 夜雨聆风
夜雨聆风





2026,AI 为什么突然“变天”了:从 OpenClaw 到 AGI,罗福莉这场访谈讲透了什么?

过去两三年,很多人讨论 AI,关注点都在模型参数、榜单排名和生成效果上。但看完罗福莉这场访谈,一个很强烈的感受是:2026 年真正的分水岭,可能已经不是“谁的模型更会答题”,而是“谁先把 AI 从 Chatbot 变成 Agent”。
在罗福莉的叙述里,OpenClaw 不是一个普通产品,也不只是一个更好用的交互壳。它真正带来的冲击,是让她第一次非常具体地感受到,AI 已经不再只是一个回答问题的系统,而开始变成一个能长期记忆、持续执行、自己修正、还能不断吸收人类经验的行动系统。也正因为如此,她才会说,技术范式已经变了。
一、OpenClaw 的震撼,不在“能回答”,而在“能做事”
这场访谈最有意思的地方,是罗福莉一开始并不是 OpenClaw 的拥护者。她第一次看到它时,甚至有些排斥。在她原本的理解里,这无非是把 Claude Code 套上一层 IM 式界面,再配上一些更偏运营感的包装,比如 Skills 社区、本地化、24 小时在线这些概念。它看起来像产品定义上的创新,而不像底层范式的变化。
但真正上手之后,她的判断变了。她把使用 OpenClaw 前后,当成一个明显的技术分界点。原因不复杂:它让模型第一次表现出一种“持续完成任务”的能力,而不是“完成一轮对话”的能力。
这两者的差别非常大。Chatbot 的基本单位是一问一答;Agent 的基本单位是一整段任务链。它要理解目标、拆解步骤、调用工具、维护上下文、保留记忆,还要在过程中根据环境反馈不断修正。模型还是那个模型,但一旦进入这种框架,它能展现出来的上限会突然变高。
罗福莉提到一个关键判断:顶尖模型决定系统上限,但优秀的 Agent 框架会把中层模型的能力显著往上抬。也就是说,很多时候不是模型本身不够强,而是过去缺少一套足够复杂、足够开放、足够可改造的框架,把模型真正组织起来。
二、真正改变行业的,是“模型与框架共同进化”
这场访谈里最值得反复琢磨的一句话,是她对“自学习”的解释。她认为,所谓 Agent 的自学习,并不是模型凭空自己变强,而是模型和 Agent 架构一起往前走。
为什么这么说?因为在 OpenClaw 这样的开源框架里,用户不仅能调用模型,还能直接修改记忆系统、工作流和多 Agent 协作逻辑。罗福莉自己就提到,她会让顶尖模型帮她重写 Memory 系统、重新设计多 Agent 架构。模型不只是工具,也在反过来帮助人塑造框架;而框架一旦被塑造得更合理,哪怕换成 Sonnet 甚至国产模型,也会突然变得非常强。
这就是她所说的“双向流动”:一方面,模型在帮助人改造框架;另一方面,框架又在重新定义模型能力的释放方式。最终产生的结果,不是谁单方面提升,而是二者共同演化。
而开源的重要性,就在这里被放大了。闭源系统再强,用户也只能使用,无法真正介入内部逻辑;开源框架则允许整个社区把经验沉淀进去,让人类智慧持续注入 Agent。罗福莉特别强调,OpenClaw 把 Skills 社区带火,不只是因为它提供了一个插件市场,而是因为它创造了一种新的知识输入方式。很多企业内部的执行规范、隐性经验和工作习惯,原本不可能出现在公开预训练语料里,但可以通过 Skills 的形式,被人主动贡献给 Agent。
换句话说,互联网知识是预训练的燃料,而 Skills 这类结构化经验,是 Agent 时代新增的“高阶养料”。
三、为什么 Code 会突然变得这么重要?
访谈里还有一个非常核心的判断:Code 不只是程序员的生产资料,它还是一种极其优质的智能训练材料。
罗福莉给出的理由很直接。Agent 的任务天然是长程、多轮、强依赖的,而真正足够长、依赖关系又足够密集的数据,在现实世界里并不多。书籍虽然也长,但信号太发散;代码则不一样,文件之间、函数之间、模块之间有极强的逻辑勾连。模型在这种数据上训练,天然更容易学会长上下文建模和复杂依赖推理。
这意味着,Code 的价值远不止“让模型会写程序”。更深一层看,软件开发本身就是一种高复杂度、多步骤、可验证的任务。如果模型能在这个领域建立稳定能力,它的泛化潜力就会自然溢出到别的领域。这也是为什么她接触 OpenClaw 后,紧接着去思考的是:怎么把 Code 的这种泛化力外延到更多任务上。
所以,今天大家看到“AI 写代码”越来越强,不能只理解成它在取代程序员的部分工作。更准确地说,代码正在成为通往更强通用智能的一条训练捷径。
四、Agent 时代,真正稀缺的是长上下文的效率

罗福莉在访谈里反复强调一个词:Long Context。
在她看来,Agent 时代对长上下文的需求,不是“更大一点就行”,而是会成为底层前提。因为一个真正复杂的任务,执行链条可能极长,涉及大量历史状态、环境信息、工具反馈和中间结果。如果上下文不够长,模型根本无法维持任务连续性;如果上下文虽然长、但推理太贵太慢,那系统又无法真正投入生产。
这也是为什么 MiMo V2 在设计时,把 Long Context efficiency 放到极高优先级,并选择了 Hybrid Attention 和 MTP 这样的路线。她的解释很明确:未来真正有价值的,不只是把上下文做长,而是把长上下文做得“足够便宜、足够快”。只有这样,百万级、千万级甚至更大规模的上下文才有现实意义。
这背后反映出的,其实是 AI 竞争重心的变化。过去很多人关心的是“模型能不能做”,现在更关键的问题变成了“模型能不能稳定、低成本、高速度地做”。一旦 AI 要进入真实工作流,成本和效率就不再是次要问题,而是决定能否落地的核心约束。
五、MiMo V2 的真正目标:不是单点模型,而是类人的协作体系
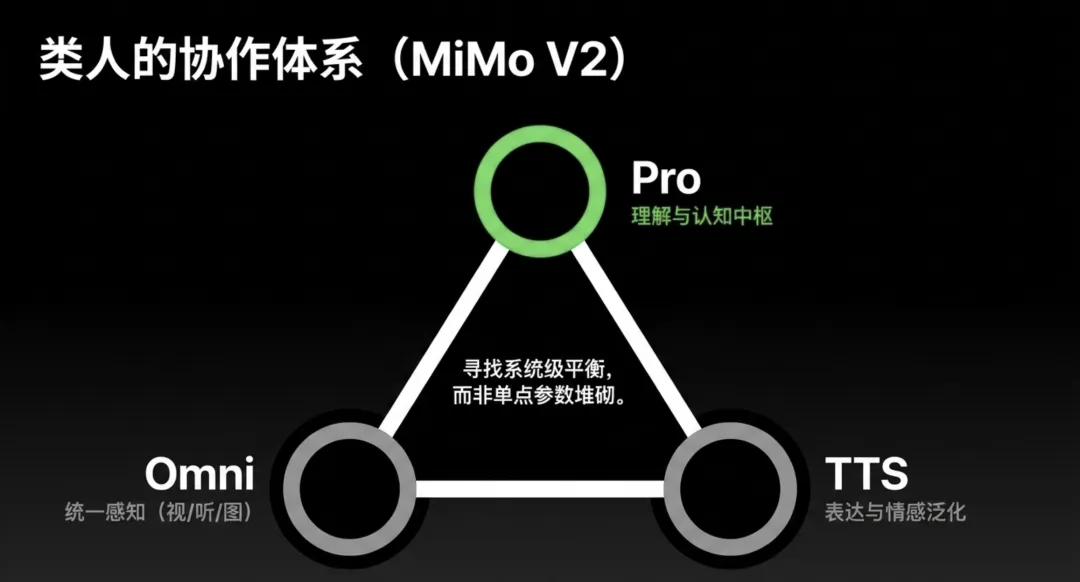
访谈进入 MiMo V2 后,罗福莉用了一个很有戏剧性的词:“我们觉醒了”。这个觉醒,不只是说模型效果变好了,而是说他们突然意识到,语言模型、全模态理解模型和语音生成模型,原来可以在 Agent 范式下被重新组织成一个协作系统。
这就是 Pro、Omni 和 TTS 同时推进的逻辑。
Pro 负责理解和认知,是整个体系的语言与推理中枢;Omni 负责感知,处理视频、音频、图片和文本的统一理解;TTS 负责表达,把系统的输出进一步扩展到声音。三者并不是在追求“把所有能力都塞进一个超大模型”,而是在成本、速度和效果之间寻找新的系统平衡。
其中最值得注意的是她对 Omni 和 TTS 的判断。她认为,原生多模态训练带来的价值,不只是多看几张图、多听几段声音,而是可能让模型对世界的感知、常识和情绪理解更强。甚至在实际体验里,参数更小的 Omni,在情商和世界感知上,有时会比更大的纯语言模型表现得更好。至于 TTS,他们一开始只是想用一种更优雅的离散化架构去做语音,结果却意外发现,在大规模训练之后,模型展现出很强的风格泛化能力,甚至能够理解更复杂的自然语言 style 描述。

这说明,多模态和语音的价值,不只是“多一项功能”,而是在逐步补足 Agent 的感官和表达系统。
六、2026 年最重要的变化,不是模型更强,而是研究方法变了

访谈里还有一个很硬核、但非常重要的判断:Agent 范式会让 Post-train 和 Research 的地位大幅上升。
罗福莉给出了一组很有代表性的资源分配比例。她认为,在新的范式下,如果把研究、预训练、后训练分开看,一个合理的卡资源比例可能是 3:1:1。也就是说,研究本身所消耗的资源,甚至要比正式训练更多。为什么?因为 Agent 场景极度复杂,很多问题没法像过去那样提前定义清楚,必须通过大量实验、反复验证和基础设施快速迭代来摸索。
这就带来了团队组织方式的变化。过去更强调长期规划、确定性和稳定性;而现在,后训练和 RL Infra 更强调敏捷、容错和跨域协同。因为 Agent 任务链很长,训练和推理之间还可能存在异构环境差异,中间的“模糊地带”越来越多。一个只擅长在确定性世界里优化指标的团队,未必适合这个新时代。
这也是为什么她后面把话题延伸到了“人”。她反复提到,好奇心、热爱、愿意跟模型高频交互、愿意探索边界的人,会更适合这个范式。因为未来的核心竞争力,不只是写出一个更好的模型结构,而是持续发现边界、快速补齐边界、再把这些经验转成新的系统能力。
七、罗福莉真正想说的,也许是这句:生产力革命已经开始了

把整场访谈串起来看,罗福莉真正关心的,并不是某个模型能不能再刷高几分 benchmark,而是一个更大的问题:当 AI 真的开始替代大规模“枯燥劳动”之后,人类要把自己放在什么位置?
她的答案不是悲观的。恰恰相反,她认为这是一个生产力加速变革的时代。很多工作会被替代,但人也因此被迫去思考,自己的意义和价值到底是什么。她还提到,如果未来 AGI 真正到来,自己更感兴趣的事情,反而可能是推动基础科学研究,或者建立支持更长期研究的公益型组织。
这很能说明她看待 AI 的方式。对她来说,AI 不是一个孤立的商业产品,而是一种会重塑研究、组织、协作和创造方式的基础力量。
所以,这场访谈最值得记住的,不是某个技术名词,而是这条主线:过去几年,大模型是在学会“说话”;而从 2026 年开始,AI 正在学会“做事”、学会“协作”,甚至开始学会“帮助自己变强”。
这才是范式真正改变的地方。