夜雨聆风
夜雨聆风





应对AI Coding提效冲击,质量与测试体系的变革与重生 -(1)挑战和冲击到底是什么?

AI Coding深度赋能前段开发,短期内带来的编码效率跃迁、极速迭代模式的剧变,缩短了前段交付周期,也对研发项目交付模式带来了显著冲击,叠加领导的压力,质量、后段的测试产生明显的“窒息感”!
1、效率失衡危机:人家都能提效,你测试为啥不能(灵魂问题)?
2、质量防线动摇:你测试“既要”快,质量“又要”不能失守变差(职责绑架)!
3、模式变革必然:开发已能极速迭代,你测试这个质量兜底的“守门员”以后咋玩(未来定位)?
本文尝试着从尽可能完整的维度,来回答这些问题,并给出一些客观的建议,抛砖引玉。

凡事都有两面,要想客观的看待这个大命题,首先要能客观的看清 “前、后、左、右”。
第一部分:挑战、冲击到底是什么?
解决问题,首先要打开问题!
-
危机的导火索:前段AI提效带来的“速度与激情”
AI 深度赋能前段开发,带来极速迭代模式的剧变!
借助 OpenCode、ClaudeCode、Copilot X、Tabnine 等 AI 工具,代码生成、Bug 修复、单测编写等工作实现高度自动化,工程师开发效率显著跃升。
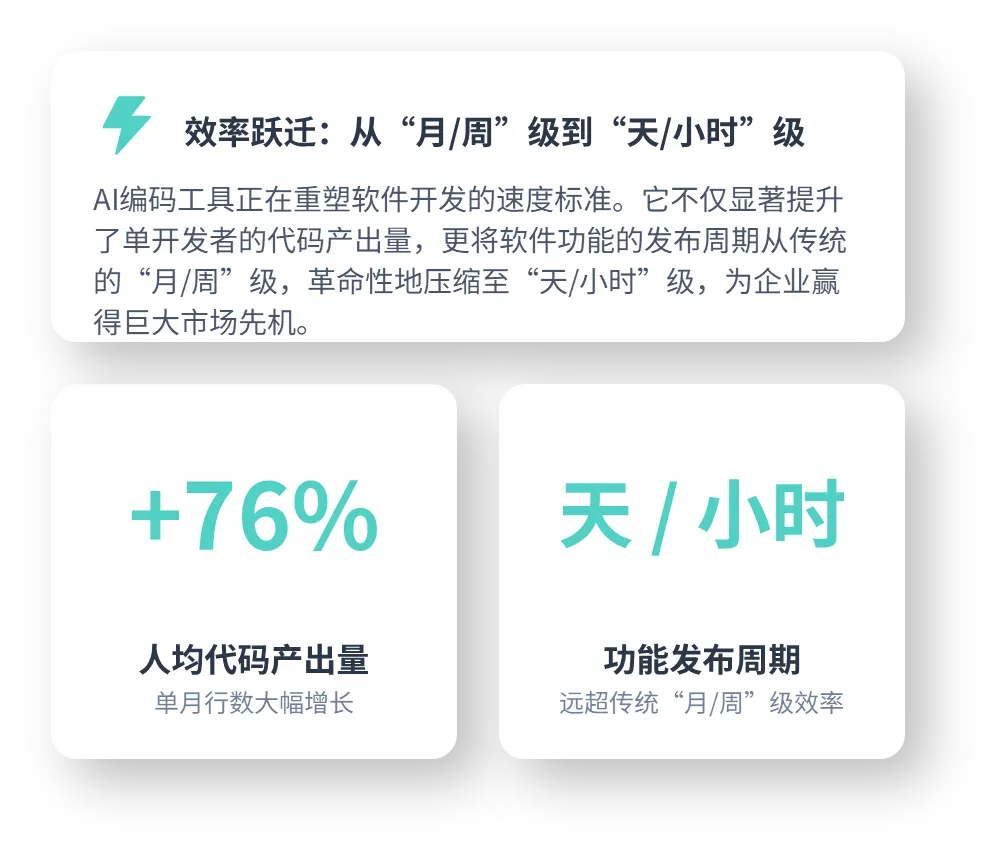
研发的编码团队彻底摆脱传统流程,实现了以“天”甚至“小时”为单位的功能发布,进入极速开发新常态。
以下是一些专业知名的研究机构的分析报告,可供参考:
1.1 Greptile 《2025 State of AI Coding》
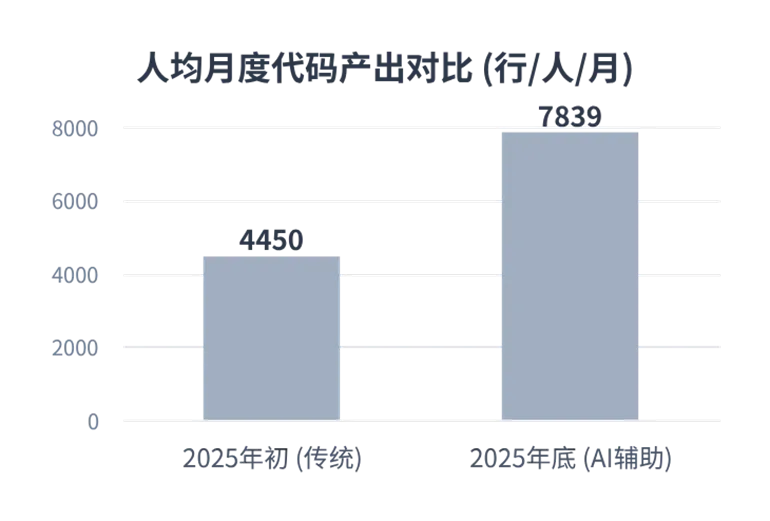
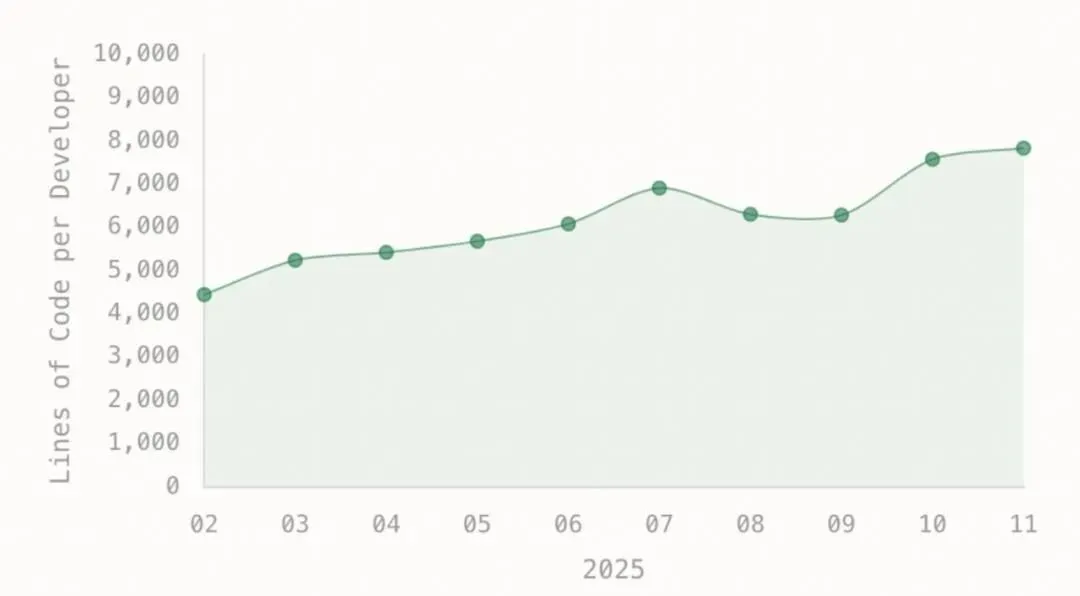
来源:Greptile. (2025). The State of AI Coding 2025.
1.2 MIT & UW (2026), CodeRabbit (2025)
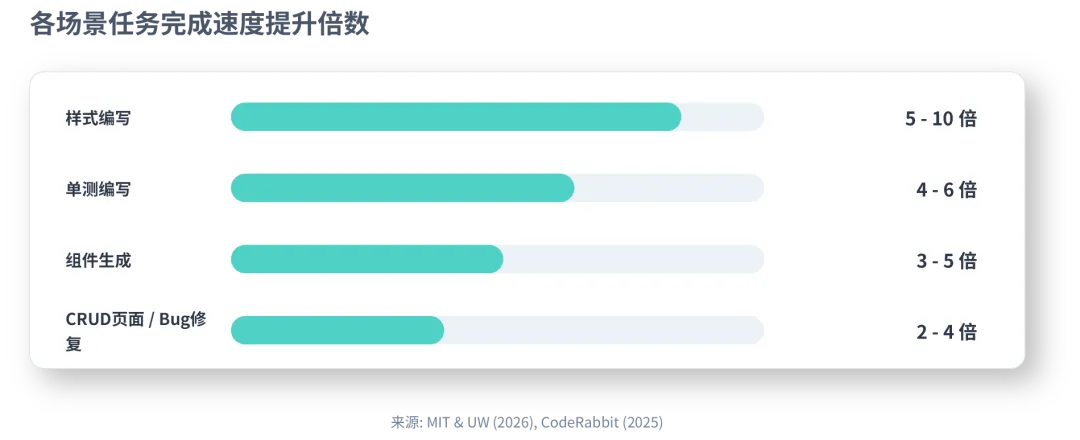
1.3 GitHub Developer Report (2025) | 阿里达摩院 & 中山大学联合研究 (2026)

正向的,AI Coding带来最大的红利就是:编码效率的极大提升!
AI Coding 的技术红利,首批收益者是编码人员,表象核心在于 “效率提升” 和 “能力放大”。它不仅让编码人员写代码更快,更重要的是,它放大了开发者的创造力和解决复杂问题的能力,让软件开发从一门 “手艺活”,逐渐演变为一门更科学、更高效的 “工程学科”。拥抱 AI Coding,就是拥抱一个更高产、更具创造力的软件开发新时代。
-
危机的另一面:前段AI提效的隐忧与挑战
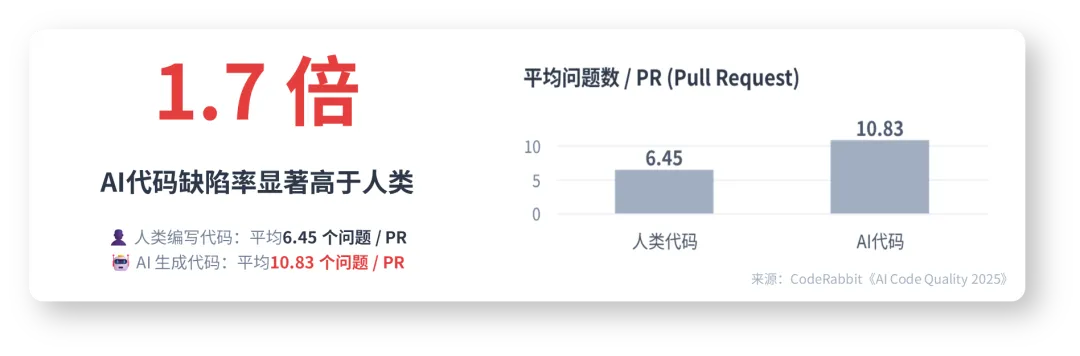
同时,负向的,速度的提升伴随着显著的质量代价,AI生成代码的缺陷率、安全漏洞与长期维护成本均显著高于人类。
这个不是最终的结论,但在AGI真正到来之前,短中期内这些问题是必然存在的!
这一点管理者必须要保持清醒,不能只被 “正向的AI红利” 蒙蔽(单方引导、片面影响、误导),否则“亚马逊核心业务板块AWS(Amazon Web Services,亚马逊云计算服务)13小时宕机事件”会发生在自己身上。
当前阶段,AI 并不是那个完美的“超级程序员”,它更像是一个高产但粗心的实习生。
可能在未来,AI会变成真正的红利,因为 人们一直在乐此不彼的探索、进步中,如:提示词工程 -> SKILLs -> Harness工程 -> … …
如下数据,并非特意为了证明 “AI的负向另一面”而针对性搜索到的“证据”,是真实客观存在的,至少在能真正驾驭AI之前是存在的。在程度上不能一刀切,是和 组织本身的知识基础、经验、规范制度强相关。
注:CodeRabbit(2025.12,工业界最权威 PR 实测)
研究对象与样本:470 个真实开源项目 PR,其中 320 个为 AI 参与编写(Copilot、Claude Code、Cursor 等),150 个为纯人工编写。
覆盖语言:Python、JS/TS、Java、C++、Go,附带少量 C#、Ruby、Rust、Shell;没有按语言单独拆分质量对比,只给了整体 1.7× 缺陷率等结论。
评估方法:CodeRabbit 自动化审查 + 人工复核,统一缺陷分级(Critical/Major/Minor/Trivial)。

其他维度的隐患还有,如:

为什么会这样?
[注:以下数据和结论参见标注来源均为知名研究机构或平台]
2.1 技术维度:AI 的 “认知” 与 “能力” 双重局限
2.1.1 LLM架构的根本性缺陷
当前主流的大语言模型(LLM)在代码生成方面存在架构性局限。MIT 与威斯康星大学在 2026 年 3 月发布的 SlopCodeBench 研究表明,在 11 个顶级模型中,没有任何一个模型能够端到端地解决任何问题,最高的检查点解决率仅为17.2%[https://arxiv.org/pdf/2603.24755]。
这种低成功率源于LLM 的本质特征 —— 它们是基于统计模式匹配而非真正的逻辑推理。AI(LLM大模型)擅长模仿语法与常见模式,但缺乏对业务上下文、边界条件、异常分支的深度理解,导致逻辑错误、漏判、错判高发。逻辑错误是 AI 代码的重灾区!【这是大模型的本质】
研究发现,AI 代码的冗余度是人类的2.2 倍,复杂度和坏味道达到2.2-2.9 倍,违反架构规则的情况高达2.9 倍(7)。更令人担忧的是,在 80% 的轨迹中出现结构侵蚀,89.8% 出现冗长问题。
具体的表象:“看起来对”但逻辑不严谨、有时候一本正经的胡说八道、幻觉… …
2.1.2 上下文理解能力的严重不足
LLM 的另一个关键缺陷是上下文理解能力有限。这种局限性在实际开发中表现为 AI 无法理解复杂的项目依赖关系。
GitHub Copilot 的代码审查功能评估研究显示,AI 在审查跨文件或跨函数的数据流方面表现极差,只能进行浅层的、基于标记的推理。
研究发现,AI 代码在业务逻辑、依赖关系和控制流方面的错误率比人类高出75%[https://blog.csdn.net/bigwhite20xx/article/details/156369299]。在 7 个基准数据集的审查中,Copilot 生成的评论不到 20 条,且大多数仅涉及拼写或次要风格问题。
2.1.3 推理能力的系统性缺失
尽管 AI 模型在语法生成方面表现出色,但在逻辑推理方面存在根本性缺陷。CodeRabbit 的研究指出,AI 擅长生成 “看起来正确” 的代码,但往往遗漏空值检查、早期返回、保护措施和全面的异常逻辑,这些问题与真实世界的故障密切相关[https://www.coderabbit.ai/blog/state-of-ai-vs-human-code-generation-report]。
这种推理缺陷在安全领域尤为突出。GitHub Copilot 的安全审计发现,其代码审查功能经常无法检测到关键漏洞,如SQL 注入、跨站脚本(XSS)和不安全反序列化,反馈主要针对低严重性问题[https://arxiv.org/pdf/2509.13650]。
2.2 数据与训练维度:”垃圾进,垃圾出” 的质量困境
2.2.1 训练数据质量的系统性问题
AI 代码质量问题的根源之一在于训练数据的质量。SonarSweep 的研究表明,使用处理后数据的模型生成的代码,安全漏洞减少了67%,错误减少了42%,而不会降低功能性能。这一发现凸显了训练数据质量对最终代码输出的决定性影响。
AI 模型的训练数据主要来自开源代码仓库,其中 GitHub/GitLab 占据主导地位,约占68%[https://wenku.csdn.net/answer/1950v2tgom]。然而,这些数据中包含大量不规范、有缺陷的 “坏代码”。研究发现,AI 倾向于模仿训练数据中看到的 “旧代码”,而这些旧代码往往充满了过时的、不安全的模式[https://blog.csdn.net/bigwhite20xx/article/details/156369299]。
在公共编码领域,AI模型的编码能力约等于平均水平,单靠个人能力很难改变的提升; 在私有业务领域,AI模型的编码能力和自己的组织历史数据与训练预料强相关,好则更好,差则更差!
2.2.2 数据偏见与代表性不足
AI 模型在代码生成过程中存在系统性偏见。ACM 数字图书馆的研究指出,AI 倾向于重现训练数据中普遍存在的不安全或次优编码实践,如易受攻击的代码片段或与安全标准不符的风格[https://acm-stag.literatumonline.com/doi/10.1145/3774324]。
这种偏见不仅体现在编码实践上,还延伸到代码相关讨论中。研究发现,AI 会复制论坛或文档中的偏见语言,在注释和解释中体现出偏见。在对四个最先进的 LLM 进行的评估中,发现所有被评估的 LLM 生成的代码都存在严重偏见[https://openreview.net/forum?id=hA0hjsKUPg]。
2.2.3 代码库污染与版本控制问题
AI 生成的代码在长期维护中面临严重的代码库污染问题。MIT 的研究显示,随着 AI 代理不断修补代码而不进行重构,复杂度会不断累积。函数因嵌套条件而膨胀,应该抽象的逻辑被重复,代码库变得越来越难以理解[https://snorkel.ai/blog/slopcodebench-measuring-code-erosion-as-agents-iterate/]。
在 20 个维护良好的代码库中,AI 代码比人类代码冗长2.2 倍,且随着每次迭代差距不断扩大。这种质量退化在迭代过程中表现得尤为明显,核心通过率与全量通过率的差距从 1.4 倍扩大到13.3 倍。
一个持续跟踪的项目显示,人类编写的代码质量保持稳定,而 AI 生成的代码在每次迭代中都在恶化。表面上核心功能似乎还能运行,但实际上边角逻辑已经 “烂透了”,一碰就崩[https://www.toutiao.com/article/7622877947883569679/?upstream_biz=doubao&source=m_redirect&wid=1777370649764]。这种 “腐烂” 效应在代码库的深层结构中逐渐累积,最终导致系统崩溃。
2.3 工程与开发流程维度:工具链与方法论的适配挑战
2.3.1 最有希望的Agent Harness还处于概念阶段
Agent Harness工程虽然被看作是驾驭AI的理想方案[https://mp.weixin.qq.com/s/1AeBaCP6VfFqItwcF7JUig],但还没有成熟的可落地推广的实践,而已有的 IDE 工具链的集成方式对 AI 代码质量产生了复杂影响,CI/CD 流程在 AI 时代面临新的适配挑战。
研究发现,传统 AI 编码工具造成 19% 的生产力损失,因为 4000-8000 个 token 的上下文窗口迫使开发者不断进行手动提示和认知模式切换,破坏了心流状态[https://www.augmentcode.com/guides/why-ai-coding-tools-make-experienced-developers-19-slower-and-how-to-fix-it]。
AI 生成的代码给传统 CI/CD 流程带来了新的复杂性。研究发现,AI 代码在集成测试中的失败率比人类代码高40%,主要原因是 AI 生成的代码缺乏对系统整体架构的理解,在与其他模块集成时容易出现兼容性问题。
2.3.2 代码审查流程的根本性变革
AI 时代的代码审查流程面临根本性变革。CodeRabbit 的研究表明,AI 生成的 PR 包含约 1.7 倍的问题,且问题严重程度更高,包含更多关键和主要问题。这导致审查时间显著增加,每个 PR 需要多处理约 4.4 个问题。
传统的代码审查流程是为人类编写的代码设计的,难以应对 AI 生成代码的特殊问题。AI 代码往往在语法上正确,但在逻辑上存在微妙错误。审查者需要花费更多时间理解 AI 的 “思维过程”,这大大增加了审查成本。
2.4 人为因素与团队管理维度:技能、信任与协作的三重挑战
2.4.1 开发者技能水平与 AI 工具使用习惯
开发者的技能水平和 AI 工具使用习惯对代码质量产生了显著影响。Stack Overflow 的调查显示,66% 的开发者对 “几乎正确但不完全对” 的 AI 解决方案感到沮丧,45.2% 认为调试 AI 生成的代码更耗时。
更令人担忧的是,只有33% 的开发者信任 AI 生成代码的准确性,较去年的 43% 有所下降[https://the-decoder.com/developers-rely-on-ai-tools-more-than-ever-but-trust-is-slipping/]。经验丰富的开发者最为谨慎,”高度信任” 率最低(2.6%),”高度不信任” 率最高(20%)。
这种信任危机源于 AI 代码的 “恐怖谷” 现象。AI 解决方案往往处于 “几乎正确” 的状态,这种状态比完全错误的代码更难调试。开发者需要花费大量时间理解 AI 的意图,找出代码中的细微错误。
2.4.2 团队协作模式的深刻变化
AI 工具正在重塑团队协作模式,但这种变化并非总是积极的。Stack Overflow 的调查显示,只有 17% 的 AI 代理用户认为代理改善了团队协作,这是所有评估指标中最低的。
这种协作困境的根源在于 AI 代码的 “黑盒” 性质。当团队成员使用 AI 生成代码时,其他人很难理解代码的生成逻辑和设计意图。这导致代码审查变得更加困难,知识传递效率下降,团队整体的代码理解能力退化。
2.4.3 质量文化与审查责任的转移
AI 时代面临着质量文化和审查责任的根本性转移。IEEE 的研究强调了在确定适当透明度水平时人类判断的重要性[https://www.computer.org/publications/tech-news/research/ai-standards]。然而,现实中,许多开发者将审查责任转移给了 AI 工具,导致质量控制体系的弱化。
CodeRabbit 的研究发现,AI 代码中错误处理和异常路径缺失的情况几乎是人类的2 倍。这表明,当开发者过度依赖 AI 时,他们可能会放松对代码质量的要求,认为 AI 会处理所有细节。
2.5 安全与合规维度:漏洞、风险与法律的三重威胁
2.5.1 安全漏洞的系统性引入
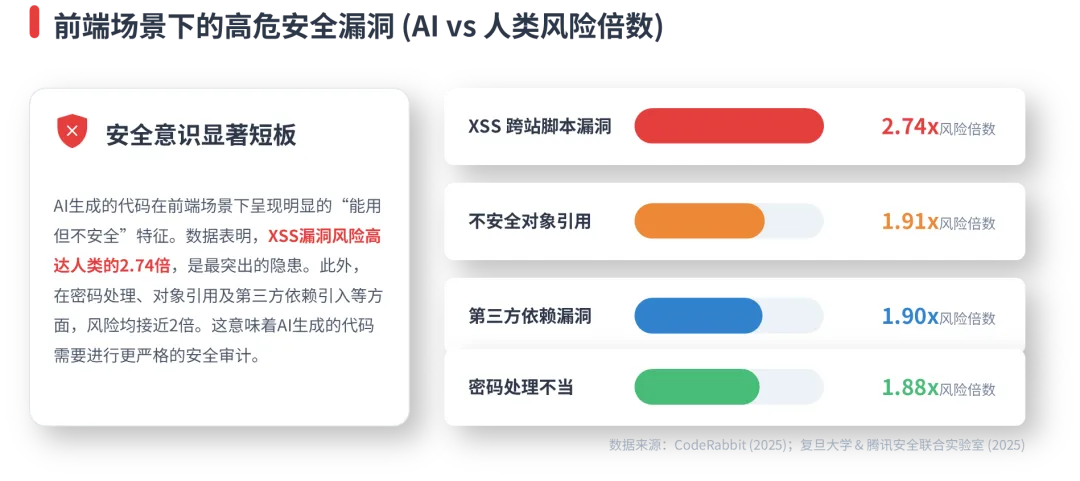
AI 代码在安全方面存在系统性漏洞。CodeRabbit 的研究显示,AI 生成代码的安全问题高达2.74 倍,最突出的模式涉及不当的密码处理和不安全的对象引用。
GitHub Copilot 的安全审计揭示了更为严重的问题。研究发现,Copilot 的代码审查功能经常无法检测到关键漏洞,如SQL 注入、跨站脚本(XSS)和不安全反序列化,其反馈主要针对低严重性问题,如编码风格和拼写错误[https://arxiv.org/pdf/2509.13650]。
在安全漏洞的具体类型上,AI 代码表现出明显的倾向性。XSS 漏洞的出现频率是人类的 2.74 倍,不安全对象引用为 1.91 倍,密码处理不当为 1.88 倍,不安全反序列化为 1.82 倍[https://www.coderabbit.ai/blog/state-of-ai-vs-human-code-generation-report]。
2.5.2 合规性风险的日益凸显
AI 代码在合规性方面面临复杂的风险。NIST 在 2025 年 7 月发布的 SP 800-53 更新草案重点关注受监管环境中的安全可靠修补[https://davegoyal.com/nist-risk-frameworks-fresh-guidance-to-harden-ai-and-it-controls-for-enterprises/]。然而,AI 生成的代码往往难以满足合规要求。
特别值得关注的是 NIST 提出的 “算法单一文化” 风险。AI 编码工具的快速采用创造了一种结构性脆弱性,几乎所有工具都共享相同的基础模型和训练数据。这种同质化增加了系统性风险,一旦某个基础模型被发现存在漏洞,可能影响所有使用该模型的系统。
2.5.3 知识产权与代码所有权的法律纠纷
AI 代码在知识产权和代码所有权方面引发了复杂的法律问题。GitHub 的研究强调了在将 AI 工具输出贡献给项目前,需要确认是否包含第三方拥有的版权材料[https://github.com/opensearch-project/technical-steering/issues/52]。
AI 生成代码的法律地位仍然模糊。当 AI 基于训练数据中的代码片段生成新代码时,可能涉及版权侵权问题。特别是当训练数据包含专有代码或未授权的开源代码时,AI 生成的代码可能继承这些法律风险。
2.6 性能与可维护性维度:效率与质量的深层矛盾
2.6.1 代码性能的严重退化
AI 生成的代码在性能方面表现出严重的退化。CodeRabbit 的研究显示,AI 生成代码中的性能回归虽然数量较少,但严重偏向 AI,过量 I/O 操作在 AI 编写的 PR 中约为8 倍。
这种性能问题的根源在于 AI 倾向于优先考虑 “解决问题” 而非 “高效解决问题”。AI 往往生成简单直接的代码,而忽略了算法复杂度和资源使用效率。在内存泄漏和资源浪费方面,AI 代码的问题也明显多于人类代码。
2.6.2 可维护性的系统性恶化
AI 代码的可维护性面临系统性挑战。CodeRabbit 的研究发现,可读性问题在 AI 贡献中激增超过3 倍,格式化问题增加 2.66 倍,命名不一致性增加近 2 倍。
MIT 的研究进一步揭示了 AI 代码的长期可维护性问题。在 20 个维护良好的代码库中,AI 代码比人类代码冗长 2.2 倍,且随着每次迭代差距不断扩大。这种退化不仅体现在代码长度上,更体现在代码结构的恶化上。
2.6.3 技术债务的快速累积
AI 编码正在加速技术债务的累积。研究发现,采用 AI 后编写的代码需要更多返工才能满足代码库标准,表明技术债务可能增加。更重要的是,额外的返工负担落在了更有经验的核心开发者身上,他们审查 6 倍的代码[https://arxiv.org/pdf/2510.10165]。
技术债务的累积不仅体现在代码质量上,还体现在开发效率的长期下降上。虽然 AI 在短期内提高了代码编写速度,但长期来看,维护这些低质量代码的成本远超初期节省的时间。
-
权衡的天枰:速度与质量
需要注意的是:AI Coding深度赋能编码效率跃迁只是研发项目内容的变化,对产品最终的交付用户的界面属性并没有发生变化,也就是说前面怎么变都行,交付给用户的产品最终质量是不能被影响(不能变差)的!
特别是那些对技术似是而非、“既要有要”的领导来说,“编码是项目的核心阶段,前段大幅度提效增速,后面的测试也要匹配增速,项目质量也要更高(最低也不能变差)”,这是一个对质量和测试人员来说是一个很不容易闭环的大命题!
我们再谨慎的回顾以下的代价对照表,至少在当前(短期内Harness工程未真正起效之前)需要被泼一盆冷水,让自己更加理智!
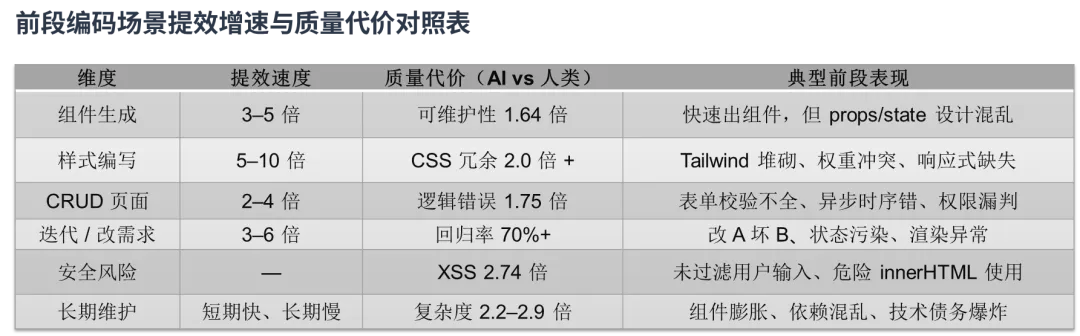
这个“速度与质量”的天枰,需要技术专家辅助管理者来权衡:
1、产品质量不劣化(提升)是企业生存的基础;
2、AI Coding的红利不可舍,AI编码是不可逆转的趋势;
3、寻求 “编码增效与质量的短期内下降的矛盾” 的解决方案;
4、研发部门AI转型的核心目标是“提升整体交付效率、降低研发成本、打造高质量产品”,前段AI提效是转型的重要抓手,而后段测试是保障转型落地的关键环节:若后段质量失控,前段再快的迭代也失去意义;若测试过于保守,又会拖累整体转型节奏;
5、全局层面需实现“三个统一”:前端迭代速度与后端测试效率统一、产品质量与交付周期统一、AI技术应用与风险管控统一;
6、既要借助AI提效抢占市场先机,也要避免因质量问题影响用户信任和部门转型成果;
7、前端AI提效追求“快迭代、快交付”,而后端测试追求“全覆盖、低风险”,两者在时间分配、资源投入上存在天然冲突;
8、以“用户体验”为底线,平衡交付速度与产品质量。
AI提效是研发部门AI转型的必然趋势,后段测试面临的冲击,本质上是“效率与质量”的平衡问题。
作为测试人员,需跳出单一测试视角,从全局、开发、测试、客户多维度出发,明确各环节的核心诉求与冲突点,通过“流程协同、AI赋能、团队升级、风险管控”四大举措,实现“前端快迭代、后端稳保障”的目标。
当前(短期内Harness工程未真正起效之前)需要勇敢的对自己的管理者 表达如下的观点:

-
质量与测试的 “窒息感”
AI Coding深度赋能前段开发,短期内带来的编码效率跃迁、极速迭代模式的剧变,缩短了前段交付周期,也对研发项目交付模式带来了显著冲击,叠加领导的压力,质量、后段的测试产生明显的“窒息感”!
这个“窒息感”至少有三大方面:
1、效率失衡危机:人家都能提效,你测试为啥不能(灵魂问题)?
2、质量防线动摇:你测试“既要”快,质量“又要”不能失守变差(职责绑架)!
3、模式变革必然:开发已能极速迭代,你测试这个质量兜底的“守门员”以后咋玩(未来定位)?
一瞬间,测试被 从研发的“辅助角色” 变成 业务发展“核心瓶颈”,形成鲜明的前后对比:

测试面临的冲击压力感知:
|
测试面临的冲击压力维度 |
重要性 |
紧急性 |
描述说明 |
|---|---|---|---|
|
效率失衡:如何能接住开发大量转测的需求工作量 |
中 |
高 |
后段测试效率提不上去,开发交付的需求积压在测试环节,项目交付直接“休克”,做都做不完,其他免谈… |
|
质量防线:过程质量->最终的用户交付质量 |
高 |
中 |
质量对企业重要性高,但存在滞后性,先解决能过下去,再持续提升质量,有质量的过下去… |
|
模式变革:测试人员后面咋玩,发展方向是啥 |
中 |
低 |
测试人员未来的发展机会,但要先解决过下去的问题… |
做数学题,让我来进一步打开、细化这些压力,算好这笔账!
4.1 效率失衡危机
测试面临的效率几笔大账如下表:(以开发AI Coding提效10倍为基准)
|
分类 |
活动描述 |
压力程度 |
描述说明 |
|---|---|---|---|
|
测新:开发10倍新需求转测试 |
新需求测试设计&生成测试用例 |
⬆10倍 |
开发转需求从10Kloc ↗ 100Kloc时: 设计用例数量:20*10=200 ↗ 2000用例 |
|
测试用例执行(主耗时活动) |
⬆10倍 |
测试周期 ↗ 10倍(不可接受)
测试人力 ↗ 10倍(不可接受) |
|
|
发现问题并回归活动 |
⬆10倍 |
新需求发现新问题:6*10=60 ↗ 600新问题 问题回归的压力也同时 ↗ 10倍 |
|
|
测旧:项目上个版本继承性功能 |
新版本旧继承功能的防修改引入的覆盖验证活动 |
↗ 全部覆盖 |
测旧工作量从人工的个别影响范围 ↗ 全部覆盖 |
|
测试资源:环境与任务 |
测试执行环境排队严重,任务大量积压 |
“拥堵” |
测试用例执行速度远跟不上前端代码的高频提交速度,效率失衡。
|
当前测试面临新需求工作量 10 倍(需结合自己开发的提效情况,换算)激增、旧功能由抽检变全量覆盖、测试环境资源拥堵任务积压三重压力,现有人力、环境、传统手工测试模式已完全承载不了业务增量与 AI 编码带来的测试复杂度提升,仅靠加人加环境不具备可行性,亟需通过智能化测试手段提效破局。
4.2 质量防线动摇
测试面临的质量几笔大账如下表:(以开发AI Coding提效10倍为基准)
|
分类 |
质量风险描述 |
压力程度 |
描述说明 |
|---|---|---|---|
|
测新:开发10倍新需求转测试 |
新需求发现问题量(平均) |
出错率:⬆1.7 倍 问题量:⬆17 倍 |
新需求发现新问题:6*10=60 ↗ 60*10*1.7=1020新问题 问题回归的压力也同时 ↗ 10*1.7 倍 |
|
业务逻辑错误、漏判、错判高发 |
出错率:⬆1.75 倍 问题量:⬆17.5 倍 |
|
|
|
性能、系统可靠性类问题 |
出错率:⬆8 倍 问题量:⬆80 倍 |
性能、系统可靠性类问题发现、定位、修改、测试回归的成本更高,且修改引入问题的概率高 |
|
|
安全/合规/漏洞质量风险 |
出错率:⬆2.74 倍 问题量:⬆27.4 倍 |
|
|
|
测旧:项目上个版本继承性功能 |
新版本旧继承功能的防修改引入的质量风险 |
↗ AI变动的代码逻辑人工很难看懂,人工几乎无法判断和识别 |
|
|
24.2% 的 AI 问题无法发现、定位解决,会长期残留,成为永久技术债务 |
↗ AI产生问题24.2%未解决 |
长期留存:有多少 AI 问题永远没解决?(arXiv,2026)分析 6275 个 GitHub 仓库、30.4 万 AI 提交、48.4 万 AI 引入问题:
|
|
|
系统架构:系统级的腐化 |
复杂模块Bug增多,修改困难,甚至无法定位和修改,系统沦为 “屎山”,只能重写 |
💀系统崩溃 |
AI Coding 对系统架构的腐化是系统性、高速、隐蔽且致命的。若无强力架构治理,6–12 个月内系统将不可维护,面临稳定性、成本、业务三重危机。 |
4.3 模式变革必然
上面“效率失衡”和“质量防线”的几笔大账,只靠测试环节的改善是解决不了问题的,需要系统性的重新设计组织,势必会引发研发新模式的变革!这不仅仅是测试部门的行动。
测试人员对这次模式变革,充满疑虑和焦躁:
|
分类 |
疑虑和焦躁描述 |
压力程度 |
描述说明 |
|---|---|---|---|
|
效率 失衡 |
开发AI提效转测工需求量,测试没“单一有效”技术手段应对 |
⬇没有“银弹” |
AI Coding的“银弹”:OpenCode、ClaudeCode、Copilot X、Tabnine 等 众多AI 工具,且能力在持续高速提升,业界有效的实践越来越多; 测试:没有类似的“银弹”,且测试活动繁杂; |
|
测试工作量增大,频繁被催进度,陷入“赶工式测试” |
压力程度: ⬆10分 |
成倍增加 从“月/周” 到“天/小时”级的频繁转测试压力 |
|
|
AI转型方向不明确,短期内全链路协同低效,测试依赖的前段扯皮增加 |
规范不明朗, 配合低效 |
传统研发的“线性流程”(需求-开发-测试-部署)无法适配AI Coding的“快速迭代”节奏,各部门沟通成本高、响应滞后,局部高效无法转化为整体高效,反而加剧流程内耗。 测试工作反复受阻:如测试重点依赖的产品规格、场景等等,文档不规范、更新不及时,前段的开发、SE提供不全、不及时 |
|
|
测试提效成了业务发展的“限速器”,成为核心焦点 |
压力程度: ⬆9分 |
很多“灵魂”问题,耗费过多精力 |
|
|
质量 防线 |
测试还有没有能力作为“守门员” “兜底”质量? |
⬇信心极其 不足 |
测试活动繁杂; 技术:没有“银弹” |
|
质量失守 |
⬆非常担心 |
技术:没有“银弹” 工作量:成倍增加 资源:环境和人力缺口无法满足 |
|
|
AI生成代码隐性缺陷多,测试难度剧增,难以全面覆盖 |
压力程度: ⬆9.5分 |
详见质量风险的描述 |
|
|
需求变更频繁且仓促,测试用例反复修改,内耗严重 |
压力程度: ⬆8.5分 |
AI Coding让开发人员能快速响应需求变更,导致产品需求变更更加频繁,且部分变更较为仓促(如产品临时调整接口参数、业务逻辑),测试人员需同步修改测试用例、调试自动化脚本,甚至重新开展测试,大量时间浪费在“修改-调整-重测”的内耗中,不仅拖慢测试进度,还容易出现用例遗漏、修改失误,加剧焦躁情绪。 |
|
|
AI变动代码范围不可控,质量责任划分模糊,出现问题后被推诿、追责 |
压力程度: ⬆7.5分 |
AI生成代码的“归属权”不清晰,开发人员认为“代码是AI生成的,出现缺陷与自身无关”,产品人员认为“需求已明确,缺陷是测试漏测导致”,而测试人员需承担最终的质量校验责任,一旦出现线上故障,容易被多方推诿、追责,即使缺陷是AI生成代码的隐性问题或开发未校验导致,测试人员也难以辩解,内心充满委屈与焦虑。 |
|
|
测试资源不足,人力、工具无法匹配高频迭代需求 |
压力程度: ⬆9.5分 |
AI Coding带来的高频迭代,让测试任务量呈倍数增加,但测试团队的人力、测试工具、测试环境等资源未同步增加——人力不足导致测试人员长期加班,测试工具适配性差(如AI测试工具不稳定、无法适配后端接口),测试环境频繁卡顿、冲突,导致测试工作无法顺利推进,既完不成进度,又无法保障质量,陷入“两难困境”。 |
|
|
个人 发展 |
自身能力无法适配AI时代测试需求,担心被淘汰 |
压力程度: ⬆9分 |
很多后端测试人员长期从事传统手动测试,对AI测试工具(如AI用例生成工具、接口自动化测试平台)的应用不熟练,面对AI生成代码的高频迭代,无法快速借助AI工具提升测试效率;同时,AI能自动完成部分基础测试工作(如简单接口的功能测试),测试人员担心自身工作被AI替代,尤其是基础测试岗位,内心充满危机感,一边赶测试进度,一边还要挤时间学习新技能,压力双重叠加。 |
|
担心测试组织被分解,个人发展的担忧 |
压力程度: ⬆9分 |
测试兜底不了,就交给开发做。 |
众多的疑虑与焦躁,核心围绕“效率、质量、能力、责任、协同”五大核心痛点,其中前3类(进度压力、隐性缺陷、能力恐慌)是测试人员最核心的焦虑来源(压力程度≥9分),也是AI Coding背景下后端测试面临的最突出问题;后7类则主要源于流程、资源、协同等配套体系的不完善,虽压力程度相对较低,但长期累积会严重影响测试人员的工作状态与工作质量,需结合研发模式变革,同步优化测试策略、资源配置、协同机制,缓解测试人员压力。
… 待续…
… 下期介绍… (若存在同样压力,请留言,相互碰撞)
第二部分:系统性应对策略
… …
第三部分:研发模式变化分析
… …
第四部分:关键应对措施
… …
⬇关注,从交流开始