 夜雨聆风
夜雨聆风





我让 AI 拥有三层记忆 · 但它从不"全部记得"
我让 AI 拥有三层记忆 · 但它从不”全部记得”
致读者: 本篇文章 4800+ 字,预计阅读时间 13min。AI 不需要记住一切,记错位才是灾难——这是我跑了一年记忆系统之后最贵的一条结论。如果你正在让 AI 记你的东西、做你的助手、跟你协同工作,这篇建议读完。
01. 先讲一个反直觉的事 · “全记住”是个坑
这两年我被问得最多的一个 AI 协作问题是——
鲈鱼,怎么让 AI 记住我所有的东西?我希望它越用越懂我。
我以前回答得很认真——讲长上下文、讲向量库、讲 memory 文件。讲到后来我发现,这个问题本身就是错的。
正确的问题不是”怎么让 AI 全部记住”,是——
AI 应该记住什么?不应该记住什么?什么东西放哪一层?
“全记住”听起来很爽,实际上是灾难。
你想象一下——你雇一个助理,他记住了你过去 5 年所有的对话、所有的偏好、所有改过的需求、所有半成品的项目。第二天他走进办公室,每说一句话都要把这 5 年的所有上下文翻一遍。这不是聪明,这是阿尔茨海默症的反面——记忆过载症。
AI 比这个更糟。它不仅”记住”,它还会主动调用这些记忆来影响每一次输出。
如果你的记忆里 30% 是过期的、20% 是当时一时兴起的判断、10% 是 bug 修了之后没回滚的旧规则——那它每次输出都在被这些噪音污染。
我跑了快一年,最后定下来一条铁律——
AI 的记忆质量 ≠ 记得多,等于”在对的层放对的东西”。
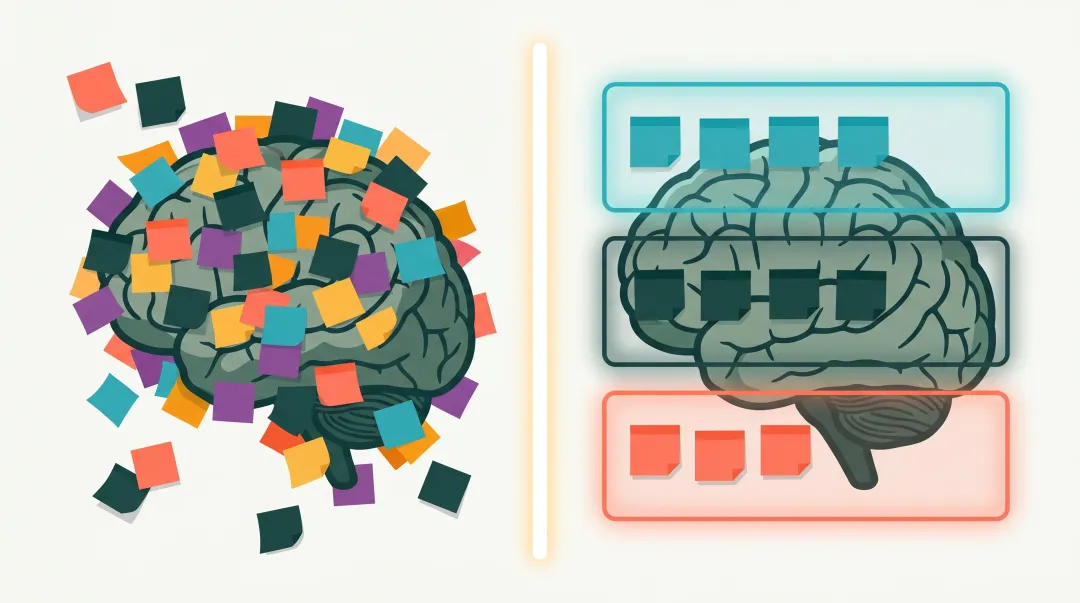
02. 三层栈 · 我的现场长这样
讲清楚为什么之前,先把”现场”摆出来。我的整套 AI 记忆体系是这样的——
┌─────────────────────────────────────────┐│ Layer 1 · AI Memory ││ /Users/.../memory/*.md ││ → AI 自己读自己写,索引层 ││ → 铁律 / 偏好 / 跨会话沉淀 │├─────────────────────────────────────────┤│ Layer 2 · Obsidian Vault ││ ~/Documents/Obsidian Vault/ ││ → 我看 + AI 读,可读副本 ││ → 项目正文 / 方法论 / 数据 / 工作日志 │├─────────────────────────────────────────┤│ Layer 3 · NotebookLM (Teacher) ││ notebooklm.google.com ││ → 慢变知识,AI 不直接读,问答层 ││ → 行业资料 / 长文档 / 课程 / 别人的产出 │└─────────────────────────────────────────┘三层各管一摊事,互不替代,互不重叠。
这套结构我没有一开始就想清楚——是被坑了三次才形成的。每一次坑都对应一层”放错位置”的代价。下面三章我把这三次坑讲完,你就知道为什么必须分三层。
03. 第一层 · AI Memory 应该只放”铁律和偏好”
Layer 1 的定义很简单:跨会话、AI 自己读自己写的索引层。
我现在 Memory 文件夹里大概有 100+ 个 .md 文件,但 MEMORY.md 主索引只有不到 80 行。这不是没东西放,是我刻意把它砍到 80 行。
为什么?
因为 Memory 是 AI 每次开新会话都会被自动加载到上下文里的东西。它不是”AI 偶尔翻一下的资料库”,是每次对话都强制注入的 system 上下文。
你放进去的每一行,都在消耗每一次对话的注意力预算。
第一次踩坑——
我刚开始用 Memory 时很贪心。我把所有”重要的事”都往里塞——
-
当前项目状态 -
最近一周的待办 -
这次任务的临时规则 -
我对某次输出的具体修改建议 -
跑过的 N 个文件路径
很快 Memory 就涨到了 180 行 / 130 多个条目。我以为这是好事——AI 应该越来越懂我。
结果是反过来——AI 越来越懒。
它每次开会话都要消化 180 行规则,输出前几轮明显在”努力照顾所有规则”,反而失去了灵性。而且这 180 行里 60% 是早就过期的临时状态——某次任务的中间产物、某个项目的旧路径、上周改完的偏好。
它在认真执行一份过时的法律。
后来我立了一条规则——
Memory 只放铁律和偏好。临时状态、项目细节、操作记录,全部不放。
具体什么算”铁律和偏好”?我用三个判断标准——
- 跨任务复用
:这条规则在 3 个以上不同任务里都生效吗? - 稳定性
:这条规则会随项目状态变化吗?会变 = 不放 - AI 必须知道才能不犯错
:不放的话 AI 会重复踩坑吗?不会 = 不放
举例——
✅ 应该放: – “用户偏好中文输出” – “默认用 Glob/Grep 搜索,不 spawn Explore agent” – “禁止自动模型降级” – “微信 4.x macOS 图片解密死路,触发立刻劝退”
❌ 不应该放: – “本周在做外卖 CPS 项目”(项目状态会变) – “今天发了 15 个邀请码”(临时状态) – “这次的 prompt 改成了 v3″(操作记录) – “remontion-studio 在桌面 luyu 文件夹里”(路径会变)
后面这些信息要去 Layer 2 找。

我现在还会做一件事——每月一次审计。
打开 MEMORY.md,逐行问自己:
这条规则我上一次”违反”是什么时候?
如果三个月没违反过,意味着 AI 已经稳定执行了,这条可以删了——它已经不是”AI 容易踩的坑”了。
如果只有一次会话偶尔忘,也删——一次性失误不值得长期占用上下文。
只留反复踩、长期会犯的硬规则。
到今天,我的 MEMORY.md 顶层条目稳定在 30 个以内。这是 Boris Cherny(Claude Code 项目负责人)公开提过的上限——再多 AI 就会开始忽略前面的内容。
04. 第二层 · Obsidian 才是”项目和数据的家”
Layer 2 的定义:人和 AI 都能读,但不会被自动加载。
这是 95% 的内容应该待的地方。
第二次踩坑——
我以前有个习惯:把项目笔记、方法论、采集到的数据,都顺手丢进 Memory。理由是”这样 AI 就知道了”。
后来发现两个大问题。
问题 1:Memory 是给 AI 看的,Obsidian 才是给我看的。
我自己想找之前对某个项目的判断,去 Obsidian 搜——搜不到,因为我写在了 Memory 里。
我想看上周整理的某个采集系统知识,去 Obsidian 翻——翻不到,因为只写了 Memory 一份。
打开 Obsidian 一看,死链一片——37 份平台知识全卡在 Memory 里,Vault 里全是 stub。
那次我做了一次审计,定下了这条铁律——
采集类知识沉淀,Memory 和 Vault 必须同时写,物理双写,不能软链接。
物理双写的意思是—— – AI 索引层 → Memory 一份,简短指针 – 用户可读层 → Vault 一份,完整正文
两份独立副本,不是同一个文件的两个入口。
为什么不能用软链接?因为软链接会让 Obsidian 启动时反复扫描索引、缓存抖动,Vault 一旦内嵌软链接,就会出现”加载缓存中”的卡死现象。我踩过一次,重启 5 次都没好——最后是把所有软链接全替换成硬路径才恢复。
问题 2:项目状态变化太快,但 Memory 改不动。
我做项目时经常这样——某个项目今天有结论 A,明天用户说”换一下 B”,后天又改回 A 的变体。
如果这些放在 Memory 里,每次改我都要——
-
找到对应的 memory 文件 -
改正文 -
改 description(一行描述) -
改 MEMORY.md 索引 -
还要担心 AI 缓存命中旧版本
而放在 Obsidian 里,直接改正文一行就行。
后来我把”项目状态”全部下沉到 Vault——
~/Documents/Obsidian Vault/├─ 知识库/核心画像/PROJECTS.md ← 当前项目状态总览├─ 工作日志/ ← 日维度记录├─ 项目/{项目名}/ ← 单项目正文└─ 数据/采集系统/{平台}/ ← 平台知识沉淀Memory 只留一行指针:
- 当前项目状态查 ~/Documents/Obsidian Vault/知识库/核心画像/PROJECTS.mdAI 每次需要项目状态时,自己去读 Vault。这样 AI 永远拿到最新版本,不需要我维护”AI 缓存的同步”。
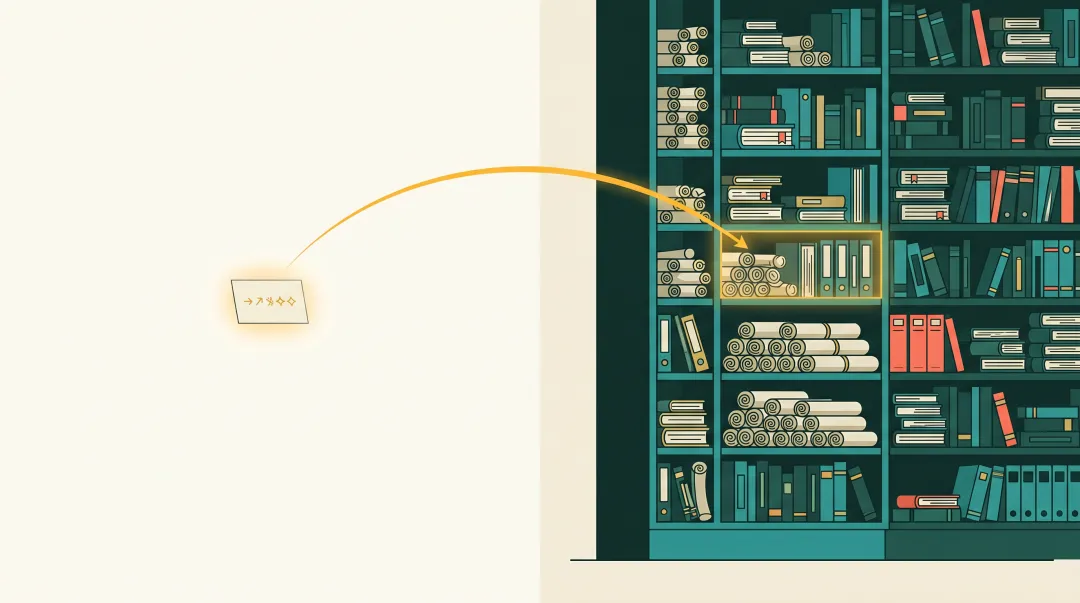
这一层还有一个隐藏价值——Vault 是 AI 的”长期工作台”。
我让 AI 写报告、整理资料、做方法论,它都直接写到 Vault 里。这些产物不进 Memory,但它们会持续在那里,下次需要时 AI 读 Vault 就能恢复上下文。
不需要”AI 记得”——它去读就行。这才是 AI 长期协同的正确姿势。
05. 第三层 · NotebookLM 才是”慢变知识的地方”
Layer 3 的定义:AI 不直接读,靠问答接口调用。
这一层是去年我踩了第三次坑之后才加进来的。
第三次踩坑——
我之前喜欢把行业资料、长课程、PDF 报告,全部塞进 Vault。理由是”AI 读 Vault 就能用上”。
结果是——
Vault 越来越胖。
一份 18 万字的提示词文档、几十份课程转录、几百个 PDF 报告,全堆在 Vault 里,搜索变慢、Obsidian 启动变慢、AI 读取一个文件夹时上下文直接溢出。
更糟的是——这些资料根本不需要”每次都读”。
它们是慢变的——一份课程转录写完之后半年都不会动;一份行业研报今年看完明年就过期。它们应该是问答式调用,不是默认加载。
那时候我在用 NotebookLM,突然意识到——这才是 Layer 3 应该长的样子。
我把所有”长文档 / 慢变知识 / 别人的产出”全部上传到 NotebookLM,按主题建 notebook:
-
“提示词工程” notebook → 我那 18 万字 + 工坊心法 + 8 把武器 -
“AI 视频体系” notebook → Remotion 文档 + 几个对标博主的转录 -
“采集系统” notebook → 各平台 API 文档 + 反爬历史 + 法务边界
一主题一 notebook,每个 notebook 装满它对应的”慢变知识”。
然后呢?AI 怎么用?
它不直接用。
需要这个领域的深度知识时,我去 NotebookLM 提问,把答案带回来给 AI。或者更进阶——让 Claude 走 MCP 调用 NotebookLM 的接口(如果你打通了的话)。
这听起来麻烦,但带来三个收益——
- Vault 瘦身
:18 万字 + 几十份转录从 Vault 里搬走,Obsidian 启动从 30 秒回到 3 秒 - AI 上下文不被污染
:不用每次都读这些慢变资料 - 知识库本身有版本
:NotebookLM 里的 source 不会跟我的工作日志混在一起

我把这种结构叫做——
Teacher 层(NotebookLM)冻结慢变知识,Claude 层执行,Obsidian 层做个人记忆。
三层从下到上,变化频率递增——
-
NotebookLM:年级慢变(行业资料、课程) -
Obsidian:周/月级中变(项目状态、方法论) -
Memory:长期不变(铁律、偏好)
注意这是反直觉的——
大多数人会以为”长期不变”应该放最深、最远;”快变”应该放最近、最浅。
我反过来——长期不变的放最近(Memory,每次自动加载),慢变的放最远(NotebookLM,需要时才问)。
为什么?因为”长期不变 + 高频使用 = 应该零成本调用”。铁律每次都生效,每次都需要 AI 知道,那就放最近,每次自动加载。
而”慢变 + 低频使用 = 应该按需调用”。一份行业研报半年用一次,根本不值得每次都注入上下文。
06. 三层之间的”流通规则”
三层各管一摊事,但它们之间是有流通的——信息会在层之间流动。
我定了三条流通规则:
规则 1 · 自下而上:Memory 是 Vault 的”提取物”
新规则、新教训、新偏好,先在 Vault 里发生——某次项目踩坑、某次和用户的对话、某次 AI 输出失误。
我先把这些事记录在 Vault 的工作日志里。
跑一段时间,如果某条规则反复出现 3 次以上,我才把它”提取”到 Memory——加上 Why(为什么)和 How to apply(怎么应用),放到合适的子索引里。
Memory 里的每一条,都是从 Vault 蒸馏出来的。
规则 2 · 自上而下:Memory 引用 Vault,不复制
Memory 里只放一行指针:
- [视频体系] luyu_zen_pipeline_v0.5 · 正文见 vault://视频体系/zen/正文一律去 Vault 看。如果某天我改了正文,Memory 不需要同步——指针不会变。
这是软件工程里的 single source of truth 原则——一份信息只在一个地方有正本。
规则 3 · NotebookLM 单向输入,不和上面两层耦合
NotebookLM 里的资料只进不出——我不会把 Memory 或 Vault 同步到 NotebookLM。
为什么?因为 Memory 和 Vault 是我的产物(持续变化),NotebookLM 是别人的产物 + 我的冻结版(基本不变)。
混在一起会让 NotebookLM 的”知识权威性”被稀释。

07. 最后一条铁律 · 不写双份,全是死链
我做这套体系最大的代价是——最初的几个月,我无意中写了大量”双份”。
一份知识,我同时写到 Memory 和 Vault; 一份方法论,我同时写到 Vault 和 NotebookLM; 一份偏好,我同时写到 Memory 和 项目 CLAUDE.md。
刚开始觉得”双保险”,半年后才发现——
双份 = 双份维护成本 = 必有一份过期 = 全是死链。
我现在的硬规则是——
每条信息只有一个正本。其他层只能放指针。
正本在哪?看它最常被谁更新——
-
我手动改:放 Vault -
AI 自动写:放 Memory -
几乎不改的别人的产出:放 NotebookLM
正本定了,其他层就只放指针。指针可以重复,正本不能重复。
这条规则定下来之后,我每个月做一次”死链审计”——
# 在 Memory 里检查所有 vault:// 指针是否还存在# 在 Vault 里检查所有 [[link]] 是否还有效# 在 CLAUDE.md 里检查所有引用的 memory 文件是否还在每次审计都会找到 3-5 个死链——文件被重命名了、文件夹被搬了、规则被合并了。审计就是为了让”指针永远对得上正本”。
08. 收个尾 · “AI 不需要全记得”
回到开头那个问题——
怎么让 AI 记住我所有的东西?
我现在的回答是——
不需要。让 AI 在对的时候,去对的层,找到对的东西。
AI 不需要”记得一切”。它需要的是——
-
知道铁律(Memory,每次自动加载) -
知道去哪查项目状态(Vault,按需读) -
知道深度知识在哪个 notebook(NotebookLM,按需问)
三层就够了。
每一层都有自己的”准入门槛”——
-
Memory:铁律 + 偏好,30 条以内 -
Vault:项目正文 + 方法论 + 数据,瘦身常态化 -
NotebookLM:慢变知识,单向输入
清晰的边界,比丰富的存储重要得多。
这不是反智,是工程。AI 系统要稳定运行一年以上,必须像一个正常的软件系统一样,分层、分职、分节奏。
否则你迟早会遇到那个问题——
AI 怎么开始变笨了?
不是它变笨了,是你给它的记忆层崩了。
最后说一句——
如果你现在 Memory 里有 200+ 行、Vault 里堆了 18 万字的别人的资料、所有东西都在一个文件夹里大杂烩——
今天就开始做”分层”。
不要追求一次到位。先把 Memory 砍到 80 行(删掉所有项目状态和临时规则),其他全往 Vault 搬。
第一周你会舍不得删。第二周你会发现 AI 输出反而稳了。第三周你会主动再砍一轮。
记忆系统也跟 skill 体系一样——会涨胖,需要修剪。