进程调度被分为 实时进程调度 和非实时进程调度两种。
3.当进程运行时出现了系统调用或中断事件,而要去执行操作系统内核的程序时,进程的运行模式就从用户模
式转为 核心 模式。
4.Linux存储管理的特点是采用在 各个分区 里进行分页的存储管理技术。
5.采用在分区里分页的虚拟存储管理技术,有利与实行存储 保护 和共享。
6.Ext2 中块组里的索引节点位图,是用来管理块组中的 索引节点 的,它占用一个盘块。
7.Ext2 中块组里的盘块位图,是用来管理块组中的 盘块 的,它占用一个盘块。
8.Linux中的进程描述符,就是通常所说的 进程控制块 。
9.Linux内核中,利用控制寄存器来控制硬设备完成输入/输出任务的软件,叫做设备驱动程序,有时也称为 设
备驱动器 。
10.网络是一种经过 网络接口 与主机交换数据的设备。
二、选择
1.下面所列的名称中, B 不是Linux 进程的状态。
A.僵死状态 B.休眠状态 C.可中断状态 D.可运行状态
2.Linux的SCHED_RR调度策略,适合于 C 。
A.运行时间短的实时进程 B.交互式分时进程
C.运行时间长的实时进程 D.批处理进程
3.下面列出的进程间通信方法中, A 不被用来在进程之间传递具体数据。
A.信号 B.消息队列 C.共享存储区 D.管道
4.Linux在实行虚拟地址转换时,采用的是 B 级页表结构。
A.一 B.二 C.三 D.四
5.在Ext2中,下面的说法, D 是错误的。
A.每个文件都有一个inode节点 B.目录文件有inode 节点
C.特别文件有inode 节点 D.打印机没有inode节点
6.在Linux 中, A 在文件系统中没有相应的inode节点。
A.网络设备 B.打印机 C.终端 D.磁盘
7.按照文件的内容,Linux把文件分成 D 三类。
A.系统文件、用户文件、设备文件 B.一般文件、流式文件、记录文件 C.目录文件、流式
文件、设备文件 D.普通文件、目录文件、特别文件
8.在Linux 中,对于页表,下面的说法里 C 是正确的。
A.页表必须占用连续的内存空间B.页表必须全部在内存
C.页表不必全部在内存,可以不占用连续的内存空间
D.页表必须全部在内存,但可以不占用连续的内存空间
三、问答
1.何谓在分区里进行分页的虚拟存储管理技术?
答:所谓在分区里进行分页的虚拟存储管理技术,即是把用户程序按照其逻辑结构,把虚拟存储空间划分成若
干个分区,然后在分区里面分页。由于通常都是按照程序的逻辑结构来划分分区,因此这种存储管理技术,不仅具
有页式存储管理的特点(各页可以存放在内存中不连续的页里),而且有利于进行存储保护和共享。
2.Linux采用的多级页表技术,有什么优点?
答:按照分页式存储管理,页表必须占据内存的连续存储区。由于Linux 提供的虚拟地址空间,最大可以有1M
个页面。因此,一个页表最大就可以有一百万个表项。把它存放在一个连续的内存区里,不利于存储空间的充分利
用。于是,Linux就将页表也按页来划分,并形成页表的索引。这样,大的页表就不必占用连续的内存空间了,从而
提高了内存空间的利用率。
3.如书上的图8-12(a)的位示图里,如果现在第36 内存块被释放,那么它是否应该和它前面的第34、35 块以及
它后面的第37、38、39、40 块,合并成为一个大的空闲区?为什么?
答:不应该与它们合并。在伙伴系统里,只有尺寸相同、又相邻接的空闲区才能进行合并。第36 内存块是由独
个内存块构成的空闲区,第 34、35 块是由两个块构成的空闲区,第 37、38、39、40 块是由四个块构成的空闲区。
既然它们的尺寸不同,因此不能合并。
4.在Ext2 中,若有一个分区大小为8GB,盘块的尺寸是4KB。试问,该文件卷最多有多少磁盘块?最多有多
少个块组?
答:由于盘块的尺寸是4KB,共有8*4K=32K个二进制位。这表明,在一个块组里,用一个盘块构成盘块位图
时,最多可以管理32K个磁盘块,也就是一个块组里最多可以有32K个磁盘块。现在分区尺寸为8GB,盘块尺寸为
4KB,所以整个文件卷有8GB/4KB=2M个盘块;有2M/32K=64个块组。
5.试画出Linux 巨型文件的索引结构图。
答:Linux 巨型文件的索引结构图如下:
6.模仿书上图8-9,画出Linux 的三级页表式地址转换过程图。
答:Linux 的三级页表式地址转换过程图如下:7.Linux的每个进程都有若干个VMA,且两个VMA可以不连续。即使两个VMA连续,它们也必须分开管理
吗?为什么?
答:即使两个VMA连续,它们也必须分开管理。这是因为两个VMA实施的存储保护可以不同,不可能进行统
一的管理。
8.试描述在Linux中,你如何能够根据给出的文件名称,找到该文件具体存放在磁盘的哪些磁盘块上的?
答:首先根据文件名称查文件目录,得到该文件的inode节点编号。再由inode节点编号,在索引节点表里找到
该文件的索引节点。最后从索引节点里的i_block[ ]数组,就可以得到该文件具体存放在哪些磁盘块里。
9.模仿书上图 8-23 所示的字符设备数据结构间的关系,画出块设备管理中 blkdevs 数组、device_struct结构、
block_device_operations结构间的关系示意图。
答:块设备数据结构间的关系示意图如下:
四、计算
1.如果在Linux 里,某段小于4MB。那么它虚拟空间的页表索引有多少表项?它有多少个页表?构成页表索引
和页表,总共需要开销多少内存空间?
答:对于 Linux 来说,它的页表索引最大有 1024 个表项,每个表项对应一个页表。每个页表有 1024 个表项,
一个表项描述了虚拟空间中的一页与内存块(4KB)的对应情况。因此,一个页表可以用来描述4MB 大小的空间。
由于现在已知段的长度小于4MB,即是虚拟地址空间小于4MB。所以,它的页表索引需要有1个表项,这个表项指向唯一的一个页表。
虽然页表索引只有1个表项,但必须占用一页的存储量。另外,一个页表要占用一页的存储量。所以,小于4MB
的段,要开销两个块的存储空间。
2.假设页面的尺寸为4KB,一个页表项用4B。若要求用页表来管理地址结构为36位的虚拟地址空间,并且每
个页表只占用一页。那么,采用多级页表结构时,需要几级才能达到管理的要求?
答:36位的虚拟地址空间尺寸为 236=16GB。已知页面的尺寸为4KB,一个页表项用4B,每个页表只占用一页。
这表示一个页表有1024个表项,可以管理1024(=210)个页面,即管理4M(=222)大小的虚存空间。根据题意,第
1级只能是一个页表,它可以管理 K个页面(因为一个页表里有 1024个表项)。K个页面的存储量是4MB。因此,
用一级页表不能管理16GB的虚拟空间。于是进入第2级;第2级有K个页表,可以管理K*K个页面。K*K个页面
的存储量是4GB。显然用二级页表不能管理16GB的虚拟空间。于是进入第3级;第3级有K*K个页表,可以管理
K*K*K个页面。K*K*K个页面的存储量是超过了16GB,达到了242。因此,本题需要使用三级页表才能够管理236
的虚拟空间。
3.Linux的空闲区队列表free_area总共可以有11个队列。试问,在第 11个队列里排队的每一个空闲区里,包
含有多少个连续的内存块?
答:Linux 的空闲区队列表free_area里,排在每个队列里的空闲区中所含连续块的数目,是按 2的次幂递增的。
在第1个队列里,空闲区中所含连续块的数目为20;在第2个队列里,空闲区中所含连续块的数目为21;在第3个
队列里,空闲区中所含连续块的数目为22;……。因此,在第11个队列里,空闲区中所含连续块的数目为210。即在
这个队列里,每个空闲区中所含连续块的数目为1024 块!
4.Linux的Ext2文件系统,其巨型文件最多可以有多少个磁盘块?
答:Ext2文件系统的巨型文件,最多可以有(b/4)*(b/4)*(b/4)+(b/4)*(b/4)+(b/4)+12个磁盘块。
第9章习题解答
一、填空
1.MS-DOS 操作系统由BOOT、IO.SYS、MSDOS.SYS以及 COMMAND.COM 所组成。
2.MS-DOS 的一个进程,由程序(包括代码、数据和堆栈)、 程序段前缀 以及环境块三部分组成。
3.MS-DOS 向用户提供了两种控制作业运行的方式,一种是 批处理方式 ,一种是命令处理方式。
4.MS-DOS 存储管理规定,从地址0开始每16 个字节为一个“ 节 ”,它是进行存储分配的单位。
5.MS-DOS在每个内存分区的前面都开辟一个 16 个字节的区域,在它里面存放该分区的尺寸和使用信息。这
个区域被称为是一个内存分区所对应的 内存控制块 。
6.MS-DOS 有4个存储区域,它们是: 常规内存区 、上位内存区、高端内存区和扩充内存区。
7.“ 簇 ”是MS-DOS进行磁盘存储空间分配的单位,它所含扇区数必须是2的整数次方。
8.当一个目录表里仅包含“.”和“..”时,意味该目录表为 空 。
9.在MS-DOS里,用文件名打开文件,随后就通过 句柄 来访问该文件了。
10.在MS-DOS 里,把 字符设备 视为设备文件。
二、选择
1.下面对DOS的说法中, B 是正确的。
A.内、外部命令都常驻内存 B.内部命令常驻内存,外部命令非常驻内存C.内、外部命令都非常驻内存 D.内部命令非常驻内存,外部命令常驻内存
2.DOS进程的程序,在内存里 D 存放在一起。
A.总是和程序段前缀以及环境块 B.和谁都不
C.总是和进程的环境块 D.总是和程序段前缀
3.MS-DOS 启动时能够自动执行的批处理文件名是: C 。
A.CONFIG.SYS B.MSDOS.SYS
C.AUTOEXEC.BAT D.COMMAND.COM
4.下面所列的内存分配算法, D 不是MS-DOS 采用的。
A.最佳适应法 B.最先适应法 C.最后适应法 D.最坏适应法
5.在MS-DOS里,从1024K到1088K的存储区域被称为 D 区。
A.上位内存 B.扩展内存 C.扩充内存 D.高端内存
6.MS-DOS 的存储管理是对 A 的管理。
A.常规内存 B.常规内存和上位内存
C.常规内存和扩展内存 D.常规内存和扩充内存
7.在下面给出的MS-DOS 常用扩展名中, B 不表示一个可执行文件。
A..exe B..obj C..com D..bat
8.下列四项中, D 不是MS-DOS 文件分配表的功能。
A.记录文件的链接结构 B.进行磁盘存储空间的管理
C.存放簇之间的链接指针 D.反映文件间的共享情况
9.下面不能作为MS-DOS 设备文件的设备是: B 。
A.显示器 B.磁盘 C.打印机 D.键盘
10.MS-DOS的设备文件是指 C 。
A.字符设备和块设备 B.块设备 C.字符设备 D.NUL设备
三、问答
1.什么是DOS的内部命令,什么是DOS的外部命令?
答:MS-DOS 把命令处理模块(COMMAND.COM)中那些功能简单、使用频率较高的操作命令称为“内部命
令”。内部命令程序都在COMMAND.COM暂驻内存模块里。只要暂驻内存模块在内存中,系统接收到一条内部命令
时,就能够直接调用它并执行。
MS-DOS 把命令处理模块(COMMAND.COM)中那些使用频度较小的操作命令称为“外部命令”。它们都是以
文件的形式存放在磁盘上。当在内存的暂驻内存模块接收到一个外部命令时,必须先将它从磁盘读入内存,然后才
能被执行。
2.试勾画出 DOS 启动过程中四大部分的相互关系。谁最先运行?谁又把谁装入到内存?最后 CPU的控制权
落在了谁的手里?
答:MS-DOS 由一个引导程序(BOOT)和3个程序模块(IO.SYS和ROM-BIOS、MSDOS.SYS、COMMAND.COM)
组成,其间的层次关系,如教材中的图8-1所示。
BOOT是一个极短的程序。系统初启时,它最先投入运行。随后检查系统盘根目录下的头两个文件是否是IO.SYS
和MSDOS.SYS。如果为真,则把IO.SYS装入到内存,结束引导任务,转而执行IO.SYS里的系统初始化程序。
IO.SYS 及ROM-BIOS 是MS-DOS的输入/输出管理模块。其中在系统盘上的 IO.SYS,是进行输入/输出的接口
模块;固化在ROM里的ROM-BIOS,是一个个具体的设备驱动程序。在引导程序将IO.SYS装入内存、转而执行IO.SYS
里的系统初始化程序后,就由它负责调入 MSDOS.SYS;负责装入 COMMAND.COM模块。所以,MSDOS.SYS 以及COMMAND.COM都是由IO.SYS装入到内存的。
COMMAND.COM是MS-DOS 操作系统与用户之间的接口。在系统启动后,CPU的控制权最后落在了它的手里,
由它接收用户输入的各种DOS命令,解释后加以执行。
3.MS-DOS不支持进程间的并发执行,进程之间只能够串行执行。那么它是怎样保证进程之间顺利切换的呢?
答:在进程的程序段前缀里,有返回时的地址,有调用者的PSP地址(即指向调用进程的进程控制块指针),这
是保证进程之间顺利切换的两个重要的信息。对于DOS来说,创建一个新进程后,子进程执行,父进程就暂停执行,
直到子进程执行完毕,根据返回地址,把控制返还给父进程。这是一个方面。另一个方面是,DOS系统总是把当前
运行进程的PSP地址保存在一个叫做“当前PSP”的单元里。谁的PSP地址在这个单元,DOS就把系统里的所有资
源都交由它去使用,一切有关资源的操作都是针对这个PSP进行的。于是,当子进程执行完毕返回时,DOS除了按
照子进程里记录的返回地址进行返回外,还将按照子进程里记录的PSP地址,把调用者的PSP地址送入“当前PSP”
单元。根据进程程序段前缀里的这两个信息,就使得DOS能够顺利地从这个进程切换到那个进程。
4.根据MS-DOS对常规内存的管理方法,试设想MS-DOS是如何进行空闲分区合并的工作的?
答:当一个分区被释放时,由它的内存控制块(MCB)可以得到与其相邻接的下一个分区的内存控制块(MCB)。
于是,从这个分区的使用标志是否为“0000H”,知道它是否空闲。只要是处于“0000H”,那么就应该将它们合并成
一个大的空闲区。合并后的这个分区的“分区性质标志”应该是合并前的后一个空闲分区的原标志,分区的使用标
志是 “0000H”,分区尺寸是两个分区原尺寸之和,再加16个字节(去掉一个内存控制块)。合并完毕后,再重复进
行,直到遇见一个分区的使用标志不是“0000H”,或分区性质标志已是“Z”时停止。
5.MS-DOS 为什么是在“申请内存分区”系统调用中进行空闲分区的合并工作,而不是在“释放内存分区”系
统调用中进行这项工作?
答:MS-DOS是通过“申请内存分区”系统调用来进行空闲分区合并的。之所以这样做,有如下几点理由。
第一,在进行存储分配时,MS-DOS 总是沿着分区的MCB链去寻找一个满足条件的空闲分区加以分配。如果当
前找到满足条件的分区,那么就可以立即将其分配出去,免去分区合并所需要的系统开销。
第二,如果当前空闲分区的尺寸不能满足要求,而后面是一个空闲分区,那么顺手将它们合并,既合乎情理,
又节省时间。
第三,如果在“释放内存分区”系统调用中进行这项工作,无法解决与释放区前面的空闲分区进行合并的工作。
所以,MS-DOS在“申请内存分区”系统调用中进行空闲分区的合并工作,这样的安排是非常正确的。
6.为什么8086/8088CPU可以直接寻址到1024KB,而80286以上机器的CPU则可以直接寻址到1088KB?
答:表9-1给出了86 系列各类处理器内存地址引线的数目。由于 8086/8088有20 根地址引线(A0~A19),因
此能够直接访问的地址范围是0~FFFFFH(十六进制表示),按十进制表示即是1024K=1M。
表9-1 86系列地址引线数目一览
处 理 器 地址引线数目 最大物理空间
8086/8088 20(A0~A19) 1MB
80286 24(A0~A23) 16MB
80386/80486 32(A0~A31) 4096MB=4GB
对于80286以及往上的处理器,其内存地址引线数目都大于20 条,所以它们的直接寻址范围都应该大于1MB。
具体地,根据PC字长为16位(两个字节),以及采用的“段址:段内位移”的地址构成方法,最大寻址范围应该表
示成:“FFFFH:FFFFH”。这样,表示段址的16 个二进制位全占用满了,表示段内位移的 16 个二进制位也全占用
满了。把段址左移4位,成为FFFF0H,加上FFFFH,得到这时的最大物理地址为10FFEFH。这表示实际直接可寻
址的范围是 0~10FFEFH,共 10FFEF+1=10FFF0H 个字节。这个数字比 1088KB 少 16 个字节(1088KB=1088×
1024=1114112字节),一般就把它当做1088KB。所以,对于 8086/8088,它们的直接寻址范围是0~1024KB;对于
80286以上的直接寻址范围是0~1088KB。
7.在MS-DOS,根目录里的目录项数是一定的。那么子目录里的目录项数有限制吗?为什么?答:图9-1(a)和图9-1(b)给出了MS-DOS 对软盘和硬盘的格式化划分。从中可以看出,无论是在软盘还是
硬盘里,为存放根目录所开辟的磁盘空间是一定的。另一方面,在MS-DOS 中,每一个文件目录项要占用32 个字节。
所以,在软盘或硬盘根目录下的目录项数目是一定的。
一个 文件分配表 文件分配表
引导扇 根目录区 文件存放区
盘卷: (FAT1) (FAT2)
(a) MS-DOS对软盘的划分
主引导扇
整个硬盘: 分区1(C:) 分区2(D:) 分区3(E:)
(具体放大)
次引导扇 文件存放区
一个
… …
分区:
又一个扇区
一个扇区
根目录区
文件分配表2(FAT2)
(具体放大) 文件分配表1(FAT1)
(b) MS-DOS对硬盘的划分
图9-1 MS-DOS对盘区的划分
但在MS-DOS 中,子目录的内容是存放在文件存放区里的。因此,只要文件存放区有空闲的地方,就可以开辟
用来存放子目录的目录项。这就是说,对于MS-DOS,子目录里的目录项数目是没有具体限制的。
8.如果要新建一个文件,就在文件分配表里寻找一个标志为“FREE”的表目,将它所对应的那个簇分配给文
件使用,并将簇号填入文件目录中。那么这时文件分配表里的那个表目应该被改记为什么标志?
答:这时文件分配表里的那个表目应该被改记为EOF。
9.试述在MS-DOS 中,怎样利用系统文件表(SFT)和进程程序段前缀里的文件打开表(JFT)来实现对一个
文件的访问?
答:MS-DOS 在系统中设置了“系统文件表”(SFT),当用户打开一个文件时,就在SFT里申请一个表目,把
文件的目录信息以及对文件的使用信息存放在表目中。因此,该 SFT起到了活动文件目录的作用。另外,MS-DOS
在每个进程的程序段前缀里,开辟有该进程的文件打开表(JFT)。
当某个进程要打开一个文件时,系统的处理分以下两步进行。
(1)先用文件名去查系统文件表SFT,看里面有没有叫这个名字的文件。如果有,说明该表目里存放着该文件
的目录等有关信息,并且能够获得该表目的序号;如果没有,则申请一个空闲的 SFT表项,把文件的目录信息从磁
盘拷贝到表目中,填写进其他信息,然后也获得该表目的序号。
(2)在进程程序段前缀的文件打开表JFT里申请一个表项,把得到的系统文件表表目序号填入该表项内,并获
得文件打开表表项的序号,即句柄。
经过这样两步之后,由文件的句柄,就可以去查进程的文件打开表。由文件打开表,就可以得到该文件在系统
文件表里的表目序号。通过这个序号去查系统文件表,就得到该文件的目录内容等信息,从而完成对文件的各种操
作。教材中的图9-20 给出了这个过程的示意图。
10.MS-DOS中,块设备没有逻辑设备名。那么 MS-DOS是根据什么来找到块设备的设备驱动程序(设备头)
的?
答:MS-DOS 把块设备和字符设备驱动程序的设备头统一链接在一起,形成了设备头(DH)链。但在字符设备
设备头的“设备名”里,写的是它的逻辑设备名,而在块设备设备头的“设备名”里,写的是它可以驱动的单元个
数。为了查找块设备使用的具体驱动程序,MS-DOS对块设备又构造了驱动器参数块(DPB)链。图9-2 给出了它们之间的联系。
A: B: C: D: E:
� 0号DPB 1号DPB 2号DPB 3号DPB 4号DPB
�
1 3 0 0
字符设备 块设备 块设备
驱动程序 驱动程序 驱动程序
系统内部参 驱动器参数块(DPB)链
数表(LOL)
1 4
�
NUL
�
-1
NUL的
设备头
CON 03H 02H
设备头(DH)链
图9-2 MS-DOS的DPB链与DH链的联系示意
有了这样的联系,通过盘符(盘符在系统内部的标识是以0代表驱动器A:,1代表驱动器B:,2代表驱动器C:
等),通过系统内部参数表(LOL)的指点,去查找驱动器参数块链。从找到的驱动器参数块中的指针,就可以得到
具体块设备的驱动程序(设备头),从而完成对块设备的输入/输出服务,MS-DOS就是这样来找到块设备的设备驱动
程序(设备头)的(这里的图9-2,即是教材上的图9-23)。
四、计算
1.已经知道MS-DOS的每个目录项要占用 32个字节。假定一磁盘卷每个扇区长 512 个字节,根目录区安排在
盘卷的5~0BH扇区。试问该盘卷的根目录里最多能够包含有多少个目录项?
解:依照题意,磁盘卷根目录区如图9-3 所示。由于一个扇区长512个字节,每个目录项要占用32个字节,
总共7个扇区用于存放根目录。因此:
512×7/32=112
5 6 7 8 9 10 11
根目录区
图9-3 根目录区示意图
这表示该盘卷的根目录里最多能够包含112个目录项。
2.假定MS-DOS的各段寄存器取值如下:CS是0010H,DS是0100H,SS是0100H,ES是1000H。试问这时
的进程可以访问内存的哪些部分?
解:由于MS-DOS 一个内存段最大为 64KB(FFFFH字节),因此,当前CS(代码段)可访问的内存区域应该
是:00100H~00100H+FFFFH,即00100H~100FFH;当前DS(数据段)和SS(栈段)可访问的内存区域应该是:
01000H~01000H+FFFFH,即 01000H~10FFFH;当前 ES(附加段)可访问的内存区域应该是:10000H~
10000H+FFFFH,即10000H~1FFFFH。这些区域之间有重叠的地方,因此最后的结果是:
CS:00100H~01000H; DS及SS:01000H~10000H; ES:10000H~1FFFFH3.假定现在系统的FAT表的表项顺序有以下的值:
X,X,8,−1,−1,−1,3,2,5,0,0,……
其中前两个X不去管它。0表示一个空闲表目,−1表示文件结尾。若某一个文件的目录表项以 7为起始簇号。
问该文件包含有多少簇?都是哪些簇?
解:按照题意,其FAT表如图9-4 所示。由于该文件的目录表项以 7为起始簇号,所以顺着簇链找下去,
可以知道该文件包含4簇,即7→2→8→5。
文件目录项
中的首簇号
7
0 1 2 3 4 5 6 7 8 9 10
文件分配表
X X 8 –1 –1 –1 3 2 5 0 0
(FAT):
图9-4 一个系统的FAT表
第 4444 章:CCCC 语言练习题
一、 单项选择题
1.( A )是构成C语言程序的基本单位。
A、函数 B、过程 C、子程序 D、子例程
2.C语言程序从 C 开始执行。
A) 程序中第一条可执行语句 B) 程序中第一个函数
C) 程序中的main函数 D) 包含文件中的第一个函数
3、以下说法中正确的是( C )。
A、C语言程序总是从第一个定义的函数开始执行
B、在C语言程序中,要调用的函数必须在main( )函数中定义
C、C语言程序总是从main( )函数开始执行
D、C语言程序中的main()函数必须放在程序的开始部分
4.下列关于C语言的说法错误的是( B ) 。
A)C程序的工作过程是编辑、编译、连接、运行
B) C语言不区分大小写。
C) C程序的三种基本结构是顺序、选择、循环
D)C程序从main 函数开始执行
5.下列正确的标识符是(C )。
A.-a1 B.a[i] C.a2_i D.intt
5~8题为相同类型题
考点:标识符的命名规则(1) 只能由字母、数字、下划线构成
(2) 数字不能作为标识符的开头
(3) 关键字不能作为标识符
选项A中的“-” ,选项B中“[”与“]”不满足(1);选项D中的int 为关键字,不满足(3)
6.下列C语言用户标识符中合法的是( B )。
A)3ax B)x C)case D)-e2 E)union
选项A中的标识符以数字开头不满足(2);选项C,E均为为关键字,不满足(3);选项D中的“-”不满足(1);
7.下列四组选项中,正确的C语言标识符是( C )。
A) %x B) a+b C) a123 D) 123
选项A中的“%” ,选项B中“+”不满足(1);选项D中的标识符以数字开头不满足(2)
8、下列四组字符串中都可以用作C语言程序中的标识符的是( A )。
A、print _3d db8 aBc B、I\am one_half start$it 3pai
C、str_1 Cpp pow while D、Pxq My->book line# His.age
选项B中的“\”,”$” ,选项D中“>”,”#”,”.”,”-”不满足(1);选项C中的while 为关键字,不满足(3)
9.C 语言中的简单数据类型包括(D )。
A、整型、实型、逻辑型 B、整型、实型、逻辑型、字符型
C、整型、字符型、逻辑型 D、整型、实型、字符型
10.在C语言程序中,表达式5%2的结果是 C 。
A)2.5 B)2 C)1 D)3
详见教材P52~53.
%为求余运算符,该运算符只能对整型数据进行运算。且符号与被模数相同。5%2=1; 5%(-2)=1;(-5)%2=-1;
(-5)%(-2)=-1;
/为求商运算符,该运算符能够对整型、字符、浮点等类型的数据进行运算,5/2=2
11.如果inta=3,b=4;则条件表达式"aage D)(*p).age
33.设有如下定义:
strucksk
{ inta;
floatb;
}data;
int*p;
若要使P指向data中的a域,正确的赋值语句是 C
A)p=&a; B)p=data.a; C)p=&data.a; D)*p=data.a;
34.设有以下说明语句:
typedef struct stu
{ int a;
float b;
}stutype;
则下面叙述中错误的是( D )。
A、struct是结构类型的关键字
B、structstu是用户定义的结构类型
C、a和b都是结构成员名
D、stutype是用户定义的结构体变量名
35. 语句int*p;说明了 C 。
A)p是指向一维数组的指针
B)p是指向函数的指针,该函数返回一int型数据
C)p是指向int型数据的指针 // 指针的定义教材P223
D)p是函数名,该函数返回一指向int型数据的指针
36.下列不正确的定义是( A )。
A. int*p=&i,i; B.int*p,i;
C.inti,*p=&i; D.inti,*p;
选项A先定义一个整型指针变量p,然后将变量i的地址赋给p。然而此时还未定义变量i因此编译器无法获得
变量i的地址。(A与C对比,选项C先定义变量i,则在内存中为i分配空间,因此i在内存空间的地址就可以确定
了;然后再定义p,此时可以为p赋i的地址,C正确)
37. 若有说明:intn=2,*p=&n,*q=p,则以下非法的赋值语句是: ( D )A)p=q B)*p=*q C)n=*q D)p=n
p,q 同为整型指针变量,二者里面仅能存放整型变量的地址。
选项A,q中为地址,因此可将此地址赋给p
选项B,*p表示p所指向对象n的内容,即一个整数;*q表示q所指向对象的内容,由于在定义q时为其初始化,
将p中n的地址给q,因此p中存放n的地址,*q表示q所指向对象n的内容.因此*p=*q 相当于 n=n;
选项C,n=*q 等价于n=n;
选项D,p中只能存放地址,不能将n中的整数值赋给p
38.有语句:inta[10],;则 B 是对指针变量p的正确定义和初始化。
A)intp=*a; B)int *p=a; C)intp=&a; D)int*p=&a;
选项A,a是数组名,不是指针变量名,因此不可用*标注数组名a
选项C,a是数组名,数组名就是地址,无需再用地址符号。而且在定义指针变量 p时,应在变量名前加*,标明p
是指针变量
选项D,a是数组名,数组名就是地址,无需再用地址符号。
39.若有说明语句“inta[5],*p=a;”,则对数组元素的正确引用是(C)。
A.a[p] B.p[a] C.*(p+2) D.p+2
首先定义一个整型数组a,a的长度为5,然后定义一个指针变量p,并同时对p进行初始化,将数组a的地址赋
给p。因此此时p中存放的数组a的首地址,即数组中第一个元素a[0]的地址。
对于数组元素下标的引用(详见p144), 一般形式 数组名[下标] 其中下标为逻辑地址下标,从 0开始计数,方括
号中的下标可以是变量,可以是表达式,但结果一定要是整数。
选项A,p中存放的是地址,不是整数,不能做数组元素的下标
选项B,a是数组名,数组名就是地址,不是整数,不能做数组元素的下标
选项C,(重点!!!详见p231~234) p+2 表示指向同一数组中的下两个元素的地址,当前 p指向a[0],则p+2
表示a[2]的地址,因此*(p+2)表示a[2]的内容
40. 有如下程序
int a[10]={1,2,3,4,5,6,7,8,9,10},*P=a;
则数值为9的表达式是 B
A) *P+9 B)*(P+8) C) *P+=9 D)P+8
(重点!!!详见p231~234)
首先定义一个整型数组a,a的长度为5,然后定义一个指针变量 P,并同时对P进行初始化,将数组a的地址赋
给P。因此此时P中存放的数组a的首地址,即数组中第一个元素a[0]的地址。
数组中9对应的是a[8], 选项B,P+8表示数组中后8个元素的地址,即a[8]的地址。*(P+8)则表示该地址内所存
放的内容,即a[8]的值。
选项A,*P表示P所指向对象的内容,此时 P指向a[0],*P即a[0]的值1.*P+9=1+9=10
选项C,*P表示P所指向对象的内容,此时P指向a[0], *P即a[0]的值。因此*P+=9 即*P=*P+9, 等价于a[0]=a[0]+9.
选项D,P+8 表示数组中后8个元素的地址,即a[8]的地址,而非a[8]中的值。
41. 在C语言中,以 D 作为字符串结束标志
A)’\n’ B)’’ C) ’0’ D)’\0’
42.下列数据中属于“字符串常量”的是( A )。
A.“a” B.{ABC} C.‘abc\0’ D.‘a’
若干个字符构成字符串
在C语言中,用单引号标识字符;用双引号标识字符串选项B,C,分别用{}和’’标识字符串
选项D,标识字符。
43.已知char x[]="hello", y[]={'h','e','a','b','e'};, 则关于两个数组长度的正确描述是 B .
A)相同 B)x大于y C)x小于y D)以上答案都不对
C语言中,字符串后面需要一个结束标志位'\0',通常系统会自动添加。
对一维数组初始化时可采用字符串的形式(例如本题数组x),也可采用字符集合的形式(例如本题数组y)。在以字
符串形式初始化时,数组x不尽要存储字符串中的字符,还要存储字符串后的结束标志位,因此数组 x的长度为6;
在以字符集合形式初始化时,数组y,仅存储集合中的元素,因此数组y长度为5
二、 读程序
基本输入输出及流程控制
1111....
####iiiinnnncccclllluuuuddddeeee<<<>>>
mmmmaaaaiiiinnnn(((())))
{{{{iiiinnnnttttaaaa====1111,,,,bbbb====3333,,,,cccc====5555;;;;
iiiiffff((((cccc========aaaa++++bbbb))))
pppprrrriiiinnnnttttffff((((""""yyyyeeeessss\\\\nnnn""""))));;;;
eeeellllsssseeee
pppprrrriiiinnnnttttffff((((""""nnnnoooo\\\\nnnn""""))));;;;
}}}}
运行结果为:nnnnoooo
详见教材pppp88889999 选择结构
详见教材pppp99991111关系符号
详见附录DDDDpppp333377778888符号的优先级
========表示判断符号两边的值是否相等;====表示将符号右边的值赋给左边的变量
本题考点是选择结构3种基本形式的第二种
选择结构三种一般形式中的“语句”皆为复合语句,复合语句要用{}括起来,只有当复合语句中只包括一条语句时可
以省略{},此题即如此,因此两个printf操作没有加{}
若c==a+b 成立,则执行printf("yes\n");
否则(即c==a+b不成立),执行printf("no\n");
+的优先级高于==,因此先算a+b,值为4, 表达式5==4 不成立,因此执行printf("no\n");即输出字符串no
2222....
####iiiinnnncccclllluuuuddddeeee<<<>>>
mmmmaaaaiiiinnnn(((()))){{{{iiiinnnnttttaaaa====11112222,,,,bbbb====----33334444,,,,cccc====55556666,,,,mmmmiiiinnnn====0000;;;;
mmmmiiiinnnn====aaaa;;;;
iiiiffff((((mmmmiiiinnnn>>>>bbbb))))
mmmmiiiinnnn====bbbb;;;;
iiiiffff((((mmmmiiiinnnn>>>>cccc))))
mmmmiiiinnnn====cccc;;;;
pppprrrriiiinnnnttttffff((((""""mmmmiiiinnnn====%%%%dddd"""",,,,mmmmiiiinnnn))));;;;
}}}}
运行结果为: mmmmiiiinnnn====----33334444
详见教材pppp88889999 选择结构
本题考点是选择结构 3333种基本形式的第一种
一共包含了两个选择结构(两个 iiiiffff语句)
定义变量,并赋值 此时aaaa====11112222,,,,bbbb====----33334444,,,,cccc====55556666,,,,mmmmiiiinnnn====0000
将aaaa中值拷贝,赋给mmmmiiiinnnn,覆盖了mmmmiiiinnnn中的0000,此时 mmmmiiiinnnn中的值被更新为11112222。
若mmmmiiiinnnn>>>>bbbb成立,则执行mmmmiiiinnnn====bbbb;;;;
若mmmmiiiinnnn>>>>cccc成立,则执行mmmmiiiinnnn====cccc;;;;
输出mmmmiiiinnnn中的值
11112222大于----33334444,,,,第一个iiiiffff语句的表达式成立,因此执行 mmmmiiiinnnn====bbbb;;;; 执行后mmmmiiiinnnn中的值被更新为----33334444....
----33334444小于55556666,,,,第二个iiiiffff语句的表达式不成立,因此不执行 mmmmiiiinnnn====cccc;;;;
最后输出mmmmiiiinnnn中的值,为----33334444....
3333....
####iiiinnnncccclllluuuuddddeeee<<<>>>
mmmmaaaaiiiinnnn(((())))
{{{{iiiinnnnttttxxxx====2222,,,,yyyy====----1111,,,,zzzz====5555;;;;
iiiiffff((((xxxx<<<>>>====0000),,,,执行zzzz====zzzz++++1111;;;;输出zzzz
2222>>>>----1111,表达式xxxx<<<>>>
mmmmaaaaiiiinnnn(((())))
{{{{ffffllllooooaaaattttaaaa,,,,bbbb,,,,cccc,,,,tttt;;;;
aaaa====3333;;;;
bbbb====7777;;;;
cccc====1111;;;;
iiiiffff((((aaaa>>>>bbbb))))
{{{{tttt====aaaa;;;;aaaa====bbbb;;;;bbbb====tttt;;;;}}}}
iiiiffff((((aaaa>>>>cccc))))
{{{{tttt====aaaa;;;;aaaa====cccc;;;;cccc====tttt;;;;}}}}
iiiiffff((((bbbb>>>>cccc))))
{{{{tttt====bbbb;;;;bbbb====cccc;;;;cccc====tttt;;;;}}}}
pppprrrriiiinnnnttttffff((((""""%%%%5555....2222ffff,,,,%%%%5555....2222ffff,,,,%%%%5555....2222ffff"""",,,,aaaa,,,,bbbb,,,,cccc))));;;;
}}}}
运行结果为:1111....00000000,,,, 2222....00000000,,,, 7777....00000000
详见教材p72数据的输出形式
本题包含了3个if 语句,每个if语句后的{}都不可省略,因为每个{}中都包含了多条语句
若表达式a>b成立,则执行{t=a;a=b;b=t;}
若表达式a>c成立,则执行{t=a;a=c;c=t;}
若表达式b>c成立,则执行{t=b;b=c;c=t;}
输出a,b,c中的值,要求输出的每个数据宽度为5个空格,小数部分保留2位,数据右对齐
3小于7,因此表达式a>b 不成立,因此不执行{t=a;a=b;b=t;}
3大于1,因此表达式a>c成立,则执行{t=a;a=b;b=t;}。第一句,将a中的3拷贝,粘贴到t中;第二句,将c中的1
拷贝,粘贴到a中,覆盖掉先前的3;第三句。将t中的3拷贝到c中,覆盖掉c中先前的1. 执行完复合语句后实现
了a,c元素的值的互换,a为1,c为3,t为3,。
7大于c中的3,因此b>c成立,执行则执行{t=b;b=c;c=t;},过程同上,执行后b为3,c为7,t为7
此时输出a,b,c中的值为1.00, 2.00, 7.00
5555.
####iiiinnnncccclllluuuuddddeeee <<<>>>
mmmmaaaaiiiinnnn(((())))
{{{{ ffffllllooooaaaatttt cccc====3333....0000,,,,dddd====4444....0000;;;;
iiiiffff((((cccc>>>>dddd))))cccc====5555....0000;;;;
eeeellllsssseeeeiiiiffff((((cccc========dddd))))cccc====6666....0000;;;;
eeeellllsssseeee cccc====7777....0000;;;;
pppprrrriiiinnnnttttffff((((““““%%%%....1111ffff\\\\nnnn””””,,,,cccc))));;;;
}}}}
运行结果为:7777....0000
此题为if...else...语句的嵌套,第二if...else...作为第一个if...else...语句else部分的复合语句。
若表达式c>d成立,则执行c=5.0;
否则(表达式c>d 不成立)
若表达式c==d 成立,则执行c=6.0;
否则,执行c=7.0;
输出c中的值
3.0 小于4.0,因此表达式c>d不成立,执行第二个if…else…。
3.0 不等于4.0,因此表达式c==d 不成立,执行c=7.0,将7.0 赋给c, 覆盖掉c中的3.0,此时c中的值为7.0
输出此时的c中的值
6666....
####iiiinnnncccclllluuuuddddeeee<<<>>>
mmmmaaaaiiiinnnn(((())))
{{{{ iiiinnnnttttmmmm;;;;
ssssccccaaaannnnffff((((""""%%%%dddd"""",,,,&&&&mmmm))));;;;
iiiiffff((((mmmm>>>>====0000))))
{{{{ iiiiffff((((mmmm%%%%2222========0000))))pppprrrriiiinnnnttttffff((((""""%%%%ddddiiiissssaaaappppoooossssiiiittttiiiivvvveeeeeeeevvvveeeennnn\\\\nnnn"""",,,,mmmm))));;;;
eeeellllsssseeee pppprrrriiiinnnnttttffff((((""""%%%%ddddiiiissssaaaappppoooossssiiiittttiiiivvvveeeeoooodddddddd\\\\nnnn"""",,,,mmmm))));;;; }}}}
eeeellllsssseeee
{{{{ iiiiffff((((mmmm%%%%2222========0000)))) pppprrrriiiinnnnttttffff((((""""%%%%ddddiiiissssaaaannnneeeeggggaaaattttiiiivvvveeeeeeeevvvveeeennnn\\\\nnnn"""",,,,mmmm))));;;;
eeeellllsssseeee pppprrrriiiinnnnttttffff((((""""%%%%ddddiiiissssaaaannnneeeeggggaaaattttiiiivvvveeeeoooodddddddd\\\\nnnn"""",,,,mmmm))));;;; }}}}
}}}}
若键入-9999,则运行结果为:::: ----9999iiiissssaaaannnneeeeggggaaaattttiiiivvvveeeeoooodddddddd
7777....
####iiiinnnncccclllluuuuddddeeee<<<>>>
mmmmaaaaiiiinnnn(((())))
{{{{iiiinnnnttttnnnnuuuummmm====0000;
wwwwhhhhiiiilllleeee((((nnnnuuuummmm<<<<====2222)))){{{{nnnnuuuummmm++++++++;pppprrrriiiinnnnttttffff((((""""%%%%dddd\\\\nnnn"""",,,,nnnnuuuummmm))));}}}}
}}}}
运行结果为:
1111
2222
3333
详见教材pppp111111115555循环结构当循环条件num<=2 成立的时候,执行循环体{num++;printf("%d\n",num);}中的语句。
循环初值num为0;
循环条件num<=2 成立
第1次循环:执行num++;即将num中的值加1,执行后num 为1;
执行printf("%d\n",num);在屏幕上输出num 中的值,即输出1,之后换行
此时num 中的值为1,循环条件num<=2 成立
第2此循环:执行num++;即将num中的值加1,执行后num 为2;
执行printf("%d\n",num);在屏幕上输出num 中的值,即输出2,之后换行
此时num 中的值为2,循环条件num<=2 成立
第3此循环:执行num++;即将num中的值加1,执行后num 为3;
执行printf("%d\n",num);在屏幕上输出num 中的值,即输出3,之后换行
此时num 中的值为3,循环条件num<=2 不成立,结束循环。
8888.
####iiiinnnncccclllluuuuddddeeee<<<>>>
mmmmaaaaiiiinnnn(((())))
{{{{iiiinnnnttttssssuuuummmm====11110000,,,,nnnn====1111;;;;
wwwwhhhhiiiilllleeee((((nnnn<<<<3333)))) {{{{ssssuuuummmm====ssssuuuummmm----nnnn;;;; nnnn++++++++;;;;}}}}
pppprrrriiiinnnnttttffff((((““““%%%%dddd,,,,%%%%dddd””””,,,,nnnn,,,,ssssuuuummmm))));;;;
}}}}
运行结果为:3333,,,,7777
当循环条件n<3成立的时候,执行循环体{sum=sum-n; n++;}中的语句。
循环初值sum 为10,n 为1;
循环条件n<3成立
第1次循环:执行sum=sum-n=10-1=9;
执行n++,即将n中的值加1,执行后n为2;
此时n中的值为2,sum 中的值为9,循环条件n<3 成立,继续执行循环
第2次循环:执行sum=sum-n=9-2=7;
执行n++,即将n中的值加1,执行后n为3;
输出此时n,sum 中的值,即为3,7。需要注意,在printf(“%d,%d”,n,sum); 中要求输出的数据彼此间用逗号间隔,因此
结果的两个数据间一定要有逗号
9999....
####iiiinnnncccclllluuuuddddeeee<<<>>>mmmmaaaaiiiinnnn(((())))
{{{{iiiinnnnttttnnnnuuuummmm,,,,cccc;;;;
ssssccccaaaannnnffff((((""""%%%%dddd"""",,,,&&&&nnnnuuuummmm))));;;;
ddddoooo {{{{cccc====nnnnuuuummmm%%%%11110000;;;; pppprrrriiiinnnnttttffff((((""""%%%%dddd"""",,,,cccc))));;;; }}}}wwwwhhhhiiiilllleeee((((((((nnnnuuuummmm////====11110000))))>>>>0000))));;;;
pppprrrriiiinnnnttttffff((((""""\\\\nnnn""""))));;;;
}}}}
从键盘输入22223333,则运行结果为:33332222
详见教材pppp111111117777循环结构;pppp66660000复合的赋值运算符
ddddoooo{{{{}}}}wwwwhhhhiiiilllleeee((((表达式))));;;;
先无条件执行循环体,再判断循环条件。注意 wwwwhhhhiiiilllleeee(表达式)后有分号
定义整型变量num,c;
为num 赋一个整型值;
执行{c=num%10; printf("%d",c); }直到循环条件(num/=10)>0不成立;
输出换行
已知为num 赋值23
第1次执行循环体
执行c=num%10=23%10=3;
执行printf("%d",c);输出3
判断循环条件 num/=10 等价于num=num/10; 因此num=23/10=2, 2大于0,因此循环条件(num/=10)>0 成立,继续执
行循环体。执行完第1次循环时,num 为2,c为3
第2次执行循环体
执行c=2%10=2;
执行printf("%d",c);再输出2
判断循环条件num=2/10=0,0 等于0,因此循环条件(num/=10)>0不成立。结束循环
11110000
####iiiinnnncccclllluuuuddddeeee<<<>>>
mmmmaaaaiiiinnnn(((())))
{{{{iiiinnnnttttssss====0000,,,,aaaa====5555,,,,nnnn;;;;
ssssccccaaaannnnffff((((""""%%%%dddd"""",,,,&&&&nnnn))));;;;
ddddoooo {{{{ssss++++====1111;;;; aaaa====aaaa----2222;;;;}}}}wwwwhhhhiiiilllleeee((((aaaa!!!!====nnnn))));;;;
pppprrrriiiinnnnttttffff((((""""%%%%dddd,%%%%dddd\\\\nnnn"""",,,,ssss,,,,aaaa))));;;;
}}}}
若输入的值1111,运行结果为: 2222,,,,1111
详见教材pppp111111117777循环结构;pppp66660000复合的赋值运算符
执行{s+=1; a=a-2;}直到循环条件a!=n 不成立;
已知为n赋值1,s 为0,a为5
第1次执行循环体
执行s+=1;等价于s=s+1=0+1执行a=a-2;a=5-2=3
判断循环条件,3 不等于1,因此循环条件a!=n 成立,继续执行循环体。
执行完第1次循环时,s为1,a为3
第2次执行循环体
执行s+=1;等价于s=s+1=1+1=2
执行a=a-2;a=3-2=1
判断循环条件,1 等于1,因此循环条件a!=n 不成立,结束循环。
执行完第2次循环时,s为2,a为1
输出此时s,a中的值,结果为2,1
11111111.
####iiiinnnncccclllluuuuddddeeee""""ssssttttddddiiiioooo....hhhh""""
mmmmaaaaiiiinnnn(((())))
{{{{cccchhhhaaaarrrrcccc;;;;
cccc====ggggeeeettttcccchhhhaaaarrrr(((())));;;;
wwwwhhhhiiiilllleeee((((cccc!!!!====''''????'''')))) {{{{ppppuuuuttttcccchhhhaaaarrrr((((cccc))));;;; cccc====ggggeeeettttcccchhhhaaaarrrr(((())));;;;}}}}
}}}}
如果从键盘输入aaaabbbbccccddddeeee?ffffgggghhhh(回车)
运行结果为:aaaabbbbccccddddeeee
11112222.
####iiiinnnncccclllluuuuddddeeee<<<>>>
mmmmaaaaiiiinnnn(((())))
{{{{cccchhhhaaaarrrrcccc;;;;
wwwwhhhhiiiilllleeee((((((((cccc====ggggeeeettttcccchhhhaaaarrrr(((())))))))!!!!====’’’’$$$$’’’’))))
{{{{iiiiffff((((‘‘‘‘AAAA’’’’<<<<====cccc&&&&&&&&cccc<<<<====‘‘‘‘ZZZZ’’’’)))) ppppuuuuttttcccchhhhaaaarrrr((((cccc))));;;;
eeeellllsssseeeeiiiiffff((((‘‘‘‘aaaa’’’’<<<<====cccc&&&&&&&&cccc<<<<====‘‘‘‘zzzz’’’’)))) ppppuuuuttttcccchhhhaaaarrrr((((cccc----33332222))));;;; }}}}
}}}}
当输入为aaaabbbb****AAAABBBB%%%%ccccdddd####CCCCDDDD$$$$时,运行结果为:AAAABBBBAAAABBBBCCCCDDDDCCCCDDDD
11113333....
####iiiinnnncccclllluuuuddddeeee<<<>>>
mmmmaaaaiiiinnnn(((())))
{{{{iiiinnnnttttxxxx,,,,yyyy====0000;;;;
ffffoooorrrr((((xxxx====1111;;;;xxxx<<<<====11110000;;;;xxxx++++++++))))
{{{{iiiiffff((((yyyy>>>>====11110000))))
bbbbrrrreeeeaaaakkkk;;;;
yyyy====yyyy++++xxxx;;;;
}}}}
pppprrrriiiinnnnttttffff((((““““%%%%dddd %%%%dddd””””,,,,yyyy,,,,xxxx))));;;;
}}}}
运行结果为:11110000 5555
详见教材pppp111122220000 ffffoooorrrr语句详见教材pppp111122226666~~~~111122228888 bbbbrrrreeeeaaaakkkk,ccccoooonnnnttttiiiinnnnuuuueeee语句
ffffoooorrrr((((表达式1111;;;;表达式2222;;;;表达式3333))))
{{{{
}}}}
((((1111)))) 先求解表达式1111
((((2222)))) 求解表达式2222,若其值为真,执行循环体,然后执行 ((((3333)))).... 若为假,则结束循环,转到((((5555))))
((((3333)))) 求解表达式3333
((((4444)))) 转回上面 ((((2222))))继续执行
((((5555)))) 循环结束,执行ffffoooorrrr语句下面的一个语句
bbbbrrrreeeeaaaakkkk,跳出循环体;ccccoooonnnnttttiiiinnnnuuuueeee,,,,结束本次循环(第 iiii次循环),继续执行下一次循环((((第iiii++++1111次循环))))
此题 表达式1为x=1,表达式2(循环条件)为x<=10,表达式3为x++
初值x为1,y为0,循环条件(即表达式2)x<=10成立,进入循环体
第1次循环
执行if语句。0小于10,if 语句的条件表达式不成立,不执行break;
执行y=y+x;y=0+1=1
转向表达式3,执行x++, x=x+1=1+1=2。循环条件x<=10成立,进入第2次循环
第2次循环
执行if语句。1小于10,if 语句的条件表达式不成立,不执行break;
执行y=y+x;y=1+2=3
转向表达式3,执行x++, x=x+1=2+1=3。循环条件x<=10成立,进入第3次循环
第3次循环
执行if语句。3小于10,if 语句的条件表达式不成立,不执行break;
执行y=y+x;y=3+3=6
转向表达式3,执行x++, x=x+1=3+1=4。循环条件x<=10成立,进入第4次循环
第4次循环
执行if语句。6小于10,if 语句的条件表达式不成立,不执行break;
执行y=y+x;y=6+4=10
转向表达式3,执行x++, x=x+1=4+1=5。循环条件x<=10成立,进入第5次循环
第5次循环
执行if语句。10等于10,if语句的条件表达式成立,执行break,跳出循环。
从break 跳出至for 语句的下一条语句。执行printf(“%d %d”,y,x);
输出当前的y与x.结果为10 5
11114444....
####iiiinnnncccclllluuuuddddeeee<<<>>>mmmmaaaaiiiinnnn(((())))
{{{{ cccchhhhaaaarrrrcccchhhh;;;;
cccchhhh====ggggeeeettttcccchhhhaaaarrrr(((())));;;;
sssswwwwiiiittttcccchhhh((((cccchhhh))))
{{{{ ccccaaaasssseeee ‘‘‘‘AAAA’’’’::::pppprrrriiiinnnnttttffff((((““““%%%%cccc””””,,,,’’’’AAAA’’’’))));;;;
ccccaaaasssseeee ‘‘‘‘BBBB’’’’::::pppprrrriiiinnnnttttffff((((““““%%%%cccc””””,,,,’’’’BBBB’’’’))));;;;bbbbrrrreeeeaaaakkkk;;;;
ddddeeeeffffaaaauuuulllltttt::::pppprrrriiiinnnnttttffff((((““““%%%%ssss\\\\nnnn””””,,,,””””ooootttthhhheeeerrrr””””))));;;;
}}}}}}}}
当从键盘输入字母 AAAA时,运行结果为:AAAABBBB
详见教材pppp111100003333,sssswwwwiiiittttcccchhhh语句
sssswwwwiiiittttcccchhhh(表达式)
{{{{ ccccaaaasssseeee 常量1111 :语句 1111
ccccaaaasssseeee 常量2222 :语句 2222
┇ ┇ ┇
ccccaaaasssseeee 常量nnnn :语句nnnn
ddddeeeeffffaaaauuuulllltttt :::: 语句nnnn++++1111
}}}}
其中表达式,常量 1111,…………,常量nnnn都为整型或字符型
ccccaaaasssseeee相当于给出执行程序的入口和起始位置,若找到匹配的常量,则从此处开始往下执行程序,不再匹配常量,直
至遇到bbbbrrrreeeeaaaakkkk或sssswwwwiiiittttcccchhhh结束
本题过程:
首先从键盘接收一个字符’A’并将其放在变量ch 中。
执行switch 语句。Switch 后面的条件表达式为ch,因此表达式的值即为字符’A’. 用字符’A’依次与下面的 case中
的常量匹配。
与第1个case后的常量匹配,则从其后的语句开始往下执行程序(在执行过程中不再进行匹配。)因此先执行
printf(“%c”,’A’),屏幕上输出A;再往下继续执行printf(“%c”,’B’),屏幕上输出B;再继续执行break,此时跳出switch
语句。
11115555....
####iiiinnnncccclllluuuuddddeeee<<<>>>
mmmmaaaaiiiinnnn(((())))
{{{{iiiinnnnttttaaaa====1111,,,,bbbb====0000;
ssssccccaaaannnnffff((((““““%%%%dddd””””,,,,&&&&aaaa))));;;;
sssswwwwiiiittttcccchhhh((((aaaa))))
{{{{ ccccaaaasssseeee1111::::bbbb====1111;bbbbrrrreeeeaaaakkkk;
ccccaaaasssseeee2222::::bbbb====2222;bbbbrrrreeeeaaaakkkk;
ddddeeeeffffaaaauuuulllltttt::::bbbb====11110000;}}}}
pppprrrriiiinnnnttttffff((((""""%%%%dddd"""",,,,bbbb))));
}}}}
若键盘输入5555,运行结果为:11110000
本题过程:首先用scanf 函数为变量a赋值为5。
执行switch 语句。switch 后面的条件表达式为a,因此表达式的值即为5. 用5依次与下面 case 中的常量匹配。
没有找到匹配的常量,因此两个case后的语句都不执行。执行default 后面的语句b=10;将10 赋给变量b。
输出变量b,结果为10
11116666....
####iiiinnnncccclllluuuuddddeeee<<<>>>
mmmmaaaaiiiinnnn(((())))____
{{{{cccchhhhaaaarrrrggggrrrraaaaddddeeee====’’’’CCCC’’’’;;;;
sssswwwwiiiittttcccchhhh((((ggggrrrraaaaddddeeee))))
{{{{
ccccaaaasssseeee‘‘‘‘AAAA’’’’::::pppprrrriiiinnnnttttffff((((““““99990000----111100000000\\\\nnnn””””))));;;;
ccccaaaasssseeee‘‘‘‘BBBB’’’’::::pppprrrriiiinnnnttttffff((((““““88880000----99990000\\\\nnnn””””))));;;;
ccccaaaasssseeee‘‘‘‘CCCC’’’’::::pppprrrriiiinnnnttttffff((((““““77770000----88880000\\\\nnnn””””))));;;;
ccccaaaasssseeee‘‘‘‘DDDD’’’’::::pppprrrriiiinnnnttttffff((((““““66660000----77770000\\\\nnnn””””))));;;;bbbbrrrreeeeaaaakkkk;;;;
ccccaaaasssseeee‘‘‘‘EEEE’’’’::::pppprrrriiiinnnnttttffff((((““““<<<<66660000\\\\nnnn””””))));;;;
ddddeeeeffffaaaauuuulllltttt::::pppprrrriiiinnnnttttffff((((““““eeeerrrrrrrroooorrrr!!!!\\\\nnnn””””))));;;;
}}}}
}}}}
运行结果为:
77770000----88880000
66660000----77770000
本题过程:
首先从键盘接收一个字符’C’并将其放在变量grade中。
执行switch 语句。switch 后面的条件表达式为grade,因此表达式的值即为字符’C’. 用字符’C’依次与下面的 case
中的常量匹配。
与第3个case后的常量匹配,则从其后的语句开始往下执行程序(在执行过程中不再进行匹配。)因此先执行
printf(“70-80\n”);,屏幕上输出70-80,并换行;再往下继续执行printf(“60-70\n”),屏幕上输出60-70,并换行;再继续
执行break, 此时跳出switch 语句。
11117777....
####iiiinnnncccclllluuuuddddeeee<<<>>>
mmmmaaaaiiiinnnn(((())))
{{{{iiiinnnnttttyyyy====9999;;;;
ffffoooorrrr((((;;;;yyyy>>>>0000;;;;yyyy--------))))
iiiiffff((((yyyy%%%%3333========0000))))
{{{{pppprrrriiiinnnnttttffff((((%%%%dddd””””,,,,--------yyyy))));;;;
}}}}
}}}}
运行结果为:
888855552222详见教材pppp55553333,自增自减符号
此题 表达式1被省略,表达式2(循环条件)为y>0,表达式3为y--
初值y为9,循环条件(即表达式2)y>0成立,进入循环体
第1次循环
执行if语句。9%3==0,if语句的条件表达式成立,执行printf(%d”,- -y),即y先自减1变为8,然后在输出,因
此屏幕上输出8
转向表达式3,执行y--, y=y-1=8-1=7。循环条件y>0 成立,进入第2次循环
第2次循环
执行if语句。7%3不为0,if语句的条件表达式不成立,不执行printf(%d”,--y)
转向表达式3,执行y--, y=y-1=7-1=6。循环条件y>0 成立,进入第3次循环
第3次循环
执行if语句。6%3==0,if语句的条件表达式成立,执行printf(%d”,- -y),即y先自减1变为5,然后在输出,因
此屏幕上输出5
转向表达式3,执行y--, y=y-1=5-1=4。循环条件y>0 成立,进入第4次循环
第4次循环
执行if语句。4%3不为0,if语句的条件表达式不成立,不执行printf(%d”,--y)
转向表达式3,执行y--, y=4-1=3。循环条件y>0成立,进入第5次循环
第5次循环
执行if语句。3%3==0,if语句的条件表达式成立,执行printf(%d”,- -y),即y先自减1变为2,然后在输出,因
此屏幕上输出2
转向表达式3,执行y--, y=y-1=2-1=1。循环条件y>0 成立,进入第5次循环
第6次循环
执行if语句。1%3不为0,if语句的条件表达式不成立,不执行printf(%d”,--y)
转向表达式3,执行y--, y=1-1=0。循环条件y>0不成立,循环结束。
11118888....
####iiiinnnncccclllluuuuddddeeee<<<>>>
mmmmaaaaiiiinnnn(((())))
{{{{iiiinnnnttttiiii,,,,ssssuuuummmm====0000;;;; iiii====1111;;;;
ddddoooo{{{{ssssuuuummmm====ssssuuuummmm++++iiii;;;;iiii++++++++;;;;}}}}wwwwhhhhiiiilllleeee((((iiii<<<<====11110000))));;;;
pppprrrriiiinnnnttttffff((((““““%%%%dddd””””,,,,ssssuuuummmm))));;;;
}}}}
运行结果为: 5555555511119999....
####iiiinnnncccclllluuuuddddeeee<<<>>>
####ddddeeeeffffiiiinnnneeeeNNNN4444
mmmmaaaaiiiinnnn(((())))
{{{{iiiinnnnttttiiii;;;;
iiiinnnnttttxxxx1111====1111,,,,xxxx2222====2222;;;;
pppprrrriiiinnnnttttffff((((""""\\\\nnnn""""))));;;;
ffffoooorrrr((((iiii====1111;;;;iiii<<<<====NNNN;;;;iiii++++++++))))
{{{{pppprrrriiiinnnnttttffff((((""""%%%%4444dddd%%%%4444dddd"""",,,,xxxx1111,,,,xxxx2222))));;;;
iiiiffff((((iiii%%%%2222========0000))))
pppprrrriiiinnnnttttffff((((""""\\\\nnnn""""))));;;;
xxxx1111====xxxx1111++++xxxx2222;;;;
xxxx2222====xxxx2222++++xxxx1111;;;;
}}}}
}}}}
运行结果为:
1111 2222 3333 5555
8888 11113333 22221111 33334444
此题 首先为整型变量赋初值x1=1,x2=2
表达式1为i=1,表达式2(循环条件)为i<=N即i<=4,表达式3为i++
循环变量初值i为1,循环条件(即表达式2)i<=4成立,进入第1次循环
第1次循环
执行printf("%4d%4d",x1,x2);因此屏幕上输出1 2
执行if语句。1%2不为0,if语句的条件表达式不成立,不执行printf("\n");
执行x1=x1+x2=1+2=3;此时x1 中的值已变为3
执行x2=x2+x1=2+3=5。
转向表达式3,执行i++, i为2。循环条件i<=4 成立,进入第2次循环
第2次循环
执行printf("%4d%4d",x1,x2);因此屏幕上输出3 5
执行if语句。2%2==0,if语句的条件表达式成立,执行pppprrrriiiinnnnttttffff((((""""\\\\nnnn""""))));;;;换行
执行x1=x1+x2=3+5=8;此时x1 中的值已变为8
执行x2=x2+x1=5+8=13。
转向表达式3,执行i++, i为3。循环条件i<=4 成立,进入第3次循环
第3次循环
执行printf("%4d%4d",x1,x2);因此屏幕上输出8 13
执行if语句。3%2不为0,if语句的条件表达式不成立,不执行printf("\n");
执行x1=x1+x2=8+13=21;此时x1 中的值已变为21
执行x2=x2+x1=21+13=34。
转向表达式3,执行i++, i为4。循环条件i<=4 成立,进入第4次循环
第2次循环
执行printf("%4d%4d",x1,x2);因此屏幕上输出21 34
执行if语句。4%2==0,if语句的条件表达式成立,执行pppprrrriiiinnnnttttffff((((""""\\\\nnnn""""))));;;;换行执行x1=x1+x2=21+34=55;此时x1中的值已变为55
执行x2=x2+x1=34+55=89。
转向表达式3,执行i++, i为5。循环条件i<=4 不成立,结束循环
22220000
####iiiinnnncccclllluuuuddddeeee<<<>>>
mmmmaaaaiiiinnnn(((())))
{{{{ iiiinnnntttt xxxx,,,,yyyy;;;;
ffffoooorrrr((((xxxx====33330000,,,,yyyy====0000;;;;xxxx>>>>====11110000,,,,yyyy<<<<11110000;;;;xxxx--------,,,,yyyy++++++++))))
xxxx////====2222,,,,yyyy++++====2222;;;;
pppprrrriiiinnnnttttffff((((““““xxxx====%%%%dddd,,,,yyyy====%%%%dddd\\\\nnnn””””,,,,xxxx,,,,yyyy))));;;;
}}}}
运行结果为:
xxxx====0000,,,,yyyy====11112222
22221111....
####iiiinnnncccclllluuuuddddeeee<<<>>>
####ddddeeeeffffiiiinnnneeeeNNNN4444
mmmmaaaaiiiinnnn(((())))
{{{{iiiinnnntttt iiii,,,,jjjj;;;;
ffffoooorrrr((((iiii====1111;;;;iiii<<<<====NNNN;;;;iiii++++++++))))
{{{{ffffoooorrrr((((jjjj====1111;;;;jjjj<<<>>>
mmmmaaaaiiiinnnn(((())))
{{{{ iiiinnnntttt iiii,,,,aaaa[[[[11110000]]]];;;;
ffffoooorrrr((((iiii====9999;;;;iiii>>>>====0000;;;;iiii--------))))
aaaa[[[[iiii]]]]====11110000----iiii;;;;
pppprrrriiiinnnnttttffff((((““““%%%%dddd%%%%dddd%%%%dddd””””,,,,aaaa[[[[2222]]]],,,,aaaa[[[[5555]]]],,,,aaaa[[[[8888]]]]))));;;;
}}}}
运行结果为:
888855552222
详见pppp111144443333----111144446666.... 例题6666....1111一定看懂!
首先定义整型变量i,整型数组a,a的长度为10,即a中包含10 个整型元素(整型变量)
执行for 循环语句
初值i=9, 使得循环条件i>=0 成立,执行循环体
第1次循环
执行a[i]=10-i 等价于a[9]=10-9=1
计算表达式3,即i--,i为8,使得循环条件i>=0成立,继续执行循环体
第2次循环
执行a[i]=10-i 等价于a[8]=10-8=2
计算表达式3,即i--,i为7,使得循环条件i>=0成立,继续执行循环体
第3次循环
执行a[i]=10-i 等价于a[7]=10-7=3
计算表达式3,即i--,i为6,使得循环条件i>=0成立,继续执行循环体
第4次循环
执行a[i]=10-i 等价于a[6]=10-6=4
计算表达式3,即i--,i为5,使得循环条件i>=0成立,继续执行循环体
第5次循环
执行a[i]=10-i 等价于a[5]=10-5=5
计算表达式3,即i--,i为4,使得循环条件i>=0成立,继续执行循环体
第6次循环
执行a[i]=10-i 等价于a[4]=10-4=6
计算表达式3,即i--,i为3,使得循环条件i>=0成立,继续执行循环体
第7次循环
执行a[i]=10-i 等价于a[3]=10-3=7
计算表达式3,即i--,i为2,使得循环条件i>=0成立,继续执行循环体
第8次循环
执行a[i]=10-i 等价于a[2]=10-2=8
计算表达式3,即i--,i为1,使得循环条件i>=0成立,继续执行循环体
第9次循环
执行a[i]=10-i 等价于a[1]=10-1=9计算表达式3,即i--,i为0,使得循环条件i>=0成立,继续执行循环体
第10 次循环
执行a[i]=10-i 等价于a[0]=10-0=10
计算表达式3,即i--,i为-1,使得循环条件i>=0 不成立,跳出循环体
2222....
####iiiinnnncccclllluuuuddddeeee<<<>>>
mmmmaaaaiiiinnnn(((())))
{{{{iiiinnnnttttiiii,,,,aaaa[[[[6666]]]];;;;
ffffoooorrrr((((iiii====0000;;;;iiii<<<<6666;;;;iiii++++++++))))
aaaa[[[[iiii]]]]====iiii;;;;
ffffoooorrrr((((iiii====5555;;;;iiii>>>>====0000;;;;iiii--------))))
pppprrrriiiinnnnttttffff((((""""%%%%3333dddd"""",,,,aaaa[[[[iiii]]]]))));;;;
}}}}
运行结果为:
5555 4444 3333 2222 1111 0000
首先定义整型变量i,整型数组a,a的长度为6,即a中包含6个整型元素(整型变量)
执行第一个for循环语句
初值i=0, 使得循环条件i<6成立,执行循环体
第1次循环
执行a[i]=i 等价于a[0]=0
计算表达式3,即i++,i为1,使得循环条件i<6成立,继续执行循环体
第2次循环
执行a[i]=i 等价于a[1]=1
计算表达式3,即i++,i为2,使得循环条件i<6成立,继续执行循环体
第3次循环
执行a[i]=i 等价于a[2]=2
计算表达式3,即i++,i为3,使得循环条件i<6成立,继续执行循环体
第4次循环
执行a[i]=i 等价于a[3]=3
计算表达式3,即i++,i为4,使得循环条件i<6成立,继续执行循环体
第5次循环
执行a[i]=i 等价于a[4]=4
计算表达式3,即i++,i为5,使得循环条件i<6成立,继续执行循环体
第6次循环
执行a[i]=i 等价于a[5]=5
计算表达式3,即i++,i为6,使得循环条件i<6不成立,结束循环
执行第二个for循环语句
初值i=5, 使得循环条件i>=0 成立,执行循环体
第1次循环
执行printf("%3d",a[i]); 即输出a[5]的值
计算表达式3,即i--,i为4,使得循环条件i>=0成立,继续执行循环体
第2次循环执行printf("%3d",a[i]); 即输出a[4]的值
计算表达式3,即i--,i为3,使得循环条件i>=0成立,继续执行循环体
第3次循环
执行printf("%3d",a[i]); 即输出a[3]的值
计算表达式3,即i--,i为2,使得循环条件i>=0成立,继续执行循环体
第4次循环
执行printf("%3d",a[i]); 即输出a[2]的值
计算表达式3,即i--,i为1,使得循环条件i>=0成立,继续执行循环体
第5次循环
执行printf("%3d",a[i]); 即输出a[1]的值
计算表达式3,即i--,i为0,使得循环条件i>=0成立,继续执行循环体
第6次循环
执行printf("%3d",a[i]); 即输出a[0]的值
计算表达式3,即i--,i为6,使得循环条件i>=0不成立,结束循环
3333....
####iiiinnnncccclllluuuuddddeeee<<<>>>
mmmmaaaaiiiinnnn(((())))
{{{{iiiinnnnttttiiii,,,,kkkk,,,,aaaa[[[[11110000]]]],,,,pppp[[[[3333]]]];
kkkk====5555;
ffffoooorrrr((((iiii====0000;iiii<<<<11110000;iiii++++++++))))
aaaa[[[[iiii]]]]====iiii;
ffffoooorrrr((((iiii====0000;iiii<<<<3333;iiii++++++++))))
pppp[[[[iiii]]]]====aaaa[[[[iiii****((((iiii++++1111))))]]]];
ffffoooorrrr((((iiii====0000;iiii<<<<3333;iiii++++++++))))
kkkk++++====pppp[[[[iiii]]]]****2222;
pppprrrriiiinnnnttttffff((((""""%%%%dddd\\\\nnnn"""",,,,kkkk))));
}}}}
运行结果为:22221111
首先定义整型变量i,k,整型数组a,a的长度为10,整型数组p,p的长度为3
k初值为5
第一个for循环语句为数组a进行初始化
执行完第一个for 语句后,a[0]=0,a[1]=1,a[2]=2,a[3]=3,a[4]=4,a[5]=5,a[6]=6,a[7]=7,a[8]=8,a[9]=9 (循
环过程略)
第二个for循环语句为数组p进行初始化
初值i=0, 使得循环条件i<3成立,执行循环体
第1次循环
执行p[i]=a[i*(i+1)]; 即p[0]=a[0*(0+1)]=a[0]=0
计算表达式3,即i++,i为1,使得循环条件i<3成立,继续执行循环体
第2次循环
执行p[i]=a[i*(i+1)]; 即p[1]=a[1*(1+1)]=a[2]=2
计算表达式3,即i++,i为2,使得循环条件i<3成立,继续执行循环体
第3次循环执行p[i]=a[i*(i+1)]; 即p[2]=a[2*(2+1)]=a[6]=6
计算表达式3,即i++,i为3,使得循环条件i<3不成立,结束循环
第三个for循环语句
初值i=0, 使得循环条件i<3成立,执行循环体
第1次循环
执行k+=p[i]*2; 即k=5+p[0]*2=5+0=5
计算表达式3,即i++,i为1,使得循环条件i<3成立,继续执行循环体
第2次循环
执行k+=p[i]*2; 即k=5+p[1]*2=5+2*2=9
计算表达式3,即i++,i为2,使得循环条件i<3成立,继续执行循环体
第1次循环
执行k+=p[i]*2; 即k=9+p[2]*2=9+6*2=21
计算表达式3,即i++,i为3,使得循环条件i<3不成立,结束循环
4444....
####iiiinnnncccclllluuuuddddeeee<<<>>>
iiiinnnntttt mmmm[[[[3333]]]][[[[3333]]]]===={{{{{{{{1111}}}},,,,{{{{2222}}}},,,,{{{{3333}}}}}}}};;;;
iiiinnnntttt nnnn[[[[3333]]]][[[[3333]]]]===={{{{1111,,,,2222,,,,3333}}}};;;;
mmmmaaaaiiiinnnn(((())))
{{{{ pppprrrriiiinnnnttttffff((((““““%%%%dddd,,,,””””,,,,mmmm[[[[1111]]]][[[[0000]]]]++++nnnn[[[[0000]]]][[[[0000]]]]))));;;;
pppprrrriiiinnnnttttffff((((““““%%%%dddd\\\\nnnn””””,,,,mmmm[[[[0000]]]][[[[1111]]]]++++nnnn[[[[1111]]]][[[[0000]]]]))));;;;
}}}}
运行结果为:
3333,,,,0000
详见教材PPPP111144449999~~~~111155552222,图6666....7777看懂!
首先定义整型二维数组m,m为3行,3列的二维矩阵,并对其以行的形式初始化
m[0][0]=1 m[0][1]=0 m[1][2]=0
m[1][0]=2 m[1][1]=0 m[2][2]=0
m[2][0]=3 m[2][1]=0 m[2][2]=0
定义整型二维数组n,m为3行,3列的二维矩阵
n[0][0]=1 n[0][1]=2 n[1][2]=3
n[1][0]=0 n[1][1]=0 n[2][2]=0
n[2][0]=0 n[2][1]=0 n[2][2]=0
因此 m[1][0]+n[0][0]=2+1=3
m[0][1]+n[1][0]=0+0=0
5555....
####iiiinnnncccclllluuuuddddeeee<<<>>>mmmmaaaaiiiinnnn(((())))
{{{{iiiinnnnttttiiii;;;;
iiiinnnnttttxxxx[[[[3333]]]][[[[3333]]]]===={{{{1111,,,,2222,,,,3333,,,,4444,,,,5555,,,,6666,,,,7777,,,,8888,,,,9999}}}};;;;
ffffoooorrrr((((iiii====1111;;;;iiii<<<<3333;;;;iiii++++++++))))
pppprrrriiiinnnnttttffff((((""""%%%%dddd """",,,,xxxx[[[[iiii]]]][[[[3333----iiii]]]]))));;;;
}}}}
运行结果为:
6666 8888
首先按存储顺序为数组x初始化
x[0][0]=1 x[0][1]=2 x[0][2]=3
x[1][0]=4 x[1][1]=5 x[1][2]=6
x[2][0]=7 x[2][1]=8 x[2][2]=9
初值i=1, 使得循环条件i<3成立,执行循环体
第1次循环
执行printf("%d ",x[i][3-i]),打印出x[i][3-i],即x[1][2]的值
计算表达式3,即i++,i为2,使得循环条件i<3成立,继续执行循环体
第2次循环
执行printf("%d ",x[i][3-i]),打印出x[i][3-i],即x[2][1]的值
计算表达式3,即i++,i为3,使得循环条件i<3成立,结束循环
6666....
####iiiinnnncccclllluuuuddddeeee<<<>>>
mmmmaaaaiiiinnnn(((())))
{{{{iiiinnnnttttnnnn[[[[3333]]]][[[[3333]]]],,,,iiii,,,,jjjj;
ffffoooorrrr((((iiii====0000;iiii<<<<3333;iiii++++++++))))
{{{{ffffoooorrrr((((jjjj====0000;jjjj<<<<3333;jjjj++++++++))))
{{{{nnnn[[[[iiii]]]][[[[jjjj]]]]====iiii++++jjjj;
pppprrrriiiinnnnttttffff((((““““%%%%dddd ””””,,,,nnnn[[[[iiii]]]][[[[jjjj]]]]))));
}}}}
}}}}
}}}}
运行结果为:
0000 1111 2222
1111 2222 3333
2222 3333 4444
循环变量i为0, 循环条件 i<3成立,执行循环体
外层for 第1次循环 相当于输出第1行
内层for 循环j初值为0,循环条件j<3 成立,执行循环体
内层for 第1次循环执行n[i][j]=i+j;即n[0][0]=0+0=0;
执行printf(“%d ”,n[i][j]);
执行内层循环表达式3,j++,j为1,j<3 成立,继续执行内层循环体
内层for 第2次循环
执行n[i][j]=i+j;即n[0][1]=0+1=1;
执行printf(“%d ”,n[i][j]);
执行内层循环表达式3,j++,j为2,j<3 成立,继续执行内层循环体
内层for 第3次循环
执行n[i][j]=i+j;即n[0][2]=0+2=2;
执行printf(“%d ”,n[i][j]);
执行内层循环表达式3,j++,j为3,j<3 不成立,结束内层循环
执行printf(“\n”);
执行外层for 语句的表达式3,i++,i为,1, i<3 成立,继续执行外层循环体
外层for 第2次循环 相当于输出第2行
内层for 循环j初值为0,循环条件j<3 成立,执行循环体
内层for 第1次循环
执行n[i][j]=i+j;即n[1][0]=1+0=1;
执行printf(“%d ”,n[i][j]);
执行内层循环表达式3,j++,j为1,j<3 成立,继续执行内层循环体
内层for 第2次循环
执行n[i][j]=i+j;即n[1][1]=1+1=2;
执行printf(“%d ”,n[i][j]);
执行内层循环表达式3,j++,j为2,j<3 成立,继续执行内层循环体
内层for 第3次循环
执行n[i][j]=i+j;即n[1][2]=1+2=3;
执行printf(“%d ”,n[i][j]);
执行内层循环表达式3,j++,j为3,j<3 不成立,结束内层循环
执行printf(“\n”);
执行外层for 语句的表达式3,i++,i为,1, i<3 成立,继续执行外层循环体
外层for 第2次循环 相当于输出第3行
内层for 循环j初值为0,循环条件j<3 成立,执行循环体
内层for 第1次循环
执行n[i][j]=i+j;即n[2][0]=2+0=1;
执行printf(“%d ”,n[i][j]);
执行内层循环表达式3,j++,j为1,j<3 成立,继续执行内层循环体
内层for 第2次循环
执行n[i][j]=i+j;即n[2][1]=2+1=2;
执行printf(“%d ”,n[i][j]);
执行内层循环表达式3,j++,j为2,j<3 成立,继续执行内层循环体
内层for 第3次循环
执行n[i][j]=i+j;即n[2][2]=2+2=3;
执行内层循环表达式3,j++,j为3,j<3 不成立,结束内层循环
执行printf(“\n”);
执行外层for 语句的表达式3,i++,i为,3, i<3 不成立,结束外层循环7777.
####iiiinnnncccclllluuuuddddeeee<<<>>>
mmmmaaaaiiiinnnn(((())))
{{{{
cccchhhhaaaarrrrddddiiiiaaaammmmoooonnnndddd[[[[]]]][[[[5555]]]]===={{{{{{{{‘‘‘‘____’’’’,,,,’’’’____’’’’,,,,’’’’****’’’’}}}},,,,{{{{‘‘‘‘____‘‘‘‘,,,,’’’’****’’’’,,,,’’’’____’’’’,,,,’’’’****’’’’}}}},,,,
{{{{‘‘‘‘****’’’’,,,,’’’’____’’’’,,,,’’’’____‘‘‘‘,,,,’’’’____‘‘‘‘,,,,’’’’****’’’’}}}},,,,{{{{‘‘‘‘____’’’’,,,,’’’’****’’’’,,,,’’’’____’’’’,,,,’’’’****’’’’}}}},,,,{{{{‘‘‘‘____’’’’,,,,’’’’____’’’’,,,,’’’’****’’’’}}}}}}}};;;;
iiiinnnnttttiiii,,,,jjjj;;;;
ffffoooorrrr((((iiii====0000;;;;iiii<<<<5555;;;;iiii++++++++))))
{{{{
ffffoooorrrr((((jjjj====0000;;;;jjjj<<<<5555;;;;jjjj++++++++))))
pppprrrriiiinnnnttttffff((((““““%%%%cccc””””,,,,ddddiiiiaaaammmmoooonnnndddd[[[[iiii]]]][[[[jjjj]]]]))));;;;
pppprrrriiiinnnnttttffff((((““““\\\\nnnn””””))));;;;
}}}}
}}}}注:““““____””””代表一个空格。
运行结果为:
****
**** ****
**** ****
**** ****
****
8888....
####iiiinnnncccclllluuuuddddeeee<<<>>>
mmmmaaaaiiiinnnn(((())))
{{{{iiiinnnnttttiiii,,,,ffff[[[[11110000]]]];;;;
ffff[[[[0000]]]]====ffff[[[[1111]]]]====1111;;;;
ffffoooorrrr((((iiii====2222;;;;iiii<<<<11110000;;;;iiii++++++++))))
ffff[[[[iiii]]]]====ffff[[[[iiii----2222]]]]++++ffff[[[[iiii----1111]]]];;;;
ffffoooorrrr((((iiii====0000;;;;iiii<<<<11110000;;;;iiii++++++++))))
{{{{iiiiffff((((iiii%%%%4444========0000))))
pppprrrriiiinnnnttttffff((((““““\\\\nnnn””””))));;;;
pppprrrriiiinnnnttttffff((((““““%%%%dddd ””””,,,,ffff[[[[iiii]]]]))));;;;
}}}}
}}}}
运行结果为:
1111 1111 2222 3333
5555 8888 11113333 22221111
33334444 55555555
9999.
####iiiinnnncccclllluuuuddddeeee““““ssssttttddddiiiioooo....hhhh””””ffffuuuunnnncccc((((iiiinnnntttt bbbb[[[[]]]]))))
{{{{ iiiinnnntttt jjjj;;;;
ffffoooorrrr((((jjjj====0000;;;;jjjj<<<<4444;;;;jjjj++++++++))))
bbbb[[[[jjjj]]]]====jjjj;;;;
}}}}
mmmmaaaaiiiinnnn(((())))
{{{{ iiiinnnntttt aaaa[[[[4444]]]],,,,iiii;;;;
ffffuuuunnnncccc((((aaaa))));;;;
ffffoooorrrr((((iiii====0000;;;;iiii<<<<4444;;;;iiii++++++++))))
pppprrrriiiinnnnttttffff((((““““%%%%2222dddd””””,,,,aaaa[[[[iiii]]]]))));;;;
}}}}
运行结果为:
0000111122223333
详见教材PPPP111199994444
定义函数func
函数头:未定义函数的类型,则系统默认为int 型。函数func的形参为整型数组名,即只接收整型数组地址。
函数体:定义整型变量j
循环变量初值(表达式1)j=0, 使得循环条件(表达式2)j<4 成立,执行循环体
第1次循环
执行b[j]=j; 即b[0]=0;
执行循环变量自增(及表达式3) j++,j为1,使得j<4成立,继续执行循环体
第2次循环
b[1]=1;
j++,j为2,使得j<4 成立,继续执行循环体
第3次循环
b[2]=2;
j++,j为3,使得j<4 成立,继续执行循环体
第4次循环
b[3]=3;
j++,j为4,使得j<4 不成立,结束循环
main 函数:
定义整型变量i和数组a,其长度为4,
func(a);表示调用函数func,并以数组名a作为调用的实参(数组名在C语言中表示数组所在内存空间的首地址,
在以数组名作为实参时,形参与实参公用存储空间,因此对数组b的操作,即对数组a的操作。)
11110000....
####iiiinnnncccclllluuuuddddeeee<<<>>>
mmmmaaaaiiiinnnn()
{{{{ffffllllooooaaaattttffffuuuunnnn((((ffffllllooooaaaattttxxxx[[[[]]]]))));
ffffllllooooaaaattttaaaavvvveeee,,,,aaaa[[[[3333]]]]===={{{{4444....5555,2222,4444}}}};aaaavvvveeee====ffffuuuunnnn(aaaa);;;;
pppprrrriiiinnnnttttffff((((““““aaaavvvveeee====%%%%7777....2222ffff””””,,,,aaaavvvveeee))));;;;
}}}}
ffffllllooooaaaattttffffuuuunnnn(ffffllllooooaaaattttxxxx[[[[]]]])
{{{{iiiinnnnttttjjjj;;;;
ffffllllooooaaaattttaaaavvvveeeerrrr====1111;
ffffoooorrrr((((jjjj====0000;;;;jjjj<<<<3333;;;;jjjj++++++++))))
aaaavvvveeeerrrr====xxxx[[[[jjjj]]]]****aaaavvvveeeerrrr;;;;
rrrreeeettttuuuurrrrnnnn(aaaavvvveeeerrrr);
}}}}
运行结果为:
aaaavvvveeee==== 33336666....00000000
11111111....
####iiiinnnncccclllluuuuddddeeee<<<>>>
mmmmaaaaiiiinnnn(((())))
{{{{iiiinnnnttttaaaa[[[[2222]]]][[[[3333]]]]===={{{{{{{{1111,,,,2222,,,,3333}}}},,,,{{{{4444,,,,5555,,,,6666}}}}}}}};;;;
iiiinnnnttttbbbb[[[[3333]]]][[[[2222]]]],,,,iiii,,,,jjjj;;;;
ffffoooorrrr((((iiii====0000;;;;iiii<<<<====1111;;;;iiii++++++++))))
{{{{ffffoooorrrr((((jjjj====0000;;;;jjjj<<<<====2222;;;;jjjj++++++++))))
bbbb[[[[jjjj]]]][[[[iiii]]]]====aaaa[[[[iiii]]]][[[[jjjj]]]];;;;
}}}}
ffffoooorrrr((((iiii====0000;;;;iiii<<<<====2222;;;;iiii++++++++))))
{{{{ffffoooorrrr((((jjjj====0000;;;;jjjj<<<<====1111;;;;jjjj++++++++))))
pppprrrriiiinnnnttttffff((((""""%%%%5555dddd"""",,,,bbbb[[[[iiii]]]][[[[jjjj]]]]))));;;;
}}}}
}}}}
运行结果为:
1111 4444 2222 5555 3333 6666
11112222.
####iiiinnnncccclllluuuuddddeeee<<<>>>
ffff((((iiiinnnntttt bbbb[[[[]]]],,,,iiiinnnntttt nnnn))))
{{{{iiiinnnntttt iiii,,,,rrrr;;;;
rrrr====1111;;;;
ffffoooorrrr((((iiii====0000;;;;iiii<<<<====nnnn;;;;iiii++++++++))))
rrrr====rrrr****bbbb[[[[iiii]]]];;;;
rrrreeeettttuuuurrrrnnnn((((rrrr))));;;;
}}}}
mmmmaaaaiiiinnnn(((())))
{{{{iiiinnnnttttxxxx,,,,aaaa[[[[]]]]===={{{{1111,,,,2222,,,,3333,,,,4444,,,,5555,,,,6666,,,,7777,,,,8888,,,,9999}}}};;;;
xxxx====ffff((((aaaa,,,,3333))));;;;
pppprrrriiiinnnnttttffff((((““““%%%%dddd\\\\nnnn””””,,,,xxxx))));;;;}}}}
运行结果为:
22224444
11113333....
####iiiinnnncccclllluuuuddddeeee""""ssssttttddddiiiioooo....hhhh""""
mmmmaaaaiiiinnnn(((())))
{{{{iiiinnnnttttjjjj,,,,kkkk;;;;
ssssttttaaaattttiiiicccciiiinnnnttttxxxx[[[[4444]]]][[[[4444]]]],,,,yyyy[[[[4444]]]][[[[4444]]]];;;;
ffffoooorrrr((((jjjj====0000;;;;jjjj<<<<4444;;;;jjjj++++++++))))
ffffoooorrrr((((kkkk====jjjj;;;;kkkk<<<<4444;;;;kkkk++++++++))))
xxxx[[[[jjjj]]]][[[[kkkk]]]]====jjjj++++kkkk;;;;
ffffoooorrrr((((jjjj====0000;;;;jjjj<<<<4444;;;;jjjj++++++++))))
ffffoooorrrr((((kkkk====jjjj;;;;kkkk<<<<4444;;;;kkkk++++++++))))
yyyy[[[[kkkk]]]][[[[jjjj]]]]====xxxx[[[[jjjj]]]][[[[kkkk]]]];;;;
ffffoooorrrr((((jjjj====0000;;;;jjjj<<<<4444;;;;jjjj++++++++))))
ffffoooorrrr((((kkkk====0000;;;;kkkk<<<<4444;;;;kkkk++++++++))))
pppprrrriiiinnnnttttffff((((""""%%%%dddd,,,,"""",,,,yyyy[[[[jjjj]]]][[[[kkkk]]]]))));;;;
}}}}
运行结果为:
0000,,,,0000,,,,0000,,,,0000,,,,1111,,,,2222,,,,0000,,,,0000,,,,2222,,,,3333,,,,4444,,,,0000,,,,3333,,,,4444,,,,5555,,,,6666
函数
1111....
####iiiinnnncccclllluuuuddddeeee<<<>>>
iiiinnnnttttSSSSuuuubbbb((((iiiinnnnttttaaaa,,,,iiiinnnnttttbbbb))))
{{{{rrrreeeettttuuuurrrrnnnn((((aaaa----bbbb))));;;;}}}}
mmmmaaaaiiiinnnn(((())))
{{{{iiiinnnntttt xxxx,,,,yyyy,,,,rrrreeeessssuuuulllltttt====0000;;;;
ssssccccaaaannnnffff((((""""%%%%dddd,,,,%%%%dddd"""",,,,&&&&xxxx,,,,&&&&yyyy))));;;;
rrrreeeessssuuuulllltttt====SSSSuuuubbbb((((xxxx,,,,yyyy))));;;;
pppprrrriiiinnnnttttffff((((""""rrrreeeessssuuuulllltttt====%%%%dddd\\\\nnnn"""",,,,rrrreeeessssuuuulllltttt))));;;;
}}}}
当从键盘输入::::6666,,,,3333运行结果为:
rrrreeeessssuuuulllltttt====3333
2222....
####iiiinnnncccclllluuuuddddeeee<<<>>>
iiiinnnntttt mmmmiiiinnnn((((iiiinnnnttttxxxx,,,,iiiinnnnttttyyyy))))
{{{{iiiinnnntttt mmmm;
iiiiffff ((((xxxx>>>>yyyy)))) mmmm====xxxx;
eeeellllsssseeee mmmm====yyyy;rrrreeeettttuuuurrrrnnnn((((mmmm))));
}
mmmmaaaaiiiinnnn(((()))) {{{{
iiiinnnntttt aaaa====3333,,,,bbbb====5555,,,,aaaabbbbmmmmiiiinnnn ;
aaaabbbbmmmmiiiinnnn====mmmmiiiinnnn((((aaaa,,,,bbbb))));
pppprrrriiiinnnnttttffff((((““““mmmmiiiinnnn iiiissss %%%%dddd””””, aaaabbbbmmmmiiiinnnn))));
}}}}
运行结果为:
mmmmiiiinnnn iiiissss 5555
3333....
####iiiinnnncccclllluuuuddddeeee<<<>>>
ffffuuuunnnncccc((((iiiinnnnttttxxxx)))){{{{
xxxx====11110000;;;;
pppprrrriiiinnnnttttffff((((““““%%%%dddd,,,,””””,,,,xxxx))));;;;
}}}}
mmmmaaaaiiiinnnn(((())))
{{{{ iiiinnnnttttxxxx====22220000;;;;
ffffuuuunnnncccc((((xxxx))));;;;
pppprrrriiiinnnnttttffff((((““““%%%%dddd””””,,,,xxxx))));;;;
}}}}
运行结果为:
11110000,,,,22220000
在main 函数中调用函数func,main函数将20作为实参穿给func,并转向开始执行func.
main()对应的内存 func()对应的内存
20 x
20 x
func()执行x=10;,其内存中x变为10.
10 x
func()执行printf(“%d, ”,x); 即输出func函数对应内存中x的值,输出的是10. 至此,func函数执行结
束,返回main 函数。main 函数执行printf(“%d”,x);此时输出main函数对应内存中的x,即20
4444....
####iiiinnnncccclllluuuuddddeeee<<<>>>
iiiinnnnttttmmmm====4444;;;;
iiiinnnnttttffffuuuunnnncccc((((iiiinnnnttttxxxx,,,,iiiinnnnttttyyyy))))
{{{{ iiiinnnnttttmmmm====1111;;;;
rrrreeeettttuuuurrrrnnnn((((xxxx****yyyy----mmmm))));;;;
}}}}
mmmmaaaaiiiinnnn(((())))
{{{{iiiinnnnttttaaaa====2222,,,,bbbb====3333;;;;
pppprrrriiiinnnnttttffff((((""""%%%%dddd\\\\nnnn"""",,,,mmmm))));;;;
pppprrrriiiinnnnttttffff((((""""%%%%dddd\\\\nnnn"""",,,,ffffuuuunnnncccc((((aaaa,,,,bbbb))))////mmmm))));;;;
}}}}
运行结果为:
4444
1111
整型变量m在函数外定义,因此m为全局变量,其作用于范围为其定义位置开始,一直到整个程序结束。因此func
与main 函数都可以访问m
程序首先执行main 函数
执行printf("%d\n",m); 即输出m中的值4,并换行。
执行printf("%d\n",func(a,b)/m);即输出表达式func(a,b)/m的值,为了计算该表达式,
需要调用函数func。此时main 将a,b中的2和3值作为实参传递给func的x和y
程序开始转向执行func函数,此时func中的x为2,y为3
执行intm=1; 此句定义了一个局部变量 m并赋值为1 。m的作用域为其所在的复合
语句,即func的函数体,因此在func的函数体重,有限访问局部变量m。
执行return(x*y-m); 即return(2*3-1);返回的是整数5.
func函数返回至main 函数中的被调用处
main 函数中func(a,b)的值为5,func(a,b)/m=5/4=1,注意,在main 函数中访问的m为全局变量m,此时main函
数无法访问func中的m,因为不在func中m的作用域。
5555....
####iiiinnnncccclllluuuuddddeeee<<<>>>
iiiinnnnttttffffuuuunnnn((((iiiinnnnttttaaaa,,,,iiiinnnnttttbbbb))))
{{{{iiiiffff((((aaaa>>>>bbbb)))) rrrreeeettttuuuurrrrnnnn((((aaaa))));;;;
eeeellllsssseeee rrrreeeettttuuuurrrrnnnn((((bbbb))));;;;
}}}}
mmmmaaaaiiiinnnn(((())))
{{{{iiiinnnnttttxxxx====11115555,,,,yyyy====8888,,,,rrrr;;;;rrrr====ffffuuuunnnn((((xxxx,,,,yyyy))));;;;
pppprrrriiiinnnnttttffff((((""""rrrr====%%%%dddd\\\\nnnn"""",,,,rrrr))));;;;
}}}}
运行结果为:rrrr====11115555
程序首先执行main 函数
执行r=fun(x,y);即将func(x,y)的值赋给r,为了计算该表达式,需要调用函数 func。此时main将x,y 中的15 和
8值作为实参传递给func的a和b
程序开始转向执行func函数,此时func中的a为15,b为8
执行if语句;判断if后面的表达式,a>b 成立,因此执行相应的操作return(a);即返回
a的值 。
func函数返回至main 函数中的被调用处
main 函数中func(x,y)的值为15,即将15 赋给r。
执行printf("r=%d\n", r); 即输出r=15
6666....
####iiiinnnncccclllluuuuddddeeee<<<>>>
iiiinnnnttttffffaaaacccc((((iiiinnnnttttnnnn))))
{{{{iiiinnnnttttffff====1111,,,,iiii;;;;
ffffoooorrrr((((iiii====1111;;;;iiii<<<<====nnnn;;;;iiii++++++++))))
ffff====ffff****iiii;;;;
rrrreeeettttuuuurrrrnnnn((((ffff))));;;;
}}}}
mmmmaaaaiiiinnnn(((())))
{{{{iiiinnnnttttjjjj,,,,ssss;;;;
ssssccccaaaannnnffff((((““““%%%%dddd””””,,,,&&&&jjjj))));;;;
ssss====ffffaaaacccc((((jjjj))));;;;
pppprrrriiiinnnnttttffff((((""""%%%%dddd!!!!====%%%%dddd\\\\nnnn"""",,,,jjjj,,,,ssss))));;;;
}}}}
如果从键盘输入3333, 运行结果为: 3333!!!!====6666
程序首先执行main 函数
执行r=fun(x,y);即将func(x,y)的值赋给r,为了计算该表达式,需要调用函数 func。此时main将x,y 中的15 和
8值作为实参传递给func的a和b
程序开始转向执行func函数,此时func中的a为15,b为8
执行if语句;判断if后面的表达式,a>b 成立,因此执行相应的操作return(a);即返回
a的值 。
func函数返回至main 函数中的被调用处
main 函数中func(x,y)的值为15,即将15 赋给r。
执行printf("r=%d\n", r); 即输出r=15
7777....
####iiiinnnncccclllluuuuddddeeee<<<>>>
uuuunnnnssssiiiiggggnnnneeeeddddffffuuuunnnn6666((((uuuunnnnssssiiiiggggnnnneeeeddddnnnnuuuummmm))))
{{{{uuuunnnnssssiiiiggggnnnneeeeddddkkkk====1111;;;;ddddoooo
{{{{kkkk****====nnnnuuuummmm%%%%11110000;;;;
nnnnuuuummmm////====11110000;;;;
}}}}wwwwhhhhiiiilllleeee((((nnnnuuuummmm))));;;;
rrrreeeettttuuuurrrrnnnnkkkk;;;;
}}}}
mmmmaaaaiiiinnnn(((())))
{{{{uuuunnnnssssiiiiggggnnnneeeeddddnnnn====22226666;;;;
pppprrrriiiinnnnttttffff((((““““%%%%dddd\\\\nnnn””””,,,,ffffuuuunnnn6666((((nnnn))))))));;;;
}}}}
运行结果为:11112222
程序首先执行main 函数
执行printf(“%d\n”,fun6(n)); 即输出表达式func(6)的值,为了计算该表达式,需要调用
函数func。此时main 将n中的26作为实参传递给func的num
程序开始转向执行func函数,此时func中的num 为26
执行do-while语句
第1次循环
执行k*=num%10,即k=k*(num%10)=1*(26%10)=6
执行num/=10;即num=num/10=26/10=2
while后面循环条件为num,此时num为2,是非0值,即表示循环条件成立,
继续执行循环体。此时k为6
第2次循环
执行k*=num%10,即k=k*(num%10)=6*(2%10)=12
执行num/=10;即num=num/10=2/10=0
while后面循环条件为num,此时num为0,表示循环条件不成立,
结束循环
执行returnk; 即返回至main 函数中的被调用处
执行main函数
继续执行printf(“%d\n”,fun6(n)); 即输出12
8888....
####iiiinnnncccclllluuuuddddeeee<<<>>>
iiiinnnnttttmmmmaaaaxxxx((((iiiinnnnttttxxxx,,,,iiiinnnnttttyyyy))));;;;
mmmmaaaaiiiinnnn(((())))
{{{{iiiinnnnttttaaaa,,,,bbbb,,,,cccc;;;;
aaaa====7777;;;;bbbb====8888;;;;
cccc====mmmmaaaaxxxx((((aaaa,,,,bbbb))));;;;
pppprrrriiiinnnnttttffff((((""""MMMMaaaaxxxxiiiissss%%%%dddd"""",,,,cccc))));;;;
}}}}
mmmmaaaaxxxx((((iiiinnnnttttxxxx,,,,iiiinnnnttttyyyy))))
{{{{iiiinnnnttttzzzz;;;;
zzzz====xxxx>>>>yyyy????xxxx::::yyyy;;;;
rrrreeeettttuuuurrrrnnnn((((zzzz))));;;;}}}}
运行结果为:
MMMMaaaaxxxxiiiissss8888
指针
1111....
####iiiinnnncccclllluuuuddddeeee<<<>>>
mmmmaaaaiiiinnnn(((( ))))
{{{{iiiinnnntttt xxxx[[[[]]]]===={{{{11110000,,,,22220000,,,,33330000,,,,44440000,,,,55550000}}}};;;;
iiiinnnntttt ****pppp;;;;
pppp====xxxx;;;;
pppprrrriiiinnnnttttffff((((““““%%%%dddd””””,,,,****((((pppp++++2222))))))));;;;
}}}}
运行结果为:
33330000
首先定义一个整型数组x,x的长度为5;然后定义一个指针变量p;对p 进行初始化,将数组x的地址赋给 p。因
此此时p中存放的数组x的首地址,即数组中第一个元素x[0]的地址。
然后执行printf 语句,输出表达式*(p+2)的值。p+2 表示以p当前指向的位置起始,之后第2个元素的地址,即
a[2]的地址。*(p+2)则表示该地址内所存放的内容,即a[2]的值30,因此输出30
2222....
####iiiinnnncccclllluuuuddddeeee<<<>>>
mmmmaaaaiiiinnnn(((())))
{{{{ cccchhhhaaaarrrrssss[[[[]]]]====””””aaaabbbbccccddddeeeeffffgggg””””;;;;
cccchhhhaaaarrrr****pppp;;;;
pppp====ssss;;;;
pppprrrriiiinnnnttttffff((((““““cccchhhh====%%%%cccc\\\\nnnn””””,,,,****((((pppp++++5555))))))));;;;
}}}}
运行结果为:
cccchhhh====ffff
首先定义一个字符型数组s,并用字符串aaaabbbbccccddddeeeeffffgggg对s进行初始化; 然后定义一个字符型指针变量p; 对p进行初
始化,将数组s的地址赋给p。因此此时p中存放的数组s的首地址,即数组中第一个元素s[0]的地址。
然后执行printf 语句,输出表达式*(p+5)的值。p+5 表示以p当前指向的位置起始,之后第5个元素的地址,即
a[5]的地址。*(p+5)则表示该地址内所存放的内容,即a[5]的值f, 因此输出ch=f
3333....
####iiiinnnncccclllluuuuddddeeee<<<>>>
mmmmaaaaiiiinnnn(((())))
{{{{iiiinnnnttttaaaa[[[[]]]]===={{{{1111,,,,2222,,,,3333,,,,4444,,,,5555}}}} ;
iiiinnnnttttxxxx,,,,yyyy,,,,****pppp;pppp====aaaa;
xxxx====****((((pppp++++2222))));
pppprrrriiiinnnnttttffff((((""""%%%%dddd:%%%%dddd\\\\nnnn"""",,,,****pppp,,,,xxxx))));
}}}}
运行结果为::::
1111::::3333
首先定义一个整型数组a,并对a进行初始化; 然后定义整型变量x,y,整型指针变量p; 再将数组a的地址赋给p。
因此此时p中存放的数组a的首地址,即数组中第一个元素a[0]的地址。执行xxxx====****((((pppp++++2222))));p+2表示以p当前所指向的
位置起始,之后第2个元素的地址,即a[2]的地址。*(p+2)则表示该地址内所存放的内容,即a[2]的值3,然后再把
3赋给x
然后执行printf语句,先输出表达式*p的值。此时*p表示的是p所指向变量的内容,即a[0]的值1。再输出一个
冒号。然后再输出x中的值3。
4444....
####iiiinnnncccclllluuuuddddeeee<<<>>>
mmmmaaaaiiiinnnn(((())))
{{{{ iiiinnnntttt aaaarrrrrrrr[[[[]]]]===={{{{33330000,,,,22225555,,,,22220000,,,,11115555,,,,11110000,,,,5555}}}},,,, ****pppp====aaaarrrrrrrr;;;;
pppp++++++++;;;;
pppprrrriiiinnnnttttffff((((““““%%%%dddd\\\\nnnn””””,,,,****((((pppp++++3333))))))));;;;
}}}}
运行结果为:11110000
首先定义一个整型数组arr,并对arr进行初始化; 然后定义整型指针变量 p; 再将数组arr 的地址赋给p。因此此
时p中存放的数组arr的首地址,即数组中第一个元素a[0]的地址。
执行p++,即p=p+1。p+1 表示以p当前所指向的位置起始,之后第1个元素的地址,即arr[1]的地址,然后再将
arr[1]的地址赋给p,执行完此语句后,p不再指向arr[0],而是指向arr[1]。
然后执行 printf 语句,输出表达式*(p+3)的值。p+3 表示以p当前指向的位置起始(此时p 指向arr[1]),之后第 3
个元素的地址,即arr[4]的地址。*(p+3)则表示该地址内所存放的内容,即arr[4]的值10, 因此输出10
5555....
####iiiinnnncccclllluuuuddddeeee<<<>>>
mmmmaaaaiiiinnnn(((())))
{{{{ iiiinnnntttt aaaa[[[[]]]]===={{{{1111,,,,2222,,,,3333,,,,4444,,,,5555,,,,6666}}}};;;;
iiiinnnntttt xxxx,,,,yyyy,,,,****pppp;;;;
pppp====&&&&aaaa[[[[0000]]]];;;;
xxxx====****((((pppp++++2222))));;;;
yyyy====****((((pppp++++4444))));;;;
pppprrrriiiinnnnttttffff((((““““****pppp====%%%%dddd,,,,xxxx====%%%%dddd,,,,yyyy====%%%%dddd\\\\nnnn””””,,,,****pppp,,,,xxxx,,,,yyyy))));;;;
}}}}
运行结果为:
****pppp====1111,,,,xxxx====3333,,,,yyyy====5555
首先定义一个整型数组 a,并对a进行初始化; 然后定义整型变量x,y,整型指针变量p; 再将数组元素a[0]的地址
赋给p。
执行x=*(p+2);p+2表示以p当前所指向的位置起始,之后第2个元素的地址,即a[2]的地址。*(p+2)则表示该地
址内所存放的内容,即a[2]的值3,然后再把3赋给x执行y=*(p+4);p+4 表示以p当前所指向的位置起始,之后第4个元素的地址,即a[4]的地址。*(p+4)则表示该地
址内所存放的内容,即a[4]的值5,然后再把5赋给y
执行printf 语句,先输出表达式*p的值。此时*p表示的是p所指向变量的内容,即a[0]的值1。再输x的值3。再
输出y的值5。
6666....
####iiiinnnncccclllluuuuddddeeee<<<>>>
mmmmaaaaiiiinnnn(((())))
{{{{ssssttttaaaattttiiiicccccccchhhhaaaarrrraaaa[[[[]]]]====””””PPPPrrrrooooggggrrrraaaammmm””””,,,,****ppppttttrrrr;;;;
ffffoooorrrr((((ppppttttrrrr====aaaa,,,,ppppttttrrrr<<<>>>
cccchhhhaaaarrrrssss[[[[]]]]====””””AAAABBBBCCCCDDDD””””;;;;
mmmmaaaaiiiinnnn(((())))
{{{{cccchhhhaaaarrrr****pppp;;;;
ffffoooorrrr((((pppp====ssss;;;;pppp<<<>>>
ssssttttrrrruuuuccccttttsssstttt
{{{{iiiinnnnttttxxxx;;;;
iiiinnnnttttyyyy;;;;
}}}}aaaa[[[[2222]]]]===={{{{5555,,,,7777,,,,2222,,,,9999}}}};;;;
mmmmaaaaiiiinnnn(((())))
{{{{
pppprrrriiiinnnnttttffff((((""""%%%%dddd\\\\nnnn"""",,,,aaaa[[[[0000]]]]....yyyy****aaaa[[[[1111]]]]....xxxx))));;;;
}}}}
运行结果是:
11114444
首先是定义结构体st,st中共有两个整型成员x,y。
然后定义一个st类型的数组a,a的长度为2,即数组中含有两个st类型的元素,分别是a[0]和a[1]. 对a进行初始
化,此题是按照储存顺序进行初始化,即将5赋给a[0]中的x(即a[0].x=5); 将7赋给a[0]中的y(即a[0].y=7); 将
2赋给a[1]中的x(即a[1].x=2); 将9赋给a[1]中的y(即a[1].y=9);
执行main函数,输出表达式a[0].y*a[1].x 的值,即7*2的值
5555 aaaa[[[[0000]]]]....xxxx aaaa[[[[0000]]]]
7777 aaaa[[[[0000]]]]....yyyy
2222 aaaa[[[[1111]]]]....xxxx aaaa[[[[1111]]]]
9999 aaaa[[[[1111]]]]....yyyy
2222....
####iiiinnnncccclllluuuuddddeeee<<<>>>
mmmmaaaaiiiinnnn(((())))
{{{{ssssttttrrrruuuuccccttttssssttttuuuu
{{{{iiiinnnnttttnnnnuuuummmm;;;;
cccchhhhaaaarrrraaaa[[[[5555]]]];;;;
ffffllllooooaaaattttssssccccoooorrrreeee;;;;
}}}}mmmm===={{{{1111222233334444,,,,””””wwwwaaaannnngggg””””,,,,88889999....5555}}}};;;;pppprrrriiiinnnnttttffff((((““““%%%%dddd,,,,%%%%ssss,,,,%%%%ffff””””,,,,mmmm....nnnnuuuummmm,,,,mmmm....aaaa,,,,mmmm....ssssccccoooorrrreeee))));;;;
}}}}
运行结果是:
1111222233334444,,,,wwwwaaaannnngggg,,,,88889999....5555
3333....
####iiiinnnncccclllluuuuddddeeee<<<>>>
ssssttttrrrruuuucccctttt ccccmmmmppppllllxxxx
{{{{ iiiinnnntttt xxxx;;;;
iiiinnnntttt yyyy;;;;
}}}}ccccnnnnuuuummmm[[[[2222]]]]===={{{{1111,,,,3333,,,,2222,,,,7777}}}};;;;
mmmmaaaaiiiinnnn(((())))
{{{{
pppprrrriiiinnnnttttffff((((““““%%%%dddd\\\\nnnn””””,,,,ccccnnnnuuuummmm[[[[0000]]]]....yyyy****ccccnnnnuuuummmm[[[[1111]]]]....xxxx))));;;;
}}}}
运行结果是:6666
与第一题解法同
4444....
####iiiinnnncccclllluuuuddddeeee<<<>>>
ssssttttrrrruuuuccccttttaaaabbbbcccc
{{{{iiiinnnnttttaaaa,,,,bbbb,,,,cccc;;;;}}}};;;;
mmmmaaaaiiiinnnn(((())))
{{{{ssssttttrrrruuuuccccttttaaaabbbbcccc ssss[[[[2222]]]]===={{{{{{{{1111,,,,2222,,,,3333}}}},,,,{{{{4444,,,,5555,,,,6666}}}}}}}};;;;
iiiinnnntttttttt;;;;
tttt====ssss[[[[0000]]]]....aaaa++++ssss[[[[1111]]]]....bbbb;;;;
pppprrrriiiinnnnttttffff((((""""%%%%dddd\\\\nnnn"""",,,,tttt))));;;;
}}}}
运行结果是:6666
与第一题解法同
三、 程序填空
1.输入一个字符,判断该字符是数字、字母、空格还是其他字符。
main( )
{charch;
ch=getchar();
if( ch>=’a’&&ch<=’z’|| ch>=’A’&&ch<=’Z’ )
printf("Itisan Englishcharacter\n");
elseif( ch>=’0’&&ch<=’9’ )printf("Itisadigitcharacter\n");
elseif( ch==‘ ’ )
printf("Itisaspace character\n");
else
printf("Itisothercharacter\n"); }
第1空:字符在计算机中以ASCII 码的形式存储。所以当输入的字符,即ch 中字符所对应的ASCII 码的范围在
英文字母的ASCII 码的范围内即可,参照p377。由于英文字母又分为大写字母和小写字母,因此此处用一个逻辑或
表达式,表示ch 中是小写字母或者大写字母,都能使得表达式成立。ch>=97&&ch<=122||ch>=65&&ch<=90
需要注意的是,对于本题区间所对应的表达式,不可写作 97<=ch<=122,也不可写作’A’<=ch <=’Z’. 对于
97<=ch<=122 因为在计算此表达式时的顺序是从左向右,因此先计算97<=ch。无论ch 中的取值如何,表达式97<=ch
的值只有两种情况:0或1.所以无论是0还是1,都小于122,因此97<=ch<=122恒成立。
第3空,判断ch 中是否为空格,也是通过 ch 中字符与空格字符的 ASCII 码来判断。在判断表达式的值是否相
等时,用关系符号==;不要用赋值符号=。
2.下列程序的功能是从输入的整数中,统计大于零的整数个数和小于零的整数个数。用输入 0来结束输入,用i,j
来放统计数,请填空完成程序。
voidmain()
{ int n,i=0,j=0;
printf(“input ainteger,0forend\n”);
scanf(“%d”,&n);
while ( n或n!=0 ) {
if(n>0)i= i+1 ;
else j=j+1;
}
printf(“i=%4d,j=%4d\n”,i,j);
}
此题用i来记录大于零的整数,用j记录小于零的整数。所以循环条件是n(或者n!=0)即当n不为0时执行循环体。
在循环体中是一个选择语句。如果n>0,则令i加1,相当于令正整数的个数加1;否则(即n<0),令j加1,相当于
令负整数的个数加1。
3.编程计算1+3+5+……+101 的值
#include
voidmain(){ inti,sum =0;
for(i=1; i<=101 ; i=i+2; )
sum =sum +i;
printf("sum=%d\n", sum); }
for语句的一般形式详见p120.
表达式1为i=1,为循环变量赋初值,即循环从1开始,本题从1到101,因此终值是101,表达式2是循环条件,
用来控制循环的结束,因此循环条件为i<=101;表达式3为循环变量的自增,本题是
4.编程计算1+3+5…+99 的值
main()
{ int i,sum=0;
i=1;
while( i<100 )
{ sum =sum +i;
I=i+2 ; }
printf("sum=%d\n", sum);
}
5.从键盘输入一个字符,判断它是否是英文字母。
#include
voidmain()
{char c;
printf("inputa character:");
c=getchar();
if(c>= ‘A’ &&c<= ‘Z’ || c>=‘a’&&c<= ‘z’) printf("Yes\n");
else printf("No");
}
6. 下面程序的功能是在a数组中查找与x值相同的元素所在位置,请填空。
#include
void main()
{inta[10],i,x;
printf(“input10 integers:”);
for(i=0;i<10;i++)
scanf(“%d”,&a[i]);
printf(“inputthenumberyou wanttofind x:”);
scanf(“%d”, &x );for(i=0;i<10;i++)
if( x==a[i] )
break;
if( i<10 )
printf(“theposof xis:%d\n”,i);
elseprintf(“cannotfindx!\n”);
}
7.程序读入20个整数,统计非负数个数,并计算非负数之和。
#include
main()
{ int i,a[20],s,count;
s=count=0;
for(i=0;i<20;i++)
scanf(“%d”,&a[i] );
for(i=0;i<20;i++)
{ if( a[i]<0 ) continue ;
s+=a[i] ;
count++;
}
printf(“s=%d\t count=%d\n”,s,count”);
}
8. 输入一个正整数n(1
intmain(void){
inti,index, k,n,temp;
/* 定义1个数组a,它有10 个整型元素*/
printf(“Entern:");
printf(“Enter%dintegers:", n);
for(i=0;i>>>aaaa[[[[jjjj]]]]))))
{{{{mmmmaaaaxxxx====aaaa[[[[jjjj]]]];;;;
mmmm====jjjj;;;;
}}}}
pppprrrriiiinnnnttttffff((((““““下标:%%%%dddd\\\\nnnn最大值::::%%%%dddd””””,,,,jjjj,,,,mmmmaaaaxxxx)))) //j为for 语句的循环变量,当for 语句执行完之后,j中的值为
6,并非最大值下标,在执行某一次循环的比较过程中,将当时最大值的下标存在了m里
}}}}
第四行改为:for(j=0;j<5;j++)
第五行改为:scanf(“%d”,&a[j]);
第七行改为:for(j=1;j<5;j++)
第八行改为:if(max10
⎩
mmmmaaaaiiiinnnn(((())))
{{{{iiiinnnnttttxxxx,,,,yyyy;;;;
pppprrrriiiinnnnttttffff((((““““\\\\nnnnIIIInnnnppppuuuuttttxxxx::::\\\\nnnn””””))));;;;
ssssccccaaaannnnffff((((““““%%%%dddd””””,,,,xxxx))));;;;// 错误同上题scanf
iiiiffff((((xxxx<<<<0000))))
yyyy====xxxx----1111;;;;eeeellllsssseeeeiiiiffff((((xxxx>>>>====0000||||||||xxxx<<<<====11110000)))) // ||表示逻辑或,当左边表达式成立或者右边表达式成立时,整个表达式成立。&&
表示逻辑与,当左边表达式和右边表达式同时成立时,整个表达式成立。此处用逻辑表达式来表示x的区间[0,10],
因此应改用逻辑与符号
yyyy====2222xxxx----1111;;;; //C语言中乘号不能省略,且用*表示乘法运算
eeeellllsssseeee
yyyy====3333xxxx----1111;;;;//C语言中乘号不能省略,且用*表示乘法运算
pppprrrriiiinnnnttttffff((((““““yyyy====%%%%dddd””””,,,,&&&&yyyy))));;;; //printf与scanf 不用,printf 后面给出的是变量名列表或表达式列表,无需地址符号
}}}}
第一处改为:scanf(“%d”,&x);
第二处改为:x>=0&&x<=10
第三处改为:y=2*x-1;
第四处改为:y=3*x-1;
第五处改为:printf(“y=%d”,y);
7777.... 求111100000000~~~~333300000000间能被3333整除的数的和。
mmmmaaaaiiiinnnn(((())))
{{{{iiiinnnnttttnnnn;;;;
lllloooonnnnggggssssuuuummmm;;;;//若定义变量的语句有错误,常见考点有两个:(1)变量的类型,(2)在定义用于存放运算结果的
变量时,一定要赋初值, 一般赋值0或者循环初值。
ffffoooorrrr((((nnnn====111100000000,,,,nnnn<<<<====333300000000,,,,nnnn++++++++)))) //for 语句的格式,三个表达式之间用分号,且分号不可省略
{{{{
iiiiffff((((nnnn%%%%3333====0000)))) // = 是赋值符号,用于将右边的值赋给左边的变量;== 是关系符号,用来判断两个
值是否相等 。改错中if 后面表达式中的赋值符号是常见的考点。
ssssuuuummmm====ssssuuuummmm****nnnn;;;;
}}}}
pppprrrriiiinnnnttttffff((((““““%%%%lllldddd””””,,,,ssssuuuummmm))));;;;
}}}}
第一处改为:longsum=0;
第二处改为:for(n=100;n<=300;n++)
第三处改为:if(n%3==0)
第四处改为:sum=sum+n;
8888.... 求表达式c= ab的值
####iiiinnnncccclllluuuuddddeeee<<<>>>
####iiiinnnncccclllluuuuddddeeee<<<>>>
iiiinnnnttttffffuuuunnnn((((iiiinnnnttttxxxx,,,,iiiinnnnttttyyyy))));;;;
mmmmaaaaiiiinnnn(((()))){{{{ iiiinnnnttttaaaa,,,,bbbb;;;; ffffllllooooaaaattttffff;;;;
ssssccccaaaannnnffff((((““““%%%%dddd,,,,%%%%dddd””””,,,,aaaa,,,,bbbb))));;;;//与改错第1题中的scanf 错误相同
iiiiffff((((aaaabbbb>>>>0000)))){{{{ //C语言中乘号不能省略,且用*表示乘法运算
ffffuuuunnnn((((aaaa,,,,bbbb))));;;;// 调用带有返回值的函数,应将函数的返回值保存在变量里
pppprrrriiiinnnnttttffff((((""""TTTThhhheeeerrrreeeessssuuuullllttttiiiissss::::%%%%dddd\\\\nnnn"""",,,,&&&&ffff)))) //与第6题中printf 错误相同
}}}}
eeeellllsssseeeepppprrrriiiinnnnttttffff((((““““eeeerrrrrrrroooorrrr!!!!””””))));;;;}}}}
ffffuuuunnnn((((xxxx,,,,yyyy)))) // 定义函数的一般形式p173-174
{{{{ ffffllllooooaaaattttrrrreeeessssuuuulllltttt;;;;
rrrreeeessssuuuulllltttt====ssssqqqqrrrrtttt((((aaaa++++bbbb))));;;;
rrrreeeettttuuuurrrrnnnn;;;; //return 语句后面可以返回0、常量、变量和表达式的值。
}}}}
第一处改为:if(a*b>0)
第二处改为:f=fun(a,b);
第三处改为:printf("Theresultis:%d\n",f);
第四处改为:floatfun(intx, inty)
第五处改为:f=fun(a,b);
第六处改为:result=sqrt(a*b);
第七处改为:returnresult;
五、 编程题
1111....输入2222个整数,求两数的平方和并输出。
#include
intmain(void)
{intt a,b,s;
printf("pleaseinputa,b:\n");
scanf("%d%d”,&a,&b);
s=a*a+b*b;
printf("theresult is%d\n",s);
return0;
}
2222.... 输入一个圆半径 rrrr,当rrrr>>>>=0000时,计算并输出圆的面积和周长,否则,输出提示信息。
#include
#definePI 3.14
intmain(void)
{double r,area,girth;
printf("pleaseinputr:\n");
scanf("%lf",&r);
if(r>=0){area=PI*r*r;
girth =2*PI*r;
printf("theareais%.2f\n", area);
printf("thegirthis%.2f\n", girth);}
else
printf("Inputerror!\n");
return 0;
}
3333、已知函数yyyy====ffff((((xxxx)))),编程实现输入一个 xxxx值,输出yyyy值。
2222xxxx++++1111 ((((xxxx<<<<0000))))
yyyy==== 0000 ((((xxxx====0000))))
2222xxxx----1111 ((((xxxx>>>>0000))))
#include
voidmain()
{intx,y;
scanf(“%d”,&x);
if(x<0)y=2*x+1;
elseif(x>0) y=2*x-1;
else y=0;
printf(“%d”,y);
}
4444....从键盘上输入一个百分制成绩 ssssccccoooorrrreeee,按下列原则输出其等级:ssssccccoooorrrreeee≥≥≥≥99990000,等级为 AAAA;88880000≤≤≤≤ssssccccoooorrrreeee<<<<99990000,等级为 BBBB;
77770000≤≤≤≤ssssccccoooorrrreeee<<<<88880000,等级为CCCC;66660000≤≤≤≤ssssccccoooorrrreeee<<<<77770000,等级为DDDD;ssssccccoooorrrreeee<<<<66660000,等级为EEEE。
#include
voidmain(){
int data;
char grade;
printf("Pleaseenter thescore:");
scanf("%d”,&data);
switch(data/10)
{ case10:
case9: grade=’A’; break;
case8: grade=’B’; break;
case7: grade=’C’; break;
case6: grade=’D’; break;
default: grade=’E’;
}
printf("thegrade is%c”,grade);
}
5555.... 编一程序每个月根据每个月上网时间计算上网费用,计算方法如下:⎧ 30元 ≤10小时
⎪
费用=
⎨
每小时3元 10−50小时
⎪
每小时2.5元 ≥50小时
⎩
要求当输入每月上网小时数,,,,显示该月总的上网费用((((6666分))))
#include
voidmain()
{inthour;
floatfee;
printf(“pleaseinputhour:\n”);
scanf(“%d”,&hour);
if(hour<=10)
fee=30;
elseif(hour>=10&&hour<=50)
fee=3*hour;
elsefee=hour*2.5;
printf(“Thetotalfeeis%f”,fee);
}
6666.... 从键盘输入11110000个整数,统计其中正数、负数和零的个数,并在屏幕上输出。
#include
voidmain( ){
inta,i,p=0,n=0,z=0;
printf("pleaseinputnumber");
for(i=0;i<10;i++){
scanf("%d,",&a);
if(a>0) p++;
elseif(a<0) n++;
elsez++;
}
printf("正数:%5d, 负数:%5d,零:%5d\n",p,n,z);
}
7777、编程序实现求1111----11110000之间的所有数的乘积并输出。
#include
void main()
{ int i;
longsum=1;
for(i=1; i<=10;i=i+1)
sum=sum*i;
printf(“thesum ofoddis:%ld”,sum);
}
8888.... 从键盘上输入11110000个数,求其平均值。
#includevoidmain(){
int a,i,sum=0;
floatave;;
for(i=0;i<10;i++){
scanf("%d",&a);
sum+=a;
}
ave=(float)sum/10;
printf("ave =%f\n", ave);
}
9999、编程序实现求1111----1111000000000000之间的所有奇数的和并输出。
#include
void main( )
{ int i,sum=0;
for(i=1; i<1000;i=i+2)
sum=sum+i;
printf(“thesum ofoddis:%d”,sum);
}
11110000....有一个分数序列:2222////1111,3333////2222,5555////3333,8888////5555,11113333////8888,……………………编程求这个序列的前 22220000项之和。
#include
voidmain(){
inti,t,n=20;
floata=2,b=1,s=0;
for(i=1;i<=n;i++)
{s=s+a/b;
t=a;
a=a+b;
b=t;
}
printf("sum=%6.2f",s);
}
11111111.从键盘输入两个数,求出其最大值(要求使用函数完成求最大值,并在主函数中调用该函数)
#include
floatmax(floatx,floaty);
voidmain()
{ floata,b,m;
scanf("%f,%f",&a,&b);
m=max(a,b);
printf("Maxis%f\n",m);
}
floatmax(floatx,floaty){
if(x>=y)
return x;
else
return y;
}
11112222.... 编写程序,其中自定义一函数,用来判断一个整数是否为素数,主函数输入一个数,输出是否为素数。
#include
#include
int IsPrimeNumber(intnumber)
{ inti;
if(number <=1)
return0;
for(i=2;i
intmain(void){
inti,n,iIndex,temp;
inta[10];
printf("Entern:");
scanf("%d", &n);
printf("Enter%d integers:\n");
for(i=0;i
intcomp(intarry[],intn)
{
inti,index,temp;
printf("为数组赋值:\n");
for(i=0;i
voidmain()
{int a[5], s=0;
inti;
for(i=0;i<5;i++)
scanf(“%d”,&a[i]);
for(i=0;i<5;i++)
s=s+a[i];
printf(“result=%f”,s/5.0);
}11115555、输入一个正整数 nnnn((((nnnn<<<<====6666)))),再输入nnnn××××nnnn的矩阵,求其主对角线元素之和及副对角线元素之和并输出。
#include
intmain(void) {
inti,j,n,sum1=0,sum2=0;
inta[6][6];
printf("Enter n(n<=6):");
scanf("%d",&n);
printf("Enter data:\n");
for(i=0;i
#define M 30
void main()
{floatscore[M],max ,min,aver;
int i;
printf(“pleaseinput score:\n”);
for(i=0;iscore[i]) min=score[i];
aver+=score[i];
}
printf(“max=%f,min=%f,aver=%f”,max, min, aver/M);
}
11117777....将一个有5555个元素的数组中的值((((整数))))按逆序重新存放。
例:::: 原来顺序为::::8888、6666、5555、4444、1111,要求改为1111、4444、5555、6666、8888
#defineN5#include
void main()
{inta[N],i,temp;
printf(“enter arraya:\n”);
for(i=0;i
voidmain()
{inta[2][3], b[3][2],i,j;
for(i=0;i<2;i++)
for(j=0;j<3;j++)
scanf(“%d”,&a[i][j]);
for(i=0;i<3;i++)
for(j=0;j<2;j++)
b[i][j]=a[j][i];
for(i=0;i<3;i++)
{for(j=0;j<2;j++)
printf("%5d",b[i][j]);
printf("\n”);
}
}
11119999、从键盘输入11110000名学生的成绩数据,按成绩从高到低的顺序排列并输出。(提示:用数组存放成绩数据)
#include
voidmain()
{inta[10];
inti,j,temp;
printf("inputscore:\n");
for(i=0;i<10;i++)
scanf("%d",&a[i]);
printf("\n");
for(i=1;i<10;i++)for(j=0;j<9;j++)
if(a[j]
void main()
{ inta[4][3],i,j,min,m,n;
printf("Please enterdata:");
for (i=0;i<4;i++)
for (j=0;j<3;j++)
scanf(“%d”,&a[i][j]);
min=a[0][0];
m=0;n=0;
for (i=0;i<4;i++)
for (j=0;j<3;j++)
if(a[i][j]库存上限——————————上限报警
0<库存量≤库存下限—————————下限报警
(1)绘出原始决策表。(2)绘出优化后的决策树。
答:(1)绘出原始决策表。
决策规则号 1111 2222 3333 4444 5555
库存量≤0 Y N N N N
库存量≤储备定额 N Y Y Y
条件
库存量≤库存上限 N N N Y Y
库存量≤库存下限 N N N N Y
缺货处
理
订货处理 ×
正常处理 ×
上限报警 ×
下限报警 ×
(2)绘出优化后的决策树。
>储备定额 正常处理
>0
库存量
>上限 订货处理
<=储备定额 <=上限 上限报警
<下限 下限报警
<=0 缺货处理
72. 某企业物资管理系统中的维修用材料计划信息一览表如下,把它化为符合 3NF的关系,每个关系中的的关
键字用下划线标出。部门编码+部门名称+材料编码+材料名称+型号+规格+计量单位+维修用
答:
部门:部门编码,部门名称
材料:材料编码,材料名称,型号,规格,计量单位
维修:部门编码,材料编码,维修用量
73. 设计代码校验位的方案如下:若原编码为 13752,共五位。从左至右取权32,16,8,4,2,对乘积之和以
11为模取余作为校验位。请计算出原编码的校验位。(写出计算过程)
答:
32×1+16×3+8×7+4×5+2×2=160
160÷11=14…6
原代码的校验位为6
74. 某工厂成品库管理的业务过程如下:成品库保管员按车间送来的入库单登记库存台帐。发货时,发货员根据
销售科送来的发货通知单将成品出库,并发货,同时填写三份出库单,其中一份交给成品库保管员,由他按此出库
单登记库存台帐,出库单的另外两联分别送销售科和会计科。试按此业务过程画出业务流程图。
答:
车间
入库单 库存台帐
销售科 发货员 保管员
发货通知单 出库单 会计科
销售科
75. 某银行储蓄所存(取)款过程如下:储户将填好的存(取)单及存折送交分类处理处。分类处理处按三种不
同情况分别处理。如果存折不符或存(取)单不合格,则将存折及存(取)单直接退还储户重新填写;如果是存款,
则将存折及存款单送交存款处处理。存款处理处取出底帐登记后,将存折退还给储户;如果是取款,则将存折及取
款单送交取款处,改服务台取出底帐及现金,记帐后将存折与现金退给储户。从而完成存(取)款处理过程。试按
此画出数据流程图。
答:
存款处理
存折(单) 分类
储户 存取款帐
处理
取款处理
76. 目前网络信息系统软件中常见的分布结构(计算模式),说明其特点
答:(!) 文件/服务器(F/S)计算模式:网络系统中的服务器向各工作站提供数据和软件资源的文件服务,各工作站
可以根据规定的权限存取服务器上的数据文件和程序文件
(2) 客户机/服务器(C/S)计算模式:将信息处理工作分解为两部分,一部分由服务器来实现,另一部分由客户
机本身来完成。用户通过客户机向服务器提出服务请求,服务器根据请求进行处理后向客户端经过加工的信息,客
户机本身也承担本地信息管理工作。
(3) 浏览器/WEB 服务器(B/S)计算模式:是一种基于互联网技术的层客户机/服务器结构。服务器端采用基于
超文本协议(HTTP)的WEB服务器,客户使用对WEB 服务器上超文本文件进行操作的浏览器。
(4) C/B/S计算模式:C/S模式和B/S模式的综合
77. 判断表、判断树
某航空公司规定,乘客可以免费托运重量不超过 30 公斤的行李。当行李重量超过 30公斤时,对头等舱的国内
乘客超重部分每公斤收费 4元,对其他舱的国内乘客超重部分每公斤收费 6元,对外国乘客超重部分每公斤收费比
国内乘客多一倍。
(1)绘出原始决策表。(2)绘出优化后的决策树
答:
(1)
决策规则号 1111 2222 3333 4444 5555 6666 7777 8888
行李重量W≤
Y Y N N N N
30
条件
国内乘客 Y Y N N Y Y N N
头等舱 Y N Y N Y N Y N
免
费
(W-30)×4 ×
(W-30)×6 ×
(W-30)×8 ×
(W-30)×12 ×
(2)
头等舱 (W-30)×4
是否
国内 头等 其他舱 (W-30)×6
舱
是否
国内 头等舱 (W-30)×8
W>30
乘客 是否
国外
行李 头等 其他舱 (W-30)×12
重量 舱
W≤30 免费
78. 某工厂对工人超产奖励的政策为:该厂生产两种产品 A和B。凡工人每月的实际生产量超过计划指标者均
有奖励。奖励政策为:对于产品A的生产者:超产数N小于或等于50 件时,每超产一件奖励1元;超产数N大于
50 件、小于100 件时,大于 50的部分每件奖励 1.25元,其余每件奖励 1元;超产数大于 100 件时,超过 100 的部
分每件奖励1.5 元,其余按超产100 件以内的方案处理。对于B产品的生产者,超产数N小于25 件时,每超产一件
奖励2元,N大于25、小于或等于50件时,超过25 件的部分每件奖励2.5元,其余按超产25件以内处理;N大于
50件者,超过件部分每件奖励3元,其余按超产50 件以内处理。绘制决策树。答:
1.0*N
1100
112.5+1.5*(N-100)
奖金政策
2.0*N
150
112.5+3*(N-50)
79. 学生评奖:
奖励的目的在于鼓励学生品学兼优,此评奖处理功能是要合理确定学生受奖等级。决定受奖的条件为:已修课
程各类成绩比率为:成绩优秀占50%或70%以上,成绩为中或以下占 15%或20%以下,团结纪律为优良或一般者。
奖励方案为一等、二等、三等奖、鼓励奖四种。其中:
(1) 成绩优秀占70%以上、成绩为中或下占15%以下、纪律为优良的为一等奖。
(2) 成绩优秀占70%以上、成绩为中或下占15%以下、纪律为一般
或成绩优秀占70%以上、成绩为中或下占20%以下、纪律为优秀
或成绩优秀占50%以上、成绩为中或下占15%以下、纪律为优秀的为二等奖。
(3) 成绩优秀占70%以上、成绩为中或下占20%以下、纪律为一般
或成绩优秀占50%以上、成绩为中或下占15%以下、纪律为一般
或成绩优秀占50%以上、成绩为中或下占20%以下、纪律为优秀的为三等奖
(4) 成绩优秀占50%以上、成绩为中或下占20%以下、纪律为一般的为鼓励奖。
答:
学生奖励处理的决策表
已修课 优≥70% Y Y Y Y N N N N 状
程各类 优≥50% - - - - Y Y Y Y 态
条 成 绩 中以下≤15% Y Y N N Y Y N N
比 率 中以下≤20% - - Y Y - - Y Y
件 团 结 优良 Y N Y N Y N Y N
纪 律
评 分 一般 N Y N Y N Y N Y
决 一等奖 X 决
策 二等奖 X X X 策
方 三等奖 X X X 规
案 鼓励奖 X 则条件取值表
条件 取值 含义
1 优≥70%
2 优≥50%
C1:已修课成绩比率
3 中以下≤15%
4 中以下≤20%
1 优良
C2:团结纪律评分
2 一般
学生奖励的决策表
1 2 3 4 5 6 7 8
C1:已修课成绩比率 1 1 1 1 2 2 2 2
3 3 4 4 3 3 4 4
C2:团结纪律评分 1 2 1 2 1 2 1 2
A1:一等奖 X
A2:二等奖 X X X
A3:三等奖 X X X
A4:鼓励奖 X
80. 库房管理系统:某公司对于其库房日常的管理业务,设置了以下库房管理系统。此系统的数据来源是生产部、
车间和物资采购员,数据去处项是主管领导,由此推出此系统的最高层数据流程图(关联图)。
系统具备四个最基本功能:入库管理、出库管理、限额管理和统计,绘制系统顶层数据流程图。
顶层数据流图中,入库管理还可以进一步分解成为三个部分:正常入库、接收退料单和退料处理,而出库管理
可分解为接收限额领料单、限额核对、接收物资领料单和出库处理四个部分,试绘制入库管理的数据流程图。
答:
关联图:
F1生产作业计划
生产部
F2领料单 F5库存报表
车间 库房管理 主管领导
F3退料单
物资 F4验收申请单
采购员
库房管理系统顶层图:F1生产作业计划
生产部
物资 F4验收申请单 1 2
采购员 入库管理 限额管理
D1 库存数据 D2 限额配套卡
F3退料单
车间
F2领料单
3 4 F5库存报表
主管领导
出库管理 统计
库房管理系统第一层数据流图:
生产部 F1
物资 F4 1.1 2
采购员 正常入库 限额管理
F3 1.2 1.3
车间
接收退料单 退料处理
D3 退料单 D1 库存数据
3.1 3.2
F2.1 接收限额
限额核对 D2 限额配套卡
限额领料单 领料单
D4 限额领料单 4
F5
主管领导
3.3 3.4 统计
F2.2 接收物资
出库处理
物资领料单 领料单
D5 物资领料单
81. 下图已给出某单位工资处理的一级数据流图,将其改成方框图形式,并试着绘制二级数据流图。
职工 考勤卡 工资单
工资处理
工资文件
答:工资处理数据流程图(最高层):
职工
1
考勤卡
工资处理 工资单
工资文件
工资处理详细数据流图:工资文件
工资固定信息
考勤卡 考勤信息 输入基本
考勤数据
情况
处理
职工
考勤文件
计算工资
结果
输出工资单
工资单
82. 车间填写领料单给仓库要求领料,库长根据用料计划审批领料单,未批准的退回车间,已批准的领料单送到
仓库保管员处,由他查阅库存帐。若帐上有货则通知车间前来领料,否则将缺货通知采购人员。绘制系统数据流图。
答:
未批准的领料
领料单
车间
用料计划
审批领料单
领 已
料 批
单 准
领料通知 缺货通知
采购员
查阅库存帐
库存账
83. 由需购置设备的部门填写申购表格,将此表格送交设备科,设备科填写预算表格送财务处,财务处核对后,
将资金返回设备科,设备科利用资金购买设备,购得设备送需购设备的部门,将收据送财务处。绘制系统数据流图。
答:
设备
供货
单位
设备购
设备预
置部门 申购 算处理
表格 预
算 采购处理
表
格
资金计划
收据
财务核
财务处
对处理
84. 简述系统测试原则。
答:
(1)由程序设计者之外的人员进行测试
(2)测试用例应由两部分组成:输入数据和预期输出结果(3)选用不合理的输入数据与非法输入测试
(4)不仅要检验程序是否实现预期功能,还要检查程序是否做了不该做的工作
(5)集中测试容易出错的模块
(6)对程序修改后,必须重新进行测试
85. 根据以下业务过程画出领料业务流程图:车间填写领料单给仓库要求领料,库长根据用料计划审批领料单,
未批准的退回车间,已批准的领料单被送到仓库保管员处,由他查阅库存帐。若帐上有货则通知车间前来领料,否
则将缺货通知采购人员。
答:
未批准的
用料计划
领料单
车间 领料单 库长
领料 已批准的
通知单 领料单
仓库
缺货 保管员
通知单
采购员 库存帐
86. 某图书馆外文采购室有两个组:订书组和验收、登记组,分别负责书籍订购和进书验收业务。订书组的主要
业务是根据供书单位的订书目录选择要订的图书,且以前订过的图书不再订购,最后打印订单,每月将订书情况进
行统计,统计结果交图书馆领导。验收、登记组的业务是根据供书单位提供的发票和图书及订单验收已到图书,并
进行进书查重检查,如果某些图书已进,就转让出去或作别的处理,对不重的书登图书总帐,将书转到编目室,每
月进行统计,上报馆领导。请根据上述描述,画出组织结构图、业务流程图、数据流程图。
答:组织结构图:
外文采购室
订书组 验收、登记组
业务流程图:发票
订书目录 图书清单
采购 验收 财务人
供货单
员
订单 订单留底 已进书卡 图书总帐
采购统 编目 进书统
进书统计
馆领
订书统计
导
数据流程图:
订单
订书目录 订单查看
供书 初步订书清单
选择图书 打印订单
单位
图 订
发
书 书
票
清 信
单 息
图书清单
验收登帐 进书查看 已订及已进图
图
书
图书信息 发 交 统计信息
票 接
单
图书总帐
各种统计
财务科 编目室
87. 试述执行信息系统的特征。
答:执行信息系统是专供高层决策者使用的系统,其特点是:
(1)数据调用方便,只要按少量键即可。
(2)大量使用图表显示企业和各基层的运营情况,并对问题及时报警。
(3)操作者无需通过交互方式参与或探讨解题过程。
(4)系统开发者不涉及尚待研究的新技术,因而易于实现。
88. 试述可行性分析中“可行”的含义及可行性分析的主要内容。
答:可行性包括可能性和必要性,可行性分析的主要内容为:经济可行性,技术可行性以及管理上的可行性。
89. 简述系统分析报告中新系统逻辑模型的主要内容。答:
(1)新系统的目标图。
(2)新系统的功能图。
(3)新系统的数据流程图。
(4)新系统的数据字典。
(5)关于处理逻辑的说明。
90. 在系统实施阶段,计算机系统的实施中供货方应负责哪些内容?
答:
(1)按订货合同,供货方与用户一起开箱验收。
(2)计算机系统的安装与调试。
(3)提供系统运行的常规诊断校验系统。
(4)机器使用操作的培训。
(5)提供完整的资料、文档。
91. 简述MIS评价的主要内容。
答:
(1)对MIS功能的评价。
(2)对现有硬件和软件的评价。
(3)对MIS应用的评价。
(4)对MIS经济效益的评价。
(5)对MIS的社会效益的评价。
92. 在信息管理中,对信息进行加工处理的最基本方式有哪几种?
答:最基本的处理方式有8种,即变换、排序、核对、合并、更新、摘出、分筛(筛选)和生成。
93. 管理信息系统科学的三要素是什么?管理信息系统有什么主要特征?
答:管理信息系统科学的三要素是系统的观点、数学的方法和计算机技术。
特征:
(1)管理信息系统是以计算机为基础的以及人作为系统组成部分的人-机系统。
(2)管理信息系统是组织内部各种信息处理系统按照总体规划而建立起来的集成化系统。
(3)管理信息系统具备以数学方法为基础,以数据处理为基本功能的预测和控制能力。
94. 建立管理信息系统的经济效益应该从哪些方面去评价?间接经济效益的主要表现是什么?
答:建立管理信息系统是为组织的管理服务的,其根本目的是要创造企业的经济效益,建立管理信息系统的经
济效益应该从直接的经济效益和间接的经济效益两个方面去评价。
间接经济效益是指管理信息系统建立后辐射到组织管理和提高管理人员素质等方面的效益。
95. 在建立管理信息系统中,人才问题反映为哪两个队伍的建设?为什么说人才问题是建立管理信息系统的成败
的关键?
答:在建立管理信息系统中,人才问题反映为两个队伍的建设,一个是系统开发队伍的建设,一个是系统管理
队伍的建设。
管理信息系统作为计算机为基础的人-机系统,人的因素是非常重要的,管理信息系统发展到今天,除了技术上
的巨大促进之外,人才问题则是成败的关键。一方面系统开发人才的技术水平和负责精神对系统的建立起到了决定
性的作用。另一方面,系统管理人才的熟练管理对系统的运行起到了良好的保障。
96. 如何理解管理信息系统既是一个技术系统,又是一个社会技术系统。
答:管理信息系统全面使用计算机、网络通讯、数据库等技术,它是一个技术系统。
MIS作为一个人机系统,以组织为根基。
组织是一个社会技术系统,MIS面向组织并未组织服务的,因此管理信息系统是一个社会技术系统。
管理信息系统和组织结构之间互相影响,管理信息系统导致新的组织结构产生,而组织结构又对管理信息系统的分析、设计等产生重要影响。
97. 说明原型法的工作流程。
答:
(1) 用户提出系统要求
(2) 识别、归纳上述要求
(3) 开发一个模型/原型
(4) 评价模型
(5) 模型不可行处理
(6) 模型不满意处理
(7) 修改模型
(8) 确定模型后的处理
(9) 实际系统开发、运行、维护等
98. 代码设计应注意哪些问题?
答:代码的设计必须满足用户的需要,在结构上应当与处理的方法相一致。代码应惟一标志它所代表的事物或
属性。设计时应预留足够位置,以适应不断变化的需要。代码要系统化、标准化。代码要易于理解。尽量避免误解,
不使用易于混淆的字符。尽量采用不容易出错的代码结构。长代码应分段。
99. 简述模块独立程度的度量标准。
答:模块独立程度可以由两个定性标准度量,分别称为块间联系和块内联系。块间联系是度量不同模块彼此间
互相依赖(联结)的紧密程度,块内联系则是衡量一个模块内部的各个部分彼此结合的紧密程度。
(1) 块间耦合(coupling)
块间耦合是一个系统内不同模块之间互连程度的度量。块间耦合强弱取决于模块间联系形式及接口的复杂程度。
模块间接口的复杂性越高,说明耦合的程度也越高。
块间耦合程度直接影响系统的可读性、可维护性及可修改性。在系统设计中,应尽可能追求块间耦合松散的系
统。在这样的系统中,可以研究、测试、维护任何一个模块,而不需要对其他模块有很多了解。同时,由于模块间
耦合简单,错误传播的可能性就越小。
(2) 块内联系(cohesion)
模块内部元素的联系方式即为块内联系,有时也称为模块内部的紧凑性或关联度或内聚度,它是决定系统结构
的另一个重要因素。
所谓模块内部的元素是指该模块的程序中的一条或若干条的指令。系统中的每个模块应具有高度的块内联系,
它的各个元素都是彼此相关的,是为完成一个共同的功能而结合在一起的。模块设计中应尽力避免较低的块内联系,
这是基本原则。
100. 选用 “事务分析”,由下面的数据流程图导出控制结构图。
L E
B
A C F H
IIII M O
D
G
N
答:XX系统
A A E、F、G E、F、G
输入 A 变换控制 输出 E、F、G
B
G E、F、G
H
C F H
E D
L M N O 输出H
