 夜雨聆风
夜雨聆风





OpenClaw的长期记忆机制是如何实现的
我们在使用 OpenClaw 的过程中,经常会强调说:你要记住这个信息。比如在生图时,封面的风格是偏手绘质感,颜色要克制一点,不要太鲜艳。那下次生图的时候它就会按照这个要求来,即使过了好久,它仍然能记得。
今天我们就来聊聊他是怎么记住的?也就是 OpenClaw 的长期记忆机制是怎么运作的?
他是基于一套可见的文件系统来做存储,而且全部用 Markdown 格式。核心包括三类:
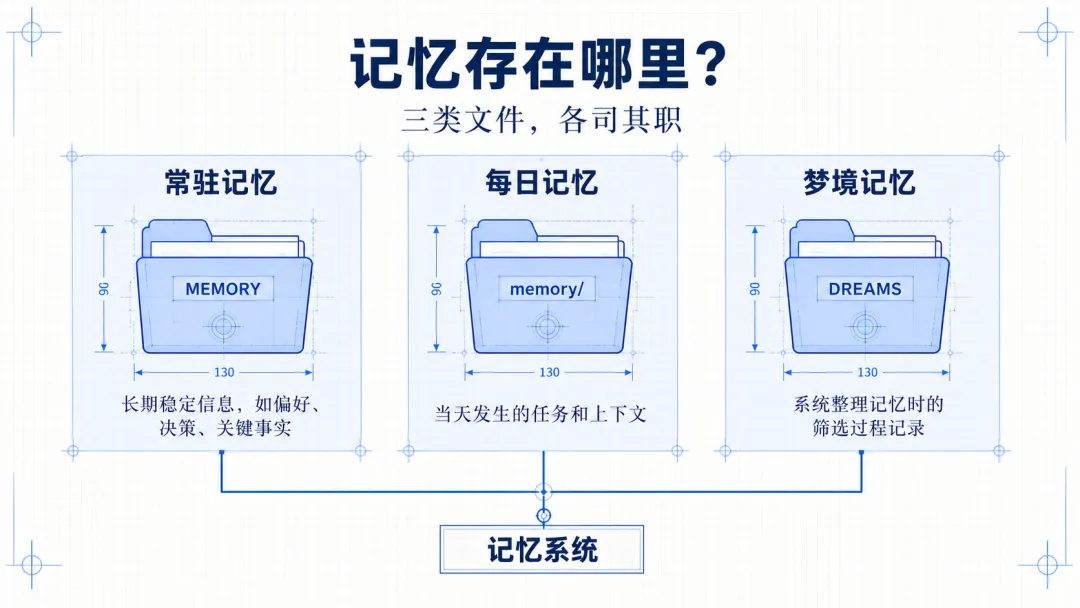
第一类是常驻记忆,也就是 MEMORY 文件。
这里存的是长期稳定的信息,比如你的使用偏好、已经做过的重要决策、以及未来还会反复用到的事实。可以把它理解成一份长期档案。
第二类是每日记忆,存放在 memory/ 目录下,用日期命名,比如 2026-04-30.md。
这里记录的是当天发生的事情、任务过程,以及阶段性的上下文。它不一定都是永久重要的,但能还原某一天发生了什么。
第三类是梦境记忆,也就是 DREAMS 文件。
这个是 dreaming 过程的审查日志,记录系统做了什么决策、为什么提升到常驻记忆里,供人类事后检查,不会被塞入到上下文里。这里先不详细介绍,等讲召回的时候像详细说下OpenClaw是如何做梦的。
这里还需要强调一下,说的都是 长期记忆体系,而不是对话过程中的短期上下文。
那这些记忆,是在什么时候、以什么方式被写进这些文件里的?
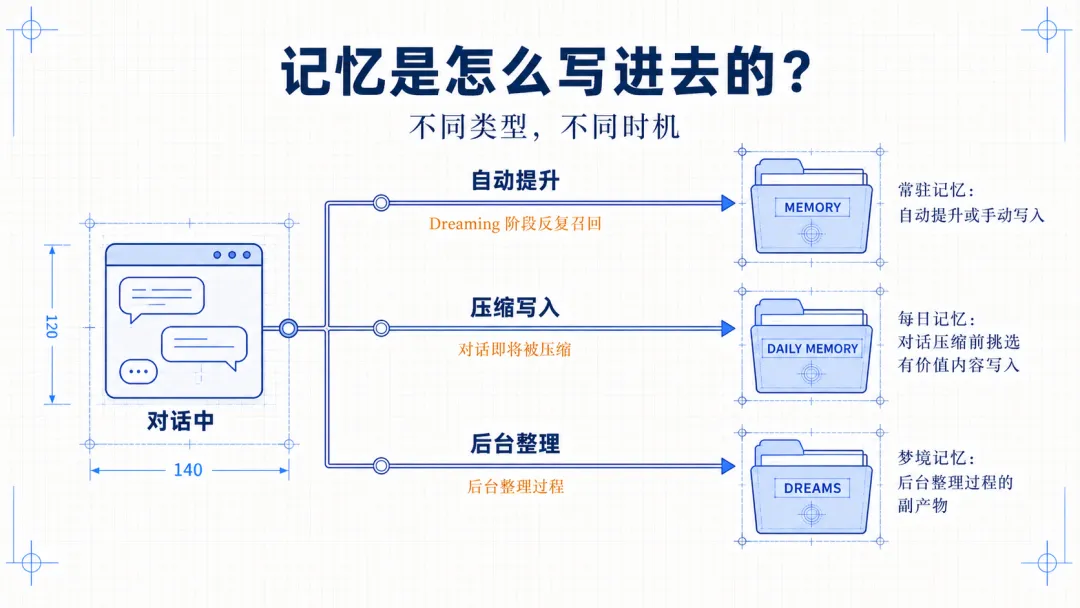
不同类型的记忆,写入的时机是不一样。
先看常驻记忆(MEMORY),它有两条主要路径:
一条是自动提升。
即在 Dreaming 阶段,系统会根据被召回的记忆来提升,这里先不详细说,后面记忆召回的时候再说下。
另一条是手动写入。
用户可以直接要求“记住这件事”,或者 AI 在判断某些信息明显具有长期价值时,也可以主动写入。
再看每日记忆。
它的写入时机通常发生在对话即将被压缩的时候。系统会从当前对话中挑选出有保留价值的内容,整理后写入当天的记忆文件。这样即使上下文被截断,重要信息也不会丢失。
至于 DREAMS 文件,等会再说。
到这里,其实只是完成了一件事:把记忆写进文件。
但光有文件还不够。
因为当文件越来越多、内容越来越长时,AI 不可能每次都把所有内容读一遍。
那它是怎么在这些文件里,快速找到相关记忆的?
OpenClaw 的做法是:在文件之外,再建一层本地数据库索引。
它会监听每日记忆文件夹,如新增、修改、删除,一旦有变化,就会把文件内容同步写入本地的 SQLite 数据库。同时会维护三张表:
* chunks:存原始文本切片,包括文件路径、行号、内容等
* chunks_fts:全文搜索索引,用于关键词检索(基于分词和倒排索引)
* chunks_vec:向量表(通过 sqlite-vec),用于语义搜索
简单来说,就是把 Markdown 文件拆成一小段一小段,然后同时建立:
* 一套“按关键词查”的索引
* 一套“按语意查”的索引(前提是配置向量模型)
这样,文件本身是可读的,数据库是可查的。
那接下来问题就变成:当你真的提出一个问题时,它是怎么从这些索引里,把相关记忆找出来并用上的?
这里主要靠两个工具,memory_search 和 memory_get。可以先把它理解成,一个负责找线索,一个负责读原文。
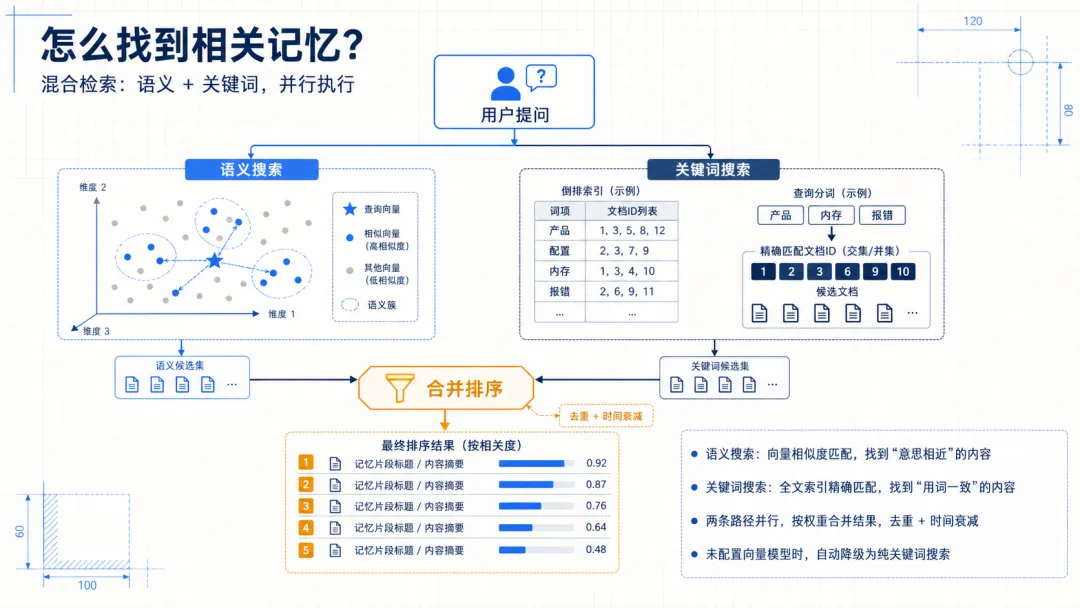
先看 memory_search,它做的事情并不是简单的关键词匹配,而是一个混合检索。它会同时跑两条路径,一条按语义找,一条按关键词找,然后把结果合在一起排序。这样既能找到表达完全一致的内容,也能找到意思相近但说法不同的记录。
语义搜索这一层,是把用户的问题转成向量,在本地的向量库里做相似度匹配。它解决的是说法不一样但意思接近的情况,比如你问编码风格,原文写的是实现核心逻辑优先,这种意思相近的就能被找出来。
关键词搜索这一层,则是基于全文索引,专门处理那些必须精确匹配的内容。比如错误信息、配置字段,这些都需要一字不差地命中。对于中文或日文这种没有空格的语言,它还会自动做分词处理,保证检索效果。
这两条路径是并行执行的,最后会按照一定权重合并结果。简单理解就是,一部分看意思像不像,一部分看词对不对。另外还会做去重,避免返回重复内容,以及时间衰减,新的记忆权重会更高。
如果没有配置向量模型,语义搜索这一层会暂时关闭,系统会自动退回到纯关键词搜索。虽然理解能力会下降,但至少还能保证能查到明确写过的内容。
还有一个比较关键的细节是,也就是前面说的做梦,每一次检索的结果都会被记录下来,放到记忆召回的json文件中,并记录召回次数和相似度。记录下的内容是在 Dreaming 阶段,用来判断哪些短期记忆值得提升为长期记忆。最终会被写入到常驻记忆中,另外为什么要被写入的内容也会存储到 DREAMS 文件。
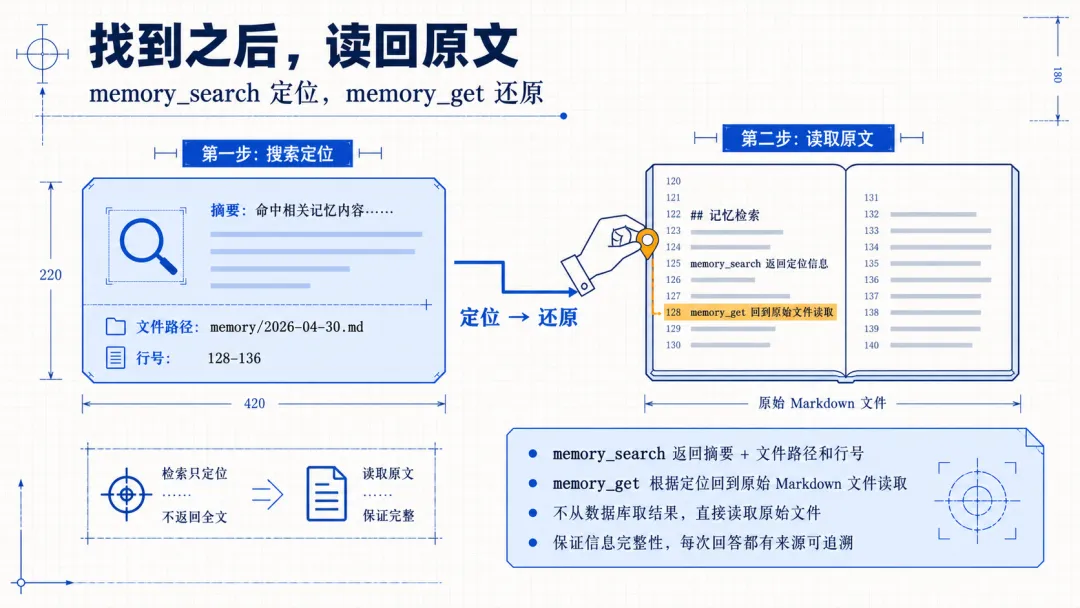
再看 memory_get,它的职责就简单很多,就是把原文读出来。memory_search 返回的只是一个摘要加上定位信息,比如文件路径和行号。如果模型判定需要更详细或者更原始信息的时候,就由 memory_get 回到具体的 Markdown 文件里,把对应位置的内容读出来。
整个记忆搜索流程就是先搜索相关片段,再定位具体位置,最后如果需要就读取原文。
最后,整篇用一句话总结就是 OpenClaw 的长期记忆会被写进文件,被索引成数据库,被工具按需调用。