 夜雨聆风
夜雨聆风





复盘:做这个 AI 测试用例设计助手,我踩过的坑和 8 个关键决策

|
🔖「AI 测试用例设计助手|LangGraph 实战系列」第 6 篇(完结篇)前 5 篇我们把核心模块都拆开讲了一遍:架构、并行、质量闭环、多模型、RAG+多模态。这一篇我想做一次“工程复盘”:哪些决策最关键、踩过哪些坑、如果重做一次我会怎么做。 |
这篇更偏经验总结,适合你在团队内部复用、也适合准备做 LLM 工作流项目的同学参考。
一、先给结论:LLM 项目能不能落地,决定因素通常不是“模型强不强”
我做完这套系统最大的感受是:模型能力只是上限,工程设计决定下限。
LLM 工作流项目常见的失败方式不是“生成不出来”,而是:
- 格式不稳:导出/落库全是补丁
- 速度太慢:用户等不下去
- 质量不可控:要么全靠运气,要么无休止重试
- 成本失控:调用量一上来就炸
- 无法迭代:每改一个点要改一堆 prompt/代码
下面 8 个决策就是我为了解决这些问题做出来的取舍。
二、关键决策 1:选 LangGraph StateGraph,而不是纯 Agent

我选择:LangGraph StateGraph
原因:
- 流程是多步骤、强依赖状态、带条件分支、还要支持并行
- 我需要显式可控的“节点 + 状态 + 路由”,而不是让 Agent 自由发散
- 质量闭环里的“阈值回流”必须硬控制,不能被模型绕过
Trade-off:
- StateGraph 前期代码量更大(你要把每个节点工程化)
- 但一旦搭好,稳定性与可维护性会明显更强
|
一句话:Agent 更像“一个人自由发挥”,StateGraph 更像“流水线工厂”。 |
三、关键决策 2:用 Send API 做动态并行,而不是固定并发
我选择:Send API 动态 Worker
原因:
- 功能点数量是运行时才确定的,无法预先写死 N 个节点
- 并行是提速最有效的方式之一:功能点越多,提速越明显
Trade-off:
- 并行带来状态合并复杂度(下面的 reducer 坑就是这么来的)
- 但收益巨大:实测 3-5x 提速,用户体验提升明显
四、关键决策 3:双层状态设计(Global State + Worker State)
我选择:全局状态 + Worker 独立上下文
原因:
- Worker 并行时必须隔离上下文,否则容易互相污染
- 全局状态用来承载“跨节点共享的数据”,Worker 状态只关心“单功能点任务”
Trade-off:
- 状态模型定义更复杂,要想清楚每个字段属于哪一层
- 但换来的是并行可控、逻辑清晰、便于调试与扩展
五、关键决策 4:自定义 reducer,解决“并行追加 + 清空重试”的冲突
我选择:自定义 reducer(add_or_reset_cases)
原因:
- 默认列表合并(operator.add)只会追加,无法表达“清空”
- 质量回流重试时需要先清空 raw_cases,再接收新一轮输出
我踩过的坑:
- 以为把 raw_cases 设为 [] 就是清空
- 实际上在 reducer 合并语义下,“空列表”可能只是“什么都不加”,旧数据还在
Trade-off:
- 自定义 reducer 需要一些实现成本
- 但这是并行系统的地基,没它重试必出问题
六、关键决策 5:质量控制用“阈值 + 回流”,而不是让模型自我判断
我选择:硬编码阈值回流(QUALITY_THRESHOLD=0.85)
原因:
- “让模型自评是否合格”非常不可靠,也很容易被 prompt 绕过
- 质量闭环必须工程化成明确规则:score 不够就回流,且最多重试 3 次
Trade-off:
- 阈值需要调参,不同业务可能不一样
- 但它把质量控制从“玄学”变成“可调的工程参数”
七、关键决策 6:重试不是重跑——改进建议注入 + 温度衰减
我选择:带反馈的迭代优化
- 把
improvement_suggestions注入重试上下文 - 把上一轮用例
existing_cases作为参考(强调不要照抄) - 降低 temperature(0.5 → 0.3),让输出更收敛
原因:
- 盲目重试只会增加成本,并不能保证变好
- 质量闭环的本质是“修订”,而不是“再创作”
Trade-off:
- Prompt 设计更复杂
- 但重试次数更少、收敛更快、输出更稳定
八、关键决策 7:多模型协同——把算力用在最值钱的节点上
我选择:按节点分配模型
- 需求解析/拆分/评审:用强模型
- 批量生成:用性价比模型
- 去重:用轻模型
原因:
- 成本主要来自“高频调用节点”(generate_cases)
- 效果上限主要来自“方向性节点”(parse/评审)
Trade-off:
- 模型调度逻辑更复杂
- 但可以做到“效果与成本同时可控”,适合生产化长期运行
九、关键决策 8:全链路结构化输出(Pydantic)+ 容错兜底
我选择:Pydantic + with_structured_output()
原因:
- 只要产物要导出 Excel/XMind、要做追溯矩阵,你就必须要稳定结构
- 结构化输出让每个节点都像一个“后端接口”,可测试、可观测、可复用
我做的兜底:
- 模型直接返回数组时,自动包装成
{cases: [...]}(model_validator) - 字段类型漂移(str ↔ list)时,模型层允许、导出层统一规范化
Trade-off:
- 前期要花时间定义数据模型与校验逻辑
- 但后期你会省下大量“解析补丁”的时间
十、我踩过的 6 个坑(如果你要做类似项目,建议直接收藏)

坑 1:把“生成”当成终点
没有评审与回流,输出就是不稳定的。
坑 2:把“并行”当成纯性能优化
并行会直接改变状态合并语义,不处理 reducer 迟早出事。
坑 3:Prompt 越长越好
上下文越长越容易漂。能结构化就结构化,能摘要就摘要。
坑 4:RAG 强制每次检索
成本爆炸 + 噪声增多。正确姿势是按需检索、结果摘要后注入。
坑 5:只看单次效果,不看分布
你需要关注的是:质量 score 的分布、重试率、平均耗时、去重率。
坑 6:导出放到最后才考虑
导出格式一旦确定,反过来会推动你把数据结构做稳定。越早做越好。
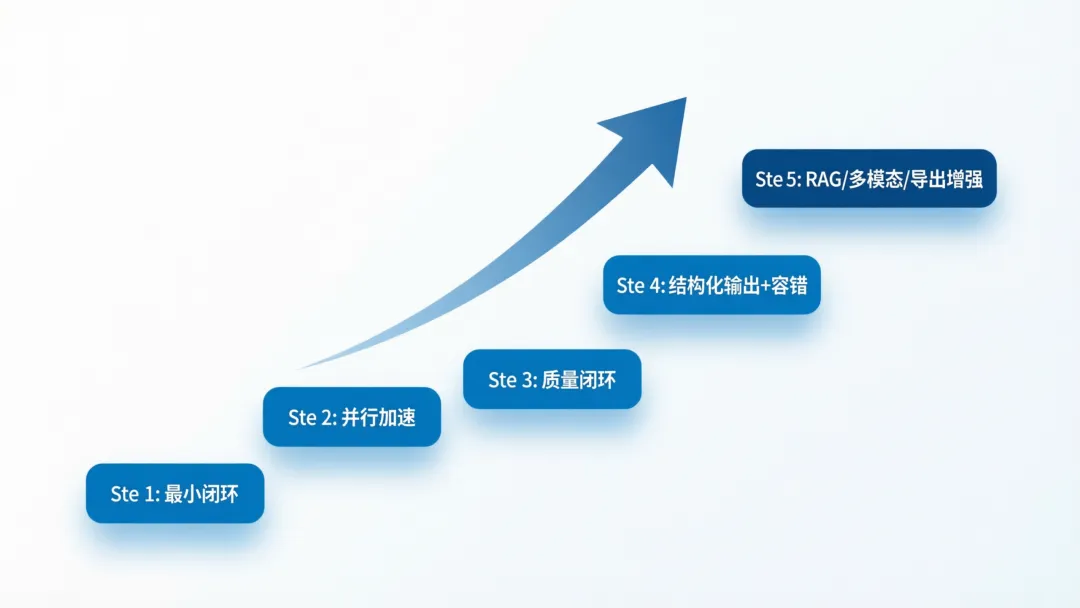
十一、如果让我从 0 再做一次,我会怎么规划(建议路线)
- 先做最小闭环:parse_requirement → generate_cases → export_json
- 再补并行:split_features + Send API
- 再补质量:quality_review + 回流
- 再补稳定:Pydantic 结构化 + 容错
- 最后再上增强:RAG / 多模态 / XMind / Excel
|
顺序很重要:先可用,再好用,最后才是“更强”。 |
十二、系列收尾:这套架构的核心价值是什么?
我对这个项目的定位一直很明确:
|
把测试设计方法论工程化成可复现、可追溯的 AI 流水线。 |
它不是为了“替代测试”,而是为了:
- 把经验固化成流程
- 把质量控制变成规则
- 把交付效率变成可度量指标
如果你在团队里推进 AI 测试落地,我建议你优先做两件事:
- 把质量闭环做出来
- 把结构化输出做扎实
剩下的(RAG、多模态、导出格式)都是可迭代增强。

完结彩蛋:你可以怎么继续扩展?
- 加“测试策略库”:按业务类型自动选择覆盖维度
- 加“接口文档解析”:自动生成接口测试用例 + 参数边界
- 加“自动化生成”:把可自动化用例直接输出到 pytest/playwright 模板
- 加“需求追溯矩阵”更细粒度:Feature → Rule → Case → Automation
如果你希望我把这套架构代码化成一套可运行的开源模板(含 Graph、节点、模型、导出器),也欢迎留言交流。