 夜雨聆风
夜雨聆风





微软悄悄开源一个Python库,PDF/Word/Excel/PPT一行代码全变Markdown!9万星炸了
【导读】微软开源了一个叫MarkItDown的Python库,号称能把PDF、Word、Excel、PPT、图片、音频、网页等十几种格式,一行命令转成Markdown。GitHub狂揽9.3万星,推特上有人直接喊出「任何文档都能转」。但真相没那么简单——图片转文本要OpenAI的key,装不全依赖就「哑火」,官方自己都说这工具「不是给人看的」。
一行代码,通吃所有文档?
4月7日,推特博主@mdancho84发了一条帖子,开头就是大写的「BREAKING」:
“Microsoft launches a free Python library that converts ANY document to Markdown.”
「微软推出免费Python库,能把任何文档转成Markdown。」
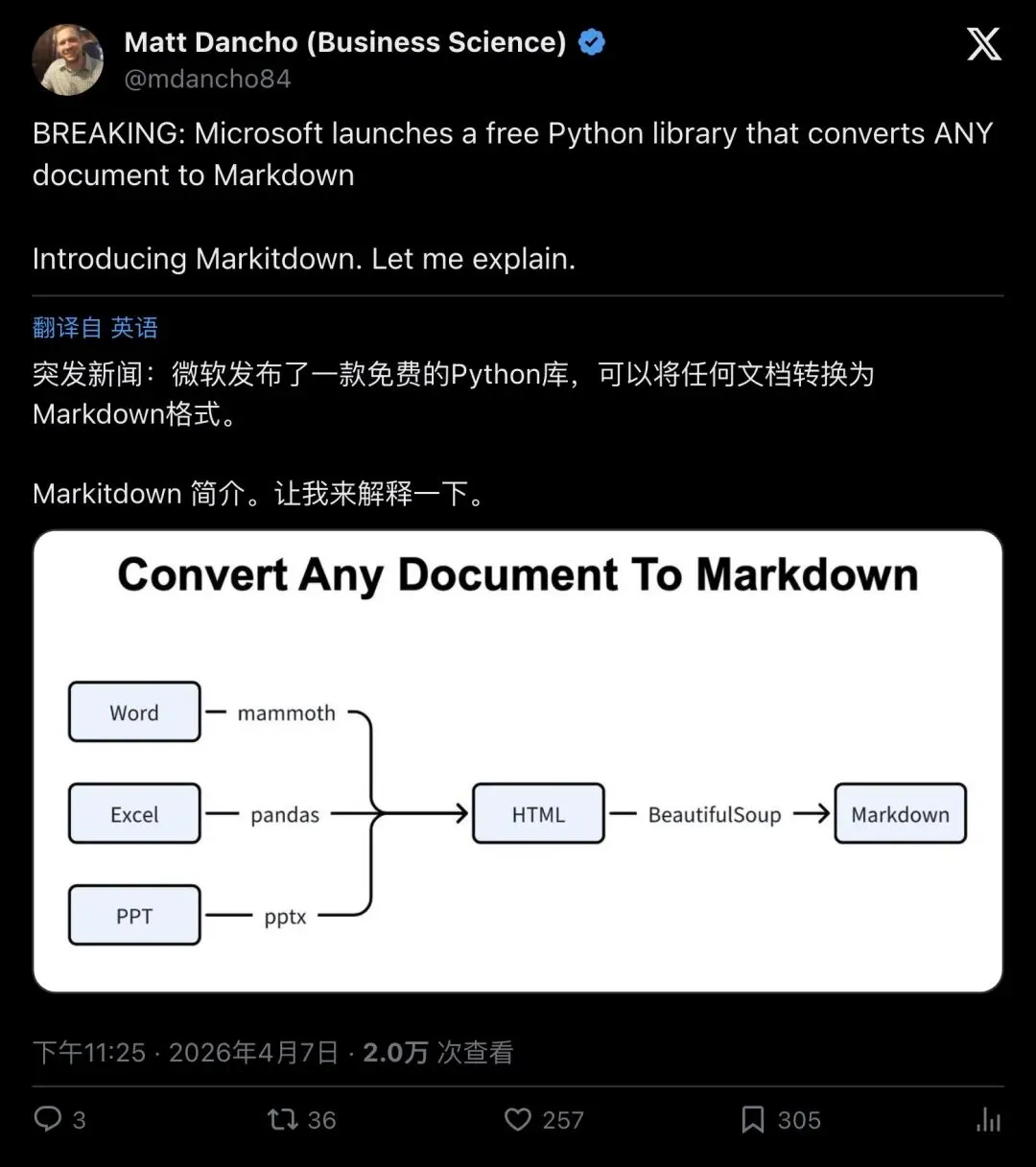
▲ @mdancho84 推文主帖,2万+浏览,257赞,305收藏
帖子里还贴了一张架构图:Word走mammoth,Excel走pandas,PPT走pptx,最终汇入HTML,再经BeautifulSoup洗成Markdown。清清楚楚,一条流水线。
这条推文迅速炸开。评论区有人说「马上加进我的Agent武器库」,有人当场转发收藏。
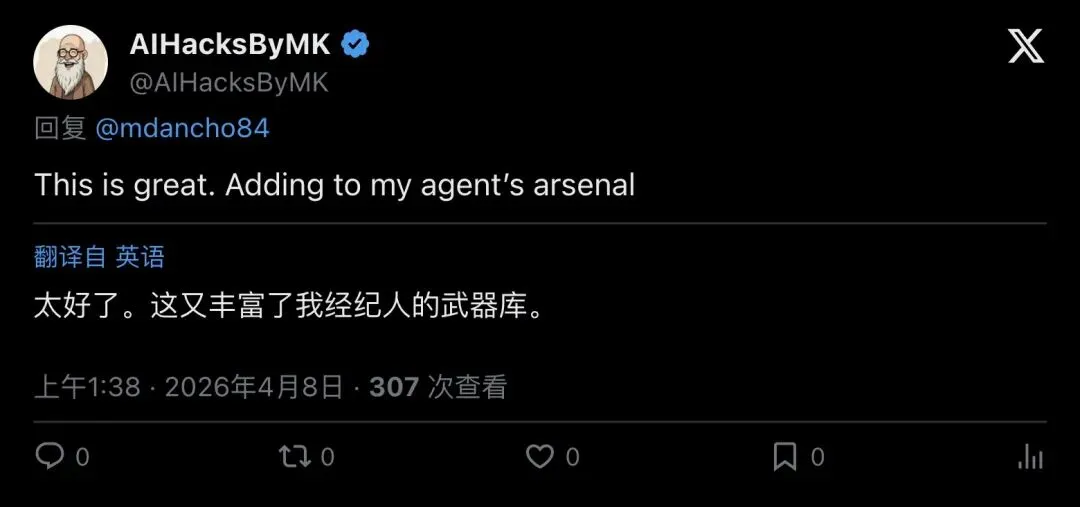
▲ @AIHacksByMK:「太好了,又丰富了我Agent的武器库。」
但且慢——「ANY document」这四个字,微软自己可没说过。
GitHub 9.3万星,微软到底做了什么?
打开微软官方仓库 microsoft/markitdown,README的定位写得很克制:
“MarkItDown is a lightweight Python utility for converting various files to Markdown for use with LLMs and related text analysis pipelines.”
「一个轻量级Python工具,把多种文件转换为Markdown,服务于LLM和文本分析流程。」
▲ GitHub仓库:9.35万星、5.7千Fork、MIT开源协议
注意用词:various files(多种文件),不是any document(任何文档)。
这个差距,就是传播口径和工程事实之间的鸿沟。
但即便如此,它支持的格式清单依然让人倒吸一口凉气:

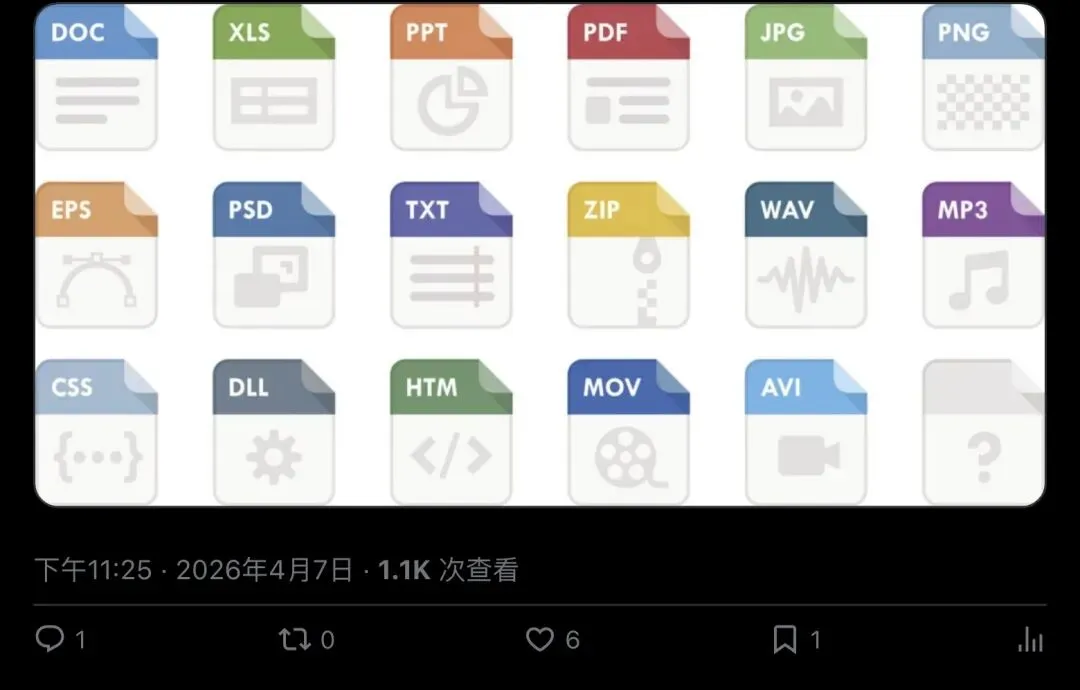
▲ 支持格式一览:PDF、PPT、Word、Excel、图片、音频、HTML、CSV/JSON/XML、ZIP、YouTube、EPub……
PDF、PowerPoint、Word、Excel、图片(EXIF+OCR)、音频(语音转写)、HTML、CSV/JSON/XML、ZIP压缩包、YouTube视频链接、EPub电子书——几乎覆盖了你日常能碰到的所有文件类型。
用起来有多简单?命令行一句话:
“` markitdown path-to-file.pdf > document.md “`
Python代码四行搞定:
“`python from markitdown import MarkItDown md = MarkItDown() result = md.convert(“test.xlsx”) print(result.text_content) “`
四行代码的魔力:Word秒变纯文本,Excel直出表格
推特线程里,@mdancho84做了现场演示。
Word文档转换:一个包含标题「MarkItDown Sample」和正文「Can you read my heart?」的docx文件,四行代码,输出干净的Markdown文本。
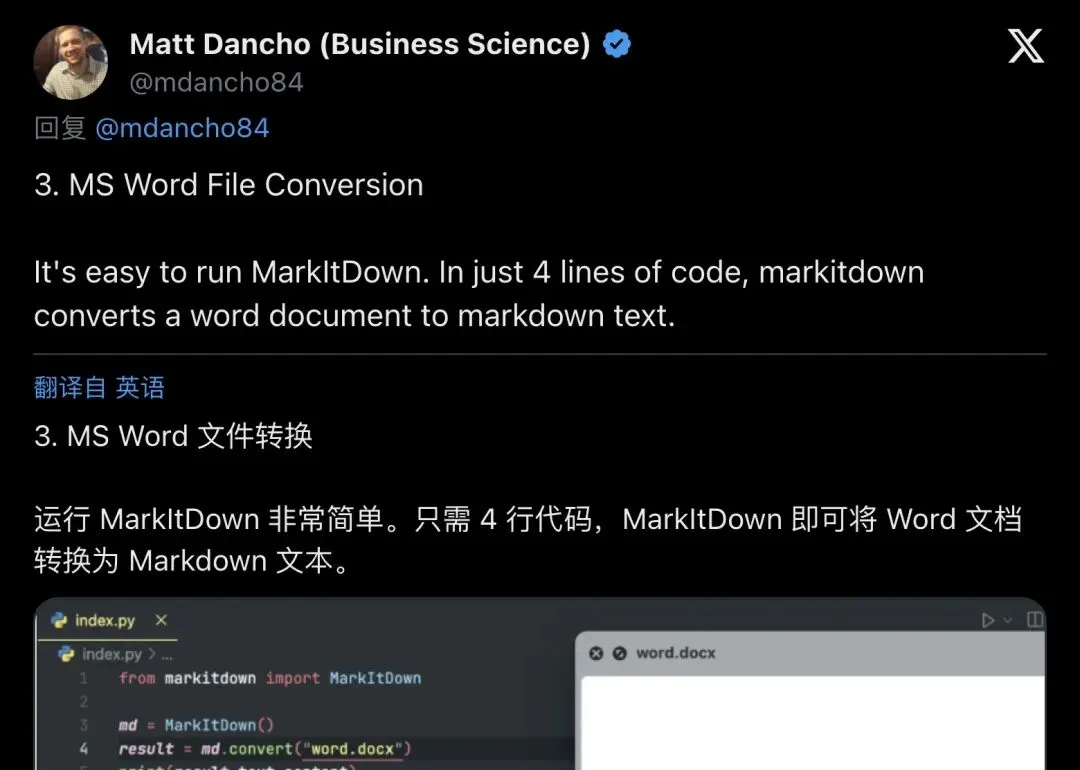
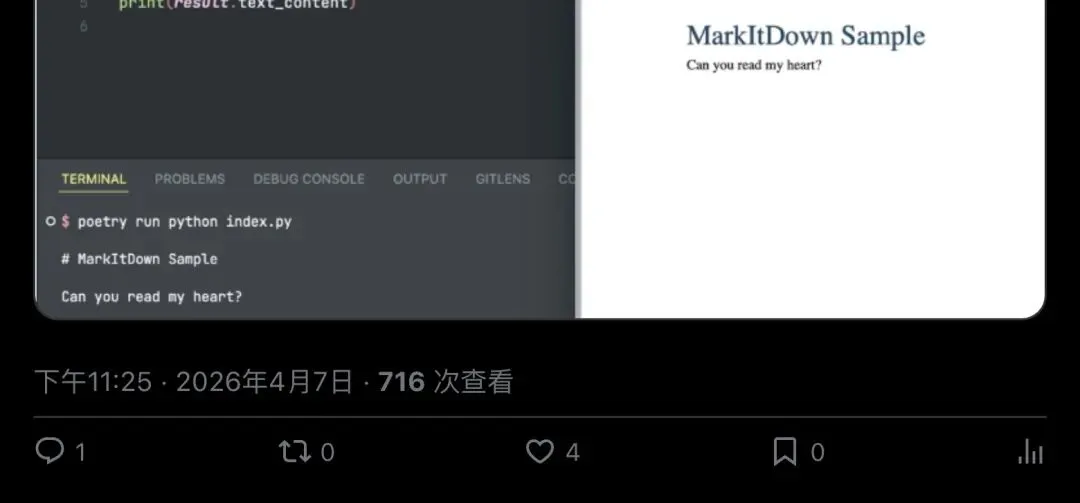
▲ Word文档→Markdown:四行代码,结构完整保留
Excel文件转换:同样四行代码,但这次返回的是一个Markdown表格——Sheet名、行列数据,全部结构化输出。
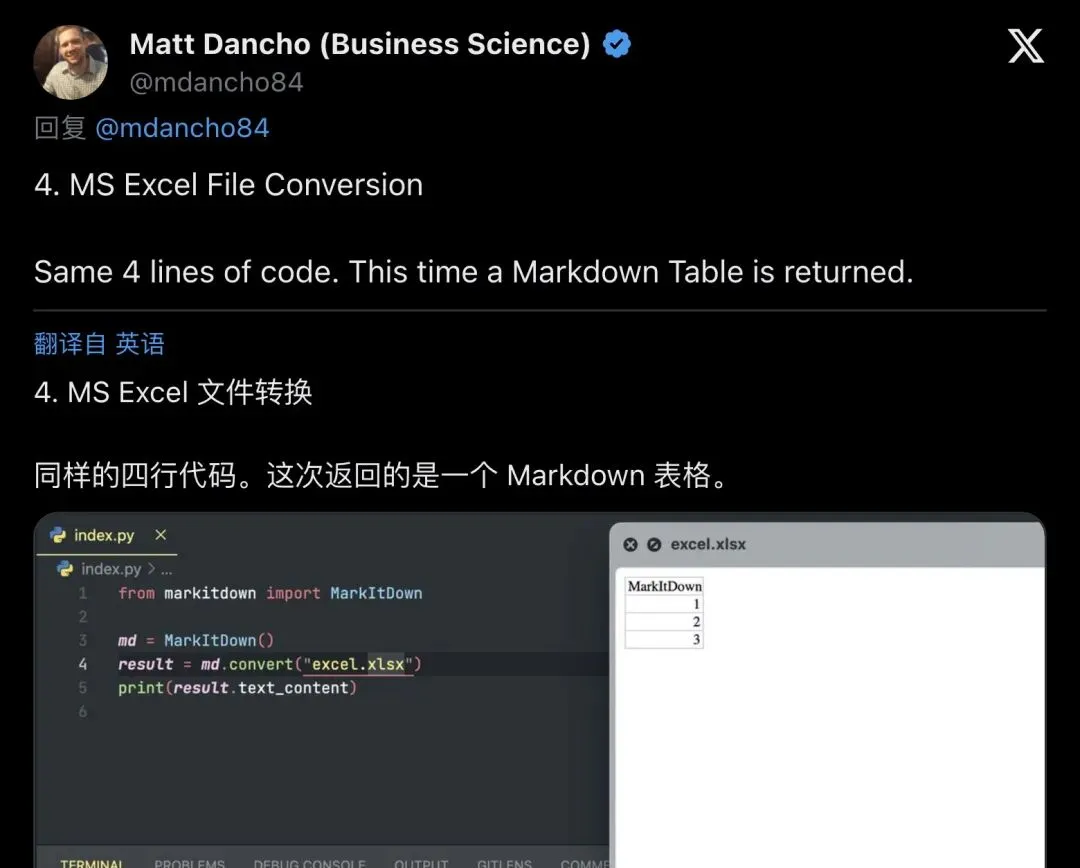
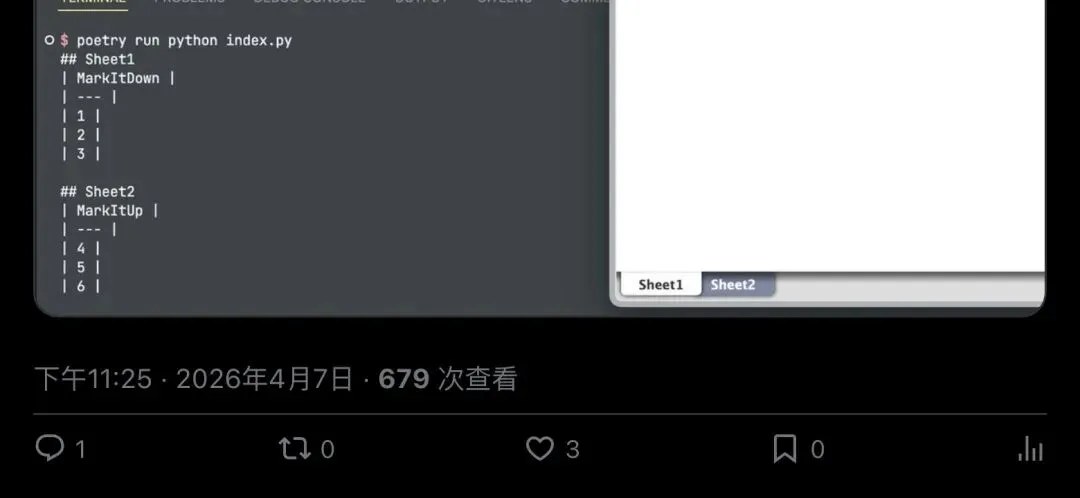
▲ Excel→Markdown表格:多Sheet支持,数据结构清晰
这两个演示看起来赏心悦目。但真正的「暗雷」,藏在下一张截图里。
图片转文本?可以,但你得交「过路费」
线程第五条,@mdancho84话锋一转:
“Note – This requires OpenAI API key to use an LLM to produce the image description.”
「注意——图片转文本需要OpenAI API密钥,用LLM来生成图像描述。」
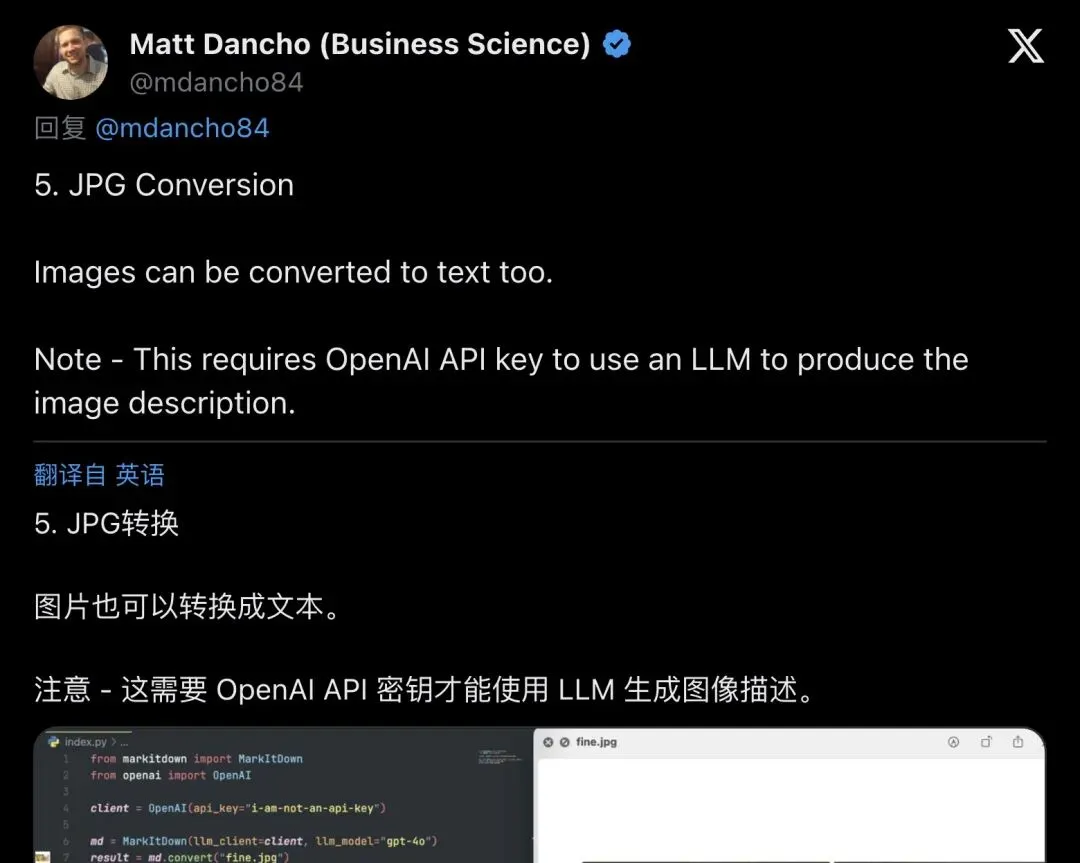
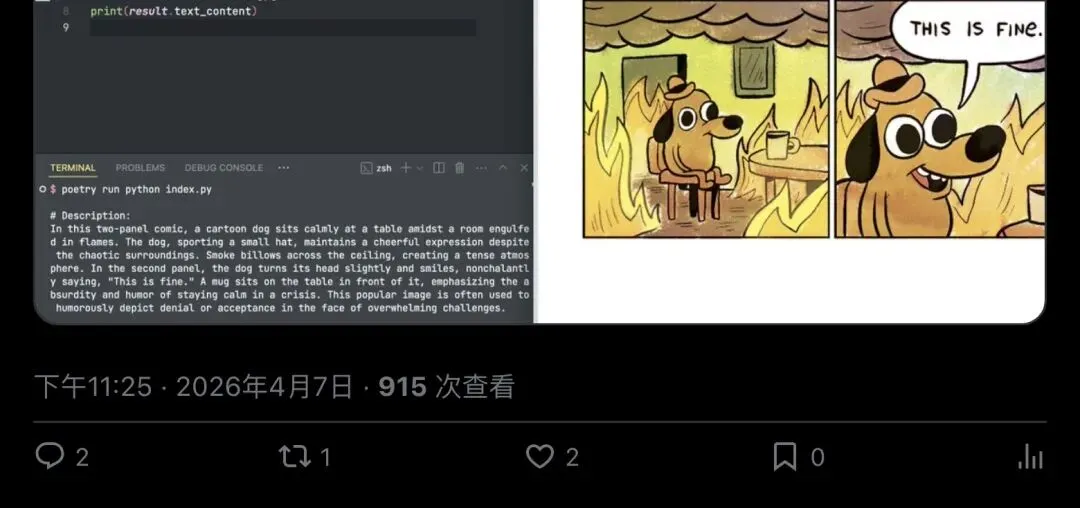
▲ 图片转文字演示:经典meme「This is fine」被LLM精准描述——但需要OpenAI API key
代码里赫然写着 `client = OpenAI(api_key=”your-api-key”)`。也就是说,MarkItDown的图片能力,本质上是把活儿外包给了OpenAI的视觉模型。
这意味着什么?成本、隐私、延迟,三座大山一起压过来。
企业里有大量扫描件、截图、照片需要转文本。如果每张图都要调一次OpenAI API,那账单可能比雇个人工录入员还贵。更别说——你愿意把公司内部文件传给OpenAI的服务器吗?
README里也坦白了:项目还提供了一个 `markitdown-ocr` 插件,用LLM Vision做OCR。听起来很美,但每一步都在烧token。
装不全依赖,工具直接「哑火」
这可能是整个项目最反直觉的一点。
MarkItDown的PyPI页面显示,它的基础依赖只有beautifulsoup4、charset-normalizer等几个轻量包。但想要真正「通吃」所有格式,你得手动安装一堆可选依赖组:
▲ PyPI页面:最新版0.1.5,2026年2月发布
-
`[pdf]`:需要pdfminer-six + pdfplumber -
`[docx]`:需要lxml + mammoth -
`[pptx]`:需要python-pptx -
`[xlsx]`:需要openpyxl + pandas -
`[audio-transcription]`:需要pydub + speechrecognition -
`[youtube-transcription]`:需要youtube-transcript-api
同一个工具,在你和同事的机器上,表现可能完全不同。原因不是什么玄学bug,就是依赖组没装全。
官方推荐的「懒人方案」是 `pip install ‘markitdown[all]’`,一次性把所有extras装上。但在企业环境里,「装一切」往往意味着更大的镜像体积、更多的供应链风险。
Hacker News的冷水:「这玩意儿2024年就有了」
推特上的传播看起来像「微软刚发布的新工具」,但Hacker News的老哥们早就见过了。
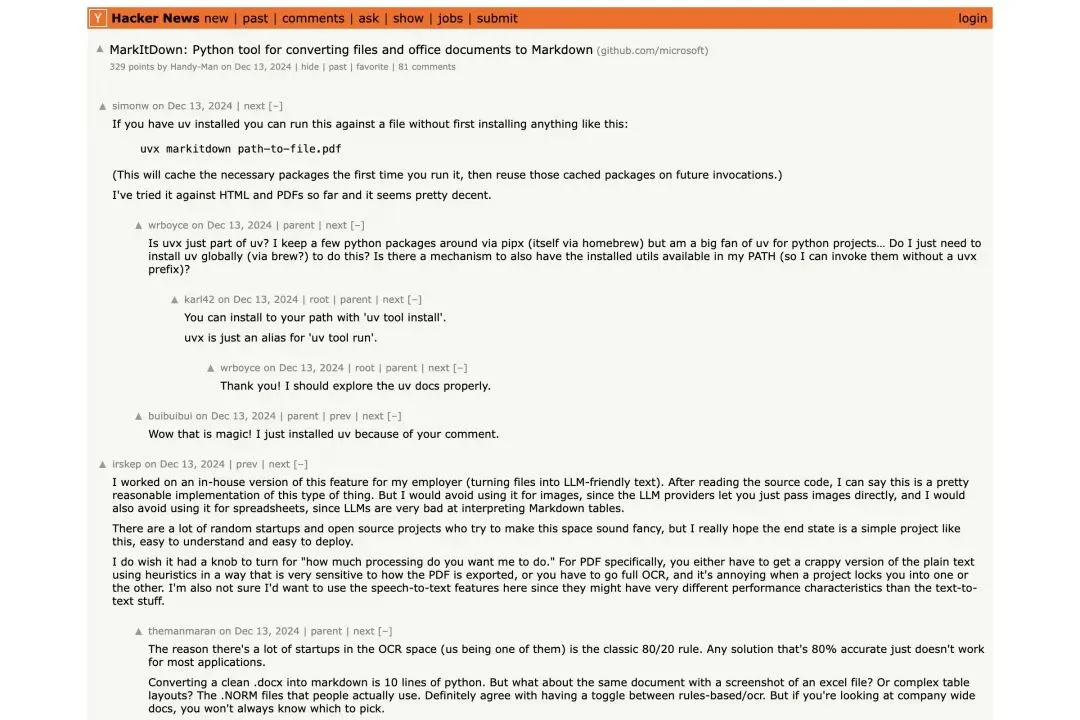
▲ HN讨论帖:329分,81条评论,2024年12月就已热议
2024年12月,HN上就出现了标题为「MarkItDown: Python tool for converting files and office documents to Markdown」的热帖,329分、81条评论。
社区里的讨论相当务实:
用户simonw分享了一个零安装技巧:如果你装了uv,直接跑 `uvx markitdown path-to-file.pdf`,连pip install都省了。
用户irskep说自己公司内部做过类似的「文件→LLM文本」方案,看了MarkItDown源码觉得「实现合理」,但也泼了冷水:不建议用它转图片(LLM直接看图更好),也不建议用Markdown表格喂电子表格数据(LLM对表格的理解本来就差)。
还有人拿它跟Pandoc比——Pandoc是文档格式转换的「瑞士军刀」,但对PPT、Excel这类Office全家桶覆盖不足。MarkItDown的差异化在于:它从一开始就是为LLM设计的,目标是「机器能读懂」,而非「人能看舒服」。
README自己也说了大实话:
“While the output is often reasonably presentable and human-friendly, it is meant to be consumed by text analysis tools — and may not be the best option for high-fidelity document conversions for human consumption.”
「输出结果通常还算能看,但它是给文本分析工具用的——如果你想要高保真的人类可读转换,它可能不是最佳选择。」
MCP Server:从命令行工具到Agent「文档大脑」
整个项目里,最容易被忽略、但可能最有杀伤力的功能是这个:
README里有一个TIP框:
“MarkItDown now offers an MCP server for integration with LLM applications like Claude Desktop.”
「MarkItDown现在提供MCP Server,可以集成到Claude Desktop等LLM应用中。」
MCP(Model Context Protocol,模型上下文协议)是当前AI Agent生态里最火的「插件标准」之一。有了MCP Server,MarkItDown就不再只是一个你得自己写脚本调用的命令行工具——它变成了一个可以被任何Agent框架自动调用的「文档摄取服务」。
想象一下:你在Claude Desktop里丢进去一份PDF合同、一个Excel预算表、一套PPT方案,Agent自动调用MarkItDown把它们全部转成Markdown,然后开始回答你的问题、生成摘要、做对比分析。
这才是微软真正的野心:不只是做一个转换工具,而是占据AI Agent工具链的最上游——数据摄取层。
真正该关心的问题
MarkItDown解决了一个实实在在的痛点:大模型时代,企业里堆积如山的PDF、Office文件,就像被锁在保险柜里的金矿,LLM看不见、读不懂、用不了。
这个工具把锁撬开了一条缝。
但它没解决的问题同样扎眼:转换质量因格式而异、图片/音频依赖外部API、企业落地需要配合权限控制和内容审计、「一个库」搞不定所有场景。
9.3万星的GitHub项目,MIT协议完全免费,支持十几种格式,四行代码上手。
对于正在搭建RAG系统、知识库、或Agent工具链的开发者来说,MarkItDown值得放进你的工具箱——但别指望它是银弹。
世界上从来没有「任何文档都能转」的银弹,只有越来越锋利的螺丝刀。
— END —