 夜雨聆风
夜雨聆风





PDF解析折腾半年,最后靠这套方案搞定了
最近有朋友问我,想用AI帮分析财务年报,但把PDF丢进去,AI读了半天,表格里的数字全乱了,问它个问题答得驴唇不对马嘴。
这其实不是AI的问题,是文件没读进去。
PDF这个格式坑很多。用复制粘贴,遇到扫描件直接凉凉;调工具提取,格式十有八九乱套——表格变成一行流水账,多栏排版挤成一团,公式图片直接不见。更根本的问题是,AI要”读懂”一份PDF,光有文字不够,它还要知道哪段是标题、哪里是表格、哪块是注释。没有这些结构信息,后续什么分析都是空谈。
现在市面上专门处理这个问题的多模态OCR模型不少,DeepSeek-OCR、PaddleOCR-VL、MinerU……每个都说自己强,但真上手就是另一回事了——显存不够、速度慢、部署文档缺三少四,搞到最后往往不了了之。
今天就来说说,这些方案到底各自适合谁、怎么把它们整合起来用。
三套方案,分别适合什么场景
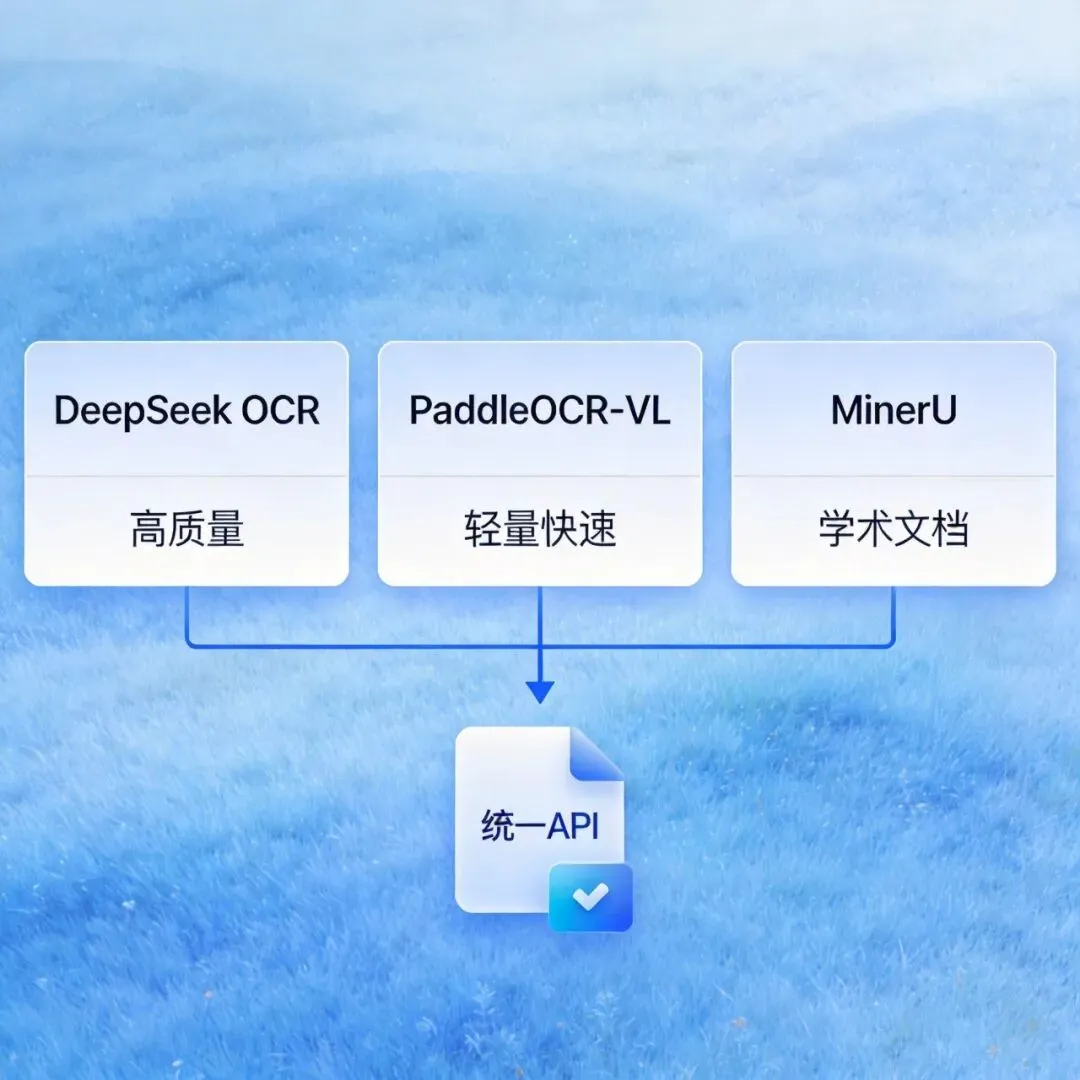
DeepSeek-OCR是DeepSeek自家出的OCR模型,理解能力强,复杂版式、混排表格、数学公式这类东西识别效果不错。要求高的场景,比如学术文献、法律合规文件,用它更稳。
PaddleOCR-VL是百度飞桨出的视觉语言模型,参数只有0.9B,但在公开测评上表现出奇地好,支持109种语言,速度快、显存省,一张3090显卡就能跑。需要批量处理大量文档的场景,它性价比最高。
MinerU偏学术方向,对论文、教材、财务报告这类文档处理得很好,输出结果格式干净,搭RAG知识库的话优先考虑它。
坦白说,这三套方案不用非得选一个,完全可以根据文档类型,让它们各司其职,外面包一层统一接口,调用方不需要关心底层用了哪个模型。
vLLM这个东西,很重要
以前大家对本地部署大模型的印象:麻烦、慢、跑起来像在煲汤。
推理速度确实是个老大难。配置装好了,跑一张PDF等一分多钟,这速度根本没法接进正式工作流里。
vLLM解决的就是这个。它是目前最主流的大模型推理加速框架,接上之后速度大幅提升,还支持批量文档并发处理,对外暴露的是标准OpenAI API格式——这意味着你本地搭的这套系统,任何支持OpenAI接口的工具都能直接调用,不用改任何代码。
硬件方面,一张3090就够,普通消费级显卡,不需要买服务器。
解析完输出什么
这套系统解析之后,每份文档会产出两个东西。
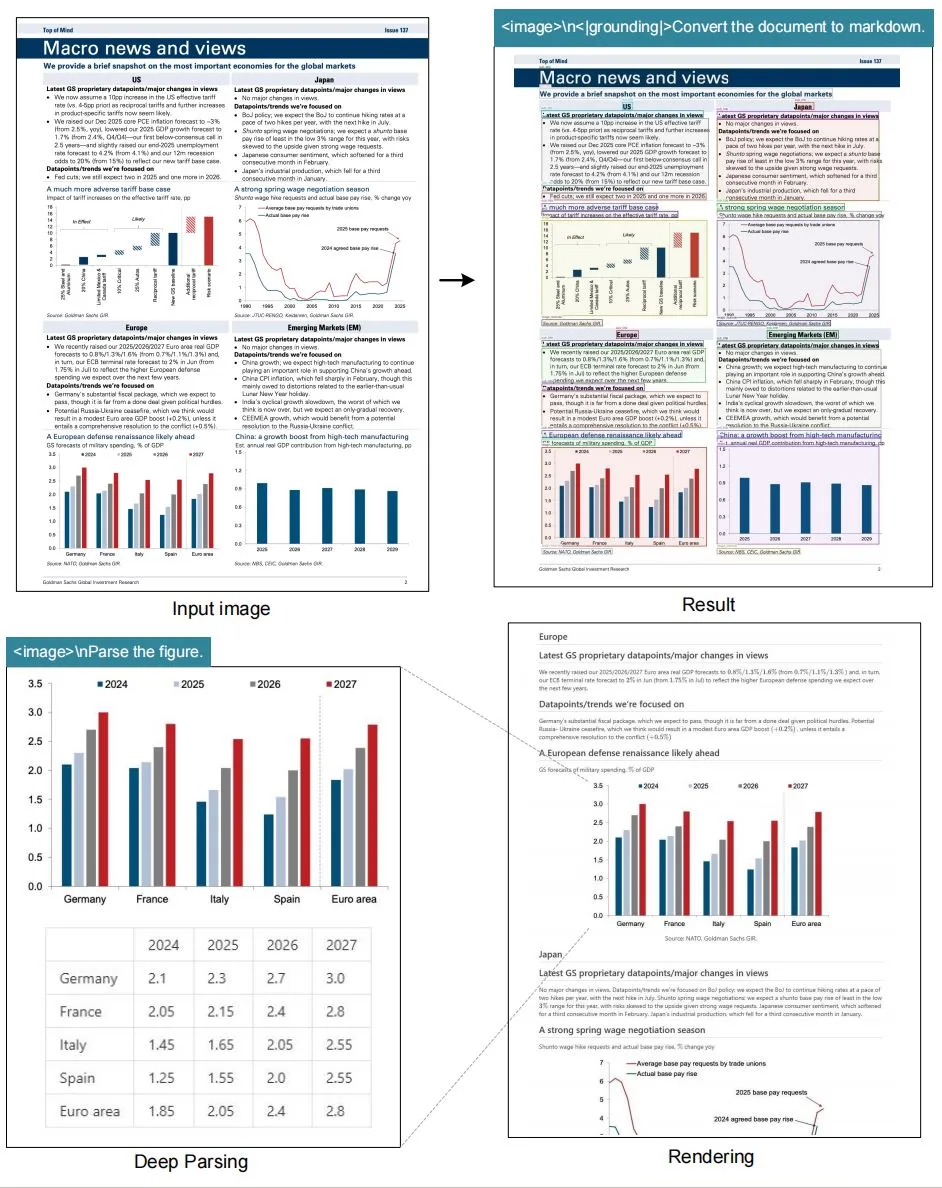
一份是结构化Markdown:标题层级、正文段落、表格、代码块、图片引用,全部自动处理完,格式很干净,可以直接给大模型用。
另一份是JSON数据:每个内容块都有独立ID、坐标位置、类型标签,文字、表格、图片、公式各自分离,接RAG系统做检索溯源很方便。
这两个输出格式的组合,覆盖了绝大部分使用场景。
接进AI工作流之后能干什么
光能解析还不够,关键是要能接进现有的流程里。
这套系统支持通过MCP协议对外暴露服务,配合LangChain 1.0可以直接接进AI智能体的工作流。你的AI助手从此多了一项能力——读文件。合同、年报、操作手册,丢进去就解析,解析完继续做分析、提问答疑、整理归档,全自动。
文档理解这块在企业场景里需求很大,信息提取、合规审查、财务对比……很多以前靠人工盯着做的事情,这套流程接好之后,AI可以直接接手。
最后说几句
说实话,PDF解析这件事技术上已经没什么太大障碍了,但真正能整合起来、跑通全流程的方案,市面上讲清楚的并不多。
DeepSeek-OCR负责质量,PaddleOCR-VL负责速度,MinerU负责学术文档,vLLM加速,统一API对外——这个组合目前来看是比较稳的。
硬件方面最低一张3090,实际测下来能用,不是噱头。
如果你正在做RAG知识库、AI文档处理流水线,或者只是想让自己的AI助手能真正读懂PDF,这套方案可以认真研究一下。
欢迎点击卡片关注东哥说AI,分享真正能落地的AI工具与实践。