 夜雨聆风
夜雨聆风





从找一篇论文开始:把 PDF 下载这件小事做成一个 Skill
事情的起点很简单:我想找点harness相关的一些论文看看
最早的流程也很普通。先用 AI 搜索找到论文页面,再去拿 PDF 链接,下载到本地,然后丢给文档阅读工具做阅读、总结或者翻译。单看每一步都不复杂,但这个流程做多了以后会发现,它其实是一串很碎的动作:重复、琐碎,而且很容易打断思路。

于是我顺手做了一个 pdf-downloader skill,把这件事整理成一套固定 SOP。
事情一开始,只是想找几篇论文
读论文这件事,通常不是从 PDF 文件本身开始的,而是从一段不完整的信息开始:
-
• 一个论文标题 -
• 一个 arXiv 页面 -
• 一篇博客里提到的 paper -
• 一个 GitHub README 里的引用 -
• 一篇产品文章附带的 research link
这时候第一步通常是搜索。
如果运气好,事情会很简单。比如 arXiv、OpenReview、ACL Anthology、NeurIPS Proceedings 这类站点,通常都能直接拿到 .pdf 链接。找到 PDF,下载、重命名、交给文档工具,流程基本就结束了

但真实情况往往没这么干净
有些页面只有 HTML,没有现成 PDF;有些 PDF 链接藏得很深;有些站点依赖浏览器环境动态加载;还有一些内容本身不是论文,而是研究博客、技术报告、产品说明,但同样值得保存下来。
于是原本只是“读一篇论文”,最后慢慢变成了一条完整 workflow:
-
1. 找 source URL -
2. 判断是不是 direct PDF -
3. 下载或生成 PDF -
4. 检查文件是否有效 -
5. 确认页数和内容 -
6. 交给文档阅读工具 -
7. 如果没有 PDF,再补一份可离线保存的文档
到这里,这件事就已经不是一次简单下载了,而是一个需要稳定处理的流程。
AI 搜索解决了入口问题,但没有解决收尾问题
AI 搜索很适合做入口定位。
给它一个论文标题,它通常能很快找到官方页面、arXiv 页面、会议页面或者作者主页。相比手动搜索,这一步已经足够高效。
但 AI 搜索大多只解决“内容在哪里”,不解决“怎么把它稳定落到本地”。
而我真正需要的,其实是一个本地文件:
-
• 能归档 -
• 能交给文档阅读工具 -
• 能离线查看 -
• 能复用 -
• 能作为后续翻译、总结、标注的输入
也就是说,搜索只是前半段。后半段是文件化、校验和归档。这部分如果没有固定流程,每次都要重新判断一遍。
最理想的路径,当然是直接拿到 PDF
最理想的情况,是页面本身就是 PDF,或者页面里有明确的 PDF 链接。
这种场景下,pdf-downloader 的动作很直接:
python3 ~/.codex/skills/pdf-downloader/scripts/download_pdf.py "$URL" --output-dir output/pdf文件下载后,再做一层基础校验:
-
• 检查文件大小 -
• 用 pypdf读取 page count -
• 尝试抽取文本 -
• 在 macOS 上用 qlmanage渲染 thumbnail -
• 确认文件不是空 PDF、错误页,或者伪装成 .pdf的 HTML
这一步不能省。因为“下载成功”不等于“拿到了正确内容”。
有时候文件后缀是 .pdf,内容其实是一个错误页;有时候请求被 403,保存下来的只是几行 HTML;还有些 PDF 虽然能打开,但没有文本层,后续交给文档阅读工具时效果会明显变差。
所以这里真正有意义的,不是“下载”这个动作,而是“校验后可用”这个结果。
麻烦的是,很多有价值的内容根本没有现成 PDF
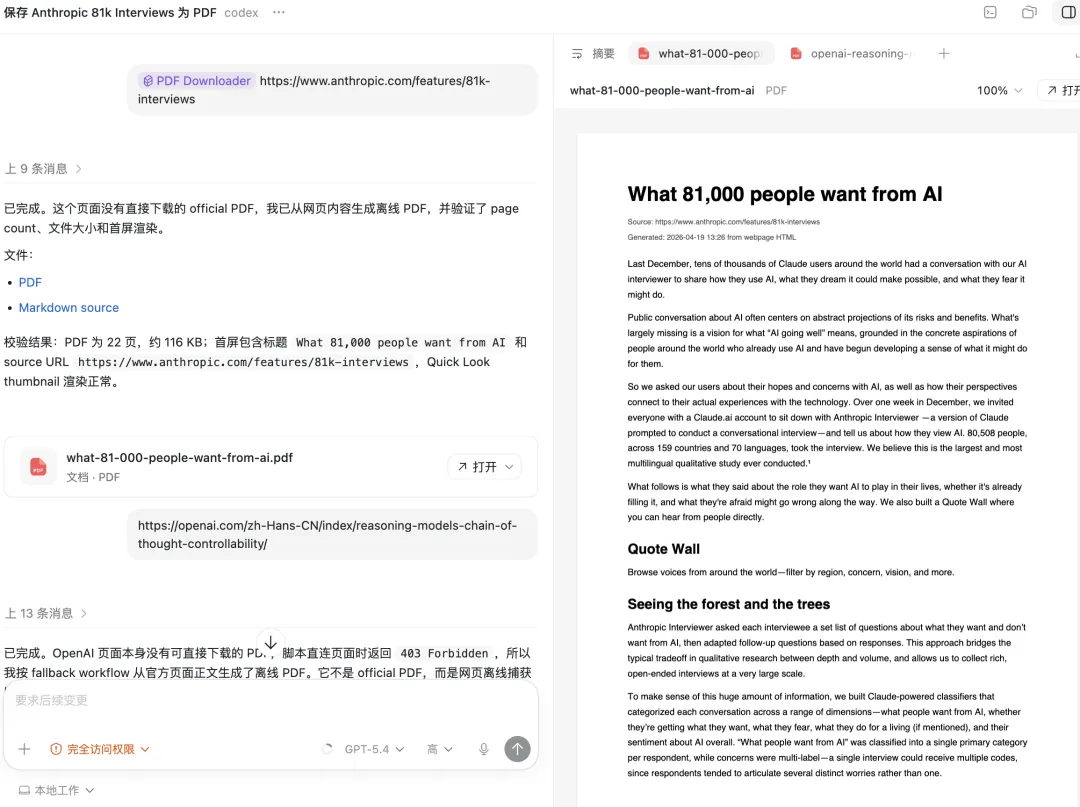
做着做着,我遇到一个很常见的问题:很多内容没有 official PDF
尤其是研究博客、技术文章、产品文档、实验报告这类网页。内容本身很完整,也很适合阅读,但只提供网页版本。
这种情况下,如果只是把 URL 丢给文档阅读工具,效果并不总是稳定。页面里可能混着导航栏、广告、脚本、折叠区域、动态组件,甚至还会被反爬或权限策略拦住。
所以后来我在 pdf-downloader 里补了一个 fallback:
当直接下载失败,或者页面本身没有可用 PDF 时,就把网页正文整理成 Markdown,再从 Markdown 生成离线 PDF。
这里生成的不是 official PDF,而是 offline webpage capture。它的目标也不是伪装成原始文件,而是把正文稳定保留下来,方便后续阅读和归档。
Fallback 的核心,不是转 PDF,而是先把正文清洗出来
网页如果直接打印成 PDF,通常会把大量无关内容一起带进去:
-
• 顶部导航 -
• footer -
• cookie banner -
• 分享按钮 -
• 相关推荐 -
• 动态组件 -
• 脚本残留文本
所以 fallback 的关键,不是“把网页转成 PDF”,而是先把正文整理成一个干净的 Markdown。
Markdown 里会保留必要的元信息,例如:
# Article TitleSource: https://example.com/articleDate: 2026-04-19Authors: ...## Section 1正文内容……## Section 2正文内容……然后再转换成 PDF:
python3 ~/.codex/skills/pdf-downloader/scripts/download_pdf.py \ --markdown tmp/article.md \ --source-url "$URL" \ --output-dir output/pdf \ --filename article-name.pdf这么做有几个直接好处:
-
• source URL 会写进 PDF -
• Markdown 源文件会保留 -
• 文档结构后续可以继续修 -
• 文档阅读工具拿到的是干净正文 -
• 长期归档时可以区分 official PDF 和 generated PDF
这样一来,整个过程就不再是“临时处理一个网页”,而变成了“稳定生产一份可追踪文档”
Skill 的价值不在脚本本身,而在 SOP
单看 pdf-downloader,它其实不复杂。核心无非是下载、解析、转换和校验。
真正有价值的地方,不是多写了一个脚本,而是把一条原本松散的流程固化成了 SOP:
-
1. 如果用户给的是 URL,就直接处理 URL -
2. 如果用户只给标题,就先搜索 primary source -
3. 优先寻找 direct PDF -
4. 如果是 PDF,就直接下载 -
5. 如果是网页,就生成离线 PDF -
6. 如果页面 blocked,就走 Markdown fallback -
7. 文件统一落到 output/pdf/ -
8. 校验 page count、file size、source URL 和首屏渲染 -
9. 最后返回本地文件路径,并标注文件类型
这套流程真正解决的,是上下文切换成本。
以前每次都要重新过一遍这些问题:
-
• 这个页面有没有 PDF? -
• 下载到哪里? -
• 文件该叫什么? -
• 要不要检查? -
• 失败了怎么补? -
• 这份 PDF 是官方的,还是我生成的?
现在这些都不需要临时判断了,skill 会按既定流程往下走。
从“调用几个工具”变成“封装一种能力”
这也是我觉得 Codex skill 很适合做这类事情的原因。
很多工作并不是某一个工具单独完成的,而是一组判断和动作的组合。比如下载 PDF 这件事,里面其实混合了:
-
• web search -
• HTTP download -
• content-type 判断 -
• HTML 提取 -
• Markdown 整理 -
• PDF 生成 -
• PDF 校验 -
• 文件命名 -
• 结果说明
如果每次都手动指挥 AI 去做这些步骤,成本并不低,而且很容易漏掉边角情况。
但封装成 skill 之后,我只需要给一个 URL 或标题,后面的流程就能稳定执行。
这不是为了少打一条命令,而是为了少重复组织一次 workflow。
最后,它变成了一个很顺手的小基础设施
这个 skill 最开始只是为了读论文方便一点。
但做完以后,它的适用范围明显更广了:
-
• paper -
• research blog -
• product announcement -
• technical documentation -
• long-form article -
• online report -
• webpage without PDF
尤其是当我要把内容交给千问文档阅读、Claude、ChatGPT 或其他文档工具时,它可以先把输入整理成一个稳定的本地 PDF。
换句话说,它做的不是“下载文件”,而是把在线内容变成可处理文档。
这个变化不大,但很实用。
小结
pdf-downloader 不是一个很宏大的工具,它只是把一个高频出现的小流程标准化了。
起点不过是读一篇论文:先用 AI 搜索找到 source,再去拿 PDF 链接下载,然后交给文档阅读工具处理。后来发现很多内容没有现成 PDF,于是顺手补上了网页转 PDF 和 Markdown fallback。再往后,这些零散动作被收进一个 skill,最后变成了一套可以重复执行的 SOP。
很多自动化都不是从“我要做一个系统”开始的,而是从“这件小事,我不想再重复想一遍”开始的
skills文件
-
• https://modelscope.cn/skills/events/Pdf-Downloader-Skills/summary