 夜雨聆风
夜雨聆风





AI越强,团队越小,但人越关键
那是一次 Code Review。
我盯着屏幕上 AI 改完时区 bug 的 PR,心里隐约有点不对劲,于是问了它一句:
AI 沉默了几秒,然后老实回答:没有,是假设的。
后来一查,数据库里有些表存的是 UTC,有些表是本地时间,还有的表第三种格式。一个我以为修了三次就该结束的 bug,又往后拖了两个月。
那一刻我突然意识到一件事:这半年来,AI 写代码的速度确实非常快,但它有一些盲区,是它自己永远不会主动发现的。而且这些盲区是系统性的,会反复出现。
这篇文章想分享的,就是我们在 Floeva(我们正在做的一款智能健康戒指)开发过程中,AI 反复掉进同一类坑的真实记录,以及我后来怎么调整自己的工作方式来跟它配合。
如果你也在重度用 Claude Code、Cursor、Codex这类 AI 编程工具,或许会有点共鸣。
先说一下背景

这个产品的后端、客户端、数据管线,几乎所有代码都是我们和 AI 一起写出来的。团队不大,但想做的事不小,所以我们把 AI 用到了非常深的程度——不仅仅是”用 AI 写代码”,而是把整个团队的工作方式按 AI 的能力重新梳理了一遍。
在讲那些坑之前,先说说我们这套工作方式本身——它构成了那些坑的土壤,也是这半年我自己最有感触的一部分。
一、我们这套”AI 原生”工作方式
先说几条已经成为日常的:
这些点单拎出来都不算稀奇,很多团队也在做。但里面最让我意外、也最值得单独拎出来说的,是下面这一条——它是真的把”工作量”重新定义了。
我们的后台管理系统,干脆不做新增和编辑界面了
传统做法是:后端写完接口,前端要再为运营同学做一套增删改查的管理界面。改字段、加配置、调参数,全靠人在后台点点点。
我们的做法是:后台只做查询和展示,新增和编辑的界面一律不做。需要改数据?写一句话给 AI,AI 直接调接口改库。需要批量修复?AI 写脚本跑。需要新增配置?AI 在 SQL 里塞一行。
当然这有前提:你得对 AI 操作数据这件事建立信任,并且把生产环境的兜底(备份、操作日志、回滚)做扎实。但这是一次性投入,比维护一堆”用了又没多用”的运营页面值多了。
这件事本身也是一个隐喻——AI 不只是改写”怎么写代码”,它也在改写”我们到底需要哪些代码”。有些过去你以为必须做的工作量,在 AI 时代根本就不该做。
顺带一提,我们团队的PM,从 PM 的视角写了一篇姊妹篇,讲的是 AI 怎么把一个小团队的战斗力撑到能和大厂百人团队的竞品掰手腕——以及职责边界、招聘标准、PM 直接读代码这些更”组织层面”的变化。如果你看完这篇还想读一些更宏观的视角,强烈推荐去看下面这篇:
效率确实拉满。但效率拉满之后,新的问题就冒出来了——当 AI 写代码的速度远快于人 review 的速度,谁来兜底质量?
我们用半年时间、上百个 PR,踩出了一些规律。
二、AI 反复掉进的几个坑
坑一:Debug Bundle 全是空值
我们想给用户加一个”导出诊断信息”的功能,帮我们排查同步慢的问题。AI 接到任务,方案做得很漂亮:数据结构设计齐整,在编排器层加了时间戳记录,测试用例写完,Eval Criteria 全部通过。
发布。导出第一份真实用户的 Bundle,打开一看——所有时间字段都是 null。
人在这里就会停下来问:”等等,这些值怎么都是空的?”AI 不会。它的”测试通过”,验证的是结构存在,不是字段有值。
根因后来查清楚了:观测点放在了编排器层(看到的是”评估完了 → 进入静默同步”这种宏观状态),但真实执行发生在 BLE 层(”连接 → 拉取 → 重算 → 上传”)。编排器层的”阶段”,和真实执行的”阶段”,根本不是一回事。
AI 在错误的抽象层放观测点,而它没有意识到。
坑二:「没改的代码」其实从来就没工作过
TopBar 同步完之后卡住不消失。AI 分析后给出修复方案,Plan 里写得清清楚楚:
人接手之后画了一张状态机矩阵,把所有路径和状态转换都列出来——发现 Path 1 里 syncing → idle 这个转换根本没有 handler。也就是说,Path 1 从来就没正确工作过。
AI 默认了一个非常隐蔽的假设:“不在我修改范围内的代码 = 已经验证能工作的代码”。这是错的。但它不会自己问”我没改的这段,真的能跑吗?”
坑三:优化引入了隐藏耦合
AI 给 Flow 重算逻辑加了短路判断——版本没变就跳过重算,性能直接起飞。单独测试,全绿。
上线之后用户报:“为什么我今天的 Flow 分还是昨天的?” 也就是上面提到的、戒指给用户看的那个核心数字——它没刷新。
查下来,重算逻辑跳过的同时,连带跳过了下游一个叫 DHR(用户每天看到的健康总览)的数据刷新。Flow 分要拿 DHR 的最新数据来算,DHR 没刷,Flow 分自然也是旧的。这个刷新本来是重算的”副作用”,AI 改的时候根本没意识到有这层依赖。
它能测试”我改的代码”,但它不会主动问:”谁在读我改的东西?“
坑四:时区,时区,还是时区
这个是最磨人的。最开始我们没把时区当回事,代码里到处直接写死 GMT+8。等用户开始跨时区使用,问题集中爆发。
我以为这是个小问题,几天就能改完。结果:改了一两个月。
每次 AI 给的修复方案看起来都对:
AI 每次都在基于一个未经验证的假设写代码。直到我学会在 Code Review 里反复问那一句:
三、AI 的盲区是系统性的
把上面这些坑放在一起看,你会发现它们不是孤立的失误,而是同一类问题的不同变体:
|
|
|
|
|---|---|---|
| 数据假设 |
|
|
| 下游追踪 |
|
|
| 抽象层错位 |
|
|
| 未改 ≠ 已验证 |
|
|
| 结构 ≠ 行为 |
|
|
这些问题的共同点是:AI 在”自己负责的范围内”做得很好,但它不会主动跨出这个范围去问问题。
而软件工程里大量真正的 bug,恰恰发生在范围的边界上。
四、半年下来,我对自己工作方式的几个调整
老实说,发现这些坑的过程,对我冲击挺大的。一开始我会有点烦躁——明明是 AI 写的代码,为什么我要花这么多精力 review?后来心态慢慢转过来:AI 不是用来替代我的,而是在重新定义我应该做什么。
写代码这件事,AI 八九不离十都能搞定。那剩下的那 10%,反而才是人真正应该死磕的地方。具体来说,我现在花更多时间在三件事上:
第一件:挑战假设
AI 写完 PR,我不再先看代码改得对不对,而是先看它的假设清单——它假设了数据是什么格式?它假设了哪些代码”不需要改”?每一个假设都要找证据。
第二件:做成本-收益判断
有一次 AI 报了个时区 bug,给了三个方案:A 重构数据模型(一周),B 加临时字段(一天),C 不修(影响 < 10 用户)。AI 倾向于选 A——技术上最干净。我选的是 B + 记录技术债。因为 Phase 5 马上要重构了,A 注定会被推翻。这种权衡,AI 不会主动做。
第三件:知道什么时候该看日志而不是加埋点
iOS 后台上传卡顿,AI 第一反应是加更多遥测。我直接去拉了服务器日志,5 秒钟定位到问题——服务器响应 250ms 以内,瓶颈在客户端。AI 那个方案,至少要再做 3 个 PR。
五、最重要的一条:教训要写成规则,不能靠记性
如果只能从这半年里带走一句话,那一定是这句。
我们一开始也试过”教训了之后下次注意”。结果每次新开一个 PR,AI 都是干净的上下文,它不记得上次踩过什么坑。同一个错,能换不同的马甲再犯一次。
后来我们改了做法:每次踩到一类新坑,就把教训直接写进项目规则文件。AI 不会自己记住,但只要规则在仓库里,它就会乖乖遵守。
到现在为止,我们项目里有几条规则就是这么沉淀下来的。挑两条最有用的,分享给在做类似事情的朋友——你可以直接抄作业,加进自己的 CLAUDE.md 或 cursor rules:
这一条直接终结了我们持续两个月的时区拉锯战。
这一条专治”AI 把没改的代码默认成正确的”这种错觉。
写到这,可能有人会觉得我在唱衰 AI 编程。其实不是。
这半年我们用 AI 写代码的速度,是过去的好几倍。如果没有它,Floeva 不可能这么快做到现在这个程度。AI 也让我们这个小团队,干出了过去要十几个人才能干的活。
但同样是这半年,我越来越清楚一件事:AI 越强,团队可以越小,但人反而越关键。关键不是写代码本身——这件事 AI 能干,而且越来越能干;关键是那些 AI 看不见的地方:挑战假设、做成本权衡、知道什么时候该看日志而不是加埋点、把踩过的坑写成下一次的规则。
它不是来替你写代码的同事,它更像一个非常勤奋、但缺乏长期记忆和跨边界思考的实习生。你不需要再帮他敲键盘,但你必须帮他守住边界。
下次当你看到 AI 说”测试已通过,可以发布”,请多问一句:
这一句话,能省下你后面好几个月的时间。
最后,顺便聊聊我们在做的 Floeva
这篇文章里所有的 PR 编号、所有的坑、所有让人头大的时区 bug,背后是一个具体的产品——Floeva 智能健康戒指。
我们为什么要在一个还在打磨期的小产品上,把 AI 用到这么深?因为团队不大,但想做的事不小:
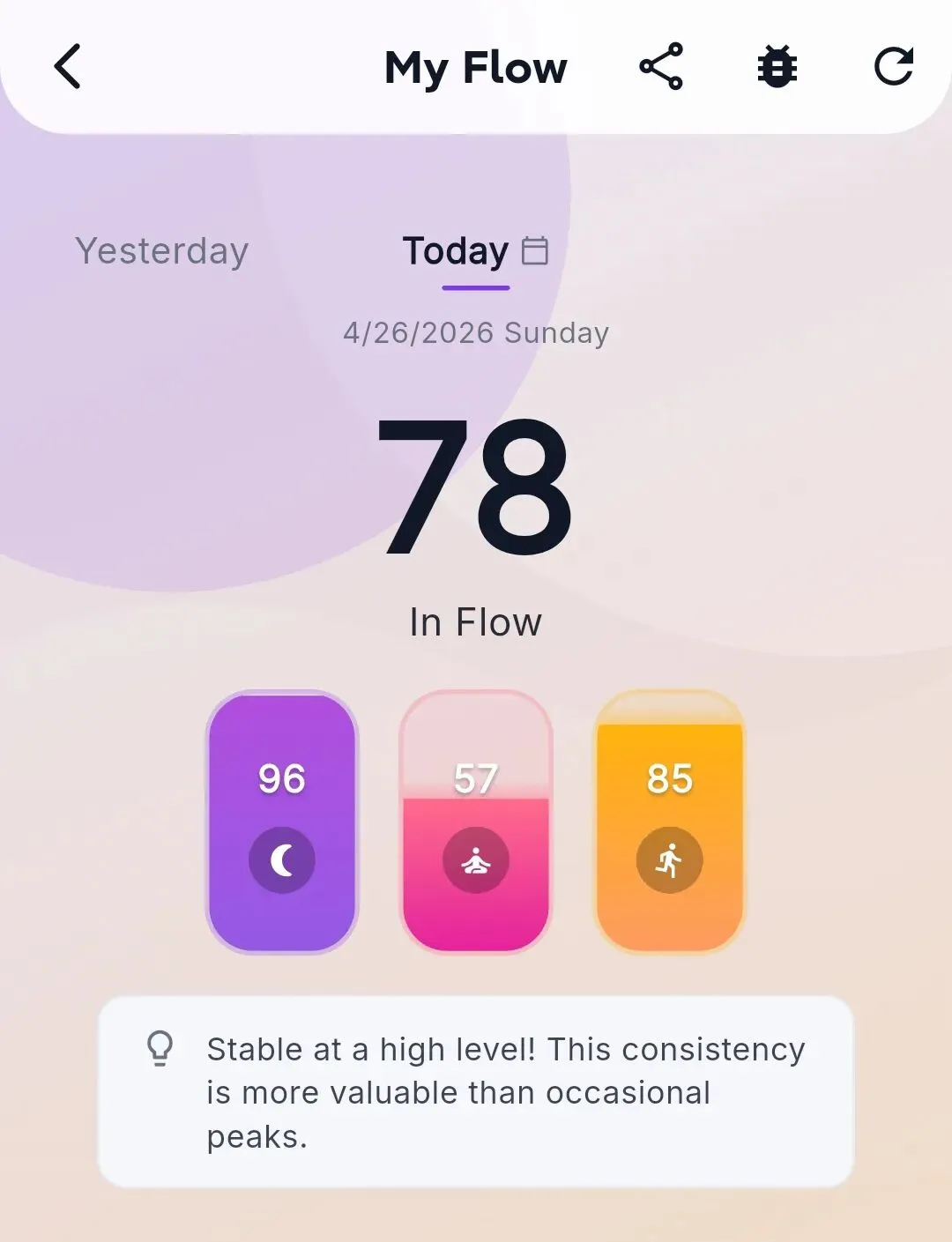
简单来说,它既是一个面向用户的健康产品,也是我们对”小团队 + AI 协作怎么把硬件软件一起做出来”这个命题的真实答卷。
这条路上的坑还会继续踩,新的踩坑笔记我也会陆续发出来。如果你对 Floeva 这个产品本身感兴趣,或者想第一时间看到我们后续的开发实录,欢迎关注公众号 哈哈AI Lab,也欢迎进群一起聊。
⚠️ 本文经验来自 2026 年初到 4 月间 Floeva 项目的真实开发记录,所述工具与做法在 AI 编程工具快速演进的当下,可能很快被新的工作流取代,请按需取用。