 夜雨聆风
夜雨聆风





研究透视:OpenAI评价体系竟成了AI“胡编”推手 | Nature
大语言模型,有时会产生自信且看似合理的错误信息(即“幻觉hallucinations”),这限制了大语言模型的可靠性。先前的研究已经提供了多种解释和有效的缓解方法,例如,检索与工具使用,基于一致性的自验证,以及基于人类反馈的强化学习。然而,即便在最先进的语言模型中,这一幻觉问题,仍然存在。
大语言模型为什么明明不知道答案,却还总喜欢一本正经地猜?近日,OpenAI公司在Nature上发文,给出了核心判断很尖锐:问题不只是模型能力不够,也不只是训练数据有噪声,而是今天最常见的训练目标和评测方式,下一词预测和基于准确率的评估,本身就在在不经意间系统性奖励了无根据“乱猜”。
这个问题拆成了两层,第一层是预训练。只要模型的核心目标还是“预测下一个词”,就天然更偏向给出一个看起来合理的续写,而不是停下来承认自己不知道。第二层是评测。今天很多主流榜单和基准测试,基本都按准确率或做对比例来打分,在这种规则里,“不知道”通常和“答错”一样都记 0 分,于是模型最理性的策略就不是谨慎,而是尽量猜。
为此,不是再一次泛泛地说“大模型会幻觉”,而是把这件事改写成了一个更具体的问题:幻觉不只是模型的缺陷,也是一种被现有激励机制不断放大的结果。

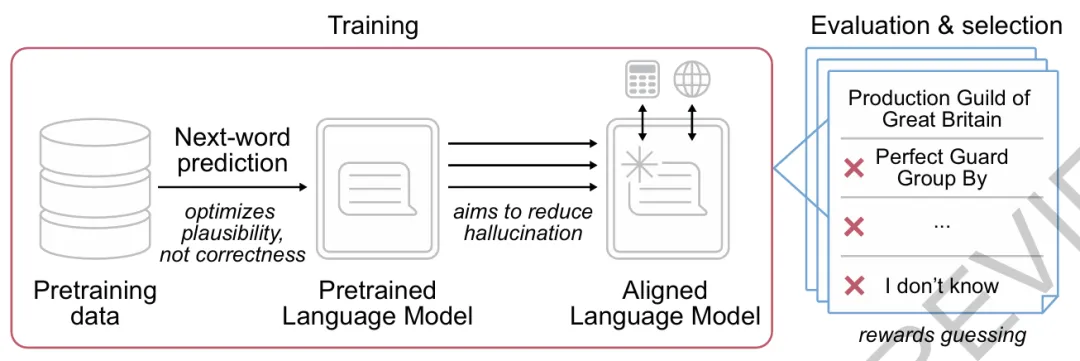

AI“胡编”归因于激励设计问题,而不只是模型结构或数据问题。一旦把规则写清楚,减少幻觉就不必再和高分对着干。
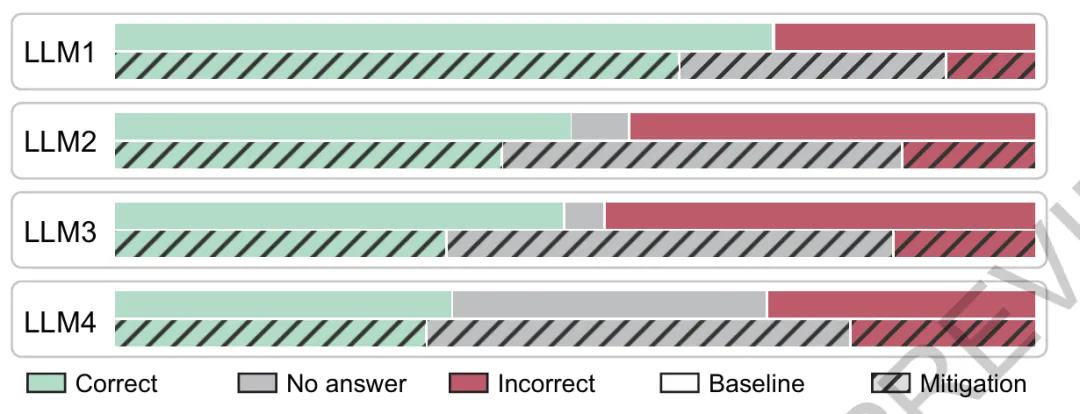
传统闭卷评分(closed‑rubric)准确率标准,这种缓解策略虽然确实减少了模型的错误回答,但同时也会降低正确回答的数量,因此在“准确率”这个头条指标上反而处于劣势。换句话说,模型明明变得更少胡编乱造了,却因为更频繁地选择弃权而在排行榜上不讨好。一旦改用开卷评分(open‑rubric),情况就完全不同了。无论是不设惩罚、轻度惩罚还是高额惩罚,只要模型明确知道当前采用的评分规则,缓解策略都更容易带来更高的得分。更直白地讲:在开卷评分下,减少幻觉终于可以和提升分数站在同一边。建议使用现有评估的开放评分标准变体,以逆转鼓励猜测的激励。将AI幻觉重新定义为激励问题,为通往更可靠的语言模型开辟了实践路径。