 夜雨聆风
夜雨聆风





AI 工程进化论 第2讲:MCP — AI 与工具世界的接口
导读
2024 年 11 月 25 日,Anthropic 发布 MCP 协议。随后 VS Code(将其列为 Host 示例)、Cursor、ChatGPT 均宣布支持。不是巧合,是标准化之后的自然结果。 本讲讲清楚一件事:MCP 解决的不是”工具调用”问题,是”工具调用标准化”问题——N×M 变成 N+M,这是量级差异,不是优化。 适合对象:在用任何 AI 编程工具、或者给 AI 接过外部系统的工程师。
先说一个真实的麻烦
你给 Claude 接了一套工具:查数据库、读文件、发通知。跑通了,用着也不错。
然后 Codex 出来了,你想试试。
你盯着自己写的那套 function call 定义——同样的工具,要重新写一遍。格式不一样,参数结构不一样,错误处理方式不一样。
这不是因为你写得不好,是因为在 MCP 之前,这件事本来就没有答案。每家模型有每家的格式,每个工具有每个的接入方式,中间没有标准。
N 个模型 × M 个工具 = N×M 套集成代码。
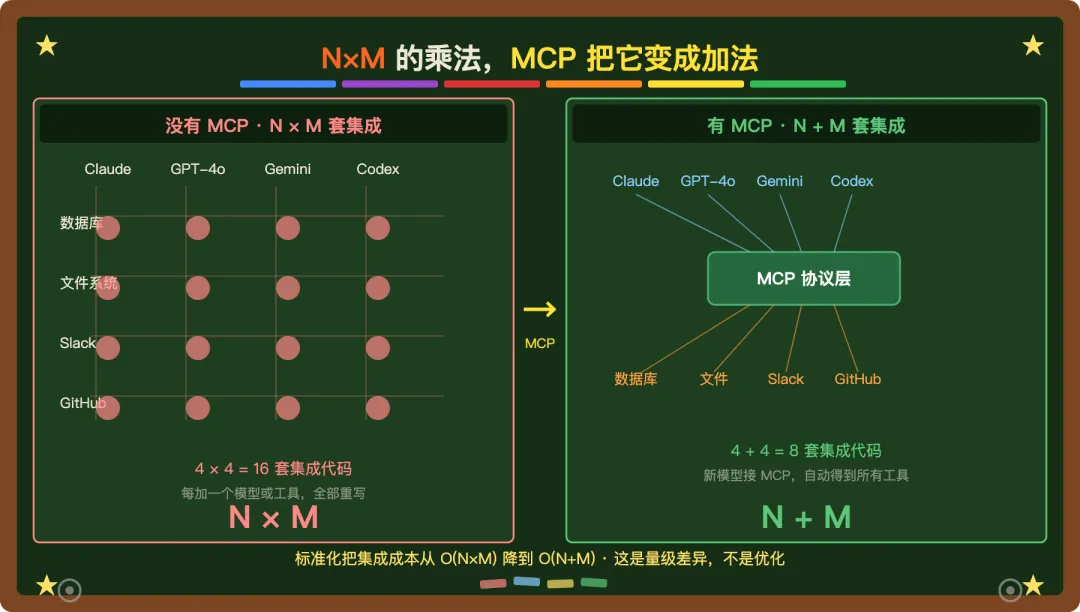
MCP 做的事情,是把这个乘法变成加法。
Function Call 出了什么问题
Function call 本身没问题,问题在它停在了哪里。
它解决的是”模型怎么描述一个函数调用”,没解决”不同模型、不同工具之间怎么对话”。每家模型发明自己的 JSON 格式,每个工具写自己的解析逻辑。结果是:
•接入 Claude:写一套
•接入 GPT-4o:再写一套
•接入 Gemini:再写一套
•新加一个数据库工具:每套都要改
这是碎片化,不是能力问题。能力各家都有,标准没有。
类比:数据库驱动在 JDBC 之前的状态。每家数据库厂商有自己的 API,应用层代码绑死在具体数据库上。JDBC 出来之后,换数据库只需要换驱动,应用层不动。
MCP 对 AI 工具生态做的是同一件事。
MCP 是什么
2024 年 11 月 25 日,Anthropic 发布 MCP(Model Context Protocol)。官方给的类比是 USB-C:
“Think of MCP like a USB-C port for AI applications.”
USB-C 之前,充电器、数据线、视频输出各自一个接口。USB-C 统一了,设备不管是谁造的,只要支持 USB-C 就能接。MCP 对 AI 工具做了同样的事。
架构上三个角色:
Host:AI 应用本身。Claude Code、VS Code、Claude Desktop,这些是 Host。负责协调多个 Client 连接。
Client:Host 内部的连接组件,每个 MCP Server 对应一个 Client。Host 连了 3 个 Server,就有 3 个 Client。
Server:暴露能力的程序。文件系统 Server、数据库 Server、Slack Server——它们把数据和操作包装成 MCP 格式,等 Client 来取。
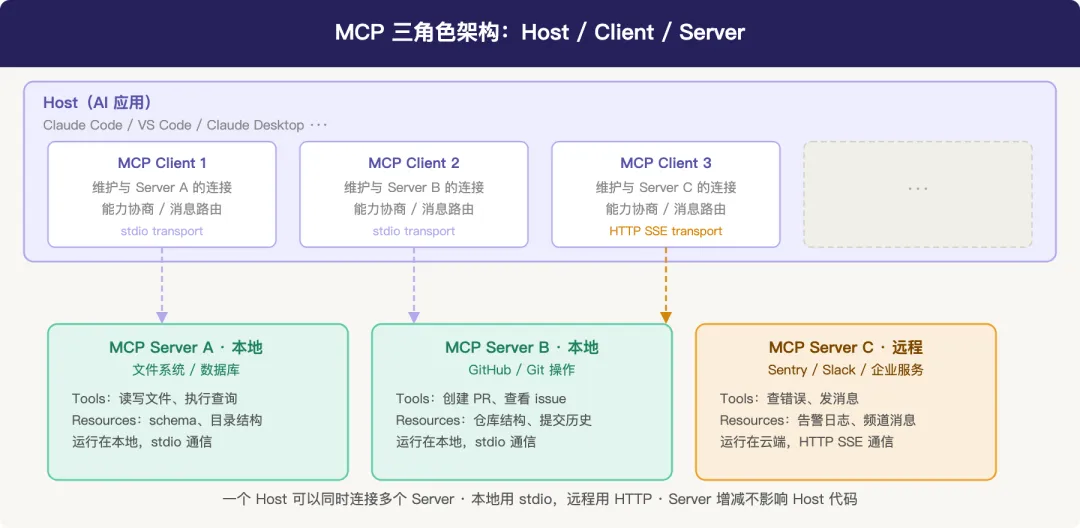
这个结构意味着:模型不直接碰工具,中间有协议层。换模型不影响 Server,加工具不影响 Host。N+M,不是 N×M。
Server 能暴露什么
MCP Server 向 Client 暴露三种原语:
Tools:可执行函数。AI 可以调用它去做事——查数据库、发邮件、跑命令。是”动作”。
Resources:数据源。文件内容、数据库 schema、API 响应——AI 可以读,但不执行。是”上下文”。
Prompts:可复用模板。预定义的 system prompt、few-shot 示例——结构化地告诉 AI 怎么处理某类任务。是”指令”。
三种原语不是并列的装饰,是有意区分的设计:动作 / 上下文 / 指令,分开管理,分开权限控制。

发现机制统一:tools/list、resources/list、prompts/list——Client 主动查询 Server 有什么,Server 动态返回当前可用的列表。Server 上线新工具,Client 会收到通知,不需要重启。
最简实现:一个 MCP Server
用 Python SDK 写一个连接数据库的 MCP Server,核心代码:
●●●from mcp.server.fastmcp import FastMCPimport psycopg2mcp = FastMCP("pg-readonly")@mcp.resource("schema://public")def get_schema() -> str: """暴露数据库 schema 作为 Resource""" conn = psycopg2.connect(DATABASE_URL) cur = conn.cursor() cur.execute(""" SELECT table_name, column_name, data_type FROM information_schema.columns WHERE table_schema = 'public' ORDER BY table_name, ordinal_position """) return "\n".join(f"{r[0]}.{r[1]}: {r[2]}" for r in cur.fetchall())@mcp.tool()def query(sql: str) -> str: """执行只读 SQL,返回结果""" if not sql.strip().upper().startswith("SELECT"): return "只允许 SELECT 查询" conn = psycopg2.connect(DATABASE_URL) cur = conn.cursor() cur.execute(sql) return str(cur.fetchall())if __name__ == "__main__": mcp.run()
这个 Server 暴露了:一个 Resource(schema)+ 一个 Tool(只读查询)。
接入 Claude Code 只需要在配置里加:
●●●{ "mcpServers": { "pg-readonly": { "command": "python", "args": ["pg_server.py"] } }}
之后 Claude Code 就能看到这个数据库的 schema,能用自然语言写 SQL 查询,不需要你再做任何额外集成。换成 Cursor 或 VS Code,同一个 Server,同一个配置格式,接法一样。
这就是”写一次,到处用”。
标准化比能力更重要
一个工具能力再强,如果每次接入都要重写,它的边际成本就不会降。
MCP 的价值不是让工具”更强”,是让工具的接入成本趋近于零。
结果已经在发生:2024 年 11 月 25 日 MCP 发布后,VS Code(官方文档已将其列为 Host 示例)、Cursor、ChatGPT 均已支持 MCP 生态。Zed、Replit、Codeium、Sourcegraph 也已在早期接入。没有厂商愿意在别人建好的生态里缺席。
三件事能带走
1. 判断一个工具要不要接 MCP,就问一句话
这个工具以后会接多个 AI 应用吗?会的话,先写 MCP Server,不要直接写 function call。一次接入,后续每个 AI 应用免费得到。
2. Tools / Resources / Prompts 不是同一个东西
Tools 是让 AI 做事,Resources 是给 AI 看背景,Prompts 是告诉 AI 怎么想。接数据库,schema 放 Resource,查询放 Tool,写 SQL 的风格指南放 Prompt。分开,权限好控制。
3. 本地用 stdio,远程用 HTTP
MCP 支持两种传输:stdio 接本地进程(零网络开销,适合开发环境),Streamable HTTP 接远程服务(支持认证、多客户端,适合生产)。选错传输方式会带来不必要的复杂度。
这个系列
上一讲说执行权转移了,这一讲解释了工具生态怎么被标准化的。没有 MCP,执行权转移只是一个想法,工具还是各自为政。
下一讲:Claude Code 架构拆解 — 终端里的 agent 是怎么工作的
MCP 发布日期来源:anthropic.com/news/model-context-protocol(2026-04-25 核实)。Host/Client/Server 架构、STDIO/HTTP 传输层、Tools/Resources/Prompts 三原语来源:modelcontextprotocol.io/docs/learn/architecture(2026-04-25 核实)。代码示例基于 MCP Python SDK FastMCP 接口。