 夜雨聆风
夜雨聆风





两周6w星的claude记忆插件,你会了吗
先说我们都能感受的痛点
我估计用 Claude Code、Cursor、Gemini CLI 的人,都遇到过这种场景:
昨天和 Claude 一起调通了一个 WebSocket 断连重连的坑,改了六七个文件,最后收尾改了一个不起眼的 keepalive 配置才跑通。今天打开项目,想让它接着加个功能,你张嘴一说”在昨天那个重连逻辑上加个指数退避”,它一脸懵:什么重连?哪个文件?你要不先给我讲一下?
于是你又花十分钟把昨天的来龙去脉讲一遍。讲完发现,它还是理解得不太对。
再严重一点的场景:/clear 之后,或者 compact 触发了,五分钟前你们刚定好的架构决策,它也忘得一干二净。你得把 CLAUDE.md 当成急救包来写,把所有”希望它永远记得”的东西塞进去。
问题是,CLAUDE.md 是静态的,你每次调通的新东西它都不会自己往里面记。时间一长,你和 Claude 的协作就像一个”每天重新认识你一遍”的实习生,效率越用越低。
claude-mem 做的事情,就是把这个断点接上。
它到底是个什么玩意儿
一句话:让 Claude Code 在会话之间有记忆的插件。
安装之后,你什么都不用做。它会在你每次敲回车、每次工具调用、每次会话结束的时候,在后台默默记录。这些记录不是原始日志,是压缩过的结构化”观察”。下次你开新会话,它会挑最相关的一小部分,自动塞进上下文里。
整个过程零人工。你该怎么用 Claude Code 就怎么用。区别只是,几天之后你会发现一件事:它开始记得事了。
安装
 Claude Code 用户直接走插件市场:
Claude Code 用户直接走插件市场:
/plugin marketplace add thedotmack/claude-mem
/plugin install claude-mem
或者命令行一条:
npx claude-mem install
装完重启 Claude Code。第一次启动会慢几秒(它要拉 Bun、uv 这些依赖,本地检查一遍),之后就是常驻模式,你几乎感觉不到它存在。
注意:
npm install -g claude-mem只装 SDK 本体,不会注册插件钩子和 Worker。
实现原理
这是整篇文章我觉得最值得讲的部分——不是因为技术炫,而是因为理解了它的架构,你才知道该怎么用。
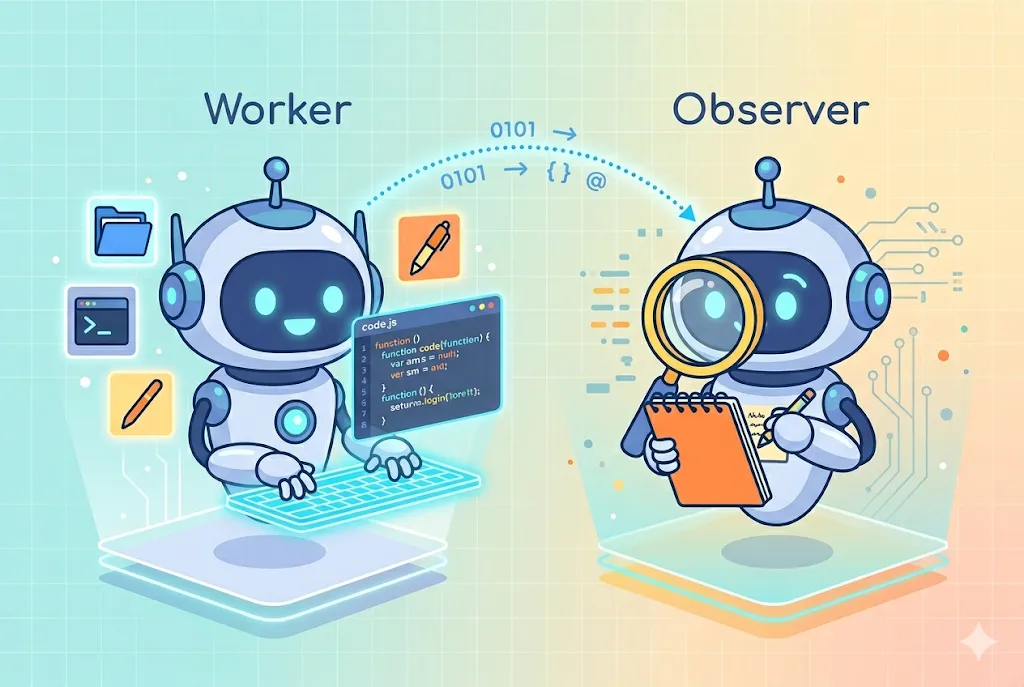
#一、观察者和主对话是两个独立的 Claude
这是 claude-mem 最关键的一个设计选择。
你开一个会话,和主 Claude 对话,它负责干活——读文件、改代码、跑命令。在你看不见的地方,claude-mem 会起另一个 Claude,我们叫它”观察者”。观察者只做一件事:看着主 Claude 在干啥,然后把关键动作压缩成结构化笔记。
观察者被严格限制了能力。它没有 Read、Write、Edit、Bash、Grep、WebSearch 这些工具——任何能产生副作用、能读文件、能联网的工具都被禁掉。它只能读主会话的历史,然后输出一段格式固定的观察笔记。
为什么这么做?因为如果让主 Claude 自己”记忆自己”,一是会打断干活的节奏,二是会膨胀上下文,三是容易陷进”我记录我做了什么”的递归里。把观察者独立出来、同时缴械,这事就稳了。
#二、记忆不是日志,是结构化的五类观察
观察者吐出来的东西是严格的五类:
- bugfix(解决了什么 bug)
- feature(实现了什么新功能)
- decision(做了什么架构/技术选择)
- discovery(发现了什么之前不知道的东西)
- change(改了什么,但不属于上面四类)
每条观察都带标题、副标题、关键事实列表、叙述、相关概念、读过和改过的文件。这套结构是后面一切能力的地基——搜索、时间线、知识问答、引用溯源,都靠这个结构撑起来。
这也是它和”直接把对话 dump 到文件里”那类方案的本质区别。原始 transcript 是噪音,结构化观察才是信号。
#三、本地双引擎:SQLite + 向量库
所有观察落在你本机的 SQLite 数据库里(~/.claude-mem/claude-mem.db),带全文索引。同时,每条观察也会同步到一个本地的向量库(通过 MCP 协议和一个独立的 Python 服务通信)。
这意味着两种能力:
- 关键字搜索:精准、快、省算力。你搜 “WebSocket reconnect”,它直接命中。
- 语义搜索:模糊、能跨词匹配。你搜”连接不稳的修复”,它也能找到昨天那次重连调试。
这两条路混着用,才是实际可用的”AI 记忆”。单靠任何一个都会有大片盲区。
#四、渐进式披露:一种特别值得抄走的搜索范式
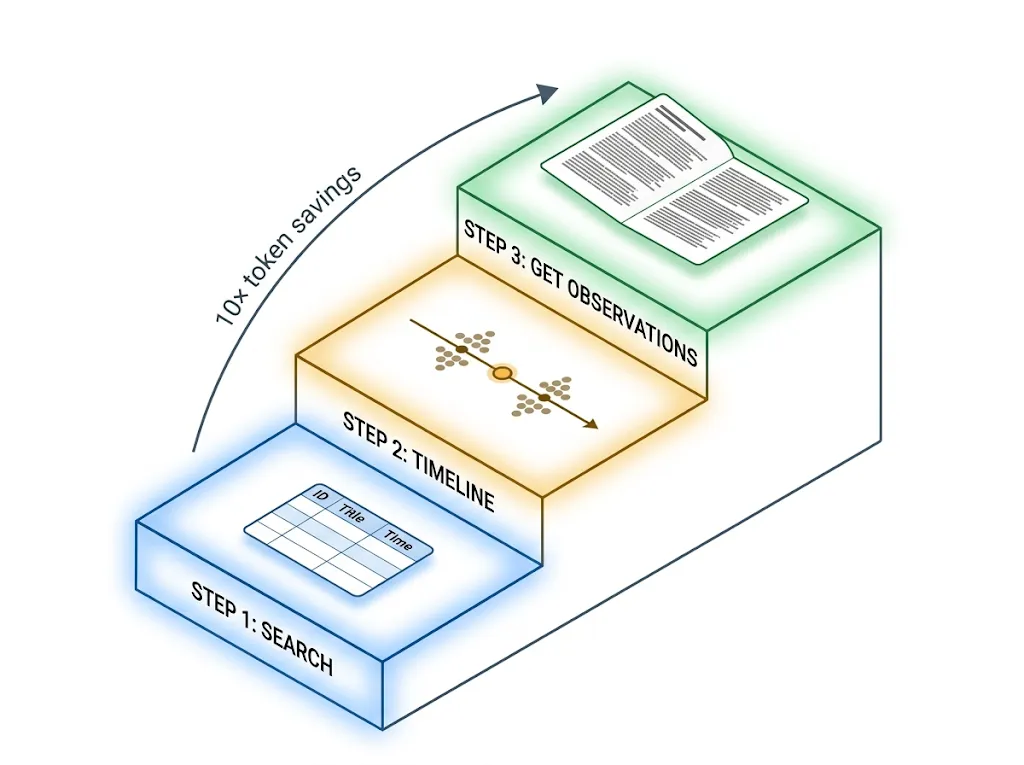
这是整套系统里最聪明的设计。
传统做法:用户问”上次我们怎么解决 JWT 过期的”,系统一口气把所有相关对话原文塞给模型,让它自己消化。问题是 token 爆炸——一次搜索可能塞进去几万 token,模型还没开始回答,上下文先吃满了。
claude-mem 的做法分三层:
- 先给索引。搜索只返回一张小表:ID、时间、类型、标题。每条大概几十个 token。
- 再看时间线。对感兴趣的那条观察,拉出它前后几条的上下文,了解当时的来龙去脉。
- 最后按 ID 批量取完整内容。只对筛选过的、真正相关的那几条,才去拉完整叙述、事实、文件列表。
相比一把梭哈,官方测算大概省 10 倍 token。更重要的是,这个范式让模型自己挑要看什么,而不是被动灌输——这恰恰是 agent 该干的事。
任何做长期记忆、做 RAG、做知识库问答的项目,这个三层范式都值得直接搬走。
什么都不做,它就已经在帮你了
装完之后你不需要改任何习惯。几天之后你会开始注意到两件事:
第一件,新会话的系统提示里会多一段。长这样:Claude 会”自己”知道,上个会话里你们刚解决完某个 bug、上周你们定了用哪个库、前天你发现某个 API 有坑。
第二件,它开始主动翻历史。当你问”我们之前是怎么处理那个 rate limit 的?”这种话,它不会再傻乎乎让你解释,而是直接去搜索记忆,给你拉回答案,还会标注来源——比如”这个决策来自 #11342 这条观察”。
你可以在浏览器打开 http://localhost:37777 看原文。
主动提问,才是最省时间的用法
自动注入的上下文是有限的(为了省 token),很多老记忆不会主动冒出来。这时候你得学会用自然语言直接问它。
几个高频场景:
- “上次我们是怎么解决 X 的?”
- “最近这周在这个项目里修过哪些 bug?”
- “我们在 auth 这块做过什么架构决策?”
- “我之前是不是研究过 Y 库?最后结论是什么?”
这些问题会触发 mem-search 这个 skill,它会按前面说的三层范式去找答案,并且把过程告诉你。我日常用下来,这种主动查询比自动注入还管用——因为当下的问题你最清楚,让它精准搜比让它猜要好得多。
用 <private> 圈出敏感信息
这是一个很容易被忽略、但必须设置好的功能。
在提问或者文件里,用这个标签包起来的内容,claude-mem 在采集的最早一层就会剥掉,完全不会进数据库、不会进向量库、不会流到观察者 Claude:
<private>
生产数据库密码:xxx
线上 API key:xxx
</private>
适用场景:调试时粘贴过真实凭据、用户数据、内部系统的敏感路径、商业敏感的业务逻辑。团队协作的话,建议把这个用法写进你的项目规范。
中文模式
默认情况下,观察笔记是英文生成的。这对国内团队不太友好——你搜”登录态过期”可能搜不到,因为它存的是”login session expired”。
解决方案是编辑 ~/.claude-mem/settings.json:
{"CLAUDE_MEM_MODE":"code--zh"}
重启 Claude Code,之后所有新观察都会用中文生成。老数据不会变,但会随着时间被新数据覆盖。
同类模式还有很多:日语、韩语、法语、德语、西班牙语等等。还有非编码场景的 email-investigation、law-study、chill 这些。挑一个顺手的就行。
配合 make-plan / do 做长任务
claude-mem 除了记忆,还附带了几个工作流 skill,其中 make-plan 和 do 这一对是我日常用得最多的。
make-plan 做什么:你告诉它你想实现什么,它不会直接开干,而是先派子 agent 去读文档、查现有代码模式,然后出一份分阶段计划。每一阶段都带”要复制文档里哪段样例”、”验证清单”、”别踩哪些坑”。
do 做什么:拿着 make-plan 出的计划,按阶段派子 agent 执行。每一阶段独立上下文、独立验收。
为什么要这么绕?因为长任务最大的杀手是上下文污染。主会话里堆了几万 token 的探索过程、失败尝试、来回改动,到最后 Claude 自己都不知道要干什么。分阶段 + 子 agent 的模式,每一段都在干净的上下文里执行,错了单独重做一段,不会污染全局。
而 claude-mem 的记忆能力,让这个模式进一步增强:前几次做类似任务时积累的观察,可以直接被新的 make-plan 调用来参考。你越用,它给的计划就越贴合你的项目习惯。
Viewer 功能
打开浏览器访问 http://localhost:37777,能看到一个本地单页应用。它不是日志面板,更像一个记忆流。
- 实时流:Claude 正在”想”什么,观察者正在记什么,SSE 推送实时刷
- 时间轴:按项目、按日期翻,看某一天你和 Claude 干了啥
- 观察/摘要/Prompt 三种视图:分别看原子观察、会话级总结、你提过的问题
- 引用锚点:每条观察都有一个直接可访问的 URL,方便在 CLAUDE.md、PR 里引用
- Settings:切换稳定/Beta 通道,尝鲜实验功能
我自己的用法:下班前花五分钟翻一下本周的时间轴。经常会发现”居然踩了这么多坑”,顺手把值得写下来的几条整理进项目文档。比起自己写周报好用多了。
踩坑
坑 1:第一次启动比较慢。 它要拉 Bun 和 uv 的运行时。如果你在国内网络,可以提前装好这两个再装 claude-mem。
坑 2:如果你用 Git Worktree,记忆会按 worktree 分开。 不过 12.2.0 之后,当一个 worktree 被 merge 回主分支,它会自动把那份记忆并入父项目。如果你版本比较老,可以手动跑 npx claude-mem adopt 合并。
坑 3:Worker 端口占用。它默认监听 37777,如果被占了,改 ~/.claude-mem/settings.json 里的端口配置。
坑 4:团队协作场景。目前记忆是本机存储,同事之间不共享。如果想共享经验,只能靠传统方式(文档、PR 描述、CLAUDE.md)。
坑 5:敏感项目先评估。虽然数据全在本机,但还是建议在处理客户代码前,把该 <private> 的都圈出来。
和别的”AI 记忆”方案比
和 Cursor 的 .cursorrules / memory:Cursor 那套是人工维护为主,你得自己写规则、自己总结。claude-mem 是自动采集为主,你几乎不用动手。代价是它的记忆是”观察”而不是”规则”——不适合用来强制某种代码风格。
和 Continue 这类自建 RAG:很多项目是自己做 embeddings + RAG 搜代码。这套侧重”代码本身的检索”,claude-mem 侧重”你和 AI 协作过程的检索”。两者解决的问题不一样,其实可以共存。
和 ChatGPT 的 memory:ChatGPT 的 memory 是跨对话的”用户偏好”,粒度很粗,主要记你是谁、喜欢啥。claude-mem 是项目级、会话级的工作记忆,粒度细得多,而且完全本地。
一个结论:如果你大量时间是在终端里和 Claude Code / Gemini CLI / OpenCode 协作写代码,claude-mem 几乎没有替代品。它解决的是”AI 协作开发”这个特定场景下的上下文断裂问题。
使用感受
- 在一个项目上持续工作几周以上。记忆的价值和项目时长成正比。
- 做复杂重构、迁移、长周期功能开发的。上下文断裂最痛的场景,也是它最能发力的场景。
- 同时维护多个项目、频繁切换的人。每次切回来不用再”讲一遍”。
- 喜欢让 AI 参与技术决策的。decision 类观察会帮你把历史判断都留下。
不那么适合的:
- 偶尔用一下 Claude 写个一次性脚本的(用不太上记忆)
- 严格不允许任何本地数据留存的(尽管它全在本机,但确实有存储)
- 对 Bun / Python 环境极度抗拒的(依赖稍微有点重)
一些可以直接搬走的设计思路
就算你不用 claude-mem,下面这几个思路也值得放进你的工具箱:
- 把”记忆”当独立进程来做,而不是塞进主模型。主模型专心干活,记忆有专门的观察者。
- 观察者必须缴械。任何有副作用的工具都禁掉,避免反作用于主会话。
- 结构化输出 > 自由文本。枚举类型 + 固定字段让下游一切能力都有抓手。
- 索引 → 时间线 → 详情的三层披露。任何长历史/长文档检索都适用,是 token 经济的标准答案。
- 本地优先 + 可视化。记忆要可审计、可引用、可追溯,不能是黑盒。
- 在边缘剥离隐私。越早过滤越安全,到下游再处理就晚了。
- 模式化而不是万能化。code / email / law / chill 是不同的观察套路,一套模板做不了所有事。
最后
大家可以装一下试试,还是有些效果的。