 夜雨聆风
夜雨聆风





还在给 AI 塞整个仓库?这个开源工具把整个文件夹变成了知识图谱
用 LLM 处理大型代码库的开发者,迟早会撞上同一堵墙。
上下文窗口是有限的,但代码库不是。
把源文件一股脑塞进 prompt,祈祷 AI 能理解。
token 暴涨,但理解力却没跟上。
更好的做法是什么?
Andrej Karpathy 最近分享了自己的知识管理方式:把论文、截图、推文全部丢进一个文件夹,用 LLM 编译成 wiki,再用 Obsidian 浏览。
最后他留了一句挑战:
“这里有很大的空间做出一款令人惊叹的产品,而不是一堆拼凑的脚本。”
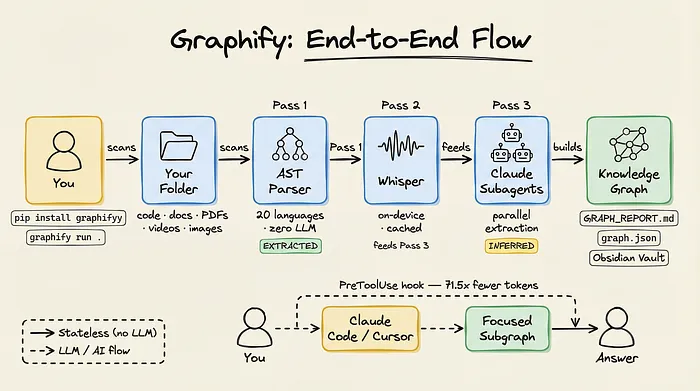
Graphify 就是冲着这个目标来的。
它的思路完全不同:不是往 AI 嘴里塞原始文件,而是先把你的代码、文档、论文、图片、视频构建成一个持久化、可查询的知识图谱。
然后只把压缩后的子图谱喂给 AI 助手。
最终效果:token 用量降低最多 71.5 倍。
第一步:安装,指向文件夹,完事
Graphify 不需要任何配置。
它不是向量数据库的封装,也不需要搭建复杂的 embedding 流水线。
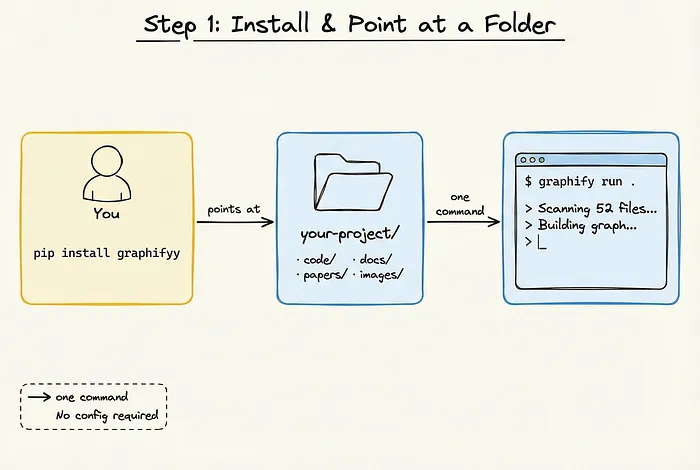
一行安装:
pip install graphifyy一行启动:
graphify run .在项目目录下跑这条命令就行。Graphify 立刻开始扫描文件——不管是代码、PDF、图片还是视频,统统开始构建图谱。
第二步:第一轮——确定性 AST 解析
第一轮处理完全在本地运行,确定性执行。
这个阶段没有任何代码被发送到 LLM API。
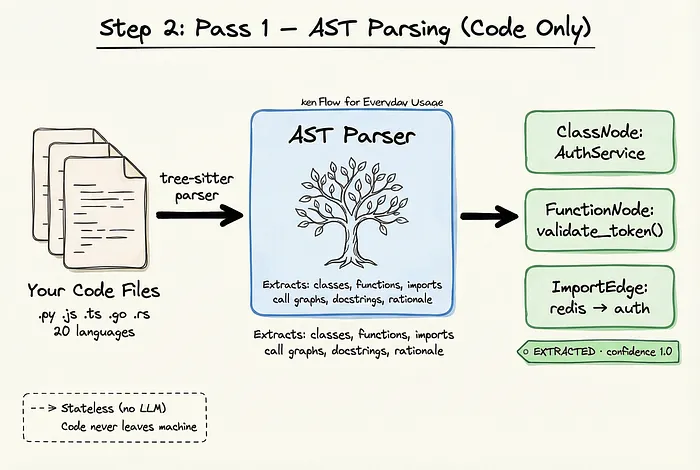
Graphify 用 tree-sitter 解析 20 种编程语言的代码。
提取什么?类、函数、import、调用关系图、文档字符串、设计理由注释。
因为这一步是确定性的,所以生成的每条边都带着 EXTRACTED 标签,置信度恒为 1.0。
这些关系是代码结构的忠实映射,不是推测。
第三步:第二轮——本地转写
如果文件夹里有音频或视频文件(比如录播课程、会议录像),Graphify 会在第二轮本地处理中搞定它们。
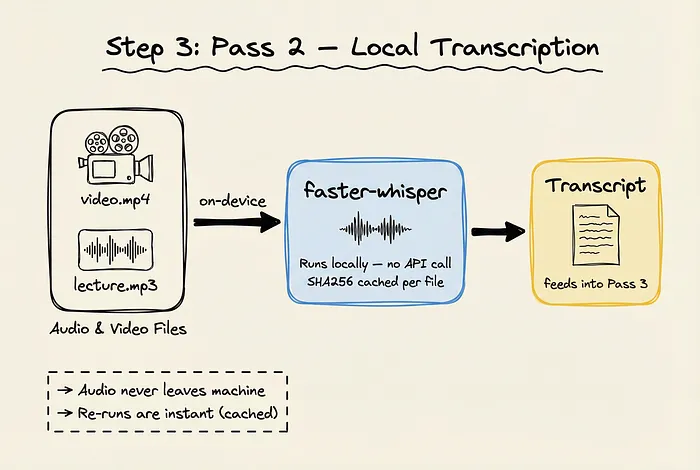
用 faster-whisper 直接在本机转写,音频数据不会离开设备。
而且转写结果有 SHA256 缓存——只要媒体文件没变,重复运行时这一步瞬间完成。
转写后的文本会进入下一轮提取。
第四步:第三轮——并行 LLM 提取
对于非结构化内容——文档、PDF、图片、以及上一轮生成的转写文本——确定性解析就不够用了。
这时候 Graphify 调用 LLM。
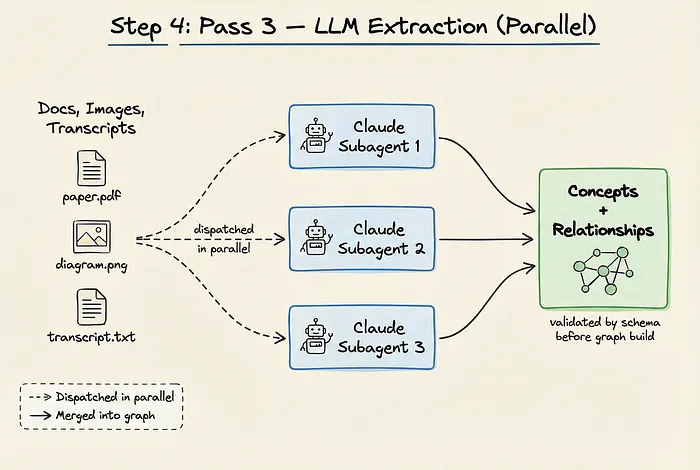
文件被分发给并行运行的 Claude 子代理。
每个子代理读取内容,提取概念、关系和设计理由。
输出严格按 schema 校验后才合并进主图谱。
因为这些关系是 AI 推导出来的,所以标注为 INFERRED,并附带置信度评分。
第五步:知识图谱输出
三轮处理完成后,Graphify 输出一个结构化的、持久化的知识图谱。
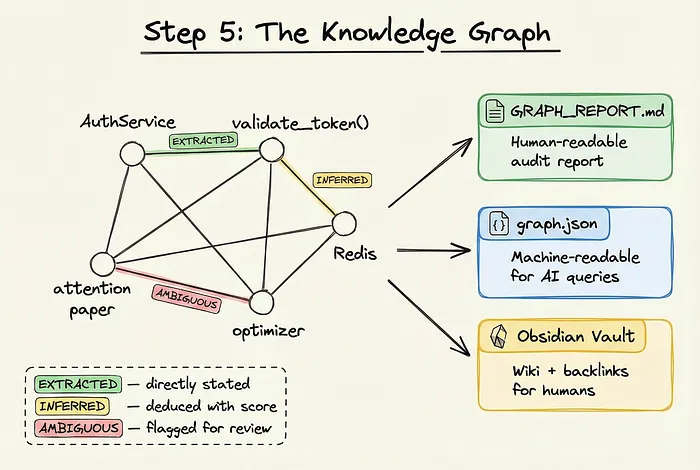
输出有三种形式:
- • GRAPH_REPORT.md:人类可读的审计报告,汇总图谱内容,标记需要人工审核的 AMBIGUOUS 边
- • graph.json:机器可读,供 AI 助手查询
- • Obsidian Vault:开箱即用的 wiki,带双向链接,可以像 Karpathy 那样可视化浏览
每条边都携带来源标签:EXTRACTED(确定提取)、INFERRED(AI 推导)、AMBIGUOUS(需要确认)。
永远清楚什么是系统找到的,什么是系统猜的。
第六步:查询图谱
Graphify 真正的威力,在于和 AI 编程助手的集成。
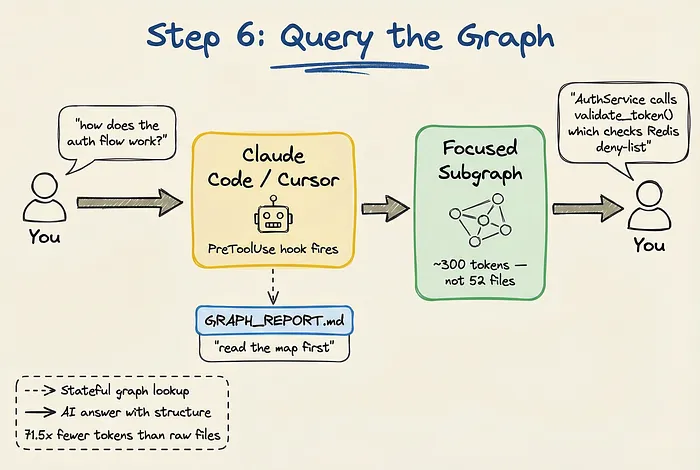
Graphify 内置了 PreToolUse 钩子。
当你问 AI 助手”认证流程是怎么走的?”,这个钩子在助手开始搜索文件之前就触发了。
助手先读取图谱索引,定位相关节点,然后只提取聚焦的子图谱。
不是把 52 个文件丢进上下文窗口,而是拿到一个大概 300 tokens 的高度相关子图。
结构化的上下文让 AI 既准确又省 token。
写在最后
把所有环节串起来看,Graphify 代表的是 AI 助手消费信息方式的一次根本性转变。
核心论点很简单:结构化的、压缩过的、带来源标签的知识图谱,是比原始文件更好的输入表示。
图谱就是上下文窗口。其他一切只是搜索。
想试试?在任意项目文件夹里跑这一行:
pip install graphifyy && graphify run .建议从一个你已经很熟悉的代码库开始——它生成的图谱会让你收获惊喜。