 夜雨聆风
夜雨聆风





单细胞转录组入门:从课程到工具的全流程干货
单细胞转录组测序(scRNA-seq)是解析细胞异质性的核心技术,能够帮助我们在单个细胞水平理解基因表达差异。对于刚入门的研究者来说,最有效的学习路径是:找对系统课程、掌握核心工具、练习真实数据。下面,我为大家梳理一套从理论到实战的全流程学习资源与工具,希望能帮助你顺利起步。
一、系统学习:从原理到代码的必学课程
打好理论基础是第一步。我推荐先从以下两门经典课程入手,它们分别侧重“知识框架构建”和“工具实战应用”。
1. 剑桥桑格研究所单细胞课程
https://www.singlecellcourse.org/index.html
这门课程被许多人称为“保姆级”入门教程,它系统性地覆盖了scRNA-seq的全部分析流程。课程从最基础的原理讲起,逐步深入到数据预处理、降维聚类、细胞注释和数据整合等高级主题,共包含11个模块。它的最大优点是手把手教学。课程基于R/Bioconductor生态,专门教你使用SingleCellExperiment这一核心数据结构。第八章还详细对比并讲解了当前主流的Seurat分析流程。即使你完全没有编程基础,也能跟着课程搭建起完整的知识框架。此外,课程网站提供了配套的公开数据集和所有R代码脚本,真正做到“学完即能上手操作”。
2. Seurat官方教程
https://satijalab.org/seurat/index.html
Seurat是scRNA-seq分析领域使用最广泛的R工具包。其官方教程是绝佳的实战练兵场。教程以经典的“2700个PBMC(外周血单个核细胞)数据集”为例,一步步演示了质量控制、高可变基因筛选、主成分分析、细胞聚类和标记基因鉴定等标准流程。随着技术发展,Seurat教程也涵盖了多模态数据整合,例如将单细胞数据与空间转录组数据结合分析。对于新手,网站提供的“常用命令速查表”非常实用,你可以随时查阅,无需死记硬背代码。
二、实战资源:数据与细胞注释“神器”
学完理论后,我们需要用真实数据巩固技能。下面这些资源能帮你解决“数据从哪来”和“细胞是什么”两大核心难题。
1. 公开数据集宝库:Hemberg Lab 数据库
https://hemberg-lab.github.io/scRNA.seq.datasets/
当你苦于没有合适的练习数据时,这个数据库就是你的救星。它系统地收集了已发表的scRNA-seq数据集,并按物种(人、小鼠等)和组织(大脑、肝脏、胰腺等)进行了分类。例如,你可以轻松找到“Camp”数据集,它来源于人脑类器官研究。每个数据集都提供了原始数据编号、实验方法和预处理说明,很多数据甚至直接提供了SCESet或SingleCellExperiment 格式的文件,为你省去了繁琐的数据下载与格式转换步骤。
2. 细胞类型鉴定权威参考库
对细胞进行聚类后,最关键的一步就是鉴定每个细胞群的身份。这时,你需要查询经典的细胞标记基因。我强烈推荐以下两个经过社区验证的数据库:
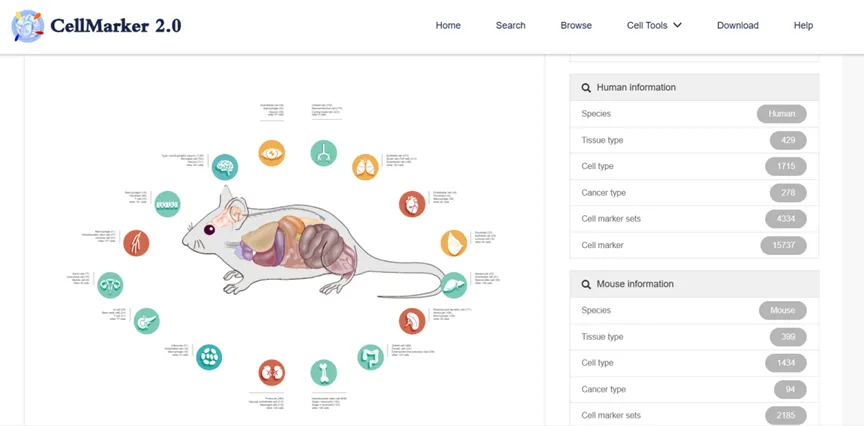
CellMarker 2.0
这个数据库收录了极为全面的信息,涵盖人和小鼠的超过1000种细胞类型和1.5万个标记基因。你可以通过“组织-细胞类型”的层级结构进行精准搜索。比如,你想鉴定大脑中的星形胶质细胞,直接搜索即可获得相关的高置信度标记基因列表。
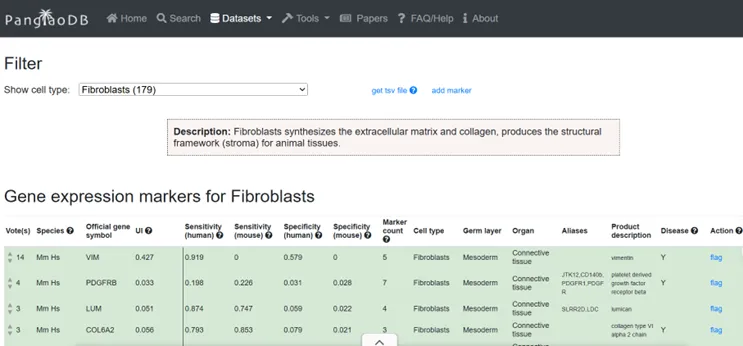
PanglaoDB
该数据库的特点是专注于高质量、高特异性的标记基因。它对收录的每个基因都进行了评估,并标注了其在特定细胞类型中的表达灵敏度和特异性。例如,当你查询成纤维细胞的标记时,它会突出显示VIM、PDGFRB这类经过广泛验证的经典基因,帮助你做出更可靠的判断。
除此之外我还整理出了常用的单细胞资源工具
10x官网:
https://www.10xgenomics.com/;
codeocean
https://codeocean.com/;
Cell Taxonomy
https://ngdc.cncb.ac.cn/celltaxonomy/ ;
CellMiner https://discover.nci.nih.gov/cellminer/home.do
希望这份梳理后的指南能为你照亮入门之路。单细胞分析是一个快速发展的领域,保持学习与实践是最好的方法。如果在具体操作中遇到问题,多查阅官方文档和社区论坛,你一定会渐入佳境。祝你在单细胞的世界里探索愉快!
图文|马采薇
排版|郑然希
审稿|袁峥嵘
