 夜雨聆风
夜雨聆风





ClaudeCode源码精读 | 02 所谓 Agent,不过是给模型套了一个循环
这是「Claude Code 源码精读」系列的第 2 篇。上一篇我们建立了对整个源码的全局认知,这一篇我们进入第一个核心模块:Agent主循环。
读完你会明白,所谓 Agent,并不神秘。
你会搞清楚三件事:
• Agent 到底是什么——一个模型驱动的工具使用循环 • 它和传统软件最本质的区别在哪里 • Claude Code 的主循环里,藏了哪些工程细节
从聊天框到 Agent,核心变化是什么?
大模型最早出现在公众视野里,是以聊天框的形式——你输入一段话,它回复一段话,对话结束。ChatGPT、DeepSeek,都是这个模式。
这个模式能解答问题、写文章、帮你想方案。但它有一个根本的局限:模型只能说,不能做。 它可以告诉你怎么改这段代码,但它自己改不了;它可以告诉你服务器可能挂了,但重启不了。说和做之间,隔着一道墙。
这道墙意味着,所有模型给出的答案,最终都要人来执行。模型是顾问,你是执行者。这个分工在简单任务上还行,但一旦任务变复杂——需要读十几个文件、反复修改、跑测试、看报错、再修改——人变成了流水线上的传话员,模型说一步,你做一步,效率极低,真正的价值也就这么被卡住了。
于是人们开始想:能不能把这道墙打掉?能不能让模型自己去读文件、自己执行命令、自己调用外部 API?
这个想法催生了”工具调用”——给模型配上一套工具,每个工具对应一个真实的操作:读文件、写文件、执行终端命令、查数据库……模型不再只是”建议你去做”,它可以通过工具伸手到外部世界。
但工具调用带来了一个新问题:谁来管这个过程?
模型调用了一个工具,结果出来了,接下来怎么办?是直接结束,还是把结果告诉模型,让它决定下一步?如果下一步又需要用工具呢?如果任务很复杂,需要连续调用十几个工具呢?
这就是 Agent 设计(也可以说是 harness engineering)要解决的核心问题:管理模型和工具之间的协作过程。
模型负责思考——看到当前状态,决定该用哪个工具,或者任务已经完成了;工具负责执行——拿到模型的指令,去真实世界里操作,把结果带回来。这两件事交替发生,一轮一轮的执行下去。
这个一轮一轮协作的骨架,就是一个Agent主循环。也就是这篇文章要讲的核心。理解了这个主循环,你也就理解了Agent最核心的概念,之后其他的概念都是在这个基础上去延展的。
一个例子
光说”Agent 循环”太抽象,直接看一个具体的案例。
假设你对 Claude Code 说:“我的程序跑起来一直报一个 TypeError,帮我修一下”
你发了这条消息,等了十几秒,Claude code 回复:”找到问题了,是第 42 行没做空值判断,已经修好了。”
这十几秒背后,就是一个完成的 Agent 循环。
第 1 轮
Claude 收到指令,但它不知道错误在哪里。它的第一个动作:调用”执行命令”工具,把程序跑一遍,拿到完整的报错信息。
工具执行,报错日志返回了。循环继续。
第 2 轮
Claude 看到了报错:TypeError: cannot read property 'id' of undefined,定位到了出错的文件和行号。但光看报错不够,它需要看上下文。于是它调用”读文件”工具,读取出错的那段代码。
工具执行,代码内容返回了。循环继续。
第 3 轮
Claude 读完代码,找到了问题:某个地方没有判断对象是否为空就直接取值了。它调用”修改文件”工具,加上空值判断,把 bug 修掉。
工具执行,修改成功。循环继续。
第 4 轮
Claude 修完了,但它不确定改对了。它再次调用”执行命令”工具,重新跑一遍程序验证。
这次程序正常运行,没有报错。Claude 回复你:”找到问题了,是第 42 行没做空值判断,已经修好了,刚才跑了一遍确认没有报错。”
这一轮,它没有调用任何工具。循环结束。
一个 Agent 循环,就是一次从用户发起对话到Agent完成任务的完整过程。
整个过程,Claude code 调用了 Claude 模型API 四次,执行工具三次。每一轮做什么,都是根据上一轮工具返回的结果来决定的——不是预先规划好的,而是走一步看一步。
不管任务是调试报错、重构代码、整理报告、完成定时任务,还是发送一封邮件,底层都是这同一个循环:
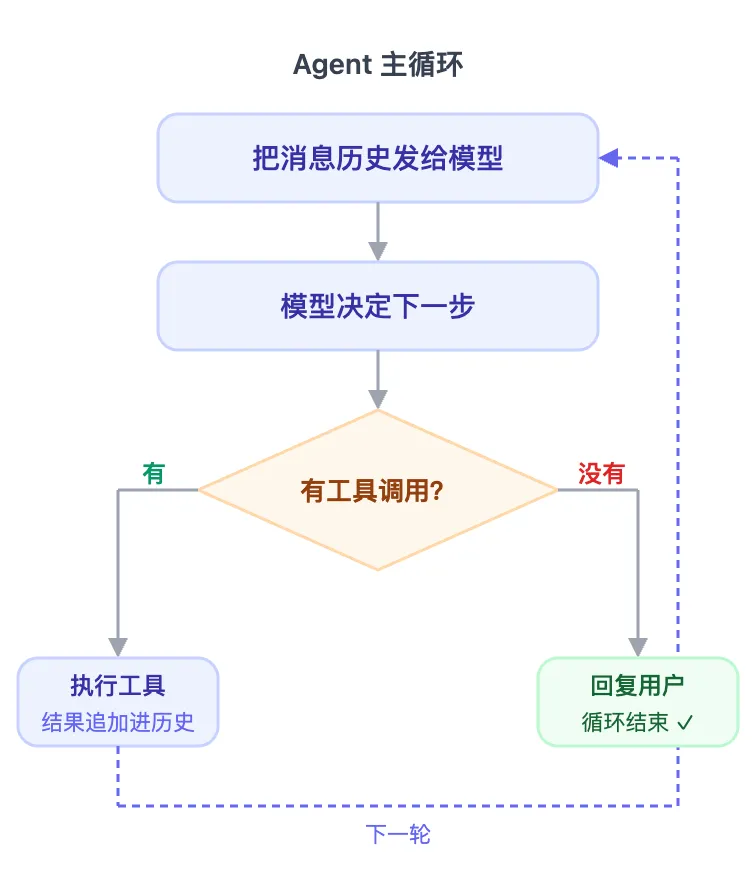
任务越复杂,循环跑的轮次越多。但骨架始终是这一个。
Agent 设计,就是围绕这个循环展开的。
query.ts主循环
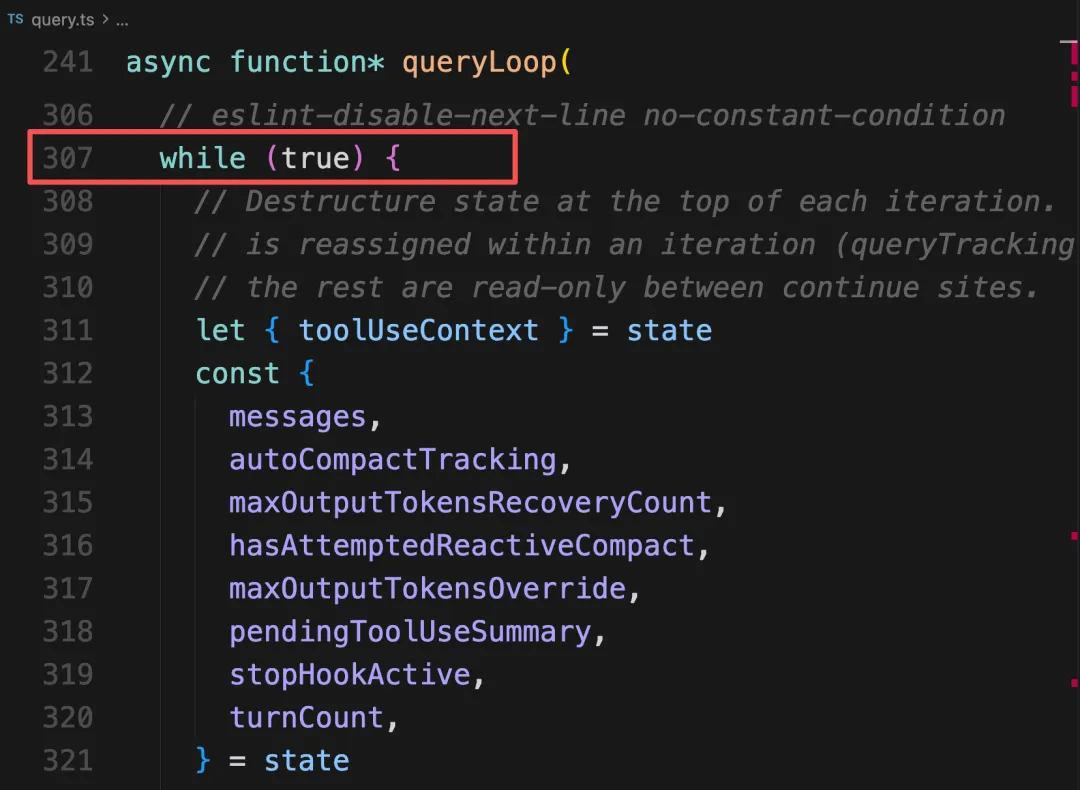
打开 Claude Code 的源码,query.ts 文件的第 307 行,就是这个循环的起点:
// query.ts(精简后的骨架)while (true) { // 第一步:把完整消息历史发给模型,流式接收响应 for await (const message of callModel({ messages, tools, systemPrompt })) { // 收集模型输出的文本块和工具调用块 } // 第二步:模型这轮没有调用工具 → 任务完成,退出 if (!needsFollowUp) { return { reason: 'completed' } } // 第三步:模型调用了工具 → 执行工具,把结果拼回历史,继续下一轮 await runTools(toolUseBlocks, ...) state = { messages: [...旧历史, ...模型回复, ...工具结果], transition: { reason: 'next_turn' } } // continue → 回到 while 顶部,开始下一轮}其中的四个元素,就是整个 Agent 能力的底层支柱:
-
• while (true):循环本身。让模型不止运行一次,可以反复执行,直到任务完成。 -
• callModel:每一轮调用模型 API,把完整的消息历史、工具列表、系统提示一起发出去,流式拿回模型的响应。 -
• needsFollowUp:这一轮模型有没有调工具?有就继续,没有就退出。它是整个循环的开关。 -
• runTools:执行模型请求的工具,把真实世界里的操作结果带回来,追加进消息历史,供下一轮使用。
其余的代码,都是在这个骨架上的延展。
其实到这个部分,这篇文章的核心就已经讲完了。但我还是想补充聊几个附加的问题。
1、谁来决定这个循环?
传统软件是确定性的——代码写死了每一步该做什么,输入相同,输出相同,流程可预测。
但在 Agent 循环里,模型读到工具结果,根据自己的判断决定下一步——调哪个工具、用什么参数、还是直接回答。没有人预先规定它走哪条路。
也就是说,每一轮该做什么,是模型决定的。他作为大脑去做决策。所以Agent的设计和模型的能力一定是相辅相成的。
这就是为什么这件事叫”驾驭工程(Harness Engineering)”——你不是在写一个执行固定步骤的程序,你是在驾驭一个有自主判断能力的模型。它的行为是不确定的,你的工作是给它设定好环境,让它在这个环境里自主完成任务。
2、上下文消息是怎么流转的?
Agent 循环的核心动作,是一条不断滚大的消息历史。每一轮,系统把完整的历史打包发给模型。模型回复之后,回复内容和工具结果又追加进历史,供下一轮使用。
用数据流的视角来看我们最前面的案例:
第 1 轮发给模型: [你的指令]第 2 轮发给模型: [你的指令] [Claude 第1轮的回复:调用运行代码工具] [工具结果:程序报错,TypeError 在第42行]第 3 轮发给模型: [你的指令] [Claude 第1轮的回复:调用了运行代码工具] [工具结果:程序报错,TypeError 在第42行] [Claude 第2轮的回复:调用了读取文件工具] [工具结果:第42行代码内容是……] ← 第 N 轮就是前面所有轮次的完整累积Claude 每一轮看到的都是从头到尾的完整历史,不是只看这一轮。它相当于每次都从头重读一遍对话记录,再决定下一步,来保证任务的持续一致。
值得注意的是,追加进历史的不只是工具输出本身,还有几类”附件”一起打包:文件变更通知、记忆预取、技能发现、用户插入的新消息。这些附件保证 Claude 每一轮都能看到完整上下文,这也是上下文越跑越大的原因之一,这里不展开了,后面上下文压缩再单独讲)。
3、边界条件的工程设计
正常情况下,循环的结束很简单——Claude 这一轮没有调用工具,任务完成,回复返回给用户。
但作为一个工程产品,这远远不够。现实里总有各种意外:上下文撑爆了、模型输出被截断、用户中途按了 Ctrl+C……每一种都要有明确的处理方式,不能让循环就这么悄悄挂掉。
源码里,query.ts 的 queryLoop 函数有 12 处 return(退出)和 7 处 continue(续跑),覆盖了各种异常情况:
-
• 上下文超限 → 先尝试压缩历史( reactive_compact_retry),压缩失败才退出(prompt_too_long) -
• 模型输出被截断 → 先把 token 上限从 8k 升到 64k 重试( max_output_tokens_escalate),还不够就注入”请继续”再跑一轮(max_output_tokens_recovery) -
• 钩子发现问题 → 把问题注入消息,让模型自己修正( stop_hook_blocking) -
• 用户按 Ctrl+C → 立即退出( aborted_streaming/aborted_tools)
这也是 CC 源码里最能体现工程成熟度的地方,也是它这么丝滑的体验所必不可少的 “dirty work” —— 不只有主路径,它是针对每一条可能出问题的分支,都做了很细致、围绕用户体验的管控处理。
如果你想自己搭一个 Agent
理解了主循环的结构,最小可用的 Agent 其实只需要三件事:
1. 一个模型调用把消息历史 + 工具列表发给 API,拿回模型的回复。
2. 一套工具执行机制解析模型回复里的工具调用,执行对应的操作,拿到结果。
3. 把结果喂回历史,再调一次把工具结果追加进消息历史,回到第一步。
循环,直到模型不再调用工具。
就这三步,你就有了一个 Agent 的骨架。它可以接任何模型(GPT、Gemini、DeepSeek),可以挂任何工具(搜索、数据库、发邮件)。Claude Code 源码里那几十万行代码,大多数是在把这三步做得更健壮——上下文太长怎么办、模型报错怎么办、用户中断怎么办、多个工具并发怎么调度。
但骨架就是这三步。
到这里,你就理解了,不管是所谓的Agent 设计、Harness 工程,这些高大上的词汇,本质上也不过就是给模型套了一个循环而已。
下一期,我们来看循环里反复出现的”工具”到底是什么,它又是怎么帮助模型实现从说到做的跨越的。
「Claude Code 源码精读」系列持续更新,关注我,每期拆解一个核心模块。