 夜雨聆风
夜雨聆风





从 0 开始实现高效 AI 写作助手 – Day 4:硬核拆解 RAG,让 AI 拥有“过目不忘”的记忆力
导语:在上一篇文章,
Day3
公众号:徒手搓AI从 0 开始实现高效 AI 写作助手 – Day 3:拒绝一键生成,网文 AI 的三大终极形态
我们达成了共识:拒绝粗暴的一键生成,而是打造“全态护航”的 AI 助手。
可能很多懂行的朋友会立刻在心中抛出了一个极其尖锐的问题:就算我在「织梦引擎」里把世界观、人物性格设定得再详细,大模型的“上下文窗口”是有极限的。几百万字的小说,它怎么可能全都记住?每次推演剧情,难道要把几十万字的设定集全发给 AI 吗?那样不仅费用扛不住,AI 的回复速度也会慢如蜗牛,甚至会“读了后面忘了前面”。
为了让「织梦引擎 (DWE)」真正拥有“过目不忘”且极速响应的记忆力,我们必须在底层引入一项当今 AI 领域最核心的黑科技:RAG(检索增强生成)。
今天,我们就来硬核拆解 RAG 的工作机制,看看它是如何根治网文 AI“吃设定”这个绝症的。
什么是 RAG?给 AI 的“开卷考试”
RAG 的全称是 Retrieval-Augmented Generation。听起来吓人,说白了就两步:先检索(查资料),再生成(写答案)。
如果大模型是一个闭卷考试的文科生,RAG 就是允许它带着你亲手写的《设定设定集》进考场。当你要它推演剧情时,它不会全凭自己预训练的“常识”去胡编乱造,而是先翻开你的设定集,找到相关段落,再结合这些精准的前提来回答。
织梦引擎 RAG 运行全链路拆解
在 DWE 中,当你向侧边栏的“灵感副驾”提问:“基于前文,主角遇到这个反派该怎么脱身?”时,后台其实经历了两个极其精密的阶段:
第一阶段:数据准备(发生在码字之前)
当你把设定录入 DWE 的【众生相】和【森罗界】模块时,系统在后台悄悄做了这些事:
分片 (Chunking):AI 无法一口吞下整部小说。系统会把你的长篇设定切分成一个个几百字的小片段(比如把主角的背景切一段,功法切一段)。
向量化 (Embedding) 与索引:这是最神奇的一步!系统通过特定的 Embedding 模型,把这一段段纯文本,变成了数学坐标系里的“向量”(一串长长的数字),并存入向量数据库中。在 AI 的视角里:含义越相近的文本,它们在数学坐标系里的“距离”就越近。(比如“铜戒指”和“神秘法宝”的向量距离会非常贴近)。
第二阶段:智能生成(发生在你卡文提问时)
当你在编辑器里发出指令,真正的魔法开始了:
-
极速召回 (Retrieval): 系统先把你的“问题”也变成向量,然后去数据库里算距离。从几十万字的设定中,瞬间“海选”出最相关的 10 个片段(比如主角当前的功法、反派的弱点)。这种向理量相似度计算速度极快,但稍微有些“粗糙”。 -
精准重排 (Reranking): 10 个片段可能还有干扰项。为了精益求精,系统会使用更精密的 Cross-encoder 模型进行二次筛选。如果说“召回”是 HR 看简历海选,“重排”就是部门主管的严苛终面。 它会把最最核心的 3 个设定片段死死咬住。 -
增强生成 (Generation): 最后,DWE 会把这 3 个绝对准确的设定片段,连同你的问题一起,打包发给本地的大模型。大模型基于这些铁证,立刻为你推演出一段逻辑严密、绝不 OOC(角色崩坏)的剧情走向!
RAG 给”一键生成”带来的降维打击
通过这套完整的 RAG 链路,「织梦引擎」实现了真正的智能进阶:
彻底告别“吃设定”:无论是一百章前埋下的伏笔,还是只出现过一次的路人甲,只要进了向量库,AI 就能在毫秒级召回,确保前后逻辑严丝合缝。
极低的算力成本:每次发给大模型的,只有经过重排的最精华的几个片段,大大节省了 Token 消耗,哪怕是低显存的本地轻薄本,也能流畅运行。
文风与世界观的绝对对齐:AI 不再满嘴跑火车,它的每一次续写和润色,都被死死限制在你亲手构建的世界观物理法则之内。
结语&开发进度
从分片、向量化,到召回、重排和生成,RAG 补足了大模型的记忆短板,为我们的写作引擎装上了最强劲的齿轮。另外补上「织梦引擎」最新效果图:
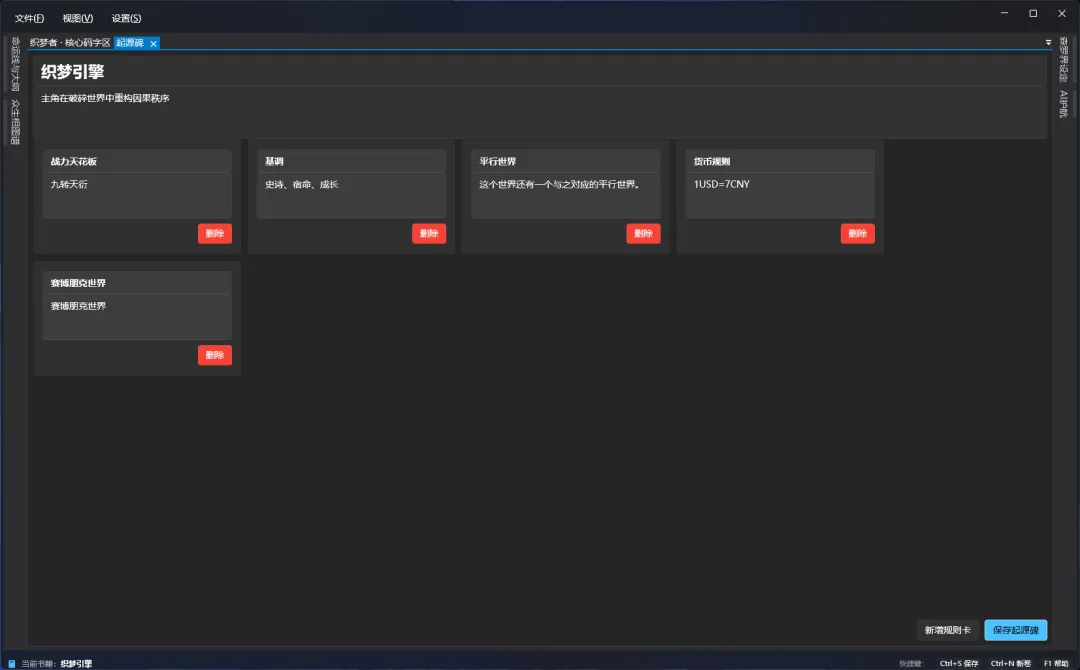
起源碑(小说世界基础设定)
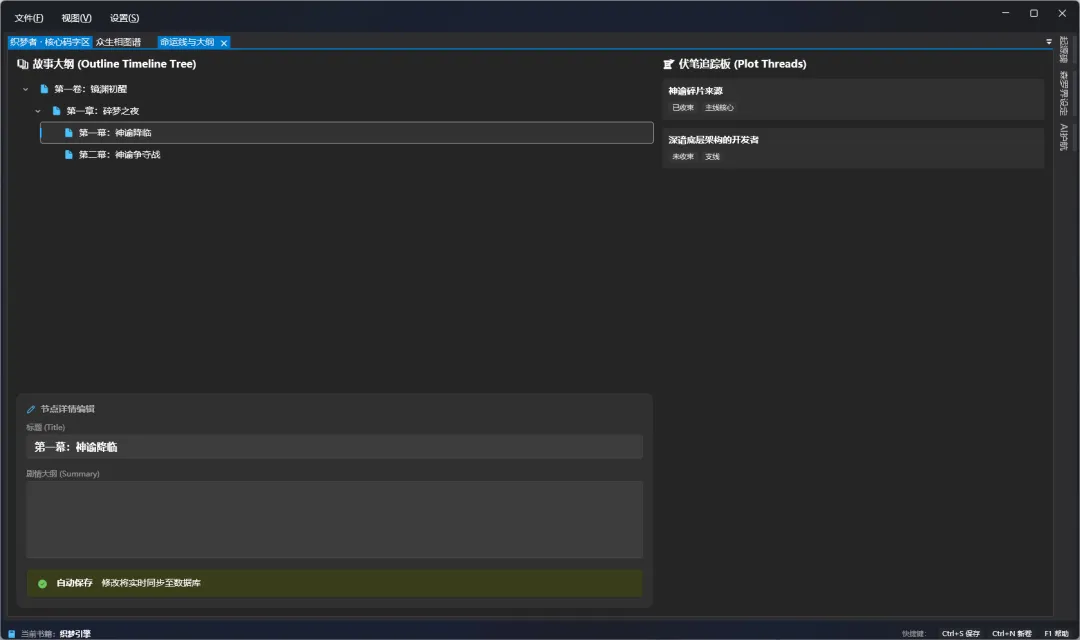
命运线与大纲
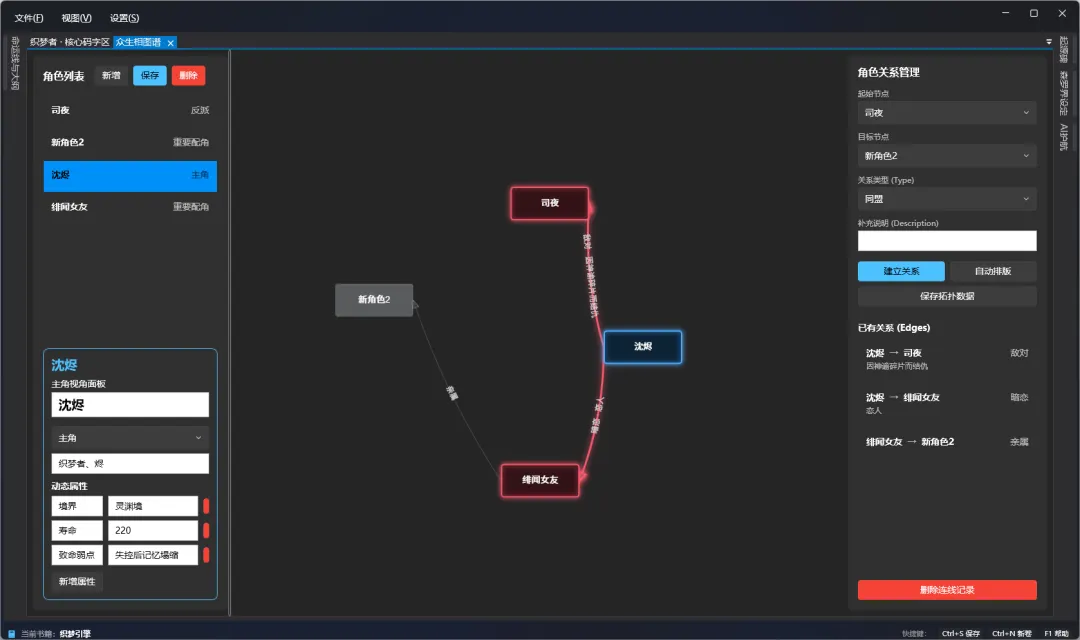
角色关系管理(众生相图谱)
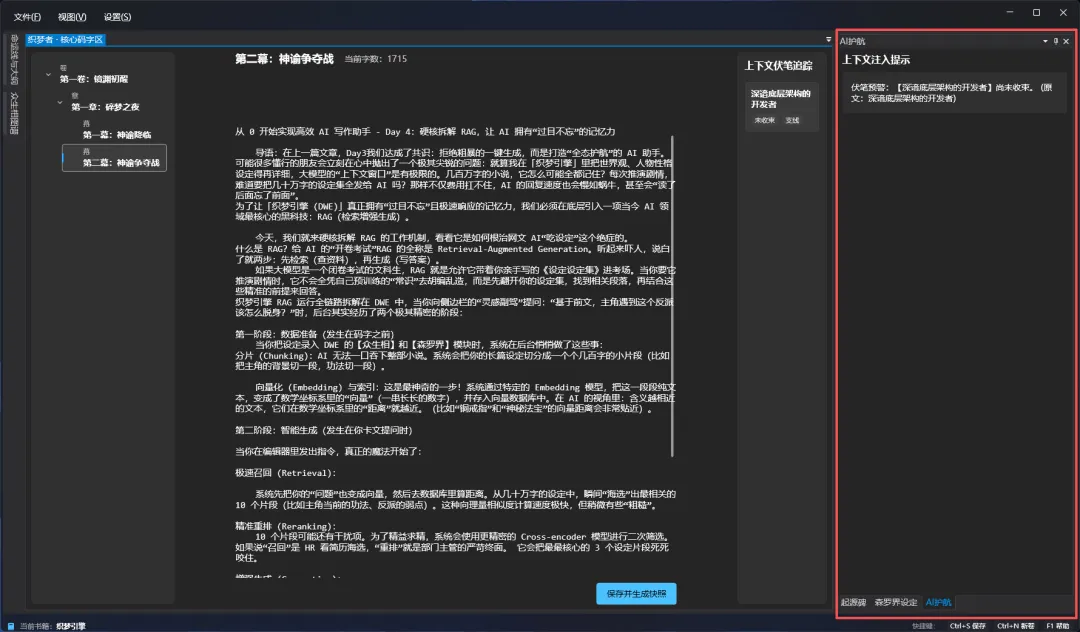
AI护航(暂未接入大模型)
森罗界(大世界详细设定)
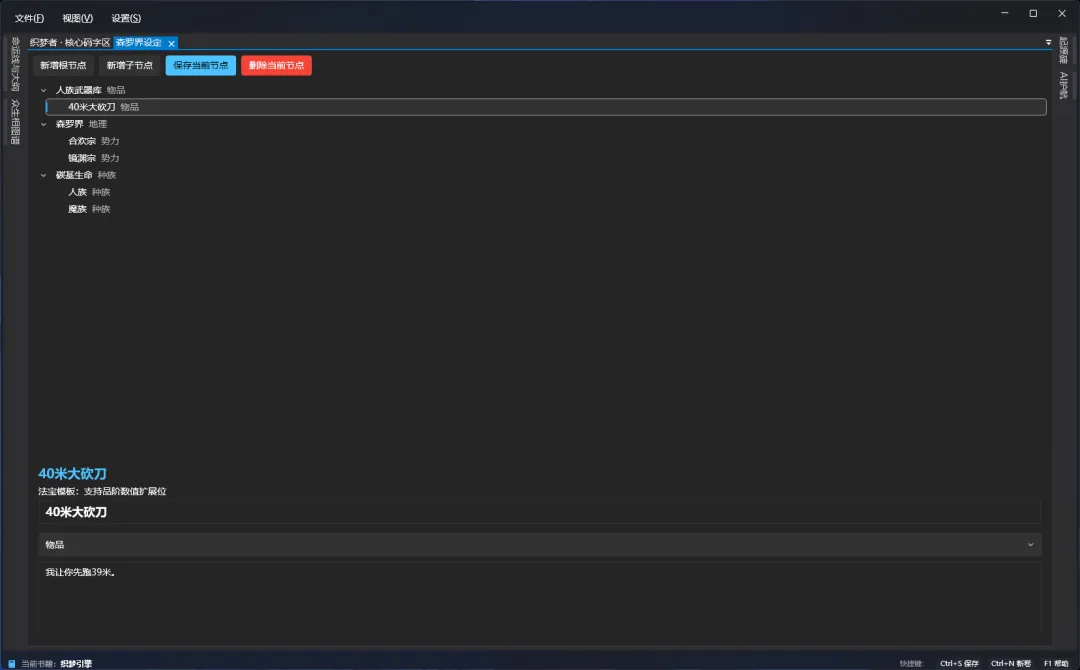
核心编辑区
主题(暗黑/明亮):
以上就是最新的开发进度,有兴趣的朋友关注我获取,希望得到大家的反馈。
(完)