打破AI唯GPU论:谁能成为关键变量CPU的承接者?
 众所周知,过去几年,AI产业几乎被一种单一叙事所主导—“算力即GPU”。从大模型训练到推理部署,从数据中心建设到资本投入,GPU几乎成为所有讨论的核心关键词。但当AI从“模型竞赛”逐渐走向“应用落地”,一个正在发生的变化是算力的内涵正在被重新定义。特别是在智能体AI、实时推理、多任务协同等新型应用场景不断涌现的背景下,CPU的角色正在从“配角”回归为“中枢”,加之中国算力体系重构与国产替代加速推进的大环境,以海光等为代表的国产高端CPU厂商,也自然开始站上更关键的位置。
如果仅从模型规模来看,AI似乎仍在延续“越大越强”的逻辑,但从应用层面观察,事情已经悄然发生了变化。大模型不再只是实验室里的能力展示,而是开始深入企业流程、行业场景乃至日常生活,这一转变带来的,并不仅仅是算力需求的增加,更是计算形态本身的重构。
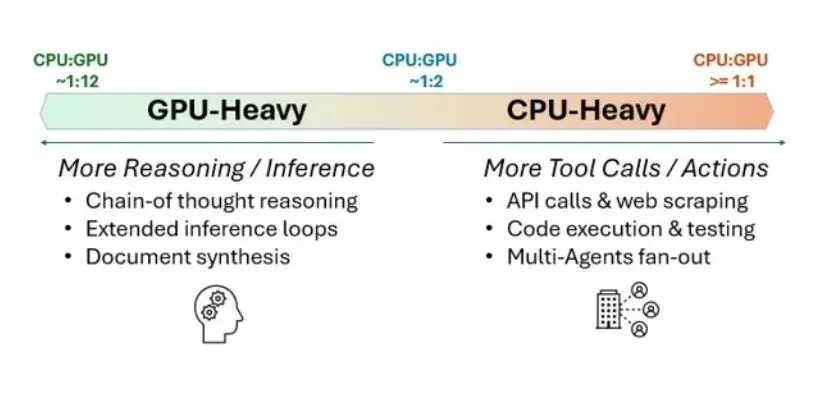
最直观的变化在于,AI不再是单一的推理过程,而是演变成一个持续运行的复杂系统。以智能体AI为例,一个看似简单的任务,往往需要被拆解为多个子任务,再分别调用不同模型或工具执行,期间还要进行状态管理、结果评估以及动态决策。而这种多步骤、多模块、多交互的运行方式,使得AI从“计算问题”转变为“流程问题”。
而在上述体系中,单纯依赖GPU的并行计算能力已经无法覆盖全部需求。这之中,尽管GPU依然擅长处理大规模矩阵运算,但当任务进入到调度、控制、数据流转等环节时,真正起主导作用的反而是CPU。也正因为如此,越来越多的研究发现,在复杂AI系统中,真正决定效率的往往不是算力峰值,是系统的协调能力。而这种变化也反映在基础设施层面。
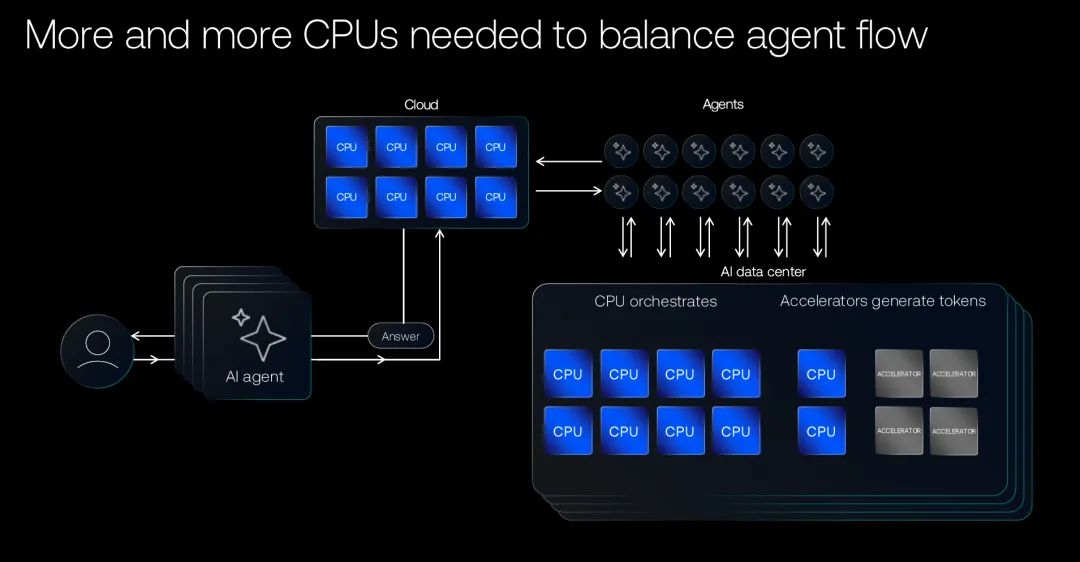
众所周知,过去的AI数据中心,更像是“GPU堆叠型架构”,CPU主要负责简单的数据分发和辅助任务,但随着AI应用复杂度的提升,这种架构逐渐暴露出瓶颈。
例如,在多任务推理场景中,GPU可能处于等待状态,而CPU却因为调度压力过大成为系统短板;在智能体应用中,大量时间消耗在工具调用与数据处理上,这些都无法通过增加GPU来解决。
正是在这样的背景下,CPU与GPU的配比正在发生变化。例如传统AI集群中,CPU与GPU的比例通常在1:4甚至更低,而在智能体和实时推理驱动下,一些云厂商的新架构已经开始向1:2甚至接近1:1演进。其背后的逻辑并不是“弱化GPU”,而是为了避免系统出现“算力空转”的结构性浪费。
与此同时,AI应用正在向边缘侧、终端侧扩展,AIPC、边缘推理设备以及行业专用系统不断涌现,这些场景对功耗、响应速度以及系统稳定性的要求更高,而这些能力的实现,同样离不开CPU的支撑。
可以说,当AI真正走出数据中心,进入真实世界,计算需求已经不再只是更强,而是更复杂。也正是在这样的背景下,市场开始重新审视一个被长期忽视的问题,即在AI系统中,真正不可或缺的不只是算力本身,是其该如何被组织与调用,而这正是CPU的核心价值所在。
如上述,当市场终于意识到“强GPU+弱CPU”的配置在智能体时代会导致严重的系统瓶颈时,全球范围内对高性能CPU的价值评估体系正在经历一场历史性重估。需要说明的是,这种重估不再仅是停留在技术参数的比较,而是深度映射到了全球供应链的供需博弈与芯片巨头的战略布局之中。
最典型的表现就是2026年初,英特尔全球渠道主管Dave Guzzi公开预警,高端服务器CPU正在经历新一轮的供应危机,而这种紧缺并非由于产能不足,而是由“工作负载结构性变化”驱动的需求激增。具体表现为,随着Agentic AI的普及,超大规模云服务商(CSP)发现,为了支撑起复杂的智能体集群,必须大规模提升服务器中CPU的配置比例。过去,一台AI服务器常见的配置是2颗CPU搭配8颗GPU,但为了应对日益沉重的逻辑编排和I/O吞吐任务,最新的架构正在向1:2甚至1:1的极端配比演进。而这种结构性的需求变化,让CPU的身价在算力成本结构中迅速上修。
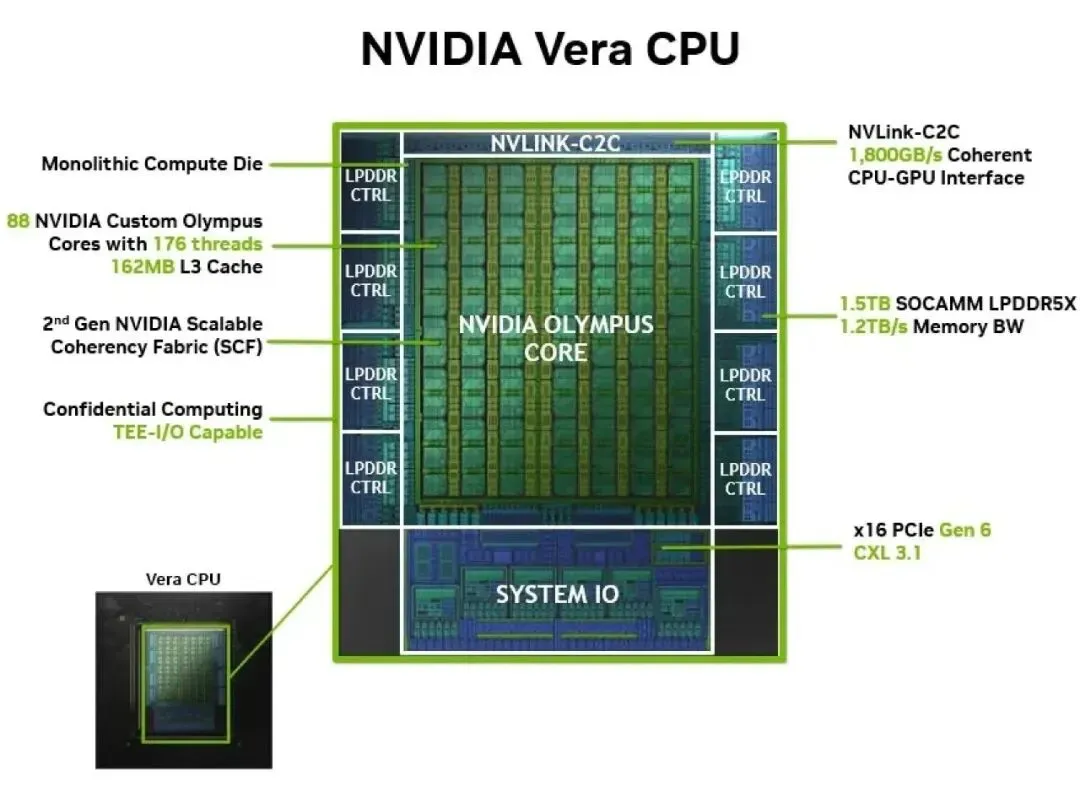
值得一提的是,英伟达作为GPU时代的绝对旗手,在其最新的GTC大会上,竟然将大量的篇幅留给了自研的Vera CPU,并高调宣布开始单独销售CPU,这一举动打破了其长期以来“以GPU为绝对中心”的商业神话。究其原因,英伟达深知,要实现真正的AGI(通用人工智能)闭环,必须掌握负责逻辑编排的“主脑”—CPU。
与此同时,微软、谷歌、亚马逊等云巨头也在2025—2026年间密集发布了拥有百核以上规模的自研CPU(如Cobalt 200、Axion系列等)。而这些巨头不计成本投入CPU研发的唯一核心逻辑在于,在智能体时代,CPU不仅是算力补充,更是系统调度的核心枢纽。谁能定义高性能CPU,某种程度上也就掌握了AI系统的“运行规则”。
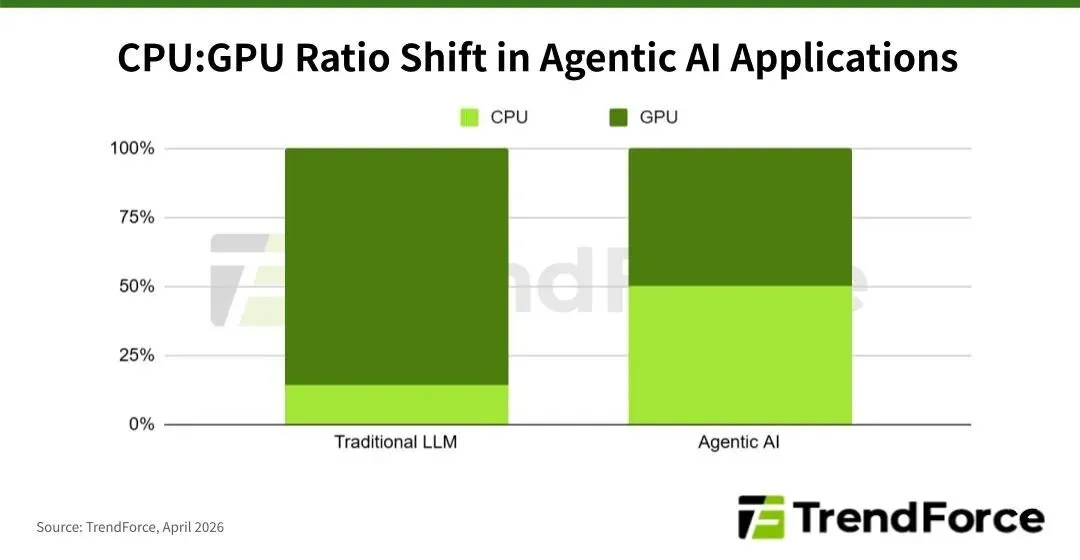
而从更深的产业维度看,CPU重要性的重现,标志着AI计算从“野蛮生长”进入了“精耕细作”的阶段。对此,有券商研报指出,在Agentic AI主导的算力市场中,CPU的价值占比正在经历从20%向40%,甚至更高的比例回归,计算不再是单纯的数值运算,而是演变成了复杂的系统工程。在这样的背景下,CPU不再是按核心数计价的普通硬件,而是作为“算力底座的核心”,其单核主频、缓存深度以及与外部系统的连接能力,都成为了AI应用能否落地的关键。正是这种价值重构,让原本被资本市场低估的CPU领军企业,重新回到了产业核心。
综上,当CPU重新回到产业视野中心时,一个更现实的问题随之浮现,那就是在中国市场,这一轮CPU需求与价值重估,将由谁来承接?
从技术路径与产业现实来看,答案很大程度上仍然指向x86体系。
原因在于,尽管Arm等架构近年来快速发展,但在服务器和企业级应用领域,x86依然拥有最深厚的软件生态积累,并具体体现在,从操作系统到数据库,从中间件到行业应用,大量核心软件都围绕x86构建,而这种生态并非短时间可以替代,尤其对于金融、电信、政务等关键行业,稳定性与兼容性甚至高于单点性能,这也决定了CPU国产化不可能简单“推倒重来”,而更需要在既有生态上实现平滑过渡。正是在这样的背景下,海光CPU的路径显得尤为现实且关键。
事实是,通过兼容x86指令集,海光在很大程度上保留了原有x86软件生态,使用户能够在无需大规模改造系统的前提下完成国产替代。而这种“低迁移成本”的优势,使其在信创推进过程中迅速获得落地空间,尤其是在对系统连续性要求极高的行业中,更具实际可行性。需要指出的是,这种路径本质上是一种工程化解法,即不是从零构建新体系,而是在既有体系中逐步实现自主可控,其虽在宣传上不具备“颠覆性叙事”,但在当下复杂的产业环境中,反而更具落地能力。
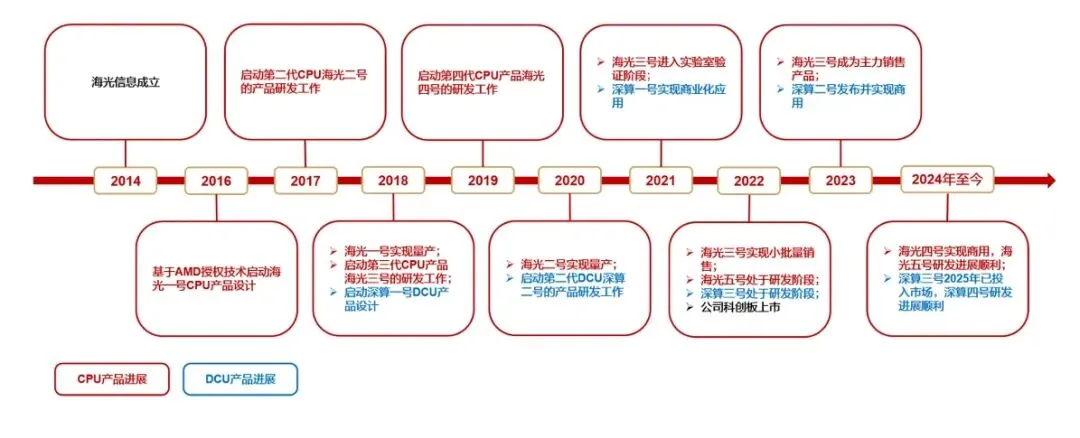
值得一提的是,在技术层面,海光CPU已经完成了从“跟随”到“并跑”的跃迁。通过“销售一代、验证一代、研发一代”的严谨产品策略,最新的海光四号(G408)系列在核心数、单核处理能力以及PCIe 5.0的适配上,已经精准契合了前述提到的AI智能体对“逻辑编排”的苛刻要求。例如在Agentic AI任务流中,海光CPU能够高效处理频繁的线程切换和复杂的条件分支,其深厚的缓存设计确保了在处理多模态数据清洗时的高吞吐量。
对此相关研报显示,在多个国产化替代项目中,海光CPU在复杂业务逻辑处理下的实测性能,已经能够与国际大厂的至强、EPYC系列同台竞技,真正解决了国产算力“好用不好用”的终极命题。
更关键的是,海光CPU正在成为中国AI产业的“安全底座”。众所周知,随着2026年全球地缘技术竞争的常态化,高端处理器的自主可控已不再是选项,而是生存的基础。针对于此,海光通过对x86架构的深度消化吸收与自主创新,构建起了一套从指令集到微架构完全自主可控的研发体系,使其在面对全球供应链波动时,能够为国内的金融、能源、电力等核心关键基础设施提供安全可靠的算力支撑。
可以预见,在Agentic AI接管越来越多决策流程的未来,谁掌握了CPU这一“逻辑中枢”,谁就更有能力掌控整个系统的运行节奏。而在中国市场,这一角色正在变得越发重要。
写在最后:如果说过去的AI竞争是“谁拥有更多GPU”,那么未来的竞争更像是“谁能构建更高效的算力系统”。在这一转变过程中,CPU的价值不再隐形,而是逐渐显性化,即AI越复杂,对调度能力的要求越高;应用越真实,对通用计算的依赖越强;生态越重要,对兼容性的需求越明显。这些因素共同作用,使CPU重新成为算力体系中的关键变量。
需要再次强调的是,这并非CPU取代GPU,而是算力体系从单点性能竞争走向系统效率竞争的必然结果。而在中国市场,这一变化叠加国产替代的大趋势,使得海光这样的厂商,不只是这一轮CPU需求与价值重估的承接者,更有可能成为AI新基础设施的关键构建者。
众所周知,过去几年,AI产业几乎被一种单一叙事所主导—“算力即GPU”。从大模型训练到推理部署,从数据中心建设到资本投入,GPU几乎成为所有讨论的核心关键词。但当AI从“模型竞赛”逐渐走向“应用落地”,一个正在发生的变化是算力的内涵正在被重新定义。特别是在智能体AI、实时推理、多任务协同等新型应用场景不断涌现的背景下,CPU的角色正在从“配角”回归为“中枢”,加之中国算力体系重构与国产替代加速推进的大环境,以海光等为代表的国产高端CPU厂商,也自然开始站上更关键的位置。
如果仅从模型规模来看,AI似乎仍在延续“越大越强”的逻辑,但从应用层面观察,事情已经悄然发生了变化。大模型不再只是实验室里的能力展示,而是开始深入企业流程、行业场景乃至日常生活,这一转变带来的,并不仅仅是算力需求的增加,更是计算形态本身的重构。
最直观的变化在于,AI不再是单一的推理过程,而是演变成一个持续运行的复杂系统。以智能体AI为例,一个看似简单的任务,往往需要被拆解为多个子任务,再分别调用不同模型或工具执行,期间还要进行状态管理、结果评估以及动态决策。而这种多步骤、多模块、多交互的运行方式,使得AI从“计算问题”转变为“流程问题”。
而在上述体系中,单纯依赖GPU的并行计算能力已经无法覆盖全部需求。这之中,尽管GPU依然擅长处理大规模矩阵运算,但当任务进入到调度、控制、数据流转等环节时,真正起主导作用的反而是CPU。也正因为如此,越来越多的研究发现,在复杂AI系统中,真正决定效率的往往不是算力峰值,是系统的协调能力。而这种变化也反映在基础设施层面。
众所周知,过去的AI数据中心,更像是“GPU堆叠型架构”,CPU主要负责简单的数据分发和辅助任务,但随着AI应用复杂度的提升,这种架构逐渐暴露出瓶颈。
例如,在多任务推理场景中,GPU可能处于等待状态,而CPU却因为调度压力过大成为系统短板;在智能体应用中,大量时间消耗在工具调用与数据处理上,这些都无法通过增加GPU来解决。
正是在这样的背景下,CPU与GPU的配比正在发生变化。例如传统AI集群中,CPU与GPU的比例通常在1:4甚至更低,而在智能体和实时推理驱动下,一些云厂商的新架构已经开始向1:2甚至接近1:1演进。其背后的逻辑并不是“弱化GPU”,而是为了避免系统出现“算力空转”的结构性浪费。
与此同时,AI应用正在向边缘侧、终端侧扩展,AIPC、边缘推理设备以及行业专用系统不断涌现,这些场景对功耗、响应速度以及系统稳定性的要求更高,而这些能力的实现,同样离不开CPU的支撑。
可以说,当AI真正走出数据中心,进入真实世界,计算需求已经不再只是更强,而是更复杂。也正是在这样的背景下,市场开始重新审视一个被长期忽视的问题,即在AI系统中,真正不可或缺的不只是算力本身,是其该如何被组织与调用,而这正是CPU的核心价值所在。
如上述,当市场终于意识到“强GPU+弱CPU”的配置在智能体时代会导致严重的系统瓶颈时,全球范围内对高性能CPU的价值评估体系正在经历一场历史性重估。需要说明的是,这种重估不再仅是停留在技术参数的比较,而是深度映射到了全球供应链的供需博弈与芯片巨头的战略布局之中。
最典型的表现就是2026年初,英特尔全球渠道主管Dave Guzzi公开预警,高端服务器CPU正在经历新一轮的供应危机,而这种紧缺并非由于产能不足,而是由“工作负载结构性变化”驱动的需求激增。具体表现为,随着Agentic AI的普及,超大规模云服务商(CSP)发现,为了支撑起复杂的智能体集群,必须大规模提升服务器中CPU的配置比例。过去,一台AI服务器常见的配置是2颗CPU搭配8颗GPU,但为了应对日益沉重的逻辑编排和I/O吞吐任务,最新的架构正在向1:2甚至1:1的极端配比演进。而这种结构性的需求变化,让CPU的身价在算力成本结构中迅速上修。
值得一提的是,英伟达作为GPU时代的绝对旗手,在其最新的GTC大会上,竟然将大量的篇幅留给了自研的Vera CPU,并高调宣布开始单独销售CPU,这一举动打破了其长期以来“以GPU为绝对中心”的商业神话。究其原因,英伟达深知,要实现真正的AGI(通用人工智能)闭环,必须掌握负责逻辑编排的“主脑”—CPU。
与此同时,微软、谷歌、亚马逊等云巨头也在2025—2026年间密集发布了拥有百核以上规模的自研CPU(如Cobalt 200、Axion系列等)。而这些巨头不计成本投入CPU研发的唯一核心逻辑在于,在智能体时代,CPU不仅是算力补充,更是系统调度的核心枢纽。谁能定义高性能CPU,某种程度上也就掌握了AI系统的“运行规则”。
而从更深的产业维度看,CPU重要性的重现,标志着AI计算从“野蛮生长”进入了“精耕细作”的阶段。对此,有券商研报指出,在Agentic AI主导的算力市场中,CPU的价值占比正在经历从20%向40%,甚至更高的比例回归,计算不再是单纯的数值运算,而是演变成了复杂的系统工程。在这样的背景下,CPU不再是按核心数计价的普通硬件,而是作为“算力底座的核心”,其单核主频、缓存深度以及与外部系统的连接能力,都成为了AI应用能否落地的关键。正是这种价值重构,让原本被资本市场低估的CPU领军企业,重新回到了产业核心。
综上,当CPU重新回到产业视野中心时,一个更现实的问题随之浮现,那就是在中国市场,这一轮CPU需求与价值重估,将由谁来承接?
从技术路径与产业现实来看,答案很大程度上仍然指向x86体系。
原因在于,尽管Arm等架构近年来快速发展,但在服务器和企业级应用领域,x86依然拥有最深厚的软件生态积累,并具体体现在,从操作系统到数据库,从中间件到行业应用,大量核心软件都围绕x86构建,而这种生态并非短时间可以替代,尤其对于金融、电信、政务等关键行业,稳定性与兼容性甚至高于单点性能,这也决定了CPU国产化不可能简单“推倒重来”,而更需要在既有生态上实现平滑过渡。正是在这样的背景下,海光CPU的路径显得尤为现实且关键。
事实是,通过兼容x86指令集,海光在很大程度上保留了原有x86软件生态,使用户能够在无需大规模改造系统的前提下完成国产替代。而这种“低迁移成本”的优势,使其在信创推进过程中迅速获得落地空间,尤其是在对系统连续性要求极高的行业中,更具实际可行性。需要指出的是,这种路径本质上是一种工程化解法,即不是从零构建新体系,而是在既有体系中逐步实现自主可控,其虽在宣传上不具备“颠覆性叙事”,但在当下复杂的产业环境中,反而更具落地能力。
值得一提的是,在技术层面,海光CPU已经完成了从“跟随”到“并跑”的跃迁。通过“销售一代、验证一代、研发一代”的严谨产品策略,最新的海光四号(G408)系列在核心数、单核处理能力以及PCIe 5.0的适配上,已经精准契合了前述提到的AI智能体对“逻辑编排”的苛刻要求。例如在Agentic AI任务流中,海光CPU能够高效处理频繁的线程切换和复杂的条件分支,其深厚的缓存设计确保了在处理多模态数据清洗时的高吞吐量。
对此相关研报显示,在多个国产化替代项目中,海光CPU在复杂业务逻辑处理下的实测性能,已经能够与国际大厂的至强、EPYC系列同台竞技,真正解决了国产算力“好用不好用”的终极命题。
更关键的是,海光CPU正在成为中国AI产业的“安全底座”。众所周知,随着2026年全球地缘技术竞争的常态化,高端处理器的自主可控已不再是选项,而是生存的基础。针对于此,海光通过对x86架构的深度消化吸收与自主创新,构建起了一套从指令集到微架构完全自主可控的研发体系,使其在面对全球供应链波动时,能够为国内的金融、能源、电力等核心关键基础设施提供安全可靠的算力支撑。
可以预见,在Agentic AI接管越来越多决策流程的未来,谁掌握了CPU这一“逻辑中枢”,谁就更有能力掌控整个系统的运行节奏。而在中国市场,这一角色正在变得越发重要。
写在最后:如果说过去的AI竞争是“谁拥有更多GPU”,那么未来的竞争更像是“谁能构建更高效的算力系统”。在这一转变过程中,CPU的价值不再隐形,而是逐渐显性化,即AI越复杂,对调度能力的要求越高;应用越真实,对通用计算的依赖越强;生态越重要,对兼容性的需求越明显。这些因素共同作用,使CPU重新成为算力体系中的关键变量。
需要再次强调的是,这并非CPU取代GPU,而是算力体系从单点性能竞争走向系统效率竞争的必然结果。而在中国市场,这一变化叠加国产替代的大趋势,使得海光这样的厂商,不只是这一轮CPU需求与价值重估的承接者,更有可能成为AI新基础设施的关键构建者。
 最近得到很多朋友的关注和互动,并且表示现在八卦文满天飞的情况下你们的文章是否过于正统过于产业了。
我要说的是,我们始终坚持写有观点有深度的文章,而非短平快的新闻传送或者八卦娱乐,为此我们将一如既往,数十年如一日,坚持自我,不忘初心,方得始终!
最近得到很多朋友的关注和互动,并且表示现在八卦文满天飞的情况下你们的文章是否过于正统过于产业了。
我要说的是,我们始终坚持写有观点有深度的文章,而非短平快的新闻传送或者八卦娱乐,为此我们将一如既往,数十年如一日,坚持自我,不忘初心,方得始终!
 夜雨聆风
夜雨聆风