4月10日三篇能落地的论文-文档分析、加密流量、智能客服
文档先解析干净,告警先讲清证据,客服先少转人工:4月10日三篇能落地的论文 AI论文落地 | 2026.04.10 | MinerU2.5-Pro / mmTraffic / 腾讯元宝金融问答
今天这三篇论文,第一篇先把复杂 PDF 解析干净,别让知识库、审计和入库系统从源头就带错。第二篇让加密流量告警不再只给结论,而是顺手生成可审计的证据报告。第三篇则盯住金融客服里最常见的转人工问题,把口语化问题更稳地翻译成后端接口调用。 适合阅读:需要自动化文档处理流程的公司,安全公司,要训练金融大模型的公司; 一、12亿小模型靠数据工程打败千亿大模型,文档解析准确率登顶
论文: 《MinerU2.5-Pro:纯靠数据工程把文档解析做到天花板》
原标题: MinerU2.5-Pro: Pushing the Limits of Data-Centric Document Parsing at Scale
作者: Bin Wang 等
机构: 上海人工智能实验室(Shanghai AI Lab)、北京大学、上海交通大学、商汤科技
论文链接: https://arxiv.org/abs/2604.04771
GitHub: https://github.com/opendatalab/MinerU
第一部分:行业现状与痛点 企业每天要处理大量非结构化文档——合同、财报、发票、研报、技术手册。传统做法是人工录入或者用光学字符识别加规则提取,但遇到复杂表格、公式密集、多栏排版的文档,错误率居高不下。金融机构每年花几十万到几百万采购文档处理服务,复杂文档的解析质量依然不够用。更棘手的是,检索增强生成和企业知识库系统的质量瓶颈就卡在文档解析这一步:解析不准,后面的问答和检索全都跟着出错。 第二部分:这篇文章在做什么 想象你有一位助手,之前能认出九成文字,但碰到复杂表格和数学公式就犯难。这篇论文做的事情,是给这位助手找来更多、更难、更准确的练习题来训练他。练习题数量从不到一千万份扩大到六千五百五十万份,而且专门挑那些所有助手都做错的”难题”反复练。结果这位助手的综合成绩从92.98分涨到95.69分,超过了参数量是他两百倍的大模型。 第三部分:论文介绍 MinerU2.5-Pro 保持 MinerU2.5 的12亿参数架构完全不变,所有提升纯靠数据工程,核心有三项创新。第一是多样性-难度感知采样(Diversity-Difficulty Aware Sampling),把训练数据从不到一千万页扩充到六千五百五十万页,同时纠正数据分布偏差。第二是跨模型一致性验证(Cross-Model Consistency Verification),用多个不同架构的模型互相校验标注质量。第三是判断-优化流水线(Judge-and-Refine Pipeline),对难样本进行渲染再验证的迭代修正。训练分三个阶段:大规模预训练、难样本微调、强化学习对齐。 在 OmniDocBench v1.6 基准测试上,MinerU2.5-Pro 总分95.69,超过 GLM-OCR 的95.15和 PaddleOCR-VL-1.5 的94.87。在困难子集上以94.08领先第二名2.07分。公式识别准确率达到97.29,表格识别准确率达到93.42,阅读顺序得分0.120,均为最优。即使和 Gemini 3 Pro(92.85)、Qwen3-VL-235B(89.78)等千亿参数通用模型相比,也全面领先。 第四部分:生产力重构——用在哪、怎么用 金融、法律、政务这三个行业最适合用这项技术做流程改造。 拿金融行业举例。一家券商研究所每天要处理约200份研报,现在的流程是:收到 PDF 扫描件后,人工逐页查看、手动摘录关键数据到系统,然后复核人员再审一遍,最后录入业务系统。每份研报人工录入大约30分钟,200份就是100小时。接入 MinerU 之后,文档扫描后直接自动解析为结构化的 Markdown 或 JSON 数据,人工只需做最后的复核,每份只要5分钟。每天省下大约83小时人力,按外包人力80元/小时算,每天省6600元,每月省约20万。同时,解析准确率从人工的约95%提升到95.69%,还消除了人为疲劳带来的波动。 法律行业的判决书和合同审查也是同样的逻辑:大量格式化文档需要从中提取关键条款和数据点。政务领域的公文和表单数字化同理。 产品化方向上,可以做文档解析的 API 服务,按页计费,对标 Mathpix 每页0.01美元的定价模式。也可以做企业知识库和检索增强生成的文档前处理模块,或者面向金融、法律的行业专用文档智能平台。 MinerU 嵌入文档处理流程后,替代了人工逐页录入环节,人工只需做最终复核。 第五部分:落地君推荐 落地君推荐金融、法律、政务、医疗、教育等文档密集型行业尝试这篇论文。项目在 GitHub 上已有59.1k stars,pip install 即可使用,支持 Docker 部署,单卡4GB显存就能跑,也支持纯 CPU 运行。核心优点有三个:一是12亿小模型纯靠数据工程就做到了榜首,这条技术路线可以复制到其他场景;二是部署成本极低,不需要昂贵的算力;三是社区成熟、文档齐全,上手门槛很低。 二、加密流量不再是黑盒:AI自动生成取证报告,安全分析师效率提升数倍
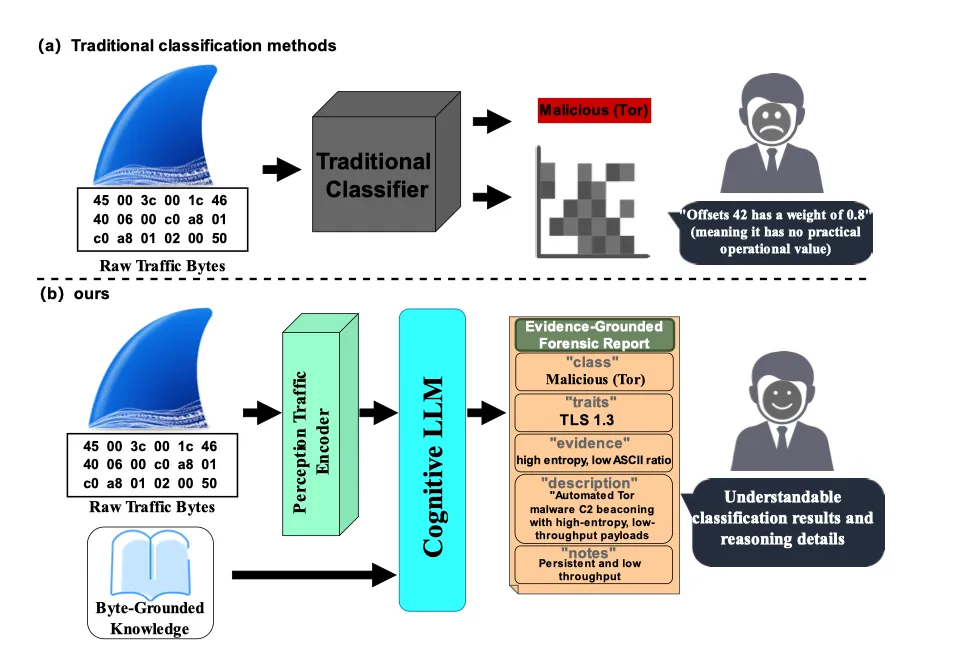
论文: 《mmTraffic:让加密流量分析从”只说结论”变成”给你看证据”》
原标题: Multimodal Reasoning with LLM for Encrypted Traffic Interpretation: A Benchmark
作者: Longgang Zhang、Xiaowei Fu、Fuxiang Huang、Lei Zhang
机构: 重庆大学微电子与通信工程学院、香港岭南大学
论文链接: https://arxiv.org/abs/2604.08140
GitHub: https://github.com/lgzhangzlg/Multimodal-Reasoning-with-LLM-for-Encrypted-Traffic-Interpretation-A-Benchmark
第一部分:行业现状与痛点 现在互联网上超过90%的流量经过加密,传统的深度包检测技术基本失效。企业花几十万甚至上百万部署下一代防火墙,但面对加密流量,安全设备只能给一个分类标签——”疑似恶意”或”正常”。安全运营中心的分析师每天面对几百条告警,最头疼的事情是没有证据链:设备说这条流量有问题,但不告诉你为什么。分析师只能手动抓包、逐条排查,每条告警要花半小时到一小时。在等保2.0和GDPR等合规要求下,光有结论没有分析过程,审计也过不了关。 第二部分:这篇文章在做什么 把加密流量分析想象成机场安检。以前的安检设备只会亮红灯绿灯,告诉你”这个包有问题”或者”没问题”,但不解释原因。mmTraffic做的事情是让安检设备在判断之后,再写一份检查报告:检测到了什么协议特征,为什么判断它是某类流量,证据在哪里。安检员拿到报告,可以直接验证和处置,不用再从头分析。 第三部分:论文介绍 mmTraffic的核心贡献有两个。第一个是构建了首个字节级有据可查的流量描述数据集,整合了6个公开数据集共31万条样本。每条样本除了分类标签,还配有行为特征描述、证据链和自然语言解释。第二个是设计了一套端到端的多模态推理框架,包含流量感知编码器和认知生成器两个模块,联合训练优化。框架采用了”语义优先引导生成”机制,模型必须先正确识别流量类别,才能输出解释文本,避免”说得流利但判断错误”的幻觉问题。实验结果显示,mmTraffic在VPN流量分类上准确率达到99.02%,与专用分类器接近;同时生成的证据报告ROUGE-L达到0.84以上,在恶意流量数据集上达到0.8853,所有输出100%符合结构化格式。 mmTraffic 多模态流量分析框架的整体架构图 第四部分:生产力重构——用在哪、怎么用 mmTraffic最直接的落地场景是网络安全运维。一个中型安全运营中心每天大概处理200条加密流量告警,分析师逐条手动排查,平均每条花45分钟。接入mmTraffic之后,系统自动对告警流量生成取证报告,分析师只需要审核报告内容,每条大概10分钟搞定。算下来每天能省约117小时的人工分析时间,相当于15个分析师一天的工作量。安全分析师年薪在30到50万之间,这笔账很容易算清楚。 电信运营商也能用。运营商需要对海量加密流量做分类管理和异常检测,mmTraffic可以嵌入现有的流量分析平台,在自动分类的同时提供可追溯的分析依据,满足监管审计要求。 企业IT安全审计是另一个方向。等保2.0要求安全事件有完整的分析记录,mmTraffic自动生成的结构化报告可以直接用于合规存档,省去分析师额外写报告的时间。 产品化方面,可以做成加密流量智能分析的私有化部署方案,或者作为模块嵌入主流的安全编排平台。代码已经在Apache-2.0协议下开源,商用门槛不高。 mmTraffic嵌入安全运维流程后,替换了原有的人工逐条分析和手动写报告环节(橙色部分为新增/替换环节) 第五部分:落地君推荐 落地君推荐网络安全、电信、金融反欺诈和政府网安监管领域的团队尝试这篇论文。代码和31万条样本数据集已在Apache-2.0协议下开源,推理只需要2张GPU,部署门槛比较低。核心优点有三个:第一,这是第一个能给加密流量”写分析报告”的AI框架,把黑盒判断变成了可解释的取证输出;第二,分类准确率接近专用模型,VPN流量达到99%以上;第三,开源协议商用友好,6个数据集覆盖场景广泛。 三、腾讯元宝背后的金融问答引擎:让AI听懂“鹅厂股价多少”
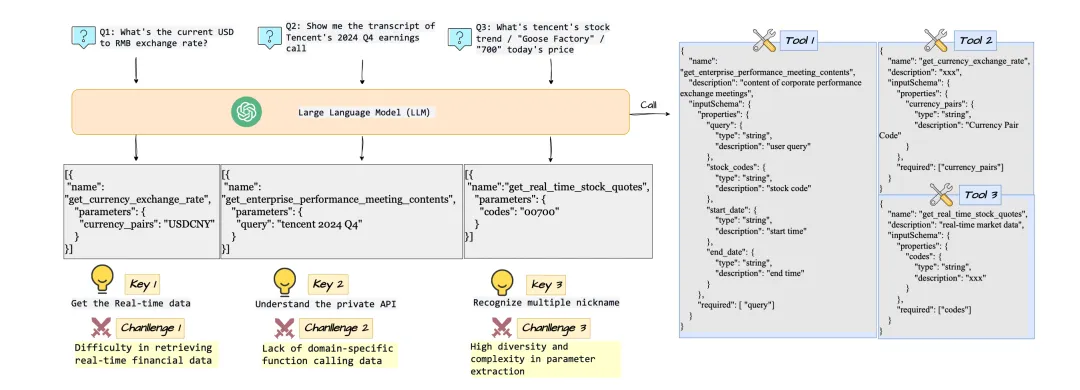
论文: 《腾讯元宝背后的金融问答引擎:让AI听懂”鹅厂股价多少”》
原标题: Data-Driven Function Calling Improvements in Large Language Model for Online Financial QA
作者: Xing Tang, Hao Chen, Shiwei Li, Fuyuan Lyu, Weijie Shi, Lingjie Li, Dugang Liu, Weihong Luo, Xiku Du, Xiuqiang He
机构: 深圳技术大学、腾讯金融科技(FiT)、华中科技大学、麦吉尔大学、香港科技大学
论文链接: https://arxiv.org/abs/2604.05387
GitHub: 暂无公开仓库(方法已在腾讯元宝生产环境部署)
第一部分:行业现状与痛点 金融行业的AI客服有一个老大难问题:用户说法太多样。同一个”查腾讯股价”的需求,有人输入港股代码”700″,有人说”鹅厂今天涨了吗”,还有人问”腾讯控股最新价多少”。AI需要把这些五花八门的说法准确翻译成后端API调用——选对接口、提对参数。通用大模型碰到金融领域的专业API和用户口语化表达,经常选错工具或提取错参数。券商和银行在搭建智能投顾和智能客服时,这个问题最让人头疼。 第二部分:这篇文章在做什么 这篇论文做的事情类似”老员工带新员工”。团队先收集线上真实用户问过的问题,找出AI答错的那些——这些就是AI的盲点。然后用大模型针对盲点自动出练习题,让AI反复训练。经过几轮迭代,AI能应对的问法越来越多。这套方法已经在腾讯元宝上线,每天处理大量金融查询。 第三部分:论文介绍 这篇论文提出了一套数据驱动的函数调用(Function Calling)优化流水线,发表于WWW 2026会议。核心创新是AugFC数据增强方法:先从线上日志中检测模型的”盲点”——那些参数提取失败率高的案例(比如”鹅厂”无法映射到”腾讯”),再用多个大模型针对盲点自动生成多样化训练样本。训练采用两阶段策略:先用监督微调(SFT)学格式,再用强化学习(RL)提升工具选择和参数提取的准确率。基于Qwen2.5系列模型,在6个基准数据集上,32B模型平均F1从0.758提升到0.806,7B模型平均F1从0.674提升到0.786。该方法已部署到腾讯元宝,服务亿级用户。 金融问答系统中函数调用优化的数据增强流程 第四部分:生产力重构——用在哪、怎么用 这套方法最直接的落地场景有三个:证券和基金公司的智能投顾、银行的智能客服、以及金融数据服务商的API调用优化。 拿券商智能客服举例。现有流程是:客户发起金融查询,AI系统理解意图后选择后端API,提取参数(比如把”鹅厂”转成标准股票代码),调用API拿到数据,再组织回答。AugFC方法嵌入在意图理解和参数提取这两步,通过持续发现盲点、补充训练数据来提升准确率。 收益算一笔账:一家中型券商智能客服每天处理5000次金融查询,如果函数调用准确率从80%提升到95%,每天多解决750个查询不再需要转人工。按每次人工介入成本5元算,每天省3750元,每月省约11万。 AugFC”找盲点、补数据、迭代修复”的思路不限于金融,医疗问诊系统、电商客服、政务查询平台——只要涉及AI调用后端工具的场景,都能用同样的方法持续优化。产品化方向上,可以做成垂直领域的”工具调用增强”中间件,卖给有智能客服需求的企业。 AugFC方法嵌入金融客服现有流程,在意图理解和参数提取环节持续优化准确率。 第五部分:落地君推荐 落地君推荐证券、银行、金融数据服务行业可以尝试这篇论文。AugFC的思路同样适用于电商客服、医疗挂号、政务便民查询等需要AI调用工具的场景。这篇论文的核心优势:一是已在腾讯元宝这个亿级用户平台经过生产验证;二是”找盲点→补数据→迭代修复”的方法论可以直接迁移到任何垂直领域;三是7B小模型就能达到很好的效果,部署成本可控。代码虽未开源,但方法论完整,可以直接复现。
 夜雨聆风
夜雨聆风