 夜雨聆风
夜雨聆风





告别“纸上谈兵”:AI世界模型如何从“猜下一帧”进化到“主动改造世界”
一篇2026年发布的长达88页的论文,为日益混乱的“世界模型”概念给出了清晰的坐标:AI理解世界的能力,可以分为预测、模拟、进化三个层次,以及物理、数字、社会、科学四个领域。
在人工智能领域,“世界模型”是一个被热议但含义却非常模糊的词。搞机器人的人说自己的模型能预测机械臂的下一个姿态,做自动驾驶的说自己的模型能生成连续的行驶画面,而研究大语言模型Agent的则认为,模型能在脑海里“想象”出网页点击后的下一步状态。
这些说法都对,但又不完全一样。正因如此,一篇发表于2026年的长篇综述论文,试图为这个“众说纷纭”的概念建立一座统一的坐标系。
这篇标题为《World Models for Agentic AI: From Local Predictors to Evidence-Driven Evolvers》的论文,由多位学者联合撰写,整合了计算机视觉、强化学习、机器人、AI for Science等领域的上千篇参考文献。它没有提出新的算法或榜单,而是给出了一个极具解释力的能力层级框架:L1 预测者、L2 模拟者、L3 进化者。同时,它按照“支配规律”的不同,把世界模型的应用场景划分为物理、数字、社会、科学四个领域。
下面,我们就来拆解这篇论文的核心思想。
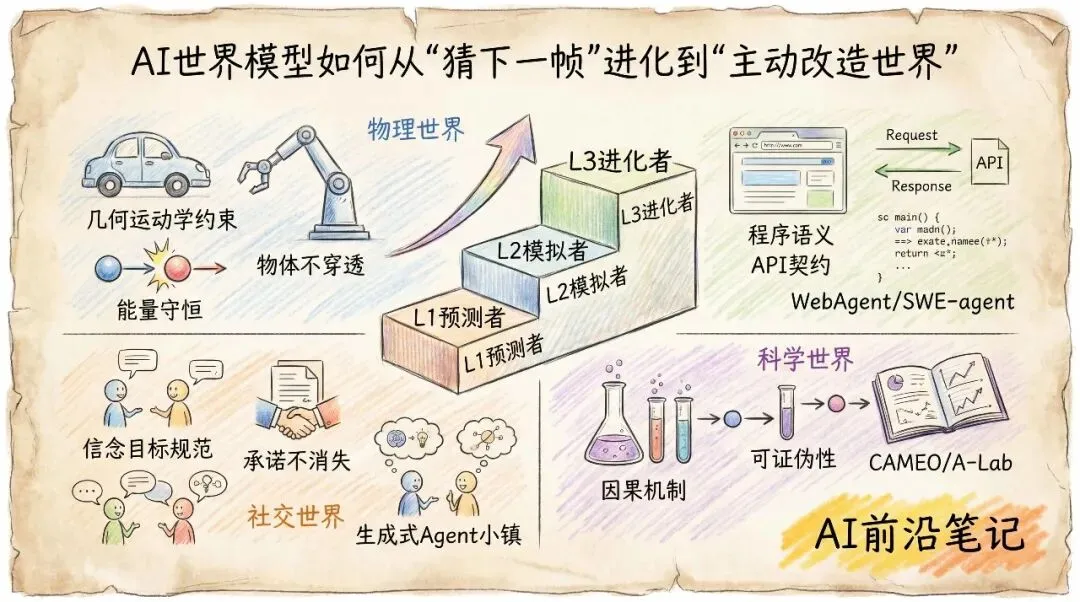
为什么我们需要一个统一的世界模型坐标系?
世界模型之所以混乱,是因为不同领域的人用它来做完全不同的事。一个生成视频的模型,只要画面流畅、物体不穿模,就可能被称为“世界模拟器”。但在强化学习工程师眼里,如果这个模型不能根据“向左推”这个动作,稳定预测出物体会向左滚动,那它对决策就毫无用处。
论文指出,真正有价值的世界模型,不应该只是“看起来像真的”,而应该能够帮助一个Agent做出更好的决策。基于这个出发点,作者提出了一个从弱到强的三级能力阶梯。
第一级:L1 预测者 —— 看一眼,猜下一步
这是最基础的能力。一个L1世界模型,能够根据当前的状态和动作,预测紧接着的下一步会变成什么样。打个比方,你看到一个人拿起杯子,L1模型能猜出下一秒杯子会离开桌面。但它不保证几十秒后杯子会不会飞到外太空去。
典型的L1模型包括Dreamer系列、MuZero等。它们通过一个“隐状态”来压缩过去的观测信息,然后学习一个局部的转移概率。这个阶段的模型,靠的是休谟所说的“恒常联结”——过去如此,未来也大概率如此。但它有一个致命弱点:一步预测很准,但多走几步,误差就会像滚雪球一样越滚越大。
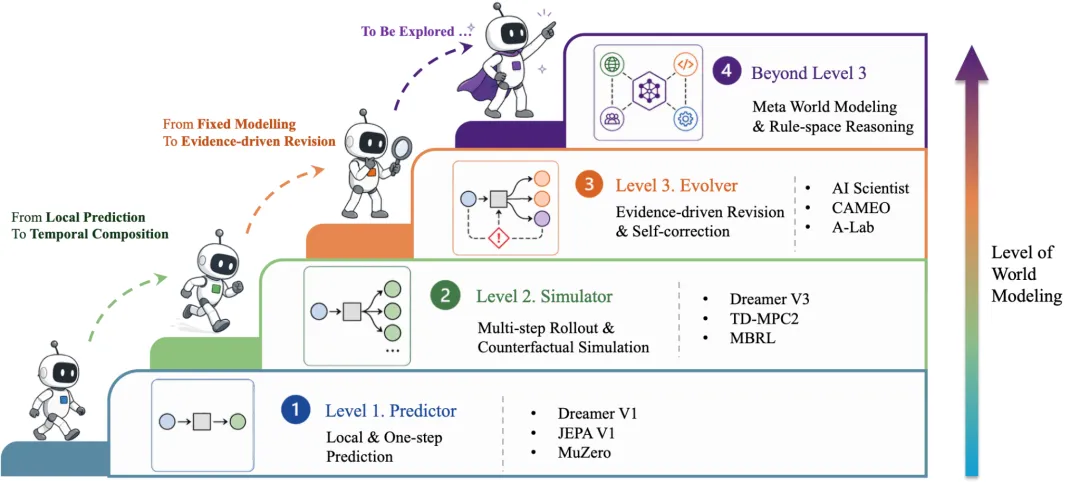
第二级:L2 模拟者 —— 在脑内预演一整条故事线
如果一个世界模型不仅知道下一步,还能连续想象10步、20步之后的状态,并且对“如果我中途换一个动作会怎样”这种反事实问题给出合理的回答,那它就进入了L2阶段。论文给L2设定了三个可测试的边界条件:
-
长程一致性:滚动的轨迹在几十步后依然可用,不会离谱地发散。
-
干预敏感性:改变动作或初始条件,后续的预测会发生稳定且有意义的改变。
-
约束符合性:生成的未来状态必须遵守所处世界的“基本法”。
这里的“基本法”因领域而异。在物理世界里,物体不能互相穿透;在数字世界里,程序不能调用一个不存在的API;在社交世界里,承诺过的事情不能无缘无故被遗忘;在科学世界里,实验的因果链条必须自洽。
论文用大量篇幅分别介绍了这四个领域中的代表性L2系统。比如物理世界中的自动驾驶世界模型GAIA-1、VISTA,数字世界中的WebAgent、SWE-agent,社交世界中的生成式Agent小镇,以及科学世界中的天气预测模型GraphCast、Pangu-Weather等。
有意思的是,论文特别强调:一个优秀的L2模拟器不需要长得和真实世界一模一样,它只需要在约束层面足够像。一个简单的刚体碰撞检测器,可能比一个画质精美但物体经常互穿的视频生成器,更适合做决策规划。
第三级:L3 进化者 —— 发现错了,就自己改自己
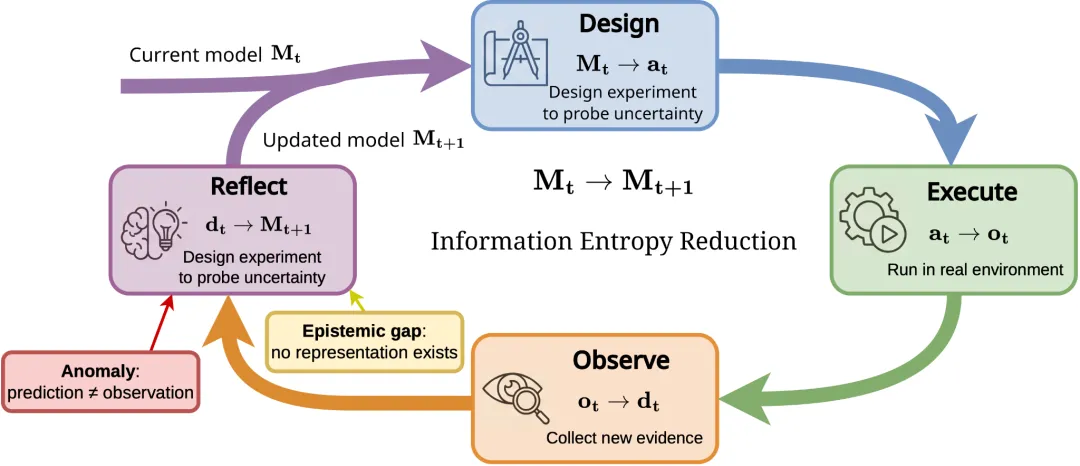
这是论文最具野心的部分。L3模型不再把世界模型当作一个训练完就冻结的组件,而是让它能够在部署过程中,主动收集证据、诊断错误、并修改自身的结构和参数。
打个比方:一个L2的自动驾驶模型,在冰雪路面上打滑了,它只能重新规划一条路径。而一个L3的模型,会意识到“我的摩擦力参数是错的”,然后主动设计一个实验(比如轻踩刹车),观察实际滑移距离,再用这个数据更新自己的动力学模型。下次再遇到冰雪路面,它的预测就准了。
论文指出,目前最接近L3的领域是自动化科学发现,比如CAMEO系统在同步辐射光源下自主合成新材料,A-Lab机器人17天完成353次实验并优化配方。在数字世界里,FunSearch和AlphaEvolve这类系统让大语言模型生成程序、自动运行测试、再根据结果改进程序,也体现了部分L3的闭环。
但在社交世界和物理机器人领域,L3还非常初步。原因是归因太难:一机器人抓取失败,到底是视觉看歪了,还是动力学模型错了,还是执行器坏了?没有明确的证据链,就无法安全地让模型自己修改自己。
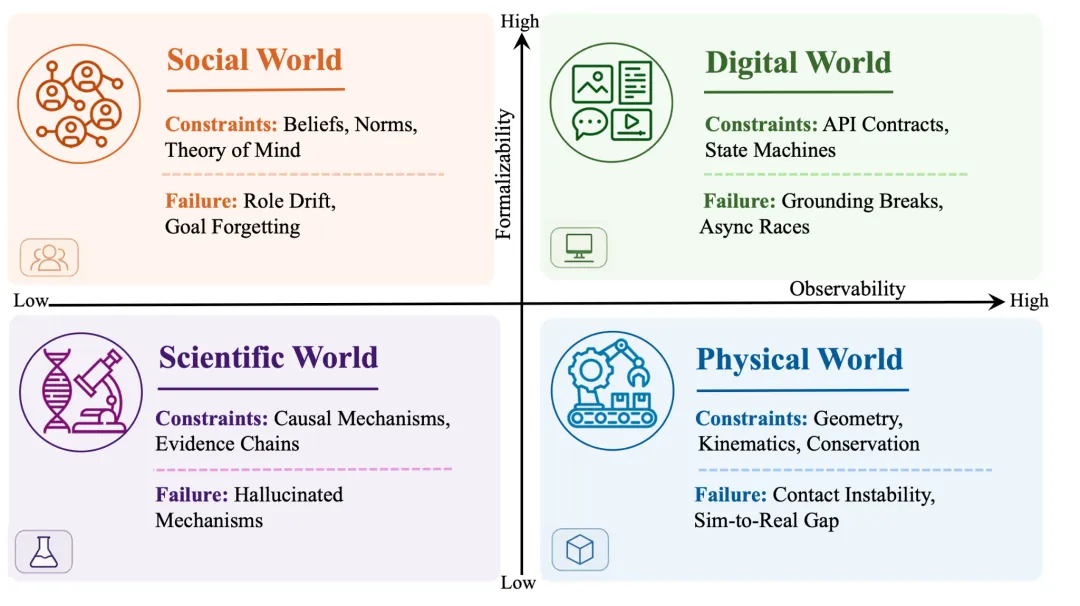
## 四个世界,各自需要什么能力?
论文的另一条主线是按照“支配规律”将应用场景分为四类。每一类对世界模型的要求差异很大:
-
物理世界:需要保持几何和运动学约束。失败模式是物体互相穿透、能量不守恒。评价靠稳定性指标。
-
数字世界:需要遵循程序语义和API契约。失败模式是调用不存在的接口、权限错误。评价靠错误分支覆盖。
-
社交世界:需要维护信念、目标、规范和契约。失败模式是人格漂移、承诺消失。评价靠反事实敏感性。
-
科学世界:需要符合因果机制和可证伪性。失败模式是幻觉机制、忽视负面结果。评价靠证据链完整性。
一个真实系统往往混合多个世界。自动驾驶既要遵守物理约束,又要预判行人的社交意图;科研自动化既要模拟化学反应,又要处理移液机器人的物理动作。
评价和实现:从“像不像”到“能不能用”
论文花了专门章节批评当前的主流评价方式:FVD、FID、PSNR这些视觉指标,和决策质量几乎没有关系。一个世界模型好不好,应该看两个数字:动作成功率(用模型规划后,真实环境里任务完成的比例)和反事实偏离度(改变动作后,预测结果是否跟着变)。
在实现架构上,论文给出了一个很实用的决策树:低延迟场景(如机器人控制)适合用轻量级隐状态+模型预测控制;中等延迟场景(如Web Agent)可以用大语言模型作为世界模型滚动;高延迟场景(如科学计算)则可以跑完整的扩散模型集成。
值得注意的是,论文反复提及一个争议性观点:L3级别的模型修订,很可能需要符号化表示。因为只有把物理定律、API规范或社交规范写成显式的、可编辑的符号(比如代码或逻辑规则),Agent才能确定地修改它们。而纯神经网络的黑箱特征,在“主动实验—归因—修改”这个闭环中会成为巨大的障碍。
未来:元世界模型与可进化Agent
论文最后提出了十个开放问题,其中最引人注目的是“建模那些自身会演化的规律”。比如病毒的免疫逃逸、气候系统的突变、社交规范的变迁——如果世界本身的规律就在变化,那么世界模型必须具备学习“规律的变化规律”的元能力。这已经是目前技术的边界之外了。
整体而言,这篇论文没有给出一个可以立刻跑起来的代码,但它提供了一份非常难得的“导航地图”。对于任何一个想在机器人、AI Agent、自动驾驶或科学发现领域认真做世界模型的研究者来说,弄懂L1、L2、L3的含义,以及自己领域属于哪个“世界”,可能是避免跑偏的第一步。
毕竟,一辆车开得再快,如果方向错了,也没什么意义。
感兴趣的可以阅读文章:https://arxiv.org/abs/2604.22748