 夜雨聆风
夜雨聆风





每次跟着AI榜单换工具,你损失的不只是时间
周五凌晨,OpenAI发布了GPT-5.5。
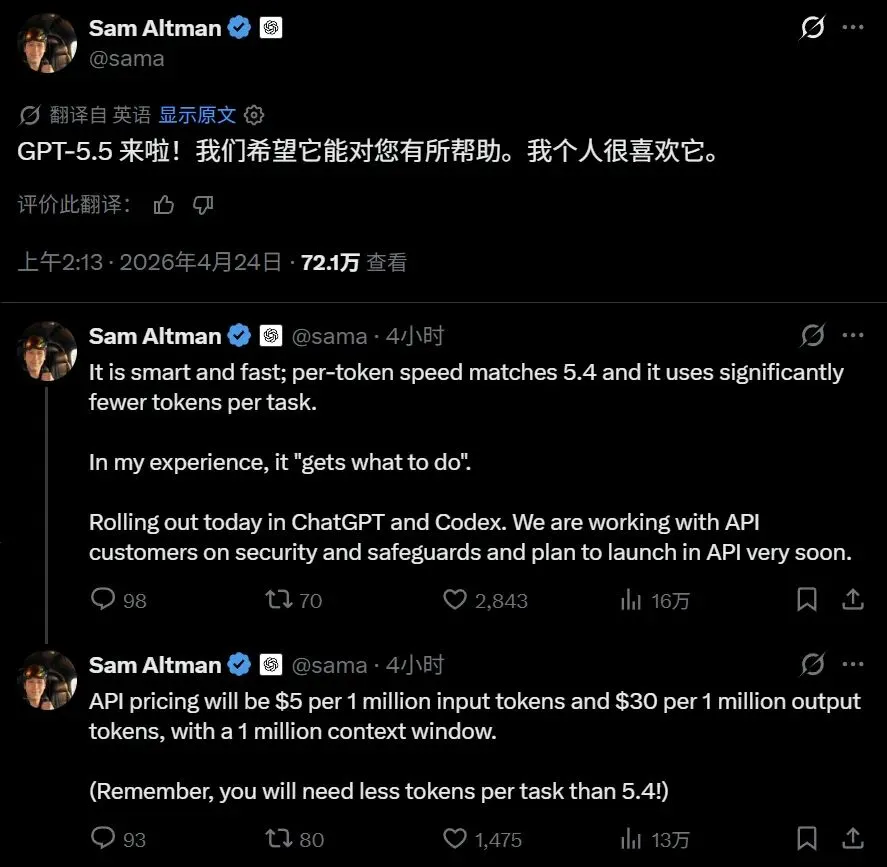
你可能已经刷到那条消息了。
“推理能力更强、代码能力更稳定、token消耗是竞品的一半。”
还有英伟达工程师的那句话:“失去GPT-5.5的访问权限,感觉就像肢体被截肢了一样。”
你心动了。准备注册,准备切换,准备把现在的工作流迁过去。
先等一下。你上一次因为榜单换工具,是什么时候?花了多少时间重新摸索用法?最后用了多久,又悄悄换回去了?
这不是你的问题,是你信错了一个东西。
01. 榜单是怎么来的
AI模型发布之前,要经过测试,测试方式是准备一批题目,数学题、阅读理解、逻辑推理、常识问答,让模型来答,看答对多少。答对越多,分数越高,榜单排名越靠前。
听起来很合理,但这里有一个问题:这些题目是固定的,而且是公开的。
02. 测试题,可能就在它的作业本里
想象一个学生,提前知道了期末考试要考哪些题,于是他把这些题全部背了一遍,考试那天,全答对了,考了满分。
你会觉得他真的学懂了吗?
AI面临的是同样的处境。模型在训练时,吃进去了互联网上几乎所有的文字,包括那些用来测试它的题目和答案。
所以当测试来临,它答对了,但不一定是因为它真的会,而是因为它之前见过这道题。
这个问题有个专门的名字:数据污染,测试集被污染进了训练数据,榜单上的高分,有一部分是靠背题得来的。
说难听一点,你看到的那张全是绿色箭头的表格,有可能是一场精心设计的开卷考试的成绩单。你拿它当择优标准,本身就是被人算计了。
03. 榜单还有另一个问题
就算没有数据污染,榜单的评估方式本身也有局限,GPT-5.5这次评测领先的维度,复杂推理、CUDA内核编写、多智能体协作。
专业性很强。
但你用AI是让它干什么的?写周报、整理会议纪要、头脑风暴、回复邮件。
它能写CUDA内核,跟它能不能帮你把周报写得不像机器人,没有任何关系。
榜单测的是它在考场上的表现,不是它在你工位上的表现,这是两件完全不同的事。
04. 所以榜单完全没用吗
也不是,榜单能帮你快速筛掉明显很弱的模型,缩小选择范围,但它只能告诉你”这个模型在考场上表现不错”,不能告诉你”这个模型适合你”。
就像找工作,简历漂亮、名校毕业是一个参考,但真正决定这个人适不适合这个岗位,还得实际合作过才知道。
榜单是简历,不是工作表现。
05. 你需要的是自己的评估标准
既然榜单不够用,怎么判断哪个模型更适合你?答案很简单:用你自己真实的任务去测。
第一步:列出你最常用AI做的三件事
就三件,不用多。
比如:写周报、整理会议纪要、头脑风暴选题,这三件事,就是你的个人测试集。
第二步:用同样的任务测试你想比较的模型
把同一个任务原封不动丢给两个模型,看结果,不要用榜单上的题,用你真实工作里的东西。
第三步:用你自己的标准打分
不是看哪个回答更长,不是看哪个格式更好看,就问自己一个问题:这个回答,我能直接用吗?顺不顺?顺的那个,就是适合你的。
一个更省力的方法
如果你懒得做上面那套流程,有个更快的方式:找一个你之前用AI做过、但结果不满意的任务,拿去测新模型。
你已经知道那个任务”正确答案”大概是什么,所以你能很快判断新模型有没有做得更好。
这比看任何榜单都管用。
最后说一句
GPT-5.5今天发布,下一个”史上最强”三个月后还会来,如果你每次都跟着榜单跑,你会一直在迁移、一直在适应、一直在重新摸索新工具的用法。
时间在流失,工作流在被打断。
你以为自己在追进步,其实只是在原地折腾。
说句安慰又真实的话:在AI时代,只要你学的足够慢就可以不用学。🤣
找到适合你的那个模型,用熟它,稳定输出。这一件事做到,比跟着榜单换一百次工具都值钱。不建立自己的评估标准,下次新模型发布你还会心动,还会迁移,还会浪费半天时间再换回来。