 夜雨聆风
夜雨聆风





文档抽取工具到底快不快?Kreuzberg Benchmarks 给出了可验证答案
做文档智能、RAG、企业搜索或知识库时,大家经常会问一个很现实的问题:
文档抽取工具到底快不快?
这个问题看起来简单,其实很难回答。
因为“快”不是一个单一指标。处理一个 PDF 很快,不代表批量处理几千份文档也快;只支持 PDF 很快,不代表处理 DOCX、PPTX、HTML、邮件、压缩包、图片和表格时也稳定;启动很快,不代表内存占用合理;某个语言版本表现好,也不代表其他语言生态下能直接复用。
所以,Kreuzberg 做了一个专门的 Benchmarks 页面:
https://kreuzberg.dev/benchmarks[1]
它不是一句“我们很快”的宣传语,而是把文档抽取性能拆成了可查看、可比较、可下载的数据。
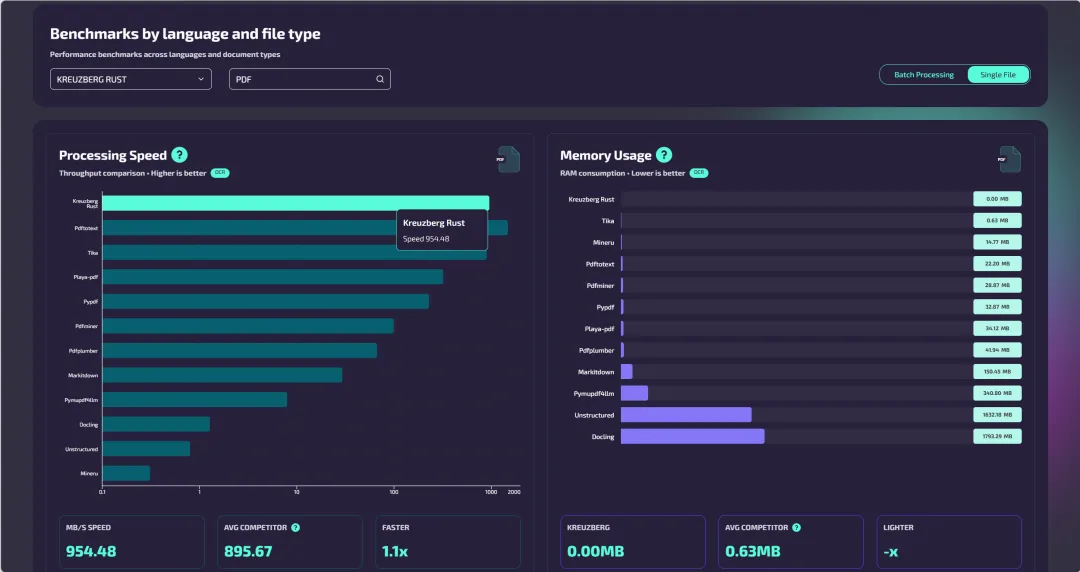
为什么文档抽取需要 Benchmark?
很多文档抽取项目在早期验证时,只会拿几份 PDF 做测试。
如果能抽出文字,体验就算“不错”;如果速度还可以,就会直接进入知识库或 RAG 流程。
但真正进入生产环境后,问题会很快暴露出来:
- –文件格式越来越多,不只是 PDF;
- –文档质量参差不齐,有扫描件、图片、表格、Office 文件和邮件;
- –数据量变大后,单文件速度不再代表整体吞吐;
- –内存占用过高,会直接影响部署成本;
- –OCR、批处理、异步处理、多语言 SDK 支持,都会影响工程落地。
这就是 Benchmark 的意义。
它不是为了在某一个样本上证明“谁最快”,而是把真实工程里关心的维度拆开:速度、吞吐、内存、CPU、文件类型、语言生态、批处理能力和功能覆盖。
Kreuzberg Benchmarks 页面想解决的,正是这个问题:让用户在选择文档抽取方案之前,先看到公开、可比较的性能数据。
Kreuzberg Benchmarks 展示了什么?
打开页面后,你会看到它围绕几个核心维度组织数据:
第一,是按语言和文件类型查看性能。
Kreuzberg 不只提供某一个语言版本。Benchmark 页面可以切换不同 Kreuzberg 语言绑定,例如 Rust、Python、Node、Go、Java、Ruby、PHP、Elixir、C#、WASM 等。你可以看到不同语言环境下,处理不同文件格式时的表现。
这对工程选型很有价值。
因为很多团队不是“为了文档抽取而选择语言”,而是已经有自己的技术栈。Python 团队关心 Python SDK,Node 团队关心 TypeScript/Node.js,后端服务可能是 Go、Java 或 Rust,浏览器端则可能关心 WASM。
Benchmark 让你可以直接从自己的技术栈出发看数据,而不是只看一个抽象结论。
第二,是单文件和批处理模式。
单文件处理速度适合评估交互式场景,比如用户上传一个文档后希望尽快看到结果。
批处理模式则更接近生产场景,比如一次性导入大量企业文档、构建知识库、迁移历史资料,或者定时处理归档文件。
Kreuzberg Benchmarks 页面把这两类场景分开看,避免用单文件性能去误判批量任务的成本。
第三,是资源使用情况。
页面中不仅有速度和吞吐,也提供 CPU Usage、内存等维度。
对开发者来说,这一点非常关键。一个工具如果只是在小样本上“跑得快”,但 CPU 或内存占用不可控,到了生产环境仍然会带来成本和稳定性问题。
文档抽取不是一次性的 Demo 能力,而是经常要嵌入长期运行的服务、队列、数据管道和 RAG 预处理流程里。资源曲线是否可控,直接影响部署方式和预算。
第四,是框架能力对比。
页面还展示了不同工具在 OCR、批处理、异步支持等方面的能力对比。
这让 Benchmark 不只是在比“速度”,也在比“工程可用性”。
因为真实项目里,速度只是第一层问题。能不能处理扫描件?能不能批量处理?能不能异步集成?能不能在现有语言栈里直接使用?这些问题同样决定工具能不能真正落地。
一些公开数据值得关注
Kreuzberg Benchmarks 的原始数据公开在 GitHub Release 中,可以直接下载 JSON 文件做二次分析。
截至官方页面当前指向的 benchmark run,数据来自:
- –Release:
benchmark-run-21708112283 - –日期:2026-02-05
- –Commit:
c9ca4f72944c256abd128f7b1028c38a9eb32964 - –原始数据:
aggregated.json、metadata.json
从公开聚合数据看,Kreuzberg 的批处理模式在性能排名中表现非常突出:
- –
kreuzberg-php:batch排名第 1; - –
kreuzberg-go:batch排名第 2; - –
kreuzberg-ruby:batch排名第 3; - –
kreuzberg-rust:single排名第 4。
在吞吐排名中,Kreuzberg 的批处理模式同样位于前列:
- –
kreuzberg-go:batch排名第 1; - –
kreuzberg-php:batch排名第 2; - –
kreuzberg-ruby:batch排名第 3; - –
kreuzberg-rust:single排名第 4。
这组数据释放了一个很明确的信号:
Kreuzberg 不只是为了“能抽取”而设计,也非常重视高吞吐、批量处理和多语言工程集成。
对于知识库、RAG、企业搜索这类场景,这一点尤其重要。
因为这些场景很少只处理一份文档。更多时候,你面对的是几百、几千、几万份历史文件。此时,批处理能力、吞吐和资源使用,往往比单次调用的漂亮体验更重要。
和其他工具相比,Benchmark 的价值在哪里?
Kreuzberg Benchmarks 页面中可以看到多个常见文档处理工具或框架的对比,包括 Unstructured、pdfplumber、PyMuPDF4LLM、Tika、Docling、MarkItDown、MinerU、Pandoc 等。
这些工具各有自己的定位,有的擅长特定格式,有的强调结构化解析,有的更适合作为通用转换工具。
Kreuzberg 的价值在于,它把自己放进了一个公开比较环境里。
这对用户很友好。
你不需要只听官方介绍,也不需要自己从零搭一套测试环境。你可以先在 Benchmarks 页面里切换文件类型、语言和处理模式,快速观察不同工具的表现;如果需要更深入分析,还可以下载原始 JSON 数据自己验证。
这是一种更透明的技术传播方式:
不只给结论,也给数据。
不只给排行榜,也给维度。
不只展示最好看的结果,也允许用户按自己的场景重新筛选。
为什么这对 RAG 和企业知识库很重要?
现在很多团队都在做 RAG,但 RAG 的效果不只取决于大模型,也取决于前面的文档处理。
如果文档抽取慢,知识库构建会慢。
如果批处理能力弱,历史资料导入会慢。
如果内存占用高,部署成本会上升。
如果格式支持有限,真实企业文档会大量失败。
如果输出质量不稳定,后面的切分、向量化、检索和回答质量都会受影响。
文档抽取是 RAG 的入口层,也是最容易被低估的一层。
Kreuzberg Benchmarks 的意义在于,它把这个入口层的性能问题前置了。你可以在真正接入之前,先评估不同语言、不同文件类型、不同处理模式下的表现。
这比“先集成,遇到问题再优化”要稳得多。
对开发者来说,它降低了选型成本
如果你是开发者,Kreuzberg Benchmarks 页面可以帮你快速回答几个问题:
我当前语言栈是否有可用的 Kreuzberg 绑定?
我要处理的文件类型是否在测试覆盖范围内?
单文件处理是否够快?
批处理吞吐是否适合离线导入任务?
内存和 CPU 使用是否适合我的部署环境?
和常见替代工具相比,Kreuzberg 的优势主要体现在哪些场景?
这些问题如果完全自己测,会消耗不少时间。
而 Benchmarks 页面把这些信息放在一个交互式界面里,再配合公开 JSON 数据,能显著降低前期调研成本。
对非开发者来说,它让“性能”变得可理解
Benchmark 通常是技术人员看的东西,但 Kreuzberg 这个页面对产品、运营、技术负责人也有价值。
因为它把抽象的性能问题变成了可视化对比。
你不需要读完全部源码,也能理解:
哪些场景适合批处理;
哪些语言版本表现更突出;
不同工具之间差异在哪里;
为什么文档抽取不是“能不能用”这么简单,而是要看吞吐、资源、格式和功能覆盖。
这对团队内部沟通很有帮助。
当你要推动一个文档智能、知识库或 RAG 项目时,Benchmark 页面可以成为一个共同参考:产品看能力,工程看集成,负责人看成本和稳定性。
透明,是 Kreuzberg 的另一个卖点
很多工具会告诉你“性能很好”。
但更值得信任的方式,是把测试结果、原始数据和对比维度公开出来。
Kreuzberg Benchmarks 页面做的正是这件事。
它让用户可以看到页面上的图表,也可以下载 GitHub Release 里的原始 JSON 数据。你可以相信官方总结,也可以自己重新分析。
对开源工具来说,这种透明度很重要。
因为文档处理本来就高度依赖真实样本。没有任何一个工具能用一句话覆盖所有场景。越是复杂的领域,越需要可验证的数据,而不是单向宣传。
总结
Kreuzberg Benchmarks 想传达的核心信息很清楚:
文档抽取不只是“能不能抽”,还要看抽得快不快、稳不稳、能不能批量跑、资源占用是否合理、是否能融入你的技术栈。
如果说 Kreuzberg Demo 解决的是“零门槛体验文档抽取”,那么 Kreuzberg Benchmarks 解决的就是“严肃选型时如何评估文档抽取能力”。
一个适合体验:
https://docs.kreuzberg.dev/demo.html[2]
一个适合选型:
https://kreuzberg.dev/benchmarks[1]
前者让你快速看到 Kreuzberg 能做什么。
后者让你用公开数据判断 Kreuzberg 是否适合你的工程场景。
对于正在建设 RAG、知识库、企业搜索、文档自动化系统的团队来说,这个 Benchmark 页面值得认真看一遍。
References
[1] https://kreuzberg.dev/benchmarks
[2] https://docs.kreuzberg.dev/demo.html
[3] https://github.com/kreuzberg-dev/kreuzberg/releases/tag/benchmark-run-21708112283
[4] https://github.com/kreuzberg-dev/kreuzberg/releases/download/benchmark-run-21708112283/aggregated.json
[5] https://github.com/kreuzberg-dev/kreuzberg/releases/download/benchmark-run-21708112283/metadata.json